
An Enhanced PSO Algorithm for Scheduling Workflow Tasks in Cloud Computing


Abstract
:1. Introduction
2. Related Works
2.1. Problem Formulation
2.2. Literature Review
2.3. Particle Swarm Optimization Algorithm
2.3.1. Principle of the PSO Algorithm
2.3.2. Task Scheduling Algorithm Based on the PSO Algorithm
| Algorithm 1: PSO Algorithm |
|
2.3.3. Algorithm Analysis
- When the PSO algorithm is scheduling tasks, it does not consider the calculation and data transmission of workflow tasks and can achieve better performance for independent task scheduling. However, the performance under workflow task scheduling is not satisfactory.
- In the PSO algorithm, the optimization direction of the particle depends on its best historical position and the global best position, the convergence speed is fast, and it is easy to fall into the local optimal solution. Particles update their location based on their historical and neighborhood information, which can easily make the load on a single resource node too high, resulting in system instability.
3. PSO Algorithm Optimization
3.1. Particle Encoding Method
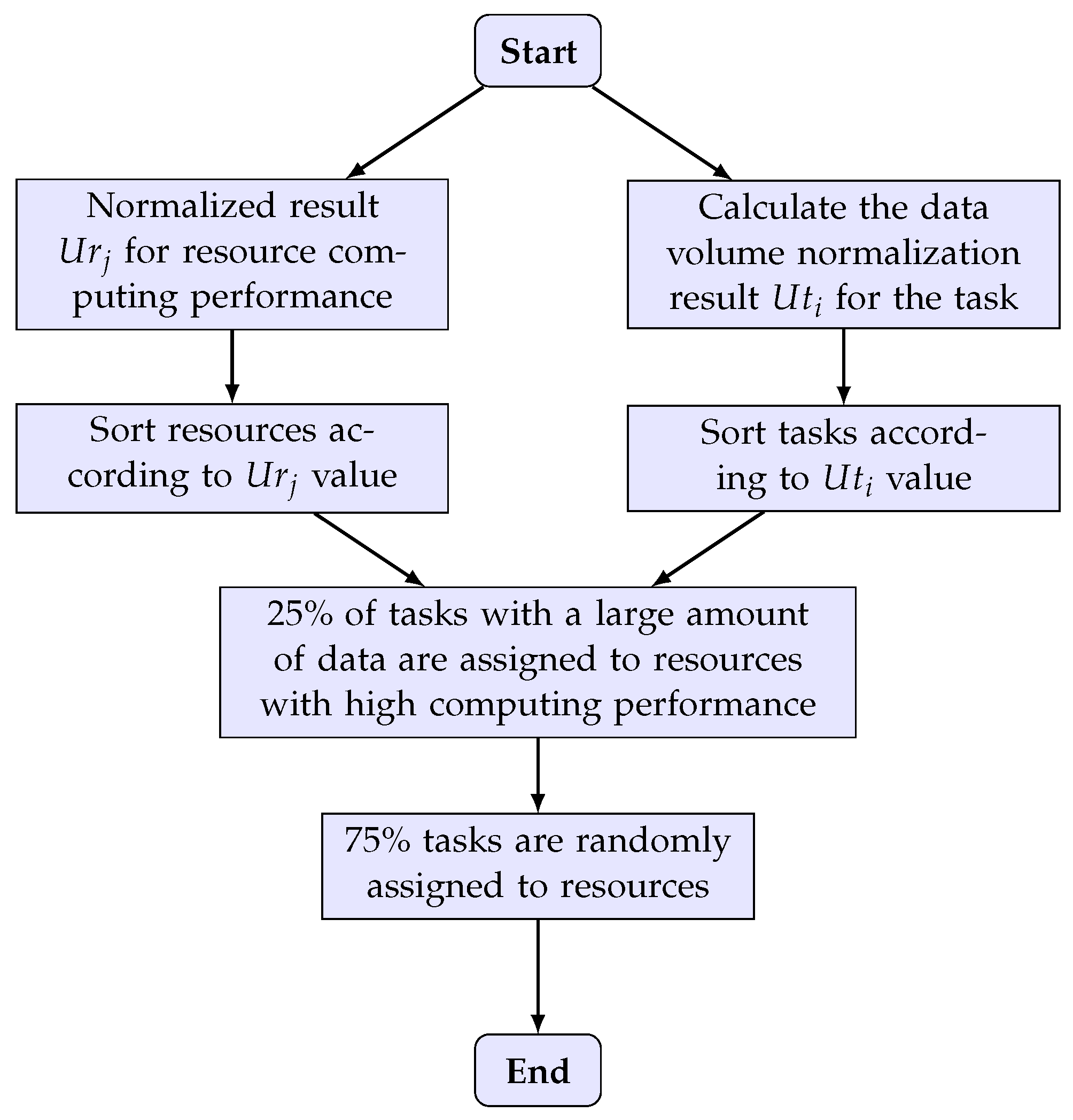
3.2. Improvements to the Initialization of Particles
3.3. Adaptive Function Design
3.4. Workflow Task Model Processing
3.4.1. Computationally Intensive Tasks
- Calculate the sum of the node weights on the path from the root node to each leaf node;
- “Gather” the path with the largest calculated value above the root node, and update the weight information of the root node;
- “Remove” the root node from the graph;
- Repeat the above process until all the nodes in the graph are “independent nodes” without successor nodes.
