
An Explainable Artificial Intelligence-Based Robustness Optimization Approach for Age-Related Macular Degeneration Detection Based on Medical IOT Systems



Abstract
:1. Introduction
2. Materials and Methodologies
2.1. Materials
2.2. Methodologies
2.2.1. Preprocessing of the Images
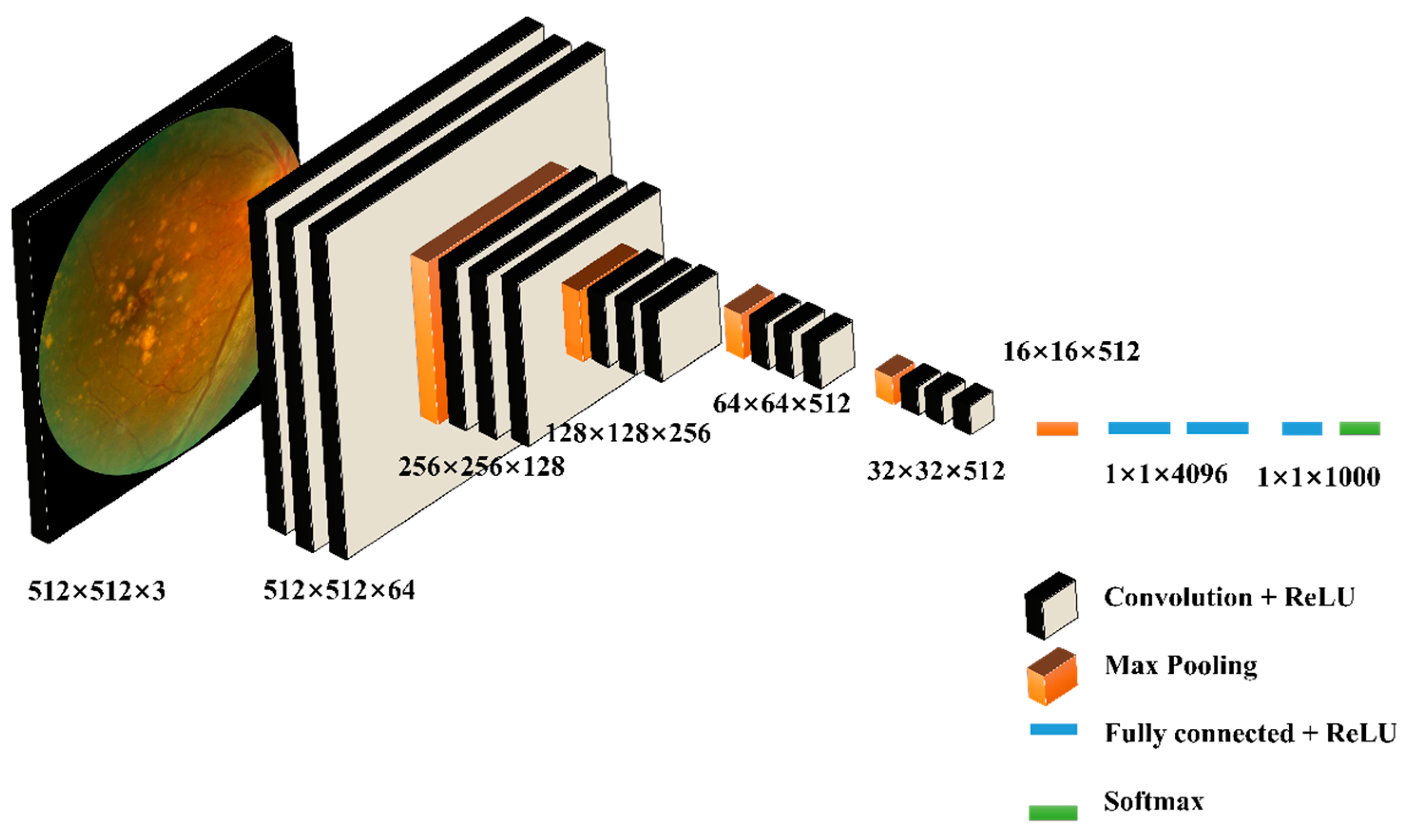
2.2.2. VGG16-Based Age-Related Macular Degeneration Detection
| Algorithm 1: VGG16 algorithm for AMD detection |
| Import: Required libraries of tensorflow as tf |
| Input: Input images of OCT, segmented OCT, FAF, regular CFP, and ROI-extracted UWF |
| Output: Results of classification |
| First import VGG model and evaluation functions from tf |
| from tensorflow.keras.applications.vgg16 import VGG16 from tensorflow.keras.layers import Dense, Flatten, Dropout |
| Second Define input shape |
| input_shape = (512, 512, 3) Initialize 2 centroids Third Load VGG16 model pre-trained on ImageNet vgg16 = VGG16(weights=‘imagenet’, input_shape=input_shape, include_top=False) # Freeze layers for layer in vgg16.layers: layer.trainable = False # Add new classifier layers x = Flatten()(vgg16.output) x = Dense(512, activation=‘relu’)(x) x = Dropout(0.5)(x) x = Dense(1, activation=‘sigmoid’)(x) Then Compile model model = tf.keras.models.Model(inputs=vgg16.input, outputs=x) model.compile(optimizer=‘adam’, loss=‘binary_crossentropy’, metrics=[‘accuracy’]) Next Train model model.fit(train_generator, epochs=10, validation_data=val_generator) Final Evaluate model test_loss, test_acc = model.evaluate(test_generator) print(‘Test accuracy:’, test_acc) |
| Return data.name, VGG16 classification results |
2.3. CAM-Based Explainable Artificial Intelligence Measurement of VGG-Based Model
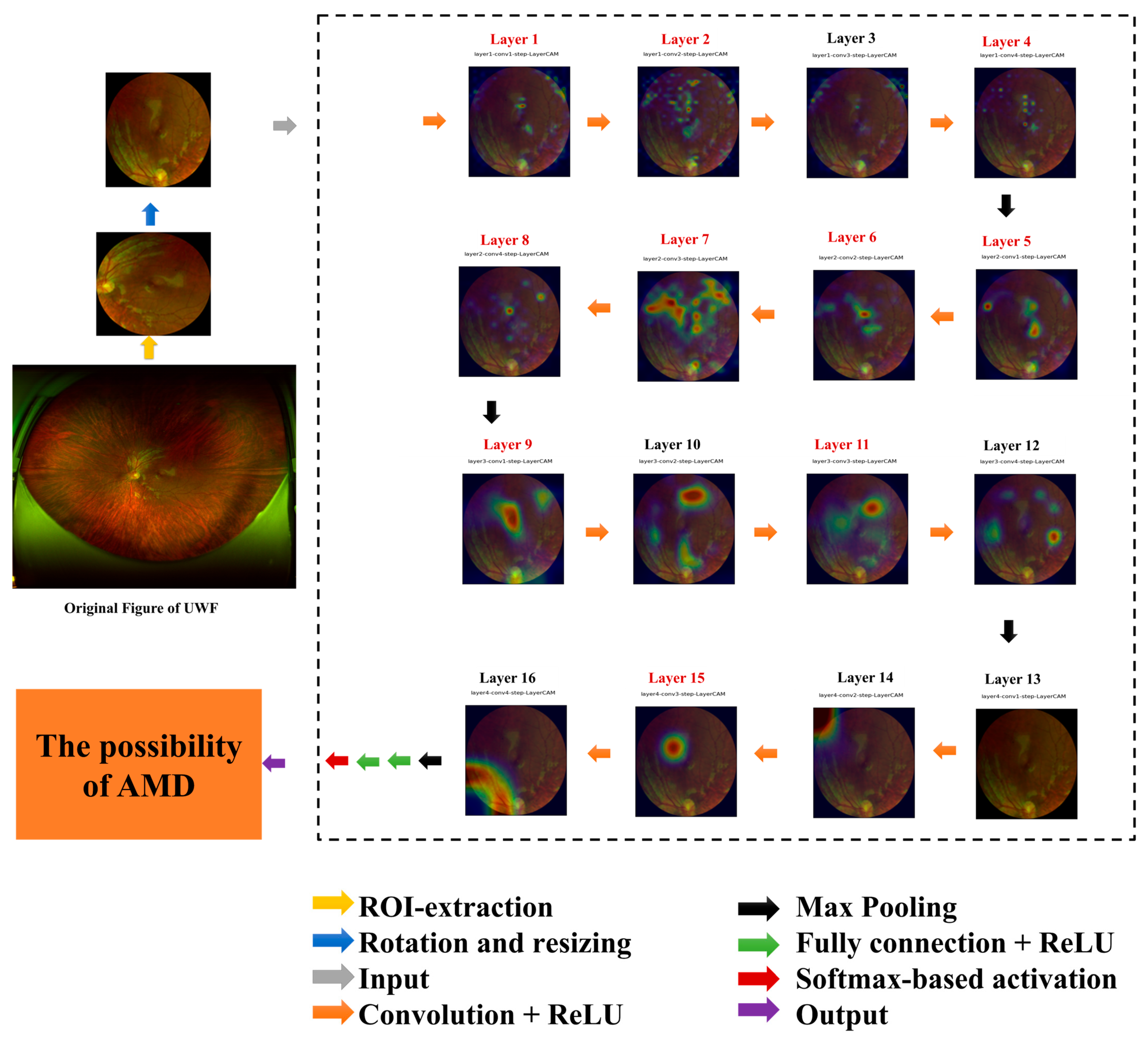
2.3.1. Class Activation Mapping Algorithm
2.3.2. Explainable Artificial Intelligence Evaluation
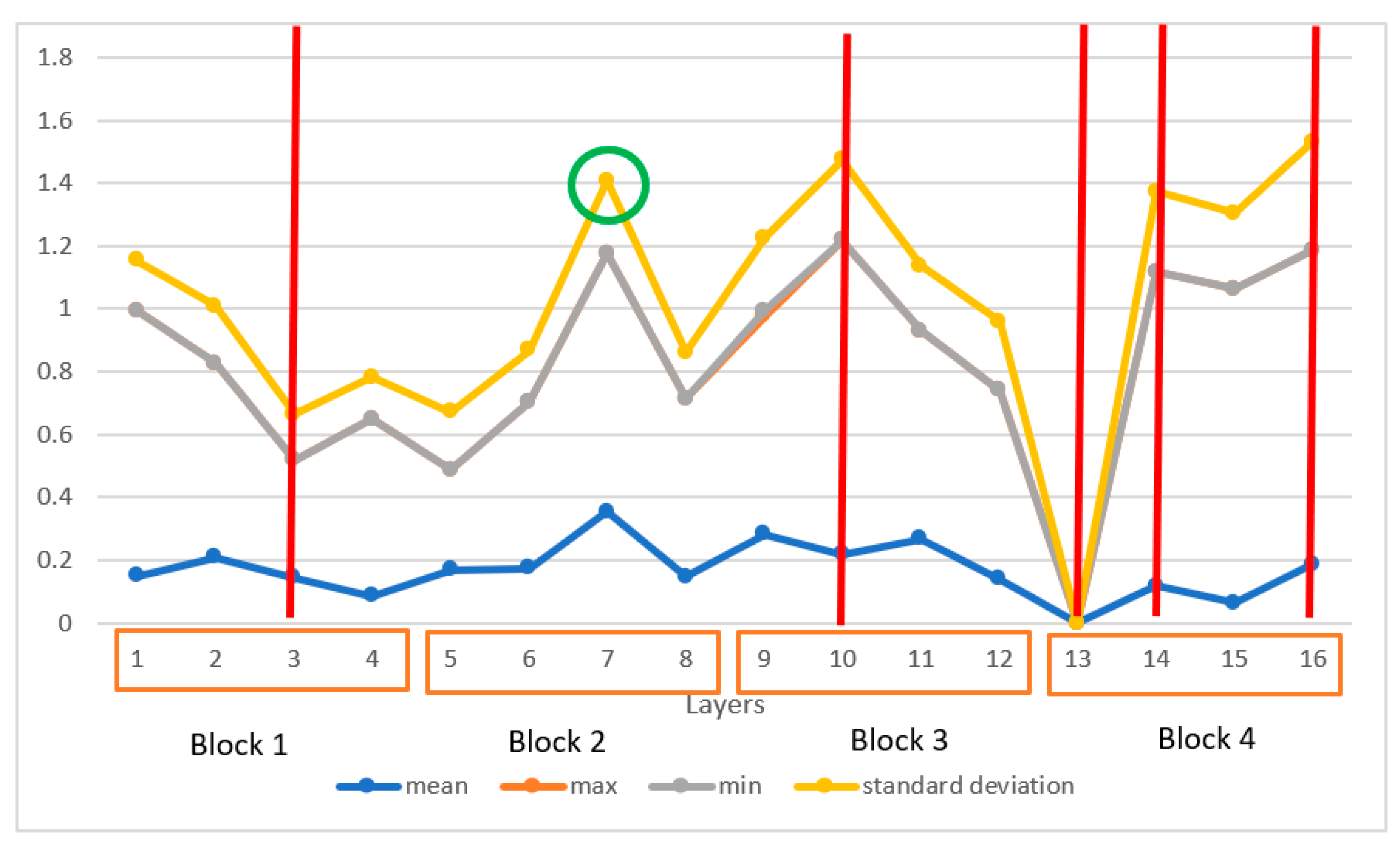
2.4. Model Optimization Based on Explainable Artificial Intelligence Metrics
2.4.1. Skip Connections
2.4.2. Attention Mechanism
2.4.3. Transfer Learning
2.4.4. Model Robustness Evaluation
3. Results
3.1. Explainable Artificial Intelligence Analysis Based on VGG16 Model for AMD Detection
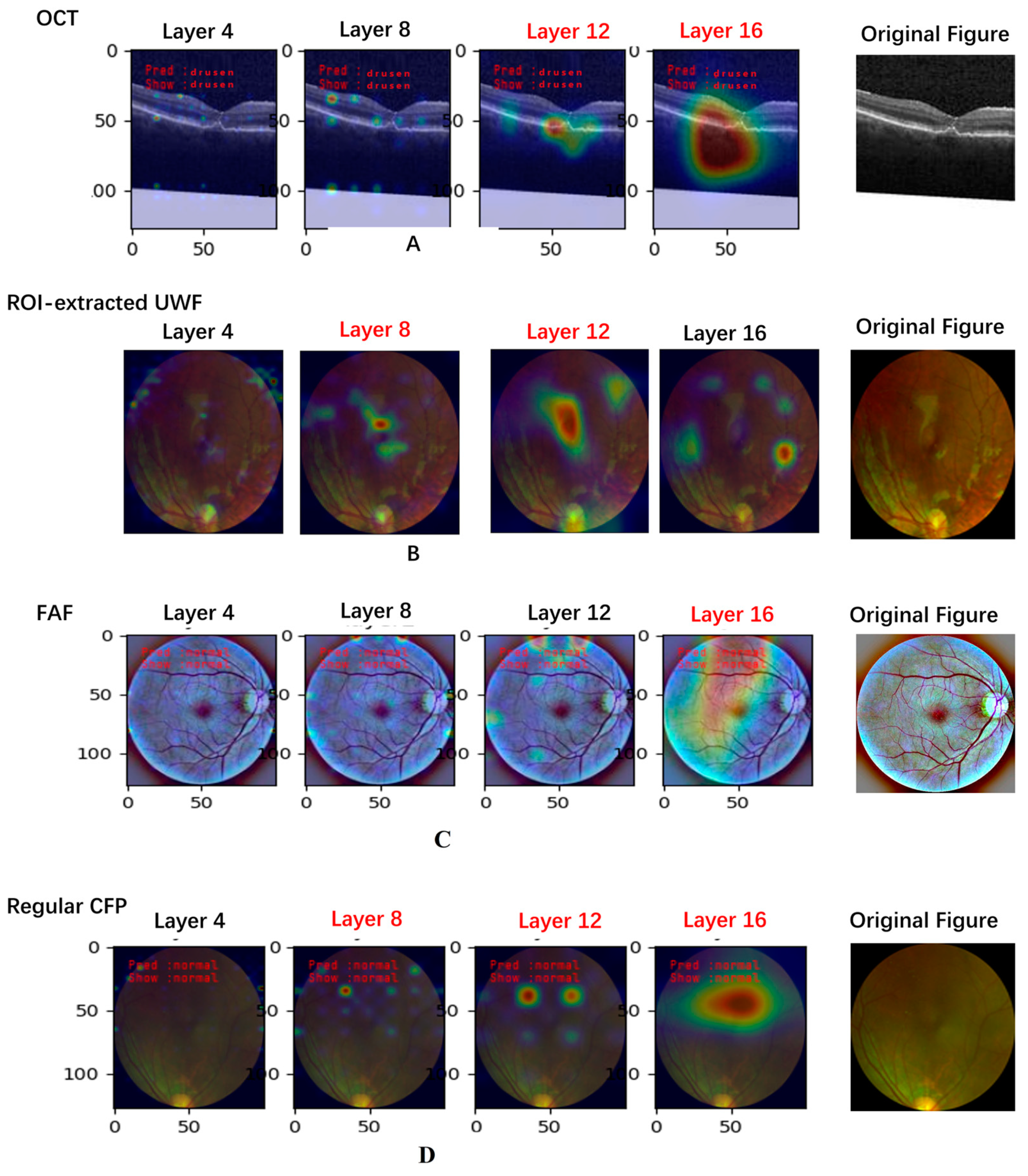
3.1.1. Explainable Artificial Intelligence Analysis Based on the Last Convolutional Layer of VGG16 Model
3.1.2. Retrospective Explainable Artificial Intelligence Analysis of VGG16 Model
