1. Introduction
Recent years have shown cloud computing to be an important solution for large-scale massive data processing, as offered by major computing service providers. Much of the wide adoption of cloud computing as an on-demand service platform is made possible due to the success of virtualization technology and the usage of virtual machines (VMs) and containers. Both containers and VMs are packaged computing environments that combine various IT components that are isolated from the rest of the hosting system. A container is a standard software unit that packages up code and all its libraries and dependencies, so that the application runs quickly and reliably in various cloud computing environments.
The use of containerized applications significantly reduces the required memory resources compared to running the same application on a VM [
1]. Typically, containers are designed to be activated and deactivated during their life cycle and can be redeployed in the same manner, regardless of the infrastructure [
2]. Using containers enables multiple applications to share the same OS, i.e., running on shared resources on the same machine. Any container orchestration, such as the common Kubernetes [
3], should dynamically and efficiently distribute the containers to available servers. In the case of a distributed application, containers also require networking resources in addition to local CPU and memory resources. Moreover, the application code may need to be executed using more than one container. Therefore, the efficient distribution of containers needs to consider the availability of both local resources (i.e., server resources), and global resources (e.g., network resources). A geo-distributed deployment that relies on Kubernetes and extends it with self-adaptation and network-aware placement capabilities is presented in [
4].
Reinforcement learning (RL) has been recently adopted to solve cloud and edge-computing resource allocation problems [
4,
5,
6,
7,
8,
9], and specifically container placement [
10,
11]. Busoniu et al. [
12] presented a comprehensive survey of multi-agents where the agents are capable of discovering a solution on their own using reinforcement learning. A reinforcement learning agent learns by trial-and-error interaction with its dynamic environment. The agent perceives the complete state of the environment and takes an action which causes a transition to a new state. The agent receives reward feedback that evaluates the quality of this transition. Alwarafy et al. presented a multi-agent deep reinforcement learning (DRL)-based framework for dynamic radio resource allocation [
13]. Horovitz and Arian [
14] presented a new method for improving reinforcement Q-Learning auto-scaling with faster convergence and reduced state and action space in a distributed cloud environment.
Finding an efficient container placement scheme to minimize the overall execution time is known as an NP-hard combinational optimization problem [
11]. The complexity increases exponentially as the number of containers increases [
15]. The complexity of assigning containers to available servers is frequently derived by fitting the cloud environment and constraints into a known (NP-complete) problem model. The most commonly used reductions are bin packing [
15,
16,
17] and integer linear programming [
4,
18].
Usmani et al. [
19] suggested modeling the problem of resource allocation, while minimizing the number of physical machines using a bin-packing algorithm [
19]. Zhang et al. [
16] propose a novel container placement strategy based on a bin packing heuristic that simultaneously considers both virtual and physical machines. Abrishami et al. [
20] adopted a two-phase scheduling algorithm for computer grids, which aimed to minimize the cost of workflow execution, while meeting user-defined constraints for the cloud environment. Li and Cai [
21] proposed a heuristic approach to elastic virtual machine provisioning, demonstrating a decrease in virtual machine rental costs of about 78%. Cai et al. [
22] proposed a unit-aware rule-based heuristic (URH), which distributes the workflow deadline to competitive task units, allowing the use of appropriate time slots on the rented virtual machines, minimizing the VM rental cost. Chen et al. [
23] presented an entropy based stochastic workload scheduler, to allocate clients’ tasks to different cloud data centers. They proposed a QoS model to measure the overall performance. Experimental results demonstrated an improvement of the accumulative QoS and sojourn time by up to 56.1% and 25.4%, respectively, compared to a baseline greedy algorithm.
Recurrent artificial neural networks are remarkably adept at sequence and reinforcement learning but are limited in their ability to represent complex data structures and to store data over long timescales, owing to a lack of external memory [
24]. Graves et al. [
24] introduced a machine learning model called a differentiable neural computer (DNC), which consists of a neural network coupled to an external memory matrix. They demonstrated that a DNC-based network has the ability to represent complex data structures and to learn and store sequential data over long timescales. We adapted the reinforcement-based DNC model proposed by [
24], due to its proven ability to represent variables and complex data structures and to store data over long timescales. In this work, we examine the benefit of using a DNC-based model applied to container allocation.
