1. Introduction
With the recent development of real-time image processing, technologies for object recognition and object retrieval in images extracted from real-time operating devices, such as closed-circuit television (CCTV), are being actively implemented [
1,
2,
3,
4,
5,
6,
7]. These technologies can be used in various fields, such as crime prevention, monitoring systems, and analyzing traffic information.
Content-based image retrieval (CBIR) involves the retrieving of images by using features extracted from objects in video images. CBIR involves vectorizing the features extracted from images and determining the similarities between the vectors to retrieve similar images. In sum, CBIR is a way of retrieving images from a database. In CBIR, a user specifies a query image and obtains images from the database that are similar to the query. To find the most similar images, CBIR compares the content of the query image with the database images. Owing to the development of new technologies, such as artificial intelligence and machine learning, researchers have conducted studies into extracting various features from images [
8,
9,
10,
11]. Data becomes increasingly high-dimensional as the features provided by images become more varied. Therefore, similarity retrieval techniques that use high-dimensional data are needed to retrieve and compare similar images or objects. Additionally, the indexing structure for high-dimensional data similarity retrieval must be appropriately constructed, in accordance with the characteristics of high-dimensional data.
Nearest neighbor search (NNS) deals with the problem of finding the closest or most similar item to a given point. Closeness is typically expressed in terms of a dissimilarity function, such as Euclidean distance, Manhattan distance, and other distance metrics. Formally, the nearest-neighbor (NN) search problem is defined as follows: given a set S of points in a space M and a query point q ∈ M, find the closest point in S to q. k-NN search is a generalized NN problem. k-NN needs to find the k closest points.
Generally, in the distributed processing environment, a distributed k-NN query is processed as follows. First, each distributed node indexes data points. Depending on the indexing scheme, the k- NN query processing methodology is different. In general, when a k-NN query is inputted, all of the nodes are requested to process the k-NN query. Each node generates k closest data points and k data points generated in n nodes are merged. Finally, the result includes the k closest points to the query from the merged result.
Various studies have been conducted recently to address these problems [
12,
13,
14,
15,
16,
17]. A distributed, in-memory-based, high-dimensional indexing technique was proposed to efficiently perform image retrieval using high-dimensional feature data [
12]. The authors of [
12] utilized big data analysis platforms, such as Spark, to implement distributed, in-memory-based, high-dimensional indexing. In addition, the authors of [
13] proposed an M-tree [
13] indexing algorithm on Spark. Since all distributed servers participate in query processing [
12], the load on all the servers can increase when there are many retrieval requests from users. In another study, a master/slave model for distributed index query processing was used to perform efficient image retrieval in airport video monitoring systems [
14]. The researchers proposed a distributed MVP (multi-vantage-point) tree, which was based on the MVP tree. However, it had an inherent flaw: it was difficult to load large-scale, high-dimensional data into its memory. Moreover, backtracking operations frequently occurred when performing k-NN query processing in the tree. Backtracking is a commonly used algorithm for searching. When processing k-NN queries in a tree structure, it explores a specific node and returns to the parent node if there are no results. It generates query results by repeating this process. In another study, a distributed k-d tree [
16] was proposed to enhance the performance of k-NN processing [
15]. However, depending on the amount of distributed data, the height of the k-d tree could increase, which would increase the search time [
15]. Using a k-d tree also results in frequent backtracking operations when performing k-NN processing [
14].
Contrary to conventional hash functions [
17], LSH (locality-sensitive hashing) aims to maximize hash collisions when indexing high-dimensional data. It stores similar data in the same bucket to improve the efficiency of the search and indexing. Using random vectors, LSH transforms high-dimensional data into low-dimensional bucket indexes. Following a query request, the system searches for the bucket that contains the query result using the query location, measures the actual distance between the data within the bucket, and performs k-NN query processing. However, in LSH, the k-NN results may include false positives, depending on the index creation parameters. More buckets can be searched to ensure accurate results; however, this increases the search cost because it requires distance comparisons among all the data in the adjacent buckets. Because k-NN query processing involves finding the closest k items, distance-based indexing is efficient as it can pre-calculate the distance values to the items and index them. In this paper, we used iDistance, which is a distance-based indexing method for efficient k-NN query processing.
The authors of [
18] used a deep learning technique based on a combination of CNNs to classify images, and used RNNs to analyze natural language queries. They also used CNNs to take advantage of the deep learning technology in image content classification. The RNN model helps users to make search queries more efficiently. The authors of [
19] identified occupied and vacant parking lots using a hybrid deep learning model. The model proposed in that study combined the superior features of CNNs and LSTM deep learning methods. The authors of [
20] proposed a CBIR system that was based on multi deep neural networks, which combined convolutional neural networks (CNNs) and k-NN methodologies. The feature extraction of the user-supplied image was performed based on the CNNs, and the image similarity was calculated based on the k-NN methodologies in order to return a list of images. The authors of [
21] compared the image retrieval of various machine learning models, such as SVMs (support vector machines), k-NNs, and CNNs.
