
A Survey of Video Surveillance Systems in Smart City


Abstract
:1. Introduction
- Object Detection and Classification: Object detection and classification techniques, that employ traditional computer vision and machine learning in edge or cloud computing, are utilized to identify various types of objects in a city scene. These objects may include people, vehicles, street plants, animals, and environmental factors. Different technologies and algorithms may be applicable, depending on the characteristics of the object, such as shape, color, and movement, to accurately detect and classify objects in video frames.
- Object Tracking: Object tracking is the process of continuously following and monitoring objects as they move across consecutive frames of a video. Valuable information such as trajectory, speed, and interactions with other objects or individuals can be obtained by tracking moving objects; for example, a hit-and-run vehicle can be tracked using a video stream from roadside closed-circuit televisions (CCTVs). Deep learning methods are often employed for object tracking and use tracking based on a single point of the object, tracking based on shape changes, or kernel-based approaches.
- HAR: HAR plays a significant role in healthcare and crowd monitoring applications, and it focuses on identifying and responding to potentially harmful actions or emergencies. HAR systems analyze and understand human actions rather than focusing solely on characteristics like movement, body shape, or skin color. Therefore, deep learning has recently been used to extract meaningful features and recognize human actions from the visual information available in video sequences.
- Anomaly Detection: Anomaly detection is important for real-time monitoring and the identification of unusual or suspicious activities. It makes proactive measures possible and prompts responses to potential threats or incidents in a smart city. Anomaly detection methods can be applied to many tasks, such as road and traffic anomaly detection, concealed weapon detection, crowd surveillance, and the detection of suspicious activity. These methods often utilize machine learning or deep learning techniques to detect behavioral patterns that deviate significantly from the expected behavior.
- Video Storage Management: For a VSS, ensuring the integrity, security, and accessibility of video data is critical. Therefore, VSSs use the blockchain to ensure data integrity, security, and controlled access by authorized personnel while efficiently storing and managing large volumes of video data using distributed storage management.
2. Video Surveillance Systems in Smart Cities
- Healthcare: Healthcare organizations use the VSS for emergency medical care, remote patient monitoring, and quarantine monitoring. Depending on a particular state of a patient detected by the camera and analyzed by deep learning algorithms such as walking, falling down, or being motionless, medical care may be given to the patient immediately. For this, video data are recorded and sent to a nearby edge node or to a cloud server. Deep learning methods like convolutional neural network (CNN) or deep neural network (DNN) decide whether the patient status requires the help of a healthcare center. Additionally, the VSS is a valuable tool to ensure compliance with quarantine guidelines and to monitor potential risks to public health during an outbreak of an infectious disease like COVID-19. For instance, health authorities can realize public quarantine to prevent the spread of the disease using the VSS with cameras placed outside the houses of quarantined individuals.
- Traffic management: Traffic management involves monitoring traffic accidents and rule violations on the road, while calculating and analyzing traffic jams using the VSS. Typically, cameras placed on roads and major intersections monitor traffic conditions and provide real-time video feeds, which can pre-process the video data using background extraction and region of interest (ROI) algorithms for real-time traffic control. Various algorithms analyze the pre-processed video data for its purpose, such as computer vision and deep learning techniques. For example, supervised deep learning methods such as CNN, mask R-CNN (MRCNN), and deep CNN (DCNN) monitor common accidents and identify similar patterns during accident monitoring. Additionally, unsupervised deep learning methods like incremental spatiotemporal learner (ISTL) discover new types of accidents to broaden the scale of the system. Furthermore, motion-detection methods based on You Only Look Once (YOLO) and CNN can predict the future movement of cars in motion in particular scenarios.
- Public safety: Video cameras placed in various public areas, such as streets, parks, transportation hubs, and commercial districts, enable the continuous monitoring of citizen activities for public safety, which particularly identify criminal activities such as theft, vandalism, and public disturbances, as well as detect suspicious movements among crowds. For this, real-time processing of recorded footage occurs on a nearby edge node or cloud server, where motion-based methods, like frame differentiating, optical flow, and deep learning algorithms, are mostly applied for human action detection. In addition, deep learning methods such as long short-term memory (LSTM), CNN, recurrent neural network (RNN), and DNN can be employed for encoder and classifier tasks, enabling the identification and categorization of prohibited human movements in an environment. Controlling cold weapons in public environments is essential to public safety. For hand-held cold weapons, they look similar to mobile phones, wallets, and cards, so deep-learning-based fine-grained algorithms are recently promising. In addition, the deployment of green plants and buildings in the urban area is primarily developed by color-based, shape-based, and texture-based computer vision methods. For instance, color-based classification methods, such as support vector machine (SVM) and k-nearest neighbor (kNN), are used to monitor plant diseases, and texture-based methods, such as Gabor filtering and local binary patterns (LBP) histograms, are used for the analysis of buildings in the city.
- Environmental monitoring: Air pollution and weather condition monitoring in urban areas rely on color-based computer vision methods to analyze live video feeds and detect visual cues related to air quality and weather patterns. For example, the VSS can identify the presence of smog or haze, which may appear as a discolored or hazy layer in the atmosphere. By focusing on specific color ranges indicative of air pollutants, real-time alerts can be provided when pollution levels exceed certain thresholds. Additionally, the system can detect rain, snow, fog, or other weather phenomena, providing valuable data for weather monitoring and forecasting. For early fire detection, it is important to detect even low-level flames as quickly as possible. Surveillance cameras are strategically placed in and around potential fire-prone zones to continuously monitor for signs of fire. Then real-time image processing techniques are applied to analyze the video frames and identify potential fire-related patterns. A combination of color-based methods, such as YOLO, CNN, and SVM classifiers, along with shape-based methods, like generative adversarial network (GAN) discriminator and DNN, can be employed to distinguish fire areas and non-fire areas. By leveraging both color and shape information, the VSS can minimize false alarms and improve the accuracy of fire detection.
3. Video Surveillance System
3.1. Monitoring Device
3.2. Edge Computing and Pre-Processing
3.3. Cloud Computing and Deep Learning
3.4. Blockchain
- Authorization and authentication: This characteristic ensures that data are exchanged only between authorized devices within the VSS for the security, integrity, and reliability of blockchain networks. By verifying the identity of devices or users with the use of membership information, authentication prevents unauthorized access to sensitive data. This process typically involves verifying credentials or digital signatures to ensure the legitimacy of participants within the blockchain network [56,57,58]. Furthermore, authentication and authorization are also used in data sharing and system integration between separate VSSs. By registering on the same blockchain, users of distinct VSSs can communicate securely by using an authentication process that allows only authorized devices to access shared data, which further enhances the security and integrity of the video surveillance ecosystem [59].
- Data integrity: This characteristic ensures that the video surveillance data stored on the blockchain are accurate, complete, and unaltered. This can be carried out using various techniques, such as digital signatures, cryptographic hashing, data encryption, and tamper-evident seals. These methods detect unauthorized changes made to the data and prevent any malicious attempts to alter the video footage [60,61].
- Distributed storage: This characteristic is based on peer-to-peer (P2P) networking, and it is used for storage like the InterPlanetary File System (IPFS). Distributed storages need to be specified for the process of accessing and cross-referencing data from multiple sources and integrating it into a single system. This makes data easier to store and distribute and enables stakeholders to access and share it seamlessly [62]. In other words, video data can be shared directly between devices without a centralized server through P2P distributed storage. This improves efficiency and reduces the risk of data loss or tampering. P2P distributed storage is used in various applications, including file sharing, content distribution, and communication platforms [63].
- Smart contracts: The smart contract is a blockchain feature that has been utilized to automate secure operations without user intervention. It increases transparency, efficiency, and flexibility in various distributed applications. Smart contracts are self-executing programs that are executed by a third party; their result is inspected by other blockchain nodes and finally written into a block. This blockchain feature enables various secure and reliable operations without having a trusted party in the distributed system [64]. Smart contracts can be used to manage assets, budgets, and even traffic congestion. For instance, smart contracts can increase transparency and ensure the proper use of a city’s budget, by automatically allocating funds for road maintenance, by taking traffic patterns and road usage as inputs in a function of the smart contract. Accordingly, city resources are scheduled efficiently for the city’s infrastructure [65].
