

Real-Time Pose Estimation Based on ResNet-50 for Rapid Safety Prevention and Accident Detection for Field Workers


Abstract
:1. Introduction
- Real-time pose estimation: This paper proposes a method that allows for the pose of a worker to be estimated in real time. This is an important contribution to estimating the pose of workers in the field and quickly detecting dangerous situations.
- Accuracy: The method proposed in this paper shows high accuracy in pose estimation through a combination of OpenPose algorithm and ResNet-50. This aids the real-time detection of a worker’s status by accurately estimating a worker’s pose.
- Safety prevention and accident detection: The method proposed in this paper monitors the pose of workers in real time and also detects safety hazards that may occur in the work environment. This helps workers perform their tasks in a safer environment while also enabling rapid response and rescue in the case of accidents.
- Building an AI-based safety system: The proposed system can be utilized to enhance safety in an enterprise or field. By analyzing and evaluating the posture and behavior of workers in real time, the posture estimation technology based on AI can contribute to building a more systematic and efficient safety management system.
- Efficient resource utilization: In this study, ResNet-50 was applied to enable real-time pose estimation at a faster speed compared to the existing OpenPose. This improved speed and accuracy can be seen as an important contribution to resource efficiency. Especially when estimating the pose of many workers simultaneously in real-time in a large work environment, the efficiency of the system is crucial.
- Optimization for industrial settings: By using a dataset of workers in an industrial setting to train and evaluate the model, this study yields optimized results for real-world work environments, which is an important contribution that increases its applicability in real-world settings.
- Future applications: The techniques in this study can serve as a basis for safety and accident prevention for field workers, and future applications can be actively researched. For example, it could be applied to posture estimation and accident prevention systems not only in industrial sites but also in various fields such as healthcare, sports, and security.
2. Related Work
2.1. OpenPose
2.2. Multi-Person Pose Estimation
2.2.1. Top-Down Method
2.2.2. Bottom-Up Method
2.2.3. Single-Stage Methods
2.3. ResNet
3. ResNet-50 Based Real-Time Pose Estimation
3.1. Overall Structure
3.2. Feature Extraction Stages
3.3. Operation Flow
3.4. Scenarios
3.4.1. Construction Sites
3.4.2. Oil and Gas Industry
3.4.3. Power Supply Industry
4. Results
4.1. Experiment Environments
4.2. Performance Metrics
4.3. Results
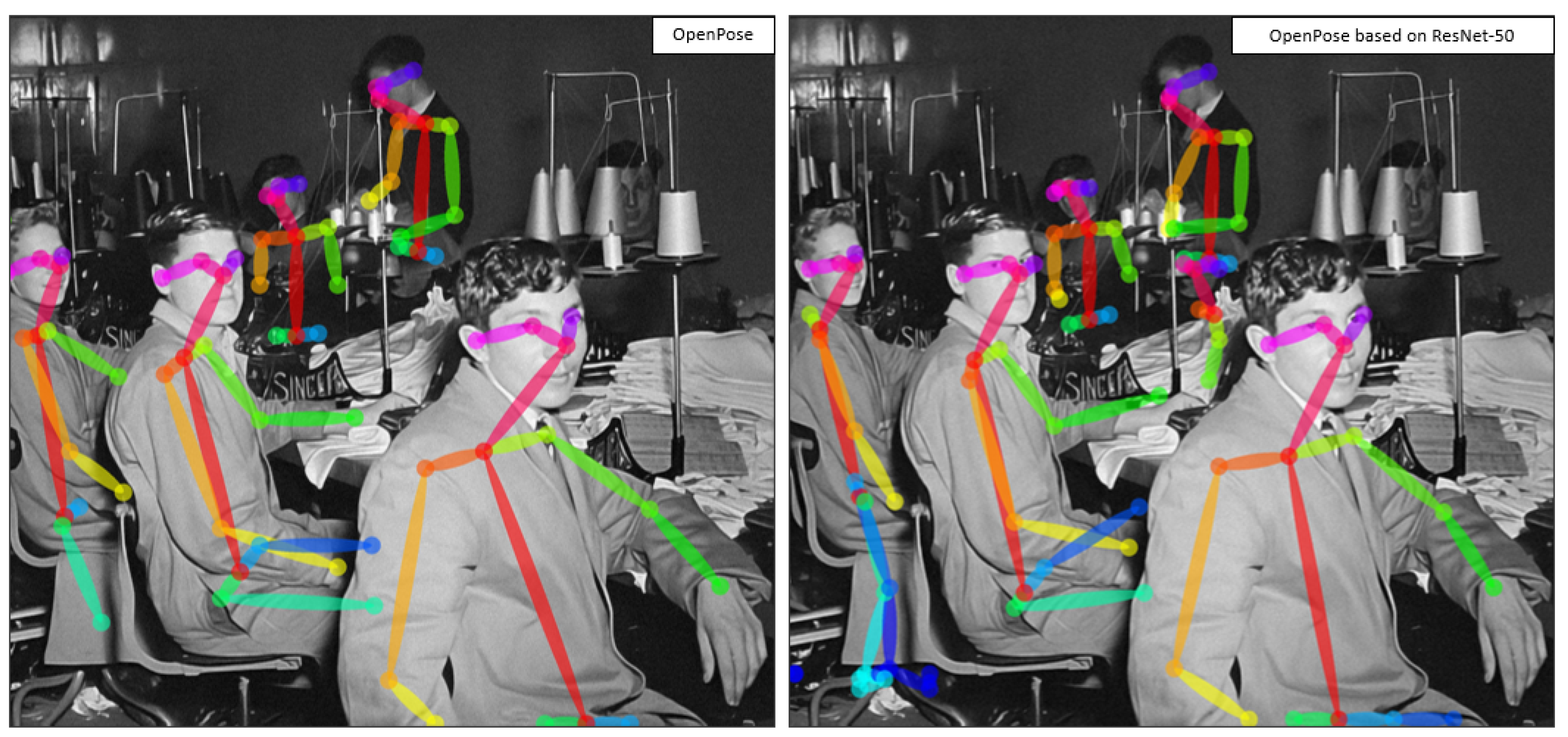
