

AV PV-RCNN: Improving 3D Object Detection with Adaptive Deformation and VectorPool Aggregation


Abstract
1. Introduction
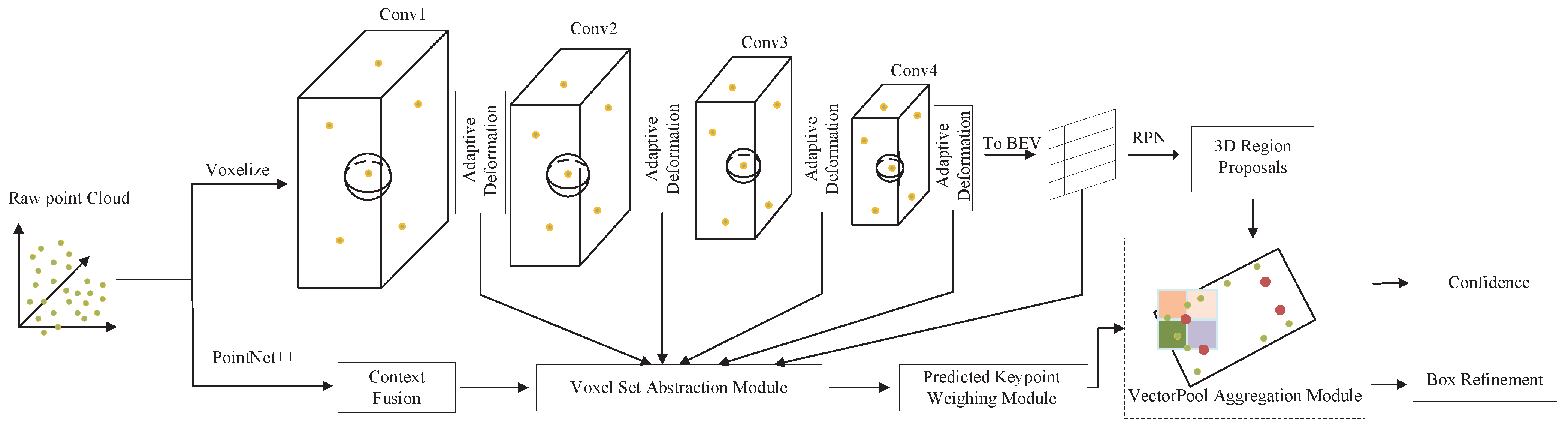
- Replacing the set abstraction of the Voxel Set Abstraction Module in PV-RCNN with the adaptive deformation module. Through the adaptive deformation module, the keypoints can be aligned with the most distinctive areas, and the most prominent features of objects of different scales can be adaptively gathered and focused, so that the model can detect uneven point cloud density better.
- Replacing the set abstraction in the RoI-grid pooling module in PV-RCNN with the VectorPool aggregation module. The VectorPool aggregation module uses independent kernel weights and channels to encode position-sensitive local features in different regions centered on grid points, which not only preserves the spatial structure of grid points well, but also saves the consumption of computing resources.
