1. Introduction
Rough set theory [
1,
2] is a tool for data mining and knowledge discovery, initially developed for complete information systems [
3,
4] and then extended for incomplete systems [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15]. Maximal consistent blocks, as a maximal collection of indiscernible objects, were introduced for incomplete data sets, with missing values represented only as “do not care” conditions, and were used as basic granules to define only ordinary lower and upper approximations in [
16]. In [
17,
18], the definition of maximal consistent blocks was generalized to cover lost values. Furthermore, two new types of approximations were introduced, global probabilistic approximations and saturated probabilistic approximations based on maximal consistent blocks [
19,
20,
21].
Several approaches for computing maximal consistent blocks: the brute force method [
22], the recursive method [
22] and the hierarchical method [
23] were introduced for incomplete data sets with only “do not care” conditions. For incomplete data sets with only lost values, the simplified recursive method based on the property that for such data sets, the characteristic relation is transitive, was provided in [
24]. In turn, in [
17], the method for computing maximal consistent blocks for arbitrary interpretations of missing attribute values based on a characteristic relation was proposed.
Analysis of the published algorithms for constructing maximal consistent blocks, for data with only “do not care” conditions, revealed two problems. Firstly, the obtained blocks might not be maximal, especially for data sets for which a characteristic relation is not transitive. The second problem is that, in some cases, the reported computational complexity of the algorithms is underestimated [
25]. Additionally, in papers [
18,
26], during the comparison of characteristic sets with generalized maximal consistent blocks in terms of an error rate and complexity of induced rule sets, the authors suggested that characteristic sets can be computed in polynomial time, while computing maximal consistent blocks is associated with exponential time complexity for incomplete data with “do not care” conditions.
In this paper, we estimate the total number of maximal consistent blocks for incomplete data sets. We define a special data set called a k-galaxy set, and we prove that the number of maximal consistent blocks grows exponentially with respect to the number of attributes for incomplete data with all missing attribute values interpreted as “do not care” conditions. Additionally, for the practical usage of this technique of incomplete data set mining, we propose a performance improvement in the form of the parallelization of the maximal consistent blocks construction method.
The paper is organized as follows. In
Section 2,
Section 3 and
Section 4, an appropriate introduction to the used approach for incomplete data mining is presented. In
Section 5, the complexity of computing maximal consistent blocks is estimated. Finally, a parallel solution for determining maximal consistent blocks is proposed in
Section 6.
2. Incomplete Data
We consider incomplete data sets with two interpretations of missing attribute values—lost values and “do not care” conditions. Lost values, denoted by question marks, are interpreted as values that are erased or not inserted. The “do not care” conditions, denoted by stars, have another interpretation. Here, we assume that the original values are irrelevant so that such values may be replaced by any existing attribute value [
27]. The practice of data mining shows that “do not care” conditions are often the results of the refusal to provide a value. For example, some respondents refuse to provide a value of the
salary attribute, or, when asked for
eye color during the collection of data about a disease, may consider such an attribute as irrelevant and again refuse to specify the value. It is worth noting that there are also other interpretations of missing attribute values, such as not applicable. An example of such a situation can be the value of the
salary attribute when a respondent is unemployed. It is important to understand the reasons and distinguish between various types of missing data, such as missing completely at random, missing at random, and missing not at random. Examples can be found in the statistical literature on missing attribute values [
28,
29].
The incomplete data set, in the form of a decision table, is presented in
Table 1. The rows of the decision table represent
cases or
objects. The set of all cases is called the
universe and is denoted by
U.
Table 1 shows
U = {1, 2, 3, 4, 5, 6, 7, 8}. The independent variables are called
attributes and are denoted by
A. In
Table 1,
Mileage,
Accident and
Equipment are the attributes. The set of all values of the attribute
a is called a domain of
a and is denoted by
. In
Table 1,
. The dependent variable
Buy is called a
decision. The set of all cases with the same decision value is called a
concept. In
Table 1, there are two concepts, the set {1, 2, 3, 4} of all cases, where the value of
Buy is
yes and the other set {5, 6, 7, 8}, where the value of
Buy is
no.
