
A Review of Federated Meta-Learning and Its Application in Cyberspace Security


Abstract
1. Introduction
- We provide a comprehensive overview of the concepts, classification, challenges, and applications of federated learning and meta-learning, as presented in Section 2.
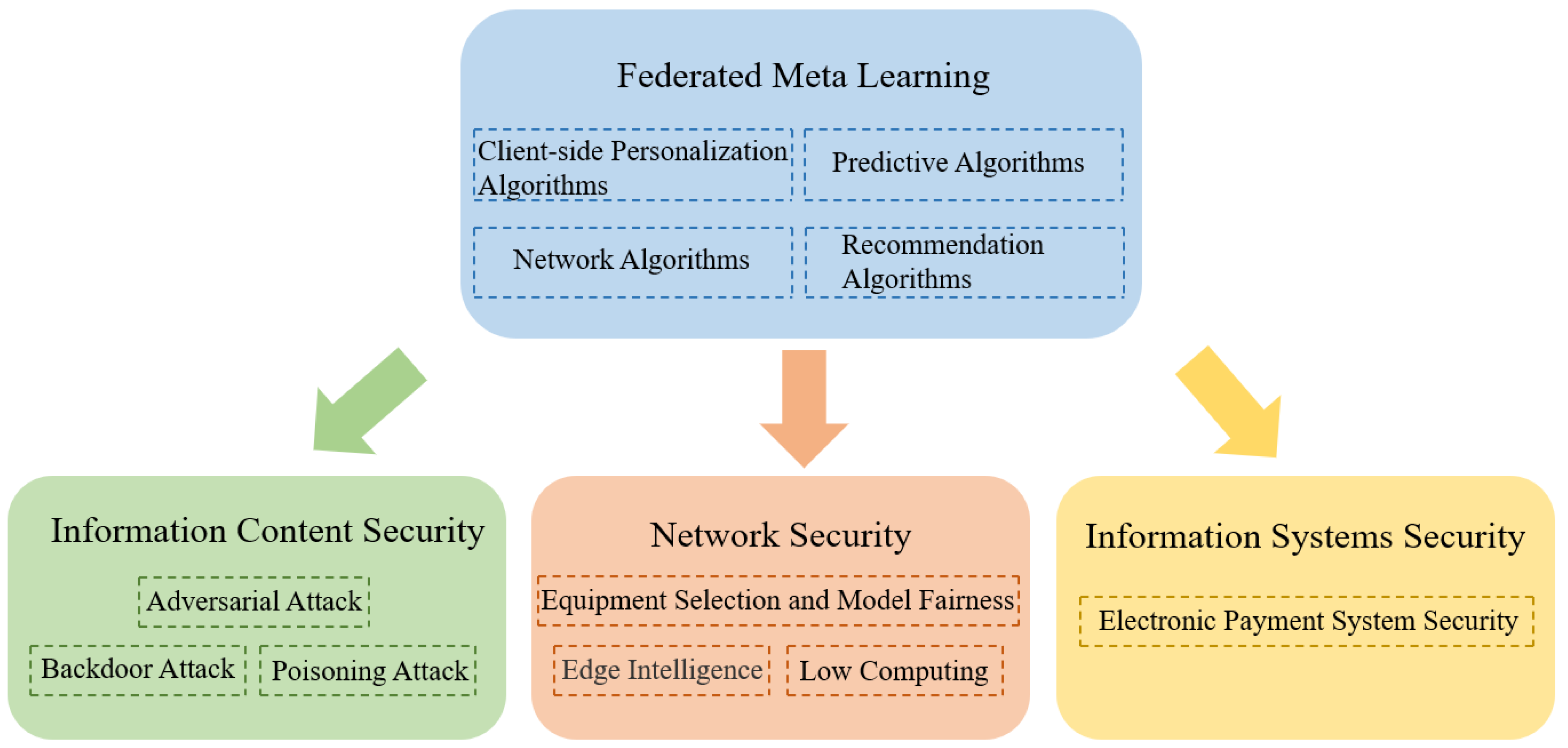
- We systematically define federated meta-learning and categorize the algorithms into four types: client-specific algorithms, network algorithms, prediction algorithms, and recommendation algorithms. Each type is introduced in detail, corresponding to the content in Section 3.
- We conduct an in-depth analysis and exploration of the application research progress in federated meta-learning in subdomains of cybersecurity, including information content security, network security, and information system security. This analysis is covered in Section 4.
- We summarize the challenges faced by federated meta-learning and its application in cybersecurity in the context of cyberspace. Furthermore, we outline future research prospects, as discussed in Section 5.
2. Overview of Federated Learning
2.1. Federated Learning
2.1.1. The Concept of Federated Learning
2.1.2. Classification of Federated Learning
- Horizontal Federated Learning
- 2.
- Vertical Federated Learning
- 3.
- Federated Transfer Learning
2.1.3. Challenges Faced by Federated Learning
- Communication Requirements
- 2.
- Data Are non-Independent and Identically Distributed
- 3.
- Privacy Protection
- 4.
