
Text3D: 3D Convolutional Neural Networks for Text Classification


Abstract
:1. Introduction
- We propose a three-dimensional convolution network (Text3D) which uses word order, word embedding and hierarchy information of BERT encoder layers as three dimension features.
- We utilize a well-designed 3D convolution mechanism and multiple filters to capture text representations structured in three dimensions produced by pretrained language model BERT.
- We conduct extensive experiments on datasets of different scales and types. The results show that our proposed model produces significant improvements on baseline models. Furthermore, we conduct additional experiments to confirm that hierarchy features of different BERT layers encode different types of word knowledge.
2. Our Approach
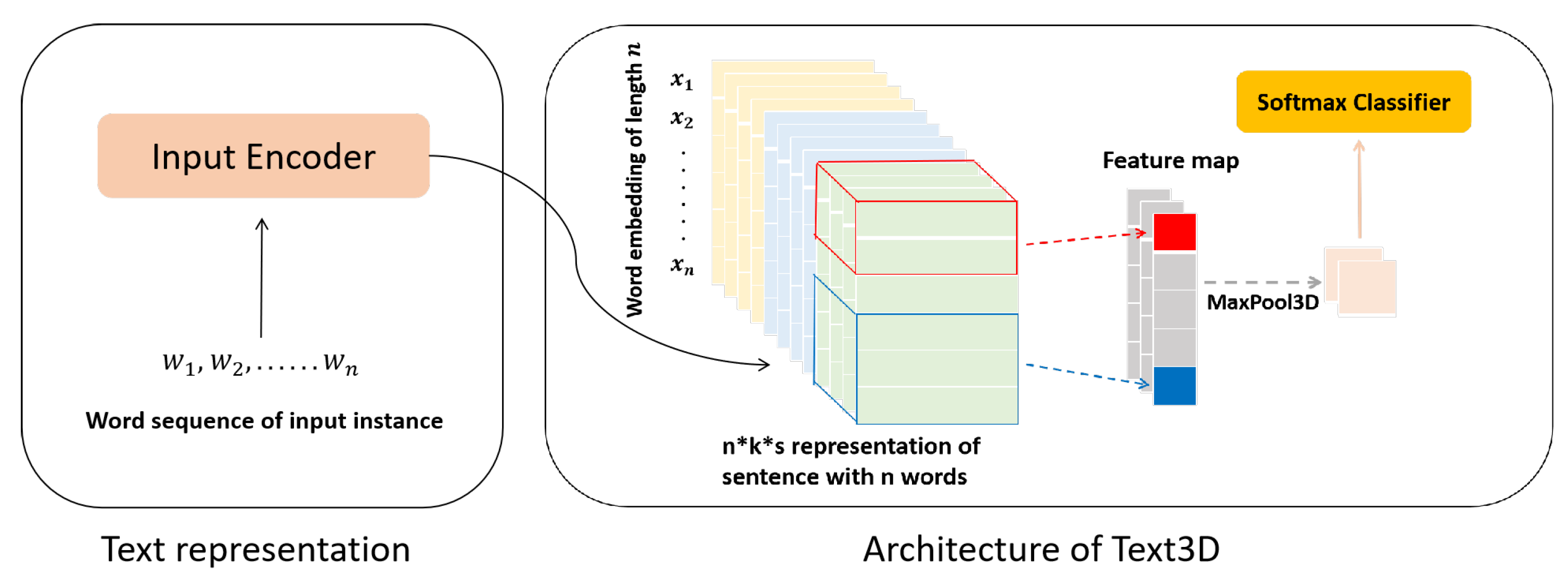
- Text representation within three dimensions, including word order, word embedding and hierarchy information of BERT.
- Well-designed 3D convolution mechanism and filters to extract features of three dimensions from text representation.