- Red: Line connecting the head and neck;
- Orange: Line connecting the right shoulder and right elbow;
- Yellow: Line connecting the right elbow and right wrist;
- Lime Green: Line connecting the left shoulder and left elbow;
- Green: Line connecting the left elbow and left wrist;
- Cyan: Line connecting the right thigh, right calf, and right foot;
- Blue: Line connecting the left thigh, left calf, and left foot;
- Pink: Line connecting the nose and right eye;
- Purple: Line connecting the nose and left eye.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Marchellus, M.; Park, I.K. Human Motion Prediction with Deep Learning: A Survey. In Proceedings of the Korean Society of Broadcast Media Engineering Conference, Seoul, Republic of Korean, 23 June 2021; pp. 183–186. [Google Scholar]
- Choi, J. A Study on Real-Time Human Pose Estimation Based on Monocular Camera. Domestic Master’s Thesis, Graduate School of General Studies, Kookmin University, Seoul, Republic of Korea, 2020. [Google Scholar]
- Zarkeshev, A.; Csiszár, C. Rescue method based on V2X communication and human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; Volume 63, pp. 1139–1146. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar] [CrossRef]
- Kocabas, M.; Karagoz, S.; Akbas, E. Multiposenet: Fast Multi-Person Estimation using pose residual network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 417–433. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Park, J.H. A Study on Recognition and Analysis of Industrial Worker Risk Situation. Ph.D. Dissertation, Baejae University Graduate School, Daejeon, Republic of Korea, 2022. [Google Scholar]
- Lin, C.-B.; Dong, Z.; Kuan, W.K.; Huang, Y.F. A framework for fall detection based on OpenPose skeleton and LSTM/GRU models. Appl. Sci. 2020, 11, 329. [Google Scholar] [CrossRef]
- Yoo, H.R.; Lee, B.-H. OpenPose-based Child Abuse Detection System Using Surveillance Video. J. Korea Telecommun. Soc. 2019, 23, 282–290. [Google Scholar]
- Younggeun, Y.; Taegeun, O. A Study on Improving Construction Worker Detection Performance Using YOLOv5 and OpenPose. J. Converg. Cult. Technol. (JCCT) 2022, 8, 735–740. [Google Scholar]
- Shi, D.; Wei, X.; Li, L.; Ren, Y.; Tan, W. End-to-end Multi-Person Estimation with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- El Kaid, A.; Brazey, D.; Barra, V.; Baïna, K. Top-down system for multi-person 3D absolute pose estimation from monocular videos. Sensors 2022, 22, 4109. [Google Scholar] [CrossRef]
