1. Introduction
Nowadays, many plants in the real word can be formulated as uncertain nonlinear systems, such as autonomous underwater vehicles [
1], mobile robots [
2], and quadrotors [
3]. Thus, tracking problems for uncertain nonlinear systems have become one of the issues, and various control methods have been developed and employed in many physical systems to achieve tracking performance.
To deal with the impact induced by uncertainties during controller design, there emerge a large amount of tools to approximate uncertainties and combined with other controllers, e.g., neural networks (NNs) [
4,
5], fuzzy logic systems [
6,
7,
8], and disturbance observers [
9,
10,
11]. For example, by integrating with a backstepping control, an adaptive tracking controller is designed in [
5] for uncertain nonlinear systems, where an NN is utilized to estimate the uncertain term of the model. Due to an uncertain dynamical model in surface vessels, proportional derivative feedback combined with a fuzzy logic system is proposed in [
7] with satisfying tracking performance and theoretical results. Taking the disturbance ability of an observer-based controller into consideration, the tracking performance can be guaranteed. For manipulators, a sliding-mode controller is investigated for tracking problems, where a nonlinear disturbance observer is implemented to predict and remove the effect of disturbance [
10]. However, manually tunned parameters limit above controllers applied in practical applications. Recently, the unknown system dynamics estimator (USDE) is a novel estimation method to deal with uncertainty and disturbance of nonlinear systems [
12], where the state can be an added filtered operation such that invariant manifold is conducted for accurate estimation. Different from NNs and fuzzy logic systems with repeated tuning, the estimator only uses the system state and the control input and can achieve rapid convergence of disturbance estimation by adjusting a parameter. For the motion control of robot systems, lumped disturbances are estimated through an improved unknown disturbance estimator [
13]. In [
14], by implementing a USDE to compensate the disturbance, a sliding-mode control is designed to obtain the performance with fast convergence and strong robustness. Since USDEs in the above literature are aimed at integral series systems, it is difficult to solve the strong coupling and multivariable functions of nonlinear systems. Moreover, it is worth mentioning that the above control methods with an inherent structure do not discuss the output constraints such as the convergence rate and the maximum steady-state error, which are important in engineering.
Combined with reinforcement learning (RL), which is a branch of machine learning, a mass of adaptive controllers for stability of closed-loop systems have been developed. By integrating it with dynamic programming, there emerge an optimal controller with a learning ability and the balancing between the tracking performance and the control cost, which are generalized as adaptive dynamic programming (ADP) without dimensionality. One of prevalent structures is actor-critic ADP to pursue the optimal control and the optimal value function [
15,
16,
17]. However, tracking error may satisfy the preassigned convergence in practical engineering applications. To address this issue, the introduction of the RL algorithm into the prescribed performance control (PPC) has attracted attention [
18], which significantly reduces tracking error and control input and improves performance [
19,
20,
21]. In [
19], a data-driven RL algorithm for performance specification was proposed to simultaneously pursue control methods for satisfying optimality and tracking errors to meet output constraints. Combined with the fault-tolerant control (FTC), nonlinear systems with output constraints are considered by RL algorithms [
22,
23,
24]. It is noted that it is difficult to achieve the fault tolerant control by RL alone. In [
23], for nonlinear systems with actuator faults, a model-free adaptive optimal control method with specified performance was designed, where an adaptive observer is employed to estimate faults, and the incremental system parameters are estimated by the recursive least squares identification method. By combining the PPC with ADP, the optimal control strategy is obtained, such that tracking error satisfies the specified performance. By introducing an intermediate controller, a controller, and a fault tolerant controller based on RL algorithms, a fault-tolerant dynamic surface control algorithm based on actor-critic ADP was proposed in [
24] for nonlinear systems with unknown parameters and actuator faults, which avoids the difficulty of RL in fault tolerant control. For the manipulator, a robust motion control method with specified performance based on reinforcement learning was proposed in [
25]. The measurement noise is eliminated by carefully adding an integral term and adopting a robust generalized proportional integral observer, and an optimal control strategy based on error transformation was designed with the actor-critic ADP method to ensure the stability of the system. For the high-order nonlinear multi-agent system containing uncertainty, the optimal consistency control problem with specified performance is considered in [
26], where the stability of a closed-loop system and the convergence of consensus errors within a certain range are proved. Based on an actor-critic network, the optimal control is investigated for robot [
27] and pure feedback system [
28] separately. It is noted that the above controllers rely on multiple neural networks to ensure the stability and optimality of the system. The weight of the neural network is complicated due to the increasing number of nodes, and many parameters are difficult to adjust. In order to satisfy the optimal predetermined performance, the main idea is to transform the constrained tracking error into an unconstrained variable by constructing transformation function, and approximate optimal control is designed within actor-actor NN by minimizing the value function related to the unconstrained variable. Noting that the Hamilton-Jacobi-Isaacs (HJI) equation can be solved for deriving the optimal control in [
29,
30], it is deemed to be conservative for the worst case of disturbance with massive control inputs. Moreover, existing design and theoretical analysis of the preset performance optimal control are mostly combined with fault-tolerant control, robust control, and adaptive control. There is no relevant research for the USDE-based optimal control to assure the preassigned convergence rate.