- Intermittent Behavior of Remote Clients
2.2. Meta-Learning
2.2.1. The Concept of Meta-Learning
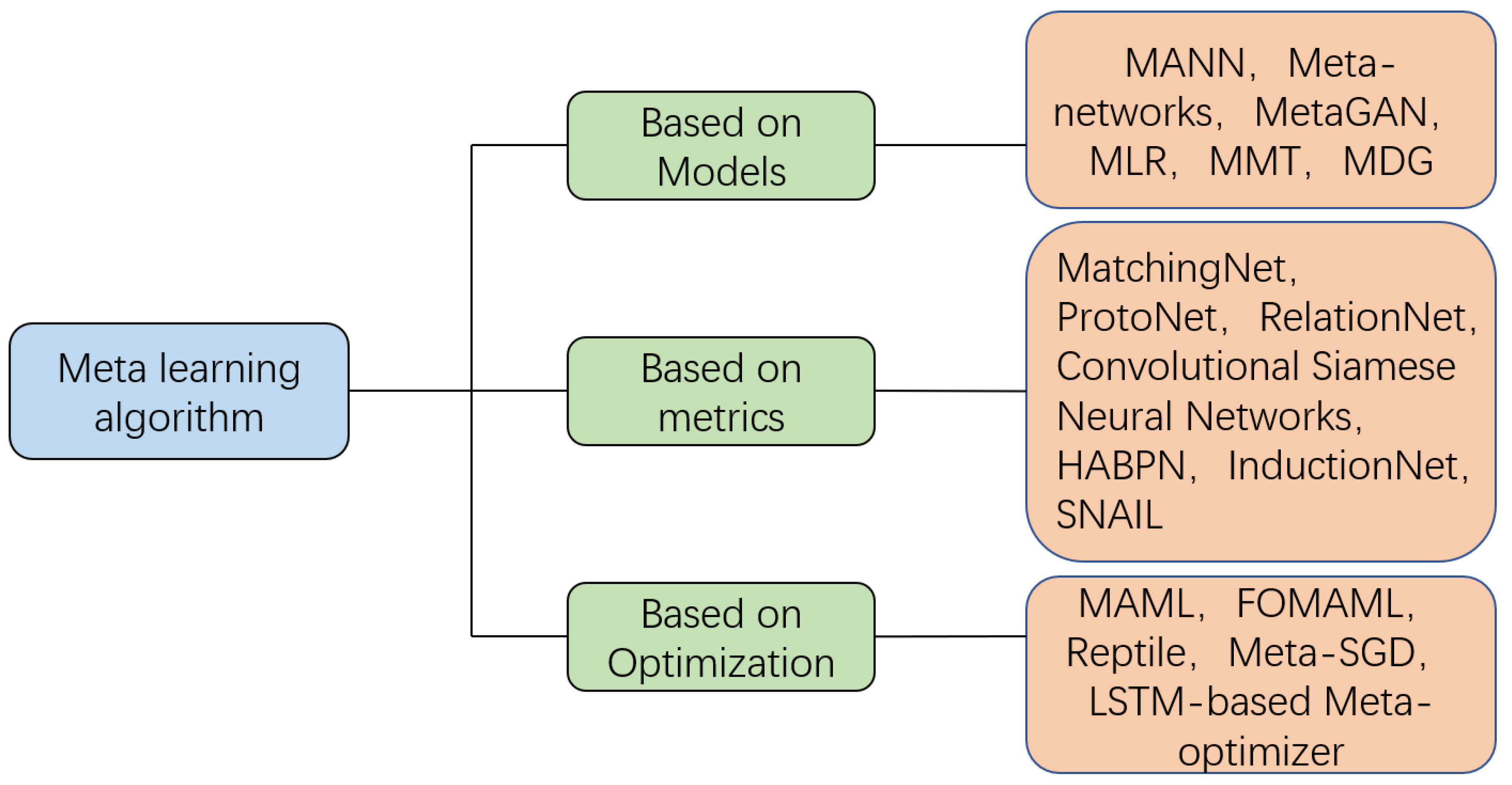
2.2.2. The Methods and Applications of Meta-Learning
3. Overview of Federated Meta-Learning
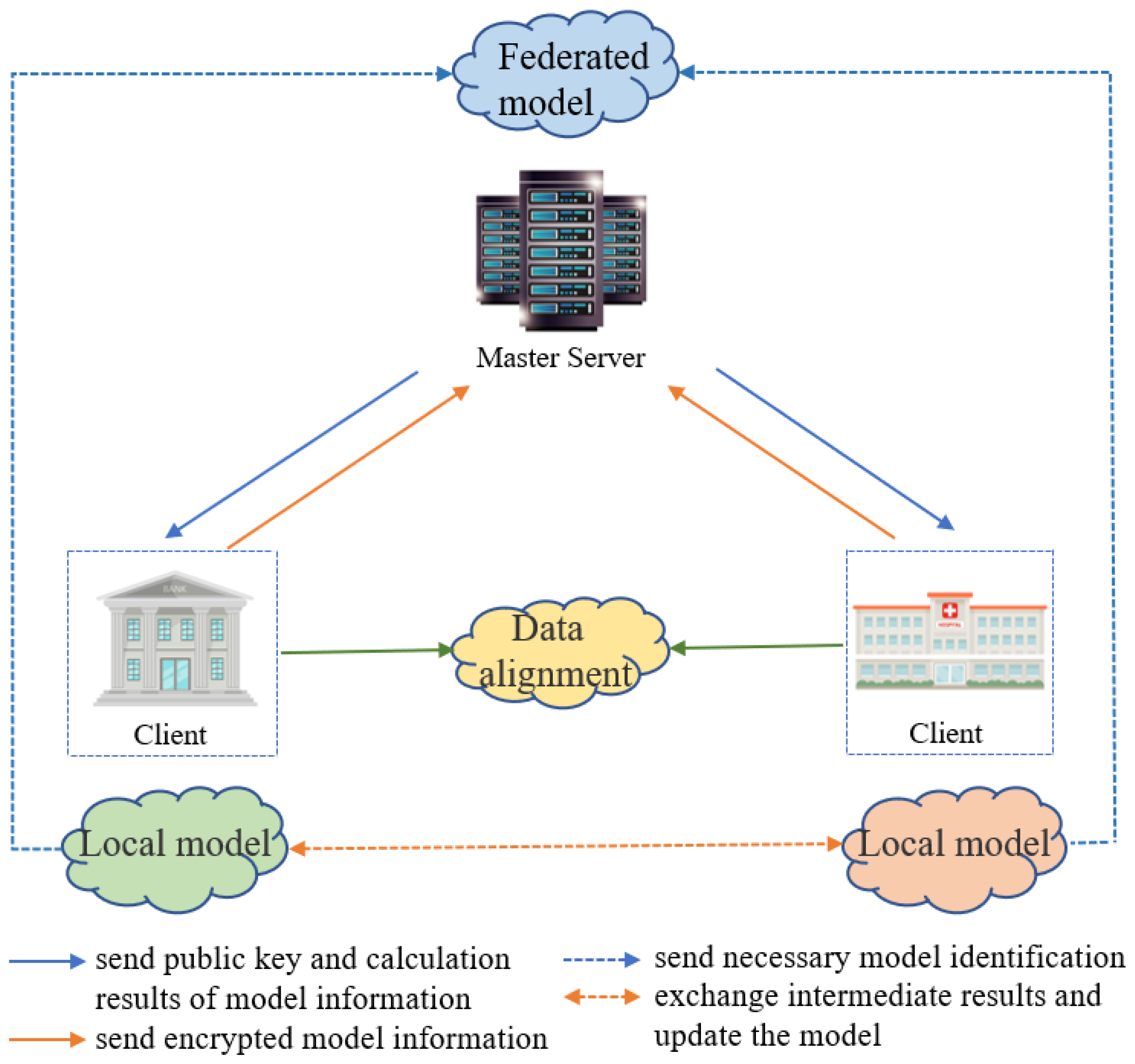
3.1. The Concept of Federated Meta-Learning
3.2. Federated Meta-Learning Algorithm
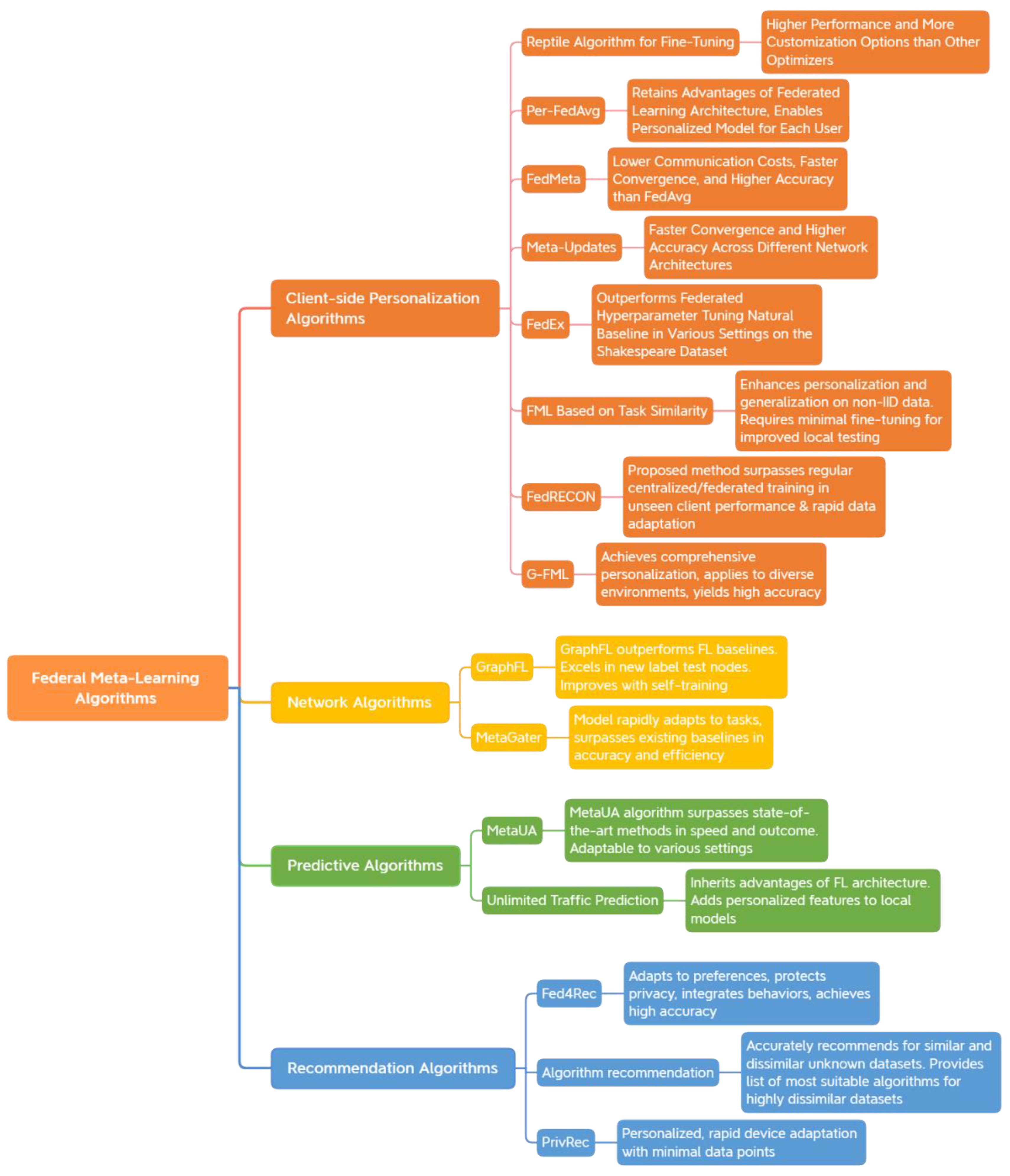
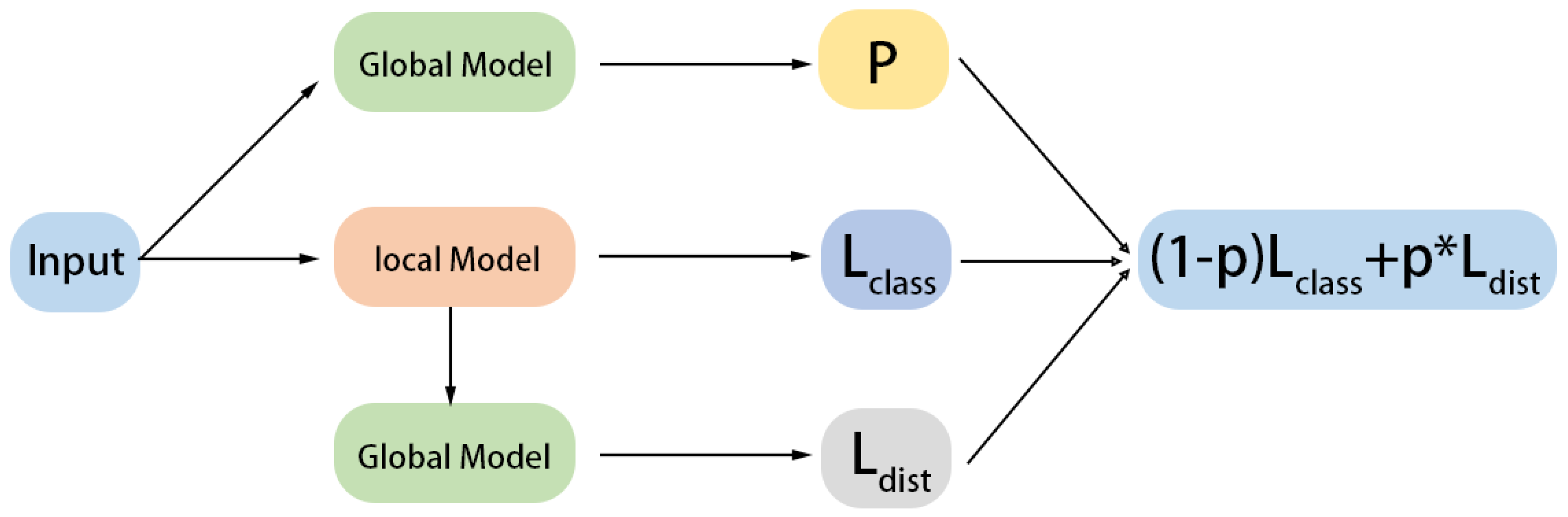
3.2.1. Client-Side Personalization Algorithms
3.2.2. Network Algorithms
3.2.3. Predictive Algorithms
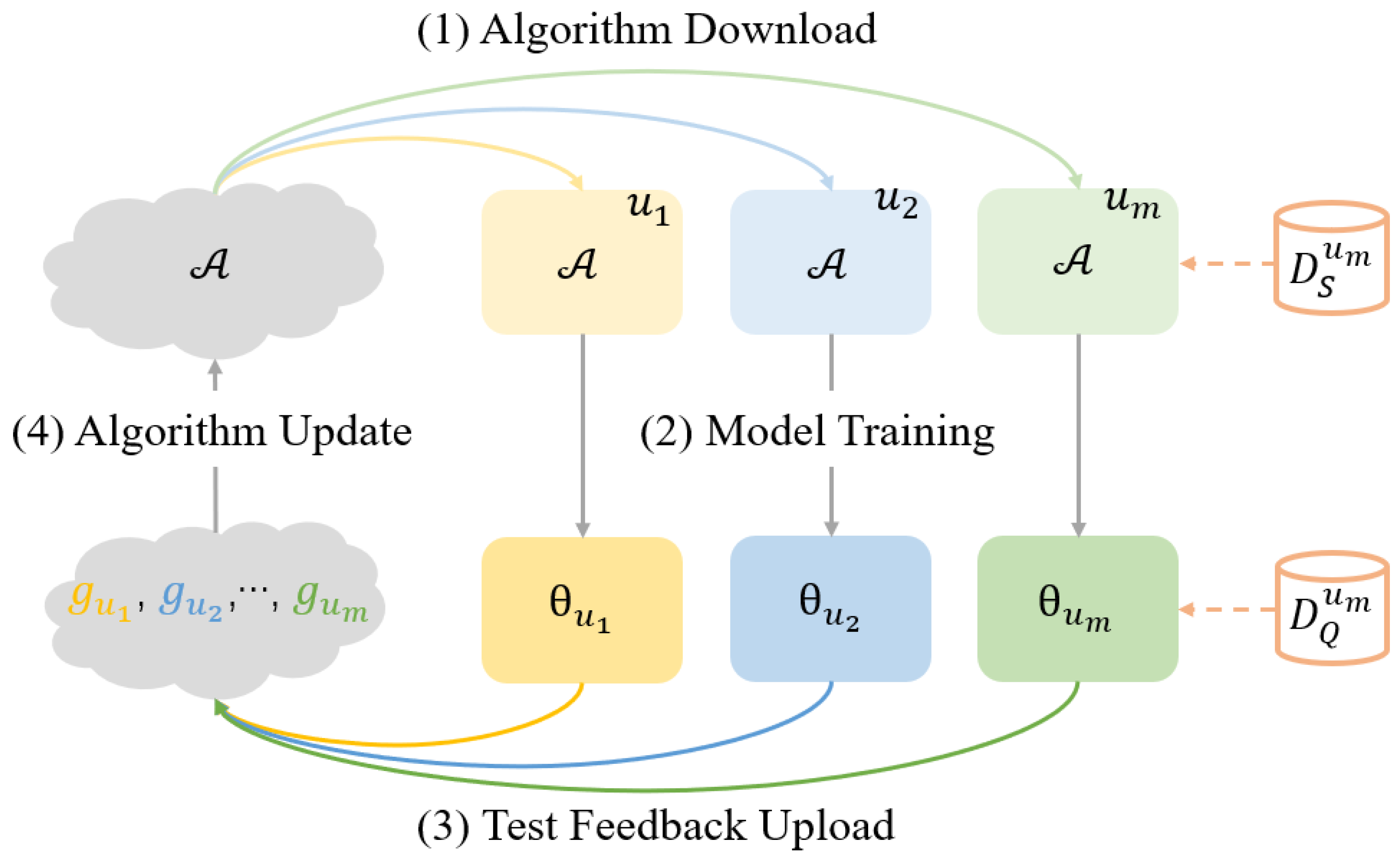
3.2.4. Recommendation Algorithms
4. Application of Federated Meta-Learning in Cyberspace Security
4.1. Federated Meta-Learning Applied to Information Content Security
4.1.1. Adversarial Attack
4.1.2. Backdoor Attack
4.1.3. Poisoning Attack
4.2. Federated Meta-Learning Applied to Network Security
4.2.1. Equipment Selection and Model Fairness
4.2.2. Edge Intelligence
4.2.3. Low Computing
4.3. Federated Meta-Learning Applied to Information Systems Security
5. Conclusions and Prospects
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Campos, E.M.; Saura, P.F.; González-Vidal, A.; Hernández-Ramos, J.L.; Bernabé, J.B.; Baldini, G.; Skarmeta, A. Evaluating Federated Learning for intrusion detection in Internet of Things: Review and challenges. Comput. Netw. 2022, 203, 108661. [Google Scholar]
- Pei, J.; Zhong, K.; Jan, M.A.; Li, J. Personalized federated learning framework for network traffic anomaly detection. Comput. Netw. 2022, 209, 108906. [Google Scholar]
- Manoharan, P.; Walia, R.; Iwendi, C.; Ahanger, T.A.; Suganthi, S.T.; Kamruzzaman, M.M.; Bourouis, S.; Alhakami, W.; Hamdi, M. SVM-based generative adverserial networks for federated learning and edge computing attack model and outpoising. Expert Syst. 2022, 40, e13072. [Google Scholar]
- Liang, T.; Zeng, B.; Liu, J.; Ye, L.; Zou, C. An unsupervised user behavior prediction algorithm based on machine learning and neural network for smart home. IEEE Access 2018, 6, 49237–49247. [Google Scholar]
- Liang, T.K.; Zeng, B.; Liu, J.Q. FP-Growth-based user temporal association control habits mining method for smart home. Appl. Res. Comput. 2020, 37, 385–389. [Google Scholar]
- Yang, H.H.; Zhongyuan, Z.H.; Quek, T.Q. Enabling Intelligence at Network Edge: An Overview of Federated Learning. ZTE Commun. 2020, 18, 2–10. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar]
- Zhu, H.; Zhang, H.; Jin, Y. From federated learning to federated neural architecture search: A survey. Complex Intell. Syst. 2021, 7, 639–657. [Google Scholar]
- Mendiboure, L.; Chalouf, M.A.; Krief, F. Edge computing based applications in vehicular environments: Comparative study and main issues. J. Comput. Sci. Technol. 2019, 34, 869–886. [Google Scholar]
- AbdulRahman, S.; Tout, H.; Ould-Slimane, H.; Mourad, A.; Talhi, C.; Guizani, M. A survey on federated learning: The journey from centralized to distributed on-site learning and beyond. IEEE Internet Things J. 2021, 8, 5476–5497. [Google Scholar]