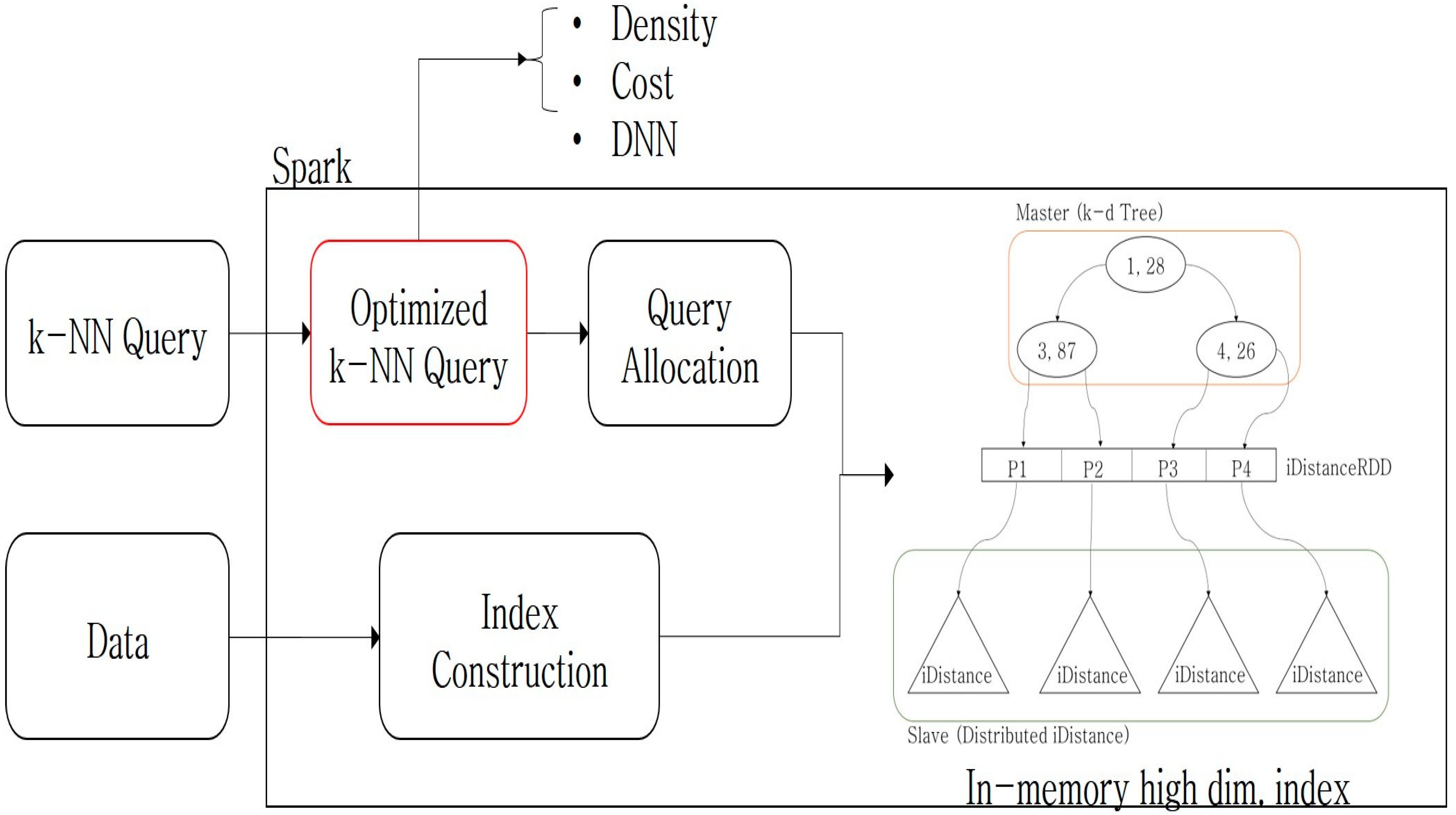
In this paper, we propose k-NN optimization techniques that use a distributed, in-memory, index retrieval system structure, which can effectively retrieve large-scale, high-dimensional data. The proposed techniques were implemented on Spark to process large-scale data and to perform distributed index construction, using our research team’s previous study [
17]. Spark is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters. It utilizes in-memory caching and optimized query execution for fast analytic queries against data of any size. In our previous study, the k-NN query was converted into a simple range query owing to the index’s characteristics; therefore, k-NN query processing optimization was required. In this study, we proposed three techniques for k-NN query optimization: optimization, using the density of the feature data; cost-based optimization, which statistically stores and processes query processing costs; and DNN-based optimization, using machine learning. The validity and superiority of the proposed indexing and optimization techniques were verified using performance evaluations for each optimization technique. This study makes the following contributions to the field:
A distributed indexing scheme for high-dimensional data: This study proposes a distributed, high-dimensional indexing scheme. The proposed scheme is a Spark-based, distributed indexing scheme for processing large, high-dimensional data efficiently.
A distributed query allocation method: In order to perform efficient distributed processing, an efficient query allocation method is required. In this paper, we propose a distributed query allocation method based on query information.