4. Features of Video Surveillance System in Smart Cities
4.1. Object Classification and Recognition
4.1.1. Motion-Based Object Detection
4.1.2. Shape-Based Object Detection
4.1.3. Texture-Based Object Detection
4.1.4. Color-Based Object Detection

{kind=link}
{kind=link}
{kind=link}
| Feature | Classification | Method | References | Description |
|---|---|---|---|---|
| Object classification | Motion-based object detection | Deep learning | [28,29,30,49,73] | Analyzes patterns of motion and changes in appearance over time, is suitable to real-time systems, and provides high accuracy |
| Frame differencing | [68,69,72] | Computationally less complex and suitable for dynamically changing environment | ||
| Optical flow | [70,71] | Requires more complex computational methods but is more accurate than frame Differencing | ||
| Traditional computer vision algorithms | [34,74,75,76] | When algorithms are tailored to specific tasks and applications, they can achieve higher accuracy and efficiency in solving the problem at hand | ||
| Shape-based object detection | GAN discriminator, DNN, multi-view, deep learning | [32,78,79,81,82,87] | Deep learning algorithms are trained to detect objects based on their shapes and other features | |
| Texture-based object detection | Gabor filtering, LBP, GLCM, LBP histogram | [31,83,84] | Feature extraction uses an algorithm based on the texture of the object, and objects are classified by deep learning algorithms | |
| Color-based object detection | SVM, kNN classifier | [85,86] | Analyzes the color distribution in a video frame and identifies objects that match a predefined color model |
4.2. Object Tracking
4.2.1. Point-Based Object Tracking
4.2.2. Kernel-Based Object Tracking
4.2.3. Silhouette-Based Object Tracking
| Feature | Classification | Method | References | Description |
|---|---|---|---|---|
| Object tracking | Point-based | Particle filter, Kalman filter, correlation filter | [35,70,90,91,92,93] | Identifies specific points on an object’s surface and monitors their movement over time to track the object’s position and motion |
| Kernel-based | YOLO, sparse low-rank Representation | [96,97,98] | Uses a probabilistic model to estimate the object’s position and motion based on a set of kernel functions | |
| Silhouette-based | Contour tracking | [100] | Deals with objects having complex or irregular shapes |
4.3. HAR
4.3.1. Abnormal Action Detection
4.3.2. Action Classification
| Feature | Classification | Method | References | Description |
|---|---|---|---|---|
| Human action detection | Abnormal action detection | Deep learning, Blockchain | [76,103,105,110] | To enhance security, it is important to identify abnormal actions among people in both outdoor and indoor environments |
| Action classification behavior analysis | Deep learning | [113,114,115,116,117] | Identifying and classifying human actions and behavior systems help to automate the detection of suspicious behavior and improve security and safety |
4.4. Anomaly Detection
4.4.1. Road and Traffic Anomalies
4.4.2. Concealed Weapon Detection
4.4.3. Fire and Environmental Monitoring
| Feature | Classification | Method | References | Description |
|---|---|---|---|---|
| Anomaly detection | Road and traffic | Deep learning | [119,120,121,122,126] | Analyzes video by identifying and classifying unusual or anomalous events that occur on a road network, such as accidents, traffic congestion, or hazardous conditions |
| Concealed weapon detection | Deep learning | [32,127,128,129] | Identifies potential threats and prevents accidents in public places by identifying cold objects such as knives, swords, and axes in real-time video through deep learning | |
| Fire and environmental monitoring | Deep learning, edge computing | [37,86,131,133,134] | Identifies potential fire hazards and takes appropriate actions to prevent the spread of fire and minimize property damage and human casualties |
4.5. Secure Video Data Management
4.5.1. Authentication and Authorization of Video Data
4.5.2. Video Data Integrity
4.5.3. Distributed Video Data Storage
| Feature | Classification | Method | References | Description |
|---|---|---|---|---|
| Data storage security | Authentication, authorization | Blockchain | [13,56,57,58,59,136] | Both authentication and authorization are crucial to maintaining the security and integrity of a VSS |
| Data integrity | Blockchain | [137,138,139,140] | Helps to prevent or mitigate security breaches and reduce false alarms | |
| Distributed video data storage | Blockchain, off-chain, IPFS | [141,142,143,144,145,146,147] | Sensitive information contained data can be achieved through the use of encryption, access controls, and other security measures |
5. Challenges and Future Work
5.1. Drone-Based Monitoring System
5.2. Unsupervised-Learning-Based Surveillance System
5.3. False Alarm Reduction
5.4. Multi-Modal-Based System
5.5. System Resource Management
- Networking: Networking is critical to the operation of VSSs that deal-with real-time transmission of large amounts of data. By focusing on improving bandwidth utilization, reducing delay, enhancing scalability, and ensuring network security, robust and efficient networks can be established for the increasing demands of modern applications and to support seamless connectivity for users. Content filtering [22], compression [29], caching [169], and dynamic content delivery [50] techniques may be used to ensure efficient bandwidth utilization. Indeed, edge-computing [23] methods help to minimize delay and improve the performance of networked systems. In addition, software-defined networking is profitable for controlling network traffic and reducing the congestion of the network [11].
- Storage: Large amounts of video data must be stored for future reference and analysis. For the storage of video files in a surveillance system, the size of the system as well as data retention requirements, data accessibility, cost, and compliance regulations should be considered. There are several options available for storing videos, such as local storage, cloud storage, blockchain, and IPFS, and each option has particular advantages and use cases. Of these, the blockchain technology provides a decentralized, transparent, and immutable data storage system for enhancing video data security. Blockchain uses cryptographic hash to create a block on a decentralized network of nodes, which makes it difficult for anyone to manipulate surveillance video data stored in the blocks. Comparing to data storage in centralized systems vulnerable to single points of failure and attacks, the blockchain as a distributed system that operates on a network of nodes spread across different locations and, maintained by various participants, is robust to malfunction of a particular storage node.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vennam, P.; T.C., P.; B.M., T.; Kim, Y.-G.; B.N., P.K. Attacks and Preventive Measures on Video Surveillance Systems: A Review. Appl. Sci. 2021, 11, 5571. [Google Scholar] [CrossRef]