- Chen, B.; Cheng, X.; Zhang, J.L. Survey of Security and Privacy in Federated Learning. J. Nanjing Univ. Aeronaut. Astronaut. 2020, 52, 675–684. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the AISTATS 2017, 2017 International Conference on Artificial Intelligence and Statistics, PMLR, Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; y Arcas, B.A. Federated learning of deep networks using model averaging. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Konečný, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- Zhou, J.; Fang, G.Y.; Wu, N. Survey on security and privacy-preserving in federated learning. J. Xihua Univ. 2020, 39, 9–17. [Google Scholar]
- Encheva, S.; Tumin, S. On improving quality of the decision making process in a federated learning system. In Proceedings of the Cooperative Design, Visualization, and Engineering: 5th International Conference, CDVE 2008 Calvià, Mallorca, Spain, 21–25 September 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 192–195. [Google Scholar]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečný, J.; Mazzocchi, S.; McMahan, B.; et al. Towards federated learning at scale: System design. Proc. Mach. Learn. Syst. 2019, 1, 374–388. [Google Scholar]
- Xu, J.; Du, W.; Xu, Q. Federated learning based atmospheric source term estimation in urban environments. Comput. Chem. Eng. 2021, 155, 107505. [Google Scholar]
- Li, Q.; Wen, Z.; He, B. Federated learning systems: Vision, hype and reality for data privacy and protection. arXiv 2019, arXiv:1907.09693. [Google Scholar]
- Xia, Q.; Ye, W.; Tao, Z. A survey of federated learning for edge computing: Research problems and solutions. High-Confid. Comput. 2021, 1, 100008–100051. [Google Scholar]
- Tang, C.M.; Hu, Y.Z. Secure Multi-Party Computation based on multi-bit fully homomorphic encryption. Chin. J. Comput. 2021, 44, 836–845. [Google Scholar]
- Luo, C.Y.; Chen, X.B.; Ma, C.D. Improved federated average algorithm based on tomographic analysis. Comput. Sci. 2021, 48, 32–40. [Google Scholar]
- Wang, J.Z.; Kong, L.W.; Huang, Z.C. Research advances on privacy protection of federated learning. Big Data Res. 2021, 7, 130–149. [Google Scholar]
- Xia, J.Z.; Lu, Y.; Zhang, Z.Y. Research on vertical federated learning based on secret sharing and homomorphic encryption. Telecommun. Netw. Technol. 2021, 47, 19–26. [Google Scholar]
- Yang, K.; Jiang, T.; Shi, Y. Federated learning via over-the-air computation. IEEE Trans. Wirel. Commun. 2020, 19, 2022–2035. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Sun, J.; Yang, X.; Yao, Y. Vertical federated learning without revealing intersection membership. arXiv 2021, arXiv:2106.05508. [Google Scholar]
- Hashemi, N.; Safari, P.; Shariati, B. Vertical federated learning for privacy-preserving ML model development in partially disaggregated networks. In Proceedings of the 2021 European Conference on Optical Communication (ECOC), Bordeaux, France, 13–16 September 2021; pp. 1–4. [Google Scholar]
- Zhang, Y.; Wu, Q.; Shikh-Bahaei, M. Vertical federated learning based privacy-preserving cooperative sensing in cognitive radio networks. In Proceedings of the 2020 IEEE Globecom Workshops (GC Wkshps), Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Yang, Q.; Liu, Y.; Cheng, Y. Federated Learning; Publishing House of Electronics Industry: Beijing, China, 2020; pp. 77–80. [Google Scholar]
- Liu, J.X.; Meng, X.F. Survey on privacy-preserving machine learning. J. Comput. Res. Dev. 2020, 57, 346. [Google Scholar]