Motivated by the above statements, we proposed an optimal control with asymmetric performance constraints under the framework of critic-only ADP by constructing a new value function. The highlights in this article can be expressed as follows:
(1) Compared with the existing observer-based controllers [
9,
10,
11], where the disturbance is estimated with observers by adjusting manually multiple parameters, the USDE was employed to approximate the lumped disturbance of nonlinear uncertain systems with an invariant manifold principle. Moreover, differing from previous function approximator-based control schemes [
12,
13,
14], by combining the RL technique into the optimal control design, the precise tracking performance and the low control cost can be achieved.
(2) Different from the optimal control derived by the actor-critic ADP framework in [
24,
26,
27,
28], a critic-only NN was designed for online learn optimal control without constructing an actor NN. In addition, to achieve the convergence rate with a preassigned region, a novel value function was minimized, such that tracking errors can evolve within the prescribed region with low control consumption. In contrast to the traditional gradient descent for weight update in actor-critic ADP, the weight law was designed ingeniously to update the weight of a critic NN, reduce the online training computation and accelerate the weight convergence.
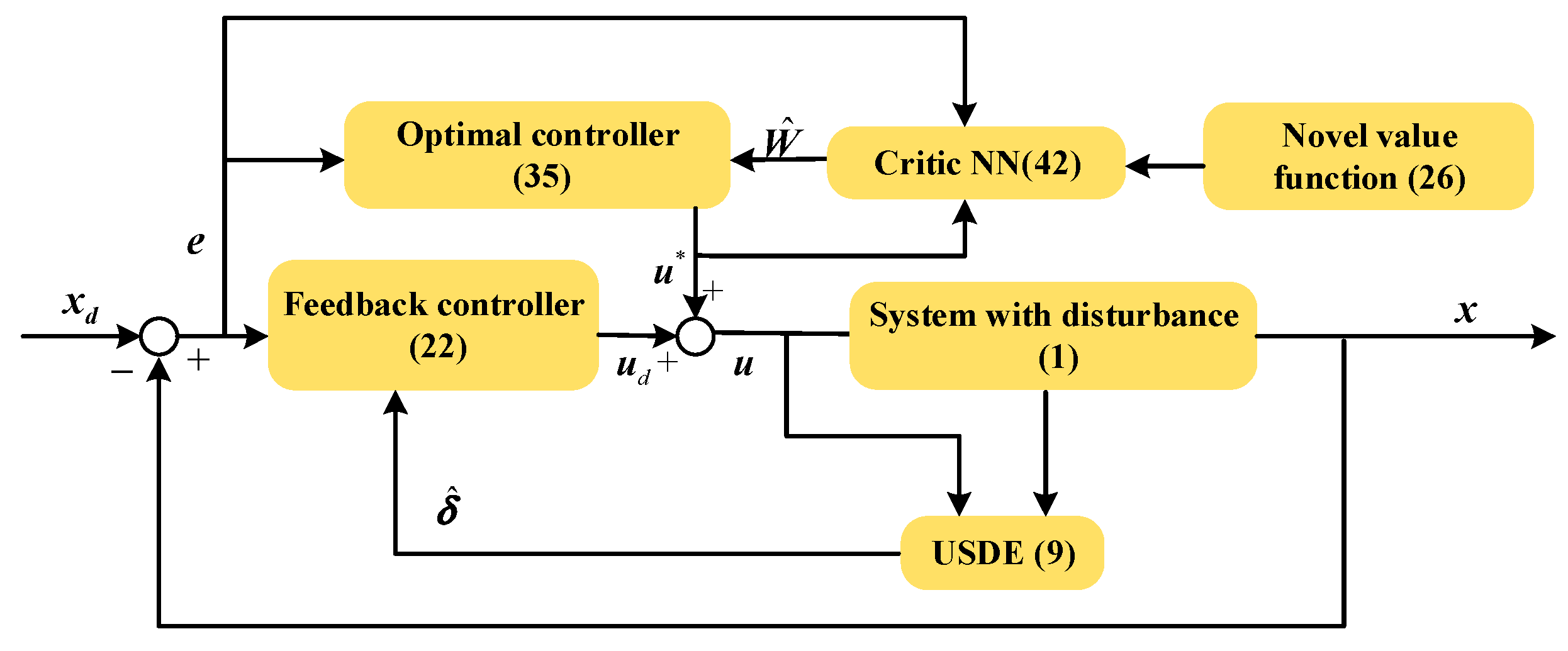
The outline of the article is organized as follows. We first gave the definition of the optimal tracking control problem with prescribed performance in
Section 2. In
Section 3, the main result of the control design was discussed, in which a feedback controller and an optimal controller were proposed. The stability analysis is illustrated in
Section 4.
Section 5 provides the effectiveness of the proposed controller on two examples.