- Patrikar, D.R.; Parate, M.R. Anomaly detection using edge computing in video surveillance system: Review. Int. J. Multimed. Inf. Retr. 2022, 11, 85–110. [Google Scholar] [CrossRef] [PubMed]
- Gawande, U.; Hajari, K.; Golhar, Y. Pedestrian detection and tracking in video surveillance system: Issues, comprehensive review, and challenges. In Recent Trends in Computational Intelligence; Intech Open: London, UK, 2020; pp. 1–24. [Google Scholar]
- Rezaee, K.; Rezakhani, S.M.; Khosravi, M.R.; Moghimi, M.K. A survey on deep learning-based real-time crowd anomaly detection for secure distributed video surveillance. Pers. Ubiquitous Comput. 2021, 1–17. [Google Scholar] [CrossRef]
- Duong, H.-T.; Le, V.-T.; Hoang, V.T. Deep Learning-Based Anomaly Detection in Video Surveillance: A Survey. Sensors 2023, 23, 5024. [Google Scholar] [CrossRef] [PubMed]
- Sreenu, G.; Saleem Durai, M.A. Intelligent video surveillance: A review through deep learning techniques for crowd analysis. J. Big Data 2019, 6, 48. [Google Scholar] [CrossRef]
- Dilshad, N.; Hwang, J.; Song, J.; Sung, N. Applications and Challenges in Video Surveillance via Drone: A Brief Survey. In Proceedings of the 2020 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Republic of Korea, 21–23 October 2020. [Google Scholar]
- Ezzat, M.A.; Abd El Ghany, M.A.; Almotairi, S.; Salem, M.A.M. Horizontal Review on Video Surveillance for Smart Cities: Edge Devices, Applications, Datasets, and Future Trends. Sensors 2021, 21, 3222. [Google Scholar] [CrossRef] [PubMed]
- Shidik, G.F.; Noersasongko, E.; Nugraha, A.; Andono, P.N.; Jumanto, J.; Kusuma, E.J. A Systematic Review of Intelligence Video Surveillance: Trends, Techniques, Frameworks, and Datasets. IEEE Access 2019, 7, 170457–170473. [Google Scholar] [CrossRef]
- Gavalas, D.; Nicopolitidis, P.; Kameas, A.; Goumopoulos, C.; Bellavista, P.; Lambrinos, L.; Guo, B. Smart Cities: Recent Trends, Methodologies, and Applications. Wirel. Commun. Mob. Comput. 2017, 2017, 7090963. [Google Scholar] [CrossRef]
- Rego, A.; Canovas, A.; Jimenez, J.M.; Lloret, J. An Intelligent System for Video Surveillance in IoT Environments. IEEE Access 2018, 6, 31580–31598. [Google Scholar] [CrossRef]
- Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S. A review of video surveillance systems. J. Vis. Commun. Image Represent. 2021, 77, 103116. [Google Scholar] [CrossRef]
- Khan, P.; Byun, Y.-C.; Park, N. A Data Verification System for CCTV Surveillance Cameras Using Blockchain Technology in Smart Cities. Electronics 2020, 9, 484. [Google Scholar] [CrossRef]
- Tsakanikas, V.; Dagiuklas, T. Video surveillance systems-current status and future trends. Comput. Electr. Eng. 2018, 70, 736–753. [Google Scholar] [CrossRef]
- Jung, J.; Yoo, S.; La, W.; Lee, D.; Bae, M.; Kim, H. AVSS: Airborne Video Surveillance System. Sensors 2018, 18, 1939. [Google Scholar] [CrossRef] [PubMed]
- Memos, V.A.; Psannis, K.E. UAV-Based Smart Surveillance System over a Wireless Sensor Network. IEEE Commun. Stand. Mag. 2021, 5, 68–73. [Google Scholar] [CrossRef]
- Khan, M.A.; Alvi, B.A.; Safi, A.; Khan, I.U. Drones for good in smart cities: A review. In Proceedings of the 2018 International Conference on Electrical, Electronics, Computers, Communication, Mechanical and Computing (EECCMC), Chennai, India, 28–29 January 2018; pp. 1–6. [Google Scholar]
- Mishra, B.; Garg, D.; Narang, P.; Mishra, V. Drone-surveillance for search and rescue in natural disaster. Comput. Commun. 2020, 156, 1–10. [Google Scholar] [CrossRef]
- Durga, S.; Surya, S.; Daniel, E. SmartMobiCam: Towards a New Paradigm for Leveraging Smartphone Cameras and IaaS Cloud for Smart City Video Surveillance. In Proceedings of the 2018 2nd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 11–12 May 2018. [Google Scholar]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A Survey on Mobile Edge Computing: The Communication Perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef]
- Cao, K.; Liu, Y.; Meng, G.; Sun, Q. An Overview on Edge Computing Research. IEEE Access 2020, 8, 85714–85728. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Zhang, Q.; Sun, H.; Wu, X.; Zhong, H. Edge Video Analytics for Public Safety: A Review. Proc. IEEE 2019, 107, 1675–1696. [Google Scholar] [CrossRef]
- Pan, J.; McElhannon, J. Future Edge Cloud and Edge Computing for Internet of Things Applications. IEEE Internet Things J. 2018, 5, 439–449. [Google Scholar] [CrossRef]
- Ren, J.; Yu, G.; He, Y.; Li, G.Y. Collaborative Cloud and Edge Computing for Latency Minimization. IEEE Trans. Veh. Technol. 2019, 68, 5031–5044. [Google Scholar] [CrossRef]
- Aslanpour, M.S.; Gill, S.S.; Toosi, A.N. Performance evaluation metrics for cloud, fog and edge computing: A review, taxonomy, benchmarks and standards for future research. Internet Things 2020, 12, 100273. [Google Scholar] [CrossRef]
- Kai, C.; Zhou, H.; Yi, Y.; Huang, W. Collaborative Cloud-Edge-End Task Offloading in Mobile-Edge Computing Networks with Limited Communication Capability. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 624–634. [Google Scholar] [CrossRef]
- Fedorov, A.; Nikolskaia, K.; Ivanov, S.; Shepelev, V.; Minbaleev, A. Traffic flow estimation with data from a video surveillance camera. J. Big Data 2019, 6, 73. [Google Scholar] [CrossRef]
- Zahra, A.; Ghafoor, M.; Munir, K.; Ullah, A.; Ul Abideen, Z. Application of region-based video surveillance in smart cities using deep learning. Multimed. Tools Appl. 2021, 1–26. [Google Scholar] [CrossRef]
- Nguyen, M.T.; Truong, L.H.; Tran, T.T.; Chien, C.F. Artificial intelligence based data processing algorithm for video surveillance to empower industry 3.5. Comput. Ind. Eng. 2020, 148, 106671. [Google Scholar] [CrossRef]
- Yaseen, M.U.; Anjum, A.; Rana, O.; Hill, R. Cloud-based scalable object detection and classification in video streams. Future Gener. Comput. Syst. 2018, 80, 286–298. [Google Scholar] [CrossRef]
- Pérez-Hernández, F.; Tabik, S.; Lamas, A.; Olmos, R.; Fujita, H.; Herrera, F. Object Detection Binary Classifiers methodology based on deep learning to identify small objects handled similarly: Application in video surveillance. Knowl.-Based Syst. 2020, 194, 105590. [Google Scholar] [CrossRef]