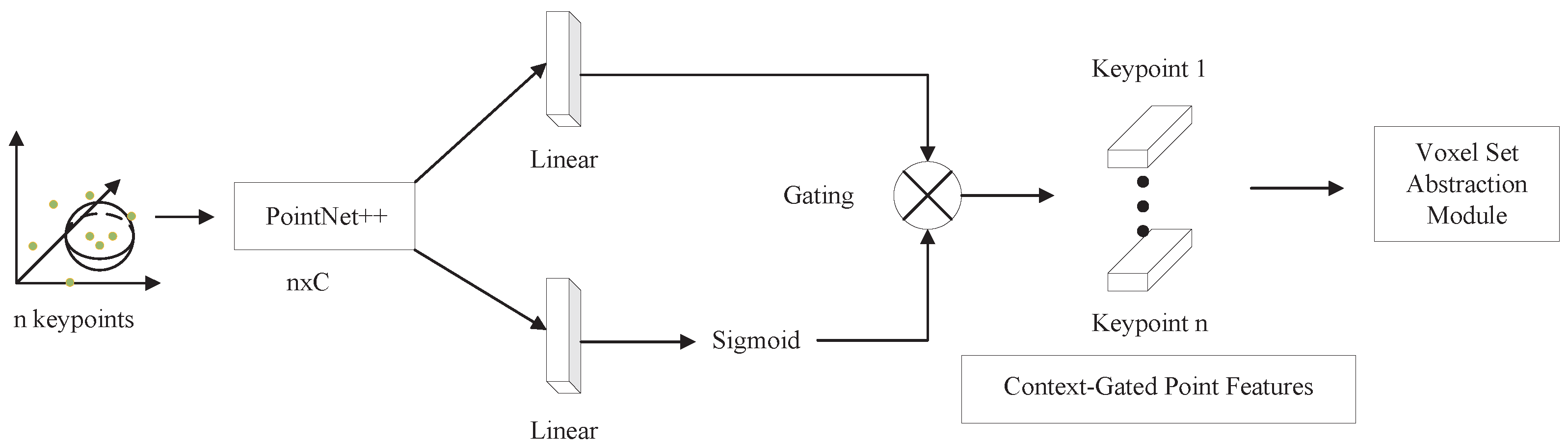
- Using the context fusion module to perform feature selection on keypoints obtained directly from PointNet++ in PV-RCNN. Representative and discriminative features can be dynamically selected from local evidence through the context gating mechanism, which adaptively highlights relevant contextual features, thus facilitating the optimization of more accurate 3D candidate boxes.
2. Related Work
3. Method
3.1. PV-RCNN
3.2. Voxel Set Abstraction Module
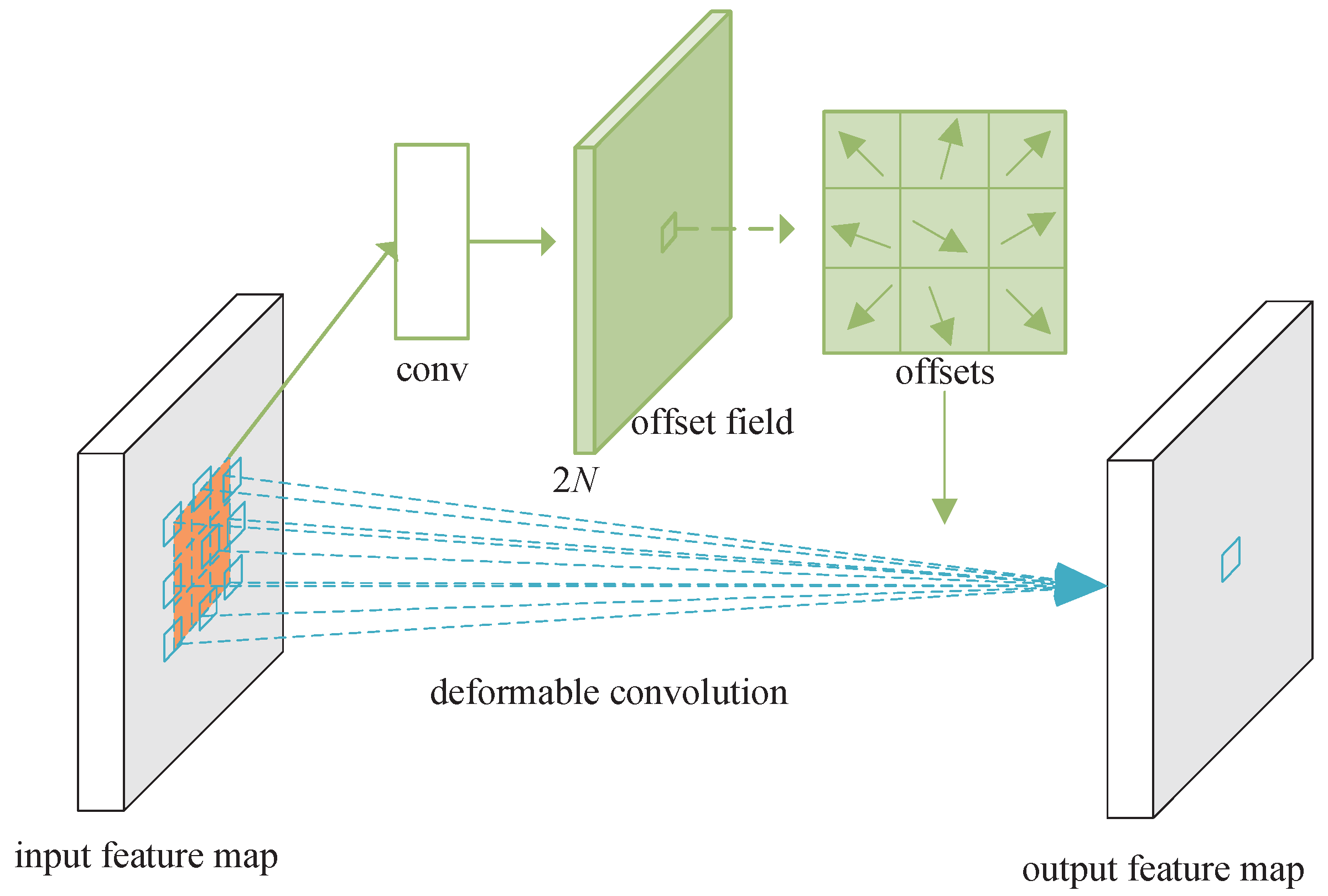
3.3. Deformable Convolution
3.4. Adaptive Deformation Module
3.5. Context Fusion Module
3.6. RoI-Grid Pooling Module
3.7. VectorPool Aggregation Module
4. Experimental Settings
4.1. Dataset Description
4.2. Evaluating Metrics
4.3. Other Setting
5. Results
5.1. Algorithm Comparison and Analysis
5.2. Ablation Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3D proposal generation and object detection from view aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars:Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Mao, J.; Xue, Y.; Niu, M.; Bai, H.; Feng, J.; Liang, X.; Xu, H.; Xu, C. Voxel transformer for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-based 3D object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3D object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3D object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. Std: Sparse-to-dense 3D object detector for point cloud. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Qi, C.R.; Litany, O.; He, K.; Guibas, L.J. Deep hough voting for 3D object detection in point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3DSSD: Point-based 3D single stage object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Bhattacharyya, P.; Czarnecki, K. Deformable PV-RCNN:Improving 3D object detection with learned deformations. arXiv 2020, arXiv:2008.08766. [Google Scholar]
