
RDVI: A Retrieval–Detection Framework for Verbal Irony Detection

 , ,
, , 
Abstract
1. Introduction
- We propose a Retrieval–Detection framework that leverages connotative knowledge to enhance the model’s ability to recognize and comprehend verbal irony.
- We utilize prompt learning to explicitly incorporate connotative knowledge into the model, thereby enhancing the model’s capacity to comprehend text semantics.
- Our approach is compared to several baseline methods, and the quantitative and qualitative results demonstrate that it achieves state-of-the-art performance in detecting verbal irony.
2. Related Work
2.1. Verbal Irony Detection
2.2. Open-Domain Question Answering
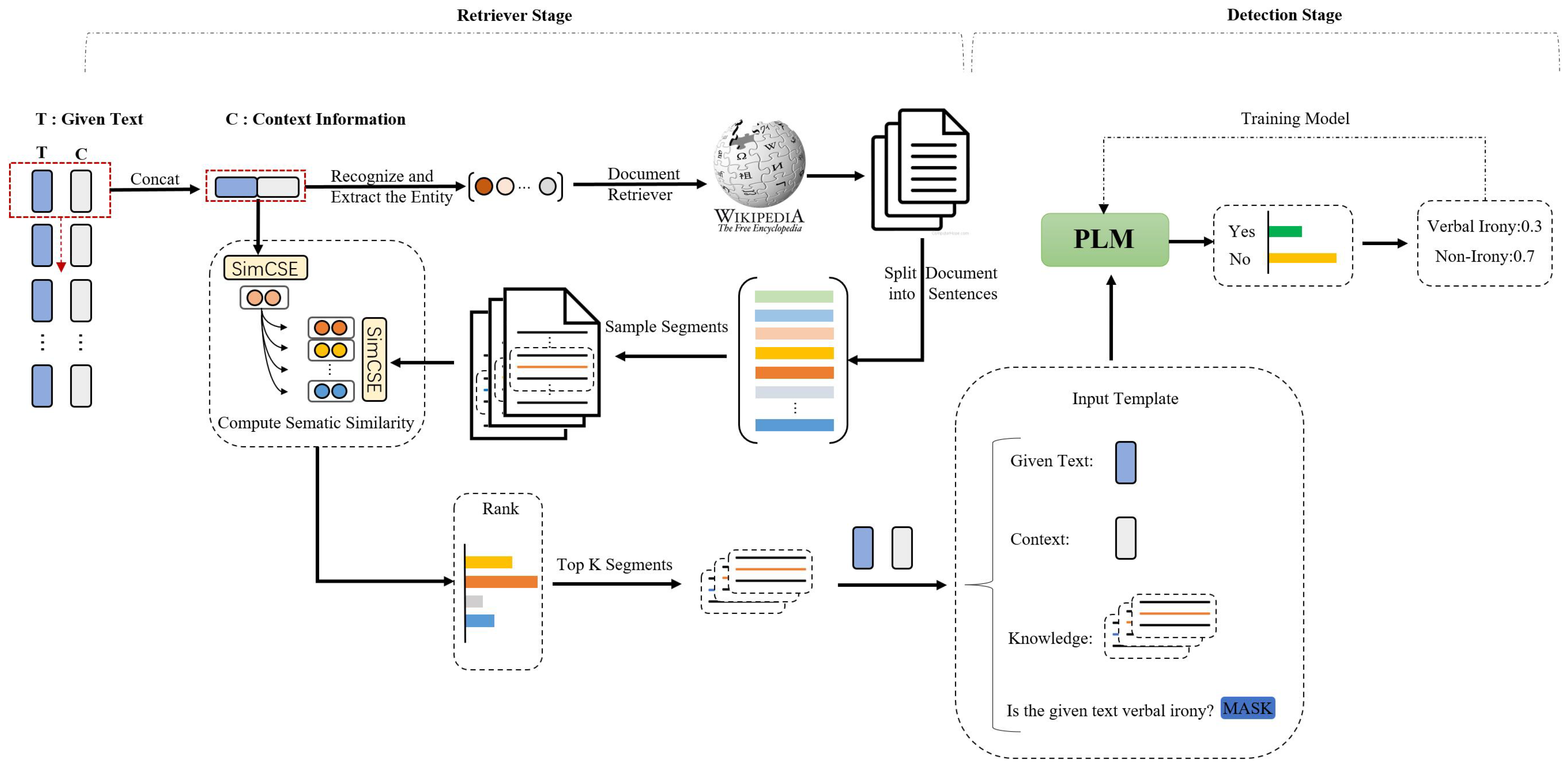
3. Approach
3.1. Retrieval Stage
3.2. Detection Stage
| Algorithm 1: Recognize and retrieve relevant connotative knowledge |
 |
- Given Text:

- Context:

- Knowledge:

- Is the given text verbal irony?

