3.1. Dataset
In this study, we employed a comprehensive dataset that integrates information from two distinct sources, each offering valuable insights into different aspects.
The first part of the dataset, which is publicly available, encompasses data on coronavirus cases and deaths sourced from the World Health Organization (WHO) [
13]. The provided dataset includes rates of cases and deaths for European Union (EU) countries per month. The data were further transformed into cases and deaths per million of population, enabling standardized comparisons across diverse regions.
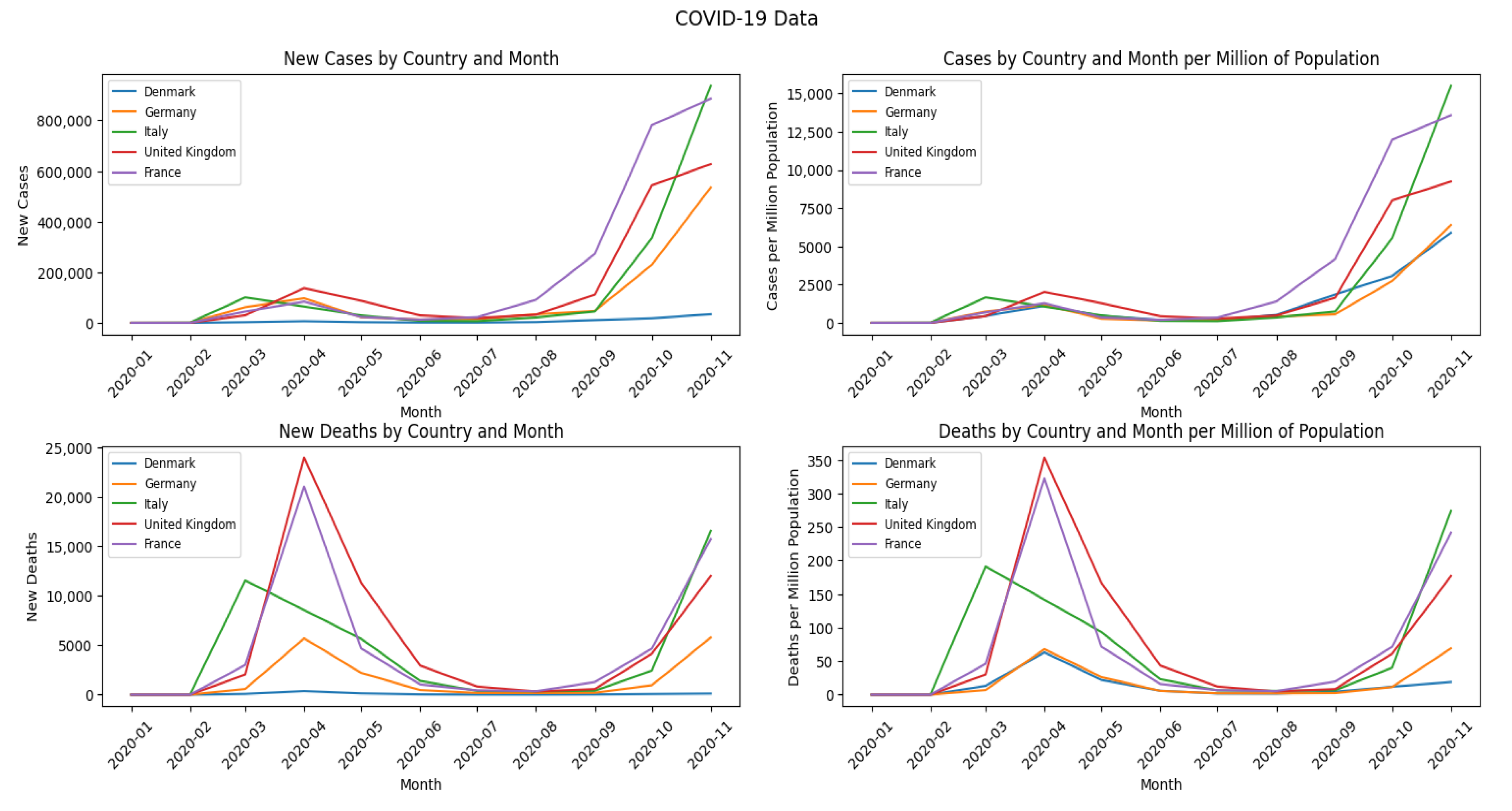
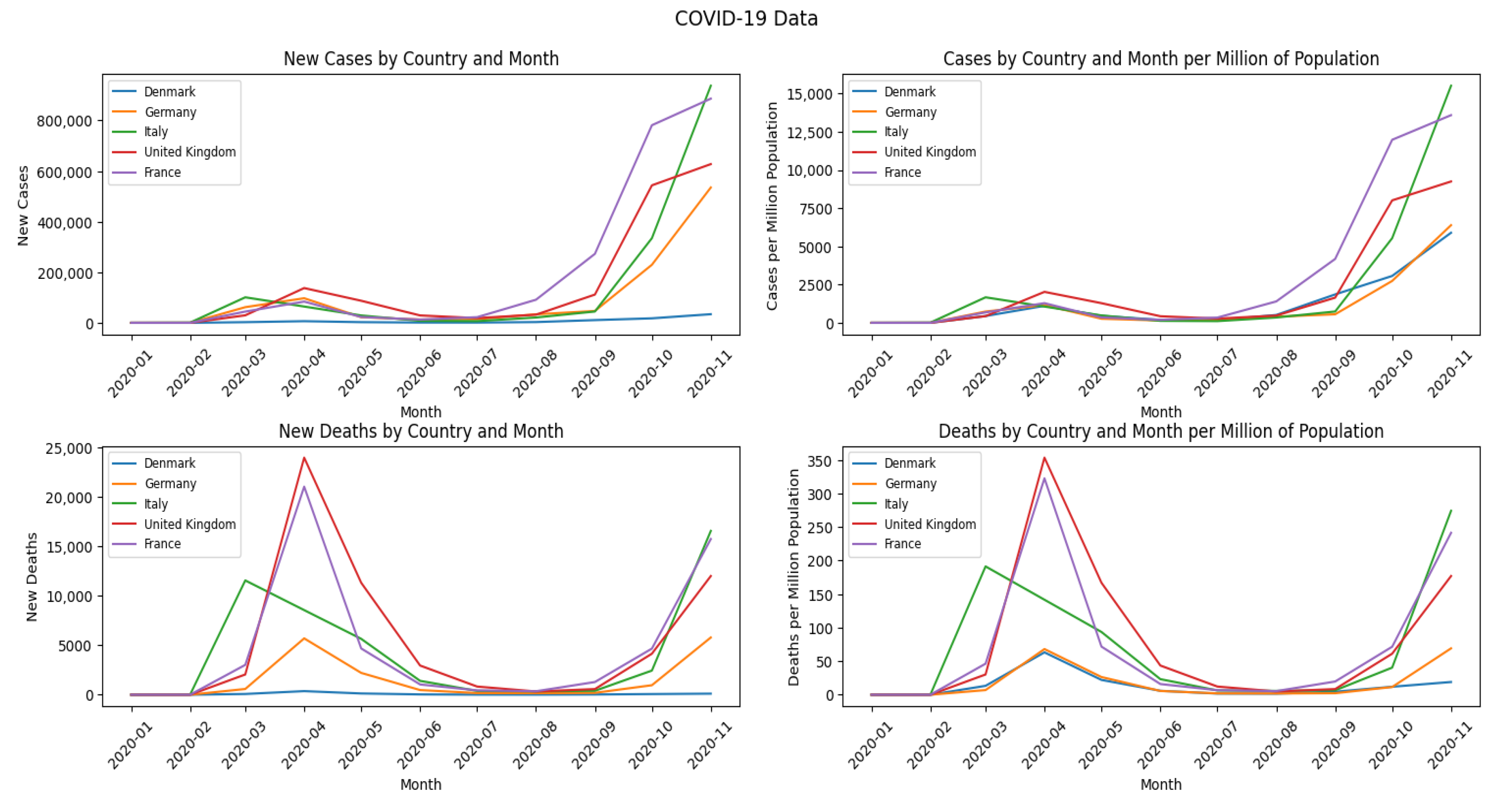
Figure 1 depicts the values of COVID-19 data per month and per million of the population for five sample countries.
The second part of the dataset comprises essential information pertaining to the price of consumer services in the Transportation, Accommodation, and Food Service sectors across the EU [