This paper presents a multi-agent based solution using a Deep RL approach to deal with the challenges of the container allocation problem. We consider and evaluate two different types of agent: LSTM-based agents and DNC-based agents. We propose an DRL-based multi-agent framework to optimize a shared objective, i.e., the efficient placement of containers, using a set of agents in a mixed cooperative–competitive environment. Each agent is provided with a shaped reward and may collaborate with other agents to improve container allocation strategies.
We compared the performance of the LSTM and the DNC multi-agents against the well-known bin packing heuristics and the common Kubernetes allocation mechanism. Experimental results showed that both of the DRL-based approaches were superior in terms of the overall runtime and demonstrated an improvement of about 28% compared to the existing techniques.
This work proposes an efficient model-free multi-agent-based approach that enables the collaboration of multiple agents to solve the container allocation problem in a real cloud environment. The proposed method uses a deep reinforcement learning approach, which is efficiently applied to the challenging container placement problem.
In addition, other contributions of this paper are listed below:
We present an integrated solution for the proposed container placement approach with the well-known Kubernetes orchestration tool;
We extensively evaluate the proposed approach in a real cloud environment, demonstrating the superiority of the proposed multi-agent model-free RL-based solution concerning other placement control policies;
We compare the performance of LSTM-based and DNC memory augmented-based agents against well-known bin packing heuristics algorithms and Kubernetes tool, while applying them to resource allocation problems in a containerized environment.
The rest of this paper is organized as follows:
Section 2 reviews related work.
Section 3 formulates the allocation problem, while
Section 4 presents the proposed approach.
Section 5 introduces the suggested container allocation framework.
Section 6 shows the experimental results, and
Section 7 concludes the paper.
2. Related Work
This section introduces existing related research works presenting different placement approaches for cloud applications subject to varying workloads. We mainly focus on Deep RL methods successfully used to solve a wide range of resource allocation problems. The RL-based approach represents an interesting approach to the runtime self-management of cloud systems [
5]. Reinforcement learning has been mostly applied to devise policies for VM allocation and provisioning and to manage containers [
4,
5,
6,
10,
11,
14], solving the cloud resource allocation problem.
Rossi et al. [
4] proposed a model-based reinforcement learning approach to control the number of replicas of individual containers based on the application response time. They also proposed an effective RL-based approach, to cope with varying workloads [
5]. In other work, they demonstrated the benefits and flexibility of the model-based reinforcement learning policy compared to the common scaling policy of Kubernetes [
10].
Liu et al. [
6] suggested a hierarchical framework of cloud resource allocation and power management using LSTM neural networks and deep reinforcement learning. They showed up to a 60% energy saving compared to the round-robin heuristics approach, at the cost of a larger latency.Yuan et al. [
11] presented a DRL-based container placement scheme to place container instances on servers, while considering end-to-end delay and resource utilization costs. The proposed method is based on an actor–critic approach and outperformed other DRL methods by up to 28%, in terms of reducing the delay and deployment costs.
Nasir et al. [
25] proposed a model-free multi-agent DRL-based framework for dynamic power allocation in wireless networks. The proposed method learns a policy that guides all links to adjust power levels under practical constraints, such as delayed information exchange and incomplete cross-link. A centralized network trainer gathers local observations from all network agents. This approach is computationally efficient and robust.
In contrast to previous works that used a centralized approach for resource allocation in containerized environments [
5,
10,
11], the present research adopts a decentralized approach to the container assignment problem. We propose a multi-agent framework to optimize the placement of the containers using a set of agents in a mixed cooperative–competitive environment. Moreover, we suggest an DRL-based model-free approach, while [
4,
5,
10] proposed a model-based RL approach. To the best of our knowledge, this work is the first to adopt a DNC memory augmented-based model to solve the complex container assignment problem.