 ), should contain the given text . The second slot, marked in yellow (
), should contain the given text . The second slot, marked in yellow ( ), should be filled with the context information . The third slot, marked in red (
), should be filled with the context information . The third slot, marked in red ( ), should contain the related segments . The fourth slot, marked in blue (
), should contain the related segments . The fourth slot, marked in blue ( ), represents the location of the masked token, which needs the model for prediction. We leverage a function to generate the input :
), represents the location of the masked token, which needs the model for prediction. We leverage a function to generate the input :4. Experiments and Analysis
4.1. Dataset
4.2. Settings and Baseline
- CNN–LSTM–DNN [61], which is a combination of CNN, LSTM, and a fully connected DNN layer for semantic modeling.
- MIARN and SIARN [37], which use a multi-dimensional intra-attention objective and a single-dimensional intra-attention objective, respectively, in a recurrent network to detect contrastive sentiment, situations, and incongruity based on intra-sentence similarity.
- SMSD and SMSD–BiLSTM [11], where SMSD is a self-matching network that captures incongruity information and compositional information of sentences based on a modified co-attention mechanism, and SMSD-BiLSTM employs a bi-directional LSTM to capture compositional information for each input sentence.
- BERT [42], which incorporates sememe knowledge and auxiliary information into BERT to construct the representation of text.
- ChatGPT is a large language model trained by OpenAI. It has a good in-context learning (ICL) [63] ability. We select two samples for each category and use the API of OpenAI https://openai.com/ (accessed on 5 May 2023) for testing.
- ChatGPT + Retrieval is a method that replaces the detection component of our proposed method with ChatGPT.
- v [47], to further analyze our method, we also attempted to replace SimCSE with BM25 to compute semantic similarity.
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gibbs, R.W., Jr.; Colston, H.L. Irony in Language and Thought: A Cognitive Science Reader; Psychology Press: London, UK, 2007. [Google Scholar]
- Colston, H.; Gibbs, R. A brief history of irony. In Irony in Language and Thought: A Cognitive Science Reader; Psychology Press: London, UK, 2007; pp. 3–21. [Google Scholar]
- Kreuz, R.J.; Roberts, R.M. On satire and parody: The importance of being ironic. Metaph. Symb. 1993, 8, 97–109. [Google Scholar] [CrossRef]
- Lucariello, J. Situational irony: A concept of events gone awry. J. Exp. Psych. Gen. 1994, 123, 129. [Google Scholar] [CrossRef]
- Gibbs, R.W., Jr.; Gibbs, J. The Poetics of Mind: Figurative Thought, Language, and Understanding; Cambridge University Press: Cambridge, MA, USA, 1994. [Google Scholar]
- Forslid, E.; Wikén, N. Automatic Irony-and Sarcasm Detection in Social Media. 2015. Available online: https://www.semanticscholar.org/paper/Automatic-irony-and-sarcasm-detection-in-Social-Forslid-Wik%C3%A9n/d153773f96b8d993c99ec3a87c132fde3689dd04 (accessed on 5 May 2023).
