

A New Data-Balancing Approach Based on Generative Adversarial Network for Network Intrusion Detection System


Abstract
1. Introduction
2. Related Works
3. UGR’16 Dataset
- Netflow probes are set up on the outgoing network interfaces of two redundant border routers, BR1 and BR2, which enable access to the Internet. This configuration allows for the collection of all incoming and outgoing connections.
- The ISP has two different subnetworks. One is termed the core network, where the services that are not protected by a firewall are located. The second is the inner network, where firewall services are provided to the clients.
- At the highest level, there is a network of attacker machines consisting of five units, designated as A1–A5.
- Within the core network, five victim machines specifically for dataset collection purposes are set up. These machines, named V11–V15, are located alongside genuine clients in an existing network referred to as victim network V1.
- In relation to the inner network, a collective of 15 additional victim machines is positioned across three separate existing networks, with each network consisting of 5 machines. These networks are designated as victim network V2 (machines V21–V25), victim network V3 (machines V31–V35), and victim network V4 (machines V41–V45).
- Planned scheduling: every attack within the batch is executed at a predetermined and known time, which is determined by an offset from the initial batch time, denoted as t0.
- Random scheduling: the initial time for the execution of each of the attacks is randomly selected between t0 + 00h00m and t0 + 01h50m, thus restricting the total duration of the batch to a maximum of 2h.
4. Proposed Model
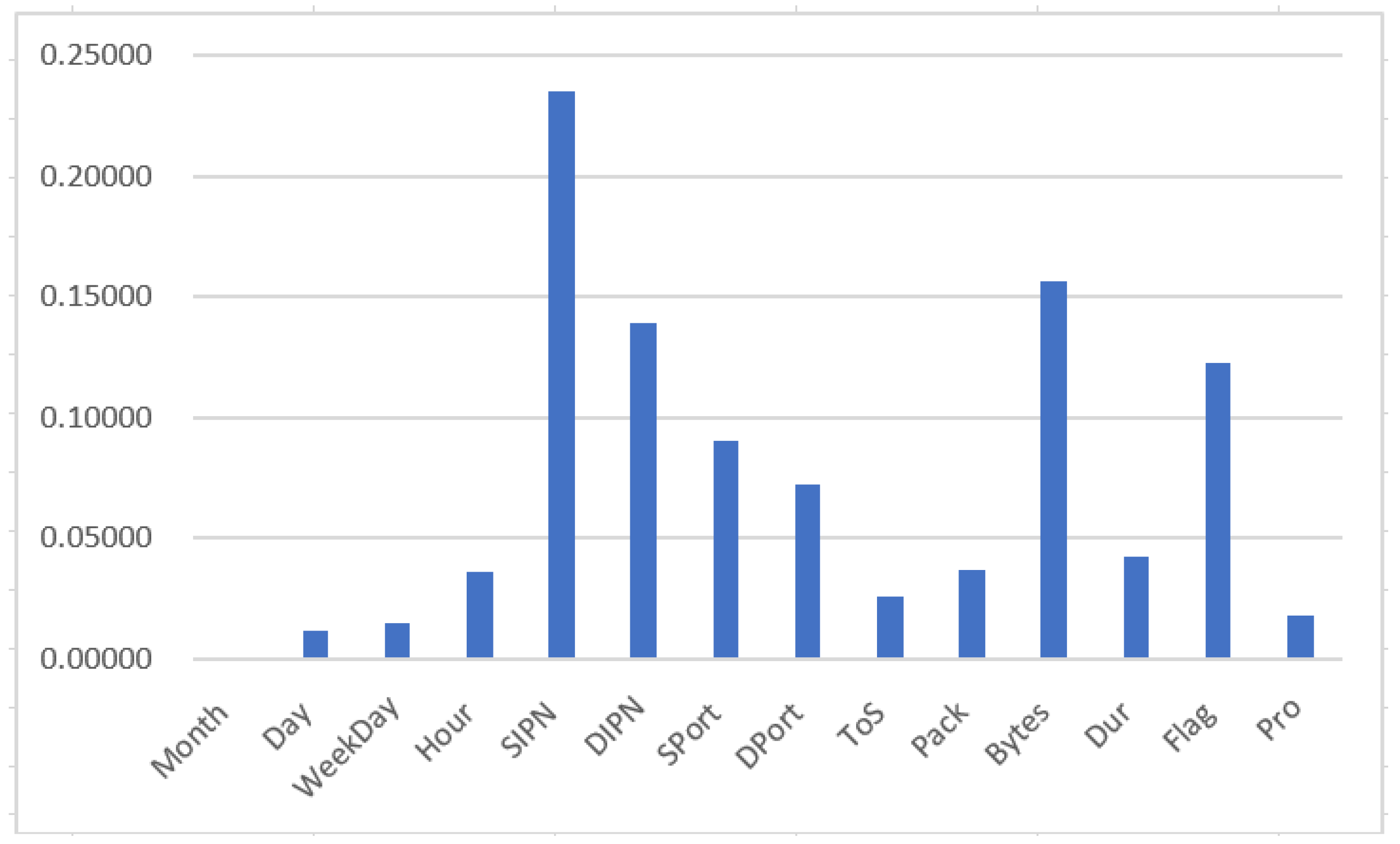
4.1. Data Preparation
- Stratified sampling: The subset selection process employed stratified sampling techniques to ensure proportional representation of each type of attack. This approach helped maintain a balanced distribution of attacks in the subset.
- Class balancing: Additional steps were taken to balance the representation of different attack types in the subset. This might include oversampling the minority classes or undersampling the majority classes to mitigate the imbalanced distribution.
- Randomization: To minimize any potential bias, randomization techniques were applied during the subset selection process. This ensured that the selection was not influenced by any specific order or predetermined biases.
