

Sign Language Translation: A Survey of Approaches and Techniques

Abstract
:1. Introduction
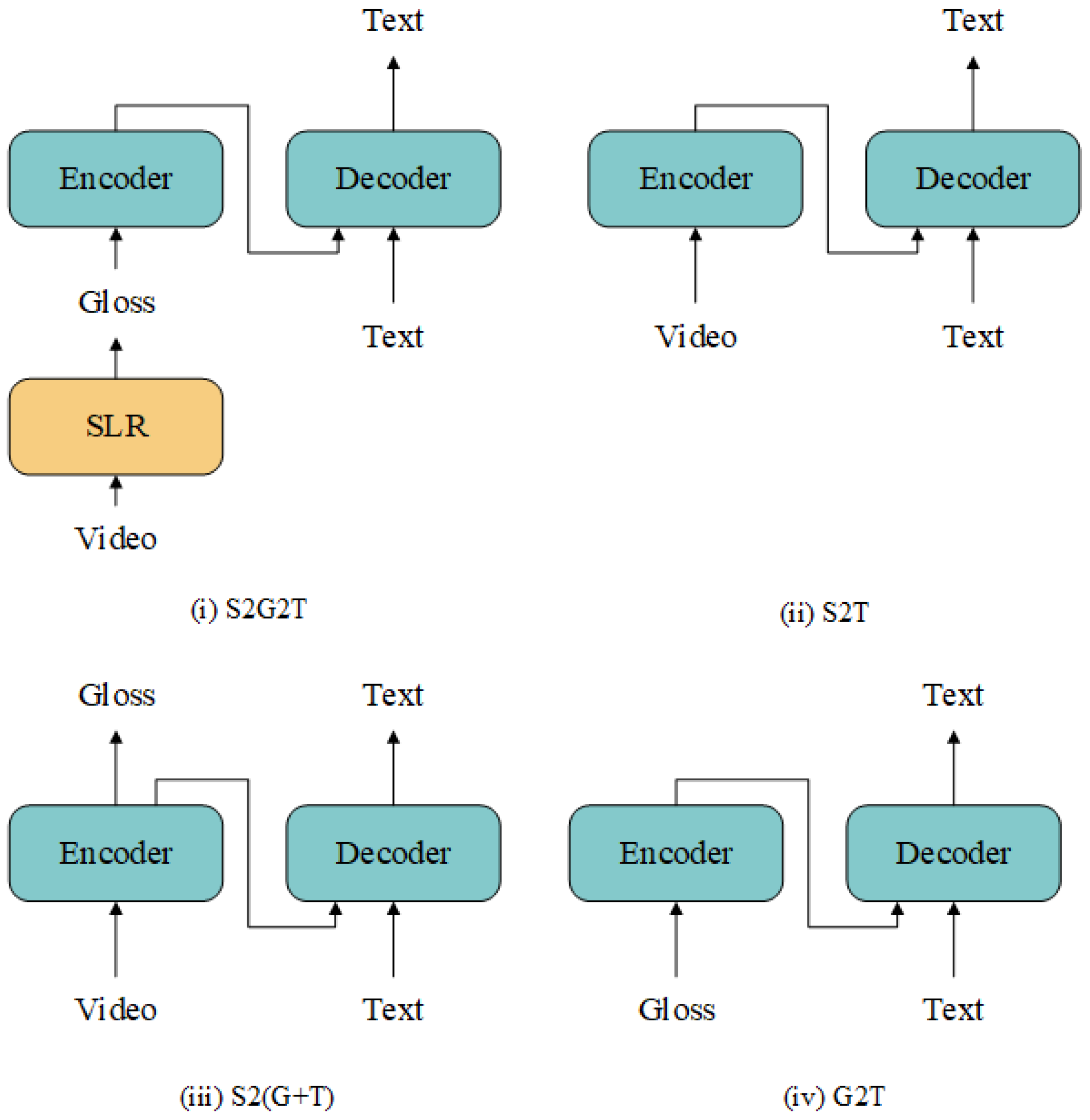
- Sign2text (S2T), which directly generates spoken language text from sign language video end to end.
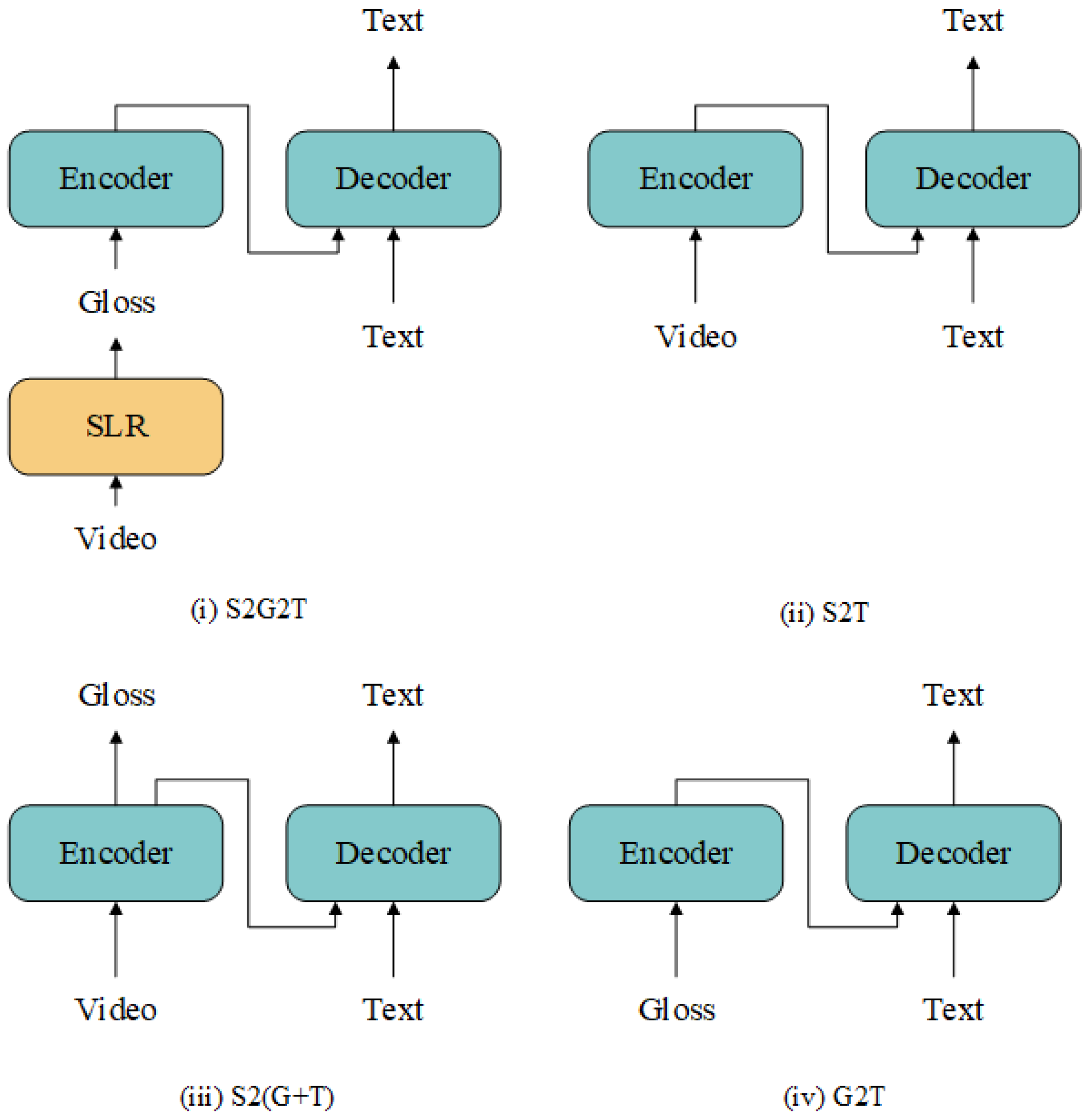
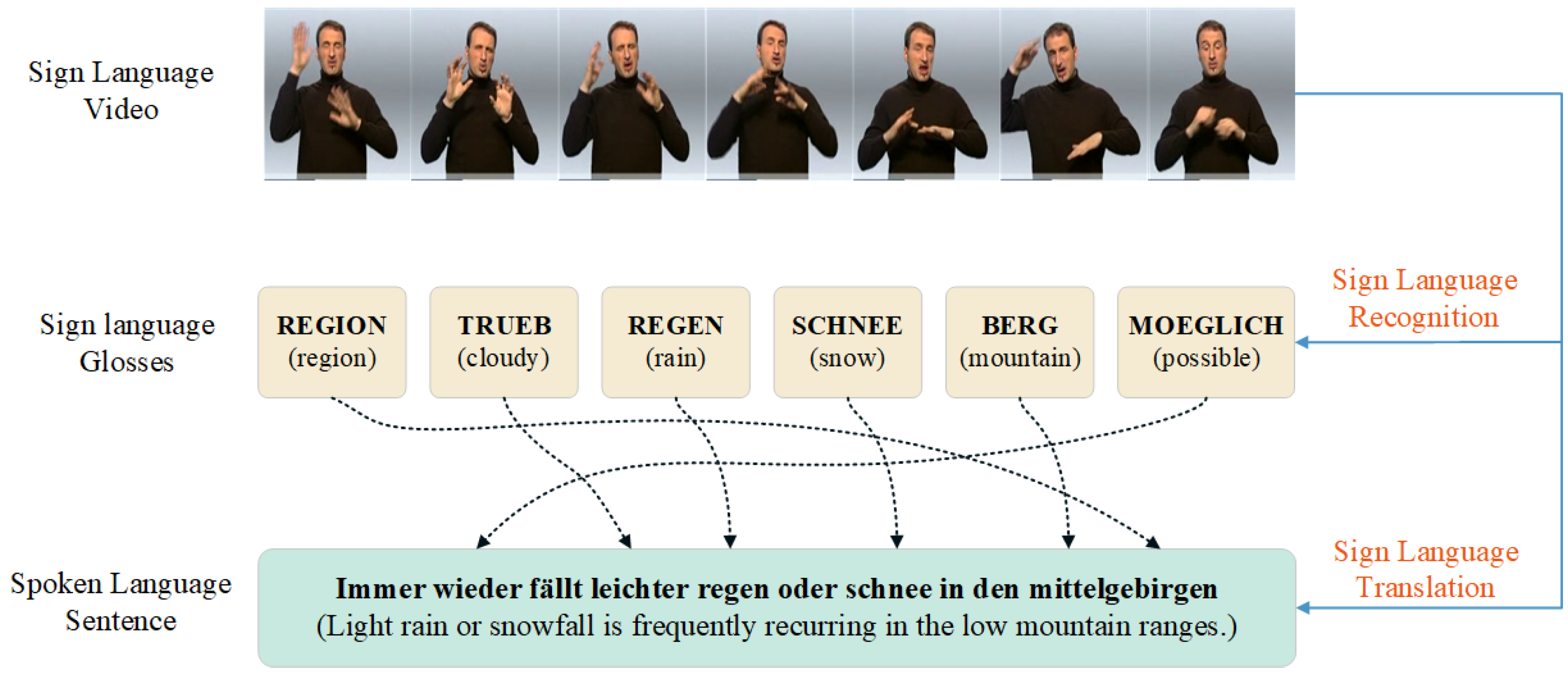
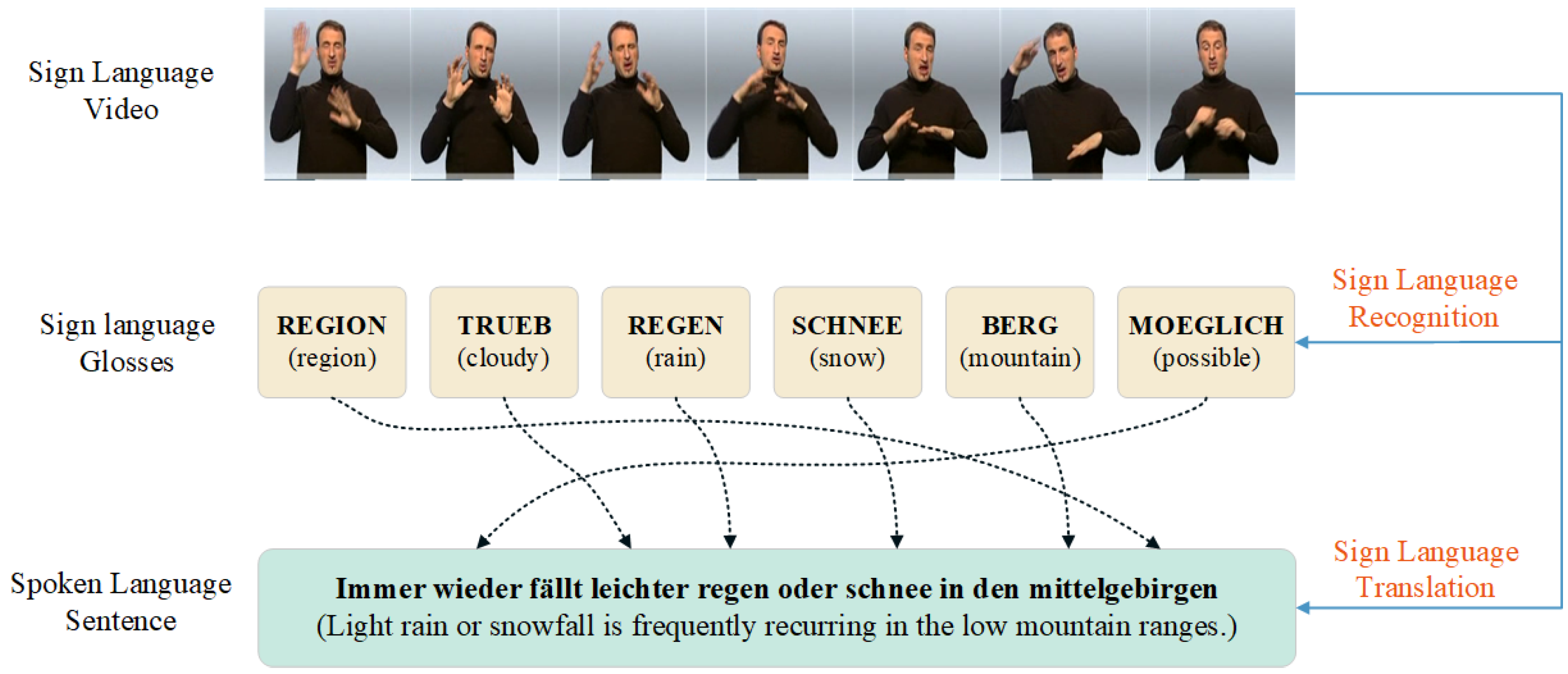
2. The Background of SLT
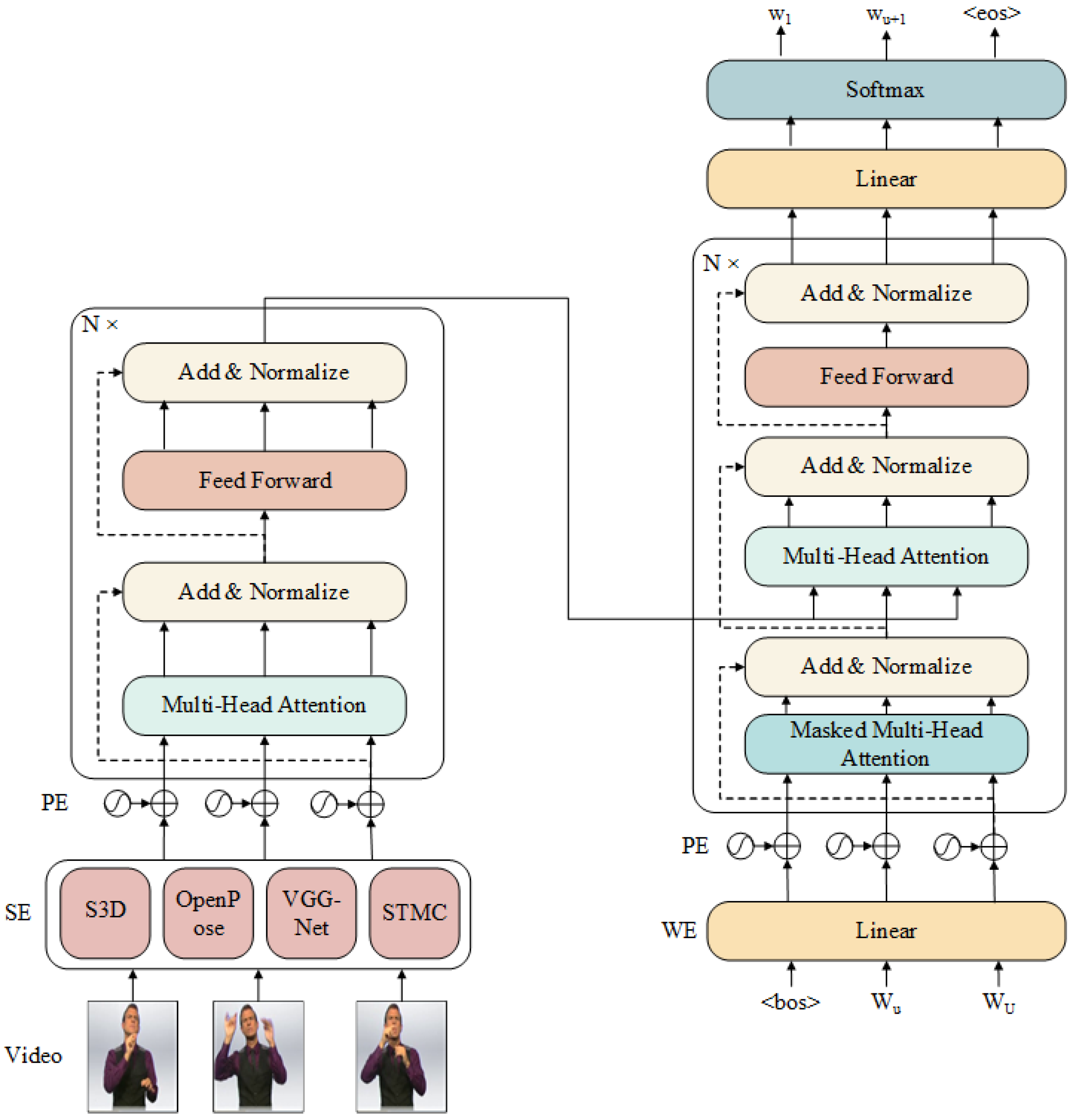
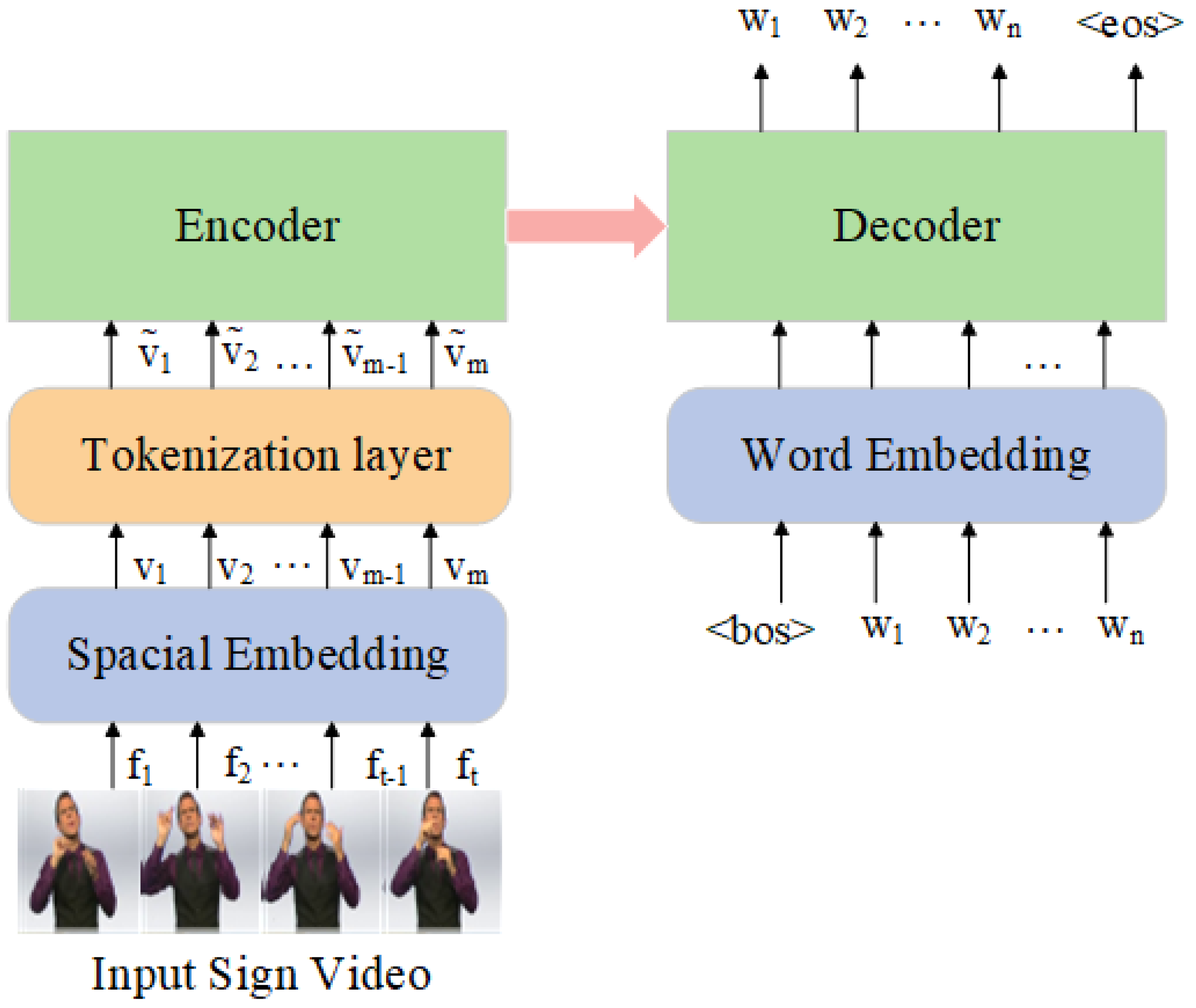
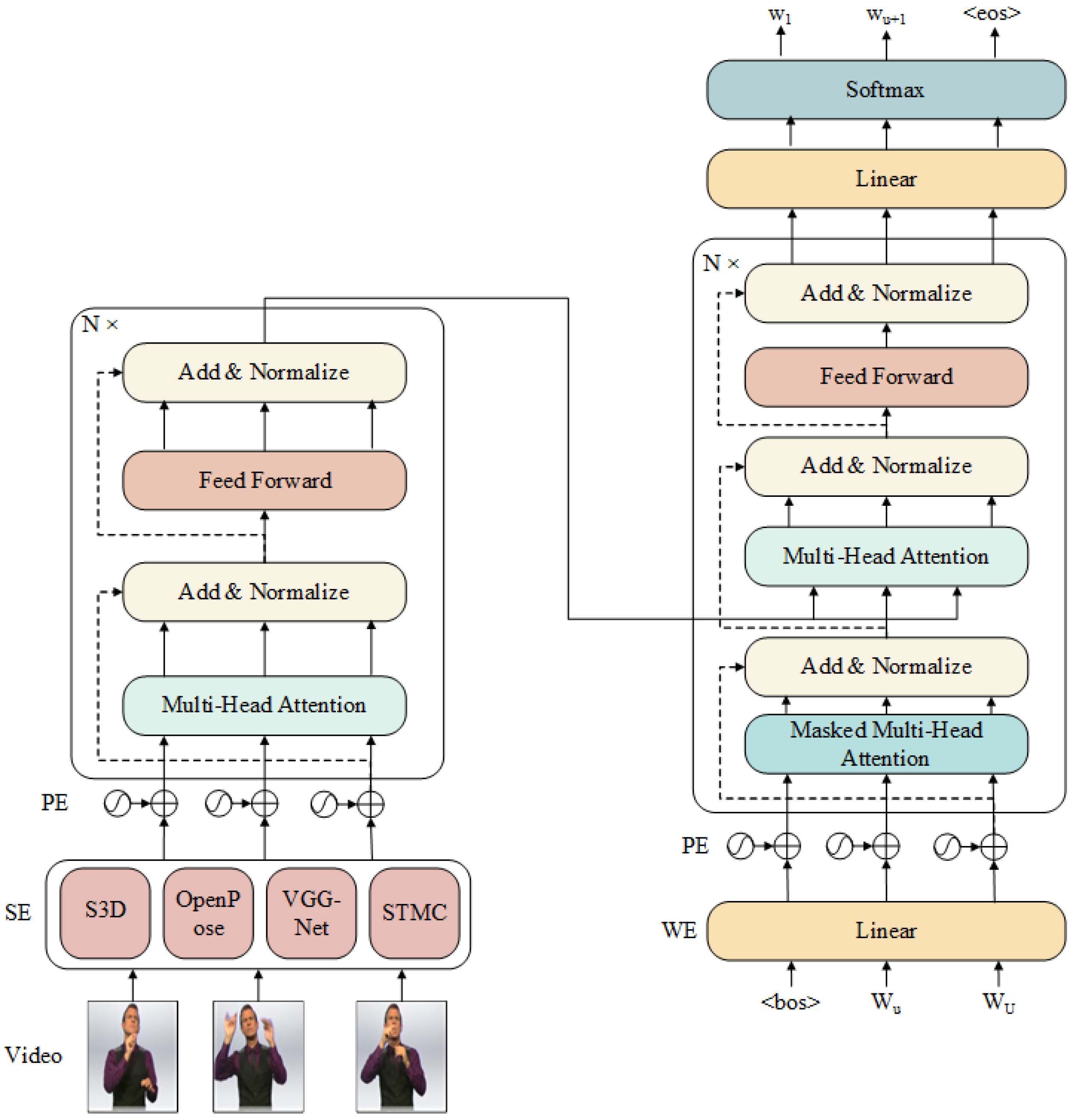
- Spatial and word embedding layers, which map the sign language video frames and spoken text into feature vectors or dense vectors, respectively.
- A tokenization layer, which tokenizes the feature vectors.
- The encoder–decoder module, which predicts the spoken text and adjusts the network parameters through backpropagation to reduce the difference between the target text and generated text.
3. Literature Review of SLT
3.1. Improving the Performance of SLR
3.2. Network Structure for Improving the Performance of Translation
3.3. Solving the Problem of the Scarcity of Sign Language
4. Datasets
5. Metrics
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhou, H.; Zhou, W.; Zhou, Y.; Li, H. Spatial-temporal multi-cue network for continuous sign language recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13009–13016. [Google Scholar]
- Rodriguez, J.; Martínez, F. How important is motion in sign language translation? IET Comput. Vis. 2021, 15, 224–234. [Google Scholar] [CrossRef]
- Zheng, J.; Chen, Y.; Wu, C.; Shi, X.; Kamal, S.M. Enhancing neural sign language translation by highlighting the facial expression information. Neurocomputing 2021, 464, 462–472. [Google Scholar] [CrossRef]
- Li, D.; Xu, C.; Yu, X.; Zhang, K.; Swift, B.; Suominen, H.; Li, H. Tspnet: Hierarchical feature learning via temporal semantic pyramid for sign language translation. Adv. Neural Inf. Process. Syst. 2020, 33, 12034–12045. [Google Scholar]
- Núñez-Marcos, A.; Perez-de Viñaspre, O.; Labaka, G. A survey on Sign Language machine translation. Expert Syst. Appl. 2022, 213, 118993. [Google Scholar] [CrossRef]
- Cui, R.; Liu, H.; Zhang, C. Recurrent convolutional neural networks for continuous sign language recognition by staged optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7361–7369. [Google Scholar]