- Mozafari, M.; Farahbakhsh, R.; Crespi, N. A BERT-based transfer learning approach for hate speech detection in online social media. In Proceedings of the International Conference on Complex Networks and Their Applications, Lisbon, Portugal, 10–12 December 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 928–940. [Google Scholar]
- Ghosh, D.; Shrivastava, R.; Muresan, S. “Laughing at you or with you”: The Role of Sarcasm in Shaping the Disagreement Space. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 19–23 April 2021; Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 1998–2010. [Google Scholar] [CrossRef]
- Van Hee, C.; Lefever, E.; Hoste, V. We Usually Don’t Like Going to the Dentist: Using Common Sense to Detect Irony on Twitter. Comput. Linguist. 2018, 44, 793–832. [Google Scholar] [CrossRef]
- Ghosh, A.; Veale, T. Magnets for Sarcasm: Making Sarcasm Detection Timely, Contextual and Very Personal. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; Association for Computational Linguistics: Toronto, ON, Canada, 2017; pp. 482–491. [Google Scholar] [CrossRef]
- Xiong, T.; Zhang, P.; Zhu, H.; Yang, Y. Sarcasm Detection with Self-matching Networks and Low-rank Bilinear Pooling. In Proceedings of the World Wide Web Conference, WWW 2019, San Francisco, CA, USA, 13–17 May 2019; Liu, L., White, R.W., Mantrach, A., Silvestri, F., McAuley, J.J., Baeza-Yates, R., Zia, L., Eds.; ACM: New York, NY, USA, 2019; pp. 2115–2124. [Google Scholar] [CrossRef]
- González, J.Á.; Hurtado, L.F.; Pla, F. Transformer based contextualization of pre-trained word embeddings for irony detection in Twitter. Inf. Proc. Manag. 2020, 57, 102262. [Google Scholar] [CrossRef]
- Savini, E.; Caragea, C. Intermediate-task transfer learning with BERT for sarcasm detection. Mathematics 2022, 10, 844. [Google Scholar] [CrossRef]
- Li, J.; Pan, H.; Lin, Z.; Fu, P.; Wang, W. Sarcasm detection with commonsense knowledge. IEEE/ACM Trans. Audio Speech Lang. Proc. 2021, 29, 3192–3201. [Google Scholar] [CrossRef]
- Castaño Díaz, C.M. Defining and characterizing the concept of Internet Meme. Ces Psicol. 2013, 6, 82–104. [Google Scholar]
- Zhu, F.; Lei, W.; Wang, C.; Zheng, J.; Poria, S.; Chua, T.S. Retrieving and reading: A comprehensive survey on open-domain question answering. arXiv 2021, arXiv:2101.00774. [Google Scholar]
- Chen, D.; Fisch, A.; Weston, J.; Bordes, A. Reading Wikipedia to Answer Open-Domain Questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Toronto, ON, Canada, 2017; pp. 1870–1879. [Google Scholar] [CrossRef]
- Wang, S.; Yu, M.; Guo, X.; Wang, Z.; Klinger, T.; Zhang, W.; Chang, S.; Tesauro, G.; Zhou, B.; Jiang, J. R 3: Reinforced ranker-reader for open-domain question answering. In Proceedings of the 2018 AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Ptáček, T.; Habernal, I.; Hong, J. Sarcasm Detection on Czech and English Twitter. In Proceedings of the COLING 2014, The 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; Dublin City University and Association for Computational Linguistics: Dublin, Ireland, 2014; pp. 213–223. [Google Scholar]
- Ghosh, A.; Li, G.; Veale, T.; Rosso, P.; Shutova, E.; Barnden, J.; Reyes, A. SemEval-2015 Task 11: Sentiment Analysis of Figurative Language in Twitter. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; Association for Computational Linguistics: Toronto, ON, Canada, 2015; pp. 470–478. [Google Scholar] [CrossRef]
- Khodak, M.; Saunshi, N.; Vodrahalli, K. A Large Self-Annotated Corpus for Sarcasm. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018; European Language Resources Association (ELRA): Paris, France, 2018. [Google Scholar]