Three k-NN query optimization techniques: In this paper, we propose three optimization techniques for efficient k-NN query processing, based on a high-dimensional distributed index. We present three optimization techniques based on density, query processing costs, and deep learning using index information. We verified the validity of the proposed optimization techniques through performance evaluations.
The remainder of this paper is structured as follows.
Section 2 explains the existing high-dimensional indexing methods and describes their problems.
Section 3 describes the k-NN optimization techniques in the proposed distributed, high-dimensional indexing methods.
Section 4 demonstrates the superiority of the proposed techniques through performance evaluations and compares the existing techniques with those proposed in this study. Finally,
Section 5 reports on the conclusions of the study and future research directions.
2. Related Work
To efficiently perform CBIR, researchers have studied high-dimensional indexing techniques for retrieval, using the high-dimensional feature vectors of objects within images [
12,
13,
14,
15,
16,
22,
23,
24,
25,
26].
A method to address the challenges in quickly and efficiently indexing large-scale multimedia data was proposed in [
12]. The proposed technique used Spark to build a distributed M-tree, enabling fast and cost-effective multimedia database retrieval. However, each node (or executor) in Spark did not have a specified indexing area and performed partitioning and indexing using the data partitioning policy. Consequently, the nodes were not filtered, because all of them must be visited when processing a k-NN query; therefore, when many queries occur, the load on all of the nodes increases, because they have to be visited when processing the queries. As a result, when the search is concentrated on a single node, the overall query processing time can be delayed until the result for that node is returned.
A new indexing method to address the scalability issue of k-d trees for k-NN query processing was proposed in [
16]. The researchers constructed a distributed k-d tree to index multi-dimensional data, which is often used in this manner [
16]. The distributed k-d tree consists of a global k-d tree and local k-d trees, which can serve as both masters and as slaves at each terminal node of the global k-d tree. The global k-d tree is used to divide the entire data area for processing, and local k-d trees are constructed for each partitioned area to build the index. The master/slave indexing structure is built and processed to perform distributed processing. Because the distributed k-d tree divides the area, it is easy to identify nodes that do not participate in query processing. Therefore, in [
1], a filtering feature was added, which enabled more efficient query processing. However, a disadvantage of the k-d tree are the frequent backtracking operations. Moreover, because the distributed k-d tree is rebuilt as a set of local k-d trees, in addition to the global k-d tree, the query processing time increases as the tree height increases, depending on the data distribution.
A distributed MVP tree, distributed-MVP (D-MVP), was implemented to perform high-dimensional indexing for image retrieval in an airport video monitoring system [
14]. The MVP tree is an improved version of the VP tree. To improve the effectiveness of later tree searches, the MVP tree divides the data using multiple partition points and stores them in each node. It also stores the distance to the partition points. The D-MVP tree uses a master/slave model for query processing, wherein the master node divides the area. The master monitors the overall system load and maintains balance. To avoid overloading a slave node, when input data are concentrated on it, the master node increases the height of the tree—a method called “hot spot load balancing”—to dynamically add partition areas. However, the M-tree family constantly calculates distances at higher nodes to find terminal nodes that can conduct query processing, which increases the load on the master node and delays the processing time in real-time query processing environments.
iDistance indexing [