- Cihan Camgoz, N.; Hadfield, S.; Koller, O.; Bowden, R. Subunets: End-to-end hand shape and continuous sign language recognition. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3056–3065. [Google Scholar]
- Koller, O.; Zargaran, S.; Ney, H.; Bowden, R. Deep sign: Enabling robust statistical continuous sign language recognition via hybrid CNN-HMMs. Int. J. Comput. Vis. 2018, 126, 1311–1325. [Google Scholar] [CrossRef] [Green Version]
- Camgoz, N.C.; Hadfield, S.; Koller, O.; Ney, H.; Bowden, R. Neural sign language translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7784–7793. [Google Scholar]
- Ananthanarayana, T.; Srivastava, P.; Chintha, A.; Santha, A.; Landy, B.; Panaro, J.; Webster, A.; Kotecha, N.; Sah, S.; Sarchet, T.; et al. Deep learning methods for sign language translation. ACM Trans. Access. Comput. (TACCESS) 2021, 14, 1–30. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, W.; Xie, C.; Pu, J.; Li, H. Chinese sign language recognition with adaptive HMM. In Proceedings of the 2016 IEEE International Conference on Multimedia and Expo (ICME), Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar]
- Hu, H.; Zhou, W.; Li, H. Hand-model-aware sign language recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 1558–1566. [Google Scholar]
- Wu, D.; Pigou, L.; Kindermans, P.J.; Le, N.D.H.; Shao, L.; Dambre, J.; Odobez, J.M. Deep dynamic neural networks for multimodal gesture segmentation and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1583–1597. [Google Scholar] [CrossRef] [Green Version]
- Koller, O.; Ney, H.; Bowden, R. Deep hand: How to train a cnn on 1 million hand images when your data is continuous and weakly labelled. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3793–3802. [Google Scholar]
- Yin, Q.; Tao, W.; Liu, X.; Hong, Y. Neural Sign Language Translation with SF-Transformer. In Proceedings of the 2022 the 6th International Conference on Innovation in Artificial Intelligence (ICIAI), Guangzhou, China, 4–6 March 2022; pp. 64–68. [Google Scholar]
- Camgoz, N.C.; Koller, O.; Hadfield, S.; Bowden, R. Sign language transformers: Joint end-to-end sign language recognition and translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10023–10033. [Google Scholar]
- Yin, K.; Read, J. Better sign language translation with STMC-transformer. arXiv 2020, arXiv:2004.00588. [Google Scholar]