14]. These data are derived from the Joint Harmonized EU Programme of Business and Consumer Surveys, conducted by the Directorate-General for Economic and Financial Affairs of the European Commission. These surveys encompass various sectors of economic activity and involve balanced responses obtained monthly by national institutes.
Within this dataset, each participating manager’s responses are accompanied by general information about their respective businesses. The survey questions address multiple facets, including the business situation development, the evolution of demand over the past three months, expectations regarding future demand, changes in employment over the past three months, and anticipated employment trends over the next three months. Additionally, a question pertains to the estimation of changes in the price of services provided over the next three months. The answers to this question were used as a ground truth for this study’s predictive modeling. All the answers to the questions in this dataset are expressed as a balanced percentage and are weighted with a coefficient dependent on the size of the firm. The balanced percentage signifies the difference between positive and negative answers. More specifically:
where
is the percentage of “improved” answers,
the percentage of “deteriorated”, and
is the balanced percentage for answers in month
t.
The Joint Harmonized EU Programme of Business and Consumer Surveys dataset contains monthly entries from various businesses based in 27 EU countries, starting from January to November 2020, for a total of 1626 entries. The distinction within the data is made based on the sub-sector of each business. The number of entries for each sub-sector throughout the data collection period is shown in
Table 1.
Overall, 15 features are used as input to the model. These features are described in
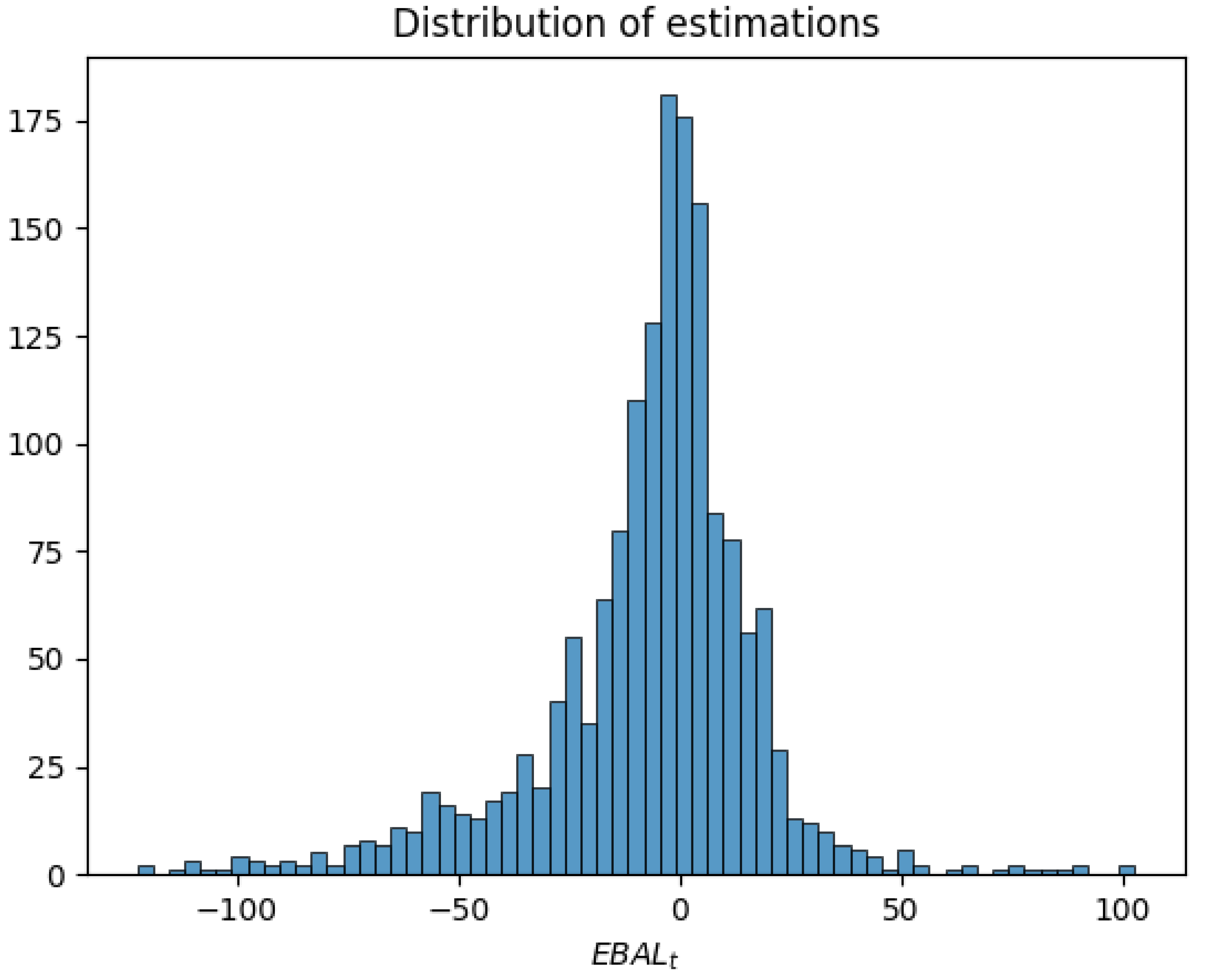
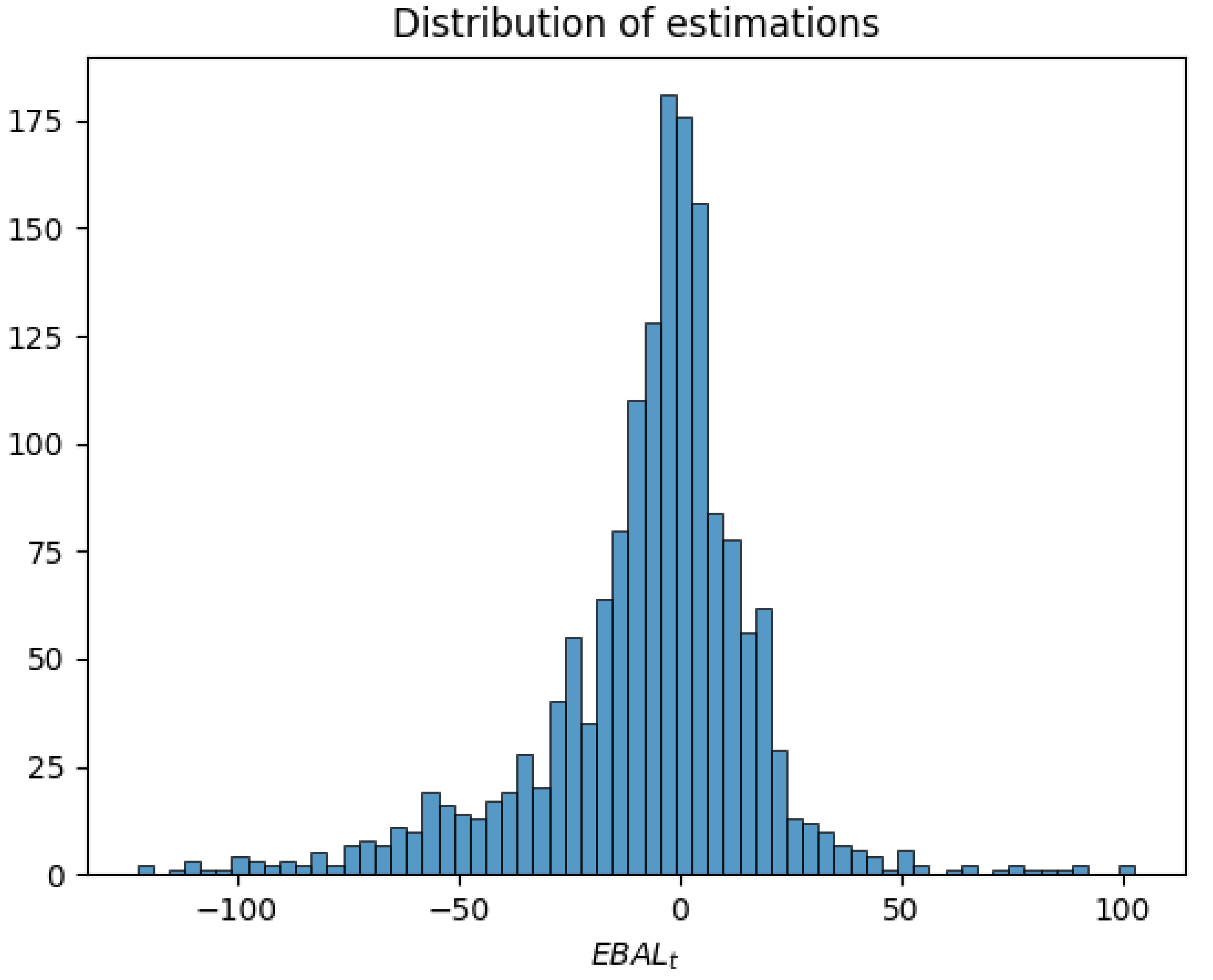
Table 2. The distribution of estimations for prices in the near future contained in the dataset is shown in
Figure 2. The histogram provides insights into the range and concentration of estimated price values, a crucial consideration for evaluating the diversity and spread of the data. The distribution appears to be skewed toward negative values, suggesting a tendency for lower estimated prices.