The value v of the attribute a for the case x is denoted by . A block of the attribute–value pair, denoted by , is the set of all cases from U that for the attribute a have the value v, .
We consider two interpretations of missing attribute values: lost values denoted by ? and “do not care” conditions denoted by ∗ in
Table 1. The set of all cases from
U that for the attribute
a have lost values
is denoted by
, whereas the set of all cases from
U that for the attribute
a have “do not care” conditions
is denoted by
.
For incomplete decision tables, the definition of a block of an attribute–value pair is modified as follows [
27]:
- –
If for an attribute a and a case x, , then the case x should not be included in any blocks for all values v of the attribute a;
- –
If for an attribute a and a case x, , then the case x should be included in blocks for all specified values v of the attribute a.
For
Table 1, all the blocks of attribute–value pairs are as follows:
,
,
,
,
,
.
3. Characteristic Relation
In an incomplete decision table, for
, the objects of the pair
are considered similar in terms of the B-characteristic relation
defined as follows [
12]:
where
is
the characteristic set, i.e., the smallest set of cases that are indistinguishable from
, for all attributes from
. For incomplete decision tables, the characteristic set is defined as follows [
11]:
- –
If is specified, then is the block of the attribute a and its value ;
- –
If or , then .
For the data set from
Table 1 and
, the characteristic sets are as follows:
,
,
,
,
,
,
,
.
The characteristic relation is = {(1, 1), (1, 4), (2, 2), (2, 3), (2, 4), (2, 6), (2, 7), (2, 8), (3, 3), (3, 6), (4, 1), (4, 4), (5, 5), (5, 6), (6, 2), (6, 6), (6, 8), (7, 1), (7, 2), (7, 4), (7, 7), (8, 6), (8, 8)}.
5. Estimation of the Number of Maximal Consistent Blocks
For a data set with all missing attribute values interpreted as lost, a family
of all maximal consistent blocks is a partition on
U [
18].
Properties of maximal consistent blocks for data sets with missing attribute values interpreted as “do not care” conditions were explored in [
16] and other papers [
22,
23]. However, the estimation of the number of possible maximal consistent blocks is an open problem. In this paper, we show that such a number may exponentially grow with respect to the number of attributes.
Proposition 1. For a data set in which all attribute values are missing and interpreted as “do not care” conditions, the total number of maximal consistent blocks is equal to 1.
Proof. This follows directly from the definition of maximal consistent blocks. □
Proposition 2. For a data set with = 1, the total number of maximal consistent blocks is equal to 1.
Proof. This follows directly from the definition of maximal consistent blocks. □
In order to estimate the number of possible maximal consistent blocks for incomplete data sets with all missing attribute values interpreted as “do not care” conditions, we introduce a special data set, which we call a k-galaxy set. Let , for all . The set is a k-galaxy set if when ; otherwise, for any and . ’·’ denotes a standard arithmetic multiplication operation.
An example of a k-galaxy set (k = 3) is shown in
Table 2.
For the
k-galaxy set (k = 3) from
Table 2, the set of all maximal consistent blocks of
A is {{1, 4, 7}, {1, 4, 8}, {1, 4, 9}, {1, 5, 7}, {1, 5, 8}, {1, 5, 9}, {1, 6, 7}, {1, 6, 8}, {1, 6, 9}, {2, 4, 7}, {2, 4, 8}, {2, 4, 9}, {2, 5, 7}, {2, 5, 8}, {2, 5, 9}, {2, 6, 7}, {2, 6, 8}, {2, 6, 9}, {3, 4, 7}, {3, 4, 8}, {3, 4, 9}, {3, 5, 7}, {3, 5, 8}, {3, 5, 9}, {3, 6, 7}, {3, 6, 8}, {3, 6, 9}}.
