
DPNet: Dual-Pyramid Semantic Segmentation Network Based on Improved Deeplabv3 Plus

Abstract
1. Introduction
1.1. Semantic Segmentation
1.2. Multi-Scale Information Fusion
1.3. Attention Module
- (1)
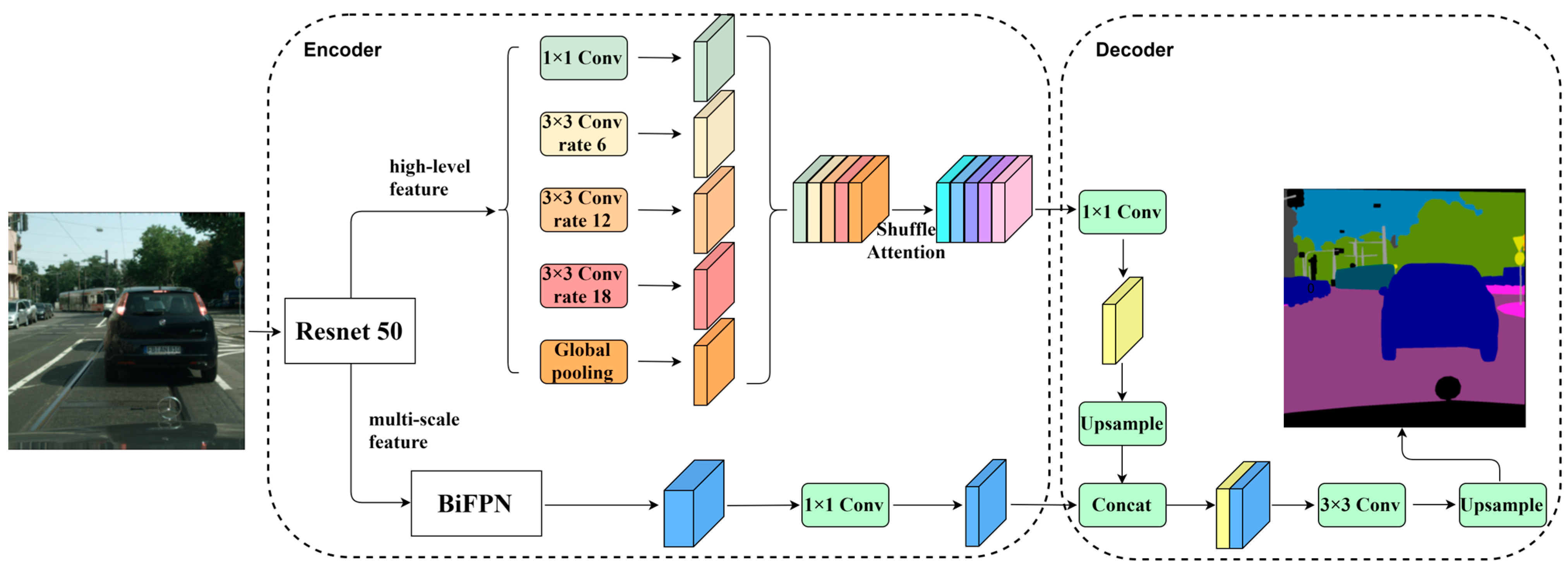
- We propose an improved semantic segmentation model based on Deeplabv3 plus, called DPNet. DPNet is a dual-pyramid semantic segmentation network.
- (2)
- We introduce a method that leverages a dual-feature pyramid to integrate feature maps at various resolutions, effectively amalgamating contextual information and enhancing accuracy. The model’s capacity to capture multi-scale information and fuse diverse-scale information is strengthened while fully exploiting the effective features extracted by the backbone network.
- (3)
- We incorporate the Shuffle Attention module, which effectively combines spatial attention and channel attention, suppressing the transmission of irrelevant information and enhancing the representational capacity of meaningful features.
- (4)
- The proposed algorithm achieves promising experimental results with mIoU values of 78.69% and 79.51% on the validation sets of the Cityscapes and Pascal VOC 2012, respectively.
