
Knowledge Discovery in Databases for a Football Match Result




Abstract
1. Introduction
- present the comprehensive approach based on different algorithms adapted to different sets of attributes enabling us to estimate the quality of algorithms existing in the literature;
- select and test the number of algorithms available in the literature and present the test benchmark;
- prepare and make available a set of real data that would enable us to conduct experiments and research on classifiers in football;
- indicate the best-fitting algorithms from the literature, considering measures like accuracy, macro precision, macro recall, and the cover for the set.
2. Background
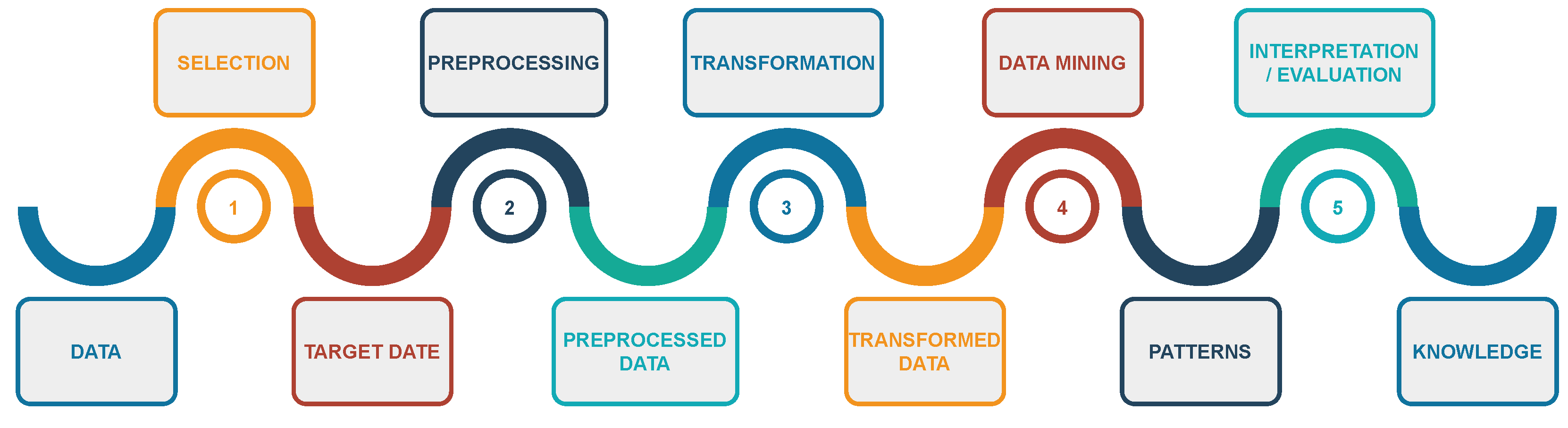
2.1. Knowledge Discovery in Databases
2.2. Sports Data
2.3. Machine Learning Algorithms in Sports Data
3. Preparing Dataset
3.1. Data Identification and Download
| Algorithm 1 Web Scraping Football Match Data |
Input: seasons—number of seasons to collect Input: www_list—list of addresses Output: output_file_matches_table—flat file containing collected matches data Output: output_file_league_table—flat file containing collected league data
|
3.2. Selection of Attributes and Creation of a Database
3.3. Data Cleaning and Preparation
3.4. Data Transformation and Creation of Sets for Analysis
- 0—draw,
- 1—home team win (visiting team loss),
- 2—visiting team win (home team loss),
- 9—information about an error in the data or formula.
4. Experiments
4.1. Experimental Design
- A separate data file was prepared for each league because each of the analyzed leagues will be trained and tested separately.
- The following columns were removed from the data set: ‘Country’, ‘League’, ‘TeamHT’, ‘TeamVT’, ‘ScoreHalf’, ‘ScoreFull’, ‘OddsHT’, ‘OddsX’.
- According to the conclusions of the literature review and our own research, records for the first five rounds of each season (≤ 5) were deleted from the dataset.
