1. Introduction
Airborne radar usually faces complicated ground and/or sea clutter when detecting low-altitude moving targets. The clutter presents space-time coupling characteristics, and its power spectrum broadens severely. In general, one-dimensional methods based on Doppler filtering or spatial beamforming cannot achieve effective target detection. The space-time adaptive processing (STAP) method combines spatial and temporal two-dimensional information to suppress clutter in the space-time domain adaptively, improving the detection performance of moving targets for airborne radar [
1,
2]. However, conventional STAP methods need to use a certain number of independent and identically distributed (IID) training range cells to estimate the clutter plus noise covariance matrix (CNCM) of the range cell under test (RUT). It has been shown that the number of IID training range cells required by conventional STAP methods is at least twice the system’s degree of freedom to ensure that the loss of the output signal-to-clutter-plus-noise ratio (SCNR) is less than 3 dB compared to that of the optimal STAP [
3]. In practice, non-ideal factors, such as non-stationary environment, non-homogeneous clutter characteristics and complicated platform motion, make this condition difficult to meet [
4,
5,
6].
To reduce the requirement for IID training range cells, reduced-dimension STAP methods, reduced-rank STAP methods, direct data domain STAP methods and SR-based STAP methods have been proposed [
7,
8,
9,
10]. Among these methods, SR-STAP methods based on the focal under-determined system solver (FOCUSS), alternating direction method of multipliers (ADMM) and sparse Bayesian learning (SBL) algorithm [
11,
12,
13,
14,
15] can achieve high-resolution estimation of the clutter space-time amplitude spectrum by using a small number of IID training range cells. Then, CNCM can be calculated to suppress clutter and detect targets. However, the SR algorithms used in SR-STAP methods usually have the problems of parameter setting difficulty, high computational complexity and low accuracy. In addition, under the non-side-looking conditions, the clutter sparsity deteriorates, and the performance of SR-STAP methods degrades severely [
16].
Recently, based on the idea of image super-resolution reconstruction via deep learning [
17,
18], a new STAP method based on convolutional neural networks (CNNs) was proposed [
19,
20]. The CNN-STAP method trains a CNN offline by constructing the dataset that simulates the real clutter environment so that it can reconstruct a high-resolution image from its low-resolution version. Then, the trained CNN is used online to process the low-resolution clutter space-time power spectrum obtained based on a small number of IID training range cells to obtain the high-resolution estimation of the clutter space-time power spectrum, thus constructing the space-time filter for clutter suppression and target detection. CNN-STAP can obtain a high clutter suppression performance, and its online computing complexity is greatly reduced compared to the SR-STAP method. However, due to the small network scale and the relatively poor reconstruction capacity of the CNN constructed in [
19], the clutter suppression performance of the CNN-STAP method needs to be further improved. Increasing the network scale can improve the reconstruction capacity of the CNN and the performance of CNN-STAP, but it inevitably increases the computational complexity.
To reduce the requirement for the network reconstruction capacity of the CNN-STAP method, the clutter space-time spectrum obtained by the SR algorithm can be used as the input of the CNN, i.e., the SR-STAP method and the CNN-STAP method can be cascaded. In such a case, due to the high quality of the input clutter space-time spectrum, a high-resolution clutter spectrum can be reconstructed using a small-scaled CNN. Moreover, this method can reduce the requirements for parameter setting and iterations of the SR-STAP method and can improve its estimation accuracy. Based on reasonable iteration parameters and a small number of iterations, the SR algorithm can be used to process a small amount of IID training range cell data to obtain the high-resolution clutter space-time spectrum with some errors. Then, the CNN can be used to improve the estimation accuracy. Furthermore, based on the idea of deep unfolding (DU) [
21,
22,
23,
24,
25], the SR algorithm can be unfolded to form a deep neural network, and its optimal parameters under a certain number of iterations can be obtained via training, which can help to improve the accuracy of clutter space-time spectrum estimation. Then, the CNN can be used to obtain the final clutter space-time spectrum estimation result.
Based on the ideas mentioned above, a DU-CNN-STAP method is proposed in this paper. First, the airborne radar signal model is established, and the SR-STAP and CNN-STAP methods are briefly introduced. Then, the processing framework, network structure, dataset construction and training methods of the DU-CNN-STAP method are introduced in detail. Finally, the performance and advantages of the DU-CNN-STAP method are verified via simulation and experimental data. The results show that, compared to the SR-STAP and CNN-STAP methods, the proposed method can improve the clutter suppression performance and have a lower computational complexity.
3. DU-CNN-STAP
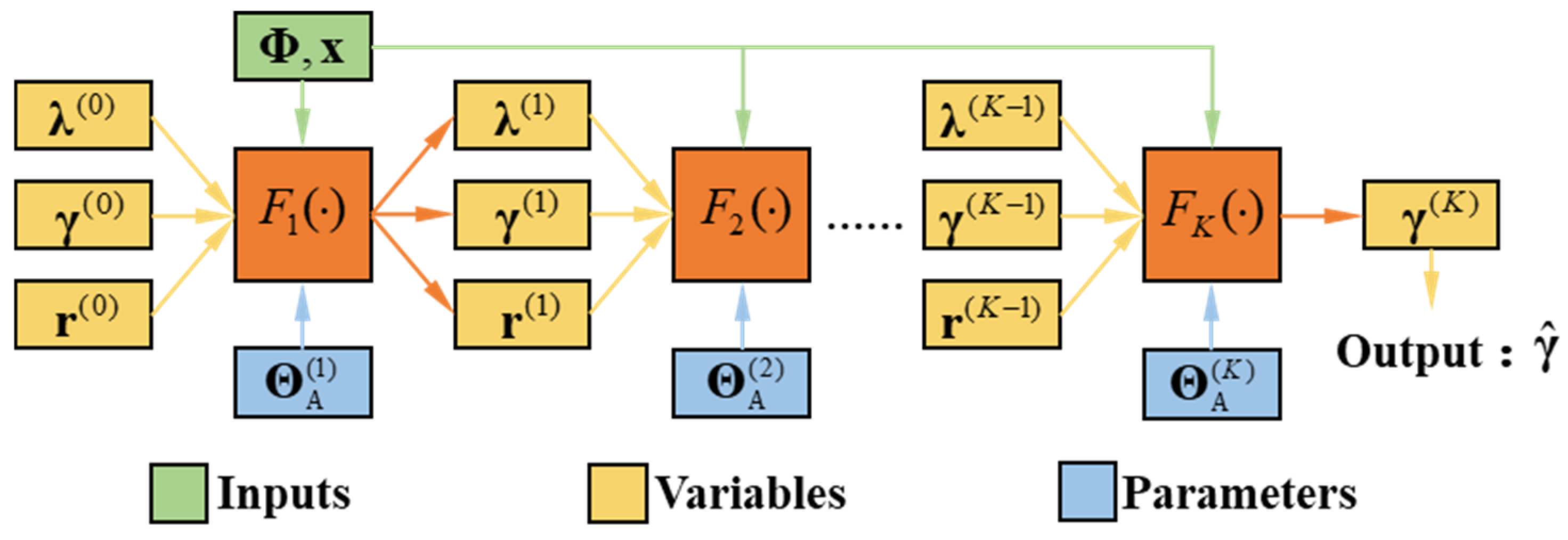
To solve the problems of SR-STAP and CNN-STAP simultaneously, the DU-CNN-STAP (deep unfolding and CNN-based STAP) method is proposed in this paper, as shown in
Figure 2. The specific operations are summarized as follows.