- Barbieri, F.; Ronzano, F.; Saggion, H. Italian Irony Detection in Twitter: A First Approach; Pisa University Press: Pisa, Italy, 2014; pp. 28–32. [Google Scholar]
- Van Hee, C.; Lefever, E.; Hoste, V. SemEval-2018 Task 3: Irony Detection in English Tweets. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; Association for Computational Linguistics: Toronto, ON, Canada, 2018; pp. 39–50. [Google Scholar] [CrossRef]
- Oprea, S.; Magdy, W. iSarcasm: A Dataset of Intended Sarcasm. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 1279–1289. [Google Scholar] [CrossRef]
- Filatova, E. Irony and Sarcasm: Corpus Generation and Analysis Using Crowdsourcing. In Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC’12), Istanbul, Turkey, 23–25 May 2012; European Language Resources Association (ELRA): Paris, France, 2012; pp. 392–398. [Google Scholar]
- Gong, X.; Zhao, Q.; Zhang, J.; Mao, R.; Xu, R. The Design and Construction of a Chinese Sarcasm Dataset. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; European Language Resources Association: Toronto, ON, Canada, 2020; pp. 5034–5039. [Google Scholar]
- Tsur, O.; Davidov, D.; Rappoport, A. ICWSM—A great catchy name: Semi-supervised recognition of sarcastic sentences in online product reviews. In Proceedings of the International AAAI Conference on Web and Social Media, Washington, DC, USA, 23–26 May 2010; Volume 4, pp. 162–169. [Google Scholar]
- Carvalho, P.; Sarmento, L.; Silva, M.J.; De Oliveira, E. Clues for detecting irony in user-generated contents: Oh…!! it’s “so easy”. In Proceedings of the 1st International CIKM Workshop on Topic-Sentiment Analysis for Mass Opinion, Hong Kong, China, 6 November 2009; pp. 53–56. [Google Scholar]
- Maynard, D.; Greenwood, M. Who cares about Sarcastic Tweets? Investigating the Impact of Sarcasm on Sentiment Analysis. In Proceedings of the 9th International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, 26–31 May 2014; European Language Resources Association (ELRA): Paris, France, 2014; pp. 4238–4243. [Google Scholar]
- Bharti, S.K.; Babu, K.S.; Jena, S.K. Parsing-based Sarcasm Sentiment Recognition in Twitter Data. In Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, ASONAM 2015, Paris, France, 25–28 August 2015; Pei, J., Silvestri, F., Tang, J., Eds.; ACM: New York, NY, USA, 2015; pp. 1373–1380. [Google Scholar] [CrossRef]
- González-Ibáñez, R.; Muresan, S.; Wacholder, N. Identifying Sarcasm in Twitter: A Closer Look. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Association for Computational Linguistics: Toronto, ON, Canada, 2011; pp. 581–586. [Google Scholar]
- Reyes, A.; Rosso, P.; Buscaldi, D. From humor recognition to irony detection: The figurative language of social media. Data Knowl. Eng. 2012, 74, 1–12. [Google Scholar] [CrossRef]
- Joshi, A.; Sharma, V.; Bhattacharyya, P. Harnessing Context Incongruity for Sarcasm Detection. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Beijing, China, 26–31 July 2015; Association for Computational Linguistics: Toronto, ON, Canada, 2015; pp. 757–762. [Google Scholar] [CrossRef]
- Bamman, D.; Smith, N. Contextualized sarcasm detection on twitter. In Proceedings of the International AAAI Conference on Web and Social Media, Oxford, UK, 26–29 May 2015; Volume 9, pp. 574–577. [Google Scholar]
- Reyes, A.; Rosso, P.; Veale, T. A multidimensional approach for detecting irony in twitter. Lang. Resour. Eval. 2013, 47, 239–268. [Google Scholar] [CrossRef]
- Amir, S.; Wallace, B.C.; Lyu, H.; Carvalho, P.; Silva, M.J. Modelling Context with User Embeddings for Sarcasm Detection in Social Media. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; Association for Computational Linguistics: Toronto, ON, Canada, 2016; pp. 167–177. [Google Scholar] [CrossRef]