3.4.2. IO-Intensive Tasks
- Calculate the sum of weights on the path from the root node to each leaf node;
- “Gather” the path with the largest calculated value above the root node, and update the weight information of the root node;
- “Remove” the root node from the graph;
- Repeat the above process until all the nodes in the graph are “independent nodes” without successor nodes.
3.4.3. Algorithm Implementation
| Algorithm 2: EPSO Algorithm |
|
4. Experiments and Analysis
4.1. Workflow Task Scheduling
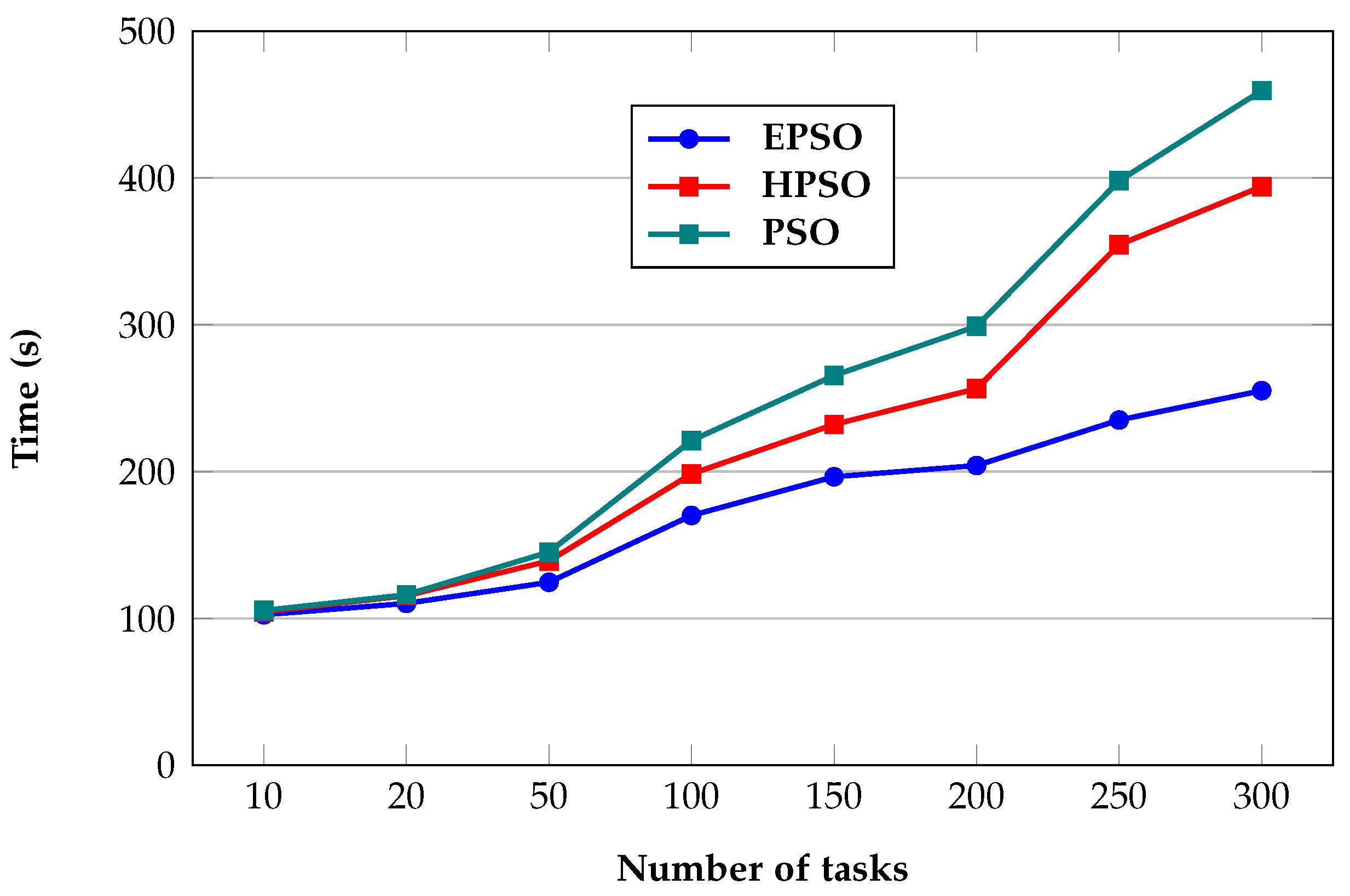
4.1.1. Time
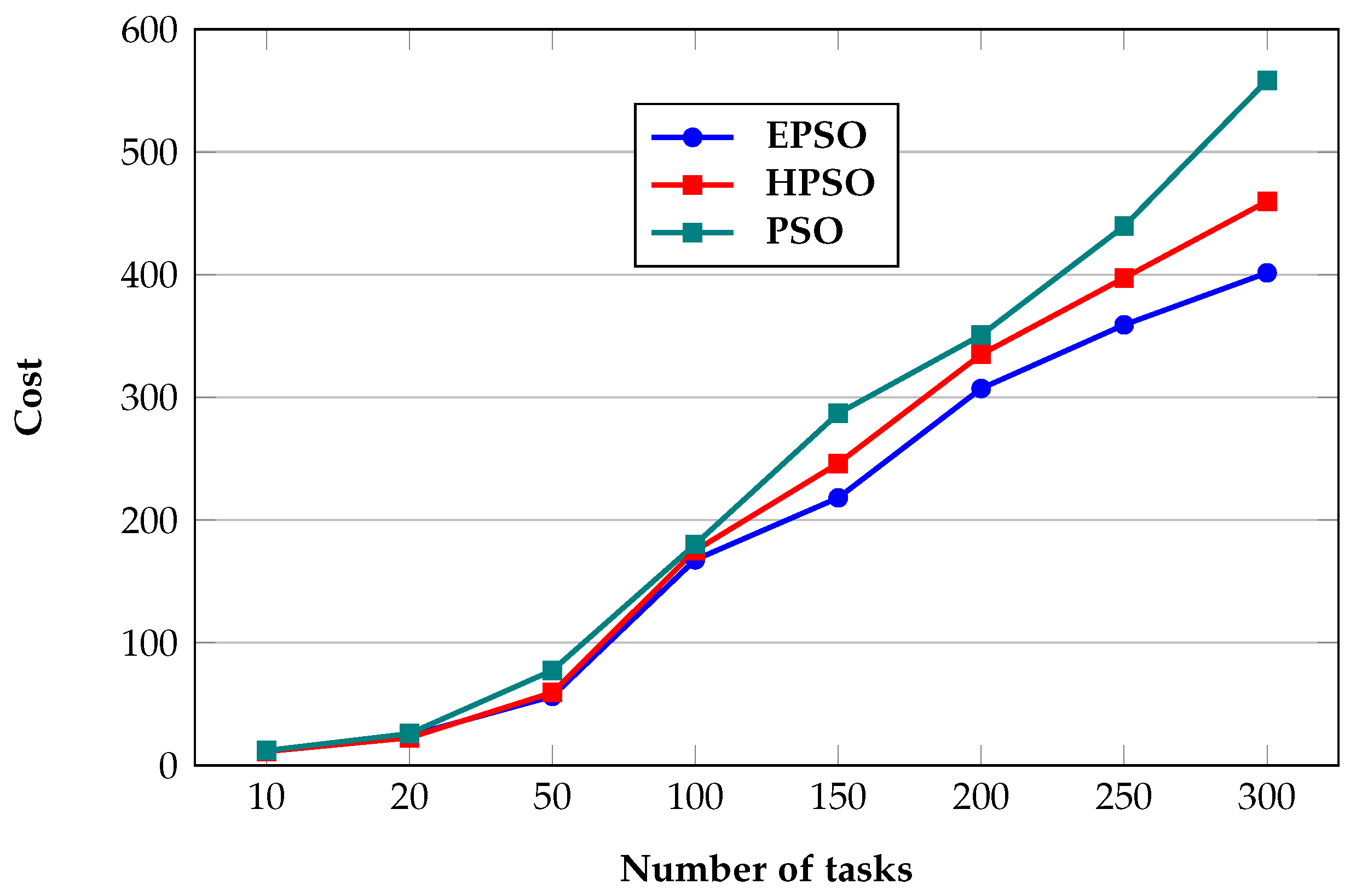
4.1.2. Cost
4.2. Independent Task Scheduling
4.2.1. Time
4.2.2. Cost
4.3. Convergence
5. Conclusions
- The adaptive function can be improved according to different application scenarios in the future.