- df_short—‘Round’, ‘PositionHT’, ‘PositionVT’, ‘PointsHT’, ‘PointsVT’, ‘Difference’—based on [37],
- df_long—‘Round’, ‘PositionHT’, ‘MatchesHT’, ‘WinsHT’, ‘DrawsHT’, ‘LossesHT’, ‘GoalsScoredHT’, ‘GoalsConcededHT’, ‘GoalDifferenceHT’, ‘PointsHT’, ‘PositionVT’, ‘MatchesVT’, ‘WinsVT’, ‘DrawsVT’, ‘LossesVT’, ‘GoalsScoredVT’, ‘GoalsConcededVT’, ‘GoalDifferenceVT’, ‘PointsVT’.
4.2. Results of the Computational Experiments
- approach07-full list of attributes-df_long with simple voting and heterogeneous set of classifiers;
- approach04-original list of attributes-df_short with heterogeneous set of classifiers and weighting based on ‘r3’
- approach05-original list of attributes-df_short with applied heterogeneous set of classifiers and weighting based on ‘a_p_r_f’
- approach06-original list of attributes-df_short with heterogeneous set of classifiers and weighting based on ‘a2’
5. Conclusions and Future Works
Access to the Dataset
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yu, J.; Wen, Y.; Yang, L.; Zhao, Z.; Guo, Y.; Guo, X. Monitoring on triboelectric nanogenerator and deep learning method. Nano Energy 2022, 92, 106698. [Google Scholar] [CrossRef]
- Flesia, L.; Monaro, M.; Mazza, C.; Fietta, V.; Colicino, E.; Segatto, B.; Roma, P. Predicting perceived stress related to the COVID-19 outbreak through stable psychological traits and machine learning models. J. Clin. Med. 2020, 9, 3350. [Google Scholar] [CrossRef]
- Liu, H.; Lang, B. Machine learning and deep learning methods for intrusion detection systems: A survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef]
- Horvat, T.; Job, J. The use of machine learning in sport outcome prediction: A review. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1380. [Google Scholar] [CrossRef]
- Kozak, J.; Głowania, S. Heterogeneous ensembles of classifiers in predicting Bundesliga football results. Procedia Comput. Sci. 2021, 192, 1573–1582. [Google Scholar] [CrossRef]
- Kapadiya, C.; Shah, A.; Adhvaryu, K.; Barot, P. Intelligent cricket team selection by predicting individual players’ performance using efficient machine learning technique. Int. J. Eng. Adv. Technol. 2020, 9, 3406–3409. [Google Scholar] [CrossRef]
- Van Eetvelde, H.; Mendonça, L.D.; Ley, C.; Seil, R.; Tischer, T. Machine learning methods in sport injury prediction and prevention: A systematic review. J. Exp. Orthop. 2021, 8, 1–15. [Google Scholar] [CrossRef]
- Chowdhury, A.K.; Tjondronegoro, D.; Chandran, V.; Trost, S. Ensemble methods for classification of physical activities from wrist accelerometry. Med. Sci. Sport. Exerc. 2017, 49, 1965–1973. [Google Scholar] [CrossRef]
- Bunker, R.P.; Thabtah, F. A machine learning framework for sport result prediction. Appl. Comput. Inform. 2019, 15, 27–33. [Google Scholar] [CrossRef]
- Eryarsoy, E.; Delen, D. Predicting the Outcome of a Football Game: A Comparative Analysis of Single and Ensemble Analytics Methods. In Proceedings of the 52nd Hawaii International Conference on System Sciences, Maui, HI, USA, 8–11 January 2019. [Google Scholar] [CrossRef]
- Maimon, O.; Rokach, L. Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Fayyad, U.; Piatetsky-Shapiro, G.; Smyth, P. From data mining to knowledge discovery in databases. AI Mag. 1996, 17, 37. [Google Scholar]
- Sport For Business. The World’s Most Watched Sports. 2023. Available online: https://sportforbusiness.com/the-worlds-most-watched-sports/ (accessed on 5 June 2023).