- Liu, Y.; Kang, Y.; Xing, C. A secure federated transfer learning framework. IEEE Intell. Syst. 2020, 35, 70–82. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1175–1191. [Google Scholar]
- Acar, A.; Aksu, H.; Uluagac, A.S. A survey on homomorphic encryption schemes: Theory and implementation. ACM Comput. Surv. 2018, 51, 1–35. [Google Scholar]
- Awan, J.; Slavković, A. Structure and sensitivity in differential privacy: Comparing k-norm mechanisms. J. Am. Stat. Assoc. 2021, 116, 935–954. [Google Scholar]
- Huang, J.; Qian, F.; Guo, Y.; Zhou, Y.; Xu, Q.; Mao, Z.M.; Sen, S.; Spatscheck, O. An in-depth study of lte: Effect of network protocol and application behavior on performance. SIGCOMM Comput. Commun. Rev. 2013, 43, 363–374. [Google Scholar]
- Van Berkel, C. Multi-core for mobile phones. In Proceedings of the Conference on Design, Automation and Test in Europe, Nice, France, 20–24 April 2009. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar]
- Briggs, C.; Fan, Z.; Andras, P. Federated learning with hierarchical clustering of local updates to improve training on non-IID data. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–9. [Google Scholar]
- Carlini, N.; Liu, C.; Kos, J. The secret sharer: Measuring unintended neural network memorization & extracting secrets. arXiv 2018, arXiv:1802.08232. [Google Scholar]
- Duchi, J.C.; Jordan, M.I.; Wainwright, M.J. Privacy aware learning. In Proceedings of the Advances in Neural Information Processing Systems, Stateline, NV, USA, 3–8 December 2012. [Google Scholar]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar]
- McMahan, H.B.; Ramage, D.; Talwar, K. Learning differentially private recurrent language models. arXiv 2017, arXiv:1710.06963. [Google Scholar]
- Dwork, C. Differential privacy: A survey of results. In Proceedings of the International Conference on Theory and Applications of Models of Computation, Xi’an, China, 25–29 April 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–19. [Google Scholar]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Jin, S.; Quek, T.Q.S.; Poor, H.V. Federated learning with differential privacy: Algorithms and performance analysis. IEEE Trans. Inf. Secur. 2020, 15, 3454–3469. [Google Scholar]
- Domingos, P. A few useful things to know about machine learning. Proc. Commun. ACM 2012, 55, 78–87. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Stateline, NV, USA, 3–8 December 2012. [Google Scholar]
- He, K.; Zhang, X.; Ren, S. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pretraining of deep bidirectional transformers for language understanding. In Proceedings of the Association for Computational Linguistics (ACL), Florence, Italy, 28 July–2 August 2019; pp. 4171–4186. [Google Scholar]
- Altae-Tran, H.; Ramsundar, B.; Pappu, A.S.; Pande, V. Low data drug discovery with one-shot learning. ACS Cent. Sci. 2017, 3, 283–293. [Google Scholar]
- Ignatov, A.; Timofte, R.; Kulik, A.; Yang, S.; Wang, K.; Baum, F.; Wu, M.; Xu, L.; Van Gool, L. AI benchmark: All about deep learning on smartphones in 2019. arXiv 2019, arXiv:1910.06663. [Google Scholar]
- Thrun, S.; Pratt, L. Learning to learn: Introduction and overview. In Learning to Learn; Springer: Boston, MA, USA, 1998. [Google Scholar]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Andrychowicz, M.; Denil, M.; Gomez, S. Learning to learn by gradient descent by gradient descent. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; p. 29. [Google Scholar]