- Kumar, S.S.; Wangyal, T.; Saboo, V.; Srinath, R. Time series neural networks for real time sign language translation. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 243–248. [Google Scholar]
- Zhou, H.; Zhou, W.; Qi, W.; Pu, J.; Li, H. Improving sign language translation with monolingual data by sign back-translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1316–1325. [Google Scholar]
- Zhou, H.; Zhou, W.; Zhou, Y.; Li, H. Spatial-temporal multi-cue network for sign language recognition and translation. IEEE Trans. Multimed. 2021, 24, 768–779. [Google Scholar] [CrossRef]
- De Coster, M.; D’Oosterlinck, K.; Pizurica, M.; Rabaey, P.; Verlinden, S.; Van Herreweghe, M.; Dambre, J. Frozen pretrained transformers for neural sign language translation. In Proceedings of the 18th Biennial Machine Translation Summit (MT Summit 2021), Virtual, 16–20 August 2021; pp. 88–97. [Google Scholar]
- Moryossef, A.; Yin, K.; Neubig, G.; Goldberg, Y. Data augmentation for sign language gloss translation. arXiv 2021, arXiv:2105.07476. [Google Scholar]
- Zhang, X.; Duh, K. Approaching sign language gloss translation as a low-resource machine translation task. In Proceedings of the 1st International Workshop on Automatic Translation for Signed and Spoken Languages (AT4SSL), Virtual, 20 August 2021; pp. 60–70. [Google Scholar]
- Cao, Y.; Li, W.; Li, X.; Chen, M.; Chen, G.; Hu, L.; Li, Z.; Kai, H. Explore more guidance: A task-aware instruction network for sign language translation enhanced with data augmentation. arXiv 2022, arXiv:2204.05953. [Google Scholar]
- Minu, R. A Extensive Survey on Sign Language Recognition Methods. In Proceedings of the 2023 7th International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 23–25 February 2023; pp. 613–619. [Google Scholar]
- Baumgärtner, L.; Jauss, S.; Maucher, J.; Zimmermann, G. Automated Sign Language Translation: The Role of Artificial Intelligence Now and in the Future. In Proceedings of the CHIRA, Virtual Event, 5–6 November 2020; pp. 170–177. [Google Scholar]
- Koller, O. Quantitative survey of the state of the art in sign language recognition. arXiv 2020, arXiv:2008.09918. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Liang, Z.; Du, J. Sequence to sequence learning for joint extraction of entities and relations. Neurocomputing 2022, 501, 480–488. [Google Scholar] [CrossRef]