Step 1. The space-time echoed signal
x is input into the DU-CNN network (as indicated by the dashed box in
Figure 2). The high-resolution clutter space-time power spectrum estimation
is obtained via the nonlinear transform of DU-CNN.
Step 2. By replacing in (20) with , the CNCM is estimated.
Step 3. The space-time adaptive weighting vector is estimated according to (15), based on which clutter suppression and target detection are conducted.
DU-CNN-STAP implements a nonlinear transform from the space-time echoed signal directly to the high-resolution clutter power spectrum, i.e., . The key of the method is the DU-CNN network. The following points should be noted: (1) The ADMM-Net is a solving network for the SR problem in (12) with the network parameter as , which can help to achieve fast acquisition of the clutter space-time amplitude spectrum . (2) The squarer module completes the conversion from the space-time amplitude spectrum to the space-time power spectrum. The transform converts the data dimension from to . The output data can be expressed as . (3) The power normalization module normalizes the space-time spectrum data to improve the network convergence and obtains the input data of the CNN, expressed as , where . (4) The CNN module is the space-time power spectrum reconstruction network with the parameter as , which implements the estimation of the normalized high-resolution clutter space-time power spectrum . (5) The power restoring module performs clutter power restoring on , whose output is . Finally, the network output of DU-CNN can be obtained.
With a small number of layers (i.e., iterations), ADMM-Net can obtain a high-resolution estimation of the clutter space-time spectrum, and the CNN can further improve the estimation accuracy. Thus, the DU-CNN-STAP method can effectively solve the problems of parameter setting difficulty, high computational complexity and low accuracy of the SR-STAP method. In addition, unlike the CNN-STAP method, which uses the low-resolution clutter space-time spectrum as the input of the reconstruction network, the input of the reconstruction network in the proposed DU-CNN-STAP method is the high-resolution clutter space-time spectrum. Thus, the DU-CNN-STAP method can reduce the requirements for the nonlinear transform capability, the network scale and the computational complexity of the reconstruction network.
In the presence of range ambiguity, the SR problems shown in (12) and (13) can still be established, and ADMM-Net can still be used [
16]. Thus, in the presence of range ambiguity, the proposed DU-CNN-STAP method is still applicable. In the following, the DU-CNN network in the DU-CNN-STAP method is introduced in detail, including its network structure, dataset construction and training method. It should be noted that this paper only considers the case with a single training range cell, i.e.,
. The processing of multiple training range cells can be implemented via a simple extension of the proposed method. Thus, the subscript
l is ignored in the following.
3.1. Network Structure
3.1.1. ADMM-Net
Because the
norm is a discontinuous function, the complexity of solving (12) is high. Thus, (12) is often solved by transforming it into an
convex optimization problem, expressed as
Introducing an auxiliary variable
, (21) can be transformed into
where
denotes the regularization factor.
The augmented Lagrange function of (22) is given by
which can be transformed into
with
as the Lagrange multiplier and
as the quadratic penalty factor.
Given the initial values
, the ADMM algorithm solves (23) via the following three steps with
iterations alternately [
27]:
where
,
and
denote the estimation of
,
and
in the
iteration, respectively.
The solutions of the sub-problems in (24) are given by [
27]
where
denotes the soft threshold operator [
28] and
denotes the iteration step size.
The ADMM algorithm can obtain a high-resolution estimation with iterations and the iteration parameters as , and . Then, the CNCM and the adaptive weighting vector can be calculated according to (14) and (15). However, ADMM is a model-driven algorithm, whose parameters need to be given in advance. In practicality, the setting of parameters is generally difficult. Improper parameter settings affect the convergence performance of the ADMM algorithm, resulting in a high computing complexity of solving (12) and a low estimation performance of the clutter space-time amplitude spectrum. Even if the parameters can be set properly, using the same parameters for each iteration does not guarantee a best convergence performance for the ADMM algorithm. To solve this problem, the ADMM algorithm with a specific number of iterations can be unfolded into a deep neural network based on the idea of deep unfolding. The learning approach can then be used to obtain optimal parameters for different iterations, improving the convergence performance of ADMM.
As shown in
Figure 3, the ADMM algorithm with
iterations is unfolded into a
K-layer ADMM-Net, whose inputs are the space-time echoed signal
and the space-time steering vector dictionary
, and the parameters are
. The output of each layer is the Lagrange multiplier
, the auxiliary variable
and the space-time amplitude spectrum
. The final output of ADMM-Net is
, and the nonlinear function
given in (26) is the same as (25).
During the data-driven network training, network parameters of ADMM-Net are adaptively tuned. This allows ADMM-Net to obtain a higher convergence performance than that of the ADMM algorithm with the same number of iterations, thus improving the estimation accuracy of the clutter space-time amplitude spectrum.