- Leung, C.K.; Joseph, K.W. Sports data mining: Predicting results for the college football games. Procedia Comput. Sci. 2014, 35, 710–719. [Google Scholar] [CrossRef]
- Joseph, A.; Fenton, N.E.; Neil, M. Predicting football results using Bayesian nets and other machine learning techniques. Knowl.-Based Syst. 2006, 19, 544–553. [Google Scholar] [CrossRef]
- Cornman, A.; Spellman, G.; Wright, D. Machine Learning for Professional Tennis Match Prediction and Betting; Stanford Unverisity: Stanford, CA, USA, 2017; Volume 1, p. 4. [Google Scholar]
- Delen, D.; Cogdell, D.; Kasap, N. A comparative analysis of data mining methods in predicting NCAA bowl outcomes. Int. J. Forecast. 2012, 28, 543–552. [Google Scholar] [CrossRef]
- Kahn, J. Neural Network Prediction of NFL Football Games; World Wide Web Electronic Publication: Burlington, MA, USA, 2003; pp. 9–15. [Google Scholar]
- McCabe, A.; Trevathan, J. Artificial intelligence in sports prediction. In Proceedings of the Fifth International Conference on Information Technology: New Generations (itng 2008), Las Vegas, NV, USA, 7–8 April 2008; pp. 1194–1197. [Google Scholar] [CrossRef]
- Valero, C.S. Predicting Win-Loss outcomes in MLB regular season games—A comparative study using data mining methods. Int. J. Comput. Sci. Sport 2016, 15, 91–112. [Google Scholar] [CrossRef]
- Huang, M.L.; Li, Y.Z. Use of machine learning and deep learning to predict the outcomes of major league baseball matches. Appl. Sci. 2021, 11, 4499. [Google Scholar] [CrossRef]
- Cai, W.; Yu, D.; Wu, Z.; Du, X.; Zhou, T. A hybrid ensemble learning framework for basketball outcomes prediction. Phys. A Stat. Mech. Its Appl. 2019, 528, 121461. [Google Scholar] [CrossRef]
- Zdravevski, E.; Kulakov, A. System for Prediction of the Winner in a Sports Game. In International Conference on ICT Innovations; Springer: Berlin/Heidelberg, Germany, 2009; pp. 55–63. [Google Scholar] [CrossRef]
- Lin, J.; Short, L.; Sundaresan, V. Predicting National Basketball Association Winners; CS 229 Final Project; Stanford University: Stanford, CA, USA, 2014; pp. 1–5. [Google Scholar]
- Kapadia, K.; Abdel-Jaber, H.; Thabtah, F.; Hadi, W. Sport analytics for cricket game results using machine learning: An experimental study. Appl. Comput. Inform. 2020; ahead-of-print. [Google Scholar] [CrossRef]
- Passi, K.; Pandey, N. Increased prediction accuracy in the game of cricket using machine learning. arXiv 2018, arXiv:1804.04226. [Google Scholar] [CrossRef]
- Gu, W.; Foster, K.; Shang, J.; Wei, L. A game-predicting expert system using big data and machine learning. Expert Syst. Appl. 2019, 130, 293–305. [Google Scholar] [CrossRef]
- Luu, B.C.; Wright, A.L.; Haeberle, H.S.; Karnuta, J.M.; Schickendantz, M.S.; Makhni, E.C.; Nwachukwu, B.U.; Williams, R.J., III; Ramkumar, P.N. Machine learning outperforms logistic regression analysis to predict next-season NHL player injury: An analysis of 2322 players from 2007 to 2017. Orthop. J. Sport. Med. 2020, 8, 2325967120953404. [Google Scholar] [CrossRef]
- Baboota, R.; Kaur, H. Predictive analysis and modelling football results using machine learning approach for English Premier League. Int. J. Forecast. 2019, 35, 741–755. [Google Scholar] [CrossRef]