3. Problem Formulation
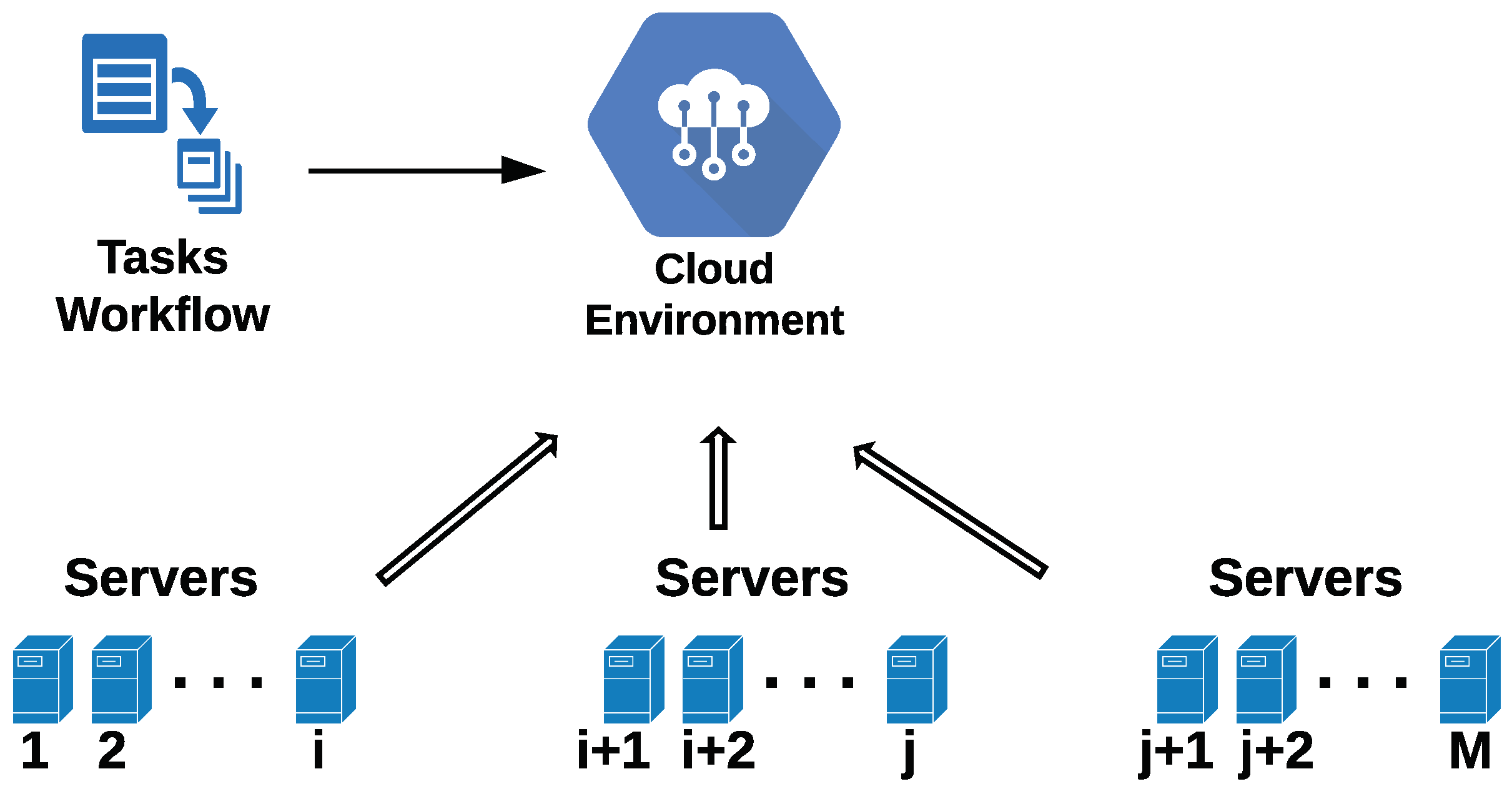
Figure 1 depicts a typical cloud environment with
M servers, each characterized by its available resources (i.e., CPU, memory, and bandwidth).
The container placement problem can be considered as batch assigning, where a batch is composed of N tasks, each with different local resource requirements for CPU computing power and memory. Some of the tasks communicate with other tasks, running on different servers, and therefore require extra bandwidth.
All the tasks in the batch should be efficiently and simultaneously assigned to the cloud servers, to fulfill the following criteria: (a) the total runtime of the entire batch should be minimized, and (b) the resource requirements of all tasks in the batch are fully met.
Let us assume a batch with
K tasks, i.e.,
K containers, and a set of
M available servers
. The required memory and computation power for each task is given as follows:
where
and
, represent the memory and computation power required by the
ith container. The bandwidth required for inter-task communication is given by
where
represents the bandwidth required for communication from task
i to task
j. The total required bandwidth is given by
where
is a
K “ones” row vector.
The servers resources are represented by the following vectors:
where
,
, and
represent the available memory, computation power, and bandwidth, of the
jth server, respectively.