- Tay, Y.; Luu, A.T.; Hui, S.C.; Su, J. Reasoning with Sarcasm by Reading In-Between. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Toronto, ON, Canada, 2018; pp. 1010–1020. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; [Google Scholar]
- Babanejad, N.; Davoudi, H.; An, A.; Papagelis, M. Affective and Contextual Embedding for Sarcasm Detection. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; International Committee on Computational Linguistics: New York, NY, USA, 2020; pp. 225–243. [Google Scholar] [CrossRef]
- Kumar, A.; Narapareddy, V.T.; Gupta, P.; Srikanth, V.A.; Neti, L.B.M.; Malapati, A. Adversarial and Auxiliary Features-Aware BERT for Sarcasm Detection. In Proceedings of the 3rd ACM India Joint International Conference on Data Science and Management of Data (8th ACM IKDD CODS and 26th COMAD), Mumbai, India, 4–7 January 2021; pp. 163–170. [Google Scholar]
- Plepi, J.; Flek, L. Perceived and Intended Sarcasm Detection with Graph Attention Networks. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 16–20 November 2021; Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 4746–4753. [Google Scholar] [CrossRef]
- Wen, Z.; Gui, L.; Wang, Q.; Guo, M.; Yu, X.; Du, J.; Xu, R. Sememe knowledge and auxiliary information enhanced approach for sarcasm detection. Inf. Proc. Manag. 2022, 59, 102883. [Google Scholar] [CrossRef]
- Wang, R.; Wang, Q.; Liang, B.; Chen, Y.; Wen, Z.; Qin, B.; Xu, R. Masking and Generation: An Unsupervised Method for Sarcasm Detection. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022. [Google Scholar]
- Harabagiu, S.M.; Maiorano, S.J.; Paşca, M.A. Open-domain textual question answering techniques. Nat. Lang. Eng. 2003, 9, 231–267. [Google Scholar] [CrossRef]
- Allam, A.M.N.; Haggag, M.H. The question answering systems: A survey. Int. J. Res. Rev. Inf. Sci. (IJRRIS) 2012, 2, 3. [Google Scholar]
- Sparck Jones, K. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Robertson, S.; Zaragoza, H. The probabilistic relevance framework: BM25 and beyond. Found. Trends Inf. Retriev. 2009, 3, 333–389. [Google Scholar] [CrossRef]
- Hermann, K.M.; Kociský, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching Machines to Read and Comprehend. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; pp. 1693–1701. [Google Scholar]
- Yang, W.; Xie, Y.; Lin, A.; Li, X.; Tan, L.; Xiong, K.; Li, M.; Lin, J. End-to-End Open-Domain Question Answering with BERTserini. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Toronto, ON, Canada, 2019; pp. 72–77. [Google Scholar] [CrossRef]
- Wang, Z.; Ng, P.; Ma, X.; Nallapati, R.; Xiang, B. Multi-passage BERT: A Globally Normalized BERT Model for Open-domain Question Answering. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Toronto, ON, Canada, 2019; pp. 5878–5882. [Google Scholar] [CrossRef]
- Karpukhin, V.; Oguz, B.; Min, S.; Lewis, P.; Wu, L.; Edunov, S.; Chen, D.; Yih, W.T. Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 6769–6781. [Google Scholar] [CrossRef]
- Nishida, K.; Saito, I.; Otsuka, A.; Asano, H.; Tomita, J. Retrieve-and-Read: Multi-task Learning of Information Retrieval and Reading Comprehension. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, CIKM 2018, Torino, Italy, 22–26 October 2018; Cuzzocrea, A., Allan, J., Paton, N.W., Srivastava, D., Agrawal, R., Broder, A.Z., Zaki, M.J., Candan, K.S., Labrinidis, A., Schuster, A., et al., Eds.; ACM: New York, NY, USA, 2018; pp. 647–656. [Google Scholar] [CrossRef]
- Khattab, O.; Potts, C.; Zaharia, M. Relevance-guided Supervision for OpenQA with ColBERT. Trans. Assoc. Comput. Linguist. 2021, 9, 929–944. [Google Scholar] [CrossRef]