3.1.2. CNN
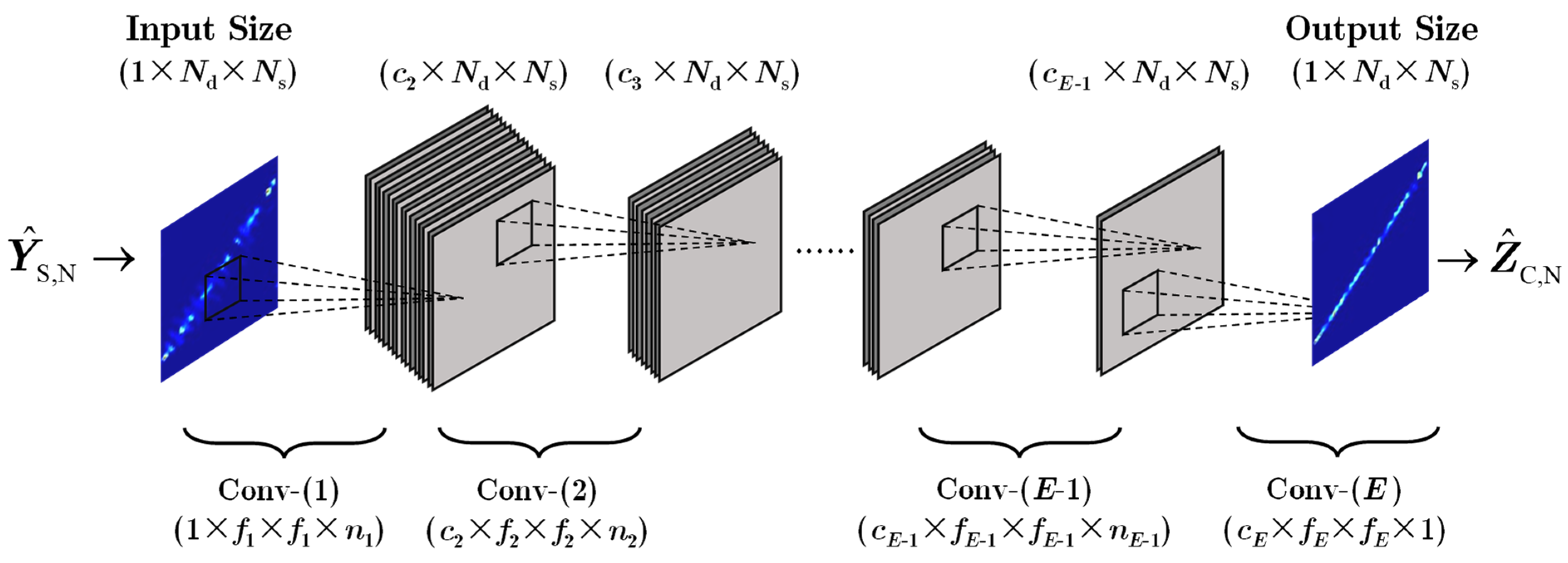
The space-time power spectrum reconstruction network in DU-CNN is a CNN with
two-dimensional convolutional layers, as shown in
Figure 4. The input of the CNN is the normalized clutter space-time power spectrum
obtained by transforming the output
of ADMM-Net, whose dimension is
, into a number of channels as 1 and a length × width as
. The output of the CNN is the normalized high-resolution clutter space-time power spectrum
. Because each convolutional layer uses a zero-padding operation, only the number of channels is changed in the processing procedure, and the length × width keeps constant. Thus, the dimension of
is also
.
The network parameters of CNN are
, where
denotes the convolutional kernel with a dimension of
,
is the number of input channels,
is the length and width of the convolutional kernel,
is the number of convolutional kernels (i.e., the number of output channels), and
is the bias vector with a dimension of
. With ∗ denoting the convolutional operation, the operations of each convolutional layer in
Figure 4 can be summarized as follows.
- (1)
Conv-(1) is used to extract features from the input clutter space-time power spectrum, which adopts the ReLU activation function. The specific operation can be expressed as
- (2)
Conv-(2)~Conv-(
E−1) realize the nonlinear mapping of features, where the ReLU activation function is adopted. The specific operation can be expressed as
- (3)
Conv-(
E) is the image reconstruction layer, where the high-resolution clutter space-time power spectrum is output. The specific operation can be expressed as
3.2. Dataset Construction
Similar to most deep neural networks, DU-CNN adopts the supervised learning method, i.e., it is trained based on the input data and its corresponding labels. In this paper, the following steps are used to construct a sufficient and complete dataset for DU-CNN to guarantee the clutter space-time spectrum estimation performance and the generalization capability of DU-CNN.
Step 1. The parameters including the airplane height , the number of ULA elements , the number of CPI pulses , the array spacing and the wavelength are assumed to be unchanged. The non-side-looking angle, the elevation angle, the clutter ridge slope and the clutter-to-noise ratio (CNR) corresponding to different range cells all obey the uniform random distribution, i.e., , , , and . According to (1), radar space-time echoed signals are generated as the input dataset for DU-CNN, with each range cell containing a total of clutter blocks. The clutter blocks distribute in the azimuth range uniformly and have scattering coefficients that obey a complex Gaussian distribution, whose power is determined by the CNR.
Step 2. The spatial frequency and Doppler frequency are discretized into and grids, respectively. The dictionary of space-time steering vectors is constructed according to (10). Different combinations of iteration parameters are set according to the convergence conditions of the ADMM algorithm. Based on (12), all the space-time echoed signals are processed by ADMM. The combination of , , and with the best estimation performance is obtained as the final parameters of ADMM. The estimated clutter space-time amplitude spectra are thus obtained as the intermediate dataset for DU-CNN. Then, according to the theoretical clutter covariance matrix, the high-resolution clutter space-time power spectra are obtained based on (17), which is used as the output label dataset for DU-CNN.
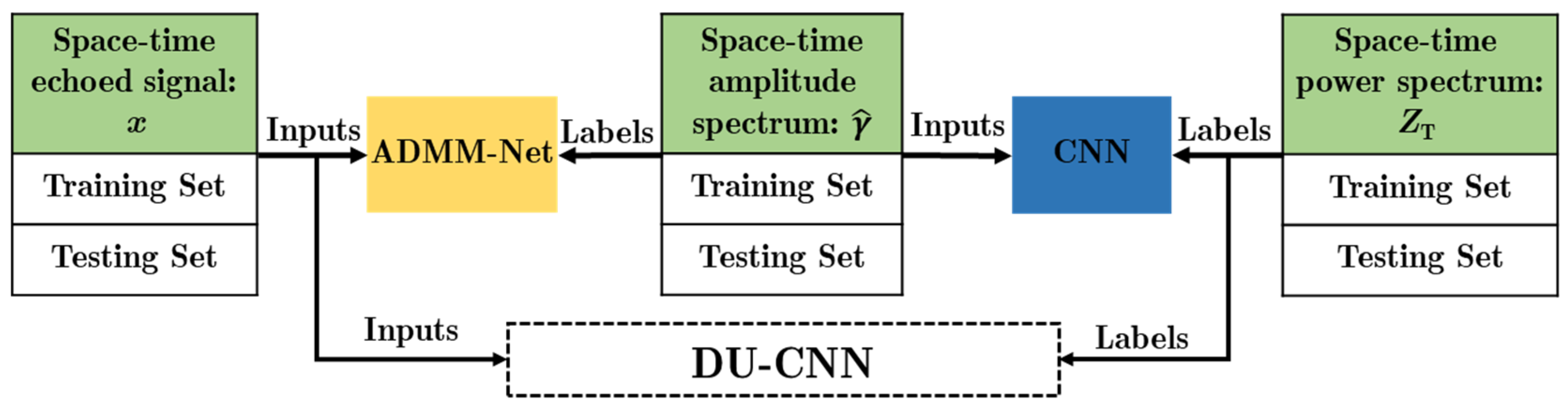
Step 3. Via the previous two steps, the datasets
,
and
are obtained. The input dataset and output label dataset of DU-CNN are set as
, the input dataset and output label dataset of ADMM-Net are set as
, and the input dataset and output label dataset of the CNN are set as
. As shown in
Figure 5, each of these three datasets is divided into a training dataset with the size as
and a testing dataset with the size as
. The training dataset is used to train the network parameters, whereas the testing dataset is not involved in the training procedure but is used to verify the performance of the trained network.