For a set X, denotes the cardinality of X.
Lemma 1. For a k-galaxy set, is equal to k, where .
Proof. If and then for any , . This means that is consistent with respect to a. Therefore, from the definition of maximal consistent blocks, there are k maximal consistent blocks with respect to a. □
For instance, in
Table 2, the set of maximal consistent blocks with respect to
Attribute 1 from the example of a k-galaxy set for k = 3 is {{1, 4, 5, 6, 7, 8, 9}, {2, 4, 5, 6, 7, 8, 9}, {3, 4, 5, 6, 7, 8, 9}}.
Lemma 2. For a k-galaxy set, let . The set is equal to , where .
Proof. Let , and . For any , , x and y are consistent with respect to a; if , then , so is a consistent block. Moreover, there does not exist such that . This means that objects with values belonging to are inconsistent. Therefore, is a maximal consistent block with respect to the attribute a.
Any attribute of a k-galaxy set contains k inconsistent objects belonging to and remaining objects of the type . Hence, each includes exactly one object with a specified value v and objects , and thus is equal to . □
In Lemma 3 and Proposition 3, provided below, we use Property 5 from [
16] which states that the set of maximal consistent blocks can be updated sequentially depending on the currently analyzed set of attributes. Let
,
,
,
and
, and from the definition of a k-galaxy set,
.
Lemma 3. For a k-galaxy set, the cardinality of each maximal consistent block of is the same, equaling , .
Proof. For any , , is consistent with respect to if and or and . From Lemma 2, the includes exactly one object with a specified value and objects [(a, *)]. Thus, for , the set of objects [(a, *)] is reduced by k objects belonging to . Additionally, based on the construction of a k-galaxy set, the objects in as well as in are discernible, so the number of elements in is less than in . Hence, increasing the number of attributes by one reduces the number of elements of by . In consequence, if , the number of elements of all is reduced to k. □
For instance, in
Table 2, k = 3,
,
the sets {1, 4}, {1, 5}, {1, 6}, {2, 4}, {2, 5}, {2, 6}, {3, 4}, {3, 5} and {3, 6} are consistent with respect to {
Attribute1,
Attribute2}, and all mentioned sets belong to R(
Attribute1,
Attribute2) (see
Section 4). For the set
is {{1, 4, 5, 6, 7, 8, 9}, {2, 4, 5, 6, 7, 8, 9}, {3, 4, 5, 6, 7, 8, 9}}, each block contains one object with a specified value belonging to
and six objects of the type [(Attribute 1, *)], so
(see
Table 3). The set
is {{1, 4, 7, 8, 9} {1, 5, 7, 8, 9}, {1, 6, 7, 8, 9}, {2, 4, 7, 8, 9}, {2, 5, 7, 8, 9} {2, 6, 7, 8, 9}, {3, 4, 7, 8, 9}, {3, 5, 7, 8, 9}, {3, 6, 7, 8, 9}}, and each block contains two objects with a specified value—the first belonging to
and the second belonging to
—and three objects [(Attribute 1, *),(Attribute 2, *)]. Therefore,
(see
Table 4). The number of elements in
is reduced by
objects with respect to
. Finally, each block of the
, presented above, contains three elements and is reduced again by
objects with respect to
.
Proposition 3. For a k-galaxy set .
Proof. For any from Lemma 1, . For any , , is consistent with respect to if and or and . Additionally, based on the construction of a k-galaxy set, the objects in as well as in are discernible, so each of the k objects belonging to is consistent with each of the k objects belonging to . Hence, there are consistent blocks with respect to the attributes {a, b}. Objects such that are added to every consistent block with respect to the set of attributes . From Lemma 3, all of the blocks have the same number of elements. There are no subsets that are consistent with respect to the set of attributes . The obtained blocks are maximal consistent blocks. Extending the set of analyzed attributes by another attribute increases the number of maximal consistent blocks k times, and thus, the number of maximal consistent blocks for the entire k-galaxy set is . □
Therefore, in the worst case, the time complexity of computing maximal consistent blocks is
, where
n is the number of objects in a data set. This result indicates that the time complexity of some known algorithms for computing maximal consistent blocks was underestimated so far, and their authors suggest that the mentioned problem is associated with polynomial time complexity [
22,
23].