- Razali, N.; Mustapha, A.; Yatim, F.A.; Ab Aziz, R. Predicting football matches results using Bayesian networks for English Premier League (EPL). In Iop Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2017; Volume 226, p. 012099. [Google Scholar] [CrossRef]
- Schauberger, G.; Groll, A.; Tutz, G. Modeling Football Results in the German Bundesliga Using Match-Specific Covariates; Technical Report; Department of Statistics: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Zaveri, N.; Shah, U.; Tiwari, S.; Shinde, P.; Teli, L.K. Prediction of football match score and decision making process. Int. J. Recent Innov. Trends Comput. Commun. 2018, 6, 162–165. [Google Scholar]
- Sujatha, K.; Godhavari, T.; Bhavani, N.P. Football match statistics prediction using artificial neural networks. Int. J. Math. Comput. Methods 2018, 3, 1–7. [Google Scholar]
- Rue, H.; Salvesen, O. Prediction and retrospective analysis of soccer matches in a league. J. R. Stat. Soc. Ser. D 2000, 49, 399–418. [Google Scholar] [CrossRef]
- Rotshtein, A.P.; Posner, M.; Rakityanskaya, A. Football predictions based on a fuzzy model with genetic and neural tuning. Cybern. Syst. Anal. 2005, 41, 619–630. [Google Scholar] [CrossRef]
- Juszczuk, P.; Kozak, J.; Dziczkowski, G.; Głowania, S.; Jach, T.; Probierz, B. Real-World Data Difficulty Estimation with the Use of Entropy. Entropy 2021, 23, 1621. [Google Scholar] [CrossRef] [PubMed]
- Głowania, S.; Kozak, J.; Juszczuk, P. New Voting Schemas for Heterogeneous Ensemble of Classifiers in the Problem of Football Results Prediction. Procedia Comput. Sci. 2022, 207, 3393–3402. [Google Scholar] [CrossRef]
- Wiseman, O. Using Machine Learning to Predict the Winning Score of Professional Golf Events on the PGA Tour. Ph.D. Thesis, National College of Ireland, Dublin, Ireland, 2016. [Google Scholar]
- Upal, M. Predicting Hole by Hole Golf Scores on the PGA Tour Ron Richardson; Mercyhurst University: Erie, PA, USA, 2019; p. 10. [Google Scholar]
- Chiang, S. Machine Learning for Table Tennis Match Prediction. arXiv 2023, arXiv:2303.16776v1. [Google Scholar]
- Lennartz, J.; Groll, A.; van der Wurp, H. Predicting Table Tennis Tournaments: A comparison of statistical modelling techniques. Int. J. Racket Sport. Sci. 2021, 3, 39–48. [Google Scholar] [CrossRef]
- Wilkens, S. Sports prediction and betting models in the machine learning age: The case of tennis. J. Sport. Anal. 2021, 7, 99–117. [Google Scholar] [CrossRef]
- Lalwani, A.; Saraiya, A.; Singh, A.; Jain, A.; Dash, T. Machine Learning in Sports: A Case Study on Using Explainable Models for Predicting Outcomes of Volleyball Matches. arXiv 2022, arXiv:2206.09258. [Google Scholar]
- Sanghvi, D.; Deshpande, P.; Shanbhogue, S.; Shah, V. Analyzing and Predicting NCAA Volleyball Match Outcome Using Machine Learning Techniques. 2021. Available online: https://ceur-ws.org/Vol-2992/icaiw_wdea_2.pdf (accessed on 1 June 2023).
- S.A.S. STS. 2022. Available online: https://stats.sts.pl/ (accessed on 1 January 2023).
- UEFA. Union of European Football Associations Country Ranking. 2023. Available online: https://www.uefa.com/nationalassociations/uefarankings/country/#/yr/2023 (accessed on 19 April 2023).
