1. Introduction
An automated program repair(APR) can reduce the debugging costs by automatically fixing a buggy code [
1,
2]. Moreover, the template-based APR technique is one of the techniques showing good performance among the APR techniques [
3,
4,
5]. It generates a template from the commit history. FixMiner [
6] collects patch history from open-source repositories. It used a rich edit script to capture the structure of the AST and then used it to generate the patch pattern. TBar [
3] verifies templates from existing template-based APR. It then checks the patches generated using such templates.
For patch generation, template-based APR approaches additionally leverage various context information about the buggy code. ConFix [
7] uses the AST node near the modification point as a context to efficiently explore the patch history and changes. CAPGEN [
8] uses genetics, variables, and dependency similarities between suspicious codes and candidate patches as context. Furthermore, it utilizes patch prioritization to increase performance.
The main metrics of existing template-based APR methods focus on a performance evaluation [
9]. Liu et al. [
9] showed that the performance of the APR technique has steadily improved. However, the efficiency, which is a key property for the practical use of the APR technique, has not improved.
To improve efficiency, APR require an effective search strategy for search within a reasonable amount of time. Among the benchmark Defects4j bugs,
Figure 1 shows the developer patches for the Lang-24 and Closure-125 bugs. Both patches can be generated using the
template proposed by TBar, one of the latest template-based APR techniques. However, in the case of TBar, the same patch can be generated only for Lang-24, and not for Closure-125.
The major difference between the two patches is that, in the case of Lang-24, only one variable is added, and in Closure-125, fnType.hasInstanceType(), a