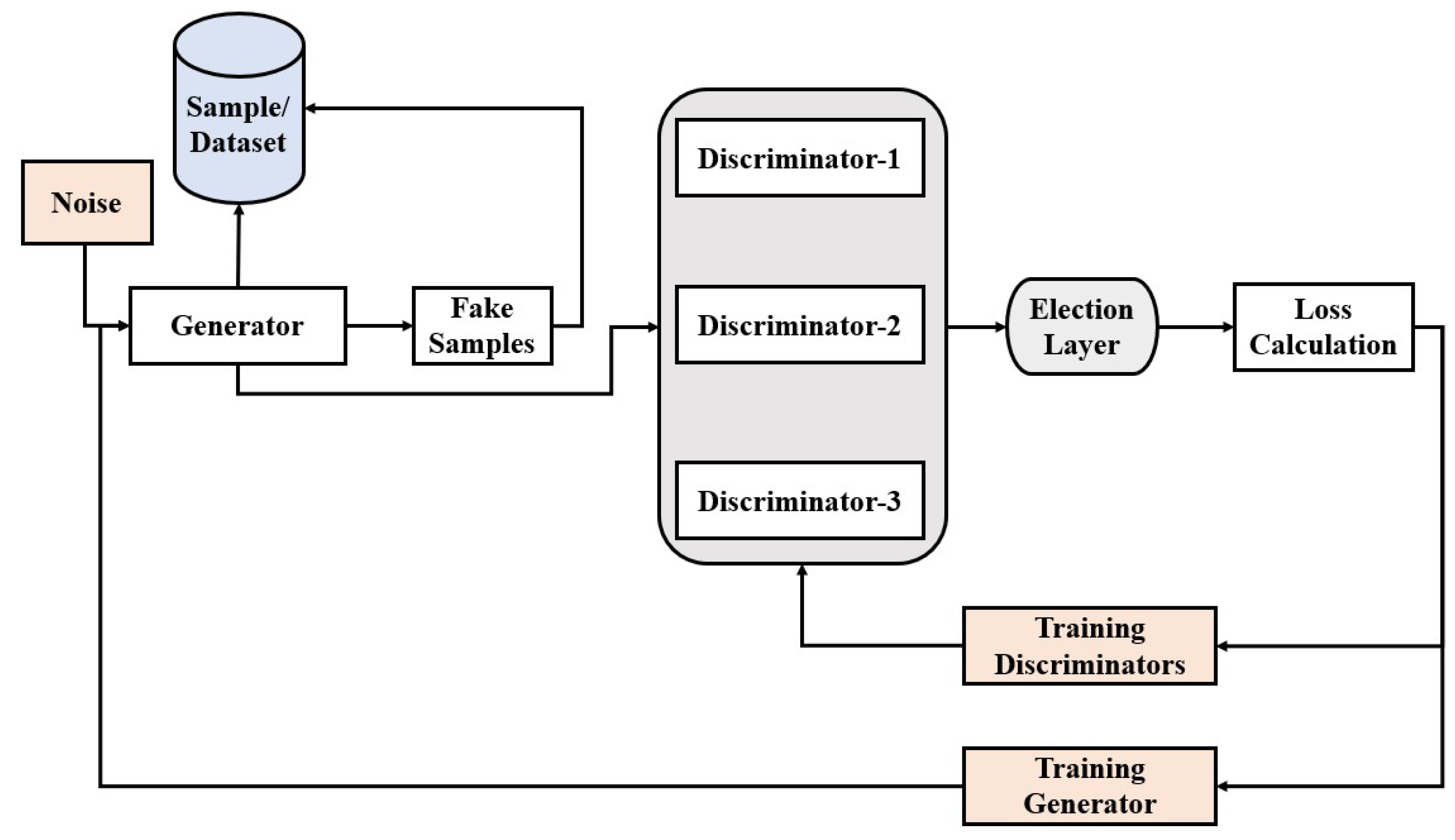
4.2. Setup of Proposed Model
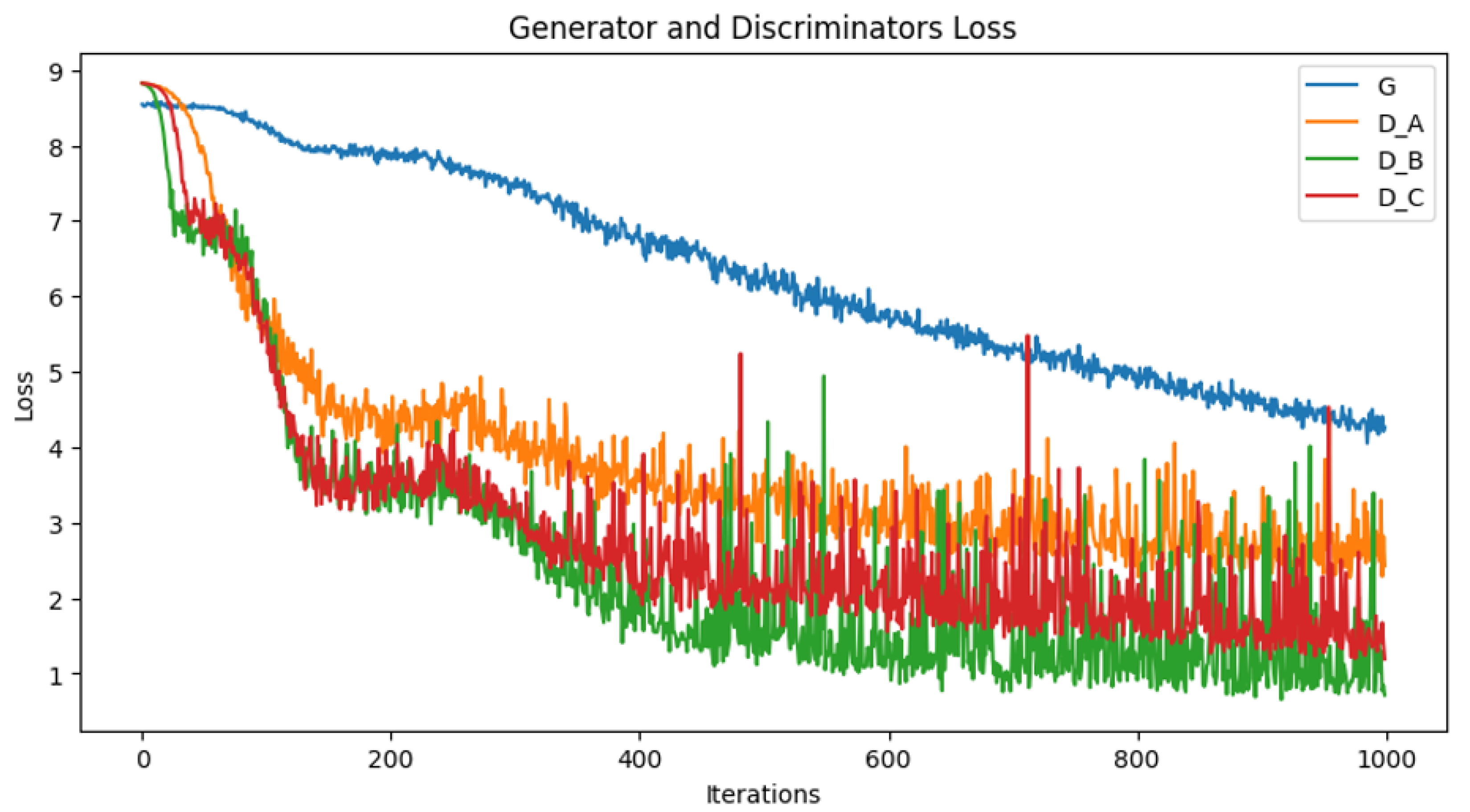
4.3. Training Phase
5. Experimental Results
5.1. Experimental Setup
5.2. Performance Metrics
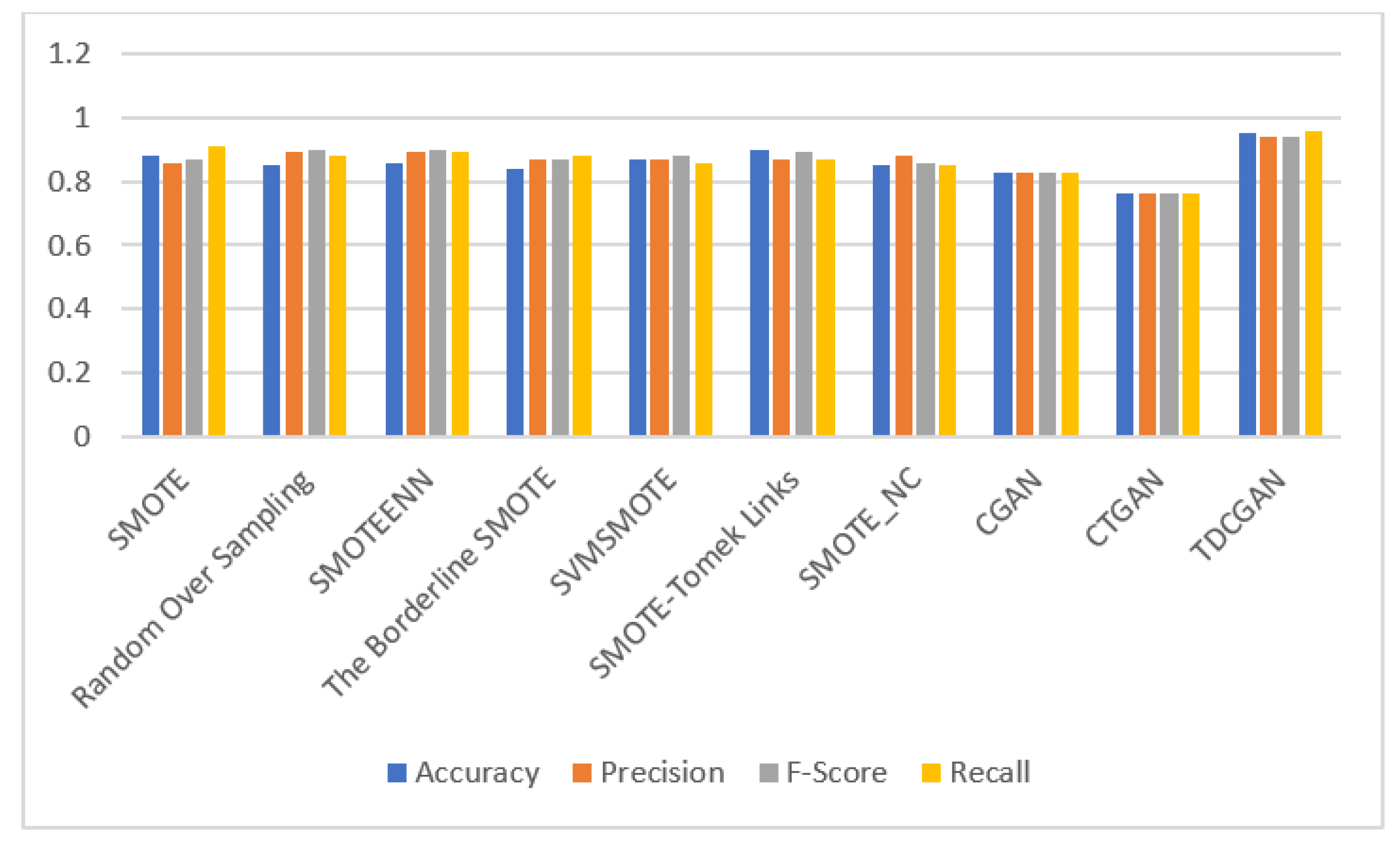
5.3. Experimental Results and Analysis
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Surakhi, O.M.; García, A.M.; Jamoos, M.; Alkhanafseh, M.Y. A Comprehensive Survey for Machine Learning and Deep Learning Applications for Detecting Intrusion Detection. In Proceedings of the 2021 22nd International Arab Conference on Information Technology (ACIT), Muscat, Oman, 21–23 December 2021; pp. 1–13. [Google Scholar]
- AlKhanafseh, M.Y.; Surakhi, O.M. VANET Intrusion Investigation Based Forensics Technology: A New Framework. In Proceedings of the 2022 International Conference on Emerging Trends in Computing and Engineering Applications (ETCEA), Karak, Jordan, 23–24 November 2022; pp. 1–7. [Google Scholar]
- Susilo, B.; Sari, R.F. Intrusion detection in IoT networks using deep learning algorithm. Information 2020, 11, 279. [Google Scholar] [CrossRef]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In Proceedings of the Information Processing in Medical Imaging: 25th International Conference, IPMI 2017, Boone, NC, USA, 25–30 June 2017; Springer: Cham, Switzerland, 2017; pp. 146–157. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets Advances in neural information processing systems. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Su, H.; Shen, X.; Hu, P.; Li, W.; Chen, Y. Dialogue generation with gan. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Maciá-Fernández, G.; Camacho, J.; Magán-Carrión, R.; García-Teodoro, P.; Therón, R. UGR’16: A new dataset for the evaluation of cyclostationarity-based network IDSs. Comput. Secur. 2018, 73, 411–424. [Google Scholar] [CrossRef]
- Abdulrahman, A.A.; Ibrahem, M.K. Toward constructing a balanced intrusion detection dataset based on CICIDS2017. Samarra J. Pure Appl. Sci. 2020, 2, 132–142. [Google Scholar]
- Lee, J.; Park, K. GAN-based imbalanced data intrusion detection system. Pers. Ubiquitous Comput. 2021, 25, 121–128. [Google Scholar] [CrossRef]
- Hajisalem, V.; Babaie, S. A hybrid intrusion detection system based on ABC-AFS algorithm for misuse and anomaly detection. Comput. Netw. 2018, 136, 37–50. [Google Scholar] [CrossRef]
- Kabir, E.; Hu, J.; Wang, H.; Zhuo, G. A novel statistical technique for intrusion detection systems. Future Gener. Comput. Syst. 2018, 79, 303–318. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. ICISSp 2018, 1, 108–116. [Google Scholar]
- Kumar, V.; Sinha, D.; Das, A.K.; Pandey, S.C.; Goswami, R.T. An integrated rule based intrusion detection system: Analysis on UNSW-NB15 data set and the real time online dataset. Clust. Comput. 2020, 23, 1397–1418. [Google Scholar] [CrossRef]
- Seo, E.; Song, H.M.; Kim, H.K. GIDS: GAN based intrusion detection system for in-vehicle network. In Proceedings of the 2018 16th Annual Conference on Privacy, Security and Trust (PST), Belfast, Ireland, 28–30 August 2018; pp. 1–6. [Google Scholar]
- Cao, B.; Li, C.; Song, Y.; Qin, Y.; Chen, C. Network Intrusion Detection Model Based on CNN and GRU. Appl. Sci. 2022, 12, 4184. [Google Scholar] [CrossRef]
- Fan, J.; Xu, J.; Ammar, M.H.; Moon, S.B. Prefix-preserving IP address anonymization: Measurement-based security evaluation and a new cryptography-based scheme. Comput. Netw. 2004, 46, 253–272. [Google Scholar] [CrossRef]
- Haag, P. NFDUMP-NetFlow Processing Tools. 2011. Available online: http://nfdump.sourceforge.net (accessed on 16 June 2023).