- Liang, Z.; Du, J.; Shao, Y.; Ji, H. Gated graph neural attention networks for abstractive summarization. Neurocomputing 2021, 431, 128–136. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Xie, S.; Sun, C.; Huang, J.; Tu, Z.; Murphy, K. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 305–321. [Google Scholar]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime multi-person 2D pose estimation using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, S. Research of a sign language translation system based on deep learning. In Proceedings of the 2019 International Conference on Artificial Intelligence and Advanced Manufacturing (AIAM), Dublin, Ireland, 17–19 October 2019; pp. 392–396. [Google Scholar]
- Guo, D.; Zhou, W.; Li, A.; Li, H.; Wang, M. Hierarchical recurrent deep fusion using adaptive clip summarization for sign language translation. IEEE Trans. Image Process. 2019, 29, 1575–1590. [Google Scholar] [CrossRef]
- Gan, S.; Yin, Y.; Jiang, Z.; Xie, L.; Lu, S. Skeleton-aware neural sign language translation. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 4353–4361. [Google Scholar]
- Kim, S.; Kim, C.J.; Park, H.M.; Jeong, Y.; Jang, J.Y.; Jung, H. Robust keypoint normalization method for Korean sign language translation using transformer. In Proceedings of the 2020 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 21–23 October 2020; pp. 1303–1305. [Google Scholar]
- Ko, S.K.; Kim, C.J.; Jung, H.; Cho, C. Neural sign language translation based on human keypoint estimation. Appl. Sci. 2019, 9, 2683. [Google Scholar] [CrossRef] [Green Version]
- Guo, D.; Zhou, W.; Li, H.; Wang, M. Hierarchical LSTM for sign language translation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–3 February 2018; Volume 32. [Google Scholar]
- Huang, J.; Zhou, W.; Zhang, Q.; Li, H.; Li, W. Video-based sign language recognition without temporal segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–3 February 2018; Volume 32. [Google Scholar]
- Parton, B.S. Sign language recognition and translation: A multidisciplined approach from the field of artificial intelligence. J. Deaf Stud. Deaf Educ. 2006, 11, 94–101. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Camgoz, N.C.; Koller, O.; Hadfield, S.; Bowden, R. Multi-channel transformers for multi-articulatory sign language translation. In Proceedings of the Computer Vision–ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; Proceedings, Part IV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 301–319. [Google Scholar]