3.2. Model Optimization Based on Explainable Artificial Intelligence Metrics
| Algorithm 2: Optimized VGG16 algorithm for AMD detection |
| Parameters: (OCT images); (regular CFP and FAF images) |
|
|
|
|
|
|
4. Discussions
5. Conclusions
6. Patents
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Grassmann, F.; Mengelkamp, J.; Brandl, C.; Harsch, S.; Zimmermann, M.E.; Linkohr, B.; Peters, A.; Heid, I.M.; Palm, C.; Weber, B.H. A Deep Learning Algorithm for Prediction of Age-Related Eye Disease Study Severity Scale for Age-Related Macular Degeneration from Color Fundus Photography. Ophthalmology 2018, 125, 1410–1420. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Glatz, M.; Riedl, R.; Glatz, W.; Schneider, M.; Wedrich, A.; Bolz, M.; Strauss, R.W. Blindness and visual impairment in Central Europe. PLoS ONE 2022, 17, e0261897. [Google Scholar] [CrossRef] [PubMed]
- Bourne, R.; Steinmetz, J.D.; Flaxman, S.; Briant, P.S.; Taylor, H.R.; Resnikoff, S.; Casson, R.J.; Abdoli, A.; Abu-Gharbieh, E.; Afshin, A.; et al. Trends in prevalence of blindness and distance and near vision impairment over 30 years: An analysis for the Global Burden of Disease Study. Lancet Glob. Health 2021, 9, e130–e143. [Google Scholar] [CrossRef] [PubMed]
- Keenan, T.D.; Cukras, C.A.; Chew, E.Y. Age-Related Macular Degeneration: Epidemiology and Clinical Aspects. Adv. Exp. Med. Biol. 2021, 1256, 1–31. [Google Scholar] [CrossRef] [PubMed]
- Adamis, A.P.; Brittain, C.J.; Dandekar, A.; Hopkins, J.J. Building on the success of anti-vascular endothelial growth factor therapy: A vision for the next decade. Eye 2020, 34, 1966–1972. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Layana, A.; Cabrera-López, F.; García-Arumí, J.; Arias-Barquet, L.; Ruiz-Moreno, J.M. Early and intermediate age-related macular degeneration: Update and clinical review. Clin. Interv. Aging 2017, 12, 1579–1587. [Google Scholar] [CrossRef] [Green Version]
- Wang, H. A Bibliographic Study and Quantitative Analysis of Age-related Macular Degeneration and Fundus Images. Ann. Ophthalmol. Vis. Sci. 2022, 5, 1–8. [Google Scholar]
- Hagiwara, Y.; Koh, J.E.W.; Tan, J.H.; Bhandary, S.V.; Laude, A.; Ciaccio, E.J.; Tong, L.; Acharya, U.R. Computer-aided diagnosis of glaucoma using fundus images: A review. Comput. Methods Programs Biomed. 2018, 165, 1–12. [Google Scholar] [CrossRef]