3.3. Training Method
To avoid falling into the local optimum and improving the convergence performance of the network, this paper adopts the method of “pre-training + fine-tuning” to train DU-CNN. First, ADMM-Net and CNN are independently pre-trained based on and , respectively. Then, DU-CNN is trained end-to-end based on , i.e., the network parameters of ADMM-Net and CNN are fine-tuned jointly. The specific steps can be summarized as follows.
Step 1. According to the iteration parameter setting of the ADMM algorithm, the parameters of ADMM-Net are initialized as
. The network loss function is defined as the mean square error (MSE) between the ADMM-Net output and the label data, which can be expressed as
where
denotes the output of the
K-th layer of ADMM-Net with
as the input and
as the parameter. The optimal parameter
of ADMM-Net can be obtained by minimizing the loss function through the back propagation method [
29], expressed as
Step 2. The Glorot method [
30] is used to initialize the network parameters of the CNN. Similarly, the network loss function is defined as the MSE of the CNN output and the label data, expressed as
where
denotes the output of the CNN with
as the input and
as the parameter. Similarly, the optimal parameters of the CNN can be obtained through the back propagation method by solving the following problem:
Step 3. Based on the independent pre-training results of ADMM-Net and CNN, DU-CNN is trained end-to-end to further improve its convergence performance. Here, the parameters of DU-CNN are initialized as
to avoid the local convergence problem that may occur when directly training DU-CNN. The network loss function is defined as
where
denotes the output of DU-CNN with
as the input and
as the parameter. Similarly, the optimal parameters of DU-CNN
can be obtained as follows:
4. Simulation Results
In this section, the performance of the DU-CNN-STAP method is verified via simulations. A comparative analysis with the CNN-STAP method and the SR-STAP method is also performed. Considering the computational complexity, dataset size and memory usage, the parameters shown in
Table 1 are used for simulations to mimic an airborne radar in a clutter environment [
14]. For the SR-STAP algorithm, the iteration parameters of the ADMM algorithm are set as
,
,
and
. For the proposed method, the number of network layers of the CNN in DU-CNN is
, and the convolutional dimensions
are set as (1 × 11 × 11 × 16), (16 × 9 × 9 × 8), (8 × 7 × 7 × 4), (4 × 5 × 5 × 2) and (2 × 3 × 3 × 1). For the CNN-STAP method, the CNN is set as the same as that in the proposed method. In the training process of ADMM-Net, the CNN and DU-CNN, the batch size is set as 128. All network parameters are optimized via the Adam optimizer, and the learning rates for different networks are set as 10
−4, 5 × 10
−3 and 2 × 10
−5, respectively.
4.1. Network Convergence Analysis
In this sub-section, the training convergences of ADMM-Net, the CNN and DU-CNN are analyzed. A comparison with the training convergence of the CNN in the CNN-STAP method [
19] is also provided. The training convergences of ADMM-Net with the number of network layers
as 20, 30 and 40 are given in
Figure 6a. It can be seen that the loss function of ADMM-Net decreases gradually and remains unchanged after about 150 epochs. As the number of network layers increases, the loss of ADMM-Net decreases, and its convergence performance improves. Considering the computing complexity and the convergence performance, the number of network layers of ADMM-Net is set as
in the following simulations.
Figure 6b provides a comparison of the convergences of CNNs between the proposed method and the CNN-STAP method. It can be seen that, under the condition with the same CNN network scale, because the input of the CNN in the proposed method is the high-resolution clutter space-time spectrum obtained by the ADMM algorithm, it has a higher performance than that of the CNN-STAP method with the Fourier-transform-based (i.e., DBF-based) low-resolution clutter space-time spectrum as its input.
Figure 6c shows the convergences of the proposed DU-CNN and the CNNs in the CNN-STAP method, where the number of network layers in CNN-New is 7 and the convolutional dimensions are (1 × 11 × 11 × 16), (16 × 9 × 9 × 12), (12 × 9 × 9 × 10), (10 × 7 × 7 × 8), (8 × 5 × 5 × 4), (4 × 5 × 5 × 2) and (2 × 3 × 3 × 1). It can be seen that (1) DU-CNN has a higher convergence performance than the CNN in the CNN-STAP method with the same parameters, and (2) increasing the network scale can improve the convergence performance of the CNN in the CNN-STAP method, obtaining the result close to DU-CNN, but its computing complexity is increased.
In general, as the network layer number and scale become larger, the nonlinear transform capability of DU-CNN becomes stronger, but the computing burden is increased. In practice, to determine the appropriate network layer number and scale of DU-CNN under different conditions, the following approach can be used: (1) conduct off-line training of DU-CNN with different network layer numbers and scales (make sure the network training converges), (2) obtain the condition for which the increase in the layer number and scale does not decrease the training loss significantly and (3) considering the balance of the clutter suppression performance and computational complexity, choose the network layer number and scale under the above-mentioned condition for DU-CNN.