6. Parallelization of the Maximal Consistent Blocks Computations
The idea of the sequential update of the set of maximal consistent blocks based on Property 5 from [
16] proposed in [
25] is more effective than the commonly used method of constructing the blocks. However, the subsets merging, which removes subsets by performing comparisons between two sets (the current set of maximal consistent blocks obtained so far and the new one built for the next attribute), has a significant impact on the overall performance. Thus, the usage of maximal consistent blocks in mining real data with a large number of missing values or/and many attributes requires additional improvements. Here, a solution based on parallel processing is proposed.
Due to the fact that the subset is a transitive relation, the merge procedure can apply subset elimination in any order; in particular, merged sets of consistent blocks can be processed in pairs at the same time.
Let
and
is equal to
. Thus, the BuildProcedure splits the set of all cases
U into a set of
maximal consistent blocks with respect to the first attribute (see
Figure 1). Then the
blocks are divided in pairs into a batch of
separate tasks that are executed simultaneously. In the first batch, the BuildProcedure is called for each block of the pair and the next attribute
, then the resulting sets are merged. The
sets of blocks, being the results of the entire batch, are divided in pairs into
separate merging tasks and the next batch is formed. The merging continues until a single set of
maximal consistent blocks is obtained. Then the set is divided in pairs into a batch of
tasks and the computations are performed for the attribute
. The processing is repeated until all the attributes in the data set are taken into account.
In the evaluation of the parallel computation, two aspects should be considered:
speedup—the improvement in running time due to parallelism; and
efficiency—the ratio of work done by a parallel algorithm to work done by a sequential algorithm [
30]. As indicated above, in the worst case in the sequential algorithm, the time complexity of computing maximal consistent blocks is
, where
n is the number of objects in a data set. The proposed approach is a synchronized parallel algorithm [
31]. The tasks are parallelized in batches. The results of each task from the given batch are not independent and have to be merged. This merging continues in subsequent batches of parallelized tasks until a single set of maximal consistent blocks is obtained. The processes are synchronized at the end of each batch. In the most optimistic scenario, in which all tasks in a batch are executed at the same time, the total number of batches (which can be estimated as
for each attribute) determines the efficiency. In practice, however, the efficiency is reduced by the fact that
processes have to wait for the processes executing the slowest task in a batch. Therefore, in the worst case, the relative improvement compared to the sequential algorithm is
.