The batch assignment problem can be formulated as a multi-objective optimization problem [
26], as follows:
subject to
The cost function
is related to the runtime
of task
i, as follows:
where
is the runtime of task
i,
T is the overall execution time (determined by the container with the longest execution time), and
. The element
of matrix
is a decision variable defined as
Equation (
8c)–(
8e) depict the server’s resource constraints, where
,
, and
stand for memory, computation, and bandwidth. While it is appealing to define the problem at hand as a minmax (or minimax) problem, we find this presentation unsatisfactory. In minmax problems, one tries to minimize only the maximal value (i.e., the maximal running time in our case). Therefore, in minmax, two solutions with the same maximal value are considered equal, regardless of the values of other (smaller) execution times. Expression (
8a) better represents this distinction.
The optimization goal is to minimize the cost function of each task, subject to the servers’ resource constraints, while keeping the overall runtime required to complete all tasks as short as possible. Equation (
8b) guarantees that any task can be assigned only to a single dedicated server, while Equation (
8c)–(
8e) ensure that the servers’ resources can fulfill the requirements of the overall tasks (≼ stands for element-wise comparison).
The total bandwidth requirements to communicate between any two servers should be less than the available network bandwidth
, as described below:
where
represents the bandwidth on the path for communication from server
i to server
j.
4. The Proposed Approach
This section presents the multi-agent-based solution using a Deep RL (DRL) approach to cope with the challenges of the container allocation problem. We propose an RL-based multi-agent framework for efficient container placement, using a set of agents in a mixed cooperative–competitive environment. Each agent is provided with a shaped reward and may collaborate with other agents to improve container allocation strategies. The main idea of RL is learning through interaction using a trial-and-error learning approach. An RL agent interacts with its environment and, upon observing the outcomes of its actions, learns to alter its behavior in response to the rewards received [
27].
The ith agent observes state from its environment at time step t and interacts with the environment by taking an action in state . Based on the current state and the chosen action, the environment and the agent transition to a new state . Upon each state transition, the environment provides a scalar reward to the agent as feedback. The best sequence of actions is determined by the rewards provided by the environment, while the goal of the agent is to maximize the expected return.
An actor–critic framework that considers the action policies of other agents has the potential to successfully learn policies that require dealing with high-complexity multi-agent problems [
28,
29]. Ryan et al. [
28] proposed a simple extension of actor–critic policy gradient methods, where the critic network is provided with extra information about the policies of other agents, while the actor network only has access to local information. In this work, we adopted a similar actor–critic approach to that proposed in [
28].
The proposed actor–critic framework is comprised of two types of neural network: an actor network, and a critic network. The actor network is used to generate actions according to the input state and is trained using a gradient-based method. We present a unique training algorithm for actor–critic-based agents.
4.1. Reinforcement Learning Framework
Figure 2 depicts a multi-agent cloud environment. Each agent is assigned a single container and is responsible for deciding on which server to place it. Agents perform the allocation of containers to the servers in a serial predetermined order (first, agent no. 1 allocates its task, while agent
K allocates its associated container only at the end of the round). This is achieved by randomly allocating the containers to the various agents. In each round, each agent is responsible for the allocation of a new container. In each round of decisions, a new state is defined for each agent, and another container has the priority of being assigned first. The state defines the container for which the agent is responsible and the previous decisions made by the agents that preceded it in the current round of decisions. In addition, the agent also receives information about the previous decisions of the next agents in line in the same round of decisions. The state also defines the utilization of the servers concerning the previous decision round.
The following sections formulate the space state, action space, and the reward for the ith agent.
4.1.1. State Space
Equation (
12) describes the state space of agent
i:
where
denotes the container for which the
ith agent is responsible at decision round
t the
ith agent’s task requirement at round
t. The previous decisions made by the agents that preceded it in the current round of decisions are denoted by the action vector
,
. The previous decisions of the next agents in line in the same round of decisions are represented by the action vector
,
. Finally,
stands for the utilization of the servers concerning the previous decision round.
4.1.2. Action Space
All agents share the same action space. Equation (
13) describes the common action space
where
stand for the
M available servers.
4.1.3. Reward
Upon each state transition, the environment provides a scalar-shaped reward
to the agent as feedback. The reward is comprised of both local and global rewards. Equation (
14) describes the reward function:
where
and
denote the local and global rewards of agent
i, respectively, and
represents the relative weights given for each reward. The amount of the reward is decided according to the performance of the specific agent at each round of decisions.
