


Oriented Object Detection in Remote Sensing Using an Enhanced Feature Pyramid Network


Abstract
:1. Introduction
2. Related Work on Object Detection
3. Methods
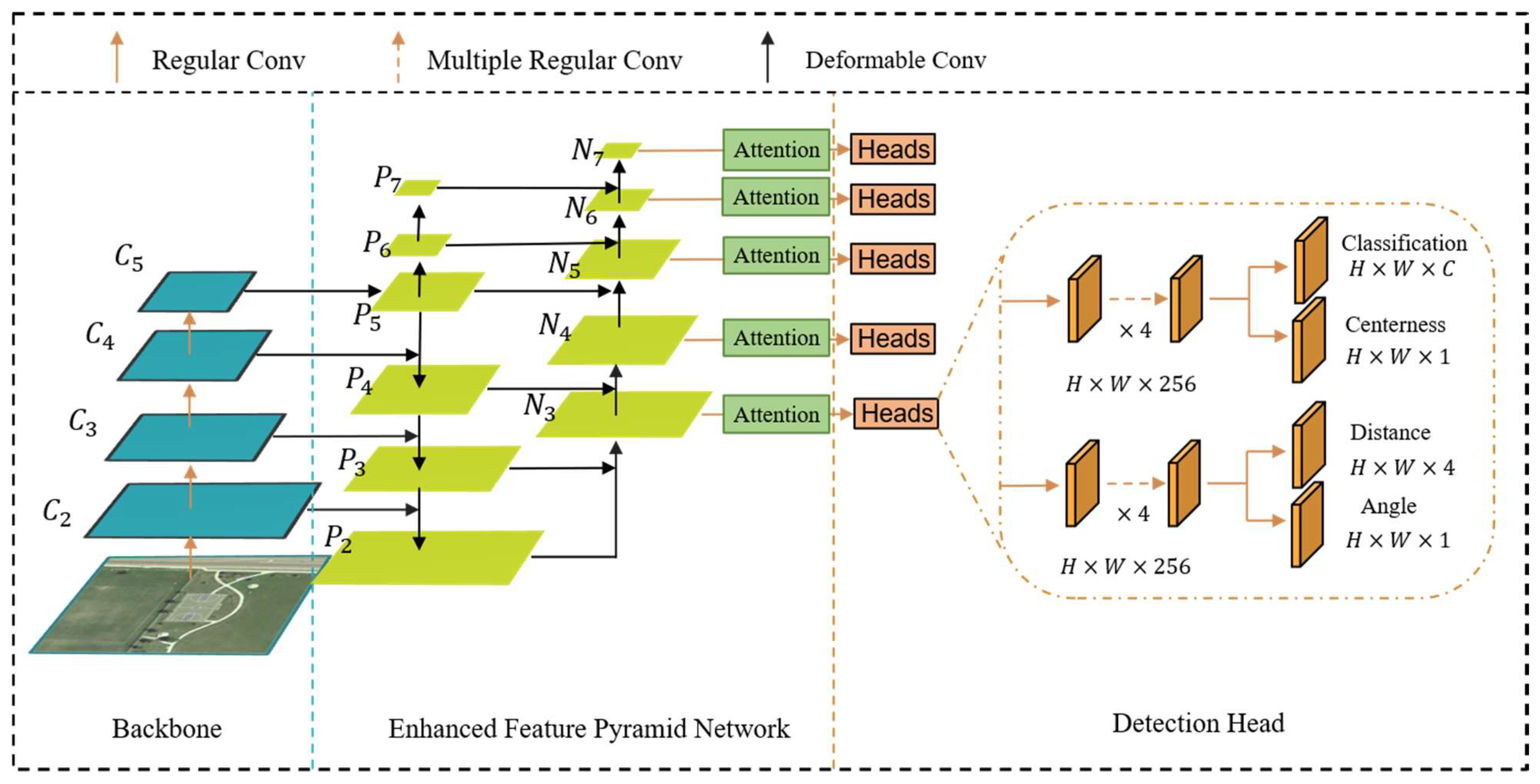
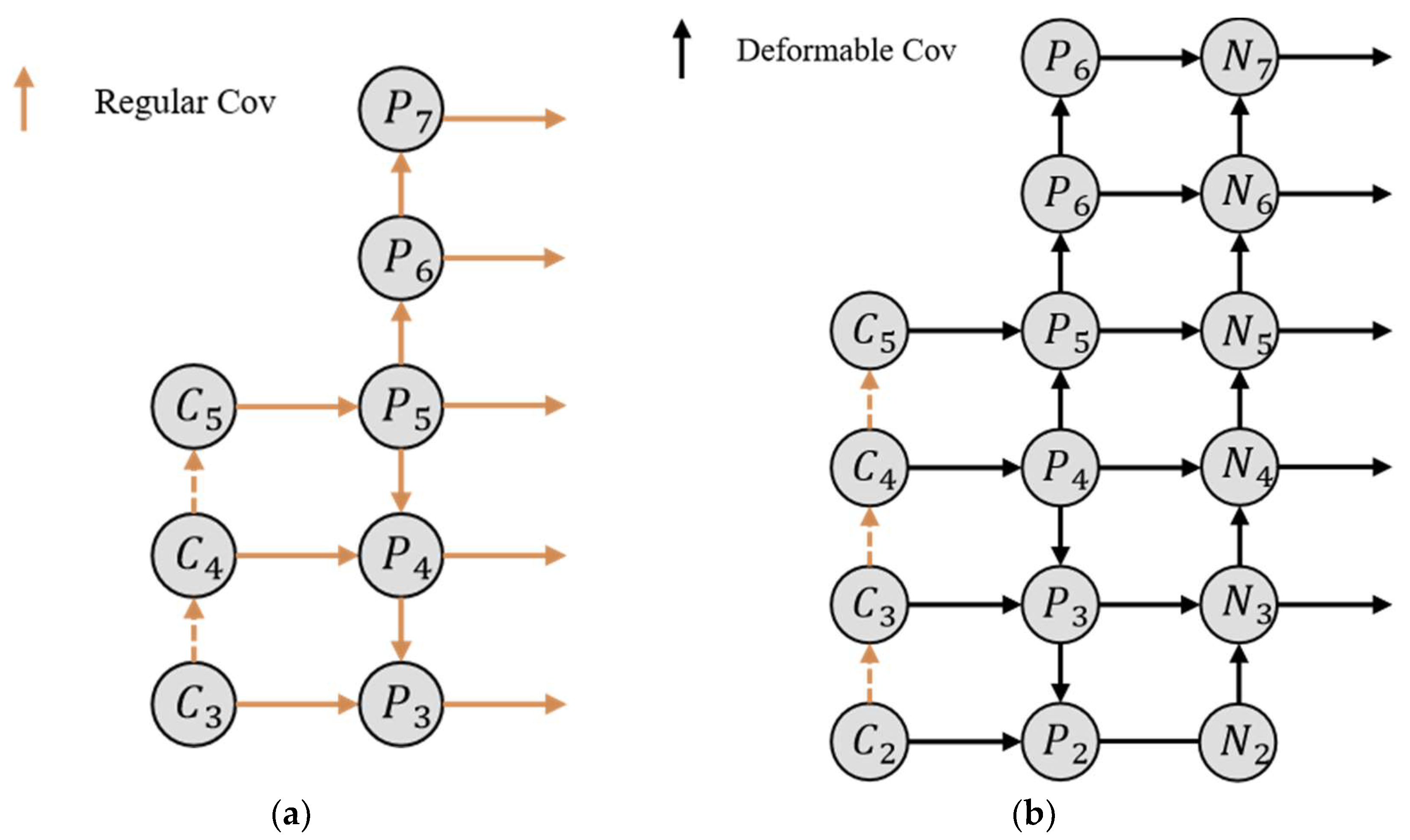
3.1. Enhanced Feature Pyramid
3.2. Oriented Object Detection
3.3. Loss Function
4. Experiments
4.1. Datasets and Evaluation Index
4.2. Model Training
4.3. Comparative Experiment and Analysis of Generalization Performance
4.4. Ablation Experiment and Detection Result Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Qiu, H.; Ma, Y.; Li, Z.; Liu, S.; Sun, J. Borderdet: Border feature for dense object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Shen, Z.; Liu, Z.; Li, J.; Jiang, Y.G.; Chen, Y.; Xue, X. Dsod: Learning deeply supervised object detectors from scratch. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Kim, K.; Lee, H.S. Probabilistic anchor assignment with iou prediction for object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Shen, Y.; Liu, D.; Zhang, F.; Zhang, Q. Fast and accurate multi-class geospatial object detection with large-size remote sensing imagery using CNN and Truncated NMS. ISPRS J. Photogramm. Remote Sens. 2022, 191, 235–249. [Google Scholar] [CrossRef]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhu, C.; Chen, F.; Shen, Z.; Savvides, M. Soft anchor-point object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Yang, X.; Zhou, Y.; Zhang, G.; Yang, J.; Wang, W.; Yan, J.; Zhang, X.; Tian, Q. The KFIoU loss for rotated object detection. In Proceedings of the Tenth International Conference on Learning Representations (ICLR), Virtual, 25–29 April 2022. [Google Scholar]
- Yang, X.; Yan, J.; Liao, W.; Yang, X.; Tang, J.; He, T. Scrdet++: Detecting small, cluttered and rotated objects via instance-level feature denoising and rotation loss smoothing. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2384–2399. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Chen, Y.; Hu, K.; Zhu, J. Oriented reppoints for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Yang, X.; Yan, J.; Ming, Q.; Wang, W.; Zhang, X.; Tian, Q. Rethinking rotated object detection with gaussian wasserstein distance loss. In Proceedings of the International Conference on Machine Learning, PMLR, Vienna, Austria, 18–24 July 2021. [Google Scholar]