Throughout this paper, the vector or matrix is represented by bold fonts, which is different from the scalar. represents the zero matrix and denotes the identity matrix. is the diagonal matrix conducted with vector . is the minimized eigenvalue of the corresponding matrix.
2. Preliminaries
The following multiple-input–multiple-output system with disturbance is considered:
where
denotes the measurable state vector and
represents the control input vectors;
and
are uncertain due to modelling errors and disturbance caused by the environment; matrix
is precisely known, which represents the input dynamics. Given bounded reference command
, the dynamic system of tracking errors can be derived from System (1) as:
Due to the Lipschitz continuity of
,
, and
, System (2) can be stabilizable from [
31].
The goal of the paper is to conduct the optimal tracking control, such that tracking errors are limited within a prescribed region while minimizing the novel value function. Specifically, the prescribed region is denoted by the following equality:
where
and
are predefined envelope functions with specific expressions:
with
representing the lower bound on the rate of convergence and
,
,
. It should be noted that uncertain
and
can be considered as lumped disturbances
. On account of the initial state
, the following assumptions are necessary to achieve the controller design.
Assumption 1. There exists the positive constant satisfying .
Assumption 2. The and are chosen such that (3) holds.
Remark 1. There exist many plants, such as autonomous underwater vehicles [1] and quadrotors [3], which can be modeled as System (1) with disturbance. Unlike the investigated controllers in [1] and [3] regardless of control consumption, the proposed optimal tracking controller was designed to achieve the stability of a closed-loop system with an adequate control input.