- Zheng, Z.; Zha, B.; Zhou, Y.; Huang, J.; Xuchen, Y.; Zhang, H. Single-stage adaptive multi-scale point cloud noise filtering algorithm based on feature information. Remote Sens. 2022, 14, 367. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1302–1310. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded pyramid network for Multi-Person Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7103–7112. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Chhabra, M.; Kumar, R. An Efficient ResNet-50 based Intelligent Deep Learning Model to Predict Pneumonia from Medical Images. In Proceedings of the 2022 International Conference on Sustainable Computing and Data Communication Systems (ICSCDS), Erode, India, 7–9 April 2022; pp. 1714–1721. [Google Scholar]
- Odusami, M.; Maskeliūnas, R.; Damaševičius, R.; Krilavičius, T. Analysis of features of Alzheimer’s disease: Detection of early stage from functional brain changes in magnetic resonance images using a finetuned ResNet18 network. Diagnostics 2021, 11, 1071. [Google Scholar] [CrossRef] [PubMed]
- Shahwar, T.; Zafar, J.; Almogren, A.; Zafar, H.; Rehman, A.U.; Shafiq, M.; Hamam, H. Automated detection of Alzheimer’s via hybrid classical quantum neural networks. Electronics 2022, 11, 721. [Google Scholar] [CrossRef]
- Li, X.X.; Li, D.; Ren, W.X.; Zhang, J.S. Loosening Identification of Multi-Bolt Connections Based on Wavelet Transform and ResNet-50 Convolutional Neural Network. Sensors 2022, 22, 6825. [Google Scholar] [CrossRef]
- Fulton, L.V.; Dolezel, D.; Harrop, J.; Yan, Y.; Fulton, C.P. Classification of Alzheimer’s disease with and without imagery using gradient boosted machines and ResNet-50. Brain Sci. 2019, 9, 212. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Zhu, Y.; Ge, Z.; Mu, H.; Qi, D.; Ni, H. Transfer learning for leaf small dataset using improved ResNet50 network with mixed activation functions. Forests 2022, 13, 2072. [Google Scholar] [CrossRef]
- Nasirahmadi, A.; Sturm, B.; Edwards, S.; Jeppsson, K.H.; Olsson, A.C.; Müller, S.; Hensel, O. Deep learning and machine vision approaches for posture detection of individual pigs. Sensors 2019, 19, 3738. [Google Scholar] [CrossRef] [PubMed]
- Pérez-Pérez, B.D.; Garcia Vazquez, J.P.; Salomón-Torres, R. Evaluation of convolutional neural networks’ hyperparameters with transfer learning to determine sorting of ripe medjool dates. Agriculture 2021, 11, 115. [Google Scholar] [CrossRef]
- Altameem, A.; Mahanty, C.; Poonia, R.C.; Saudagar, A.K.J.; Kumar, R. Breast cancer detection in mammography images using deep convolutional neural networks and fuzzy ensemble modeling techniques. Diagnostics 2022, 12, 1812. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, Real-Time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. Comput. Vision–Eccv. 2016, 14, 630–645. [Google Scholar]
- Mascarenhas, S.; Agarwal, M. A comparison between VGG16, VGG19 and ResNet50 architecture frameworks for Image Classification. In Proceedings of the International Conference on Disruptive Technologies for Multi-Disciplinary Research and Applications (CENTCON), Bengaluru, India, 22–24 December 2021; pp. 96–99. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. DHow transferable are features in deep neural networks? Adv. Neural Inf. Process. Syst. 2014, 27, 3320–3328. [Google Scholar]