2.1. Text Representation
2.2. Model Architecture
3. Experiments
3.1. Datasets and Baselines
3.2. Experiment Settings
3.3. Test Performance
4. Discussion
4.1. Different Hierarchy of BERT
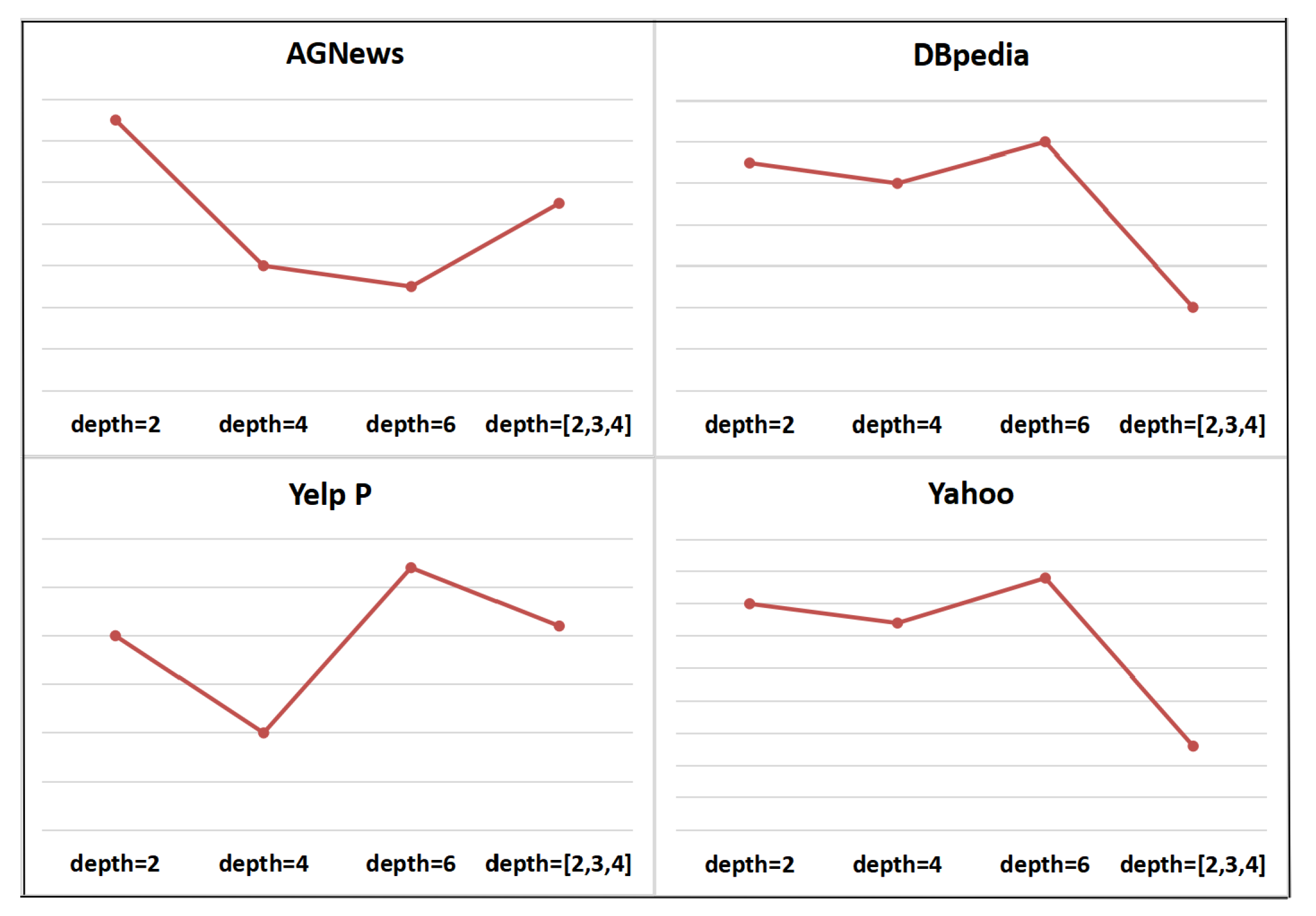
4.2. Depth of Filter
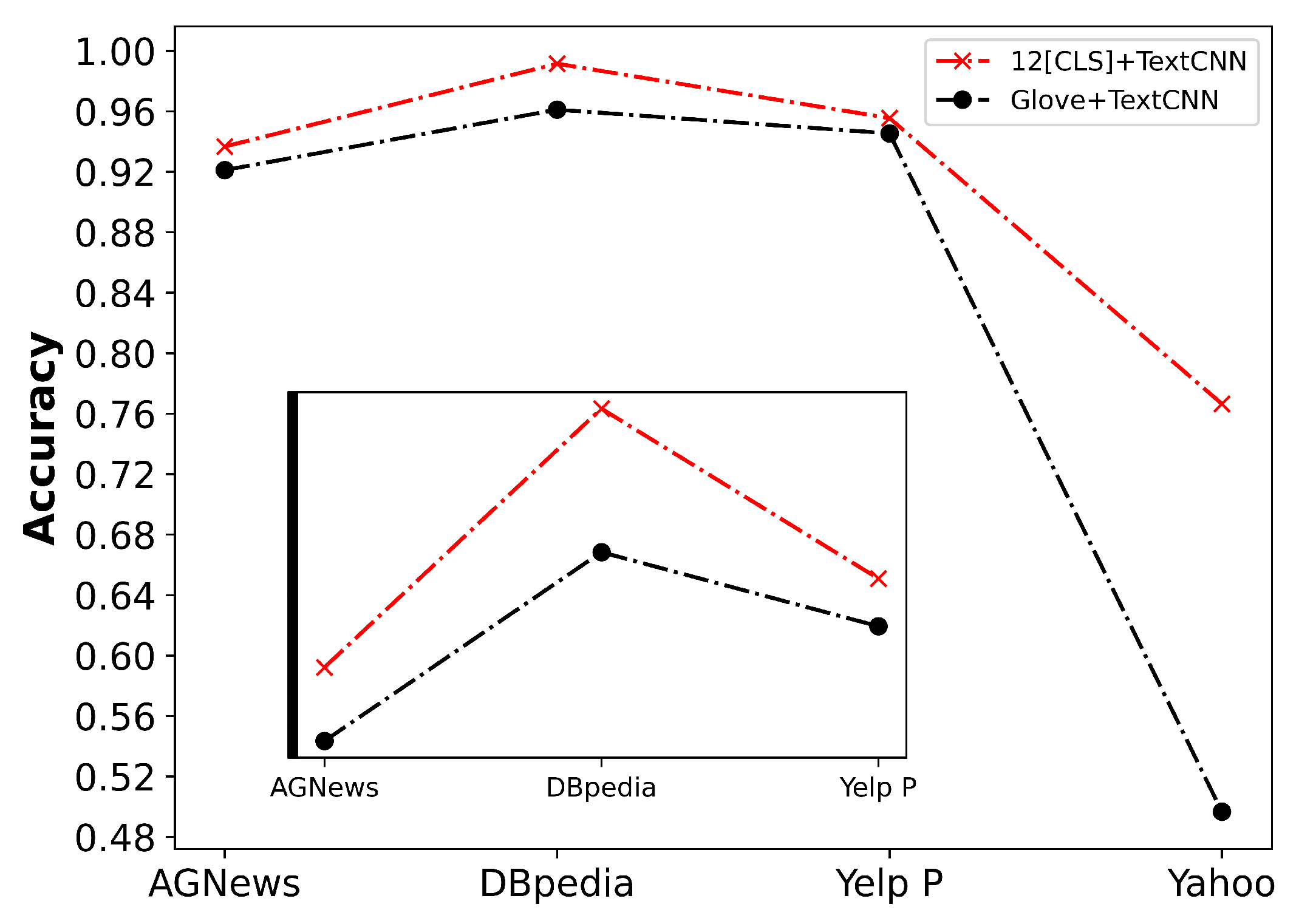
4.3. Ablation Study
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, S.; Manning, C. Baselines and bigrams: Simple, good sentiment and topic classification. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, Jeju Island, Republic of Korea, 8 July 2012; pp. 90–94. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25 October 2014; pp. 1746–1751. [Google Scholar]
- Johnson, R.; Zhang, T. Effective use of word order for text categorization with convolutional neural networks. In Proceedings of the North American Chapter of the Association for Computational Linguistics Human Language Technologies, Denver, CO, USA, 31 May 2015. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. In Proceedings of the Annual Conference on Neural Information Processing Systems 28, Montreal, QC, Canada, 7 December 2015. [Google Scholar]
- Conneau, A.; Schwenk, H.; Barrault, L.; LeCun, Y. Very deep convolutional networks for natural language processing. arXiv 2016, arXiv:1606.01781v1. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Document modeling with gated recurrent neural network for sentiment classification. In Proceedings of the Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17 September 2015. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the North American Chapter of the Association for Computational Linguistics Human Language Technologies, San Diego, CA, USA, 12 June 2016. [Google Scholar]
- Zhang, Y.; Wallace, B. A sensitivity analysis of (and practitioners’ guide to) convolutional neural networks for sentence classification. In Proceedings of the 8th International Joint Conference on Natural Language Processing, Taipei, Taiwan, 27 November 2016; pp. 253–263. [Google Scholar]