- Metz, L.; Maheswaranathan, N.; Cheung, B. Meta-learning update rules for unsupervised representation learning. arXiv 2018, arXiv:1804.00222. [Google Scholar]
- Marcus, G. Deep learning: A critical pppraisal. arXiv 2018, arXiv:1801.00631. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Feurer, M.; Hutter, F. Hyperparameter optimization. In Automated Machine Learning: Methods, Systems, Challenges; Springer: Berlin/Heidelberg, Germany, 2019; pp. 3–33. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. Darts: Differentiable architecture search. arXiv 2018, arXiv:1806.09055. [Google Scholar]
- Zhou, W.; Li, Y.; Yang, Y. Online meta-critic learning for off-policy actor-critic methods. Adv. Neural Inf. Process. Syst. 2020, 33, 17662–17673. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical Networks for few shot learning. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Duan, Y.; Schulman, J.; Chen, X.; Bartlett, P.L.; Sutskever, I.; Abbeel, P. RL2: Fast reinforcement learning via slow reinforcement learning. arXiv 2016, arXiv:1611.02779. [Google Scholar]
- Houthooft, R.; Chen, Y.; Isola, P. Evolved policy gradients. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; p. 31. [Google Scholar]
- Alet, F.; Schneider, M.F.; Lozano-Perez, T. Meta-learning curiosity algorithms. arXiv 2020, arXiv:2003.05325. [Google Scholar]
- Real, E.; Aggarwal, A.; Huang, Y. Regularized evolution for image classifier architecture search. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4780–4789. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. In Proceedings of the ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Santoro, A.; Bartunov, S.; Botvinick, M. Meta-learning with memory-augmented neural networks. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1842–1850. [Google Scholar]
- Zhang, R.; Che, T.; Ghahramani, Z. Metagan: An adversarial approach to few-shot learning. In Proceedings of the NeurlPS, Montréal, QC, Canada, 3–8 December 2018; p. 31. [Google Scholar]
- Olasehinde, O.O.; Johnson, O.V.; Olayemi, O.C. Evaluation of selected meta learning algorithms for the prediction improvement of network intrusion detection system. In Proceedings of the 2020 International Conference in Mathematics, Computer Engineering and Computer Science (ICMCECS), Ayobo, Nigeria, 18–21 March 2020; pp. 1–7. [Google Scholar]
- Danielsson, P.E. Euclidean distance mapping. Comput. Graph. Image Process. 1980, 14, 227–248. [Google Scholar]
- Xia, P.; Zhang, L.; Li, F. Learning similarity with cosine similarity ensemble. Inf. Sci. 2015, 307, 39–52. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst. 2016, 29, 3630–3638. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Gao, T.; Han, X.; Liu, Z. Hybrid attention-based prototypical networks for noisy few-shot relation classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6407–6414. [Google Scholar]
- Geng, R.; Li, B.; Li, Y.; Ye, Y.; Jian, P.; Sun, J. Few-Shot Text Classification with Induction Network. arXiv 2019, arXiv:1902.10482. [Google Scholar]
- Mishra, N.; Rohaninejad, M.; Chen, X. A simple neural attentive meta-learner. arXiv 2017, arXiv:1707.03141. [Google Scholar]