- Kan, J.; Hu, K.; Hagenbuchner, M.; Tsoi, A.C.; Bennamoun, M.; Wang, Z. Sign language translation with hierarchical spatio-temporal graph neural network. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 3367–3376. [Google Scholar]
- Wang, S.; Guo, D.; Zhou, W.G.; Zha, Z.J.; Wang, M. Connectionist temporal fusion for sign language translation. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 26 October 2018; pp. 1483–1491. [Google Scholar]
- Guo, D.; Wang, S.; Tian, Q.; Wang, M. Dense Temporal Convolution Network for Sign Language Translation. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 744–750. [Google Scholar]
- Song, P.; Guo, D.; Xin, H.; Wang, M. Parallel temporal encoder for sign language translation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1915–1919. [Google Scholar]
- Fang, B.; Co, J.; Zhang, M. Deepasl: Enabling ubiquitous and non-intrusive word and sentence-level sign language translation. In Proceedings of the 15th ACM Conference on Embedded Network Sensor Systems, Delft, The Netherlands, 6–8 November 2017; pp. 1–13. [Google Scholar]
- Arvanitis, N.; Constantinopoulos, C.; Kosmopoulos, D. Translation of sign language glosses to text using sequence-to-sequence attention models. In Proceedings of the 2019 15th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Sorrento, Italy, 26–29 November 2019; pp. 296–302. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Kalchbrenner, N.; Blunsom, P. Recurrent continuous translation models. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1700–1709. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. arXiv 2014, arXiv:1409.3215. [Google Scholar]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal convolutional networks for action segmentation and detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 156–165. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Yin, K.; Read, J. Attention Is All You Sign: Sign Language Translation with Transformers. Available online: https://www.slrtp.com/papers/extended_abstracts/SLRTP.EA.12.009.paper.pdf (accessed on 12 May 2023).