- Johnson, R.; Zhang, T. Deep Pyramid Convolutional Neural Networks for Text Categorization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:1512.00567. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7 December 2015; pp. 4489–4497. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2 June 2019; pp. 4171–4186. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. In Proceedings of the 2019 Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8 December 2019; pp. 5753–5763. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4 December 2017; pp. 6000–6010. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 1 November 2018; pp. 353–355. [Google Scholar]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to fine-tune bert for text classification? In Proceedings of the 18th China National Conference (CCL 2019), Kunming, China, 18 October 2019; pp. 194–206. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A lite BERT for self-supervised learning of language representations. In Proceedings of the International Conference on Learning Representations, Online, 26 April 2020. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Zhao, T. SMART: Robust and efficient finetuning for pre-trained natural language models through principled regularized optimization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 6 July 2020; pp. 2177–2190. [Google Scholar]
- Jawahar, G.; Sagot, B.; Seddah, D. What does BERT learn about the structure of language? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July 2019; pp. 3651–3657. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8 December 2014; pp. 568–576. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural Language Processing (Almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 26 October 2014; pp. 1532–1543. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01795v3. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Type | Classes | Train | Test |
|---|---|---|---|---|
| AGNews | News Topic | 4 | 120 K | 7.6 K |
| DBpedia | Wikipedia Topic | 14 | 560 K | 70 K |