2. Methods
2.1. Multi-Scale Information Feature Fusion in the Dual-Pyramid Structure
2.2. Shuffle Attention Module
3. Experiments and Results
3.1. Experimental Environment
3.2. Datasets
3.2.1. Cityscapes
3.2.2. Pascal VOC 2012
3.3. Evaluation Metrics
3.4. Ablation Study on Cityscapes Dataset
3.5. Results on Cityscapses Dataset
3.6. Results on Pascal VOC 2012 Dataset
4. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mo, Y.; Wu, Y.; Yang, X.; Liu, F.; Liao, Y. Review the state-of-the-art technologies of semantic segmentation based on deep learning. Neurocomputing 2022, 493, 626–646. [Google Scholar] [CrossRef]
- Feng, D.; Haase-Schutz, C.; Rosenbaum, L.; Hertlein, H.; Glaser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1341–1360. [Google Scholar] [CrossRef]
- Li, J.; Jiang, F.; Yang, J.; Kong, B.; Gogate, M.; Dashtipour, K.; Hussain, A. Lane-deeplab: Lane semantic segmentation in automatic driving scenarios for high-definition maps. Neurocomputing 2021, 465, 15–25. [Google Scholar] [CrossRef]
- Wang, H.; Chen, Y.; Cai, Y.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. Sfnet-n: An improved sfnet algorithm for semantic segmentation of low-light autonomous driving road scenes. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21405–21417. [Google Scholar] [CrossRef]
- Zhou, W.; Liu, J.; Lei, J.; Yu, L.; Hwang, J.-N. Gmnet: Graded-feature multilabel-learning network for rgb-thermal urban scene semantic segmentation. IEEE Trans. Image Process. 2021, 30, 7790–7802. [Google Scholar] [CrossRef]
- Emek Soylu, B.; Guzel, M.S.; Bostanci, G.E.; Ekinci, F.; Asuroglu, T.; Acici, K. Deep-learning-based approaches for semantic segmentation of natural scene images: A review. Electronics 2023, 12, 2730. [Google Scholar] [CrossRef]
- Gu, J.; Bellone, M.; Sell, R.; Lind, A. Object segmentation for autonomous driving using iseauto data. Electronics 2022, 11, 1119. [Google Scholar] [CrossRef]
- Heller, N.; Isensee, F.; Maier-Hein, K.H.; Hou, X.; Xie, C.; Li, F.; Nan, Y.; Mu, G.; Lin, Z.; Han, M.; et al. The state of the art in kidney and kidney tumor segmentation in contrast-enhanced ct imaging: Results of the kits19 challenge. Med. Image Anal. 2021, 67, 101821. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet plus plus: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imag. 2020, 39, 1856–1867. [Google Scholar] [CrossRef]
- Chin, C.-L.; Lin, J.-C.; Li, C.-Y.; Sun, T.-Y.; Chen, T.; Lai, Y.-M.; Huang, P.-C.; Chang, S.-W.; Sharma, A.K. A novel fuzzy dbnet for medical image segmentation. Electronics 2023, 12, 2658. [Google Scholar] [CrossRef]
- Jia, J.; Song, J.; Kong, Q.; Yang, H.; Teng, Y.; Song, X. Multi-attention-based semantic segmentation network for land cover remote sensing images. Electronics 2023, 12, 1347. [Google Scholar] [CrossRef]
- Gibril, M.B.A.; Shafri, H.Z.M.; Al-Ruzouq, R.; Shanableh, A.; Nahas, F.; Al Mansoori, S. Large-scale date palm tree segmentation from multiscale uav-based and aerial images using deep vision transformers. Drones 2023, 7, 93. [Google Scholar] [CrossRef]
- Wang, X.; Shu, L.; Han, R.; Yang, F.; Gordon, T.; Wang, X.; Xu, H. A survey of farmland boundary extraction technology based on remote sensing images. Electronics 2023, 12, 1156. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 432–448. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H.; Soc, I.C. Dual attention network for scene segmentation. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3141–3149. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhu, Z.; Xu, M.; Bai, S.; Huang, T.; Bai, X. Asymmetric non-local neural networks for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 593–602. [Google Scholar]