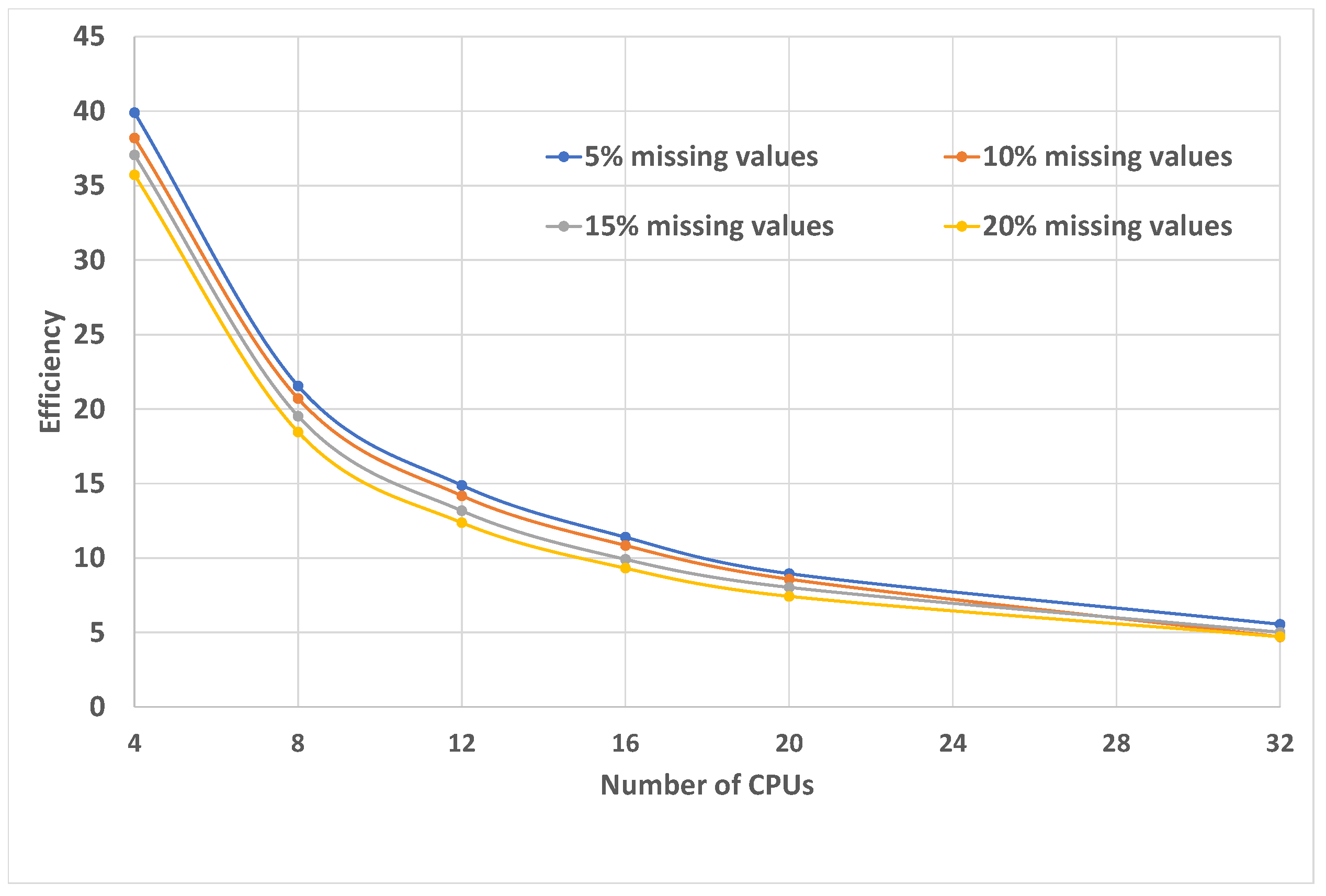
For the demonstration of the real values of the efficiency, the
abalone data set with all missing attribute values interpreted as “do not care” conditions was selected, due to the fact that during the experiments performed, using the sequential algorithm, this set turned out to be the most demanding one [
25]. The analysis was conducted using 4, 6, 8, 12, 16, 20 and 32 processors. The
abalone data set contained 4177 observations and 8 attributes. The “do not care” conditions data sets were prepared by randomly replacing 5%, 10%, 15%, 20% of existing specified attribute values with the “*”s. Results of the analysis are presented in
Figure 2 and
Figure 3. The speedup does not increase linearly with the number of processors; instead, it tends to saturate. The efficiency drops as the number of processors increases. For parallel systems, this observation is called Amdahl’s law [
32]. However, the results show a general increase in the speed (performance) of the parallel approach compared to the sequential computing of maximal consistent blocks. The proposed parallel algorithm includes operations that need to be executed sequentially and the increase in processing speed obtained due to the parallelization of the algorithm is limited by these sequential operations.









{kind=link}
{kind=link}
{kind=link}