- Zheng, J.; Zhao, Z.; Chen, M.; Chen, J.; Wu, C.; Chen, Y.; Shi, X.; Tong, Y. An improved sign language translation model with explainable adaptations for processing long sign sentences. Comput. Intell. Neurosci. 2020, 2020, 8816125. [Google Scholar] [CrossRef] [PubMed]
- Voskou, A.; Panousis, K.P.; Kosmopoulos, D.; Metaxas, D.N.; Chatzis, S. Stochastic transformer networks with linear competing units: Application to end-to-end sl translation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11946–11955. [Google Scholar]
- Qin, W.; Mei, X.; Chen, Y.; Zhang, Q.; Yao, Y.; Hu, S. Sign language recognition and translation method based on VTN. In Proceedings of the 2021 International Conference on Digital Society and Intelligent Systems (DSInS), Chengdu, China, 19–21 November 2021; pp. 111–115. [Google Scholar]
- Yin, A.; Zhao, Z.; Jin, W.; Zhang, M.; Zeng, X.; He, X. MLSLT: Towards Multilingual Sign Language Translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5109–5119. [Google Scholar]
- Guo, Z.; Hou, Y.; Hou, C.; Yin, W. Locality-Aware Transformer for Video-Based Sign Language Translation. IEEE Signal Process. Lett. 2023, 30, 364–368. [Google Scholar] [CrossRef]
- Orbay, A.; Akarun, L. Neural sign language translation by learning tokenization. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020; pp. 222–228. [Google Scholar]
- De Coster, M.; Dambre, J. Leveraging frozen pretrained written language models for neural sign language translation. Information 2022, 13, 220. [Google Scholar] [CrossRef]
- Zhao, J.; Qi, W.; Zhou, W.; Duan, N.; Zhou, M.; Li, H. Conditional sentence generation and cross-modal reranking for sign language translation. IEEE Trans. Multimed. 2021, 24, 2662–2672. [Google Scholar] [CrossRef]
- Fu, B.; Ye, P.; Zhang, L.; Yu, P.; Hu, C.; Chen, Y.; Shi, X. ConSLT: A token-level contrastive framework for sign language translation. arXiv 2022, arXiv:2204.04916. [Google Scholar]
- Chen, Y.; Wei, F.; Sun, X.; Wu, Z.; Lin, S. A simple multi-modality transfer learning baseline for sign language translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5120–5130. [Google Scholar]
- Barrault, L.; Bojar, O.; Costa-Jussa, M.R.; Federmann, C.; Fishel, M.; Graham, Y.; Haddow, B.; Huck, M.; Koehn, P.; Malmasi, S.; et al. Findings of the 2019 Conference on Machine Translation (WMT19). In Proceedings of the Fourth Conference on Machine Translation, Florence, Italy, 1–2 August 2019. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Moe, S.Z.; Thu, Y.K.; Thant, H.A.; Min, N.W.; Supnithi, T. Unsupervised Neural Machine Translation between Myanmar Sign Language and Myanmar Language. Ph.D. Thesis, MERAL Portal, Mandalay, Myanmar, 2020. [Google Scholar]
- Albanie, S.; Varol, G.; Momeni, L.; Afouras, T.; Chung, J.S.; Fox, N.; Zisserman, A. BSL-1K: Scaling up co-articulated sign language recognition using mouthing cues. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XI 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 35–53. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Improving neural machine translation models with monolingual data. arXiv 2015, arXiv:1511.06709. [Google Scholar]
- Nunnari, F.; España-Bonet, C.; Avramidis, E. A data augmentation approach for sign-language-to-text translation in-the-wild. In Proceedings of the 3rd Conference on Language, Data and Knowledge (LDK 2021), Schloss Dagstuhl-Leibniz-Zentrum für Informatik, Zaragoza, Spain, 1–3 September 2021. [Google Scholar]
- Gómez, S.E.; McGill, E.; Saggion, H. Syntax-aware transformers for neural machine translation: The case of text to sign gloss translation. In Proceedings of the 14th Workshop on Building and Using Comparable Corpora (BUCC 2021), Online, 6 September 2021; pp. 18–27. [Google Scholar]
- Mocialov, B.; Turner, G.; Hastie, H. Transfer learning for british sign language modelling. arXiv 2020, arXiv:2006.02144. [Google Scholar]
- Ye, J.; Jiao, W.; Wang, X.; Tu, Z. Scaling Back-Translation with Domain Text Generation for Sign Language Gloss Translation. arXiv 2022, arXiv:2210.07054. [Google Scholar]
- Zhang, B.; Müller, M.; Sennrich, R. SLTUNET: A simple unified model for sign language translation. arXiv 2023, arXiv:2305.01778. [Google Scholar]
- Ye, J.; Jiao, W.; Wang, X.; Tu, Z.; Xiong, H. Cross-modality Data Augmentation for End-to-End Sign Language Translation. arXiv 2023, arXiv:2305.11096. [Google Scholar]
- Koller, O.; Forster, J.; Ney, H. Continuous sign language recognition: Towards large vocabulary statistical recognition systems handling multiple signers. Comput. Vis. Image Underst. 2015, 141, 108–125. [Google Scholar] [CrossRef]
- Othman, A.; Jemni, M. English-asl gloss parallel corpus 2012: Aslg-pc12. In Sign-lang@ LREC 2012; European Language Resources Association (ELRA): Paris, France, 2012; pp. 151–154. [Google Scholar]
- Su, K.Y.; Wu, M.W.; Chang, J.S. A new quantitative quality measure for machine translation systems. In Proceedings of the COLING 1992 Volume 2: The 14th International Conference on Computational Linguistics, Nantes, France, 23–28 August 1992. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Toronto, ON, Canada, 2004; pp. 74–81. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the Acl Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization; Association for Computational Linguistics: Toronto, ON, Canada, 2005; pp. 65–72. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Tillmann, C.; Vogel, S.; Ney, H.; Zubiaga, A.; Sawaf, H. Accelerated DP based search for statistical translation. In Proceedings of the Eurospeech, Rhodes, Greece, 22–25 September 1997. [Google Scholar]