- Ndichu, S.; Ban, T.; Takahashi, T.; Inoue, D. AI-Assisted Security Alert Data Analysis with Imbalanced Learning Methods. Appl. Sci. 2023, 13, 1977. [Google Scholar] [CrossRef]
- Wang, Z.; She, Q.; Ward, T.E. Generative adversarial networks in computer vision: A survey and taxonomy. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Jiang, W.; Hong, Y.; Zhou, B.; He, X.; Cheng, C. A GAN-based anomaly detection approach for imbalanced industrial time series. IEEE Access 2019, 7, 143608–143619. [Google Scholar] [CrossRef]
- Yang, Y.; Nan, F.; Yang, P.; Meng, Q.; Xie, Y.; Zhang, D.; Muhammad, K. GAN-based semi-supervised learning approach for clinical decision support in health-IoT platform. IEEE Access 2019, 7, 8048–8057. [Google Scholar] [CrossRef]
- Wang, X.; Guo, H.; Hu, S.; Chang, M.C.; Lyu, S. Gan-generated faces detection: A survey and new perspectives. arXiv 2022, arXiv:2202.07145. [Google Scholar]
- Xia, X.; Pan, X.; Li, N.; He, X.; Ma, L.; Zhang, X.; Ding, N. GAN-based anomaly detection: A review. Neurocomputing 2022, 493, 497–535. [Google Scholar] [CrossRef]
- Durgadevi, M. Generative Adversarial Network (GAN): A general review on different variants of GAN and applications. In Proceedings of the 2021 6th International Conference on Communication and Electronics Systems (ICCES), Coimbatre, India, 8–10 July 2021; pp. 1–8. [Google Scholar]
- Zaidan, M.A.; Surakhi, O.; Fung, P.L.; Hussein, T. Sensitivity Analysis for Predicting Sub-Micron Aerosol Concentrations Based on Meteorological Parameters. Sensors 2020, 20, 2876. [Google Scholar] [CrossRef] [PubMed]
- Surakhi, O.; Serhan, S.; Salah, I. On the ensemble of recurrent neural network for air pollution forecasting: Issues and challenges. Adv. Sci. Technol. Eng. Syst. J. 2020, 5, 512–526. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attack | Label Description | |
|---|---|---|
| DoS11 | DoS | One-to-one DoS (denial of service) attack, where the attacker A1 attacks the victim V21 |
| DoS53s | DoS | The five attackers A1–A5 attack three of the victims, each one at a different network |
| DoS53a | DoS | The attacks are executed as in DoS53s, but now every victim is sequentially selected |
| Scan11 | Scan11 | One-to-one scan attack, where the attacker A1 scans the victim V41 |
| Scan44 | Scan14 | Four-to-four scan attack, where the attackers A1, A2, A3 and A4 initiate a scan at the same time to the victims V21, V11, V31 and V41 |
| Botnet | Nerisbotnet | Mixing botnet captures recorded elsewhere in a controlled environment with our background traffic |
| IP in blacklist | Blacklist | It is an attack of class signature |
| UDP Scan | Anomaly-udpscan | Depending on the source port of the connection, each victim host is scanned through a specific range of 60 ports |
| SSH Scan | Anomaly-sshscan | An anomaly attack |
| SPAM | Anomaly-spam | An anomaly attack |