The incorporation of insights from the WHO COVID-19 Dashboard and the Joint Harmonized EU Programme of Business and Consumer Surveys into this comprehensive dataset offers a valuable basis for our study. It allows us to investigate various aspects of the pandemic’s impact and analyze economic trends. By utilizing these combined data sources, our aim is to gain a deeper understanding of the intricate relationship between public health dynamics and the economic landscape. We apply genetic algorithms in order to maximize the potential of this dataset and optimize model parameters to enhance predictive performance.
3.2. Preprocessing
In order to prepare the raw dataset for subsequent analysis, some preprocessing steps were undertaken. These steps ensured the suitability of the data for the chosen analytical techniques and contributed to the overall quality of the results.
Categorical features, represented as string values, required transformation into numerical format. For this reason, categorical encoding was used to convert them into an appropriate form. Additionally, prior to feeding the data into the analytical pipelines of this study, features underwent min-max scaling. Min-max scaling was selected due to its effectiveness in maintaining feature distributions while aligning them to a consistent scale. Finally, the dataset was partitioned into training and testing subsets using 80% of the samples for training purposes and 20% for testing purposes with a 5-fold cross validation strategy. This approach translates to a training set comprising 1300 samples and a testing set comprising 326 samples.
3.3. Methodology
The methodology of this study utilizes genetic algorithms (GAs) [
36,
37] to optimize the hyperparameters of predictive models. A genetic algorithm is an optimization technique inspired by the process of natural selection. It evolves and refines a population of potential solutions over multiple generations to find the best solution to a complex problem. Genetic algorithms were chosen as the optimization technique due to their ability to efficiently search through a large solution space [
38]. In this study, the fitness function for the GA was derived from the loss function of a regressor trained on the dataset. Its aim is to minimize the prediction error and improve the overall performance of the models. The root mean squared error (
) was used as the evaluation metric, which is defined as follows:
where
N represents the number of samples,