22] is a distance-based indexing technique that represents high-dimensional data as one-dimensional distances and indexes the data in a B+-tree [
22,
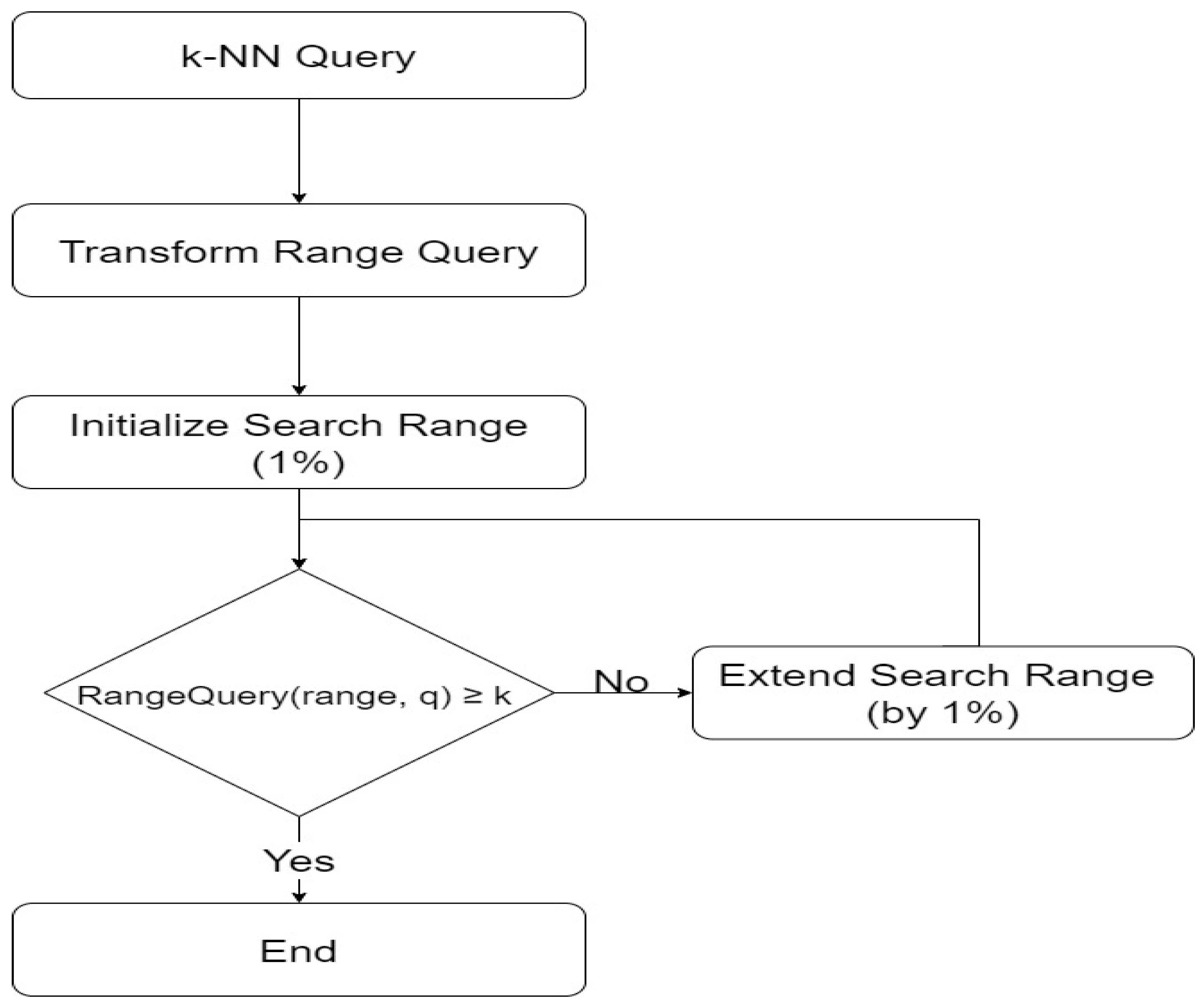
23]. The distance is calculated between the reference point and the corresponding data when they are displayed in the distance space. Key-values are generated in order of proximity to the reference point, and these key-values are indexed in the B+-tree. Because indexing is performed using only distance, the exact location of the object cannot be determined, and there is a possibility of generating the same key-value. Since iDistance adds a constant to the distance, there is almost no probability that one data point will be included in two reference points. However, if the distance exceeds the constant, an incorrect key-value may be generated. Therefore, an appropriate constant must be assigned. K-NN queries are converted to range queries for processing in iDistance because the index is the distance to the reference point. It is not possible to precisely locate all the data. The distance value between the query and reference points is calculated in order to compute the actual key-value to be inserted into the B+ tree, and only the data within the search range in which the k-NN query is converted is searched to generate the k-NN result. The search range converted to iDistance is initially set to 1% of the total index area, which may lead to frequent search range expansions. Therefore, an optimization technique is needed to convert these k-NN queries into range queries.
The authors of [
24] proposed an optimization technique based on product quantization. They applied the optimization technique in different similarity search scenarios, such as brute-force, approximate, and compressed-domain. They also presented a near-optimal algorithmic layout for exact and approximate k-nearest neighbor searches on GPU.
The authors of [
25] proposed a distributed image retrieval framework, based on location-sensitive hash (LSH) on Spark. A distributed, K-means-based bag of visual words (BoVW) algorithm and an LSH algorithm were proposed to build LSH index vectors on Spark in parallel. It performs a K-means-based BoVW distributed algorithm by extracting SIFT feature data point sets. However, it takes more than 95% of the time for the whole process of constructing the index, and the effect of clustering is very uncertain.
The authors of [
26] proposed a fast CBIR system using Spark (CBIR-S), which targets large-scale images. It uses a memory-centric distributed storage system called Tachyon to enhance the write operation. It can speed up by using a parallel k-NN search method, which is based on the MapReduce model on Spark. In addition, it can exploit the cache method of the Spark framework.
A distributed, in-memory, high-dimensional indexing technique—which our research team previously proposed—was presented in [
17]. It aims at efficient CBIR in large-scale, high-dimensional data, using a high-dimensional indexing technique with a master/slave structure. Additionally, Spark was used to build an index for high-dimensional vector data. A hybrid distributed high-dimensional index was implemented to address the issue of k-d trees and iDistance. Combining the advantages of both indexes, the overall structure consists of a master/slave structure, in which the master is responsible for data distribution and for selecting slaves for query processing, which reduces the system load. The slave nodes process the query and conduct the data indexing.
The k-NN algorithm has a wide range of uses because it finds k neighbors for a given value of k. However, it has a drawback: the processing cost increases proportionally to the amount of data or the number of dimensions. Several studies have been conducted to improve the throughput of k-NN [
26,
27,
28].
The “jump method” was proposed to increase the speed of k-NN query processing [
28]. To achieve this, the k-means algorithm is applied to the data, and clusters are generated using the formula proposed in the study. When the user provides a value for k, k centers are created, and the k-means algorithm allocates each data point to the nearest center.