| Number | Feature Name | Type |
|---|---|---|
| 1 | Timestamp | date-time |
| 2 | Flow duration | continuous numeric |
| 3 | Source IP address | categorical |
| 4 | Source IP address | categorical |
| 5 | Source port number | discrete numeric |
| 6 | Destination port number | discrete numeric |
| 7 | Protocol | categorical |
| 8 | Flag | categorical |
| 9 | Forwarding status | numeric |
| 10 | Source type of service | discrete numeric |
| 11 | Total number of packets | Continuous numeric |
| 12 | Total number of bytes | Continuous numeric |
| 13 | Class (Label) | categorical |
| From | To | Class Label | Counts | Percentage |
|---|---|---|---|---|
| 27 July 2016 | 31 July 2016 | background | 197,185 | 98.5% |
| 27 July 2016 | 31 July 2016 | dos | 1169 | 0.6% |
| 27 July 2016 | 31 July 2016 | scan44 | 578 | 0.3% |
| 27 July 2016 | 31 July 2016 | blacklist | 545 | 0.3% |
| 27 July 2016 | 31 July 2016 | nerisbotnet | 227 | 0.1% |
| 27 July 2016 | 31 July 2016 | anomaly-spam | 170 | 0.1% |
| 27 July 2016 | 31 July 2016 | scan11 | 126 | 0.1% |
| Unit | Description |
|---|---|
| Processor | Intel® Xeon® |
| CPU | 2.30 GHz with No.CPUs 2 |
| RAM | 12 GB |
| OS | |
| Packages | TensorFlow 2.6.0 |
| Accuracy | Precision | F1 Score | Recall |
|---|---|---|---|
| 0.95 | 0.94 | 0.94 | 0.96 |
| Model | Accuracy | Precision | F1 Score | Recall |
|---|---|---|---|---|
| SMOTE | 0.88 | 0.86 | 0.87 | 0.91 |
| Random Oversampling | 0.85 | 0.89 | 0.90 | 0.88 |
| SMOTEENN | 0.86 | 0.89 | 0.90 | 0.89 |
| The Borderline SMOTE | 0.84 | 0.87 | 0.87 | 0.88 |
| SVMSMOTE | 0.89 | 0.90 | 0.91 | 0.89 |
| SMOTE-Tomek Links | 0.90 | 0.87 | 0.89 | 0.87 |
| SMOTE_NC | 0.85 | 0.88 | 0.86 | 0.85 |
| CGAN | 0.83 | 0.83 | 0.83 | 0.83 |
| CTGAN | 0.76 | 0.76 | 0.76 | 0.76 |
| TDCGAN | 0.95 | 0.94 | 0.94 | 0.96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jamoos, M.; Mora, A.M.; AlKhanafseh, M.; Surakhi, O. A New Data-Balancing Approach Based on Generative Adversarial Network for Network Intrusion Detection System. Electronics 2023, 12, 2851. https://doi.org/10.3390/electronics12132851
Jamoos M, Mora AM, AlKhanafseh M, Surakhi O. A New Data-Balancing Approach Based on Generative Adversarial Network for Network Intrusion Detection System. Electronics. 2023; 12(13):2851. https://doi.org/10.3390/electronics12132851
Chicago/Turabian StyleJamoos, Mohammad, Antonio M. Mora, Mohammad AlKhanafseh, and Ola Surakhi. 2023. "A New Data-Balancing Approach Based on Generative Adversarial Network for Network Intrusion Detection System" Electronics 12, no. 13: 2851. https://doi.org/10.3390/electronics12132851
APA StyleJamoos, M., Mora, A. M., AlKhanafseh, M., & Surakhi, O. (2023). A New Data-Balancing Approach Based on Generative Adversarial Network for Network Intrusion Detection System. Electronics, 12(13), 2851. https://doi.org/10.3390/electronics12132851