- Zhao, L.; Wang, S.; Wang, S.; Ye, Y.; Ma, S.; Gao, W. Enhanced Surveillance Video Compression with Dual Reference Frames Generation. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1592–1606. [Google Scholar] [CrossRef]
- Lv, T.; Zhang, H.Y.; Yan, C.H. Double mode surveillance system based on remote audio/video signals acquisition. Appl. Acoust. 2018, 129, 316–321. [Google Scholar] [CrossRef]
- Elhoseny, M. Multi-object Detection and Tracking (MODT) Machine Learning Model for Real-Time Video Surveillance Systems. Circuits Syst. Signal Process. 2020, 39, 611–630. [Google Scholar] [CrossRef]
- Zhou, X.; Xu, X.; Liang, W.; Zeng, Z.; Yan, Z. Deep-Learning-Enhanced Multitarget Detection for End–Edge–Cloud Surveillance in Smart IoT. IEEE Internet Things J. 2021, 8, 12588–12596. [Google Scholar] [CrossRef]
- Sinha, S.D.D. BESDDFFS: Blockchain and EdgeDrone Based Secured Data Delivery for Forest Fire Surveillance. Peer-Peer Netw. Appl. 2021, 14, 3688–3717. [Google Scholar]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Fernandez-Carrobles, M.M.; Deniz, O.; Maroto, F. Gun and knife detection based on faster R-CNN for video surveillance. In Proceedings of the Pattern Recognition and Image Analysis: 9th Iberian Conference, IbPRIA 2019, Madrid, Spain, 1–4 July 2019; Proceedings, Part II; Springer: Berlin/Heidelberg, Germany, 2019; pp. 441–452. [Google Scholar]
- Ullah, A.; Ahmad, J.; Muhammad, K.; Sajjad, M.; Baik, S.W. Action recognition in video sequences using deep bi-directional LSTM with CNN features. IEEE Access 2017, 6, 1155–1166. [Google Scholar] [CrossRef]
- Mumtaz, A.; Bux Sargano, A.; Habib, Z. Fast learning through deep multi-net CNN model for violence recognition in video surveillance. Comput. J. 2022, 65, 457–472. [Google Scholar] [CrossRef]
- Leon, D.G.; Groli, J.; Yeduri, S.R.; Rossier, D.; Mosqueron, R.; Pandey, O.J.; Cenkeramaddi, L.R. Video Hand Gestures Recognition Using Depth Camera and Lightweight CNN. IEEE Sens. J. 2022, 22, 14610–14619. [Google Scholar] [CrossRef]
- Song, W.; Yu, J.; Zhao, X.; Wang, A. Research on action recognition and content analysis in videos based on DNN and MLN. Comput. Mater. Contin. 2019, 61, 1189–1204. [Google Scholar] [CrossRef]
- Williams, J.; Kleinegesse, S.; Comanescu, R.; Radu, O. Recognizing emotions in video using multimodal dnn feature fusion. In Proceedings of Grand Challenge and Workshop on Human Multimodal Language (Challenge-HML); Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 11–19. [Google Scholar] [CrossRef]
- Fan, Y.; Lu, X.; Li, D.; Liu, Y. Video-based emotion recognition using CNN-RNN and C3D hybrid networks. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 445–450. [Google Scholar]
- Rouast, P.V.; Adam, M.T.; Chiong, R. Deep learning for human affect recognition: Insights and new developments. IEEE Trans. Affect. Comput. 2019, 12, 524–543. [Google Scholar] [CrossRef]
- Sandhya Devi, M.R.S.; Vijay Kumar, V.R.; Sivakumar, P. A Review of image Classification and Object Detection on Machine learning and Deep Learning Techniques. In Proceedings of the 2021 5th International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 2–4 December 2021. [Google Scholar]
- Rehman, A.; Belhaouari, S.B. Deep learning for video classification: A review. TechRxiv 2021. [Google Scholar] [CrossRef]
- Zhao, Y.; Yin, Y.; Gui, G. Lightweight Deep Learning Based Intelligent Edge Surveillance Techniques. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 1146–1154. [Google Scholar] [CrossRef]
- Xu, R.; Kumar, R.; Wang, P.; Bai, P.; Meghanath, G.; Chaterji, S.; Mitra, S.; Bagchi, S. ApproxNet: Content and Contention-Aware Video Object Classification System for Embedded Clients. ACM Trans. Sens. Netw. 2022, 18, 1–27. [Google Scholar] [CrossRef]
- Ibba, S.; Pinna, A.; Seu, M.; Pani, F.E. CitySense: Blockchain-Oriented Smart Cities; ACM: New York, NY, USA, 2017. [Google Scholar]
- Mora, O.B.; Rivera, R.; Larios, V.M.; Beltran-Ramirez, J.R.; Maciel, R.; Ochoa, A. A Use Case in Cybersecurity based in Blockchain to deal with the security and privacy of citizens and Smart Cities Cyberinfrastructures. In Proceedings of the 2018 IEEE International Smart Cities Conference (ISC2), Kansas City, MO, USA, 16–19 September 2018. [Google Scholar]
- Viriyasitavat, W.; Anuphaptrirong, T.; Hoonsopon, D. When blockchain meets Internet of Things: Characteristics, challenges, and business opportunities. J. Ind. Inf. Integr. 2019, 15, 21–28. [Google Scholar] [CrossRef]
- Chattu, V.K.; Nanda, A.; Chattu, S.K.; Kadri, S.M.; Knight, A.W. The Emerging Role of Blockchain Technology Applications in Routine Disease Surveillance Systems to Strengthen Global Health Security. Big Data Cogn. Comput. 2019, 3, 25. [Google Scholar] [CrossRef]
- Rejeb, A.; Rejeb, K.; Simske, S.J.; Keogh, J.G. Blockchain technology in the smart city: A bibliometric review. Qual. Quant. 2021, 56, 2875–2906. [Google Scholar] [CrossRef]
- Yetis, R.; Sahingoz, O.K. Blockchain Based Secure Communication for IoT Devices in Smart Cities. In Proceedings of the 2019 7th International Istanbul Smart Grids and Cities Congress and Fair (ICSG), Istanbul, Turkey, 25–26 April 2019; pp. 134–138. [Google Scholar]
- Gallo, P.; Pongnumkul, S.; Quoc Nguyen, U. BlockSee: Blockchain for IoT Video Surveillance in Smart Cities. In Proceedings of the 2018 IEEE International Conference on Environment and Electrical Engineering and 2018 IEEE Industrial and Commercial Power Systems Europe (EEEIC/I&CPS Europe), Palerno, Italy, 12–15 June 2018; pp. 1–6. [Google Scholar]
- Botello, J.V.; Mesa, A.P.; Rodríguez, F.A.; Díaz-López, D.; Nespoli, P.; Mármol, F.G. BlockSIEM: Protecting Smart City Services through a Blockchain-based and Distributed SIEM. Sensors 2020, 20, 4636. [Google Scholar] [CrossRef]
- Li, J.; Liu, X.; Zhao, J.; Liang, W.; Guo, L. Application Model of Video Surveillance System Interworking Based on Blockchain. In Proceedings of the 2021 IEEE 4th Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 18–20 June 2021; Volume 4, pp. 1874–1879. [Google Scholar]
- Wei, P.; Wang, D.; Zhao, Y.; Tyagi, S.K.S.; Kumar, N. Blockchain data-based cloud data integrity protection mechanism. Future Gener. Comput. Syst. 2020, 102, 902–911. [Google Scholar] [CrossRef]
- Zarour, M.; Alenezi, M.; Ansari, M.T.J.; Pandey, A.K.; Ahmad, M.; Agrawal, A.; Kumar, R.; Khan, R.A. Ensuring data integrity of healthcare information in the era of digital health. Healthc. Technol. Lett. 2021, 8, 66–77. [Google Scholar] [CrossRef]