- Zhao, T.; Lu, X.; Lee, K. SPARTA: Efficient Open-Domain Question Answering via Sparse Transformer Matching Retrieval. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 565–575. [Google Scholar] [CrossRef]
- Lewis, P.S.H.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.; Rocktäschel, T.; et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; [Google Scholar]
- Wang, J.; Jatowt, A.; Färber, M.; Yoshikawa, M. Answering event-related questions over long-term news article archives. In Proceedings of the Advances in Information Retrieval: 42nd European Conference on IR Research; Proceedings, Part I 42, ECIR 2020, Lisbon, Portugal, 14–17 April 2020; Springer: Berline/Heidelberg, Germany, 2020; pp. 774–789. [Google Scholar]
- Lee, J.; Yun, S.; Kim, H.; Ko, M.; Kang, J. Ranking Paragraphs for Improving Answer Recall in Open-Domain Question Answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Toronto, ON, Canada, 2018; pp. 565–569. [Google Scholar] [CrossRef]
- Wang, S.; Yu, M.; Jiang, J.; Zhang, W.; Guo, X.; Chang, S.; Wang, Z.; Klinger, T.; Tesauro, G.; Campbell, M. Evidence Aggregation for Answer Re-Ranking in Open-Domain Question Answering. In Proceedings of the 6th International Conference on Learning Representations, Conference Track Proceedings. OpenReview.net, 2018, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gao, T.; Yao, X.; Chen, D. SimCSE: Simple Contrastive Learning of Sentence Embeddings. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 6894–6910. [Google Scholar] [CrossRef]
- Ding, N.; Hu, S.; Zhao, W.; Chen, Y.; Liu, Z.; Zheng, H.; Sun, M. OpenPrompt: An Open-source Framework for Prompt-learning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Dublin, Ireland, 22–27 May 2022; Association for Computational Linguistics: Toronto, ON, Canada, 2022; pp. 105–113. [Google Scholar] [CrossRef]
- Ghosh, A.; Veale, T. Fracking Sarcasm using Neural Network. In Proceedings of the 7th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, San Diego, CA, USA, 12–17 June 2016; Association for Computational Linguistics: Toronto, ON, Canada, 2016; pp. 161–169. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Toronto, ON, Canada, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Dong, Q.; Li, L.; Dai, D.; Zheng, C.; Wu, Z.; Chang, B.; Sun, X.; Xu, J.; Sui, Z. A Survey for In-context Learning. arXiv 2023, arXiv:2301.00234. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9. [Google Scholar]



{kind=link}
{kind=link}
| Category | Content |
|---|---|
| Verbal Ironic Expression | The terrorist’s weapons and ammunition have arrived. |
| Context Information | Samsung released the first mass-produced folding screen mobile phone in history |
| Connotative Knowledge | Samsung note 7 mobile phone battery faults. |
| Category | Comment | News | Comment (AVG) | Title (AVG) | |
|---|---|---|---|---|---|
| Train | Verbal Irony | 2222 | 640 | 23.966 | 24.251 |
| Non-Irony | 2222 | 637 | 22.383 | 24.259 | |
| Test | Verbal Irony | 264 | 80 | 23.098 | 25.001 |
| Non-Irony | 264 | 80 | 29.220 | 24.996 |
| Approaches | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|
| CNN-LSTM-DNN | 65.29% | 65.28% | 65.27% | 65.28% |
| MIARN | 68.12% | 67.92% | 67.84% | 68.50% |
| SIARN | 70.39% | 70.34% | 70.32% | 70.34% |
| SMSD | 68.51% | 68.51% | 68.50% | 68.50% |
| SMSD-BiLSTM | 71.13% | 70.96% | 70.91% | 70.96% |
| BERT | 75.21% | 76.39% | 75.68% | 75.57% |
| BERT | 78.79% | 74.55% | 75.93% | 75.95% |
| ChatGPT | 62.60% | 75.93% | 71.11% | 71.32% |
| ChatGPT + Retrieval | 64.12% | 84.00% | 75.58% | 75.91% |
| RDVI | 75.57% | 81.15% | 78.95% | 78.97% |
| RDVI | 71.37% | 85.39% | 79.41% | 79.54% |
| Approaches | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|