- Głowania, S.; Kozak, J.; Juszczuk, P. Source Data of Top European Football Leagues. 2023. Available online: https://www.ue.katowice.pl/index.php?id=25091 (accessed on 1 June 2023).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Breiman, L.; Friedman, J.; Stone, C.; Olshen, R. Classification and Regression Trees Chapman & Hall; Wadsworth International Group: New York, NY, USA, 1984. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar] [CrossRef]
- Fan, R.E.; Chang, K.W.; Hsieh, C.J.; Wang, X.R.; Lin, C.J. LIBLINEAR: A library for large linear classification. J. Mach. Learn. Res. 2008, 9, 1871–1874. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the Icml, Citeseer, Bari, Italy, 3–6 July 1996; Volume 96, pp. 148–156. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Rifkin, R.M.; Lippert, R.A. Notes on Regularized Least Squares. 2007. Available online: https://dspace.mit.edu/handle/1721.1/37318 (accessed on 1 January 2023).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sport | Article and Algorithms |
|---|---|
| American Football | |
| Baseball | |
| Basketball | |
| Cricket | |
| Field Hockey | |
| Football |
|
| Golf | |
| Table Tennis | |
| Tennis | |
| Volleyball |
| Attribute | Description |
|---|---|
| Round | round number for which the summary was prepared, |
| Position | team position in the league table, |
| Team | team name, |
| Matches | number of matches played, |
| Wins | number of matches played in the season ended in a win, |
| Draws | number of games played in the season ended in a draw, |
| Losses | number of matches played in the season ended in a loss, |
| GoalsScored | number of goals scored during the season, |
| GoalsConceded | number of goals conceded during the season, |
| GoalDifference | the difference between the number of goals scored and conceded during the season, |
| Points | number of points scored, |
| Country | country of competition, |
| League | name of the league along with the season. |
| Attribute | Description |
|---|---|
| Round | round number with gameplay, |
| Hour | match start time, |
| TeamHT | home team name, |
| TeamVT | visiting team name, |
| ScoreHalf | halftime score, |
| ScoreFull | match result, |
| OddsHT | home team win odds, |
| OddsX | draw odds, |
| OddsVT | visiting team win odds, |
| Country | country of competition, |
| League | name of the league along with the season. |
| Country | Number of Records | Data Gaps * | Training Set | Test Set |
|---|---|---|---|---|
| England | 4180 | 0 | 3762 | 363 |
| Spain | 4180 | 0 | 3762 | 363 |
| Germany | 3366 | 0 | 3022 | 289 |
| Italy | 4180 | 0 | 3762 | 363 |
| France | 4180 | 101 | 3661 | 363 |
| Netherlands | 3366 | 77 | 2945 | 289 |
| Portugal | 3168 | 1 | 2823 | 289 |
| ‘Country’ | ‘League’ | ‘Round’ |
| ‘TeamHT’ | ‘PositionHT’ | ‘MatchesHT’ |
| ‘WinsHT’ | ‘DrawsHT’ | ‘LossesHT’ |
| ‘GoalsScoredHT’ | ‘GoalsConcededHT’ | ‘GoalDifferenceHT’ |
| ‘PointsHT’ | ‘TeamVT’ | ‘PositionVT’ |
| ‘MatchesVT’ | ‘WinsVT’ | ‘DrawsVT’ |
| ‘LossesVT’ | ‘GoalsScoredVT’ | ‘GoalsConcededVT’ |
| ‘GoalDifferenceVT’ | ‘PointsVT’ | ‘ScoreHalf’ |
| ‘ScoreFull’ | ‘OddsHT’ | ‘OddsX’ |
| ‘OddsVT’ | ‘Season’ | ‘Difference’ |