- Lian, X.; Pang, Y.; Han, J.; Pan, J. Cascaded hierarchical atrous spatial pyramid pooling module for semantic segmentation. Pattern Recognit. 2020, 110, 107622. [Google Scholar] [CrossRef]
- Jiang, D.; Qu, H.; Zhao, J.; Zhao, J.; Hsieh, M.-Y. Aggregating multi-scale contextual features from multiple stages for semantic image segmentation. Connect. Sci. 2021, 33, 605–622. [Google Scholar] [CrossRef]
- Zhu, Q.; Liao, C.; Hu, H.; Mei, X.; Li, H. Map-net: Multiple attending path neural network for building footprint extraction from remote sensed imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6169–6181. [Google Scholar] [CrossRef]
- Dai, Y.; Wang, J.; Li, J.; Li, J. Pdbnet: Parallel dual branch network for real-time semantic segmentation. Int. J. Control. Autom. Syst. 2022, 20, 2702–2711. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. arXiv 2020, arXiv:1911.09070. [Google Scholar]
- Ou, X.; Wang, H.; Zhang, G.; Li, W.; Yu, S. Semantic segmentation based on double pyramid network with improved global attention mechanism. Appl. Intell. 2023, 53, 18898–18909. [Google Scholar] [CrossRef]
- Lin, Z.; Sun, W.; Tang, B.; Li, J.; Yao, X.; Li, Y. Semantic segmentation network with multi-path structure, attention reweighting and multi-scale encoding. Vis. Comput. 2023, 39, 597–608. [Google Scholar] [CrossRef]
- Jia, W.K.; Tian, Y.Y.; Luo, R.; Zhang, Z.H.; Lian, J.; Zheng, Y.J. Detection and segmentation of overlapped fruits based on optimized mask r-cnn application in apple harvesting robot. Comput. Electron. Agric. 2020, 172, 105380. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2022, 52, 8574–8586. [Google Scholar] [CrossRef]
- Sinha, A.; Dolz, J. Multi-scale self-guided attention for medical image segmentation. IEEE J. Biomed. Health Inform. 2021, 25, 121–130. [Google Scholar] [CrossRef]
- Cheng, H.K.; Chung, J.; Tai, Y.-W.; Tang, C.-K. Cascadepsp: Toward class-agnostic and very high-resolution segmentation via global and local refinement. arXiv 2020, arXiv:2005.02551. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. arXiv 2020, arXiv:1910.03151. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, Q.-L.; Yang, Y.-B. SA-Net: Shuffle attention for deep convolutional neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2235–2239. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | BiFPN | Shuffle Attention | mIoU | mPA | mIoU (Gaussian Noise) | mPA (Gaussian Noise) |
|---|---|---|---|---|---|---|---|
| Deeplabv3 plus [14] | ResNet-50 | 76.59 | 95.88 | 70.93 | 94.88 | ||
| Deeplabv3 plus + BiFPN | ResNet-50 | √ | 77.83 | 96.1 | 73.34 | 95.64 | |
| Deeplabv3 plus + Shuffle Attention | ResNet-50 | √ | 77.79 | 96.05 | 72.58 | 95.34 | |
| Deeplabv3 plus + BiFPN + Shuffle Attention | ResNet-50 | √ | √ | 78.69 | 96.21 | 74.78 | 95.66 |
| Method | Backbone | BiFPN | Shuffle Attention | FLOPs (G) | Memory (MB) |
|---|---|---|---|---|---|
| Deeplabv3 plus [14] | ResNet-50 | 397.74 | 2285 | ||
| Deeplabv3 plus + BiFPN | ResNet-50 | √ | 415.26 | 2480 | |
| Deeplabv3 plus + Shuffle Attention | ResNet-50 | √ | 397.77 | 2333 | |
| Deeplabv3 plus + BiFPN + Shuffle Attention | ResNet-50 | √ | √ | 415.29 | 2527 |
| Methods | FCN [15] | Deeplabv3 [21] | UPerNet [16] | PSPNet [19] | DANet [18] | DPNet |
|---|---|---|---|---|---|---|
| Road | 97.76 | 97.81 | 97.85 | 97.62 | 98.0 | 98.16 |