4. Stability Analysis
Due to the above-mentioned theoretical result of the disturbance approximation error and weight error, the stability of the closed-loop system can be proven with prescribed performance.
Theorem 2. For nonlinear uncertain system (1) with constraint (3), the optimal control is designed with weight update (42), the tracking error is uniform ultimate boundedness and evolves within predefined region.
Proof of Theorem 2. According to Equations (21) and (35), the system of the tracking error can be obtained:
with
is the optimal value function form and
. □
Firstly, due to the weight convergence of the critic NN, one has:
Then,
In addition,
Lastly, the stability of the whole system can be derived as:
If
, Equation (50) can be written in the following form:
where
Noting that
is bounded, the boundedness of
can be derived along the boundness of disturbance estimation errors, the weight estimation error, and the HJB error. Thus, the parameters of the controller design should satisfy:
such that
, resulting in the uniform ultimate boundedness of the tracking error.
For arbitrary
, there exists:
which can indicate the PPC is be violated.
5. Simulations
In this section, we implemented the following examples to demonstrate the effectiveness and superiority of the investigated controller scheme. Without loss of generality, the sampling period was 5 ms, and solver ode4 was selected during the simulations.
Example 1. In order to verify the design of the optimal tracking controller with preset performance, a second-order nonlinear system is considered as:The given track commands are and , and the tracking error should meet the following constraints:where and . The initial state is . For verifying the devised controller, we assume that:which is uncertain, and disturbance is added. In order to achieve