- The optimization target can be broadened in order to consider other important objectives, such as load balancing, CPU utilization, and energy consumption.
- The integration and evaluation of the proposed algorithm in the context of a real-world unified cloud management platform can be investigated.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Marston, S.; Li, Z.; Bandyopadhyay, S.; Zhang, J.; Ghalsasi, A. Cloud computing—The business perspective. Decis. Support Syst. 2011, 51, 176–189. [Google Scholar] [CrossRef]
- Hoffa, C.; Mehta, G.; Freeman, T.; Deelman, E.; Keahey, K.; Berriman, B.; Good, J. On the use of cloud computing for scientific workflows. In Proceedings of the 4th IEEE International Conference on eScience, eScience 2008, Indianapolis, IN, USA, 7–12 December 2008; pp. 640–645. [Google Scholar] [CrossRef] [Green Version]
- Chenhong, Z.; Shanshan, Z.; Qingfeng, L.; Jian, X.; Jicheng, H. Independent tasks scheduling based on genetic algorithm in cloud computing. In Proceedings of the 5th International Conference on Wireless Communications, Networking and Mobile Computing, WiCOM 2009, Beijing, China, 24–26 September 2009. [Google Scholar] [CrossRef]
- Kennedy, J. Particle Swarm Optimization. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2011; pp. 760–766. [Google Scholar] [CrossRef]
- Xue, S.J.; Wu, W. Scheduling Workflow in Cloud Computing Based on Hybrid Particle Swarm Algorithm. Telkomnika Indones. J. Electr. Eng. 2012, 10. [Google Scholar] [CrossRef]
- Guo, L.; Zhao, S.; Shen, S.; Jiang, C. Task scheduling optimization in cloud computing based on heuristic Algorithm. J. Netw. 2012, 7, 547–553. [Google Scholar] [CrossRef]
- Varalakshmi, P.; Ramaswamy, A.; Balasubramanian, A.; Vijaykumar, P. An Optimal Workflow Based Scheduling and Resource Allocation in Cloud. In Advances in Computing and Communications; Abraham, A., Lloret Mauri, J., Buford, J.F., Suzuki, J., Thampi, S.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 411–420. [Google Scholar]
- Pandey, S.; Wu, L.; Guru, S.M.; Buyya, R. A particle swarm optimization-based heuristic for scheduling workflow applications in cloud computing environments. In Proceedings of the International Conference on Advanced Information Networking and Applications, AINA, Perth, WA, Australia, 20–23 April 2010; pp. 400–407. [Google Scholar] [CrossRef]
- Arunarani, A.R.; Manjula, D.; Sugumaran, V. Task scheduling techniques in cloud computing: A literature survey. Future Gener. Comput. Syst. 2019, 91, 407–415. [Google Scholar] [CrossRef]
- Motlagh, A.A.; Movaghar, A.; Rahmani, A.M. Task scheduling mechanisms in cloud computing: A systematic review. Int. J. Commun. Syst. 2020, 33, e4302. [Google Scholar] [CrossRef]
- Bulchandani, N.; Chourasia, U.; Agrawal, S.; Dixit, P.; Pandey, A. A survey on task scheduling algorithms in cloud computing. Int. J. Sci. Technol. Res. 2020, 9, 460–464. [Google Scholar]
- Ibrahim, I.M.; Zeebaree, S.R.M.; M.Sadeeq, M.A.; Radie, A.H.; Shukur, H.M.; Yasin, H.M.; Jacksi, K.; Rashid, Z.N. Task Scheduling Algorithms in Cloud Computing: A Review. Turk. J. Comput. Math. Educ. (TURCOMAT) 2021, 12, 1041–1053. [Google Scholar] [CrossRef]