- Wang, H.; Chong, K.K.L.; Li, Z. Applications of AI to Age-Related Macular Degeneration: A case study and a brief review. In Proceedings of the 2022 International Conference on Computer Engineering and Artificial Intelligence (ICCEAI), Shijiazhuang, China, 22–24 July 2022; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar]
- Li, J.-P.O.; Liu, H.; Ting, D.S.J.; Jeon, S.; Chan, R.V.P.; Kim, J.E.; Sim, D.A.; Thomas, P.B.M.; Lin, H.; Chen, Y.; et al. Digital technology, tele-medicine and artificial intelligence in ophthalmology: A global perspective. Prog. Retin. Eye Res. 2021, 82, 100900. [Google Scholar] [CrossRef]
- Russakoff, D.B.; Lamin, A.; Oakley, J.D.; Dubis, A.M.; Sivaprasad, S. Deep Learning for Prediction of AMD Progression: A Pilot Study. Investig. Opthalmol. Vis. Sci. 2019, 60, 712–722. [Google Scholar] [CrossRef] [Green Version]
- Gutfleisch, M.; Ester, O.; Aydin, S.; Quassowski, M.; Spital, G.; Lommatzsch, A.; Rothaus, K.; Dubis, A.M.; Pauleikhoff, D. Clinically applicable deep learning-based decision aids for treatment of neovascular AMD. Graefe’s Arch. Clin. Exp. Ophthalmol. 2022, 260, 2217–2230. [Google Scholar] [CrossRef]
- Yan, Q.; Weeks, D.E.; Xin, H.; Swaroop, A.; Chew, E.Y.; Huang, H.; Ding, Y.; Chen, W. Deep-learning-based prediction of late age-related macular degeneration progression. Nat. Mach. Intell. 2020, 2, 141–150. [Google Scholar] [CrossRef] [PubMed]
- Serener, A.; Serte, S. Dry and wet age-related macular degeneration classification using oct images and deep learning. In Proceedings of the 2019 Scientific Meeting on Electrical-Electronics & Biomedical Engineering and Computer Science (EBBT), Istanbul, Turkey, 24–26 April 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Saha, S.; Nassisi, M.; Wang, M.; Lindenberg, S.; Kanagasingam, Y.; Sadda, S.; Hu, Z.J. Automated detection and classification of early AMD biomarkers using deep learning. Sci. Rep. 2019, 9, 10990. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, H.; Li, Z.; Xing, L.; Chong, K.K.; Zhou, X.; Wang, F.; Zhou, J.; Li, Z. A Bibliographic Study of Macular Fovea Detection: AI-Based Methods, Applications, and Issues. In Proceedings of the World Conference on Intelligent and 3-D Technologies (WCI3DT 2022) Methods, Algorithms and Applications; Springer: Singapore, 2023. [Google Scholar]