The local reward of the
ith agent is represented by the time difference between the overall execution time
(determined by the container with the longest execution time) and the execution time of the container for which the local agent is responsible:
where
is the runtime of task
i.
The global reward is determined relative to the time difference between the overall runtime in the current and previous rounds of decisions:
4.2. Actor–Critic Approach
The advantage actor–critic (A2C) method has achieved superior performance in solving sequential decision problems [
27]. We employed this actor–critic approach to find a policy that maximizes the expected reward
R over all possible dialogue trajectories. The actor is responsible for selecting the actions and therefore determining the policy, while the critic estimates the value function and hence criticizes the actor’s actions [
30].
The policy is a probabilistic mapping function between the state space and the action space and depends on the parameters learned by policy gradient algorithms [
30]. Therefore, the policy is directly optimized by gradient descent, concerning the expected return (long-term cumulative reward).
In our proposed multi-agent-based approach, each agent consists of two neural networks: the actor network, and the critic network. We consider two different types of network: LSTM-based agents, and DNC-based agents. Both the LSTM- and the DNC-based networks are implemented using two hidden layers with eight neurons each (representing the number of servers), followed by a fully-connected layer with eight neurons for the actor network and a single neuron for the critic network. The DNC-based network is implemented using the software package provided by [
31].
In each decision round, each actor is fed with a different advantage value from its corresponding critic, for each agent. Assuming a set of K actors, the parameters learned by the policy gradient algorithm for each actor are defined by for the policy (for the ith agent).
Given the objective loss function
J, the policy gradient is computed using the advantage function
, as follows:
where
and
represent the state space and the taken action for the
ith agent in each decision round. The training of both actor–critic networks is carried out according to Equation (
17) applying the gradient-descent algorithm.
4.3. Multi-Agent RL-Based Approach
We propose an efficient model-free multi-agent-based approach that enables the collaboration of multiple agents to solve the container allocation problem in a cloud environment. The interaction between multiple agents in a shared environment can either be competitive or cooperative [
12]. In this work, we adopt a mixed cooperative–competitive approach [
28]. Each agent aims at minimizing both the execution time of the container assigned to it (i.e., competitive approach) and the overall runtime (i.e., cooperative approach).
The assignment decision for each agent depends on both the local and global rewards, thus considering the decisions taken by all the other agents. In case the container needs to communicate with another container or a remote server, the agent should learn to assign its container to a close or the same host server, to minimize the communication latency.
Since each agent is aware of all assignment decisions taken by the other agents, the environment is stationary even as the decision policy changes, as depicted by [
28]:
for any
.
Foerster et al. [
32] suggested a multi-agent actor–critic method called counterfactual multi-agent policy gradients, which uses a centralized critic to estimate the
Q-function and decentralized actors to optimize the agents’ policies. We adopt a similar approach adapted to both decentralized actors and decentralized critics.
The counterfactual policy estimates the marginal contribution of a single agent’s action, while keeping the other agents’ actions fixed. The idea of the counterfactual approach is inspired by difference rewards [
32]. Difference rewards are a powerful way to perform multi-agent credit assignment, since an agent which directly tries to maximize the system reward has difficulty determining the effect of its actions on its reward [
32,
33]. In contrast, agents using the difference reward have more influence over the value of their own reward; therefore, a good action taken by the agent is more likely to be reflected in its local reward. Moreover, any action taken by the agent that improves the difference reward also improves the true global reward, which does not depend on the agent’s actions. In this work, the impact of the agent’s action on the global reward is estimated using the difference between the global and the local agent rewards.
5. Container Allocation Framework
The container placement problem can be considered as batch assigning, where each batch is composed of N tasks, each with different local resource requirements. We propose an RL-based multi-agent framework for efficient container placement, using a set of agents in a mixed cooperative–competitive environment. An RL-based agent interacts with its environment and, upon observing the outcomes of its actions, learns to alter its own behavior in response to the rewards received. Each agent is provided with a shaped reward and may collaborate with other agents to improve container allocation strategies.