- Gedara, K.M.; Nguyen, M.; Yan, W.Q. Visual Blockchain for Intelligent Surveillance in Smart Cities; IGI: Antwerp, Belgium, 2018. [Google Scholar]
- Atlam, H.F.; Azad, M.A.; Alzahrani, A.G.; Wills, G. A Review of Blockchain in Internet of Things and AI. Big Data Cogn. Comput. 2020, 4, 28. [Google Scholar] [CrossRef]
- Nagothu, D.; Xu, R.; Nikouei, S.Y.; Chen, Y. A Microservice-enabled Architecture for Smart Surveillance using Blockchain Technology. In Proceedings of the 2018 IEEE International Smart Cities Conference (ISC2), Kansas, MO, USA, 16–19 September 2018; pp. 1–4. [Google Scholar]
- Alam, T. IBchain: Internet of Things and Blockchain Integration Approach for Secure Communication in Smart Cities. Informatica 2021, 45, 477–486. [Google Scholar] [CrossRef]
- Mishra, P.K.; Saroha, G.P. A Study on Classification for Static and Moving Object in Video Surveillance System. Int. J. Image Graph. Signal Process. 2016, 8, 76–82. [Google Scholar] [CrossRef]
- Chen, K.-H.; Wang, J.-H.; Su, C.-W. An Energy-efficient and Accurate Object Detection Design for Mobile Applications. In Proceedings of the 2022 IEEE International Conference on Consumer Electronics, Taiwan, China, 6 July 2022. [Google Scholar]
- Rakibe, R.S.; Patil, B.D. Background subtraction algorithm based human motion detection. Int. J. Sci. Res. Publ. 2013, 3, 2250–3153. [Google Scholar]
- Susheel Kumar, K.; Prasad, S.; Saroj, P.K.; Tripathi, R.C. Multiple Cameras Using Real Time Object Tracking for Surveillance and Security System. In Proceedings of the 2010 3rd International Conference on Emerging Trends in Engineering and Technology, Goa, India, 19–21 November 2010. [Google Scholar]
- Huang, H.; Xu, Y.; Huang, Y.; Yang, Q.; Zhou, Z. Pedestrian tracking by learning deep features. J. Vis. Commun. Image Represent. 2018, 57, 172–175. [Google Scholar] [CrossRef]
- Joshi, R.C.; Joshi, M.; Singh, A.G.; Mathur, S. Object Detection, Classification and Tracking Methods for Video Surveillance: A Review. In Proceedings of the 2018 4th International Conference on Computing Communication and Automation (ICCCA), Greater Nodia, India, 14–15 December 2018; pp. 1–7. [Google Scholar]
- Sengar, S.S.; Mukhopadhyay, S. Moving object detection based on frame difference and W4. Signal Image Video Process. 2017, 11, 1357–1364. [Google Scholar] [CrossRef]
- Naik, U.P.; Rajesh, V.; Kumar, R. Implementation of YOLOv4 Algorithm for Multiple Object Detection in Image and Video Dataset using Deep Learning and Artificial Intelligence for Urban Traffic Video Surveillance Application. In Proceedings of the 2021 Fourth International Conference on Electrical, Computer and Communication Technologies (ICECCT), Erode, India, 15–17 September 2021; pp. 1–6. [Google Scholar]
- Martella, F.; Fazio, M.; Celesti, A.; Lukaj, V.; Quattrocchi, A.; Di Gangi, M.; Villari, M. Federated Edge for Tracking Mobile Targets on Video Surveillance Streams in Smart Cities. In Proceedings of the 2022 IEEE Symposium on Computers and Communications (ISCC), Rhodes Island, Greece, 30 June–3 July 2022; pp. 1–6. [Google Scholar]
- Wang, Y.; Zhang, J.; Zhu, L.; Sun, Z.; Lu, J. A Moving Object Detection Scheme based on Video Surveillance for Smart Substation. In Proceedings of the 2018 14th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 12–16 August 2018; pp. 500–503. [Google Scholar]
- Thenmozhi, T.; Kalpana, A.M. Adaptive motion estimation and sequential outline separation based moving object detection in video surveillance system. Microprocess. Microsyst. 2020, 76, 103084. [Google Scholar] [CrossRef]
- Arikumar, K.S.; Deepak Kumar, A.; Gadekallu, T.R.; Prathiba, S.B.; Tamilarasi, K. Real-Time 3D Object Detection and Classification in Autonomous Driving Environment Using 3D LiDAR and Camera Sensors. Electronics 2022, 11, 4203. [Google Scholar] [CrossRef]
- Ammar, S.; Bouwmans, T.; Zaghden, N.; Neji, M. Deep detector classifier (DeepDC) for moving objects segmentation and classification in video surveillance. IET Image Process. 2020, 14, 1490–1501. [Google Scholar] [CrossRef]
- Kunpeng, Y.; Shan, H.; Sun, T.; Hu, R.; Wu, Y.; Yu, L.; Zhang, Z.; Quek, T.Q.S. Reinforcement Learning-based Mobile Edge Computing and Transmission Scheduling for Video Surveillance. IEEE Trans. Emerg. Top. Comput. 2021, 10, 1142–1156. [Google Scholar] [CrossRef]
- Zhao, B.; Feng, J.; Wu, X.; Yan, S. A survey on deep learning-based fine-grained object classification and semantic segmentation. Int. J. Autom. Comput. 2017, 14, 119–135. [Google Scholar] [CrossRef]
- Dhiyanesh, B.; Rajkumar, S.; Radha, R. Improved Object Detection in Video Surveillance Using Deep Convolutional Neural Network Learning. In Proceedings of the 2021 Fifth International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC 2021), Palladam, India, 11–13 November 2021; pp. 1–8. [Google Scholar]
- Deng, Y.; Chen, H.; Li, Y. MVF-Net: A Multi-view Fusion Network for Event-based Object Classification. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 8275–8284. [Google Scholar] [CrossRef]
- Manik, F.Y.; Saputra, S.K.; Ginting, D.S.B. Plant Classification Based on Extraction Feature Gray Level Co-Occurrence Matrix Using k-nearest Neighbour. J. Phys. Conf. Ser. 2019, 1566, 012107. [Google Scholar] [CrossRef]
- Bhatti, U.A.; Yu, Z.; Chanussot, J.; Zeeshan, Z.; Yuan, L.; Luo, W.; Nawaz, S.A.; Bhatti, M.A.; Ain, Q.U.; Mehmood, A. Local Similarity-Based Spatial–Spectral Fusion Hyperspectral Image Classification with Deep CNN and Gabor Filtering. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Hossain, E.; Hossain, M.F.; Rahaman, M.A. A Color and Texture Based Approach for the Detection and Classification of Plant Leaf Disease Using KNN Classifier. In Proceedings of the 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’s Bazar, Bangladesh, 7–9 February 2019; pp. 1–6. [Google Scholar]
- Hashemzadeh, M.; Zademehdi, A. Fire detection for video surveillance applications using ICA K-medoids-based color model and efficient spatio-temporal visual features. Expert Syst. Appl. 2019, 130, 60–78. [Google Scholar] [CrossRef]
- Zhang, M.; Cao, J.; Sahni, Y.; Chen, Q.; Jiang, S.; Yang, L. Blockchain-Based Collaborative Edge Intelligence for Trustworthy and Real-Time Video Surveillance. IEEE Trans. Ind. Inform. 2022, 19, 1623–1633. [Google Scholar] [CrossRef]
- Mangawati, A.; Mohana; Leesan, M.; Aradhya, H.V.R. Object Tracking Algorithms for Video Surveillance Applications. In Proceedings of the International Conference on Communications and Signal Processing, Chennai, India, 3–5 April 2018; pp. 0667–0671. [Google Scholar]