Reference [
29] overcomes the limitation of the original k-NN algorithm’s ignoring of the influence of the neighboring points, which directly affects localization accuracy. The researchers improved the indoor location identification using Wi-Fi-received, signal strength indicator (RSSI)-based fingerprints. The RSSI is highly dependent on the access point (AP) and the fingerprint learning stage, thus DNN is used in conventional k-NN to resolve this dependency. Additionally, DNN is used to classify fingerprint data sets. Then these possible locations in a certain class are classified by the improved k-NN algorithm to determine the final position. The improved k-NN is conducted by boosting the weights on K-nearest neighbors according to the number of matching AP.k-NN, and DNN were used to address the intrusion detection accuracy of existing intrusion detection systems [
30]. Network attack data are classified by performing classification and labeling tasks on a “CICIDS-2017” dataset, which includes network attacks. The k-NN algorithm is used for machine learning, whereas DNN is used for deep learning, and the outputs of the two methods are then compared. A comparison with the general k-NN queries using the results demonstrates the superiority of DNN.
To perform efficient k-NN in a pre-built, high-dimensional index structure, an optimized k-NN query processing technique, which is tailored to the index structure, is required. This study investigates various k-NN optimization techniques for distributed, in-memory, high-dimensional indexes. The proposed techniques utilize deep learning models to optimize k-NN query processing performance. The proposed technique utilizes iDistance’s k-NN query processing method. iDistance converts a k-NN query into a range query and iteratively increases the scope of the search from 1% of the total index area until it finds k points. Here, a deep learning model was used to find a way to optimize the initial search area. We started with the idea that we can learn the initial search area based on many of the k-NN query processing logs that have been performed previously. In the query log, the query point information and k value information of the k-NN query were used as input features of deep learning, and the query processing result (final search area) was used as the correct answer data to perform weight learning of the DNN. This allows for optimal initial search values when a new k-NN query is entered, which is determined by iDistance as the initial search area, and query processing is performed.
4. Performance Evaluations
This section demonstrates the validity of the proposed k-NN query processing optimization techniques through our performance evaluations. The optimal model was derived from a performance evaluation of the proposed DNN model, and the query processing time was compared with existing studies. The proposed techniques find k nearest data precisely when processing k-NN queries. That is, it achieves 100 % accuracy when processing k-NN queries. Therefore, we do not evaluate the accuracy of k-NN queries in the proposed techniques, but only the query processing time.