- Snover, M.; Dorr, B.; Schwartz, R.; Micciulla, L.; Makhoul, J. A study of translation edit rate with targeted human annotation. In Proceedings of the 7th Conference of the Association for Machine Translation in the Americas: Technical Papers, Cambridge, MA, USA, 8–12 August 2006; pp. 223–231. [Google Scholar]
- Doddington, G. Automatic evaluation of machine translation quality using n-gram co-occurrence statistics. In Proceedings of the Second International Conference on Human Language Technology Research, San Diego, CA, USA, 24–27 March 2002; pp. 138–145. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef] [Green Version]
- Oram, P. WordNet: An electronic lexical database. Christiane Fellbaum (Ed.). Cambridge, MA: MIT Press, 1998. Pp. 423. Appl. Psycholinguist. 2001, 22, 131–134. [Google Scholar] [CrossRef]
- Forster, J.; Schmidt, C.; Hoyoux, T.; Koller, O.; Zelle, U.; Piater, J.H.; Ney, H. RWTH-PHOENIX-weather: A large vocabulary sign language recognition and translation corpus. In Proceedings of the LREC, Istanbul, Turkey, 23–25 May 2012; Volume 9, pp. 3785–3789. [Google Scholar]
- Schembri, A.; Fenlon, J.; Rentelis, R.; Reynolds, S.; Cormier, K. Building the British sign language corpus. Lang. Doc. Conserv. 2013, 7, 136–154. [Google Scholar]
- Viitaniemi, V.; Jantunen, T.; Savolainen, L.; Karppa, M.; Laaksonen, J. S-pot–a benchmark in spotting signs within continuous signing. In Proceedings of the LREC Proceedings, Reykjavik, Iceland, 26–31 May 2014; European Language Resources Association (LREC): Paris, France, 2014. [Google Scholar]
- Hanke, T.; Schulder, M.; Konrad, R.; Jahn, E. Extending the Public DGS Corpus in size and depth. In Proceedings of the Sign-Lang@ LREC, Marseille, France, 11–16 May 2020; European Language Resources Association (ELRA): Paris, France, 2020; pp. 75–82. [Google Scholar]
- Adaloglou, N.; Chatzis, T.; Papastratis, I.; Stergioulas, A.; Papadopoulos, G.T.; Zacharopoulou, V.; Xydopoulos, G.J.; Atzakas, K.; Papazachariou, D.; Daras, P. A comprehensive study on deep learning-based methods for sign language recognition. IEEE Trans. Multimed. 2021, 24, 1750–1762. [Google Scholar] [CrossRef]
- Duarte, A.; Palaskar, S.; Ventura, L.; Ghadiyaram, D.; DeHaan, K.; Metze, F.; Torres, J.; Giro-i Nieto, X. How2sign: A large-scale multimodal dataset for continuous american sign language. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2735–2744. [Google Scholar]
- Von Agris, U.; Kraiss, K.F. Towards a video corpus for signer-independent continuous sign language recognition. Gesture Hum. Comput. Interact. Simul. Lisbon Port. May 2007, 11, 2. [Google Scholar]
- Dreuw, P.; Neidle, C.; Athitsos, V.; Sclaroff, S.; Ney, H. Benchmark Databases for Video-Based Automatic Sign Language Recognition. In Proceedings of the LREC, Marrakech, Morocco, 26 May–1 June 2008. [Google Scholar]
- Chai, X.; Wang, H.; Chen, X. The devisign large vocabulary of chinese sign language database and baseline evaluations. In Technical Report VIPL-TR-14-SLR-001. Key Lab of Intelligent Information Processing of Chinese Academy of Sciences (CAS); Institute of Computing Technology: Beijing, China, 2014. [Google Scholar]
- Li, D.; Rodriguez, C.; Yu, X.; Li, H. Word-level deep sign language recognition from video: A new large-scale dataset and methods comparison. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1459–1469. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literatures | Task | Classification | Latest Year |
|---|---|---|---|
| Minu et al. [25] | SLR | Traditional and modern | 2022 |
| Marcos et al. [5] | SLT | Year | 2022 |
| Baumgärtner et al. [26] | SLR/SLT/SLG | SLR/SLT/SLG | 2019 |
| Koller et al. [27] | SLR | None | 2020 |
| Ours | SLT | Three specific types | 2023 |
| Model | Dev | Test | ||
|---|---|---|---|---|
| WER | del/ins | WER | del/ins | |
| SMC [1] | 22.7 | 7.6/3.8 | 22.4 | 7.4/3.5 |
| STMC [1] | 21.1 | 7.7/3.4 | 20.7 | 7.4/2.6 |
| HST-GNN [47] | 19.5 | - | 19.8 | - |
| Hybrid CNN-HMM [8] | 31.6 | - | 32.5 | - |
| CTF [48] | 37.9 | 12.8/5.2 | 37.8 | 11.9/5.6 |
| DenseTCN [49] | 35.9 | 10.7/5.1 | 36.5 | 10.5/5.5 |
| Song et al. [50] | 38.1 | 12.7/5.5 | 38.3 | 11.9/5.6 |
| Model | Dev | Test | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BL-1 | BL-2 | BL-3 | BL-4 | ROUGE | METEOR | WER | BL-1 | BL-2 | BL-3 | BL-4 | ROUGE | METEOR | WER | |
| TSPNet-Sequential (Li et al.) [4] | - | - | - | - | - | - | - | 35.65 | 22.8 | 16.6 | 12.97 | 34.77 | ||
| TSPNet-Joint (Li et al.) [4] | - | - | - | - | - | - | - | 36.1 | 23.12 | 16.88 | 13.41 | 34.96 | ||
| SANet (Gan et al.) [40] | 56.6 | 41.5 | 31.2 | 23.5 | 54.2 | - | - | 57.3 | 42.4 | 32.2 | 24.8 | 54.8 | ||
| Multistream (Zheng et al.) [3] | - | - | - | 10.76 | 34.81 | - | - | - | - | - | 10.73 | 34.75 | ||
| Camgoz et al. [46] | - | - | - | 19.51 | 45.9 | - | - | - | - | - | 18.51 | 43.57 | ||
| Kan et al. [47] | 46.1 | 33.4 | 27.5 | 22.6 | - | - | - | 45.2 | 34.7 | 27.1 | 22.3 | - | ||
| S2G2T (Camgoz et al.) [9] | 42.88 | 30.3. | 23.02 | 18.4 | 44.14 | - | - | 43.29 | 30.39 | 22.82 | 18.13 | 43.8 | ||
| Multiregion (Zheng et al.) [3] | - | - | - | 10.94 | 34.96 | - | - | - | - | - | 10.89 | 34.88 | ||