- Yang, X.; Yang, X.; Yang, J.; Ming, Q.; Wang, W.; Tian, Q.; Yan, J. Learning high-precision bounding box for rotated object detection via kullback-leibler divergence. Adv. Neural Inf. Process. Syst. 2021, 34, 18381–18394. [Google Scholar]
- Guo, Z.; Liu, C.; Zhang, X.; Jiao, J.; Ji, X.; Ye, Q. Beyond bounding-box: Convex-hull feature adaptation for oriented and densely packed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Yang, X.; Hou, L.; Zhou, Y.; Wang, W.; Yan, J. Dense label encoding for boundary discontinuity free rotation detection. In Proceedings of the IEEE/CVF Conference on computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Wang, K.; Zhan, B.; Zu, C.; Wu, X.; Zhou, J.; Zhou, L.; Wang, Y. Semi-supervised medical image segmentation via a tripled-uncertainty guided mean teacher model with contrastive learning. Med. Image Anal. 2022, 79, 102447. [Google Scholar] [CrossRef] [PubMed]
- Tang, P.; Yang, P.; Nie, D.; Wu, X.; Zhou, J.; Wang, Y. Unified medical image segmentation by learning from uncertainty in an end-to-end manner. Knowl.-Based Syst. 2022, 241, 108215. [Google Scholar] [CrossRef]
- Luo, Y.; Zhou, L.; Zhan, B.; Fei, Y.; Zhou, J.; Wang, Y.; Shen, D. Adaptive rectification based adversarial network with spectrum constraint for high-quality PET image synthesis. Med. Image Anal. 2022, 77, 102335. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, L.; Yu, B.; Wang, L.; Zu, C.; Lalush, D.S.; Lin, W.; Wu, X.; Zhou, J.; Shen, D. 3D auto-context-based locality adaptive multi-modality GANs for PET synthesis. IEEE Trans. Med. Imaging 2018, 38, 1328–1339. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, B.; Wang, L.; Zu, C.; Lalush, D.S.; Lin, W.; Wu, X.; Zhou, J.; Shen, D.; Zhou, L. 3D conditional generative adversarial networks for high-quality PET image estimation at low dose. Neuroimage 2018, 174, 550–562. [Google Scholar] [CrossRef]