| RDVI w/o | 67.18% | 83.41% | 76.56% | 76.86% |
| RDVI w/o | 75.19% | 82.08% | 79.32% | 79.35% |
| RDVI w/o | 74.12% | 78.92% | 77.53% | 77.33% |
| RDVI w/o | 73.06% | 80.31% | 77.76% | 77.84% |
| RDVI | 71.37% | 85.39% | 79.41% | 79.54% |
| Batch Size | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|
| 8 | 70.83% | 81.30% | 77.18% | 77.27% |
| 16 | 71.37% | 85.39% | 79.41% | 79.54% |
| 32 | 66.03% | 88.72% | 78.43% | 78.78% |
| 48 | 73.66% | 82.13% | 78.72% | 78.78% |
| Learning Rate | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|
| 60.03% | 88.27% | 75.50% | 76.10% | |
| 71.37% | 85.39% | 79.41% | 79.54% | |
| 76.34% | 78.74% | 77.82% | 77.82% | |
| 68.70% | 85.31% | 78.19% | 78.39% |
| Top K | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|
| 1 | 71.37% | 85.39% | 79.41% | 79.54% |
| 2 | 64.89% | 89.01% | 78.00% | 78.40% |
| 3 | 70.99% | 84.55% | 78.84% | 78.97% |
| 4 | 70.23% | 83.26% | 77.88% | 78.01% |
| 5 | 67.94% | 85.99% | 78.16% | 78.40% |
| Window Size | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|
| 1 | 70.99% | 84.16% | 78.65% | 78.78% |
| 3 | 71.37% | 85.39% | 79.41% | 79.54% |
| 5 | 72.52% | 84.07% | 79.26% | 79.35% |
| Approaches | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|
| BERT | 31.11% | 52.04% | 54.63% | 60.05% |
| BERT | 29.11% | 56.22% | 55.29% | 61.69% |
| ChatGPT | 44.67% | 41.27% | 50.24% | 51.32% |
| ChatGPT + Retrieval | 28.67% | 48.13% | 52.43% | 58.14% |
| RDVI | 30.67% | 57.02% | 56.13% | 62.15% |
| RDVI | 40.89% | 52.27% | 57.40% | 60.51% |
| Index | Given Text | Context | Connotative Knowledge |
|---|---|---|---|
| 1 | Falling down and getting up makes one stronger! | An Indian fighter jet crashed in the Indian-controlled Kashmir region. | The region is divided amongst three countries in a territorial dispute: Pakistan controls the northwest portion (Northern Areas and Kashmir), India controls the central and southern portion (Jammu and Kashmir) and Ladakh … |
| 2 | Americans are having a great time playing the arms race game by themselves. | Cutting Equipment Purchases, the US Department of Defense allocates $100 billion for research and development. | The United States has deployed overseas troops in multiple countries and regions around the world, totaling over 230,000 personnel. Currently, the US is the country with the highest military expenditure in the world, … |
| 3 | Keep going. I believe in you. | US military officials claimed that the political situation in Afghanistan does not allow for the withdrawal of US troops. | After years of military operations yielding little results, the United States decided to withdraw from Afghanistan in 2014. The new Afghan government supported by the US was plagued by corruption issues… |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, Z.; Wang, R.; Chen, S.; Wang, Q.; Ding, K.; Liang, B.; Xu, R. RDVI: A Retrieval–Detection Framework for Verbal Irony Detection. Electronics 2023, 12, 2673. https://doi.org/10.3390/electronics12122673
Wen Z, Wang R, Chen S, Wang Q, Ding K, Liang B, Xu R. RDVI: A Retrieval–Detection Framework for Verbal Irony Detection. Electronics. 2023; 12(12):2673. https://doi.org/10.3390/electronics12122673
Chicago/Turabian StyleWen, Zhiyuan, Rui Wang, Shiwei Chen, Qianlong Wang, Keyang Ding, Bin Liang, and Ruifeng Xu. 2023. "RDVI: A Retrieval–Detection Framework for Verbal Irony Detection" Electronics 12, no. 12: 2673. https://doi.org/10.3390/electronics12122673
APA StyleWen, Z., Wang, R., Chen, S., Wang, Q., Ding, K., Liang, B., & Xu, R. (2023). RDVI: A Retrieval–Detection Framework for Verbal Irony Detection. Electronics, 12(12), 2673. https://doi.org/10.3390/electronics12122673