- Balaji, S.R.; Karthikeyan, S. A survey on moving object tracking using image processing. In Proceedings of the 2017 11th International Conference on Intelligent Systems and Control (ISCO), Coimbatore, India, 5–6 January 2017; pp. 469–474. [Google Scholar]
- Cob-Parro, A.C.; Losada-Gutiérrez, C.; Marrón-Romera, M.; Gardel-Vicente, A.; Bravo-Muñoz, I. Smart Video Surveillance System Based on Edge Computing. Sensors 2021, 21, 2958. [Google Scholar] [CrossRef] [PubMed]
- Elafi, I.; Jedra, M.; Zahid, N. Unsupervised detection and tracking of moving objects for video surveillance applications. Pattern Recognit. Lett. 2016, 84, 70–77. [Google Scholar] [CrossRef]
- Zhu, J.; Lao, Y.; Zheng, Y.F. Object Tracking in Structured Environments for Video Surveillance Applications. IEEE Trans. Circuits Syst. Video Technol. 2010, 20, 223–235. [Google Scholar] [CrossRef]
- Liu, S.; Liu, D.; Srivastava, G.; Połap, D.; Woźniak, M. Overview and methods of correlation filter algorithms in object tracking. Complex Intell. Syst. 2020, 7, 1895–1917. [Google Scholar] [CrossRef]
- Comaniciu, D.; Ramesh, V.; Meer, P. Kernel-based object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 564–577. [Google Scholar] [CrossRef]
- Xu, S.; Wang, J.; Shou, W.; Ngo, T.; Sadick, A.-M.; Wang, X. Computer vision techniques in construction: A critical review. Arch. Comput. Methods Eng. 2021, 28, 3383–3397. [Google Scholar] [CrossRef]
- Chen, B.-H.; Shi, L.-F.; Ke, X. Low-Rank Representation with Contextual Regularization for Moving Object Detection in Big Surveillance Video Data. In Proceedings of the 2017 IEEE Third International Conference on Multimedia Big Data (BigMM), Laguna Hills, CA, USA, 19–21 April 2017; pp. 134–141. [Google Scholar]
- Chen, B.-H.; Shi, L.-F.; Ke, X. A Robust Moving Object Detection in Multi-Scenario Big Data for Video Surveillance. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 982–995. [Google Scholar] [CrossRef]
- Jha, S.; Seo, C.; Yang, E.; Joshi, G.P. Real time object detection and trackingsystem for video surveillance system. Multimed. Tools Appl. 2021, 80, 3981–3996. [Google Scholar] [CrossRef]
- Kothiya, S.V.; Mistree, K.B. A review on real time object tracking in video sequences. In Proceedings of the 2015 International Conference on Electrical, Electronics, Signals, Communication and Optimization (EESCO), Visakhapatnam, India, 25 January 2015; pp. 1–4. [Google Scholar]
- Kanagamalliga, S.; Vasuki, S. Contour-based object tracking in video scenes through optical flow and gabor features. Optik 2018, 157, 787–797. [Google Scholar]
- Kong, Y.; Fu, Y. Human Action Recognition and Prediction: A Survey. Int. J. Comput. Vis. 2022, 130, 1366–1401. [Google Scholar] [CrossRef]
- Tomar, A.; Kumar, S.; Pant, B. Crowd Analysis in Video Surveillance: A Review. In Proceedings of the 2022 International Conference on Decision Aid Sciences and Applications (DASA), Chiangrai, Thailand, 23–25 March 2022; pp. 162–168. [Google Scholar]
- Andrade-Ambriz, Y.A.; Ledesma, S.; Ibarra-Manzano, M.A.; Oros-Flores, M.I.; Almanza-Ojeda, D.L. Human activity recognition using temporal convolutional neural network architecture. Expert Syst. Appl. 2022, 191, 116287. [Google Scholar] [CrossRef]
- Li, Q.; Lin, W.; Li, J. Human activity recognition using dynamic representation and matching of skeleton feature sequences from RGB-D images. Signal Process. Image Commun. 2018, 68, 265–272. [Google Scholar] [CrossRef]
- Bevilacqua, A.; Macdonald, K.; Rangarej, A.; Widjaya, V.; Caulfield, B.; Kechadi, T. Human Activity Recognition with Convolutional Neural Networks. In Machine Learning and Knowledge Discovery in Databases; Springer International Publishing: Wurzburg, Germany, 2019; pp. 541–552. [Google Scholar]
- Zhang, S.; Li, Y.; Zhang, S.; Shahabi, F.; Xia, S.; Deng, Y.; Alshurafa, N. Deep Learning in Human Activity Recognition with Wearable Sensors: A Review on Advances. Sensors 2022, 22, 1476. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, W.; Wang, K.I.-K.; Wang, H.; Yang, L.T.; Jin, Q. Deep-Learning-Enhanced Human Activity Recognition for Internet of Healthcare Things. IEEE Internet Things J. 2020, 7, 6429–6438. [Google Scholar] [CrossRef]
- Wan, S.; Qi, L.; Xu, X.; Tong, C.; Gu, Z. Deep Learning Models for Real-time Human Activity Recognition with Smartphones. Mob. Netw. Appl. 2020, 25, 743–755. [Google Scholar] [CrossRef]
- Xia, K.; Huang, J.; Wang, H. LSTM-CNN Architecture for Human Activity Recognition. IEEE Access 2020, 8, 56855–56866. [Google Scholar] [CrossRef]
- Islam, A.; Shin, S.Y. BHMUS: Blockchain Based Secure Outdoor Health Monitoring Scheme Using UAV in Smart City. In Proceedings of the 2019 7th International conference on Information and Communication Technology (ICoICT), Kuala Lumpur, Malaysia, 24–26 July 2019; pp. 1–6. [Google Scholar]
- Ko, T. A survey on behavior analysis in video surveillance for homeland security applications. In Proceedings of the 2008 37th IEEE Applied Imagery Pattern Recognition Workshop, Washington, DC, USA, 15–18 October 2008; pp. 1–8. [Google Scholar]
- Gowsikhaa, D.; Abirami, S.; Baskaran, R. Automated human behavior analysis from surveillance videos: A survey. Artif. Intell. Rev. 2014, 42, 747–765. [Google Scholar] [CrossRef]
- Khalifa, O.O.; Roubleh, A.; Esgiar, A.; Abdelhaq, M.; Alsaqour, R.; Abdalla, A.; Ali, E.S.; Saeed, R. An IoT-Platform-Based Deep Learning System for Human Behavior Recognition in Smart City Monitoring Using the Berkeley MHAD Datasets. Systems 2022, 10, 177. [Google Scholar] [CrossRef]
- Khan, I.U.; Afzal, S.; Lee, J.W. Human Activity Recognition via Hybrid Deep Learning Based Model. Sensors 2022, 22, 323. [Google Scholar] [CrossRef]
- Bilal, M.; Maqsood, M.; Yasmin, S.; Hasan, N.U.; Rho, S. A transfer learning-based efficient spatiotemporal human action recognition framework for long and overlapping action classes. J. Supercomput. 2022, 78, 2873–2908. [Google Scholar] [CrossRef]
- Rajavel, R.; Ravichandran, S.K.; Harimoorthy, K.; Nagappan, P.; Gobichettipalayam, K.R. IoT-based smart healthcare video surveillance system using edge computing. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 3195–3207. [Google Scholar] [CrossRef]
- Khan, M.A.; Javed, K.; Khan, S.A.; Saba, T.; Habib, U.; Khan, J.A.; Abbasi, A.A. Human action recognition using fusion of multiview and deep features: An application to video surveillance. Multimed. Tools Appl. 2020, 1–27. [Google Scholar] [CrossRef]