- Nichol, A.; Achiam, J.; Schulman, J. On first-order meta-learning algorithms. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-sgd: Learning to Learn Quickly for Few-Shot Learning. arXiv 2017, arXiv:1707.09835. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar]
- Wang, J.Z.; Kong, L.W.; Huang, Z.Z. Research review of federated learning algorithms. Big Data Res. 2020, 6, 64–82. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Chen, F.; Luo, M.; Dong, Z. Federated meta-learning with fast convergence and efficient communication. arXiv 2018, arXiv:1802.07876. [Google Scholar]
- Jiang, Y.; Konečný, J.; Rush, K. Improving federated learning personalization via model agnostic meta learning. arXiv 2019, arXiv:1909.12488. [Google Scholar]
- Fallah, A.; Mokhtari, A.; Ozdaglar, A. Personalized federated learning: A meta-learning approach. arXiv 2020, arXiv:2002.07948. [Google Scholar]
- Yao, X.; Huang, T.; Zhang, R.X. Federated learning with unbiased gradient aggregation and controllable meta updating. arXiv 2019, arXiv:1910.08234. [Google Scholar]
- Khodak, M.; Li, T.; Li, L. Weight sharing for hyperparameter optimization in federated learning. In Proceedings of the Int. Workshop on Federated Learning for User Privacy and Data Confidentiality in Conjunction with ICML, Vienna, Austria, 17–18 July 2020. [Google Scholar]
- Zhang, M.; Sapra, K.; Fidler, S. Personalized federated learning with first order model optimization. arXiv 2020, arXiv:2012.08565. [Google Scholar]
- Balakrishnan, R.; Akdeniz, M.; Dhakal, S. Resource management and model personalization for federated learning over wireless edge networks. J. Sens. Actuator Netw. 2021, 10, 17. [Google Scholar] [CrossRef]
- Singhal, K.; Sidahmed, H.; Garrett, Z. Federated reconstruction: Partially local federated learning. Adv. Neural Inf. Process. Syst. 2021, 34, 11220–11232. [Google Scholar]
- Yang, L.; Huang, J.; Lin, W. Personalized federated learning on non-iid data via group-based meta-learning. ACM Trans. Knowl. Discov. Data 2023, 17, 1–20. [Google Scholar]
- Wang, B.; Li, A.; Li, H. Graphfl: A federated learning framework for semi-supervised node classification on graphs. arXiv 2020, arXiv:2012.04187. [Google Scholar]
- Lin, S.; Yang, L.; He, Z. MetaGater: Fast learning of conditional channel gated networks via federated meta-learning. In Proceedings of the 2021 IEEE 18th International Conference on Mobile Ad Hoc and Smart Systems (MASS), Denver, CO, USA, 4–7 October 2021; pp. 164–172. [Google Scholar]
- Liu, X.; Twardowski, B.; Wijaya, T.K. Online Meta-Learning for Model Update Aggregation in Federated Learning for Click-Through Rate Prediction. arXiv 2022, arXiv:2209.00629. [Google Scholar]
- Zhang, C.; Zhang, H.; Qiao, J.; Yuan, D.; Zhang, M. Deep transfer learning for intelligent cellular traffic prediction based on cross-domain big data. IEEE J. Sel. Areas Commun. 2019, 37, 1389–1401. [Google Scholar]
- Xu, Y.; Yin, F.; Xu, W.; Lin, J.; Cui, S. Wireless traffic prediction with scalable gaussian process: Framework, algorithms, and verification. IEEE J. Sel. Areas Commun. 2019, 37, 1291–1306. [Google Scholar] [CrossRef]
- Saad, W.; Bennis, M.; Chen, M. A vision of 6G wireless systems: Applications, trends, technologies, and open research problems. IEEE Netw. 2019, 34, 134–142. [Google Scholar]