- Houssein, E.H.; Gad, A.G.; Wazery, Y.M.; Suganthan, P.N. Task Scheduling in Cloud Computing based on Meta-heuristics: Review, Taxonomy, Open Challenges, and Future Trends. Swarm Evol. Comput. 2021, 62, 100841. [Google Scholar] [CrossRef]
- Awad, A.I.; El-Hefnawy, N.A.; Abdel-Kader, H.M. Enhanced Particle Swarm Optimization for Task Scheduling in Cloud Computing Environments. Procedia Comput. Sci. 2015, 65, 920–929. [Google Scholar] [CrossRef] [Green Version]
- Mirzayi, S.; Rafe, V. A hybrid heuristic workflow scheduling algorithm for cloud computing environments. J. Exp. Theor. Artif. Intell. 2015, 27, 721–735. [Google Scholar] [CrossRef]
- Xue, S.; Shi, W.; Xu, X. A Heuristic Scheduling Algorithm based on PSO in the Cloud Computing Environment. Int. J. u- e- Serv. Sci. Technol. 2016, 9, 349–362. [Google Scholar] [CrossRef]
- Huang, X.; Li, C.; Chen, H.; An, D. Task scheduling in cloud computing using particle swarm optimization with time varying inertia weight strategies. Clust. Comput. 2020, 23, 1137–1147. [Google Scholar] [CrossRef]
- Alsaidy, S.A.; Abbood, A.D.; Sahib, M.A. Heuristic initialization of PSO task scheduling algorithm in cloud computing. J. King Saud Univ.—Comput. Inf. Sci. 2022, 34, 2370–2382. [Google Scholar] [CrossRef]
- Su, Y.; Bai, Z.; Xie, D. The optimizing resource allocation and task scheduling based on cloud computing and Ant Colony Optimization Algorithm. J. Ambient. Intell. Humaniz. Comput. 2021. [Google Scholar] [CrossRef]
- Hamed, A.Y.; Alkinani, M.H. Task scheduling optimization in cloud computing based on genetic algorithms. Comput. Mater. Contin. 2021, 69, 3289–3301. [Google Scholar] [CrossRef]
- Chaudhary, N.; Kalra, M.; Scholar, P.G. An improved Harmony Search algorithm with group technology model for scheduling workflows in cloud environment. In Proceedings of the 4th IEEE Uttar Pradesh Section International Conference on Electrical, Computer and Electronics, UPCON 2017, Mathura, India, 26–28 October 2017; pp. 73–77. [Google Scholar] [CrossRef]
- Gabi, D.; Ismail, A.S.; Zainal, A.; Zakaria, Z.; Al-Khasawneh, A. Hybrid cat swarm optimization and simulated annealing for dynamic task scheduling on cloud computing environment. J. Inf. Commun. Technol. 2018, 17, 435–467. [Google Scholar] [CrossRef]
- Chen, X.; Long, D. Task scheduling of cloud computing using integrated particle swarm algorithm and ant colony algorithm. Clust. Comput. 2019, 22, 2761–2769. [Google Scholar] [CrossRef]
- Jia, L.W.; Li, K.; Shi, X. Cloud Computing Task Scheduling Model Based on Improved Whale Optimization Algorithm. Wirel. Commun. Mob. Comput. 2021, 2021, 4888154. [Google Scholar] [CrossRef]
- Keivani, A.; Tapamo, J.R. Task scheduling in cloud computing: A review. In Proceedings of the 2nd International Conference on Advances in Big Data, Computing and Data Communication Systems, Winterton, South Africa, 5–6 August 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Sharma, P.; Shilakari, S.; Chourasia, U.; Dixit, P.; Pandey, A. A survey on various types of task scheduling algorithm in cloud computing environment. Int. J. Sci. Technol. Res. 2020, 9, 1513–1521. [Google Scholar]