method invocation, is added. Compared to Lang-24, Closure-125 has an exponential search space because it requires an additional search of the class and method. If TBar can effectively search the ingredient search space, it will produce a patch equivalent to that of the developer of the closure-125 bug within a given amount of time.
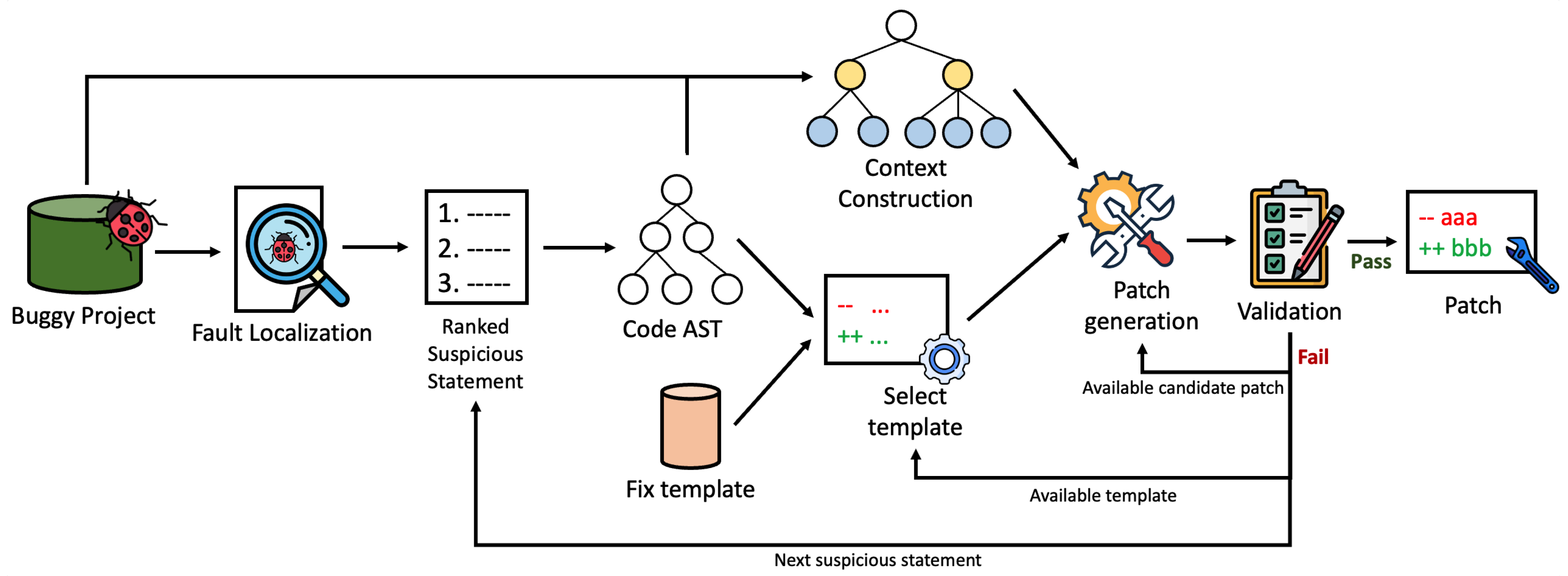
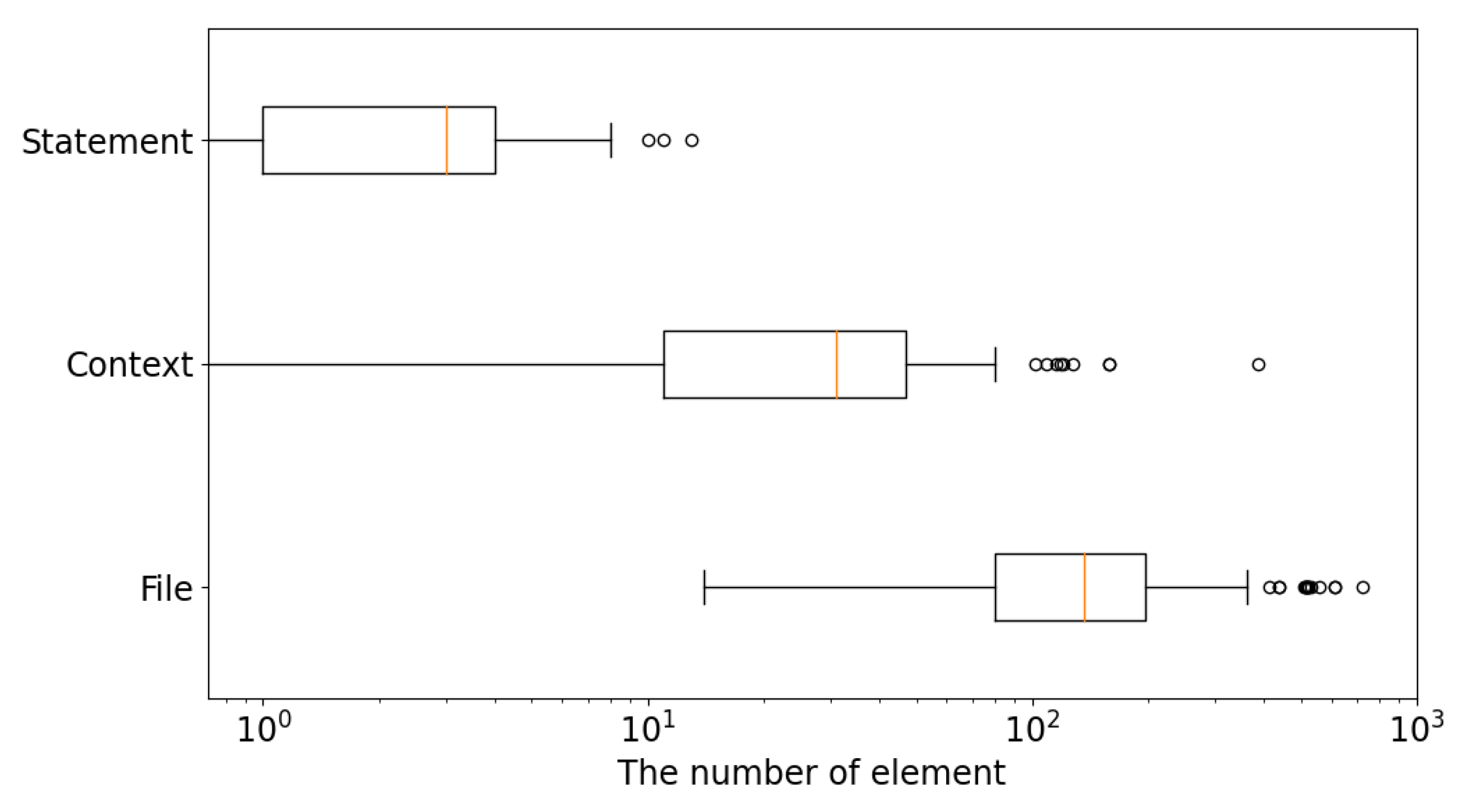
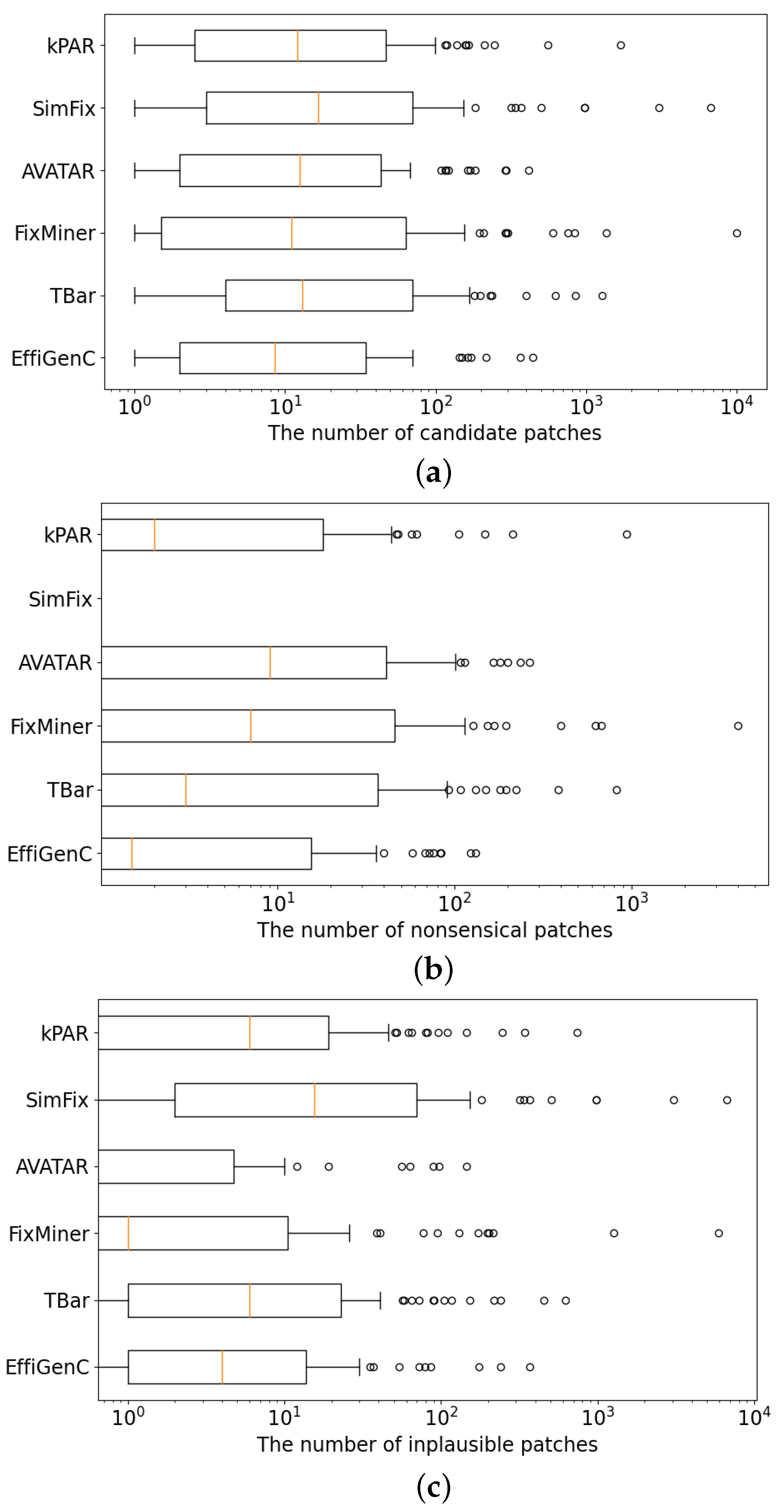
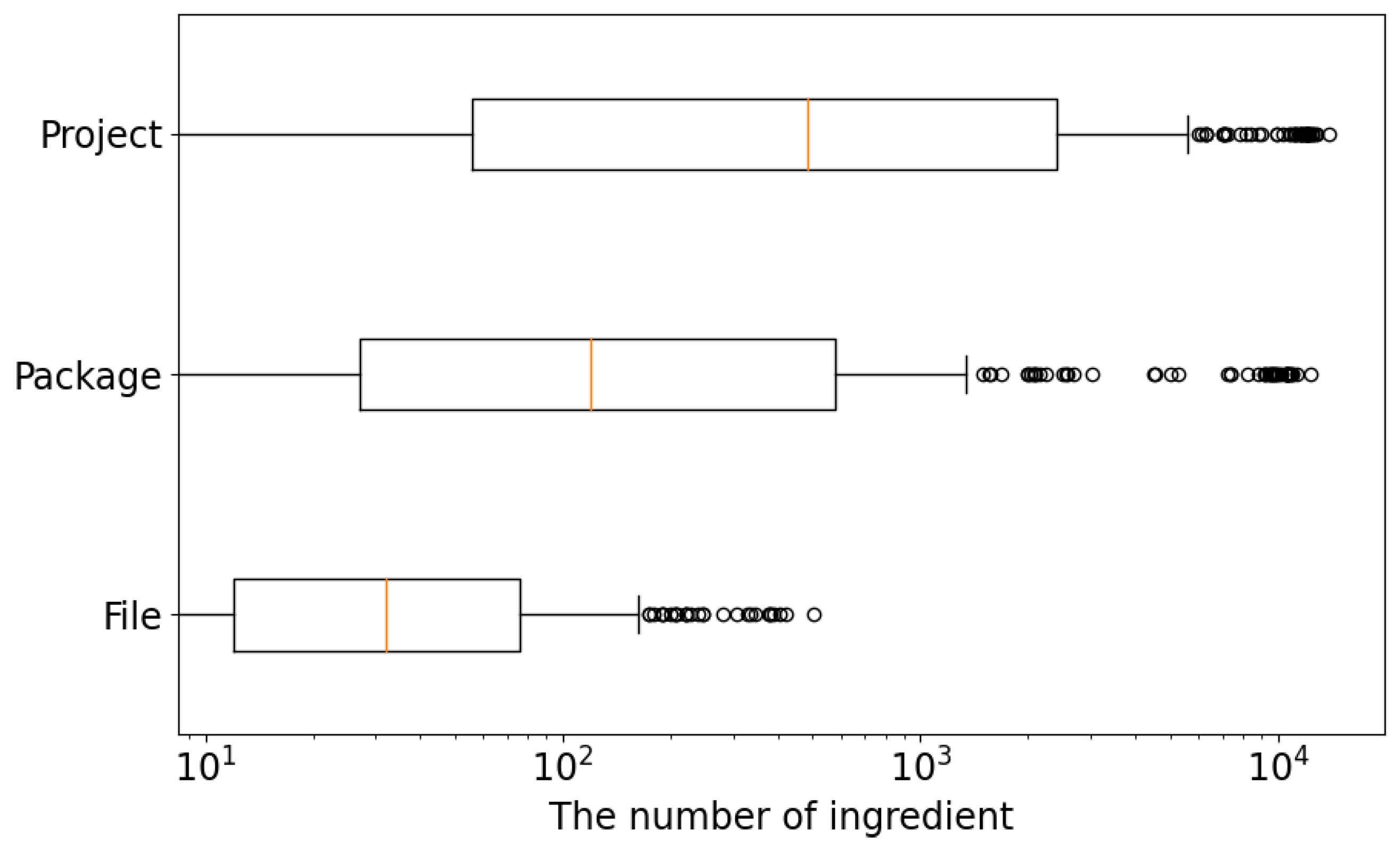
In this paper, to improve the efficiency of the template-based APR, we propose EffiGenC (Increasing the Efficiency of Patch Generation using Context) that efficiently explores the search space of ingredients using context. EffiGenC considers the statement related to the target statement as context. For this, we extend the concept of reaching definition in compiler theory. Reaching definition for a given statement is the closest earlier statement whose target variable can reach it without an intervening assignment. EffiGenC obtains the statements and methods that are the context of target statements through reaching definition. It explores the context and collects the patch materials needed to generate a patch. This experimental study on five state-of-the-art template-based APR systems demonstrate that, overall, EffiGenC can reduce the number of candidate patch by up to 86%. Even when we extend the search space from file to project, the number of candidate patches increased by only 29% compared to the exponential increase of ingredients.
The contributions of this study are as follows.
New context concept through extended reaching definition.
An APR technique to efficiently explore the patch ingredient search space.
Evaluation of APR performance and efficiency through Real java dataset.
The rest of this paper is organized as follows. The following
Section 2 summarizes the terms for understanding the proposed approach.