| Sidewalk | 83.29 | 83.01 | 83.46 | 82.53 | 84.55 | 85.18 |
| Building | 91.28 | 92.27 | 92.1 | 92.28 | 92.35 | 92.93 |
| Wall | 36.06 | 47.76 | 59.6 | 55.13 | 57.83 | 56.69 |
| Fence | 50.63 | 60.1 | 57.86 | 58.69 | 60.5 | 61.47 |
| Pole | 63.41 | 64.09 | 62.8 | 63.45 | 64.3 | 67.65 |
| Traffic light | 71.12 | 70.78 | 70.83 | 71.06 | 71.05 | 73.68 |
| Traffic sign | 79.43 | 77.64 | 78.07 | 78.74 | 78.79 | 80.38 |
| Vegetation | 91.94 | 92.14 | 91.96 | 92.17 | 92.11 | 92.63 |
| Terrain | 61.7 | 59.86 | 62.95 | 62.91 | 63.73 | 63.6 |
| Sky | 94.08 | 94.58 | 94.41 | 94.3 | 94.15 | 94.82 |
| Person | 80.27 | 81.95 | 80.82 | 81.31 | 81.25 | 83.24 |
| Rider | 55.45 | 63.36 | 57.89 | 62.86 | 60.38 | 65.21 |
| Car | 92.7 | 94.43 | 94.77 | 94.63 | 95.01 | 95.2 |
| Truck | 30.37 | 73.74 | 56.49 | 59.92 | 67.57 | 69.69 |
| Bus | 61.29 | 85.35 | 81.93 | 81.04 | 84.48 | 89.76 |
| Train | 34.35 | 78.24 | 79.14 | 61.52 | 78.62 | 80.4 |
| Motorcycle | 51.96 | 65.76 | 61.05 | 63.98 | 63.66 | 66.13 |
| Bicycle | 77.36 | 76.62 | 76.4 | 76.42 | 76.7 | 78.27 |
| mIoU | 68.66 | 76.81 | 75.81 | 75.29 | 77.11 | 78.69 |
| mPA | 95.32 | 95.78 | 95.73 | 95.71 | 95.92 | 96.21 |
| Methods | FCN [15] | HRNet [17] | UPerNet [16] | PSPNet [19] | Deeplabv3 Plus [14] | DPNet |
|---|---|---|---|---|---|---|
| BG | 93.52 | 93.53 | 93.63 | 93.65 | 93.68 | 93.77 |
| Aeroplane | 83.54 | 82.27 | 90.79 | 90.8 | 90.83 | 90.62 |
| Bicycle | 40.4 | 45.55 | 44.04 | 44.66 | 42.81 | 43.81 |
| Bird | 85.09 | 89.26 | 90.25 | 90.11 | 90.03 | 90.28 |
| Boat | 60.51 | 66.41 | 76.15 | 71.61 | 72.84 | 73.35 |
| Bottle | 56.75 | 75.43 | 78.24 | 80.94 | 79.22 | 80.87 |
| Bus | 90.95 | 91.59 | 92.97 | 92.07 | 92.55 | 93.58 |
| Car | 82.95 | 88.77 | 88.05 | 90.5 | 89.39 | 91.53 |
| Cat | 87.38 | 90.41 | 93.43 | 94.08 | 93.65 | 94.44 |
| Chair | 36.07 | 43.07 | 38.65 | 50.55 | 37.69 | 37.83 |
| Cow | 56.85 | 83.01 | 90.61 | 92.74 | 87.37 | 91.1 |
| Table | 33.66 | 55.7 | 60.16 | 49.88 | 60.62 | 61.2 |
| Dog | 77.2 | 85.88 | 89.92 | 89.52 | 88.97 | 90.49 |
| Horse | 70.54 | 82.05 | 89.56 | 92.33 | 89.01 | 90.33 |
| Motorbike | 77.22 | 84.79 | 85.34 | 86.59 | 87.22 | 88.05 |
| Person | 86.48 | 88.4 | 86.25 | 88.53 | 86.86 | 87.56 |
| Plant | 49.97 | 56.29 | 65.9 | 56.86 | 61.48 | 67.7 |
| Sheep | 73.72 | 83.52 | 87.17 | 91.5 | 83.37 | 89.77 |
| Sofa | 46.8 | 48.84 | 51.78 | 45.82 | 52.78 | 51.8 |
| Train | 81.72 | 84.4 | 82.35 | 81.77 | 84.21 | 85.42 |
| TV | 71.1 | 76.23 | 77.96 | 73.6 | 78.93 | 76.3 |
| mIoU | 68.73 | 75.97 | 78.72 | 78.48 | 78.26 | 79.51 |
| mPA | 93.5 | 94.32 | 94.58 | 94.73 | 94.55 | 94.77 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Zhang, X.; Yan, T.; Tan, A. DPNet: Dual-Pyramid Semantic Segmentation Network Based on Improved Deeplabv3 Plus. Electronics 2023, 12, 3161. https://doi.org/10.3390/electronics12143161
Wang J, Zhang X, Yan T, Tan A. DPNet: Dual-Pyramid Semantic Segmentation Network Based on Improved Deeplabv3 Plus. Electronics. 2023; 12(14):3161. https://doi.org/10.3390/electronics12143161
Chicago/Turabian StyleWang, Jun, Xiaolin Zhang, Tianhong Yan, and Aihong Tan. 2023. "DPNet: Dual-Pyramid Semantic Segmentation Network Based on Improved Deeplabv3 Plus" Electronics 12, no. 14: 3161. https://doi.org/10.3390/electronics12143161
APA StyleWang, J., Zhang, X., Yan, T., & Tan, A. (2023). DPNet: Dual-Pyramid Semantic Segmentation Network Based on Improved Deeplabv3 Plus. Electronics, 12(14), 3161. https://doi.org/10.3390/electronics12143161