- Wang, M.H.; Yu, X. A Bibliographic Study of “Liver-Eye” Related Research:A Correlation Function Analytic Research between Age-Related Macular Degeneration (AMD) and Traditional Chinese Medicine (TCM) Liver Wind Internal Movement Syndrome. Adv. Clin. Med. 2023, 13, 6342. [Google Scholar] [CrossRef]
- Ravi, V.; Narasimhan, H.; Chakraborty, C.; Pham, T.D. Deep learning-based meta-classifier approach for COVID-19 classification using CT scan and chest X-ray images. Multimed. Syst. 2022, 28, 1401–1415. [Google Scholar] [CrossRef]
- Holzinger, A.; Dehmer, M.; Emmert-Streib, F.; Cucchiara, R.; Augenstein, I.; Del Ser, J.; Samek, W.; Jurisica, I.; Díaz-Rodríguez, N. Information fusion as an integrative cross-cutting enabler to achieve robust, explainable, and trustworthy medical artificial intelligence. Inf. Fusion 2022, 79, 263–278. [Google Scholar] [CrossRef]
- Wang, H. A Survey of AI to AMD and Quantitative Analysis of AMD Pathology Based on Medical Images. Artif. Intell. Robot. Res. 2022, 11, 143–157. [Google Scholar]
- García-Floriano, A.; Ferreira-Santiago, Á.; Camacho-Nieto, O.; Yáñez-Márquez, C. A machine learning approach to medical image classification: Detecting age-related macular degeneration in fundus images. Comput. Electr. Eng. 2019, 75, 218–229. [Google Scholar] [CrossRef]
- Salehi, M.A.; Mohammadi, S.; Gouravani, M.; Rezagholi, F.; Arevalo, J.F. Retinal and choroidal changes in AMD: A systematic review and meta-analysis of spectral-domain optical coherence tomography studies. Surv. Ophthalmol. 2022, 68, 54–66. [Google Scholar] [CrossRef]
- Gualino, V.; Tadayoni, R.; Cohen, S.Y.; Erginay, A.; Fajnkuchen, F.; Haouchine, B.; Krivosic, V.; Quentel, G.; Vicaut, E.; Gaudric, A. Optical coherence tomography, fluorescein angiography, and diagnosis of choroidal neovascularization in age-related macular degeneration. Retina 2019, 39, 1664–1671. [Google Scholar] [CrossRef]
- Oh, K.; Kang, H.M.; Leem, D.; Lee, H.; Seo, K.Y.; Yoon, S. Early detection of diabetic retinopathy based on deep learning and ultra-wide-field fundus images. Sci. Rep. 2021, 11, 1897. [Google Scholar] [CrossRef]
- Yang, J.; Fong, S.; Wang, H.; Hu, Q.; Lin, C.; Huang, S.; Shi, J.; Lan, K.; Tang, R.; Wu, Y.; et al. Artificial intelligence in ophthalmopathy and ultra-wide field image: A survey. Expert Syst. Appl. 2021, 182, 115068. [Google Scholar] [CrossRef]