is the observed value, and
is the predicted value. In this particular scenario,
pertains to the balanced percentage of responses from each business. This response corresponds to their estimation of the anticipated price change for services offered over the upcoming three months. This estimation is further weighted by a coefficient that takes into account the respective size of each firm [
14]. This composite approach ensures a comprehensive and nuanced evaluation of the pricing dynamics within the diverse landscape of businesses under consideration.
The study employed four distinct regression models: the multilayer perceptron (MLP) neural network architecture [
39], the XGBoost model [
40], the random forest model [
41], and the CatBoost model [
42]. The multilayer perceptron is a neural network architecture, comprising multiple layers of interconnected nodes, able to learn complex patterns and relationships from data. XGBoost utilizes boosting to enhance decision trees, random forest employs ensemble learning with multiple decision trees, and CatBoost incorporates categorical feature support for improved performance. The genetic algorithm can be applied to modify the hyperparameters of these models, tailoring them to extract maximum predictive accuracy.
By employing these regression models, we aimed to leverage their respective strengths and explore the potential performance gains in regression tasks. The subsequent sections of the methodology chapter delve into the details of the hyperparameter optimization process using GAs for each model, aiming to identify the most effective hyperparameter combinations.
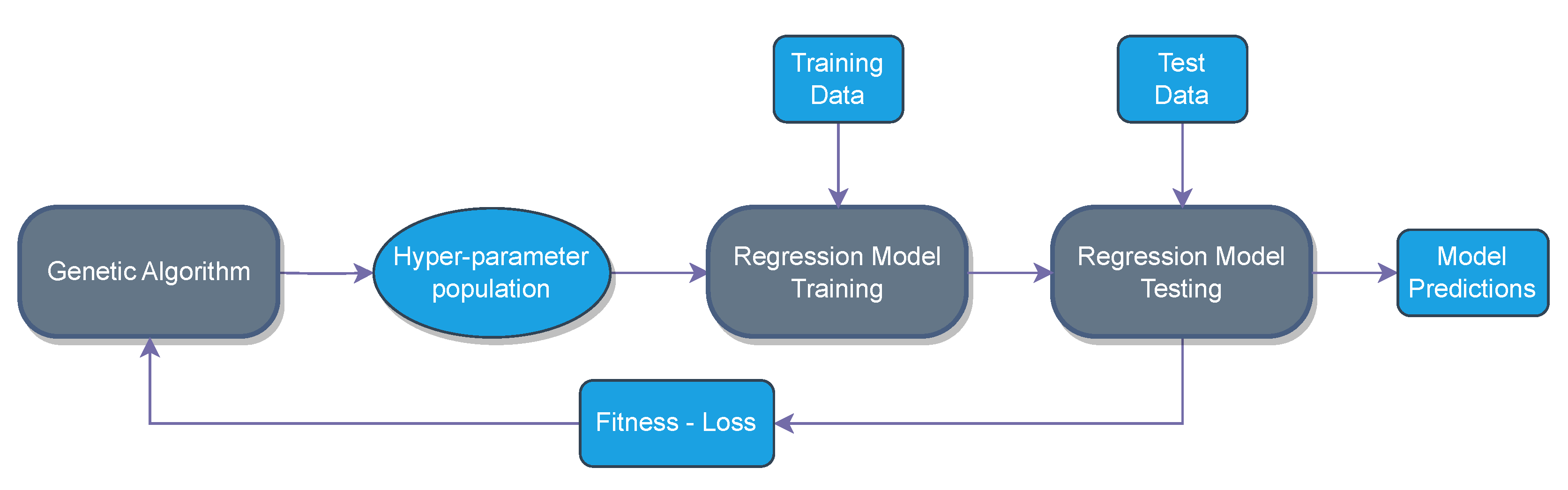
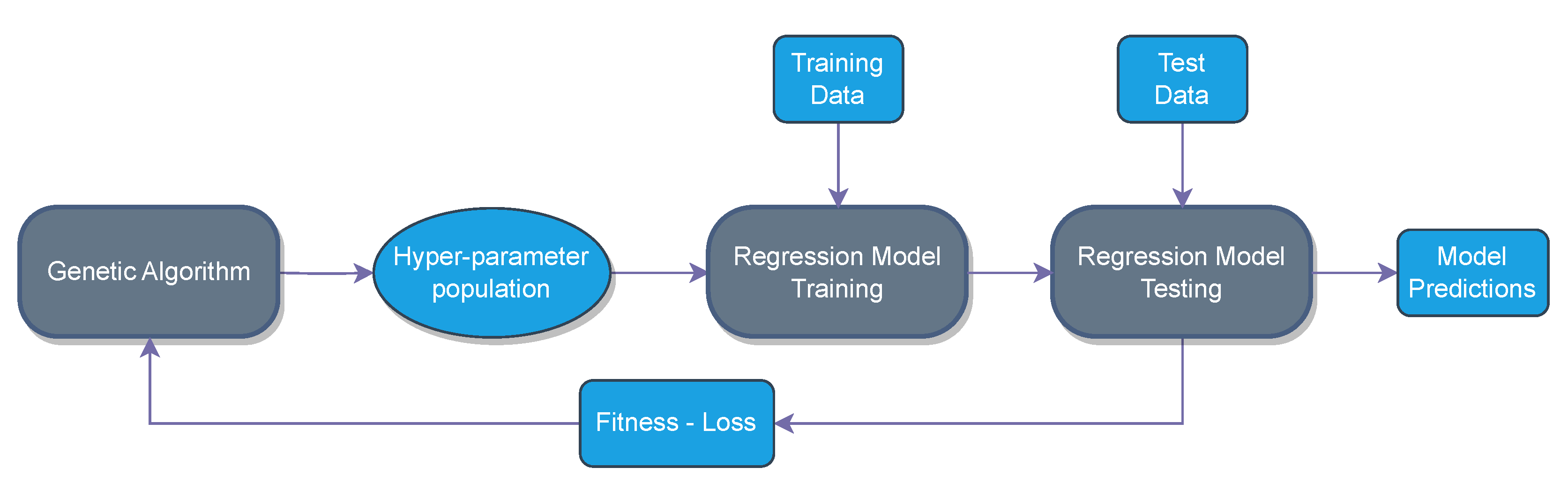
In
Figure 3, we present the iterative process of training predictive models on the training data, evaluating their performance on the test data, and using the resulting loss as a fitness function for the GA. Subsequently, the GA generates new populations of hyperparameter combinations through crossover and mutation. This iterative process continues for a specified number of generations, aiming to converge on optimal hyperparameter configurations that improve model performance.
The following subsections provide a detailed breakdown of the utility that each part of the presented pipeline has.
3.3.1. Genetic Algorithm
The GA was employed for optimizing the hyperparameters of the models, with the population characteristics defined as follows:
Population Size: A population size of 100 individuals was selected for each generation. This choice aimed to strike a balance between exploring a diverse range of hyperparameter configurations and computational efficiency. A larger population size allows for a more comprehensive search of the hyperparameter space, increasing the chances of finding optimal solutions.
Mutation Probability: A mutation probability of 0.2 was set to introduce small random changes to the hyperparameters of individuals in the population. This probability ensures that the GA explores new regions of the hyperparameter space beyond the initially selected individuals. By incorporating mutation, the GA promotes exploration and prevents premature convergence to suboptimal solutions.
Crossover Probability: The crossover probability was set to 0.8, facilitating the exchange of hyperparameter characteristics between selected individuals during reproduction. Crossover enables the recombination of promising hyperparameter combinations, potentially leading to the discovery of better solutions. A higher crossover probability increases the chances of sharing beneficial hyperparameter traits between individuals in the population.
Number of Generations: The GA was executed for 10 generations, allowing the population to evolve and improve over time. This number of generations strikes a balance between allowing sufficient iterations for convergence and avoiding excessive computational time. By evolving the population over multiple generations, the GA refines the hyperparameter configurations toward more optimal solutions.
The population characteristics were carefully determined through experimentation, with the goals of attaining optimal results while ensuring computational efficiency. The specified GA was applied consistently to all the models. By defining these parameters, the GA efficiently explored the hyperparameter space, gradually converging toward optimal hyperparameter combinations that maximize the performance of the models.
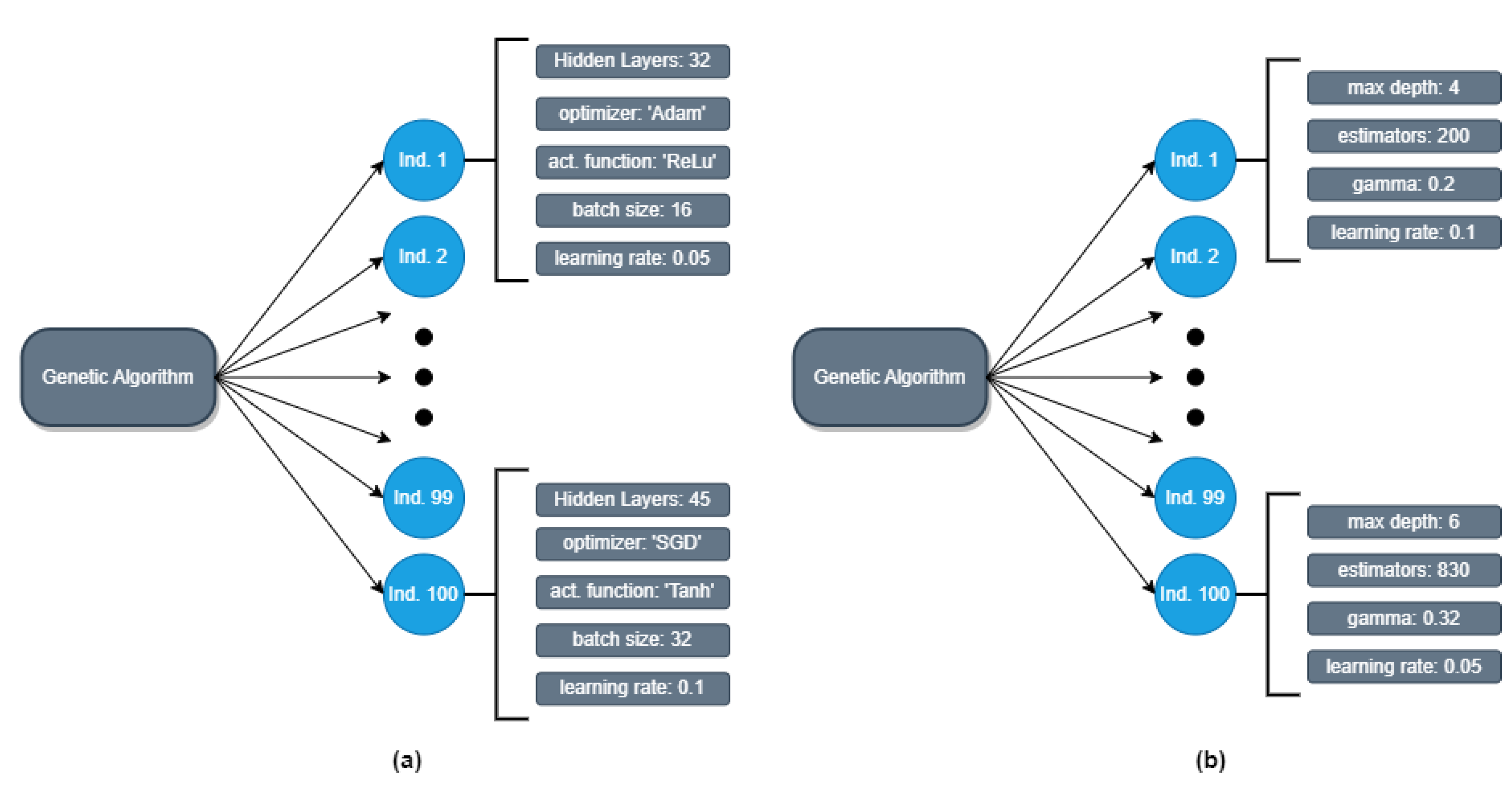
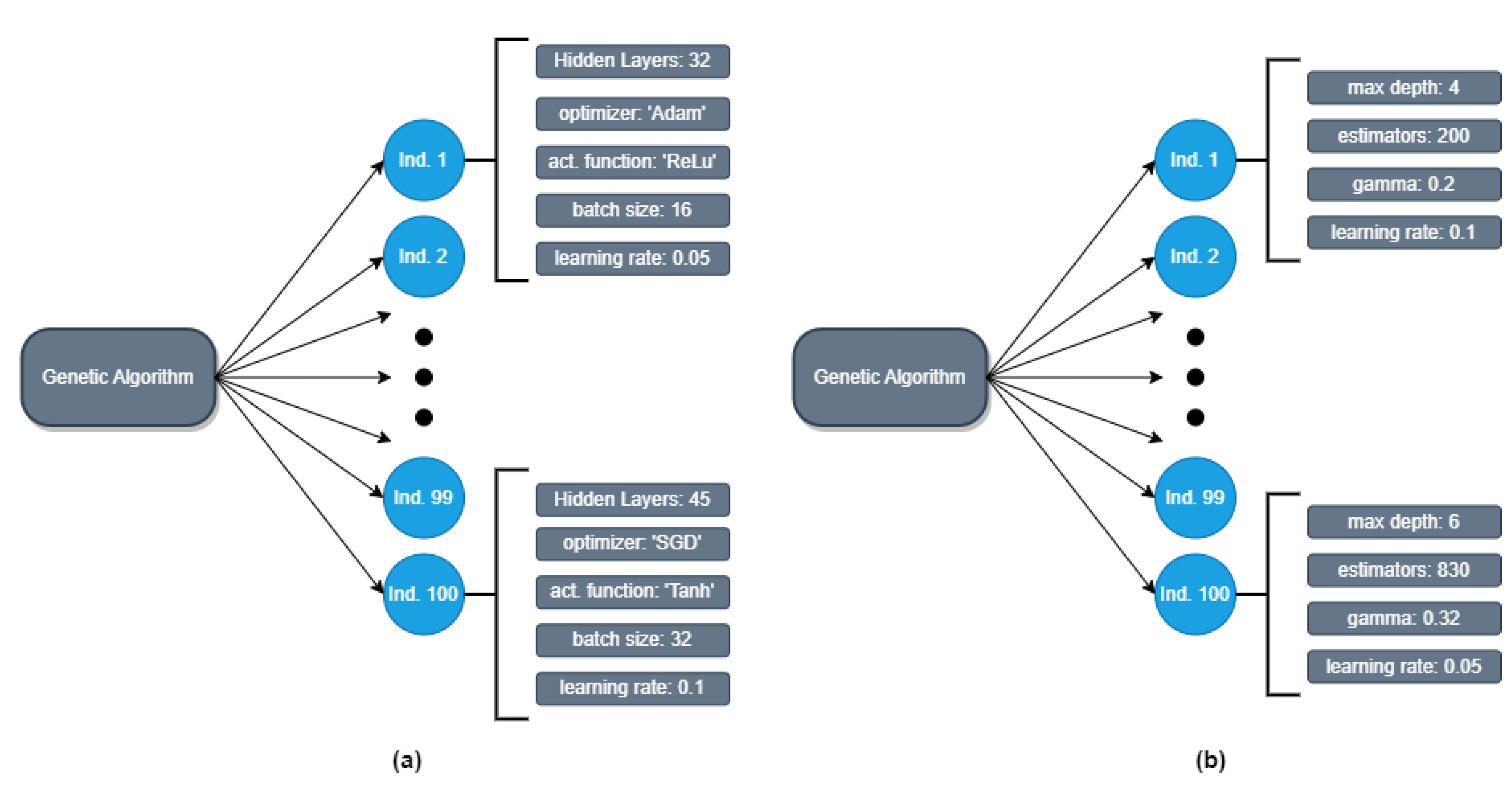
Figure 4 illustrates examples of the population generated by the GA and provides insights into the characteristics of selected individuals. These examples highlight the diverse hyperparameter configurations explored by the GA during its optimization process. By observing these individuals, we can showcase the range of hyperparameter values and combinations explored by the GA in its search for optimal solutions.