- Shi, S.; Jiang, L.; Deng, J.; Wang, Z.; Guo, C.; Shi, J.; Wang, X.; Li, H. PV-RCNN++: Point-voxel feature set abstraction with local vector representation for 3D object detection. Int. J. Comput. Vis. 2023, 131, 531–551. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Gkioxari, G.; Malik, J.; Johnson, J. Mesh r-cnn. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Qin, C.; You, H.; Wang, L.; Kuo, C.C.J.; Fu, Y. Pointdan: A multi-scale 3D domain adaption network for point cloud representation. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Shi, S.; Wang, Z.; Shi, J.; Wang, X.; Li, H. From points to parts: 3D object detection from point cloud with part-aware and part-aggregation network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2647–2664. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Car AP (IoU = 0.7) | Cyclist AP (IoU = 0.5) | Pedestrian AP (IoU = 0.5) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | Easy | Moderate | Hard | |
| PointPillar [5] | 87.75 | 78.39 | 75.18 | 81.57 | 62.93 | 58.98 | 57.30 | 51.41 | 46.87 |
| SECOND [4] | 90.55 | 81.61 | 78.61 | 82.96 | 66.74 | 62.78 | 55.94 | 51.14 | 46.16 |
| PointRCNN [11] | 91.81 | 80.70 | 78.22 | 92.50 | 71.89 | 67.48 | 62.10 | 55.55 | 48.83 |
| PartA2-Net [22] | 92.15 | 82.91 | 81.99 | 90.34 | 70.13 | 66.92 | 66.88 | 59.67 | 54.62 |
| PV-RCNN [15] | 92.10 | 84.36 | 82.48 | 89.10 | 70.38 | 66.01 | 62.71 | 54.49 | 49.87 |
| PV-RCNN++ [17] | 91.52 | 84.51 | 82.29 | 93.00 | 75.52 | 70.93 | 63.58 | 57.56 | 52.18 |
| Deformable PV-RCNN [16] | 91.93 | 84.83 | 82.57 | 90.75 | 73.77 | 70.14 | 66.21 | 58.76 | 53.79 |
| Ours | 92.25 | 84.63 | 82.30 | 94.43 | 73.95 | 69.49 | 66.47 | 59.08 | 54.09 |
| Model | Car Recall (IoU = 0.7) | Cyclist Recall (IoU = 0.5) | Pedestrian Recall (IoU = 0.5) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | Easy | Moderate | Hard | |