- Letaief, K.B.; Chen, W.; Shi, Y.; Zhang, J.; Zhang, Y.-J.A. The roadmap to 6g: AI empowered wireless networks. IEEE Commun. Mag. 2019, 57, 84–90. [Google Scholar]
- Zhang, L.; Zhang, C.; Shihada, B. Efficient wireless traffic prediction at the edge: A federated meta-learning approach. IEEE Commun. Lett. 2022, 26, 1573–1577. [Google Scholar] [CrossRef]
- Zhao, S.; Bharati, R.; Borcea, C. Privacy-aware federated learning for page recommendation. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 1071–1080. [Google Scholar]
- Arambakam, M. Federated Meta-Learning: A Novel Approach for Algorithm Selection. Master Thesis, University of Dublin, Dublin, Ireland, 2020. [Google Scholar]
- Wang, Q.; Yin, H.; Chen, T. Fast-adapting and privacy-preserving federated recommender system. VLDB J. 2021, 31, 877–896. [Google Scholar] [CrossRef]
- Wang, S.W. On Information Security, Network Security, and Cyberspace Security. J. Libr. Sci. China 2015, 41, 72–84. [Google Scholar] [CrossRef]
- Information Security Professional Instruction Committee-Information Security Professional Specification Project Group. Information Security Majority Insructive Specification; Tsinghua University Press: Beijing, China, 2014. [Google Scholar]
- Zhang, H.G.; Du, R.Y.; Fu, J.M. Information security discipline. Netw. Secur. 2014, 56, 619–620. [Google Scholar]
- Zhang, H.G.; Wang, L.N.; Du, R.Y. Information security discipline system structure research. J. Wuhan. Univ. 2010, 56, 614–620. [Google Scholar]
- Zhang, H.G.; Han, W.B.; Lai, X.J.; Lin, D.D.; Ma, J.F.; Li, J.H. Overview of Cyberspace Security. Chin. Sci. Inf. Sci. 2016, 46, 125–164. [Google Scholar]
- Lin, S.; Yang, G.; Zhang, J. A collaborative learning framework via federated meta-learning. In Proceedings of the 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS), Singapore, 29 November–1 December 2022; pp. 289–299. [Google Scholar]
- Huang, A. Dynamic backdoor attacks against federated learning. arXiv 2020, arXiv:2011.07429. [Google Scholar]
- Chen, C.L.; Golubchik, L.; Paolieri, M. Backdoor attacks on federated meta-learning. arXiv 2020, arXiv:2006.07026. [Google Scholar]
- Aramoon, O.; Chen, P.Y.; Qu, G. Meta Federated Learning. arXiv 2021, arXiv:2102.05561. [Google Scholar]
- El-Bouri, R.; Zhu, T.; Clifton, D.A. Towards Scheduling Federated Deep Learning Using Meta-Gradients for Inter-Hospital Learning. arXiv 2021, arXiv:2107.01707. [Google Scholar]
- Połap, D.; Woźniak, M. Meta-heuristic as manager in federated learning approaches for image processing purposes. Appl. Soft Comput. 2021, 113, 107872. [Google Scholar] [CrossRef]
- Edmunds, R.; Golmant, N.; Ramasesh, V.; Kuznetsov, P.; Patil, P.; Puri, R. Transferability of adversarial attacks in model-agnostic meta learning. In Proceedings of the Deep Learning and Security Workshop (DLSW), Singapore, 14–15 December 2017. [Google Scholar]
- Yin, C.; Tang, J.; Xu, Z.; Wang, Y. Adversarial meta-learning. arXiv 2018, arXiv:1806.03316. [Google Scholar]
- Netzer, Y.; Wang, T.; Coates, A. Reading Digits in Natural Images with Unsupervised Feature Learning. Available online: http://ai.stanford.edu/~twangcat/papers/nips2011_housenumbers.pdf (accessed on 7 July 2023).