Table 1 shows the performance evaluation environment. The distributed environment was implemented with four nodes, which consisted of an Intel(R) Core(TM) i5-6400, 2.7 GHz 4 Core processor (Santa Clara, CA, USA) and 48 GB of main memory. The evaluation was conducted using a total of eight partitions, with two partitions allocated to each server. The proposed techniques were implemented on Spark 2.3.1 (Apache Software Foundation, Wilmington, DE, USA). Additionally, the DNN model for machine-learning-based optimization was implemented by using TensorFlow 2.0.0 (Google, Mountain View, CA, USA).
The feature data that can be distinguished for each image must be extracted for use in the query processing.
Table 2 shows the experimental data’s features. The dataset consisted of the image features that were extracted using the scale-invariant feature transform (SIFT) [
32] algorithm. The SIFT extracts the features invariant to the image’s size and rotation. The dimension of each data point can have values ranging between 0 and 255, and one data point represents the object features within a single image file. A dataset of one million 128-dimensional data points was used.
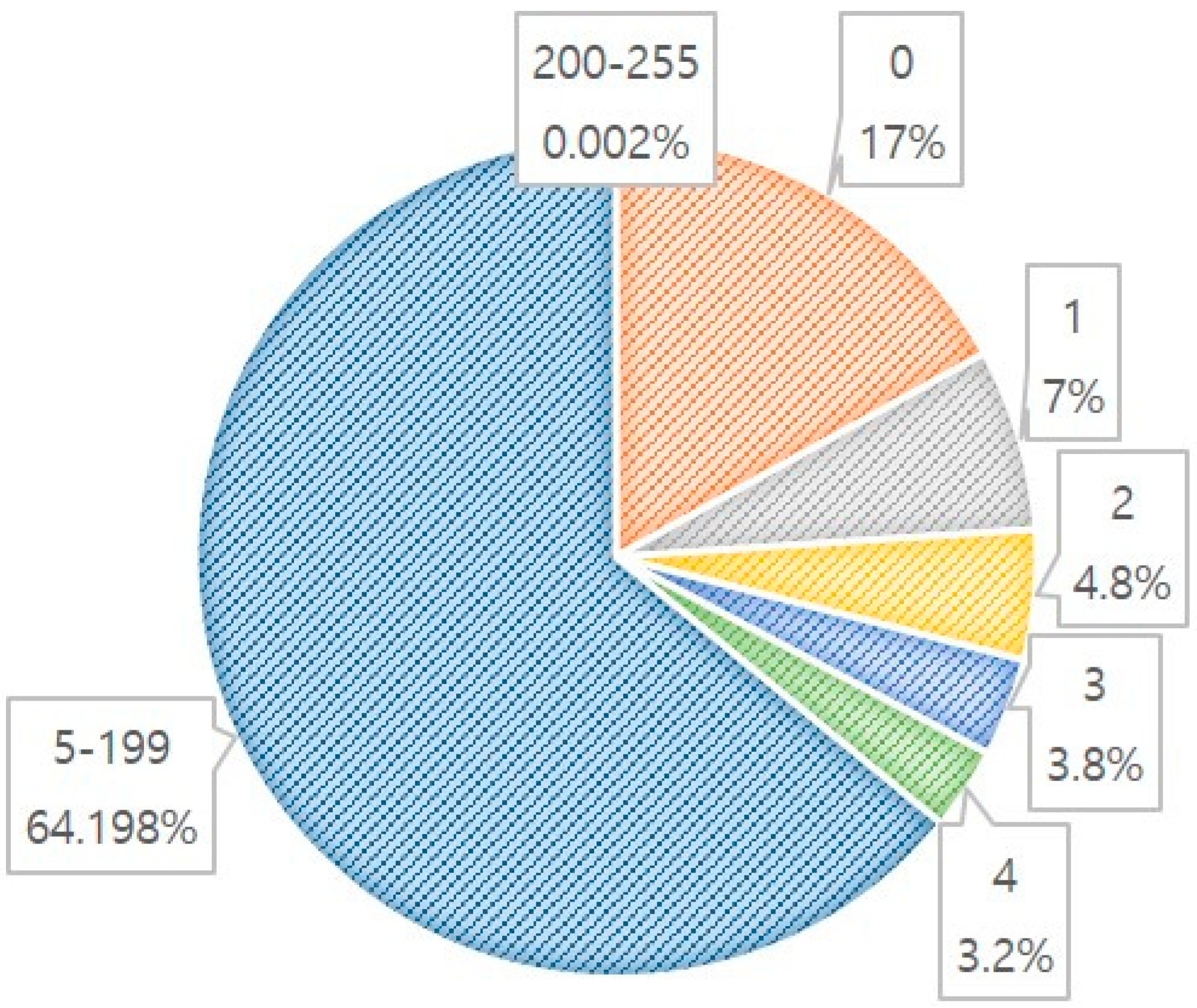
Figure 9 shows the distribution of all the data values. Comparing the distribution of the values from 0 to 255, out of 128 million data points, 21 million had a value of 0 (17% of the total), 7% had a value of 1, 4.8% had a value of 2, 3.8% had a value of 3, 3.2% had a value of 4, and 0.002% had values of 200–255. The performance evaluation used skewed data extracted by the SIFT algorithm.
To demonstrate the validity of the optimization technique using the DNN model, the MSE was evaluated in accordance with the DNN model depth. We created the model using TensorFlow, an open-source platform for machine learning, as the underlying platform. In total, 80% of the total data were used for training and 20% were used for validation. We used the Adam function, which is commonly used in DNN.
Figure 10 shows the MSE according to the DNN model’s depth. As the depth value increased, the MSE decreased up until a depth of eight and, after that, it started to increase. This was confirmed as having been caused by overfitting—a problem in machine learning models.
To avoid overfitting, we selected an appropriate depth using the results of previous experiments and conducted the training accordingly. Keras is an open-source library that serves a Python interface for artificial neural networks. It acts as an interface for the TensorFlow and offers various functions to optimize machine learning models.
Figure 11 shows the MSE according to the optimization function. The depth of the DNN model was set to six. According to the performance evaluation results, Adamax [
33] showed the smallest MSE value. Therefore, we conducted a performance evaluation using the Adamax optimization function, which demonstrated the best performance.