the control objective, the proposed optimal tracking controller is realized based on a feedback control and an optimal control. The feedback control is based on a USDE to compensate the influence of disturbance on the system. The optimal regulation law is to minimize value function (26) under the ADP framework, where , and are the identity matrices of the respective dimensions. In order to approximate the optimal value function, the activation function was selected as , and other simulation parameters were selected as , , , and . The initial weight was .
The simulation results for a period of 20 s are shown from
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8.
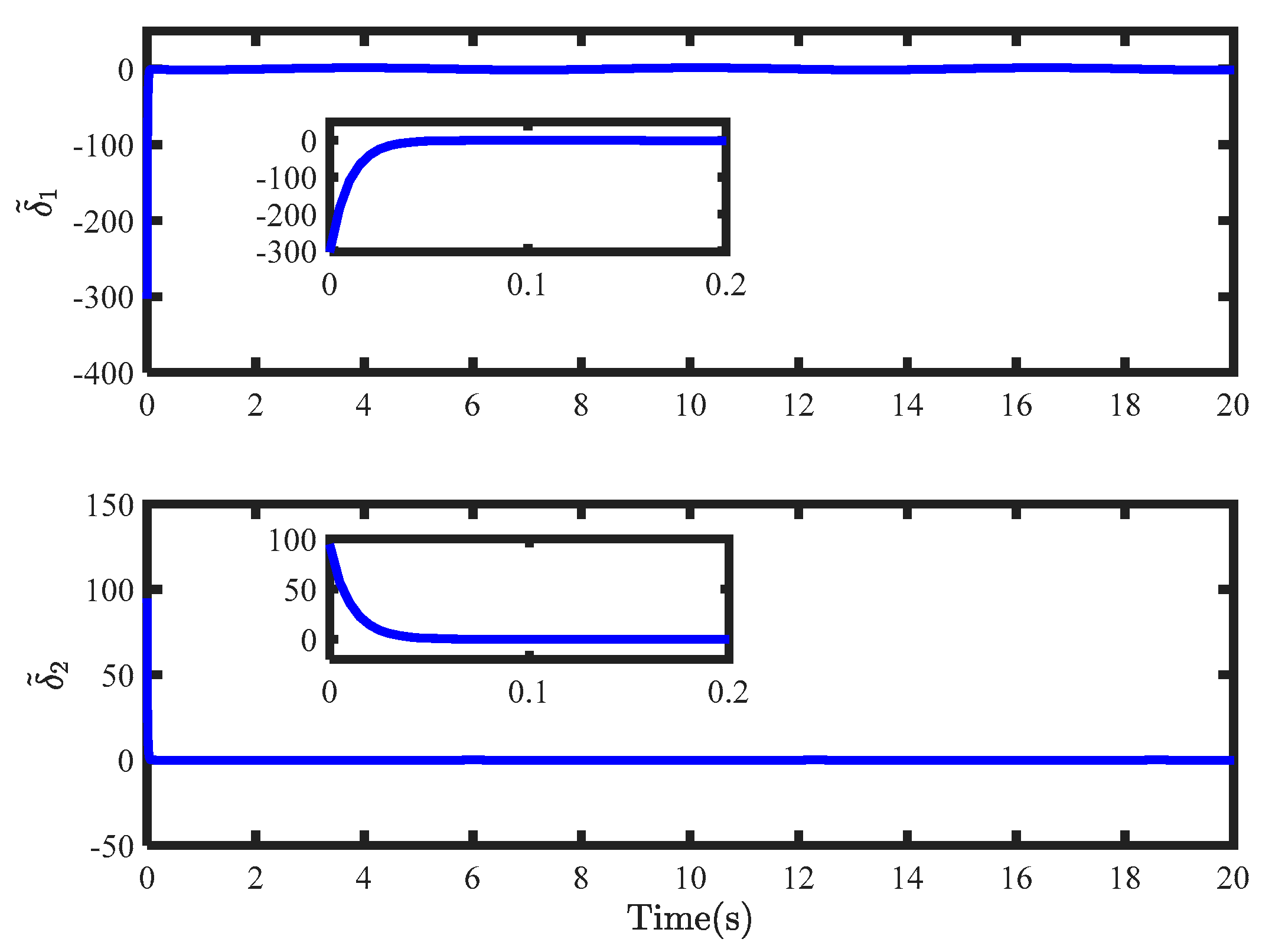
Figure 2 gives the simulation results of the system state and the reference command, which indicates that the state can accurately track the reference command within 4 s. The tracking errors enter the steady state quickly, which can be due to the estimation from the USDE, as shown in
Figure 3. Lumped disturbances can be approximated precisely within 0.1 s.
The control inputs of the proposed controller are described in
Figure 4, which include the feedback control and the optimal control.
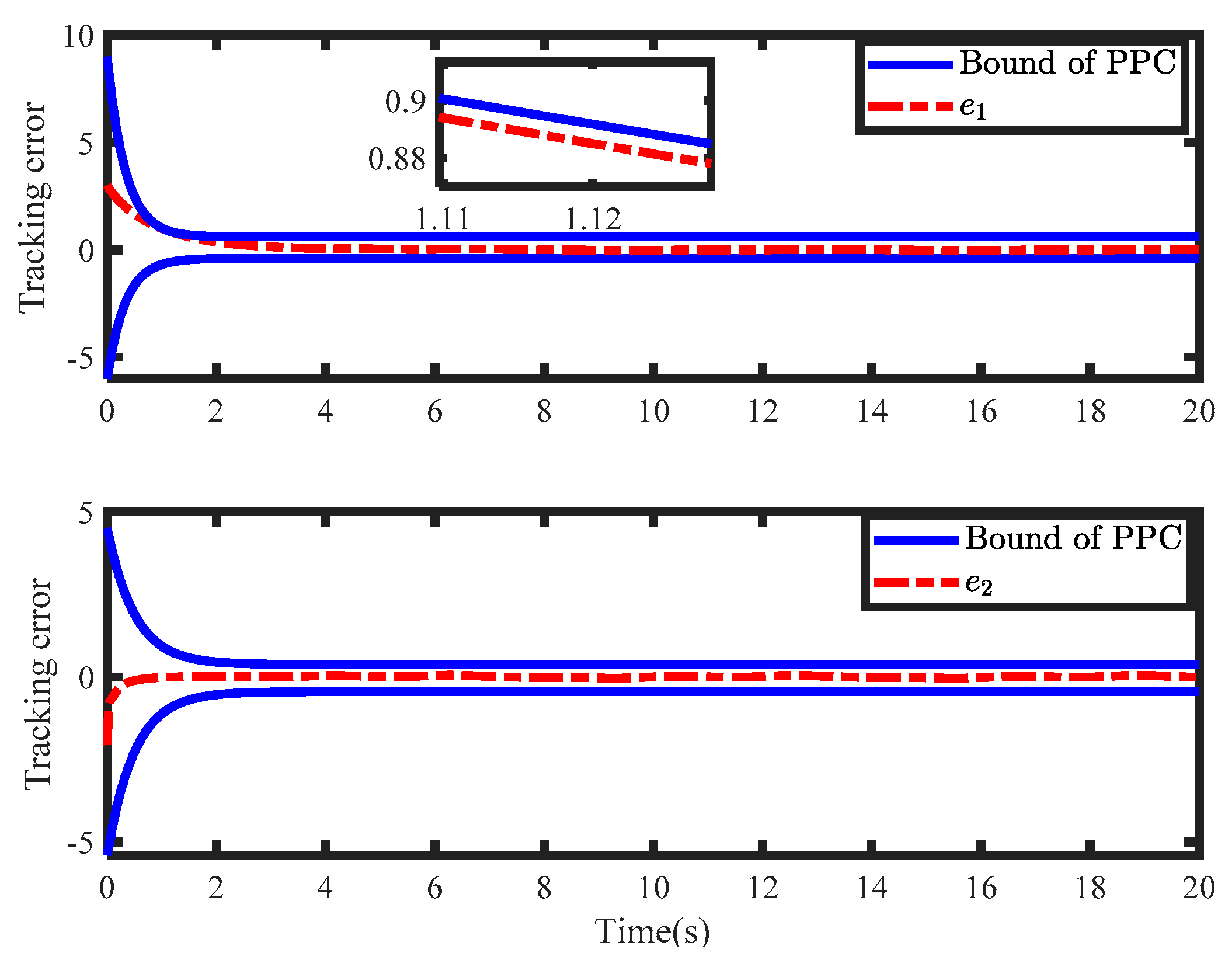
Figure 5 describes the simulation results of the tracking error and asymmetric output performance constraints. It can be found that the tracking errors converged to a specified asymmetric envelope, which indicated that the designed controller with an optimal preset performance can make tracking errors converge to zero within a predetermined convergence rate. The stability of the closed-loop system hinged on the weight of the critic NN, as illustrated in
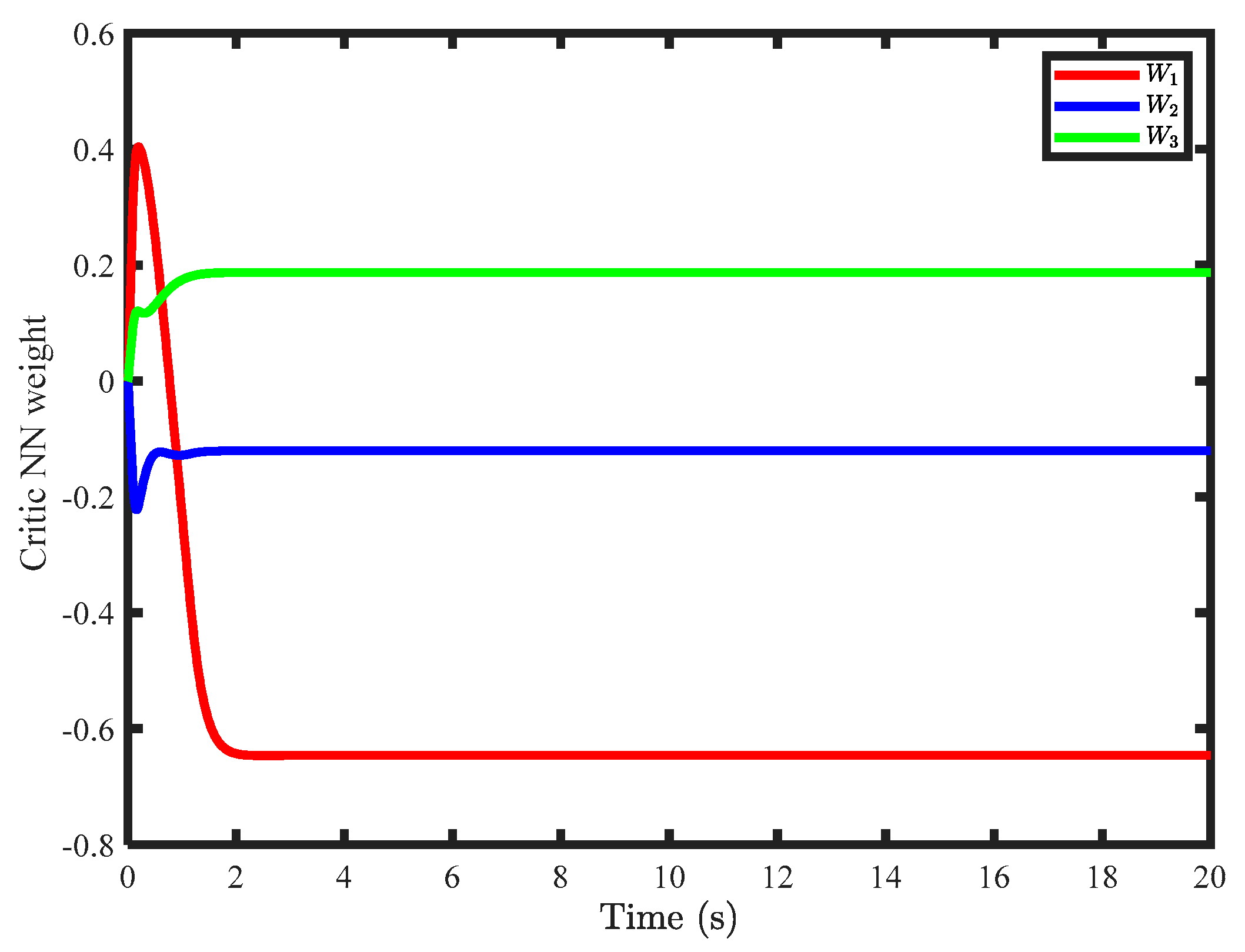
Figure 6, which showed the approximation of weight can converge to the ideal weight within 2 s.