- Matsuba, S.; Tabuchi, H.; Ohsugi, H.; Enno, H.; Ishitobi, N.; Masumoto, H.; Kiuchi, Y. Accuracy of ultra-wide-field fundus ophthalmoscopy-assisted deep learning, a machine-learning technology, for detecting age-related macular degeneration. Int. Ophthalmol. 2019, 39, 1269–1275. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, H.; Ji, Y. Adversarial Training for Improving Model Robustness? Look at Both Prediction and Interpretation. Proc. Conf. AAAI Artif. Intell. 2022, 36, 10463–10472. [Google Scholar] [CrossRef]
- Lim, J.S.; Hong, M.; Lam, W.S.; Zhang, Z.; Teo, Z.L.; Liu, Y.; Ng, W.Y.; Foo, L.L.; Ting, D.S. Novel technical and privacy-preserving technology for artificial intelligence in ophthalmology. Curr. Opin. Ophthalmol. 2022, 33, 174–187. [Google Scholar] [CrossRef]
- Ting, D.S.; Peng, L.; Varadarajan, A.V.; Keane, P.A.; Burlina, P.M.; Chiang, M.F.; Schmetterer, L.; Pasquale, L.R.; Bressler, N.M.; Webster, D.R.; et al. Deep learning in ophthalmology: The technical and clinical considerations. Prog. Retin. Eye Res. 2019, 72, 100759. [Google Scholar] [CrossRef]
- Karnowski, T.P.; Aykac, D.; Giancardo, L.; Li, Y.; Nichols, T.; Tobin, K.W.; Chaum, E. Automatic detection of retina disease: Robustness to image quality and localization of anatomy structure. In Proceedings of the 2011 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Boston, MA, USA, 30 August–3 September 2011; IEEE: Piscataway, NJ, USA, 2011. [Google Scholar]
- Kamran, S.A.; Tavakkoli, A.; Zuckerbrod, S.L. Improving robustness using joint attention network for detecting retinal degeneration from optical coherence tomography images. In Proceedings of the 2020 IEEE International Conference On Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Hahn, T.; Pyeon, M.; Kim, G. Self-routing capsule networks. Adv. Neural Inf. Process. Syst. 2019, 32, 1–10. [Google Scholar]
- Liang, Y.; Li, B.; Jiao, B. A deep learning method for motor fault diagnosis based on a capsule network with gate-structure dilated convolutions. Neural Comput. Appl. 2021, 33, 1401–1418. [Google Scholar] [CrossRef]
- Tjoa, E.; Guan, C. A Survey on Explainable Artificial Intelligence (XAI): Toward Medical XAI. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4793–4813. [Google Scholar] [CrossRef]
- Hagras, H. Toward Human-Understandable, Explainable AI. Computer 2018, 51, 28–36. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Mooney, P. Retinal OCT Images (Optical Coherence Tomography); Kaggle: San Francisco, CA, USA, 2018. [Google Scholar]