The genetic algorithm was executed to identify the optimal hyperparameters for all the models. Each model’s fitness function, derived from the loss function, guided the GA’s search for optimal hyperparameter combinations. The GA iteratively evolved the population over 10 generations, selecting individuals based on their fitness, performing crossover, and applying mutation to explore different hyperparameter configurations. The fittest individuals, which exhibited the lowest prediction error, were prioritized for reproduction, fostering the convergence of the population toward optimal solutions.
Following the GA optimization, a small grid search was conducted around the best hyperparameters obtained from the GA. This additional fine-tuning step aimed to further enhance the models’ performance by exploring neighboring values of the optimized hyperparameters. While the GA effectively explores a wide range of combinations, it may not exhaustively search the immediate vicinity of the best configuration found. The grid search involved systematically evaluating the performance of the models with slight variations in the identified hyperparameters, allowing us to identify potential performance gains that may not have been captured during the GA optimization process. By extensively exploring the range of parameters available, we ensured that the models were configured with the most optimal settings.
3.3.2. MLP Optimization
Each member of the population used for the MLP optimization process was represented by several hyperparameters that determined the model configuration. The population for the MLP fine-tuning contained the following hyperparameters:
Number of Layers: The number of hidden layers for the MLP architecture ranged from 1 to 50 in order to uncover the optimal network depth.
Optimizer: The choice of optimizer was restricted to stochastic gradient descent (SGD) and Adam.
Activation Function: The MLP architecture employed different activation functions, including rectified linear unit (ReLU), hyperbolic tangent (Tanh), logistic (Sigmoid), and identity.
Batch Size: The batch size for training varied between 4 and 128.
Learning Rate: The learning rate ranged from 0.01 to 0.1, providing a range of step sizes during model training.
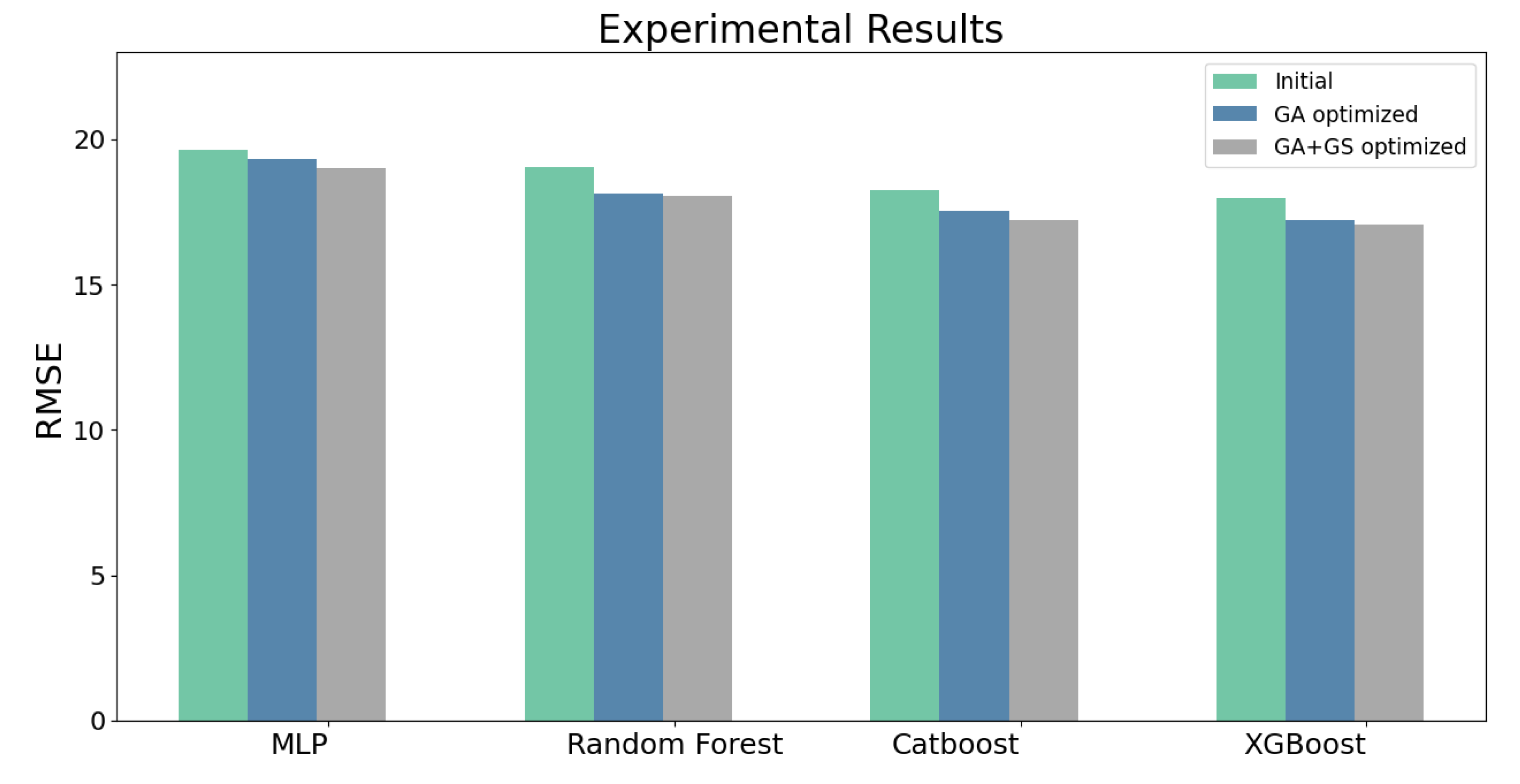
Table 3 summarizes the best hyperparameters obtained for the MLP architecture. The optimization techniques (GA and GA + GS) successfully identified optimal hyperparameter combinations for each architecture, leading to improved performance.
3.3.3. Random Forest Optimization
The optimization process for the random forest model involved the fine-tuning of several critical hyperparameters to enhance predictive performance. The selected hyperparameters for the random forest optimization included:
Minimum Samples Split: The minimum number of samples required to split an internal node in the random forest ranged from 2 to 10, aiming to control tree growth and overfitting.