| ‘Target’ |
| Approach | A Set of Attributes | Voting Type | Implementation |
|---|---|---|---|
| approach01 | df_short | simple | [5] |
| approach02 | df_short | unanimous | [5] |
| approach03 | df_short | majority | [37] |
| approach04 | df_short | weighted (Equation (3)) | [37] |
| approach05 | df_short | weighted (Equation (4)) | [37] |
| approach06 | df_short | weighted (Equation (1)) | [37] |
| approach07 | df_long | simple | [5] |
| approach08 | df_long | weighted (Equation (1)) | [37] |
| approach09 | df_long | weighted (Equation (3)) | [37] |
| approach10 | df_long | weighted (Equation (4)) | [37] |
| approach11 | df_long | majority | [37] |
| approach12 | df_long | unanimous | [5] |
| Class 0 (Draw) | Class 1 (Home Team Win) | Class 2 (Visiting Team Win) | ||||
|---|---|---|---|---|---|---|
| Country | Training Set | Test Set | Training Set | Test Set | Training Set | Test Set |
| England | 0.2382 | 0.1952 | 0.4608 | 0.3857 | 0.3010 | 0.4190 |
| Spain | 0.2427 | 0.2714 | 0.4761 | 0.4238 | 0.2812 | 0.3048 |
| Germany | 0.2479 | 0.2222 | 0.4436 | 0.4967 | 0.3085 | 0.2810 |
| Italy | 0.2579 | 0.2429 | 0.4437 | 0.4429 | 0.2984 | 0.3143 |
| France | 0.2683 | 0.2619 | 0.4537 | 0.3571 | 0.2780 | 0.3810 |
| Netherlands | 0.2316 | 0.2353 | 0.4755 | 0.4510 | 0.2929 | 0.3137 |
| Portugal | 0.2361 | 0.2484 | 0.4587 | 0.4052 | 0.3052 | 0.3464 |
| Predicted | ||||||
|---|---|---|---|---|---|---|
| Actual | Class 1 | Class 2 | ⋯ | Class i | ⋯ | Class C |
| class 1 | ⋯ | ⋯ | ||||
| class 2 | ⋯ | ⋯ | ||||
| ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | |
| class i | ⋯ | ⋯ | ||||
| ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ |
| class C | ⋯ | ⋯ | ||||
| Approach | Accuracy | Accuracy All Case | Cover | Macro Precision | Macro Recall | Macro F1–Score |
|---|---|---|---|---|---|---|
| approach01 | 0.5106 | 0.5106 | 1.0000 | 0.3733 | 0.4423 | 0.3760 |
| approach02 | 0.5983 | 0.3151 | 0.5300 | 0.4083 | 0.4830 | 0.4291 |
| approach03 | 0.5143 | 0.5075 | 0.9900 | 0.3526 | 0.4443 | 0.3777 |
| approach04 | 0.5174 | 0.5174 | 1.0000 | 0.4715 | 0.4534 | 0.4075 |
| approach05 | 0.5174 | 0.5174 | 1.0000 | 0.4668 | 0.4568 | 0.4189 |
| approach06 | 0.5154 | 0.5154 | 1.0000 | 0.4637 | 0.4495 | 0.3983 |
| approach07 | 0.5179 | 0.5179 | 1.0000 | 0.4091 | 0.4472 | 0.3842 |
| approach08 | 0.5135 | 0.5135 | 1.0000 | 0.4073 | 0.4445 | 0.3845 |
| approach09 | 0.5120 | 0.5120 | 1.0000 | 0.4171 | 0.4444 | 0.3885 |
| approach10 | 0.5092 | 0.5092 | 1.0000 | 0.4209 | 0.4438 | 0.3940 |
| approach11 | 0.5204 | 0.5072 | 0.9700 | 0.3611 | 0.4487 | 0.3819 |
| approach12 | 0.5935 | 0.3179 | 0.5400 | 0.4099 | 0.4787 | 0.4239 |
| Approach | Accuracy | Accuracy All Case | Cover | Macro Precision | Macro Recall | Macro F1–Score |
|---|---|---|---|---|---|---|
| approach01 | 0.4929 | 0.4929 | 1.0000 | 0.3331 | 0.4146 | 0.3539 |
| approach02 | 0.5793 | 0.3087 | 0.5300 | 0.3852 | 0.4379 | 0.3949 |
| approach03 | 0.4952 | 0.4897 | 0.9900 | 0.3342 | 0.4159 | 0.3558 |
| approach04 | 0.5032 | 0.5032 | 1.0000 | 0.3998 | 0.4258 | 0.3775 |
| approach05 | 0.5040 | 0.5040 | 1.0000 | 0.4038 | 0.4297 | 0.3881 |