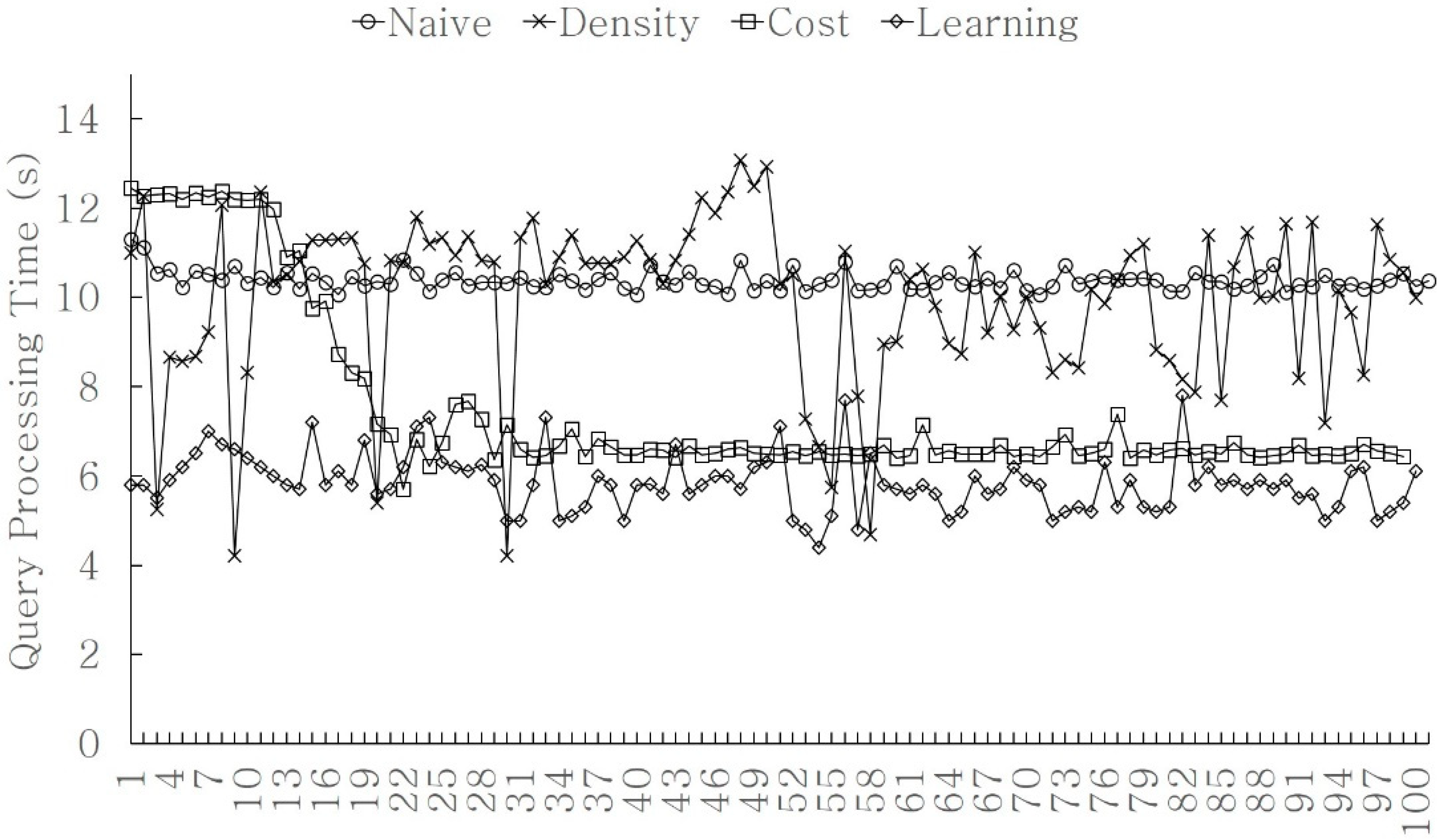
In order to demonstrate the validity of the need for optimization, we evaluated the effectiveness of each optimization technique. We compared the existing iDistance technique with the three optimization techniques proposed in this study. The query processing time was compared after 100 queries had been performed.
Figure 12 shows the performance comparison results of the k-NN query processing techniques. The x-axis represents the query number, which is the order in which the queries were input. The queries continued to be processed using the existing schemes, and the performance did not improve because there were no other methods for additional optimization. Therefore, they performed consistently from the beginning to the end. The proposed optimization techniques demonstrated performance changes as the queries were processed. Although the density-based optimization technique performed well in certain situations, it did not consistently perform well. It achieved good performance in areas in which the calculated density values matched. However, when the density values differed, it specified a considerably wide search range value. As the search range expanded, it increased the number of candidate sets. This resulted in a large distance calculation cost and a decrease in the query processing performance. The statistical optimization technique using query search cost had a search range increasing or decreasing factor. As shown in the graph, as the factor processed the queries, the performance improved and converged to a certain value. However, it was observed that it took some time for the value to converge. The DNN-based optimization technique using machine learning demonstrated consistently low processing costs from the beginning, compared with other techniques. The validity of the proposed k-NN optimization technique was proven using the performance evaluation results.
We compared the query processing time of the proposed optimization techniques and the existing distributed, high-dimensional indexing methods to verify their superiority. We selected the existing methods, such as the distributed k-d tree, the distributed iDistance, the sequential search, and the join-based k-NN. The distributed iDistance method was implemented on Spark. The sequential search was also implemented on Spark, where it searched and compared files sequentially using distributed processing. The join-based k-NN, which is a parallel CBIR system, was implemented on the Spark and Tachyon frameworks [
26].
A performance evaluation was first conducted while we range queries were being processed. The range query parameters were as follows: The range was set to 50. We conducted 100 queries with 128-dimensional-feature data points.
Figure 13 shows the range query processing time for each distributed high-dimensional indexing scheme. The sequential search showed consistent performance, regardless of the query, because it compared all data. The distributed k-d tree method showed the worst performance because it had to search both the global and local k-d trees, which resulted in high tree search costs and inferior performance, compared to the sequential search in tall trees, owing to the backtracking operations. The distributed iDistance method performed better than the sequential search, but worse than the proposed method. Since all of the nodes participate in the query, a master node that partitions data areas, such as the k-d tree, is lacking. Join k-NN performed better than the distributed k-d trees, but worse than the sequential search. Compared with the existing iDistance method, the proposed method performed better in reducing the processing time. In our method, the master node k-d tree limited the number of nodes participating in the query by partitioning areas. The proposed distributed, high-dimensional indexing scheme performed the best in terms of its range query processing time.