Assuming K containers are allocated to M servers, where , K agents are required, since each agent is responsible for the placement of a single container. Each container is assigned to one of the given M servers; however, multiple containers can be assigned to the same server. The training of the actor–critic networks for each agent is an iterative process. In each iteration (i.e., decision round), a single allocation per agent is carried out. Then, according to the performance achieved (i.e., the overall execution time and the local reward) a new allocation is generated in the next round. The training process is terminated when the contribution to the execution time improvement is marginal.
Agents perform the allocation of containers to the servers in a fixed serial predetermined order, while each agent is assigned a single container and is responsible for deciding on which server to place it. The containers are randomly allocated to the various available agents. In each decision round, each agent is coupled with a different container; thus, another container receives the priority for being assigned. Each agent is informed of the previous decisions made by the preceding agents and of the servers’ utilization concerning the previous decision round.
Algorithm 1 depicts the container allocation process. The allocation process is carried out iteratively (lines 2–14) by training the actor and critic networks for each agent. In each iteration, the containers are randomly assigned to the agents (line 3), and the shaped reward is calculated according to the performance of each agent (lines 8–10). Then the critic estimates the advantage value (line 11) and, finally, the critic and actor networks weights are updated (lines 12–13).
| Algorithm 1 Container Allocation Process. |
 |
5.1. Complexity
The complexity of the state–action space, and consequently the DRL complexity, is proportional to the total number of agents in the system. Y. Ren et al. [
34] provided a detailed complexity analysis for a similar multi-agent DRL-based approach applied to fog computing, offloading computation-intensive tasks to fog access points. The training process runs offline and is performed in the cloud that has sufficient computation resources. Hence, we mainly pay attention to the complexity of online decision making.
In our multi-agent DRL approach, each task is assigned to a DRL-based agent. Hence, the total complexity relies on the complexity of a single DRL-based agent. Based on the complexity analysis described in [
34], we can formulate the total complexity of our DRL-based approach as follows:
where
K is the number of containers,
M is the numbers of servers, and assuming
L hidden layers with
H neurons in each hidden layer.
5.2. Existing Container Allocation Approaches
We compared the performance of the LSTM and the DNC multi-agents against the well-known bin packing heuristics and the common open-source Kubernetes allocation tool used for allocation, deployment, and management of containerized applications [
35,
36]. As a deployment tool, Kubernetes handles container distribution using a heuristic bin-packing algorithm. An integrated solution for the proposed container placement approach with the Kubernetes orchestration tool is provided by replacing the Kubernetes decision mechanism with the allocation deployment suggested in the proposed RL multi-agent approach.
As carried out by Kubernetes, two scoring strategies are evaluated in this work, to support the bin packing of resources: (a) best-fit and (b) max-fit bin-packing algorithms. The best-fit strategy allows specifying the resources along with weights for each resource, to score servers based on the request-to-capacity ratio [
33]. In this case, a scheduled container is assigned to the server with the lowest available resource capacity (which can still accommodate the container) [
15]. On the other hand, the max-fit strategy scores the servers based on the utilization of resources, favoring the ones with higher allocation. Therefore, a scheduled container is assigned to the server with the highest available resource capacity. We apply a 3D bin packing allocation for both the max-fit and best-fit algorithms [
37].
6. Experimental Results
This section presents the results of the proposed multi-agent RL-based approach. The achieved performance is compared with the common Kubernetes tool and classical bin-packing heuristic algorithms. The results showed that the proposed approach outperformed the Kubernetes and the greedy bin-packing algorithm for LSTM- and DNC-based agents. The implementation of both agents was carried out using the Tensor Flow machine learning platform and written in Python.
It is important to emphasize that the experimental results were carried out in real time using a real private cloud environment. The experimental environment included eight servers, which were deployed as virtual machines. The servers were characterized by different processors, memory, and CPU resources, as depicted in
Table 1. The deployment of the containers was carried out using the Kubernetes tool. Although the implementation in the present work is considered an “on-premise private cloud”, the same approach may be used for public and/or hybrid clouds in which Kubernetes is usually used for orchestrating the deployment of containers.
Figure 3 depicts the overall batch execution time as a function of the number of iterations, for both LSTM-based and DNC-based agents. The training process converges after about 350 iterations.
For the DNC-based agents, the best result was achieved with a learning rate (LR) of and a memory matrix size of . The LSTM-based agents outperformed the DNC agents and resulted in a faster batch execution time.