| approach06 | 0.5016 | 0.5016 | 1.0000 | 0.3788 | 0.4225 | 0.3688 |
| approach07 | 0.4952 | 0.4952 | 1.0000 | 0.3357 | 0.4158 | 0.3584 |
| approach08 | 0.4897 | 0.4897 | 1.0000 | 0.3314 | 0.4106 | 0.3566 |
| approach09 | 0.4857 | 0.4857 | 1.0000 | 0.3312 | 0.4076 | 0.3543 |
| approach10 | 0.4865 | 0.4865 | 1.0000 | 0.3671 | 0.4117 | 0.3664 |
| approach11 | 0.4967 | 0.4850 | 0.9800 | 0.3362 | 0.4177 | 0.3606 |
| approach12 | 0.5576 | 0.3111 | 0.5600 | 0.3791 | 0.4306 | 0.3823 |
| Approach | Accuracy | Accuracy All Case | Cover | Macro Precision | Macro Recall | Macro F1–Score |
|---|---|---|---|---|---|---|
| approach01 | 0.5286 | 0.5286 | 1.0000 | 0.5535 | 0.4576 | 0.3977 |
| approach02 | 0.5977 | 0.3244 | 0.5400 | 0.4108 | 0.4847 | 0.4294 |
| approach03 | 0.5343 | 0.5244 | 0.9800 | 0.4029 | 0.4581 | 0.3934 |
| approach04 | 0.5280 | 0.5280 | 1.0000 | 0.4238 | 0.4614 | 0.3998 |
| approach05 | 0.5268 | 0.5268 | 1.0000 | 0.4217 | 0.4599 | 0.3979 |
| approach06 | 0.5292 | 0.5292 | 1.0000 | 0.4149 | 0.4621 | 0.3993 |
| approach07 | 0.5262 | 0.5262 | 1.0000 | 0.3853 | 0.4565 | 0.3932 |
| approach08 | 0.5316 | 0.5316 | 1.0000 | 0.4233 | 0.4620 | 0.3976 |
| approach09 | 0.5321 | 0.5321 | 1.0000 | 0.4237 | 0.4627 | 0.3983 |
| approach10 | 0.5315 | 0.5315 | 1.0000 | 0.4227 | 0.4624 | 0.3981 |
| approach11 | 0.5310 | 0.5250 | 0.9900 | 0.3865 | 0.4610 | 0.3964 |
| approach12 | 0.5685 | 0.3393 | 0.6000 | 0.4067 | 0.4640 | 0.4088 |
| Approach | Accuracy | Accuracy All Case | Cover | Macro Precision | Macro Recall | Macro F1–Score |
|---|---|---|---|---|---|---|
| approach01 | 0.5305 | 0.5305 | 1.0000 | 0.3454 | 0.4306 | 0.3813 |
| approach02 | 0.6030 | 0.2996 | 0.5000 | 0.3993 | 0.4919 | 0.4355 |
| approach03 | 0.5352 | 0.5294 | 0.9900 | 0.3478 | 0.4339 | 0.3845 |
| approach04 | 0.5185 | 0.5185 | 1.0000 | 0.5135 | 0.4185 | 0.3835 |
| approach05 | 0.5098 | 0.5098 | 1.0000 | 0.4415 | 0.4162 | 0.3892 |
| approach06 | 0.5207 | 0.5207 | 1.0000 | 0.5285 | 0.4192 | 0.3790 |
| approach07 | 0.5305 | 0.5305 | 1.0000 | 0.3454 | 0.4256 | 0.3779 |
| approach08 | 0.5262 | 0.5262 | 1.0000 | 0.3443 | 0.4249 | 0.3778 |
| approach09 | 0.5305 | 0.5305 | 1.0000 | 0.3487 | 0.4284 | 0.3817 |
| approach10 | 0.5240 | 0.5240 | 1.0000 | 0.3689 | 0.4247 | 0.3829 |
| approach11 | 0.5310 | 0.5120 | 0.9600 | 0.3451 | 0.4308 | 0.3807 |
| approach12 | 0.5492 | 0.2974 | 0.5400 | 0.3437 | 0.4407 | 0.3831 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Głowania, S.; Kozak, J.; Juszczuk, P. Knowledge Discovery in Databases for a Football Match Result. Electronics 2023, 12, 2712. https://doi.org/10.3390/electronics12122712
Głowania S, Kozak J, Juszczuk P. Knowledge Discovery in Databases for a Football Match Result. Electronics. 2023; 12(12):2712. https://doi.org/10.3390/electronics12122712
Chicago/Turabian StyleGłowania, Szymon, Jan Kozak, and Przemysław Juszczuk. 2023. "Knowledge Discovery in Databases for a Football Match Result" Electronics 12, no. 12: 2712. https://doi.org/10.3390/electronics12122712
APA StyleGłowania, S., Kozak, J., & Juszczuk, P. (2023). Knowledge Discovery in Databases for a Football Match Result. Electronics, 12(12), 2712. https://doi.org/10.3390/electronics12122712