- Stallkamp, J.; Schlipsing, M.; Salmen, J. Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition. Neural Netw. 2012, 32, 323–332. [Google Scholar] [CrossRef]
- Li, T.; Sanjabi, M.; Beirami, A. Fair resource allocation in federated learning. arXiv 2019, arXiv:1905.10497. [Google Scholar]
- Yue, S.; Ren, J.; Xin, J. Efficient federated meta-learning over multi-access wireless networks. IEEE J. Sel. Areas Commun. 2022, 40, 1556–1570. [Google Scholar] [CrossRef]
- Yue, S.; Ren, J.; Xin, J. Inexact-ADMM based federated meta-learning for fast and continual edge learning. In Proceedings of the Twenty-Second International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, Shanghai, China, 26–29 July 2021; pp. 91–100. [Google Scholar]
- Elgabli, A.; Issaid, C.B.; Bedi, A.S. Energy-efficient and federated meta-learning via projected stochastic gradient ascent. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar]
- Zheng, W.; Yan, L.; Gou, C. Federated meta-learning for fraudulent credit card detection. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 4654–4660. [Google Scholar]
- Li, X.; Liu, S.; Li, Z. Flowscope: Spotting money laundering based on graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 4731–4738. [Google Scholar]
- Dal Pozzolo, A.; Boracchi, G.; Caelen, O. Credit card fraud detection: A realistic modeling and a novel learning strategy. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 3784–3797. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Data Characteristics | How FL Works under Different Data Distributions | Model Performance | Aggregation Strategies | Solution |
|---|---|---|---|---|---|
| Data are IID | Each client’s data samples exhibit the same distribution and characteristics, and the data between clients are similar. | In each training round, individual clients independently train their local data and subsequently upload the model parameters to the server. The server then averages the received model parameters and updates the global model. | Due to the similarity in data distribution, the model generally converges rapidly, and its performance remains relatively consistent across various clients. | FedAvg | |
| Data are non-IID | The data distribution and characteristics of different clients may exhibit substantial variations, as observed in data collected from diverse regions, various users, or different devices. | When clients conduct local training, they can employ class-balanced sampling methods to ensure sufficient training data for each category. Alternatively, they may use a class-weighted loss function, giving rare classes more significant weight. During model aggregation, different aggregation strategies can be adopted to optimize model aggregation in non-IID environments. | The significant diversity in data across different clients can lead to a decline in model performance when using straightforward aggregation methods like FedAvg. Such methods may overlook essential features specific to certain domains, thereby neglecting their contribution to the global model update. | Weighted Average FedAvg+ | Local Training Strategies |
| Aggregation Strategies | |||||
| Model Personalization |
| Problems | Algorithm or Model | Advantages and Disadvantages | Related Work |
|---|---|---|---|
| Adversarial attacks | Robust FedML | It can prevent future confrontation attacks, and it will not significantly sacrifice the accuracy of rapid adaptive learning accuracy at the edge node of the target | [110] |
| Backdoor attacks | Symbiosis network | In terms of dynamic backdoor attacks, the accuracy is high and will not significantly affect the main tasks | [111] |
| Matching network | It greatly reduces the success rate of the backdoor attack but also reduces the accuracy of the main task | [112] | |
| Meta-FL | Defends the privacy of the participants while defending the backdoor attack | [113] | |
| Poisoning attacks | Student–Teacher Algorithm | The use of teaching settings overcomes the problem of node poisoning faced in federal learning, but, if data poisoning occurs, the scheduling program needs to continue several iteration trainings | [114] |
| Metaheuristic algorithm | This method has higher accuracy than traditional federated learning methods and can be used for fast image analysis and detecting database poisoning of any staff. However, many heuristic parameters may be improperly selected | [115] |
| Problems | Algorithm or Model | Advantages and Disadvantages | Related Work |
|---|---|---|---|
| Equipment Selection and Model Fairness | q-MAML | It performs more fairly on different tasks and can be extended to federal learning scenarios | [120] |
| NUFM | Promote model convergence and optimize tradeoffs between convergence, clock time, and energy consumption | [121] | |
| Edge Intelligence | Platform-assisted collaborative learning framework | It can quickly adapt to the target edge node and has fast convergence speed | [110] |
| ADMM-FedMeta | Decouple the regularizer from the edge node to the platform, which reduces the cost of local computing, and can also effectively use the resources between the local device and the server | [122] | |
| Low Computing | Energy-efficient feedback meta-learning framework | Greatly reduces the calculation cost, improves communication efficiency, and achieves high performance in order to significantly lower energy consumption | [123] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, F.; Li, M.; Liu, X.; Xue, T.; Ren, J.; Zhang, C. A Review of Federated Meta-Learning and Its Application in Cyberspace Security. Electronics 2023, 12, 3295. https://doi.org/10.3390/electronics12153295
Liu F, Li M, Liu X, Xue T, Ren J, Zhang C. A Review of Federated Meta-Learning and Its Application in Cyberspace Security. Electronics. 2023; 12(15):3295. https://doi.org/10.3390/electronics12153295
Chicago/Turabian StyleLiu, Fengchun, Meng Li, Xiaoxiao Liu, Tao Xue, Jing Ren, and Chunying Zhang. 2023. "A Review of Federated Meta-Learning and Its Application in Cyberspace Security" Electronics 12, no. 15: 3295. https://doi.org/10.3390/electronics12153295
APA StyleLiu, F., Li, M., Liu, X., Xue, T., Ren, J., & Zhang, C. (2023). A Review of Federated Meta-Learning and Its Application in Cyberspace Security. Electronics, 12(15), 3295. https://doi.org/10.3390/electronics12153295