4.2. Clutter Suppression Performance
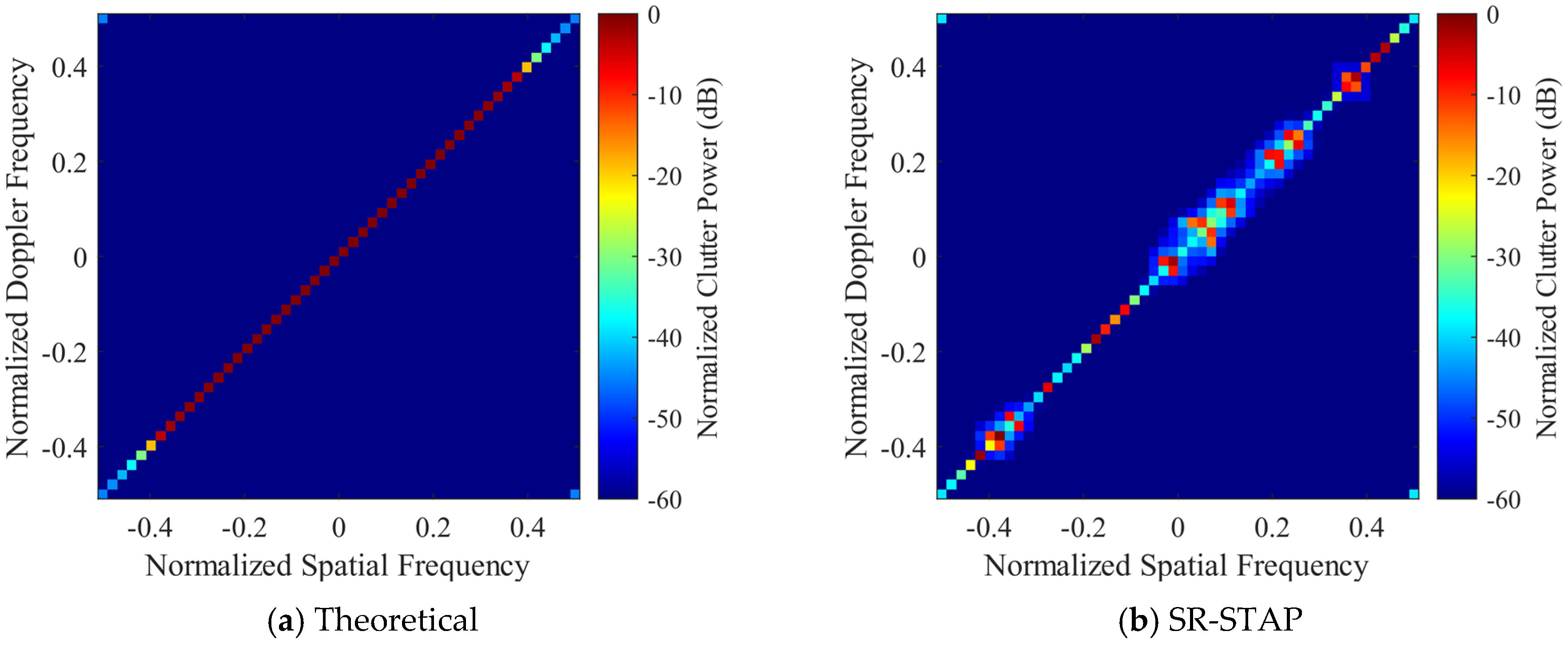
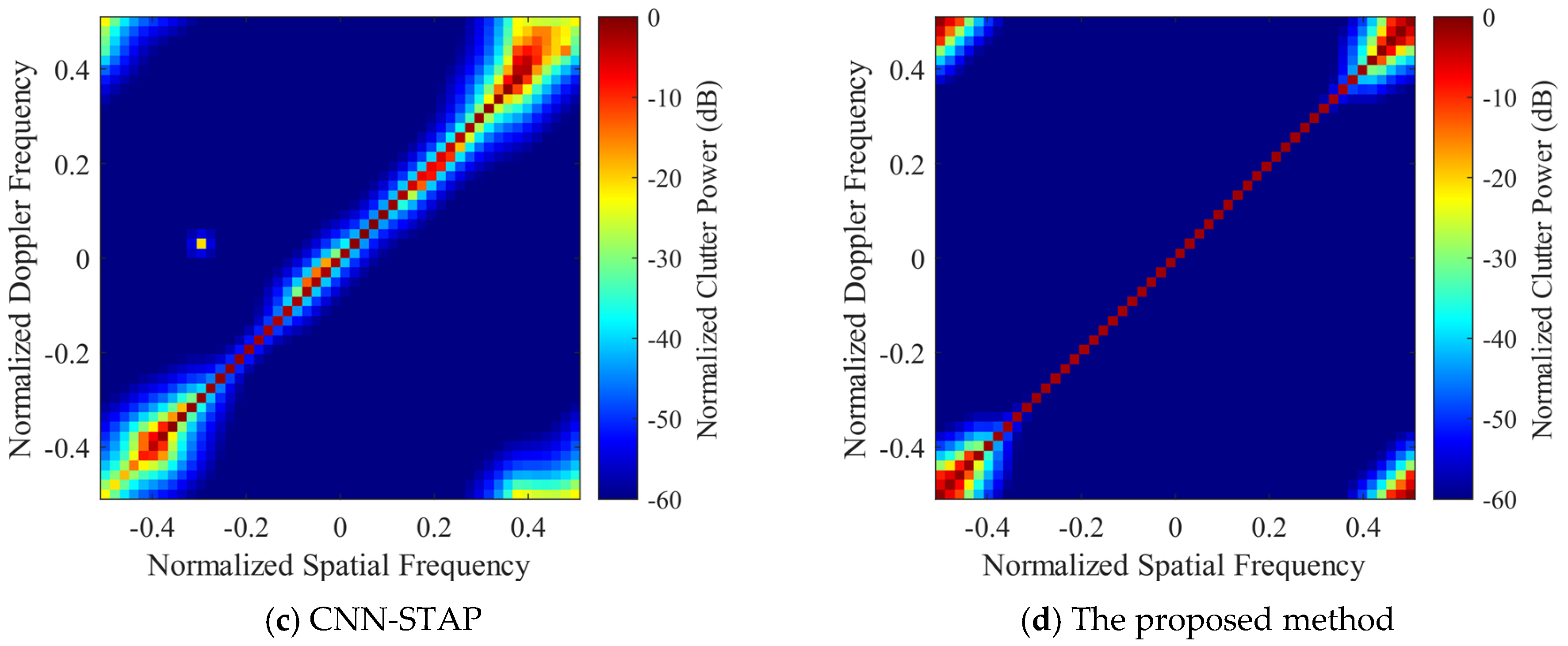
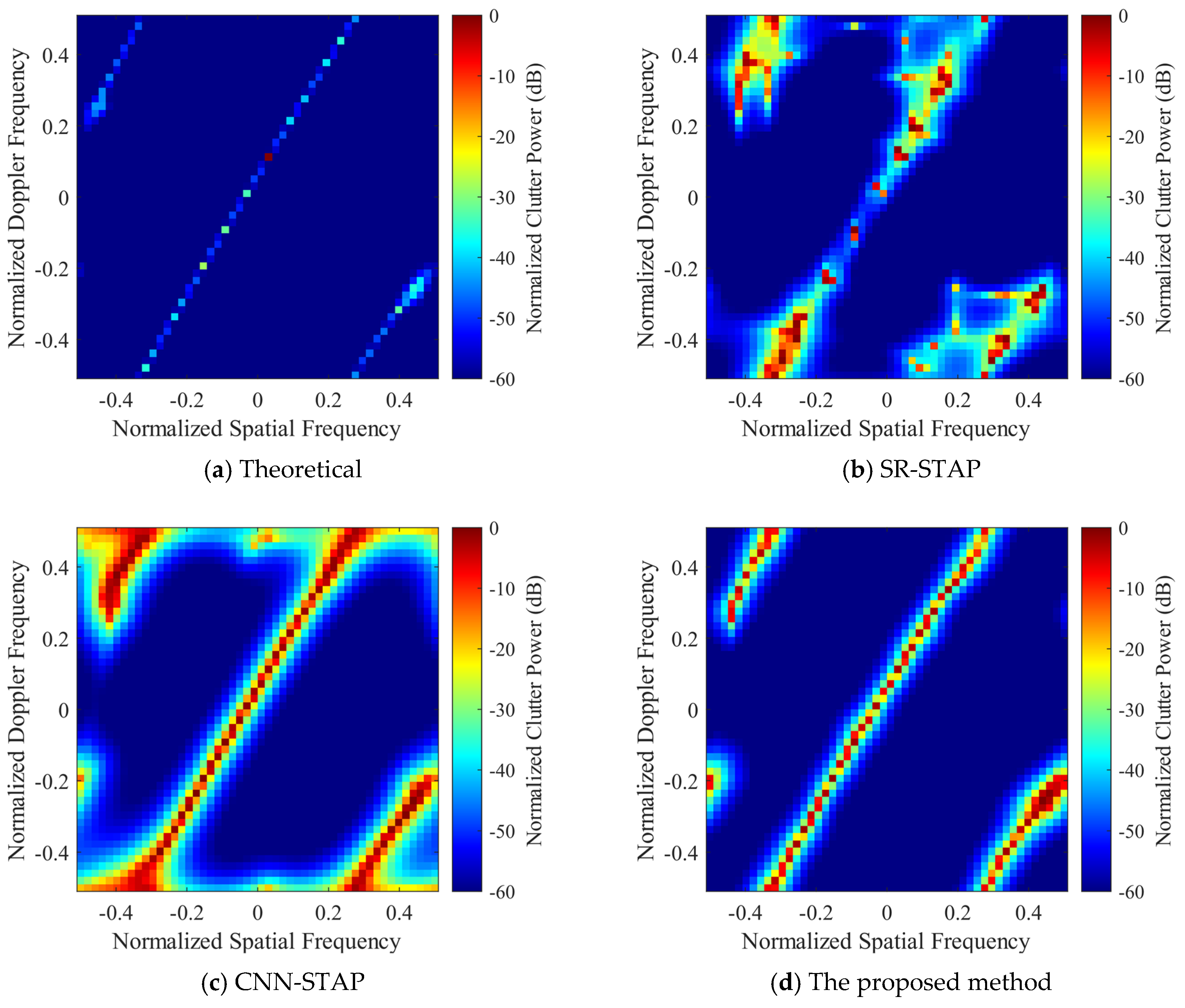
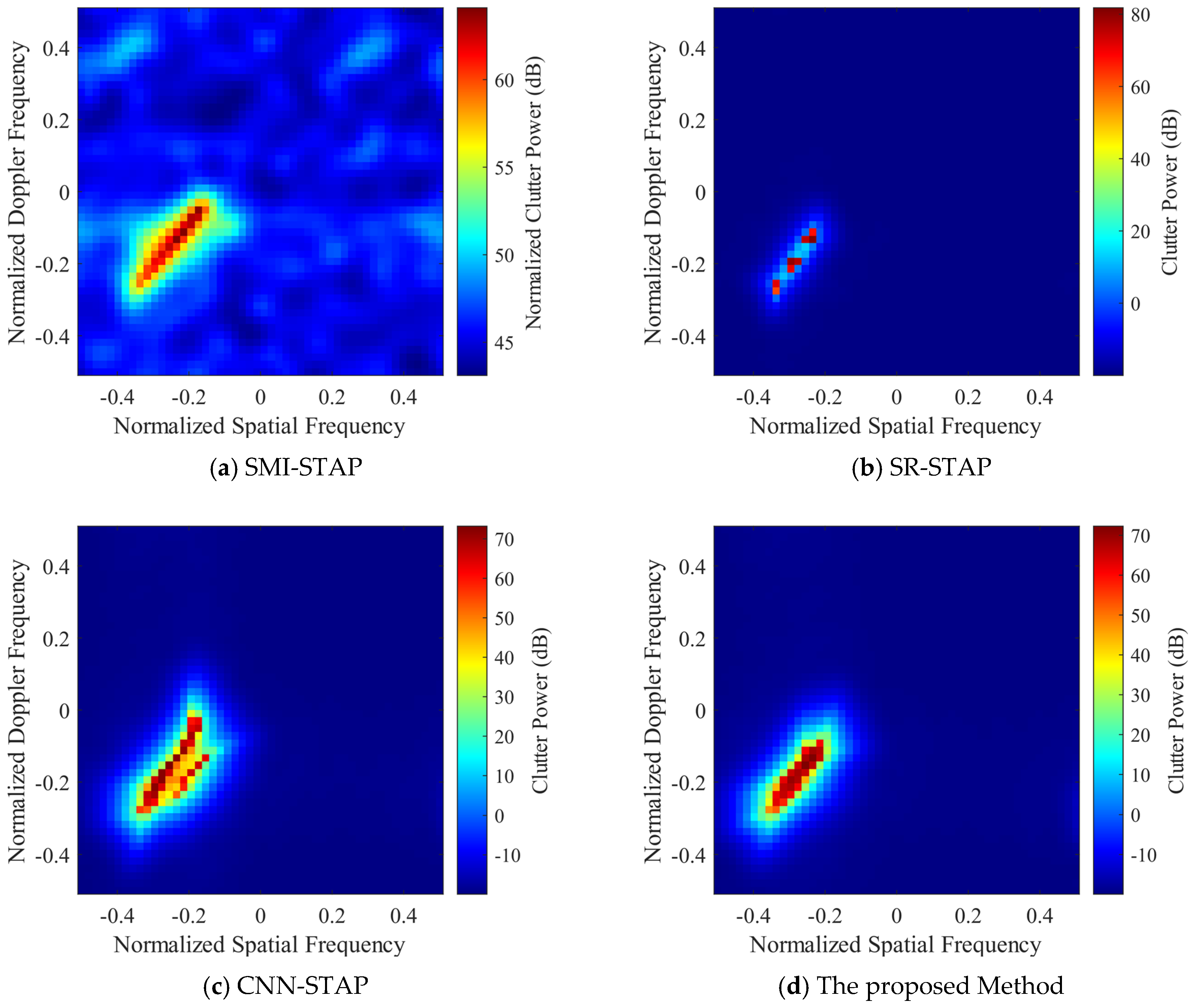
In this sub-section, the clutter suppression performance of DU-CNN-STAP is verified and compared with the CNN-STAP and SR-STAP methods. For convenience, the SR-STAP method still adopts the ADMM algorithm; hence, it is also named ADMM-SATP. The clutter space-time spectra estimated by different methods are shown in
Figure 7 and
Figure 8, where
Figure 7 corresponds to the side-looking case with the simulation parameters as
,
,
and
and
Figure 8 corresponds to the non-side-looking case with the simulation parameters as
,
,
and
.