- Dahmane, S.; Yagoubi, M.B.; Lorenz, P.; Barka, E.; Lakas, A.; Lagraa, N.; Kerrache, C.A. V2X-based COVID-19 Pandemic Severity Reduction in Smart Cities. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar]
- Pramanik, A.; Sarkar, S.; Maiti, J. A real-time video surveillance system for traffic pre-events detection. Accid. Anal. Prev. 2021, 154, 106019. [Google Scholar] [CrossRef]
- Zhou, J.T.; Du, J.; Zhu, H.; Peng, X.; Liu, Y.; Goh, R.S.M. AnomalyNet: An Anomaly Detection Network for Video Surveillance. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2537–2550. [Google Scholar] [CrossRef]
- Franklin, R.J.; Dabbagol, V. Anomaly Detection in Videos for Video Surveillance Applications using Neural Networks. In Proceedings of the 2020 Fourth International Conference on Inventive Systems and Control (ICISC), TamilNadu, India, 8–10 January 2020; pp. 632–637. [Google Scholar]
- Gayal, B.S.; Patil, S.R. Detecting and localizing the anomalies in video surveillance using deep neuralnetwork with advanced feature descriptor. In Proceedings of the 2022 International Conference on Advances in Computing, Communication and Applied Informatics (ACCAI), TamilNadu, India, 28–29 January 2022; pp. 1–9. [Google Scholar]
- Lu, C.; Shi, J.; Jia, J. Abnormal event detection at 150 fps in matlab. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2720–2727. [Google Scholar]
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhury, A.K.; Davis, L.S. Learning temporal regularity in video sequences. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, LasVegas, NV, USA, 27–30 June 2016; pp. 733–742. [Google Scholar]
- Medel, J.R.; Savakis, A. Anomaly detection in video using predictive convolutional long short-term memory networks. arXiv 2016, arXiv:1612.00390. [Google Scholar]
- Nawaratne, R.; Alahakoon, D.; De Silva, D.; Yu, X. Spatiotemporal Anomaly Detection Using Deep Learning for Real-Time Video Surveillance. IEEE Trans. Ind. Inform. 2020, 16, 393–402. [Google Scholar] [CrossRef]
- Olmos, R.; Tabik, S.; Lamas, A.; Pérez-Hernández, F.; Herrera, F. A binocular image fusion approach for minimizing false positives in handgun detection with deep learning. Inf. Fusion 2019, 49, 271–280. [Google Scholar] [CrossRef]
- Castillo, A.; Tabik, S.; Pérez, F.; Olmos, R.; Herrera, F. Brightness guided preprocessing for automatic cold steel weapon detection in surveillance videos with deep learning. Neurocomputing 2019, 330, 151–161. [Google Scholar] [CrossRef]
- Ingle, P.Y.; Kim, Y.-G. Real-Time Abnormal Object Detection for Video Surveillance in Smart Cities. Sensors 2022, 22, 3862. [Google Scholar] [CrossRef]
- Fan, X.; Huang, C.; Fu, B.; Wen, S.; Chen, X. UAV-assisted data dissemination in delay-constrained VANETs. Mob. Inf. Syst. 2018, 2018, 8548301. [Google Scholar] [CrossRef]
- Foggia, P.; Saggese, A.; Vento, M. Real-Time Fire Detection for Video-Surveillance Applications Using a Combination of Experts Based on Color, Shape, and Motion. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1545–1556. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Baik, S.W. Early fire detection using convolutional neural networks during surveillance for effective disaster management. Neurocomputing 2018, 288, 30–42. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Baratov, N.; Kutlimuratov, A.; Whangbo, T.K. An Improvement of the Fire Detection and Classification Method Using YOLOv3 for Surveillance Systems. Sensors 2021, 21, 6519. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Mehmood, I.; Rho, S.; Baik, S.W. Convolutional Neural Networks Based Fire Detection in Surveillance Videos. IEEE Access 2018, 6, 18174–18183. [Google Scholar] [CrossRef]
- Jayamohan, M.; Yuvaraj, S.; Vijayakumar, P. Review of Video Analytics Method for Video Surveillance. In Proceedings of the 2021 4th International Conference on Recent Trends in Computer Science and Technology (ICRTCST), Jamshedpur, India, 11–12 February 2022; pp. 43–47. [Google Scholar]
- Islam, A.; Sadia, K.; Masuduzzaman, M.; Shin, S.Y. BUMAR: A Blockchain-Empowered UAV-Assisted Smart Surveillance Architecture for Marine Areas. In Proceedings of the 2020 International Conference on Computing Advancements, Dhaka, Bangladesh, 10–12 January 2020; pp. 1–5. [Google Scholar]
- Uda, R. Data Protection Method with Blockchain against Fabrication of Video by Surveillance Cameras. In Proceedings of the 2020 The 2nd International Conference on Blockchain Technology, Hilo HI, USA, 12–14 March 2020; pp. 29–33. [Google Scholar]
- Kerr, M.; Han, F.; Schyndel, R.V. A Blockchain Implementation for the Cataloguing of CCTV Video Evidence. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zeland, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Li, H.; Xiezhang, T.; Yang, C.; Deng, L.; Yi, P. Secure Video Surveillance Framework in Smart City. Sensors 2021, 21, 4419. [Google Scholar] [CrossRef]
- Lee, D.; Park, N. Blockchain based privacy preserving multimedia intelligent video surveillance using secure Merkle tree. Multimed. Tools Appl. 2021, 80, 34517–34534. [Google Scholar] [CrossRef]
- Deepak, K.; Badiger, A.N.; Akshay, J.; Awomi, K.A.; Deepak, G.; Kumar, N.H. Blockchain-based Management of Video Surveillance Systems: A Survey. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), TamilNadu, India, 6–7 March 2020; pp. 1256–1258. [Google Scholar]
- Fitwi, A.; Chen, Y.; Zhu, S. A Lightweight Blockchain-Based Privacy Protection for Smart Edge. In Proceedings of the 2019 IEEE International Conference on Blockchain (Blockchain), Seoul, Republic of Korea, 14–17 March 2019; pp. 552–555. [Google Scholar]
- Raj, A.V.B.; Srikanth, B.; Thilagavathy, A.; Mathivanan, B. A Surveillance System Focused On Approved Blockchains and Computation of Edges. J. Phys. Conf. Ser. 2020, 1964, 042058. [Google Scholar]
- Wang, R.; Tsai, W.-T.; He, J.; Liu, C.; Li, Q.; Deng, E. A Video Surveillance System Based on Permissioned Blockchains and Edge Computing. In Proceedings of the 2019 IEEE International Conference on Big Data and Smart Computing (BigComp), Kyoto, Japan, 27 February–2 March 2019; pp. 1–6. [Google Scholar]
- Jeong, Y.; Hwang, D.; Kim, K.-H. Blockchain-Based Management of Video Surveillance Systems. In Proceedings of the 2019 International Conference on Information Networking (ICOIN), Kuala Lumpur, Malaysia, 9–11 January 2019; pp. 465–468. [Google Scholar]
- Tsai, M.H.; Venkatasubramanian, N.; Hsu, C.H. Multi-level feature driven storage management of surveillance videos. Pervasive Mob. Comput. 2021, 76, 101441. [Google Scholar] [CrossRef]