Section 3 presents the detailed process of the proposed technique.
Section 4 and
Section 5 present our experimental setup and results.
Section 6 discusses the limitation of our approaches. After surveying the related studies in
Section 7, we provide some concluding remarks in
Section 8.
6. Threats to Validity
Benchmark overfitting patch. The validity can be threatened by the benchmarks used in the evaluation. Although Defects4j is a high-quality Java project bug framework, there is a threat in which the patches generated by each APR only overfit that bug [
18], and there is a risk because the framework does not cover all bug types. However, many APR studies have evaluated the performance of patch generation using benchmarks [
14,
19,
20].
Additional computing cost. EffiGenC can efficiently generate patches by reducing the patch ingredient search space. We also show this through the NPC score. The computational cost of constructing the context and collecting ingredients from such context does not appear in NPC score. However, as a result of running TBar and EffiGenC in the same environment, it took an average of 661 s for TBar and 580 s for EffiGenC to generate the correct patch. Therefore, we can observe that the context construction and patch generation process of EffiGenC are sufficiently efficient.
Scalability. For the experiment, we implemented EffiGenC on TBar. Therefore, it can be observed that the patch ingredient search space construction method of EffiGenC is limited to TBar. The context construction of EffiGenC is a method that can be applied to any technique that uses suspicious statements regardless of TBar. In addition, if it is template-based APR, the concretization process that inserts ingredients to make the template a candidate patch is a common process. Therefore, the process of extracting the patch ingredient of EffiGenC can also be sufficiently generalized. EffiGenC can efficiently generate patches regardless of the technique.
7. Related Work
Research related to APR has been actively conducted [
1]. APR is largely divided into search-based APR and semantic-driven APR. A search-based APR generates a candidate patch by defining and exploring a space in which a candidate patch exists. GenProg [
21] generates a candidate patch by manipulating the existing buggy source code using genetic programming. By contrast, ARJA [
10] generates candidate patches for Java programs using multi-objective genetic programming. Unlike genetic programming, which uses stochastic elements, EffiGenC generates candidate patches based on templates collected from previous patch history.
Semantic-driven APR is a technique for generating correct patches using semantic information such as a symbolic execution or the satisfiability modulo theory. SemFix [
22] generates a correct patch using symbolic execution, constraint solving, and program synthesis. Angelix [
23] generates a patch by introducing the concepts of an angelic path and an angelic forest. Furthermore, Angelix alleviates the problem of scalability, which is a problem in semantic-driven APR.
There are studies using the patch history to increase the number of correct patches PAR [
24] generates a new correct patch for the target project that fails to generate an existing correct patch by creating a template with the pattern found by manually analyzing the patch manually generated patch. Prophet [
25] generates a machine-learning model that extracts the correct patch characteristics from a human-written patch in an open-source software repository project. The model was used to prioritize candidate patches and increase the rank of the correct patch. EffiGenC also creates patches by exploring the search space more efficiently through the context, rather than using only the patch history.
As research on search-based APR remains active, empirical analyses of the search space and algorithms have been conducted. Wen et al. [
26] revealed that the quality of the search space significantly influences the performance of search-based APR when analyzing the search space explored through existing APR techniques. In addition, the quality of the patch is dependent on test cases. A technique for sampling only good test cases is needed to generate the correct patch with a high performance and high efficiency. Fan Long et al. [
25] analyzed the density of plausible and correct patches in a space explored through the APR approach and showed that there are plausible patches other than the correct patch.
Owing to the problematic performance and efficiency of search-based APR, studies using context have continued to efficiently explore the search space. SimFix [
22] extracts high-level abstract changes from the past patch histories. Based on this, the correct patch is generated by applying a patch to a suspicious statement. In addition, CapGen [
8] proposed a patch-prioritization technique to generate more correct patches with an efficient patch validation. To prioritize the patch, the genealogy, variable, and dependency context scores between the suspicious statement and the past patch history were calculated and prioritized based on this technique. ConFix [
7] considered the context by extracting the parent and sibling nodes from the previous patch history. When a suspicious statement identified, ConFix extracts the context and applies only the change in the same context existing in the database to more efficiently generate the correct patch. EffiGenC uses the same context as previous techniques. However, we redefine the context using an extended reaching definition. In addition, EffiGenC effectively reduces the ingredient search space required for patch generation.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}