| PV-RCNN [15] | 90.16 | 76.64 | 74.79 | 93.33 | 67.58 | 60.26 | 68.26 | 59.36 | 51.92 |
| Ours | 90.27 | 79.69 | 76.07 | 95.07 | 67.45 | 59.77 | 72.38 | 63.34 | 55.31 |
| Iterations | PV-RCNN/Memory (MB) | Ours/Memory (MB) |
|---|---|---|
| 100 | 8085 | 7081 |
| 200 | 8085 | 7083 |
| 300 | 8085 | 7083 |
| 400 | 8085 | 7083 |
| PV-RCNN/FPS | Ours/FPS |
|---|---|
| 3 | 4 |
| Adaptive Deformation | VectorPool Aggregation | Car AP (IoU = 0.7) | Cyclist AP (IoU = 0.5) | Pedestrian AP (IoU = 0.5) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Mid | Hard | Easy | Mid | Hard | Easy | Mid | Hard | ||
| 92.10 | 84.36 | 82.48 | 89.10 | 70.38 | 66.01 | 62.71 | 54.49 | 49.87 | ||
| 91.93 | 84.83 | 82.57 | 90.75 | 73.77 | 70.14 | 66.21 | 58.76 | 53.79 | ||
| 91.58 | 82.82 | 82.20 | 88.86 | 70.66 | 66.42 | 64.93 | 57.65 | 53.12 | ||
| 92.25 | 84.63 | 82.30 | 94.43 | 73.95 | 69.49 | 66.47 | 59.08 | 54.09 | ||
| Context Fusion | Car | Cyclist | Pedestrian |
|---|---|---|---|
| × | 82.63 | 71.09 | 58.46 |
| √ | 84.63 | 73.95 | 59.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guan, S.; Wan, C.; Jiang, Y. AV PV-RCNN: Improving 3D Object Detection with Adaptive Deformation and VectorPool Aggregation. Electronics 2023, 12, 2542. https://doi.org/10.3390/electronics12112542
Guan S, Wan C, Jiang Y. AV PV-RCNN: Improving 3D Object Detection with Adaptive Deformation and VectorPool Aggregation. Electronics. 2023; 12(11):2542. https://doi.org/10.3390/electronics12112542
Chicago/Turabian StyleGuan, Shijie, Chenyang Wan, and Yueqiu Jiang. 2023. "AV PV-RCNN: Improving 3D Object Detection with Adaptive Deformation and VectorPool Aggregation" Electronics 12, no. 11: 2542. https://doi.org/10.3390/electronics12112542
APA StyleGuan, S., Wan, C., & Jiang, Y. (2023). AV PV-RCNN: Improving 3D Object Detection with Adaptive Deformation and VectorPool Aggregation. Electronics, 12(11), 2542. https://doi.org/10.3390/electronics12112542