- Zhan, B.; Xiao, J.; Cao, C.; Peng, X.; Zu, C.; Zhou, J.; Wang, Y. Multi-constraint generative adversarial network for dose prediction in radiotherapy. Med. Image Anal. 2022, 77, 102339. [Google Scholar] [CrossRef]
- Jiao, Z.; Peng, X.; Wang, Y.; Xiao, J.; Nie, D.; Wu, X.; Wang, X.; Zhou, J.; Shen, D. TransDose: Transformer-based Radiotherapy Dose Prediction from CT Images guided by Super-Pixel-Level GCN Classification. Med. Image Anal. 2023, 89, 102902. [Google Scholar] [CrossRef] [PubMed]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning roi transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.S.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1452–1459. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Yi, J.; Wu, P.; Liu, B.; Huang, Q.; Qu, H.; Metaxas, D. Oriented object detection in aerial images with box boundary-aware vectors. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021. [Google Scholar]
- Xiao, Z.; Qian, L.; Shao, W.; Tan, X.; Wang, K. Axis learning for orientated objects detection in aerial images. Remote Sens. 2020, 12, 908. [Google Scholar] [CrossRef]
- Yang, X.; Sun, H.; Sun, X.; Yan, M.; Guo, Z.; Fu, K. Position detection and direction prediction for arbitrary-oriented ships via multitask rotation region convolutional neural network. IEEE Access 2018, 6, 50839–50849. [Google Scholar] [CrossRef]
- Dong, X.; Qin, Y.; Gao, Y.; Fu, R.; Liu, S.; Ye, Y. Attention-Based Multi-Level Feature Fusion for Object Detection in Remote Sensing Images. Remote Sens. 2022, 14, 3735. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, S.; Thachan, S.; Chen, J.; Qian, Y. Deconv R-CNN for small object detection on remote sensing images. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018. [Google Scholar]
- Zhang, Z.; Liu, Y.; Liu, T.; Lin, Z.; Wang, S. DAGN: A real-time UAV remote sensing image vehicle detection framework. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1884–1888. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Li, Q.; Mou, L.; Jiang, K.; Liu, Q.; Wang, Y.; Zhu, X.X. Hierarchical region based convolution neural network for multiscale object detection in remote sensing images. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium. Valencia, Spain, 22–27 July 2018. [Google Scholar]