| Yelp Polarity | Sentiment | 2 | 560 K | 38 K |
| Yahoo | QA Topic | 10 | 1.4 M | 60 K |
| AGNews | DBpedia | Yelp Polarity | Yahoo | |
|---|---|---|---|---|
| TextCNN | 0.8808 | 0.9610 | 0.9453 | 0.4966 |
| Word-level CNN | 0.9145 | 0.9858 | 0.9540 | 0.7116 |
| Char-level CNN | 0.9015 | 0.9834 | 0.9475 | 0.7120 |
| BERT | 0.9329 | 0.9806 | 0.9453 | 0.7635 |
| FastText [30] | 0.9250 | 0.9860 | 0.9570 | 0.7230 |
| DPCNN [9] | 0.9313 | 0.9912 | 0.9736 | 0.7610 |
| Text3D | 0.9380 | 0.9919 | 0.9580 | 0.7695 |
| AGNews | DBpedia | Yelp Polarity | Yahoo | |
|---|---|---|---|---|
| 1–4 | 0.9309 | 0.9902 | 0.9132 | 0.7585 |
| 5–8 | 0.9568 | 0.9918 | 0.9524 | 0.7641 |
| 9–12 | 0.9410 | 0.9920 | 0.9599 | 0.7687 |
| All 12 | 0.9380 | 0.9919 | 0.9580 | 0.7695 |
| AGNews | DBpedia | Yelp Polarity | Yahoo | |
|---|---|---|---|---|
| Depth = 2 | 0.9379 | 0.9919 | 0.9580 | 0.7695 |
| Depth = 4 | 0.9372 | 0.9918 | 0.9570 | 0.7692 |
| Depth = 6 | 0.9371 | 0.9920 | 0.9587 | 0.7699 |
| Depth = [3, 4, 5] | 0.9375 | 0.9912 | 0.9581 | 0.7673 |
| AGNews | DBpedia | Yelp Polarity | Yahoo | |
|---|---|---|---|---|
| Text3D | 0.9380 | 0.9919 | 0.9580 | 0.7695 |
| 12[CLS]+TextCNN | 0.9366 | 0.9914 | 0.9554 | 0.7664 |
| Glove+TextCNN | 0.9210 | 0.9610 | 0.9453 | 0.4966 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Li, J.; Zhang, Y. Text3D: 3D Convolutional Neural Networks for Text Classification. Electronics 2023, 12, 3087. https://doi.org/10.3390/electronics12143087
Wang J, Li J, Zhang Y. Text3D: 3D Convolutional Neural Networks for Text Classification. Electronics. 2023; 12(14):3087. https://doi.org/10.3390/electronics12143087
Chicago/Turabian StyleWang, Jinrui, Jie Li, and Yirui Zhang. 2023. "Text3D: 3D Convolutional Neural Networks for Text Classification" Electronics 12, no. 14: 3087. https://doi.org/10.3390/electronics12143087
APA StyleWang, J., Li, J., & Zhang, Y. (2023). Text3D: 3D Convolutional Neural Networks for Text Classification. Electronics, 12(14), 3087. https://doi.org/10.3390/electronics12143087