- Naren, O.S. Retinal OCT—C8; Kaggle: San Francisco, CA, USA, 2021. [Google Scholar]
- K-S-Sanjay-Nithish. Retinal Fundus Images; Kaggle: San Francisco, CA, USA, 2021. [Google Scholar]
- Larxel. Retinal Disease Classification; Kaggle: San Francisco, CA, USA, 2021. [Google Scholar]
- Larxel. Ocular Disease Recognition; Kaggle: San Francisco, CA, USA, 2020. [Google Scholar]
- Yi, X.; Walia, E.; Babyn, P. Generative adversarial network in medical imaging: A review. Med Image Anal. 2019, 58, 101552. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yoo, T.K.; Choi, J.Y.; Kim, H.K. A generative adversarial network approach to predicting postoperative appearance after orbital decompression surgery for thyroid eye disease. Comput. Biol. Med. 2020, 118, 103628. [Google Scholar] [CrossRef] [PubMed]
- Kadry, S.; Rajinikanth, V.; Crespo, R.G.; Verdú, E. Automated detection of age-related macular degeneration using a pre-trained deep-learning scheme. J. Supercomput. 2022, 78, 7321–7340. [Google Scholar] [CrossRef]
- Ye, L.-Y.; Miao, X.-Y.; Cai, W.-S.; Xu, W.-J. Medical image diagnosis of prostate tumor based on PSP-Net+VGG16 deep learning network. Comput. Methods Programs Biomed. 2022, 221, 106770. [Google Scholar] [CrossRef]
- Bae, W.; Noh, J.; Kim, G. Rethinking class activation mapping for weakly supervised object localization. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28 2020, Proceedings, Part XV 16; Springer: Berlin, Germany, 2020. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 839–847. [Google Scholar]
- Jiang, P.-T.; Zhang, C.-B.; Hou, Q.; Cheng, M.-M.; Wei, Y. LayerCAM: Exploring Hierarchical Class Activation Maps for Localization. IEEE Trans. Image Process. 2021, 30, 5875–5888. [Google Scholar] [CrossRef]
- Mohseni, S.; Zarei, N.; Ragan, E.D. A Multidisciplinary Survey and Framework for Design and Evaluation of Explainable AI Systems. ACM Trans. Interact. Intell. Syst. 2021, 11, 24. [Google Scholar] [CrossRef]
- Mao, X.; Shen, C.; Yang, Y.B. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee MM, R.; Tajbakhsh, N.; Liang, J. Unet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar] [CrossRef] [Green Version]