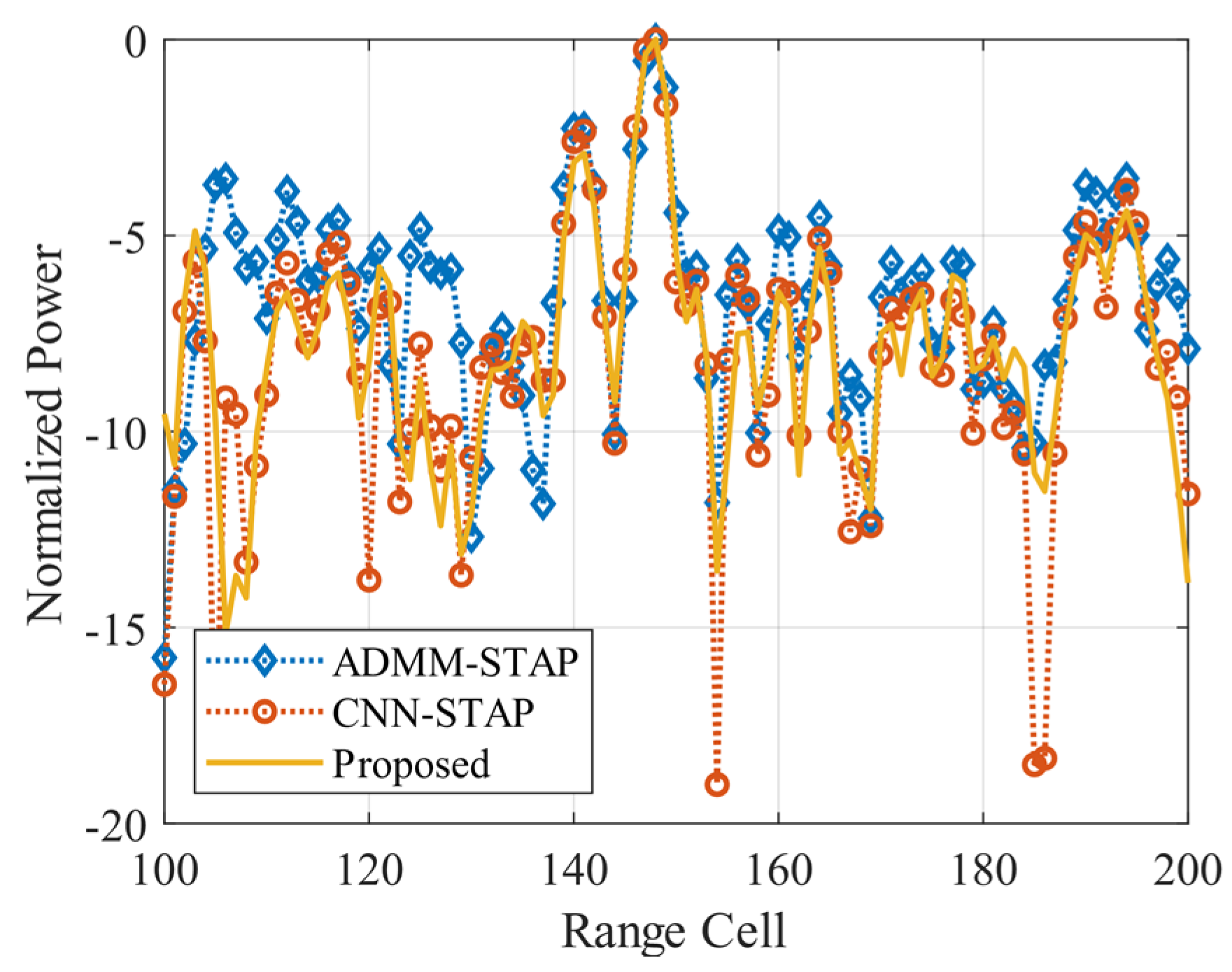
It can be seen that the SR-STAP method can obtain a high clutter space-time spectrum estimation performance under the side-looking condition; however, an uneven clutter distribution problem occurs. As the clutter sparsity becomes worse under the non-side-looking case, there are some interferences deviating from the clutter ridge, and the performance of the SR-STAP method deteriorates severely. Under the two conditions, the CNN-STAP method can reconstruct the clutter space-time spectrum effectively. The clutter distribution is continuous, and there is less interference deviating from the clutter ridge. However, this method broadens the clutter ridge. The proposed DU-CNN-STAP method can obtain a higher performance compared to those of the CNN-STAP and SR-STAP methods, with the obtained clutter space-time spectrum estimation results being close to the theoretical ones.
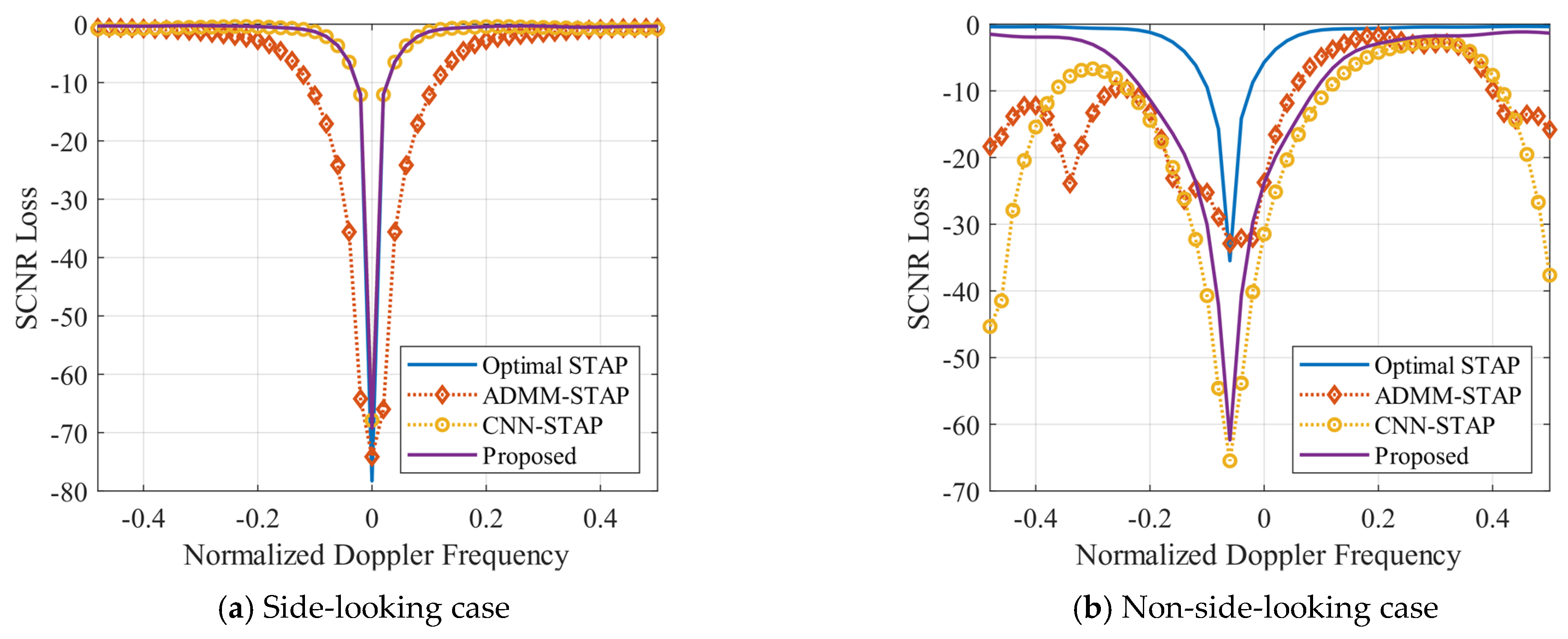
Based on the clutter space-time spectra shown in
Figure 7 and
Figure 8, the clutter suppression performance of different methods is shown in
Figure 9 by using the SCNR loss as the indicator. The spatial frequency of the target is set to 0, and its normalized Doppler frequency varies linearly in the range of
. It can be seen that the SR-STAP and CNN-STAP methods can generate a deep null close to the zero frequency under the side-looking condition, providing good suppression of the clutter. However, unevenly distributed clutter, interferences deviating from the clutter ridge and the broadened clutter ridge make the null formed by the SR-STAP method wider, reducing its slow target detection performance. In contrast, the DU-CNN-STAP method proposed in this paper can benefit from a higher clutter spectrum estimation performance; thus, the width and depth of the null are well controlled to obtain a high clutter suppression performance.