| Sign2Text (Camgoz et al.) [9] | 45.54 | 32.6 | 25.3 | 20.69 | - | - | - | 45.34 | 32.31 | 24.83 | 20.17 | - | ||
| Best Recog. Sign2(Gloss+Text) [16] | 46.56 | 34.03 | 26.83 | 22.12 | - | - | 24.61 | 47.2 | 34.46 | 26.75 | 21.8 | - | 24.49 | |
| Best Trans. Sign2(Gloss+Text) [16] | 47.26 | 34.4 | 27.05 | 22.38 | - | - | 24.98 | 46.61 | 33.73 | 26.19 | 21.32 | - | 26.16 | |
| STMC-Transformer [17] | 48.27 | 35.2 | 27.47 | 22.47 | 46.31 | 44.95 | - | 48.73 | 36.53 | 29.03 | 24.0 | 46.77 | 45.78 | |
| STMC-Transformer Ens. [17] | 50.31 | 37.6 | 29.81 | 24.68 | 48.7 | 47.45 | - | 50.63 | 38.36 | 30.58 | 25.4 | 48.78 | 47.6 | |
| Zheng et al. [59] | 31.43 | 19.12 | 13.4 | 10.35 | 32.76 | - | - | 31.86 | 19.51 | 13.81 | 10.73 | 32.99 | ||
| Voskou et al. (Yin and Read) [60] | 49.12 | 36.29 | 28.34 | 23.23 | - | - | - | 48.61 | 35.97 | 28.37 | 23.65 | - | ||
| Multitask (Orbay and Akarun) [64] | - | - | - | - | - | - | - | 37.22 | 23.88 | 17.08 | 13.25 | 36.28 | ||
| BN-TIN-Transf.2+BT [19] | 49.33 | 36.43 | 28.66 | 23.51 | 49.53 | - | - | 48.55 | 36.13 | 28.47 | 23.51 | 49.35 | ||
| BN-TIN-Transf.+SignBT [19] | 51.11 | 37.9 | 29.8 | 24.45 | 50.29 | - | - | 50.8 | 37.75 | 29.72 | 24.32 | 49.54 | ||
| BERT2RND (Coster et al.) [21] | - | - | - | 22.47 | - | - | 36.59 | - | - | - | 22.25 | - | 35.76 | |
| BERT2BERT (Coster et al.) [21] | - | - | - | 21.26 | - | - | 40.99 | - | - | - | 21.16 | - | 39.99 | |
| mBART-50 (Coster et al.) [21] | - | - | - | 17.06 | - | - | 40.25 | - | - | - | 16.64 | - | 39.43 | |
| BERT2RNDff Sign2Text [65] | - | - | - | 21.58 | 47.36 | - | - | - | - | - | 21.39 | 46.67 | ||
| BERT2RNDff Sign2(Gloss+Text) [65] | - | - | - | 21.97 | 47.54 | - | - | - | - | - | 21.52 | 47 | ||
| Zhao et al. [66] | 35.85 | 24.77 | 18.65 | 15.08 | 38.96 | 22.0 | 70.0 | 36.71 | 25.4 | 18.86 | 15.18 | 38.85 | 21.0 | 72 |
| ConSLT (Fu et al.) [67] | 50.47 | 37.54 | 29.62 | 24.31 | - | - | - | 51.29 | 38.62 | 30.79 | 25.48 | - | ||
| Sign2Gloss2Text [68] | 50.36 | 37.5 | 29.69 | 24.63 | 50.23 | - | - | 49.94 | 37.28 | 29.67 | 24.6 | 49.59 | ||
| Sign2Text (Chen et al.) [68] | 53.95 | 41.12 | 33.14 | 27.61 | 53.1 | - | - | 53.97 | 41.75 | 33.84 | 28.39 | 52.65 | ||
| TIN-SLT (Cao et al.) [24] | - | - | - | - | - | - | - | 51.06 | 38.85 | 31.23 | 26.13 | 48.56 | 47.83 | |
| Model | Dev | Test | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BL-1 | BL-2 | BL-3 | BL-4 | ROUGE | METEOR3 | BL-1 | BL-2 | BL-3 | BL-4 | ROUGE | METEOR3 | |
| Camgoz et al. [46] | 44.4 | 31.83 | 24.61 | 20.16 | 46.02 | - | 44.13 | 31.47 | 23.89 | 19.26 | 45.45 | - |
| Camgoz et al. [16] | 50.69 | 38.16. | 30.53 | 25.35 | - | - | 48.9 | 36.88 | 29.45 | 24.54 | - | - |
| Transformer [58] | - | - | - | - | - | - | 47.69 | 35.52 | 28.1 | 23.32 | 46.58 | 44.85 |
| Transformer Ens. [58] | - | - | - | - | - | - | 48.4 | 36.9 | 29.7 | 24.9 | 48.51 | 46.24 |
| Transformer [17] | 49.05 | 36.2. | 28.53 | 23.52 | 47.36 | 46.09 | 47.69 | 35.52 | 28.17 | 23.32 | 46.58 | 44.85 |
| Transformer Ens. [17] | 48.85. | 36.62 | 29.23 | 24.38 | 49.01 | 46.96 | 48.4 | 36.9 | 29.7 | 24.9 | 48.51 | 46.24 |
| mBART w/ CC25 [68] | 54.01 | 41.41 | 33.5. | 28.19 | 53.79 | - | 52.65 | 39.99 | 32.07 | 26.7 | 52.54 | - |
| TIN-SLT [24] | 52.35. | 39.03. | 30.83 | 25.38 | 48.82 | 48.4 | 52.77 | 40.08 | 32.09 | 26.55 | 49.43 | 49.36 |
| BT-tuned [22] | - | - | - | - | - | - | - | - | - | 22.02 | - | - |
| General-tuned [22] | - | - | - | - | - | - | - | - | - | 23.35 | - | - |
| Specific-tuned [22] | - | - | - | - | - | - | - | - | - | 23.17 | - | - |
| Transformer+Scaling BT [77] | 48.68 | 37.94. | 30.58 | 25.56 | - | - | 47.7 | 37.09 | 29.92 | 25.04 | - | - |
| Dataset | Language | Video | Gloss | Text | Signs | Running Glosses | Signers | Duration (h) |
|---|---|---|---|---|---|---|---|---|
| RWTH-Phoenix-Weather [91] | DGS | ✓ | ✓ | ✓ | 911 | 21,822 | 7 | 3.25 |
| BSL [92] | BSL | ✓ | ✓ | ✓ | 5k | - | 249 | - |
| S-pot [93] | Suvi | ✓ | ✓ | ✓ | 1211 | - | 5 | - |
| RWTH-Phoenix-Weather-2014 [80] | DGS | ✓ | ✓ | ✓ | 1081 | 65,227 | 9 | - |
| DGS Korpus [94] | DGS | ✓ | ✓ | ✓ | - | - | 330 | - |
| GSL [95] | GSL | ✓ | ✓ | ✓ | 310 | - | 7 | - |
| RWTH-Phoenix-2014T [9] | DGS | ✓ | ✓ | ✓ | 1066 | 67,781 | 9 | 11 |
| How2Sign [96] | ASL | ✓ | ✓ | ✓ | 16,000 | - | 11 | 79 |
| CSL-Daily [19] | CSL | ✓ | ✓ | ✓ | 2000 | 20,654 | 10 | 20.62 |
| SIGNUM [97] | DGS | ✓ | ✓ | ✗ | 455 | - | 25 | 55 |
| RWTH-BOSTON-104 [98] | ASL | ✓ | ✓ | ✗ | 104 | - | 3 | 0.145 |
| Devisign-G [99] | CSL | ✓ | ✓ | ✗ | 36 | - | 8 | - |
| USTC CSL [44] | CSL | ✓ | ✓ | ✗ | 178 | - | 50 | 100 |
| WLASL [100] | ASL | ✓ | ✓ | ✗ | 2000 | - | 119 | - |
| ASLG-PC12 [81] | ASL | ✗ | ✓ | ✓ | - | - | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, Z.; Li, H.; Chai, J. Sign Language Translation: A Survey of Approaches and Techniques. Electronics 2023, 12, 2678. https://doi.org/10.3390/electronics12122678
Liang Z, Li H, Chai J. Sign Language Translation: A Survey of Approaches and Techniques. Electronics. 2023; 12(12):2678. https://doi.org/10.3390/electronics12122678
Chicago/Turabian StyleLiang, Zeyu, Huailing Li, and Jianping Chai. 2023. "Sign Language Translation: A Survey of Approaches and Techniques" Electronics 12, no. 12: 2678. https://doi.org/10.3390/electronics12122678
APA StyleLiang, Z., Li, H., & Chai, J. (2023). Sign Language Translation: A Survey of Approaches and Techniques. Electronics, 12(12), 2678. https://doi.org/10.3390/electronics12122678