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Yan, Y.; Jin, K.; Gao, Z.; Huang, X.; Wang, F.; Wang, Y.; Ye, J. Attention-based deep learning system for automated diagnoses of age-related macular degeneration in optical coherence tomography images. Med. Phys. 2021, 48, 4926–4934. [Google Scholar] [CrossRef]
- Gour, N.; Khanna, P. Multi-class multi-label ophthalmological disease detection using transfer learning based convolutional neural network. Biomed. Signal Process. Control 2021, 66, 102329. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Brendel, W.; Rauber, J.; Kümmerer, M.; Ustyuzhaninov, I.; Bethge, M. Accurate, reliable and fast robustness evaluation. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Qin, C.; Martens, J.; Gowal, S.; Krishnan, D.; Dvijotham, K.; Fawzi, A.; De, S.; Stanforth, R.; Kohli, P. Adversarial robustness through local linearization. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Li, Z.; Caro, J.O.; Rusak, E.; Brendel, W.; Bethge, M.; Anselmi, F.; Patel, A.B.; Tolias, A.S.; Pitkow, X. Robust deep learning object recognition models rely on low frequency information in natural images. PLoS Comput. Biol. 2023, 19, e1010932. [Google Scholar] [CrossRef]
- Saarela, M.; Geogieva, L. Robustness, Stability, and Fidelity of Explanations for a Deep Skin Cancer Classification Model. Appl. Sci. 2022, 12, 9545. [Google Scholar] [CrossRef]
- Al-Essa, M.; Andresini, G.; Appice, A.; Malerba, D. XAI to Explore Robustness of Features in Adversarial Training for Cybersecurity. In Foundations of Intelligent Systems: 26th International Symposium, ISMIS 2022, Cosenza, Italy, 3–5 October 2022, Proceedings; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Bradshaw, T.J.; McCradden, M.D.; Jha, A.K.; Dutta, J.; Saboury, B.; Siegel, E.L.; Rahmim, A. Artificial Intelligence Algorithms Need to Be Explainable—Or Do They? J. Nucl. Med. 2023, 64, 976–977. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Type | Layers | |||
|---|---|---|---|---|
| 4 | 8 | 12 | 16/Output | |
| OCT | 0.24 | 0.38 | 0.64 | 0.58 |
| Segmented OCT | 1 | 0.9 | 0.94 | 1 |
| FAF | 0.78 | 0.69 | 0.54 | 0.57 |
| Regular CFP | 0.65 | 0.77 | 0.41 | 0.36 |
| ROI-extracted UWF | 0.86 | 0.76 | 0.84 | 0.89 |
| Methods | Data Type | Loss | Accuracy for the Training and Validation Dataset | Accuracy for the Unseen Testing Dataset | Sensitivity | Specificity | AUC | XAI Indicator | Test Time/Second (Per Image) |
|---|---|---|---|---|---|---|---|---|---|