To evaluate the performance of k-NN queries, we set k to 100 and conducted the same 100 queries that we used in the range query evaluation. In particular, we compared the performances of the existing methods, the hybrid indexing method proposed by our research team, and a method that applies the three optimization techniques used for hybrid indexing.
Figure 14 shows the k-NN query processing time with the indexing method. The sequential search had the worst performance because it requires extensive time to compare the distance for all the data and because it manages the k-nearest list using additional comparison operations. Although the distributed k-d tree method performed poorly in the range queries, it excelled in the k-NN queries. This is because it only finds the kth data in the local k-d tree and performs range retrieval using this, taking only as much time as a range query. However, as the k value increased, the distributed k-d tree method still struggled to find the kth data in the local k-d tree because of the excessive backtracking operations. The join k-NN technique is a state-of-the-art scheme, which exhibited very good performance for k-NN. However, it performed very badly during the range query evaluation. The distributed iDistance and the proposed techniques did not perform as effectively as the distributed k-d tree because they perform iterative range expansions and range searches to process k-NN queries and to find k items. Nevertheless, the distributed high-dimensional indexing method proposed in this study outperformed the existing distributed iDistance method. The reason for this was that the k-d tree in the master node pre-filters are areas that must not be retrieved by selecting nodes to participate in the query.
To evaluate the performance of the proposed density-based and DNN-based optimization techniques, we compared the changes in the difference in the search range values and the changes in k in the k-NN queries (
Figure 15). The density-based optimization showed a linear increase in the difference between the actual and predicted search range values as k changed. When k was 100, the predicted search range value was more than 140% higher than the actual search area, resulting in frequent unnecessary searches. Conversely, the DNN-based optimization technique showed an average difference between the actual and predicted search range values of approximately 5.79%, demonstrating that it accurately predicted the actual search area. Moreover, contrary to the density-based technique, the performance of the DNN-based optimization technique was not significantly impacted by the changes in k, demonstrating that it is a more stable optimization technique.
The performance evaluation results of the proposed k-NN optimization techniques showed the following: Density-based optimization techniques had different processing times depending on the density consistency. As a result, the average processing time was very unstable and the overall query processing performance was reduced. The cost-based optimization technique outperformed the density-based technique, but was worse than the distributed k-d tree. However, when comparing the range and k-NN queries, the proposed technique performed better, overall, because the distributed k-d tree took approximately three times as long to process the range queries. Finally, the method that applied machine learning optimization to the proposed technique outperformed the other optimization techniques. The machine-learning-based optimization technique demonstrated a stable query processing time, compared with the density-based optimization technique, and provided a more optimized query range in a faster time than the cost-based optimization technique. We demonstrated the superiority of our proposed high-dimensional indexing method, in terms of range and k-NN query processing times, using an overall performance evaluation.
The advantages of the proposed techniques in comparison with state-of-the-art technologies are as follows. First, the proposed techniques can improve the query processing time by filtering areas that do not need to be searched in advance in a distributed processing system structure. The existing techniques perform k-NN query processing through a distributed processing framework such as MapReduce [
26]. Since they do not have any indices, unnecessary operations will be performed on all of the nodes. This results in a performance degradation of the overall system. Second, the query processing results of the proposed techniques only provide accurate results. The existing techniques provide approximate results to speed up search performance [
24]. Third, various k-NN query optimization techniques have been proposed. When the proposed techniques apply to the real world system, they have the advantage of being able to find optimal performance by replacing optimization techniques. On the other hand, the limitations of the proposed techniques are as follows. First, we provide various optimization techniques to improve the performance of k-NN query processing. However, we do not show the “best” performance compared to the existing techniques. Second, there is the limitation that the proposed index and query processing techniques depends on a specific platform, such as Spark.
5. Conclusions
In this paper, we proposed three k-NN optimization techniques for a distributed, in-memory indexing method, which can efficiently retrieve large-scale, high-dimensional data. The proposed techniques were designed based on the density, cost, and DNN, and were implemented on Spark—a distributed in-memory processing platform—to process large-scale data. A distance-based index, iDistance, was used to efficiently manage high-dimensional values. The proposed techniques’ superiority in terms of range and k-NN query processing time was demonstrated through performance evaluations. The proposed techniques were tested in a cluster environment, which consisted of four servers. In the experiment, we used SIFT to extract the image features. The extracted features consisted of data points with 128 dimensions, which had values ranging from 0 to 255. The proposed techniques performed k-NN query processing based on distance-based, high-dimensional indexes. Therefore, since the k-NN query was only processed using distance information, we had to perform the calculation of the actual distance for the candidates. Therefore, when a significant number of candidate groups were generated, the query processing performance was poor. In the future, we will improve the query performance of the k-NN by making new optimizations. We also intend to conduct additional research on k-NN optimization in the future. Furthermore, we will devise an optimization model for distance-based indexes.



 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}