- Fu, K.; Chang, Z.; Zhang, Y.; Xu, G.; Zhang, K.; Sun, X. Rotation-aware and multi-scale convolutional neural network for object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 161, 294–308. [Google Scholar] [CrossRef]
- Li, Y.; Pei, X.; Huang, Q.; Jiao, L.; Shang, R.; Marturi, N. Anchor-free single stage detector in remote sensing images based on multiscale dense path aggregation feature pyramid network. IEEE Access 2020, 8, 63121–63133. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, L.; Lu, H.; He, Y. Center-boundary dual attention for oriented object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5603914. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- De Boer, P.T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A high resolution optical satellite image dataset for ship recognition and some new baselines. In Proceedings of the ICPRAM, Porto, Portugal, 24–26 February 2017. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G.S. Align deep features for oriented object detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5602511. [Google Scholar] [CrossRef]
- Liu, Z.; Hu, J.; Weng, L.; Yang, Y. Rotated region based CNN for ship detection. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3det: Refined single-stage detector with feature refinement for rotating object. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021. [Google Scholar]
- Zhu, M.; Hu, G.; Zhou, H.; Wang, S.; Zhang, Y.; Yue, S.; Bai, Y.; Zang, K. Arbitrary-oriented ship detection based on RetinaNet for remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6694–6706. [Google Scholar] [CrossRef]


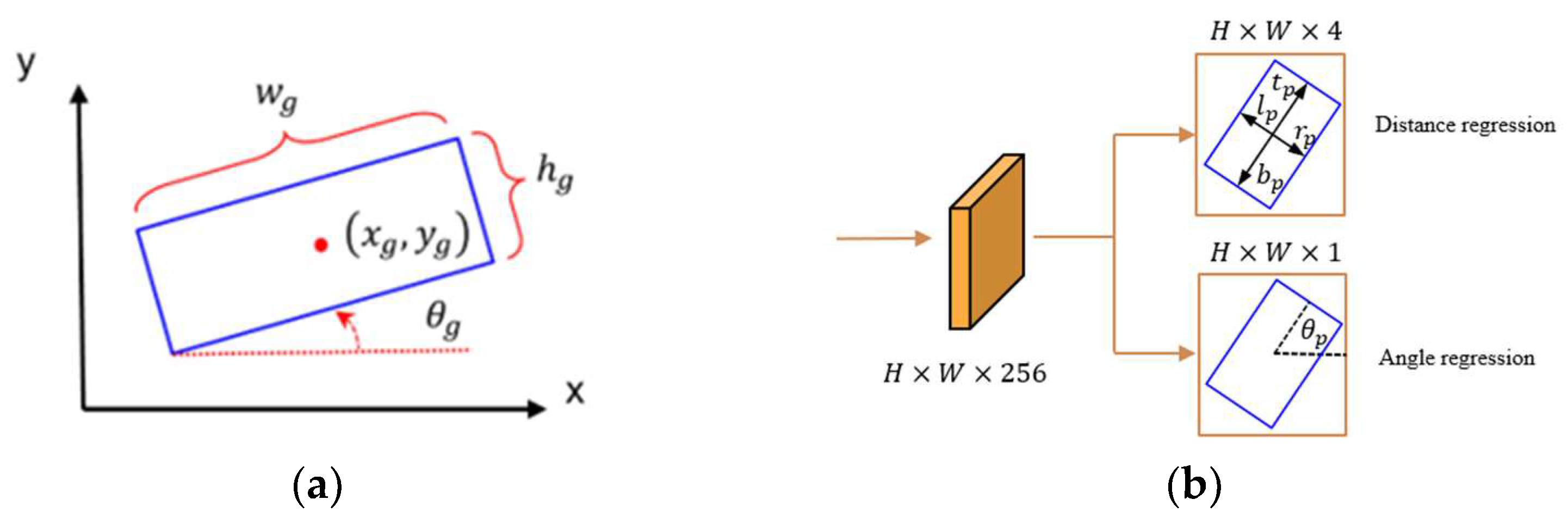









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Method | |||||
|---|---|---|---|---|---|---|
| S2aNet | R-F-R | R3det | P-RetinaNet | Baseline | Ours | |
| Aircraft | 88.7 | 88.6 | 88.8 | 88.8 | 88.1 | 89.9 * |
| Baseball field | 74.2 | 76.2 | 75.1 | 75.3 | 74.2 | 78.3 * |
| Bridge | 44.6 | 47.3 | 46.7 | 42.8 | 40.5 | 48.8 * |