| Original VGG16 | OCT | 0.024 | 100% | 82% | 74% | 60% | 88.11% | 0.5 | 0.084 |
| Segmented OCT | 0.015 | 100% | 90% | 89% | 91% | 91.01% | 1 | 0.112 | |
| FAF | 0.044 | 100% | 97% | 94% | 95% | 90.72% | 0.5 | 0.117 | |
| Regular CFP | 0.217 | 99.58% | 57% | 61% | 46% | 80.88% | 0.3 | 0.067 | |
| ROI-extracted UWF | 0.009 | 100% | 81% | 83% | 79% | 86.994% | 0.9 | 0.099 | |
| Average values for all data types | 0.024 | 100% | 82% | 80% | 74% | 90.772% | 0.64 | 0.084 | |
| Improved VGG16 | OCT | 0.012 | 100% | 90.6% | 91% | 89.1% | 91.4% | 0.64 | 0.07 |
| End-cut-OCT | 0.002 | 98.9% | 94.6% | 96% | 96% | 94.14% | 0.6 | 0.45 | |
| Segmented OCT | 0.001 | 100.0% | 99.0% | 100% | 99% | 99.75% | 1 | 0.06 | |
| Regular CFP | 0.011 | 98.7% | 93.7% | 91% | 96% | 96.10% | 0.8 | 0.21 | |
| ROI-extracted UWF | 0.007 | 99.7% | 91.2% | 94% | 96% | 84.25% | 0.9 | 0.15 | |
| FAF with transfer | 0.001 | 100.0% | 99.2% | 100% | 99% | 98.62% | 0.9 | 0.12 | |
| FAF without transfer | 0.011 | 100.0% | 100% | 100% | 100% | 94.62% | 0.84 | 0.12 | |
| Average values for all data types | 0.55% | 99.55% | 96.62% | 96% | 96% | 94.58% | 84.00% | 18.50% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, M.H.; Chong, K.K.-l.; Lin, Z.; Yu, X.; Pan, Y. An Explainable Artificial Intelligence-Based Robustness Optimization Approach for Age-Related Macular Degeneration Detection Based on Medical IOT Systems. Electronics 2023, 12, 2697. https://doi.org/10.3390/electronics12122697
Wang MH, Chong KK-l, Lin Z, Yu X, Pan Y. An Explainable Artificial Intelligence-Based Robustness Optimization Approach for Age-Related Macular Degeneration Detection Based on Medical IOT Systems. Electronics. 2023; 12(12):2697. https://doi.org/10.3390/electronics12122697
Chicago/Turabian StyleWang, Mini Han, Kelvin Kam-lung Chong, Zhiyuan Lin, Xiangrong Yu, and Yi Pan. 2023. "An Explainable Artificial Intelligence-Based Robustness Optimization Approach for Age-Related Macular Degeneration Detection Based on Medical IOT Systems" Electronics 12, no. 12: 2697. https://doi.org/10.3390/electronics12122697
APA StyleWang, M. H., Chong, K. K.-l., Lin, Z., Yu, X., & Pan, Y. (2023). An Explainable Artificial Intelligence-Based Robustness Optimization Approach for Age-Related Macular Degeneration Detection Based on Medical IOT Systems. Electronics, 12(12), 2697. https://doi.org/10.3390/electronics12122697