- Ikechukwu, A.V.; Murali, S.; Deepu, R.; Shivamurthy, R.C. Shivamurthy. ResNet-50 vs VGG-19 vs training from scratch: A comparative analysis of the segmentation and classification of Pneumonia from chest X-ray images. Glob. Transit. Proc. 2021, 2, 375–381. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2d human pose estimation: New benchmark and state of the art analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3686–3693. [Google Scholar]
- Park, J.-H.; Ha, O.-K.; Jun, Y.-K. Analysis of Image Processing Techniques for Real-Time Object Recognition. Proc. Korea Comput. Inf. Soc. 2017, 25, 35–36. [Google Scholar]
- Fang, H.S.; Li, J.; Tang, H.; Xu, C.; Zhu, H.; Xiu, Y.; Li, Y.L.; Lu, C. Alphapose: Whole-body regional Multi-Person Estimation and tracking in Real-Time. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 7157–7173. [Google Scholar] [CrossRef] [PubMed]
- Güler, R.A.; Neverova, N.; Kokkinos, I. Densepose: Dense human Pose Estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| OS | CUDA | cMa + ke | cuDNN | OpenCV | Python | Visual Studio | GPU | |
|---|---|---|---|---|---|---|---|---|
| Development Environment | Windows 11 Home | v11.8 | v3.26.3 | v8.2.4 | v4.5.4 | v3.9.13 | 2019 Enterprise | NVIDIA GeForce RTX 3070Ti Laptop GPU |
| Model | AP | mAP | Accuracy | F1-Score | Precision | Recall |
| OpenPose | 0.88 | 0.89 | 0.90 | 0.87 | 0.88 | 0.86 |
| OpenPose based on ResNet-50 | 0.91 | 0.92 | 0.92 | 0.90 | 0.91 | 0.89 |
| AlphaPose | 0.88 | 0.89 | 0.91 | 0.88 | 0.87 | 0.89 |
| DensePose | 0.86 | 0.87 | 0.88 | 0.85 | 0.86 | 0.84 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Kim, T.-y.; Beak, S.; Moon, Y.; Jeong, J. Real-Time Pose Estimation Based on ResNet-50 for Rapid Safety Prevention and Accident Detection for Field Workers. Electronics 2023, 12, 3513. https://doi.org/10.3390/electronics12163513
Lee J, Kim T-y, Beak S, Moon Y, Jeong J. Real-Time Pose Estimation Based on ResNet-50 for Rapid Safety Prevention and Accident Detection for Field Workers. Electronics. 2023; 12(16):3513. https://doi.org/10.3390/electronics12163513
Chicago/Turabian StyleLee, Jieun, Tae-yong Kim, Seunghyo Beak, Yeeun Moon, and Jongpil Jeong. 2023. "Real-Time Pose Estimation Based on ResNet-50 for Rapid Safety Prevention and Accident Detection for Field Workers" Electronics 12, no. 16: 3513. https://doi.org/10.3390/electronics12163513
APA StyleLee, J., Kim, T.-y., Beak, S., Moon, Y., & Jeong, J. (2023). Real-Time Pose Estimation Based on ResNet-50 for Rapid Safety Prevention and Accident Detection for Field Workers. Electronics, 12(16), 3513. https://doi.org/10.3390/electronics12163513