In order to illustrate the superiority of the proposed controller in achieving preset performance, it was compared with the optimal controller based on the traditional value function in [
32], which is named WPPC. Noting that the controller in [
32] is based on a fixed-time disturbance observer, we set the feedback controller based on a USDE for the sake of fair comparison.
Figure 7 shows the simulation results of the tracking error and the PPC envelope. Although the system state tracked the reference command successfully, the tracking errors could not evolve within the envelope, and the transient performance could not be guaranteed to meet the output constraints. This indicates that the convergence rate of the tracking error was slower than that of the specified convergence rate and the predetermined performance could not be guaranteed.
Figure 8 compares the value functions of the two controllers for 20 s. In contrast, the value function of the new controller decreased by 6% compared to the optimal controller without taking into preset performance account. Therefore, the new controller can ensure that the tracking error meets the output performance constraints while its value function is smaller.
Example 2. Noting that the trajectory tracking problem of the quadrotor can be affected by uncertain dynamic drift and disturbance induced by wind, the effectiveness of the proposed control is carried on a quadrotor [3,31]. Noting that position and attitude loops are considered in [3,31], the position dynamic of the quadrotor is considered as:where parameters of the model are listed in Table 1. The given reference trajectory is . To carry out the proposed controller on Equation (53), we reformulate it as:
where
For approximating the optimal control, the critic NN is structured with 15 neurons with [−5,5]. For the initial position and weight, we choose the following parameters:
and
. The other controller parameters are listed in
Table 2.
The performance of the proposed controller was discussed as follows.
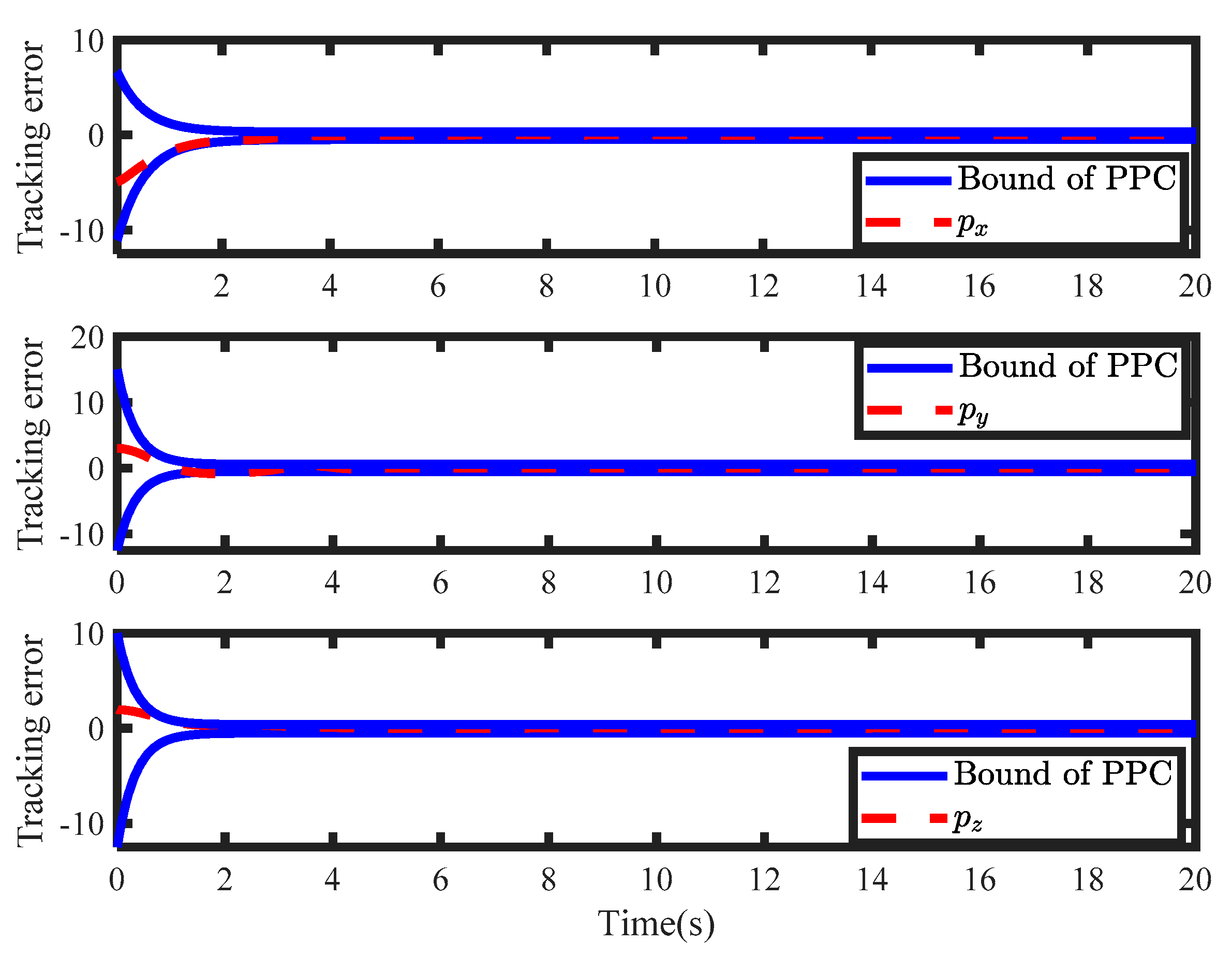
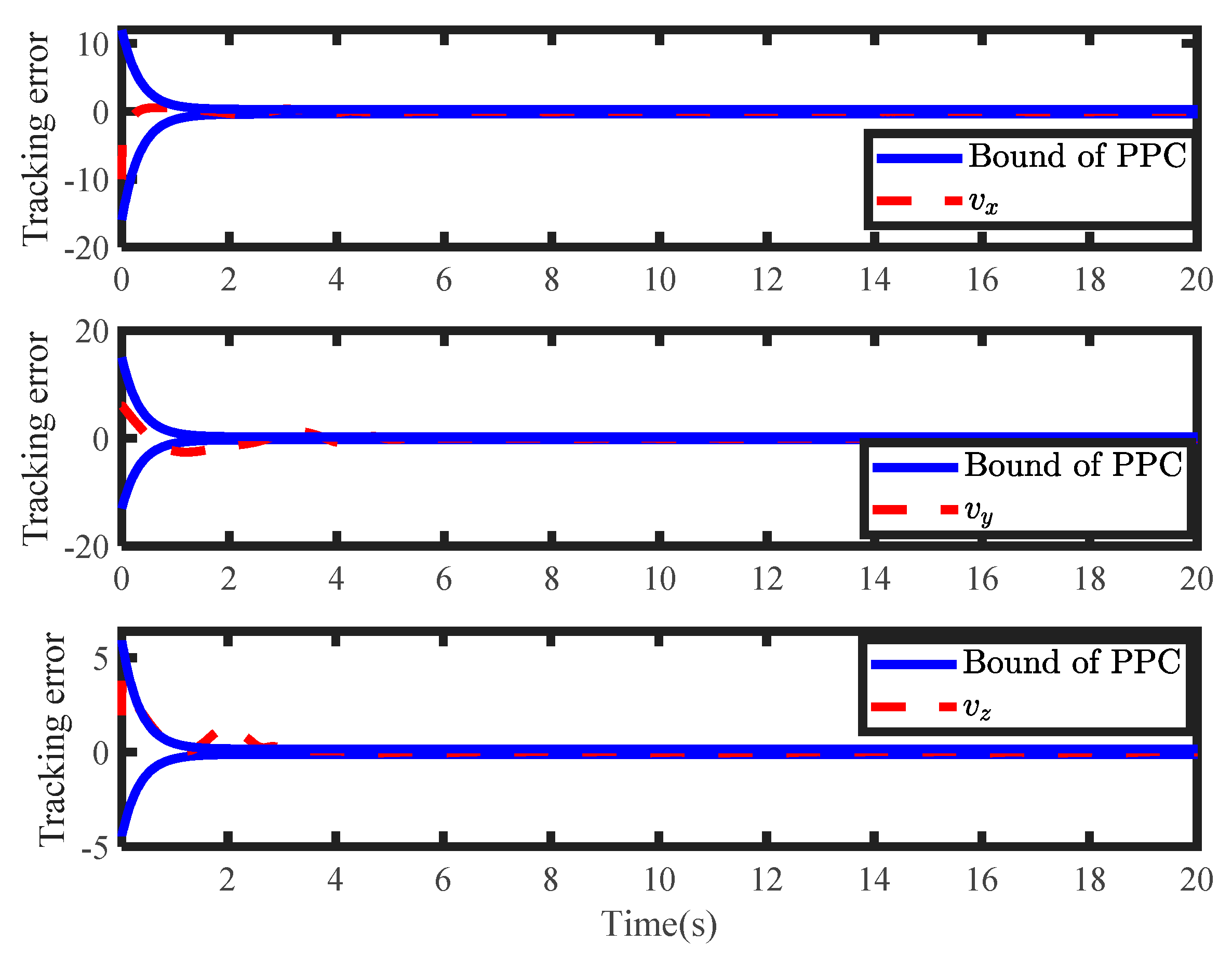
Figure 9 and
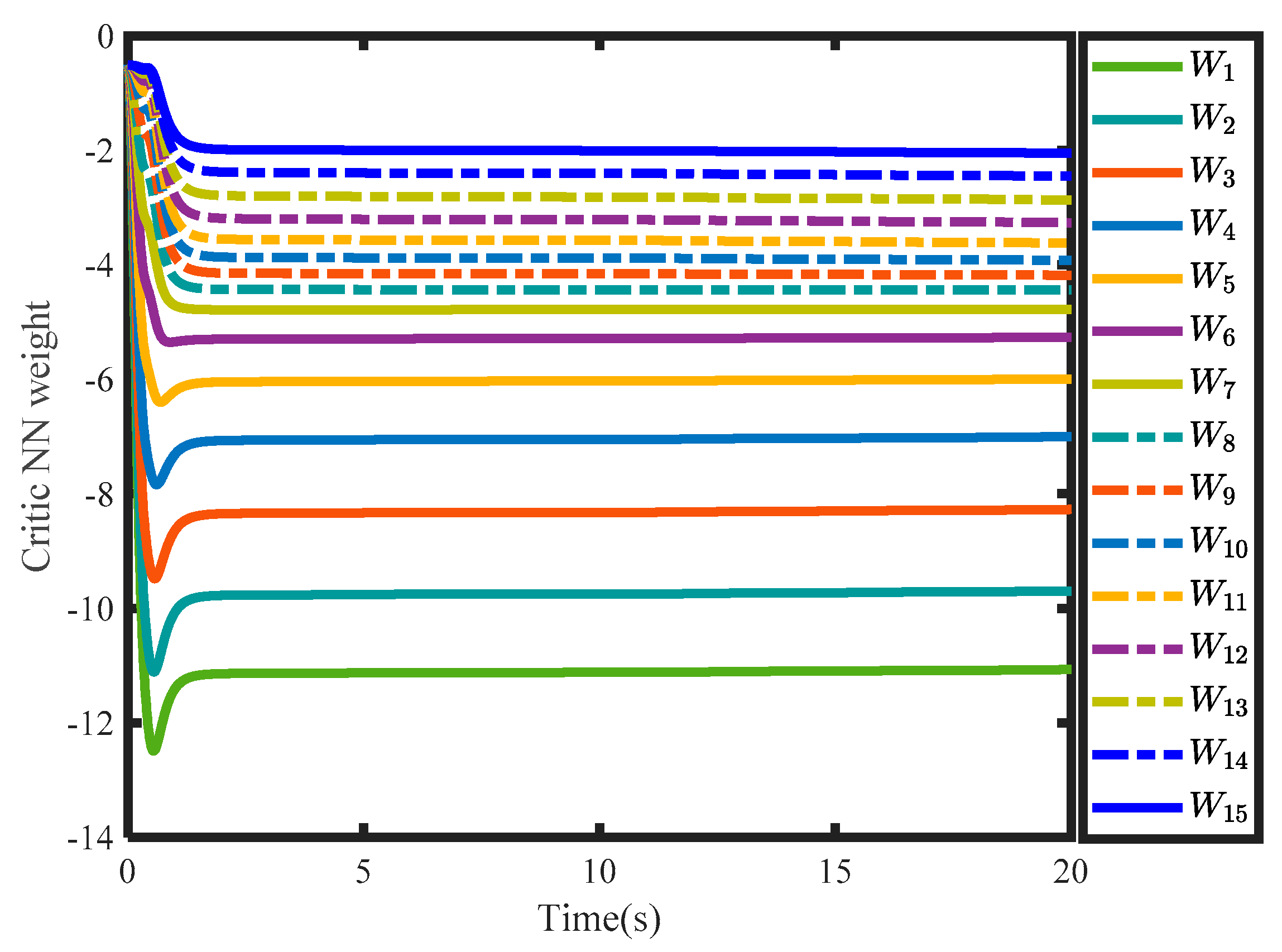
Figure 10 show the tracking performances of the position and the velocity. It can be found that tracking errors evolved the predefined constraints. By running the novel value function, tracking errors converged to zero within the convergence rate. During the controller design, the weight of the critic NN is crucial for solving the HJB equation.
Figure 11 gives the convergence of weight, which is essential for the stability of the closed-loop system. To verify the advantage of the novel value function, the optimal tracking controller in [
32] was executed for System (54). In the position loop, the tracking errors of the position and the velocity are shown in
Figure 12 and
Figure 13, which indicates the tracking errors could not evolve the predefined envelope by minimizing the value function without the PPC constraints. Therefore, the effectiveness of the proposed optimal control was verified to deal with prescribed performance. Noting that the proposed controller and the optimal tracking controller in [
32] are based on simulation, we will further consider experimental validation based on physical systems to verify the feasibility of the proposed method, where complete response associated is impossible.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}