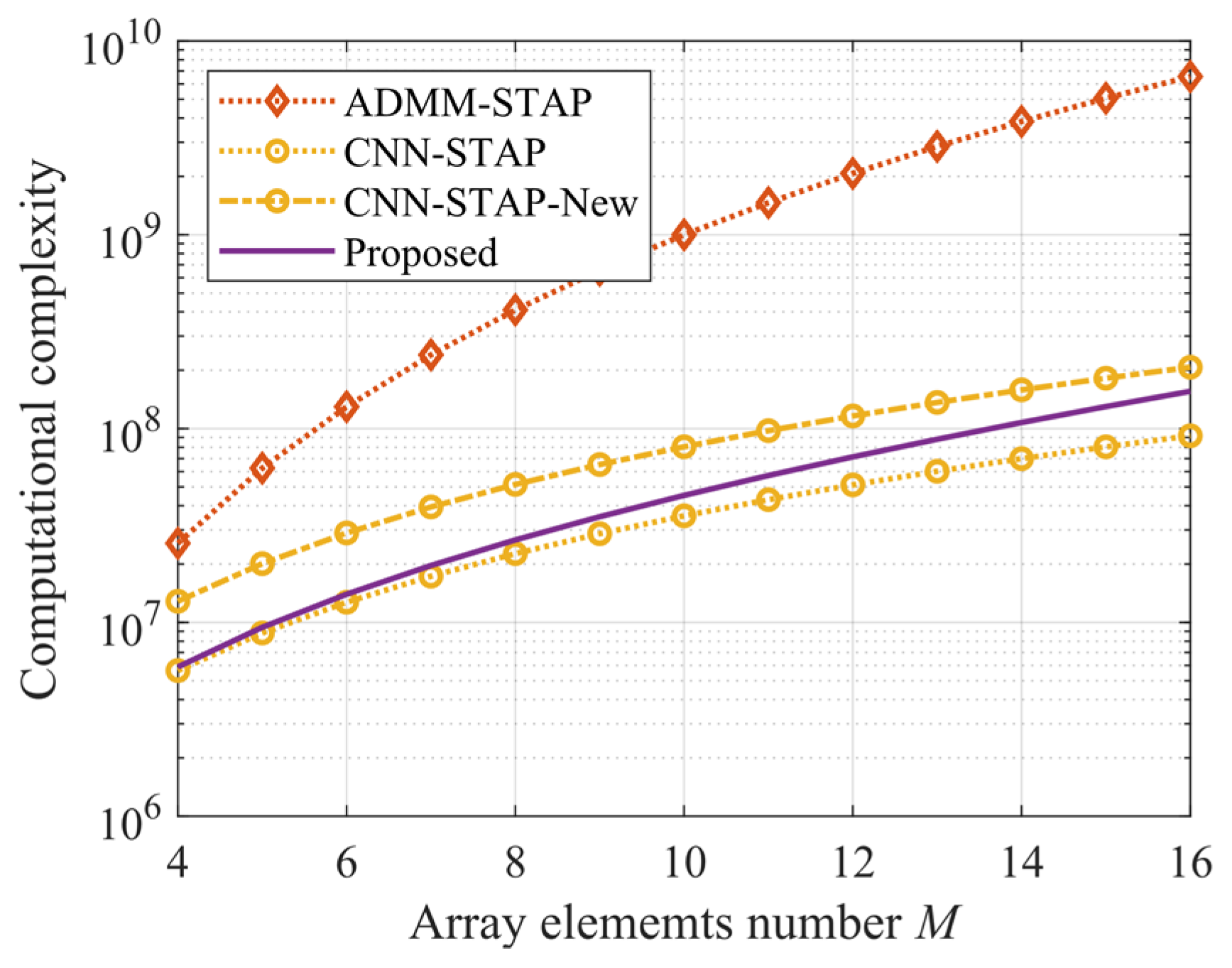
4.3. Computational Complexity Analysis
In this sub-section, the computational complexity of the proposed method is analyzed, and a comparison with the SR-STAP and CNN-STAP methods is also provided. It should be emphasized that, because the method of offline training and online application can be used, the computational complexity analysis in this paper does not consider the computational complexity required for network training. Using the number of multiplications as the indicator, the computational complexity of the Fourier-transform-based spectrum estimation method in (16), the ADMM algorithm in (25) and the CNN method in (27–29) are shown in
Table 2. It should be noted that the trained ADMM-Net has the same operations as those of the ADMM algorithm. Thus, under the same iteration number (network layer), the computational complexities of ADMM-Net and ADMM are the same. According to
Table 2, the computational complexities of the proposed method, the SR-STAP method and the CNN-STAP method for clutter space-time spectrum estimation are
,
and
, respectively. The resulting computational complexities of different methods under the condition of
are shown in
Figure 10, where CNN-STAP-New corresponds to CNN-New in
Figure 6c, whose network scale is increased to improve the performance of CNN-STAP. It can be seen that the computational complexities of the proposed method and the CNN-STAP method are much lower than that of the SR-STAP (i.e., ADMM-STAP) method. As the dimensionality of the estimation problem becomes higher, the advantage becomes more obvious. Under the condition that the number of array elements is larger, the computational complexity of the proposed method is higher than that of the CNN-STAP method. However, to obtain a performance similar to that of the proposed method, the computational complexity of the CNN-STAP method increases.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}