Minimum Samples Leaf: The minimum number of samples required to form a leaf node varied between 1 and 5, influencing the granularity of tree structures.
Number of Estimators: The number of decision trees in the random forest ensemble was explored across a range from 50 to 1000.
Maximum Depth: The maximum depth of each tree in the ensemble spanned from 3 to 10, impacting the complexity of individual trees.
The hyperparameters fine-tuned through the optimization process for the random forest model are displayed in
Table 4.
3.3.4. CatBoost Optimization
The hyperparameters selected for optimization in the fine-tuning of the CatBoost model include the following:
Number of Estimators: The number of trees in the CatBoost ensemble varied from 50 to 1000.
Maximum Depth: The maximum depth of each tree ranged from 3 to 10.
Learning Rate: The learning rate for boosting iterations ranged from 0.01 to 0.5.
L2 Regularization: The L2 regularization parameter, which controls the amount of regularization applied to the model, ranged from 1 to 10.
The outcomes of the optimization process for the CatBoost model are summarized in
Table 5, showcasing the refined hyperparameters.
3.3.5. XGBoost Optimization
The hyperparameters selected for optimization in the fine-tuning of the XGBoost model include maximum depth, number of estimators, gamma, and learning rate:
Maximum Depth: The maximum depth of each tree ranged from 3 to 10.
Number of estimators: The number of trees in the XGBoost ensemble varied from 50 to 1000.
Gamma: The gamma parameter, controlling the minimum reduction in loss required for further partitioning, varied between 0.0 and 1.0.
Learning Rate: The learning rate for boosting iterations ranged from 0.01 to 0.1.
Table 6 showcases the final hyperparameters of the XGBoost model obtained through the optimization process.
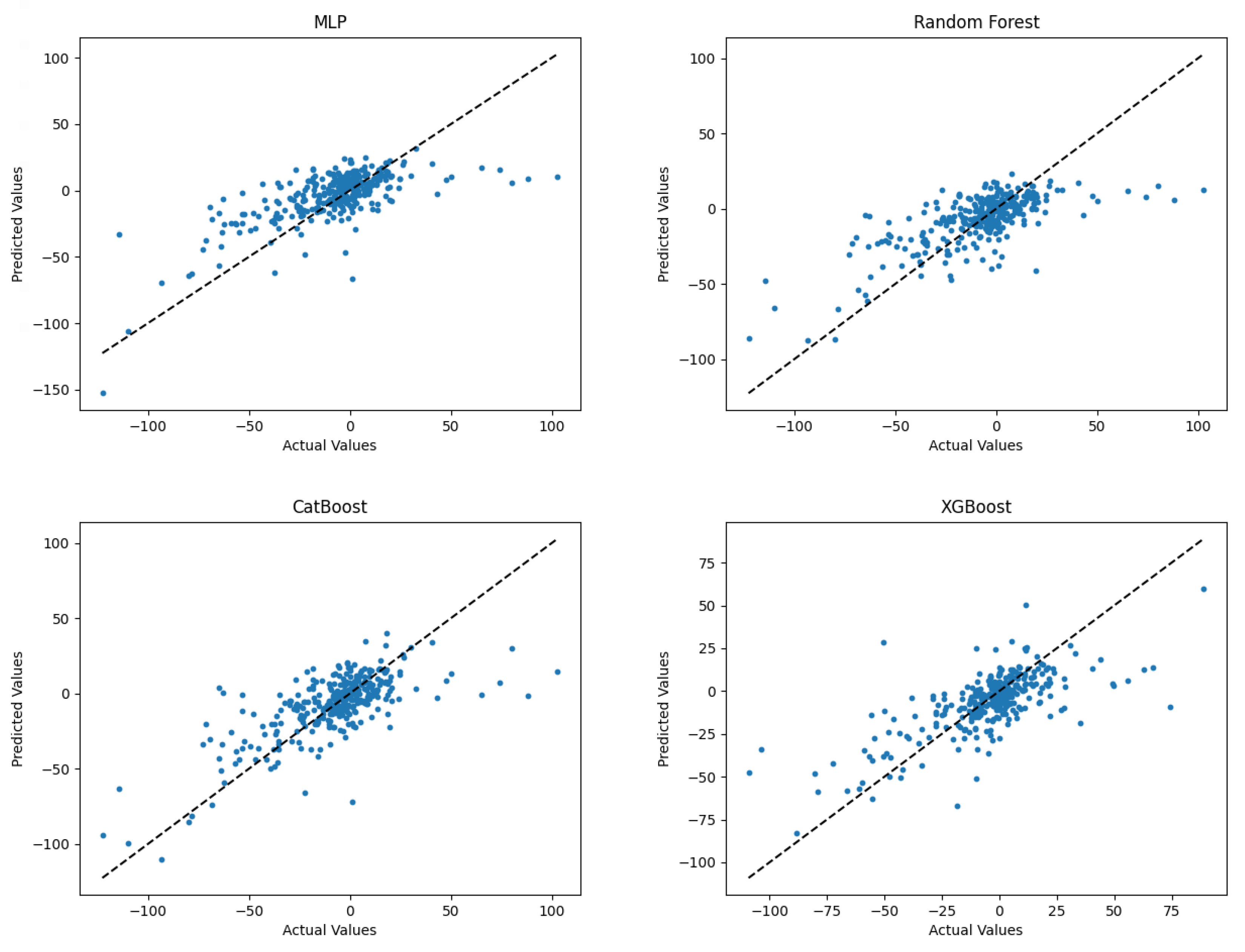
In summary, the methodology employed a genetic algorithm to optimize the hyperparameters of various machine learning models. The GA leveraged a fitness function derived from the loss function to guide the search for optimal combinations. The optimized hyperparameters were then fine-tuned through a small grid search, allowing for further performance improvements. The subsequent sections present the experimental results and analyses, showcasing the performance enhancements achieved by the optimized models. All results presented in this study were obtained through 5-fold cross-validation.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}