| Track Stadium | 66.6 | 71.2 * | 67.5 | 65.2 | 65.2 | 66.3 |
| Compact Cars | 63.6 | 65.2 | 65.0 | 62.4 | 65.9 | 70.1 * |
| Large Vehicles | 80.2 | 75.7 | 75.2 | 69.2 | 81.0 | 81.3 * |
| Vessels | 89.1 * | 87.9 | 86.5 | 83.9 | 83.9 | 87.9 |
| Tennis court | 89.5 | 90.2 * | 90.0 | 89.0 | 87.4 | 86.9 |
| Basketball Court | 57.9 | 53.0 | 53.2 | 59.4 | 59.4 | 59.9 * |
| Storage Tank | 67.8 | 62.6 | 66.9 | 65.9 | 69.0 | 69.7 * |
| Soccer Field | 56.3 | 64.0 * | 50.7 | 53.3 | 56.6 | 55.1 |
| Circular Road | 57.6 | 61.7 * | 59.4 | 60.6 | 59.9 | 60.4 |
| Seaport | 71.9 | 72.4 | 65.6 | 59.8 | 64.7 | 72.8 * |
| Swimming Pool | 54.8 | 60.2 | 57.0 | 55.0 | 54.8 | 61.0 * |
| Helicopter | 59.0 | 53.4 | 47.1 | 49.9 | 56.4 * | 47.7 |
| mAP | 68.1 | 68.6 | 66.3 | 65.4 | 66.0 | 69.0 * |
| Method | AP |
|---|---|
| R-F-R | 76.4 |
| R-RetinaNet | 84.8 |
| Baseline | 87.9 |
| R3det | 88.8 |
| Ours | 89.8 * |
| Method | Deformable Convolution | Attention Module | Datasets | |
|---|---|---|---|---|
| DOTA | HRCS2016 | |||
| Baseline | 66.0 | 87.8 | ||
| Ours | √ | 67.3 | 88.2 | |
| Ours | √ | 66.8 | 88.6 | |
| Ours | √ | √ | 69.0 * | 89.8 * |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, X.; Zhou, W.; Wang, K.; He, B.; Fu, Y.; Wu, X.; Zhou, J. Oriented Object Detection in Remote Sensing Using an Enhanced Feature Pyramid Network. Electronics 2023, 12, 3559. https://doi.org/10.3390/electronics12173559
Zhu X, Zhou W, Wang K, He B, Fu Y, Wu X, Zhou J. Oriented Object Detection in Remote Sensing Using an Enhanced Feature Pyramid Network. Electronics. 2023; 12(17):3559. https://doi.org/10.3390/electronics12173559
Chicago/Turabian StyleZhu, Xinyu, Wei Zhou, Kun Wang, Bing He, Ying Fu, Xi Wu, and Jiliu Zhou. 2023. "Oriented Object Detection in Remote Sensing Using an Enhanced Feature Pyramid Network" Electronics 12, no. 17: 3559. https://doi.org/10.3390/electronics12173559
APA StyleZhu, X., Zhou, W., Wang, K., He, B., Fu, Y., Wu, X., & Zhou, J. (2023). Oriented Object Detection in Remote Sensing Using an Enhanced Feature Pyramid Network. Electronics, 12(17), 3559. https://doi.org/10.3390/electronics12173559