- Shami, T.M.; El-Saleh, A.A.; Alswaitti, M.; Al-Tashi, Q.; Summakieh, M.A.; Mirjalili, S. Particle Swarm Optimization: A Comprehensive Survey. IEEE Access 2022, 10, 10031–10061. [Google Scholar] [CrossRef]
- Shi, Y.; Eberhart, R. A modified particle swarm optimizer. In Proceedings of the IEEE Conference on Evolutionary Computation, ICEC, Anchorage, AK, USA, 4–9 May 1998; pp. 69–73. [Google Scholar] [CrossRef]
- Vecchiola, C.; Kirley, M.; Buyya, R. Multi-Objective Problem Solving With Offspring on Enterprise Clouds. In Proceedings of the 10th International Conference on High Performance Computing in Asia-Pacific Region, Kaohsiung, Taiwan, 2–5 March 2009; pp. 132–139. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Resource | 7 | 5 | 4 | 3 | 6 | 2 | 1 | 2 |
| Parameter | Value |
|---|---|
| Maximum number of resources | 250 |
| Particle inertia | 0.99 |
| The maximum number of iterations | 50 |
| Task length | 10,000–40,000 |
| The amount of data transferred by the task | 150–200 |
| Task computing requirements | 500–1000 |
| Task bandwidth requirements | 60–100 |
| Number of Tasks | EPSO | HPSO | PSO |
|---|---|---|---|
| 10 | 102.485 | 104.485 | 105.416 |
| 20 | 110.215 | 115.475 | 116.125 |
| 50 | 124.596 | 139.156 | 145.156 |
| 100 | 170.123 | 198.417 | 221.152 |
| 150 | 196.482 | 232.156 | 265.478 |
| 200 | 204.151 | 256.482 | 298.985 |
| 250 | 235.156 | 354.545 | 398.121 |
| 300 | 255.145 | 394.156 | 459.562 |
| Number of Tasks | EPSO | HPSO | PSO |
|---|---|---|---|
| 10 | 11.5 | 11.3 | 12.1 |
| 20 | 24.3 | 22.5 | 25.9 |
| 50 | 56.3 | 59.4 | 77.4 |
| 100 | 167.6 | 175.1 | 180.2 |
| 150 | 218.1 | 246.2 | 286.9 |
| 200 | 307.2 | 335 | 350.8 |
| 250 | 359.1 | 397.4 | 439.5 |
| 300 | 401.5 | 459.8 | 558.3 |
| Number of Tasks | EPSO | HPSO | PSO |
|---|---|---|---|
| 10 | 72.325 | 83.534 | 92.785 |
| 20 | 81.563 | 95.265 | 108.783 |
| 50 | 99.125 | 114.255 | 127.678 |
| 100 | 127.425 | 154.678 | 189.425 |
| 150 | 151.897 | 178.787 | 217.454 |
| 200 | 178.578 | 212.673 | 259.425 |
| 250 | 198.435 | 226.524 | 287.542 |
| 300 | 225.523 | 254.246 | 327.789 |
| Number of Tasks | EPSO | HPSO | PSO |
|---|---|---|---|
| 10 | 8.2 | 9.3 | 11.9 |
| 20 | 21.7 | 22.4 | 26.8 |
| 50 | 49.1 | 57.4 | 72.3 |
| 100 | 142.8 | 167.7 | 196.4 |
| 150 | 214.7 | 239.1 | 290.9 |
| 200 | 298.3 | 325.7 | 389.5 |
| 250 | 353.3 | 382.4 | 457.5 |
| 300 | 391.5 | 432.8 | 554.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anbarkhan, S.H.; Rakrouki, M.A. An Enhanced PSO Algorithm for Scheduling Workflow Tasks in Cloud Computing. Electronics 2023, 12, 2580. https://doi.org/10.3390/electronics12122580
Anbarkhan SH, Rakrouki MA. An Enhanced PSO Algorithm for Scheduling Workflow Tasks in Cloud Computing. Electronics. 2023; 12(12):2580. https://doi.org/10.3390/electronics12122580
Chicago/Turabian StyleAnbarkhan, Samar Hussni, and Mohamed Ali Rakrouki. 2023. "An Enhanced PSO Algorithm for Scheduling Workflow Tasks in Cloud Computing" Electronics 12, no. 12: 2580. https://doi.org/10.3390/electronics12122580
APA StyleAnbarkhan, S. H., & Rakrouki, M. A. (2023). An Enhanced PSO Algorithm for Scheduling Workflow Tasks in Cloud Computing. Electronics, 12(12), 2580. https://doi.org/10.3390/electronics12122580