Both the training set and the testing set included various task batches, where each batch included up to 28 different tasks. Each task was characterized by different resource requirements (i.e., CPU time, memory, and communication bandwidth). For the testing, a total of 30 different task batches were used, and the average results are presented.
Figure 4 compares the performance of the proposed LSTM and DNC agents to the Kubernetes tool and the two classical bin-packing algorithms. For the testing set, the results show that the proposed RL-based approach outperformed the three heuristic classical approaches in terms of the average batch execution time.
For all scenarios with less than 20 tasks per batch, the Kubernetes tool showed the best results, compared to the other classical methods.
The LSTM achieved the best performance for all tested scenarios, demonstrating an average improvement of about 25%, 31%, and 32% compared to the Kubernetes, Best-Fit, and Max-Fit, correspondingly. The LSTM execution time ranged from 70 to 285 s, for 8 and 28 tasks per batch, respectively, while the DNC-based agents resulted in a slower execution time of about 8%.
Table 2 depicts the average completion time achieved for the mixed tasks, i.e., tasks that included communication. The results show an improvement of 26% and 30% for 8 and 12 tasks per batch when using the proposed LSTM compared to the best-performing bin packing method. For the scenarios with batches that included more than 12 tasks, the average improvement reduced to about 10%, which means that as the number of tasks per batch increased, the classical methods performed better.
Figure 5 shows the average execution times for local tasks (which do not require communication with other tasks) as a function of the number of tasks. The superiority of the proposed approach is not decisive. With up to 16 tasks, the proposed RL-based approach showed the best results, while with over 16 tasks the max-fit approach seems preferable. The LSTM- and DNC-based agents demonstrated similar results to the Kubernetes. The best-fit method demonstrated the worst performance for all cases.
Figure 6 shows the average completion times for tasks that included communication requirements. The proposed RL-based approach outperformed the three classical approaches in terms of the average batch execution time. The results showed that the LSTM-based agents outperformed the DNC-based agents, while the Kubernetes outperformed the max-fit and best-fit approaches (up to 20 tasks).
From the results shown in
Figure 5 and
Figure 6, it follows that the relative advantage of the proposed RL-based approach was mainly due to the efficiency in allocating tasks that included communication with other tasks.
Figure 7 depicts the performance of the five different approaches as a function of system load (i.e., number of tasks), in terms of statistic parameters. The DRL-based agents outperformed the classical approaches, while the LSTM-based agent demonstrated the best results for all scenarios.
Figure 7 shows that the efficiency of the DRL-based agents significantly increased as the system load increased. For example, the median batch execution time for 28 tasks was 285 s and 394 s for the LSTM and Kubernetes agents, respectively. The results indicate that our DRL-based approach achieved a 30% speedup, compared to the common Kubernetes approach.
Since the performance criteria were chosen as the completion time of the slowest task, we evaluated the effect of the allocation method on the remaining tasks. Let us consider that the batch completion time is
T.
Figure 7 shows that the completion time of
of the tasks was close to
T, within a time range of
,
,
for the Kubernetes, LSTM, and best-fit approaches, respectively. Moreover,
of the tasks ended within a time range of
,
, and
of
T, for the Kubernetes, LSTM and best-fit approaches, respectively. Therefore, the chosen completion time criterion, practically represents the average completion time of the tasks and the proposed allocation methods fairly distributed the tasks among the servers.
Figure 8 depicts the distribution of the average tasks among the 8 servers for a batch of 16 tasks.
7. Summary and Conclusions
This paper presents a multi-agent-based framework using a deep reinforcement learning-based approach to cope with the challenges of the container allocation problem. This work suggests a new approach for assigning containers to servers in a cloud environment, while meeting computing resource requirements and minimizing the overall task completion time. We showed that decentralizing the allocation decisions among multiple agents effectively tackles the high complexity of task allocation in a cloud environment. Two RL-based agents, the LSTM-based and DNC-based agents, were evaluated, demonstrating their efficiency compared to the well-known bin packing heuristics and the common Kubernetes allocation orchestration tool. The experimental results showed that both DRL-based approaches were superior in terms of the overall runtime and demonstrated an improvement of about 28% compared to the existing techniques. Furthermore, the results showed that the LSTM-based agents outperformed the DNC-based agents, while the Kubernetes outperformed the max-fit and best-fit approaches. We conclude that the relative advantage of the proposed RL-based approach is mainly due to its efficiency in allocating tasks that include communication with other tasks.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}