- Dave, M.; Rastogi, V.; Miglani, M.; Saharan, P.; Goyal, N. Smart Fog-Based Video Surveillance with Privacy Preservation based on Blockchain. Wirel. Pers. Commun. 2022, 124, 1677–1694. [Google Scholar] [CrossRef]
- Li, X.; Savkin, A.V. Networked Unmanned Aerial Vehicles for Surveillance and Monitoring: A Survey. Future Internet 2021, 13, 174. [Google Scholar] [CrossRef]
- Nikooghadam, M.; Amintoosi, H.; Islam, S.H.; Moghadam, M.F. A provably secure and lightweight authentication scheme for Internet of Drones for smart city surveillance. J. Syst. Archit. 2021, 115, 101955. [Google Scholar] [CrossRef]
- Yue, X.; Liu, Y.; Wang, J.; Song, H.; Cao, H. Software Defined Radio and Wireless Acoustic Networking for Amateur Drone Surveillance. IEEE Commun. Mag. 2018, 56, 90–97. [Google Scholar] [CrossRef]
- Lykou, G.; Moustakas, D.; Gritzalis, D. Defending Airports from UAS: A Survey on Cyber-Attacks and Counter-Drone Sensing Technologies. Sensors 2020, 20, 3537. [Google Scholar] [CrossRef]
- Castrillo, V.U.; Manco, A.; Pascarella, D.; Gigante, G. A Review of Counter-UAS Technologies for Cooperative Defensive Teams of Drones. Drones 2022, 6, 65. [Google Scholar] [CrossRef]
- Isaac-Medina, B.K.; Poyser, M.; Organisciak, D.; Willcocks, C.G.; Breckon, T.P.; Shum, H.P. Unmanned aerial vehicle visual detection and tracking using deep neural networks: A performance benchmark. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1223–1232. [Google Scholar]
- Souli, N.; Kolios, P.; Ellinas, G. An Autonomous Counter-Drone System with Jamming and Relative Positioning Capabilities. In Proceedings of the ICC 2022-IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; pp. 5110–5115. [Google Scholar]
- Kumar, V.S.; Sakthivel, M.; Karras, D.A.; Gupta, S.K.; Gangadharan, S.M.P.; Haralayya, B. Drone Surveillance in Flood Affected Areas using Firefly Algorithm. In Proceedings of the 2022 International Conference on Knowledge Engineering and Communication Systems (ICKES), Chickballapur, India, 28–29 December 2022; pp. 1–5. [Google Scholar]
- Kumar, A.; Sharma, K.; Singh, H.; Naugriya, S.G.; Gill, S.S.; Buyya, R. A drone-based networked system and methods for combating coronavirus disease (COVID-19) pandemic. Future Gener. Comput. Syst. 2021, 115, 1–19. [Google Scholar] [CrossRef]
- Chen, K.W.; Xie, M.R.; Chen, Y.M.; Chu, T.T.; Lin, Y.B. DroneTalk: An Internet-of-Things-Based Drone System for Last-Mile Drone Delivery. IEEE Trans. Intell. Transp. Syst. 2022, 23, 15204–15217. [Google Scholar] [CrossRef]
- Ruichek, Y. Attractive-and-repulsive center-symmetric local binary patterns for texture classification. Eng. Appl. Artif. Intell. 2019, 78, 158–172. [Google Scholar]
- Shi, H.; Ghahremannezhad, H.; Liu, C. Unsupervised Anomaly Detection in Traffic Surveillance Based on Global Foreground Modeling. In Proceedings of the 2022 IEEE International Conference on Imaging Systems and Techniques (IST), New York, NY, USA, 21–23 June 2022; pp. 1–6. [Google Scholar]
- Gamage, C.; Dinalankara, R.; Samarabandu, J.; Subasinghe, A. A comprehensive survey on the applications of machine learning techniques on maritime surveillance to detect abnormal maritime vessel behaviors. WMU J. Marit. Aff. 2023, 22. [Google Scholar] [CrossRef]
- Olmos, R.; Tabik, S.; Perez-Hernandez, F.; Lamas, A.; Herrera, F. MULTICAST: MULTI Confirmation-level Alarm SysTem based on CNN and LSTM to mitigate false alarms for handgun detection in video-surveillance. arXiv 2021, arXiv:2104.11653. [Google Scholar]
- Allaoui, T.; Jeridi, M.H.; Ezzedine, T. False Alarm Reduction in WSN Surveillance Application through ML techniques. In Proceedings of the 2023 International Wireless Communications and Mobile Computing (IWCMC), Marrakesh, Morocco, 19–23 June 2023. [Google Scholar]
- Zhang, X.; Yu, Q.; Yu, H. Physics Inspired Methods for Crowd Video Surveillance and Analysis: A Survey. IEEE Access 2018, 6, 66816–66830. [Google Scholar] [CrossRef]
- Azam, Z.; Islam, M.M.; Huda, M.N. Comparative Analysis of Intrusion Detection Systems and Machine Learning Based Model Analysis through Decision Tree. IEEE Access 2023, 11, 80348–80391. [Google Scholar] [CrossRef]
- Liang, P.P.; Zadeh, A.; Morency, L.P. Foundations and Recent Trends in Multimodal Machine Learning: Principles, Challenges, and Open Questions. arXiv 2022, arXiv:2209.03430. [Google Scholar]
- Hafeez, S.; Alotaibi, S.S.; Alazeb, A.; Al Mudawi, N.; Kim, W. Multi-sensor-based Action Monitoring and Recognition via Hybrid Descriptors and Logistic Regression. IEEE Access 2023, 11, 48145–48157. [Google Scholar] [CrossRef]
- Javeed, M.; Mudawi, N.A.; Alabduallah, B.I.; Jalal, A.; Kim, W. A Multimodal IoT-Based Locomotion Classification System Using Features Engineering and Recursive Neural Network. Sensors 2023, 23, 4716. [Google Scholar] [CrossRef]
- Vikram, R.; Sinha, D. A multimodal framework for Forest fire detection and monitoring. Multimed. Tools Appl. 2023, 82, 9819–9842. [Google Scholar] [CrossRef]
- Alladi, T.; Chamola, V.; Sahu, N.; Guizani, M. Applications of blockchain in unmanned aerial vehicles: A review. Veh. Commun. 2020, 23, 100249. [Google Scholar] [CrossRef]
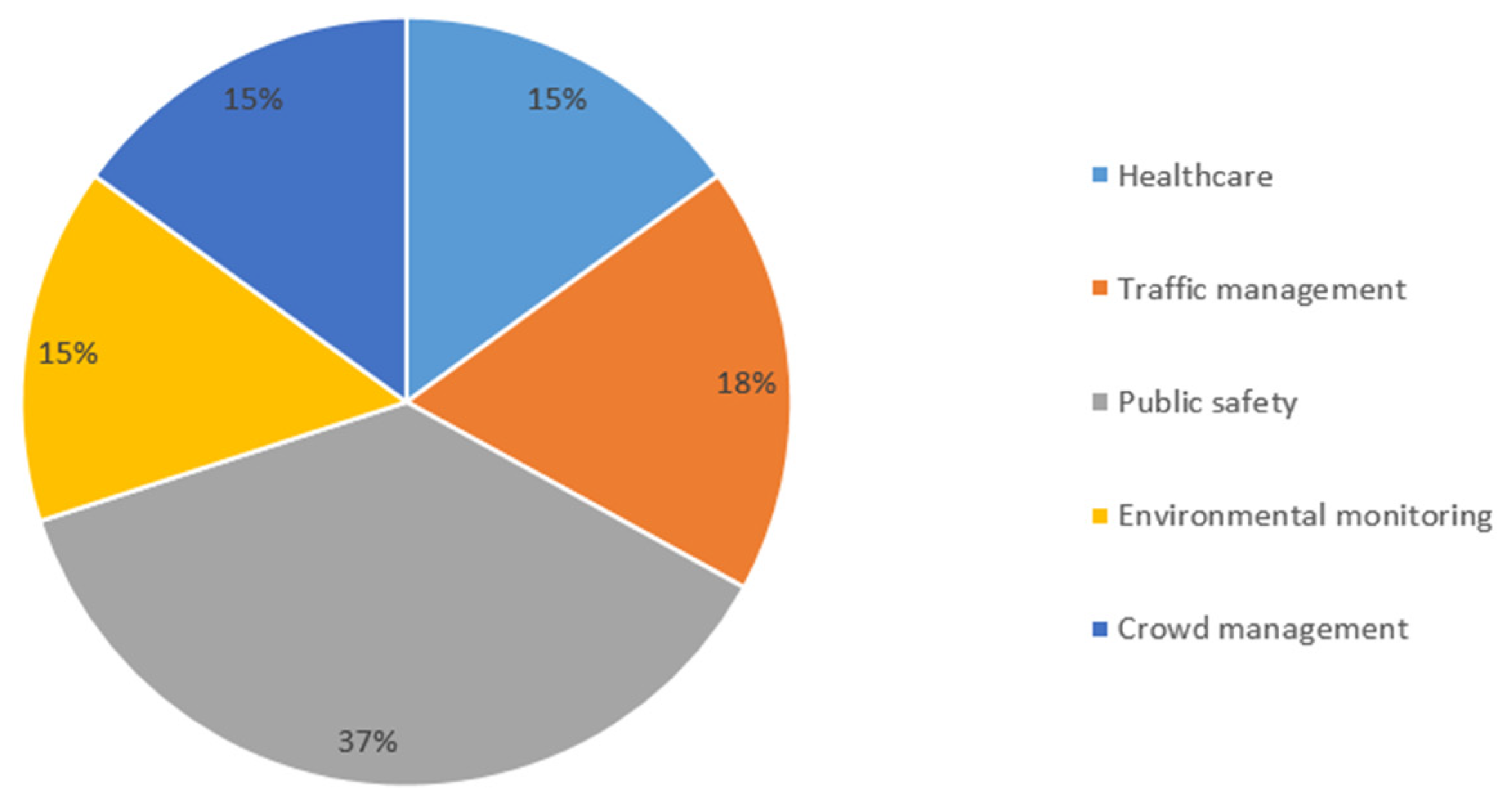


| Healthcare |
|
| Traffic management |
|
| Public safety |
|
| Environmental monitoring |
|
| System | Method | Reason for False Alarm |
|---|---|---|
| [126] | Deep learning | Alarms are recognized as abnormal when unknown or new normality appears |
| [121] | Neural network | What is considered an anomaly today may not be considered an anomaly tomorrow due to the lack of data |
| [161] | Deep learning | Post-incident alarm triggering occurs from training crowd safety analysis on only human movement |
| [116,118] | In order not to create false alarms in the healthcare system, it is necessary to use a human observer | |
| [162] | Intruders may deliberately trigger false alarms by covering or tampering with cameras |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Myagmar-Ochir, Y.; Kim, W. A Survey of Video Surveillance Systems in Smart City. Electronics 2023, 12, 3567. https://doi.org/10.3390/electronics12173567
Myagmar-Ochir Y, Kim W. A Survey of Video Surveillance Systems in Smart City. Electronics. 2023; 12(17):3567. https://doi.org/10.3390/electronics12173567
Chicago/Turabian StyleMyagmar-Ochir, Yanjinlkham, and Wooseong Kim. 2023. "A Survey of Video Surveillance Systems in Smart City" Electronics 12, no. 17: 3567. https://doi.org/10.3390/electronics12173567
APA StyleMyagmar-Ochir, Y., & Kim, W. (2023). A Survey of Video Surveillance Systems in Smart City. Electronics, 12(17), 3567. https://doi.org/10.3390/electronics12173567