
Robust Hierarchical Federated Learning with Anomaly Detection in Cloud-Edge-End Cooperation Networks




Abstract
1. Introduction
- A novel method called R-HFL is proposed to ensure the training performance under Byzantine attacks by the distributed anomaly detection mechanism customized for the HFL framework.
- The effectiveness and convergence of our proposed method are mathematically discussed in the general non-convex case.
- Numerical results are provided to experimentally show that our proposed algorithm can effectively minimize the negative impact of abnormal behaviours, which further illustrates the feasibility of distributive detection in the HFL system.
2. Related Work
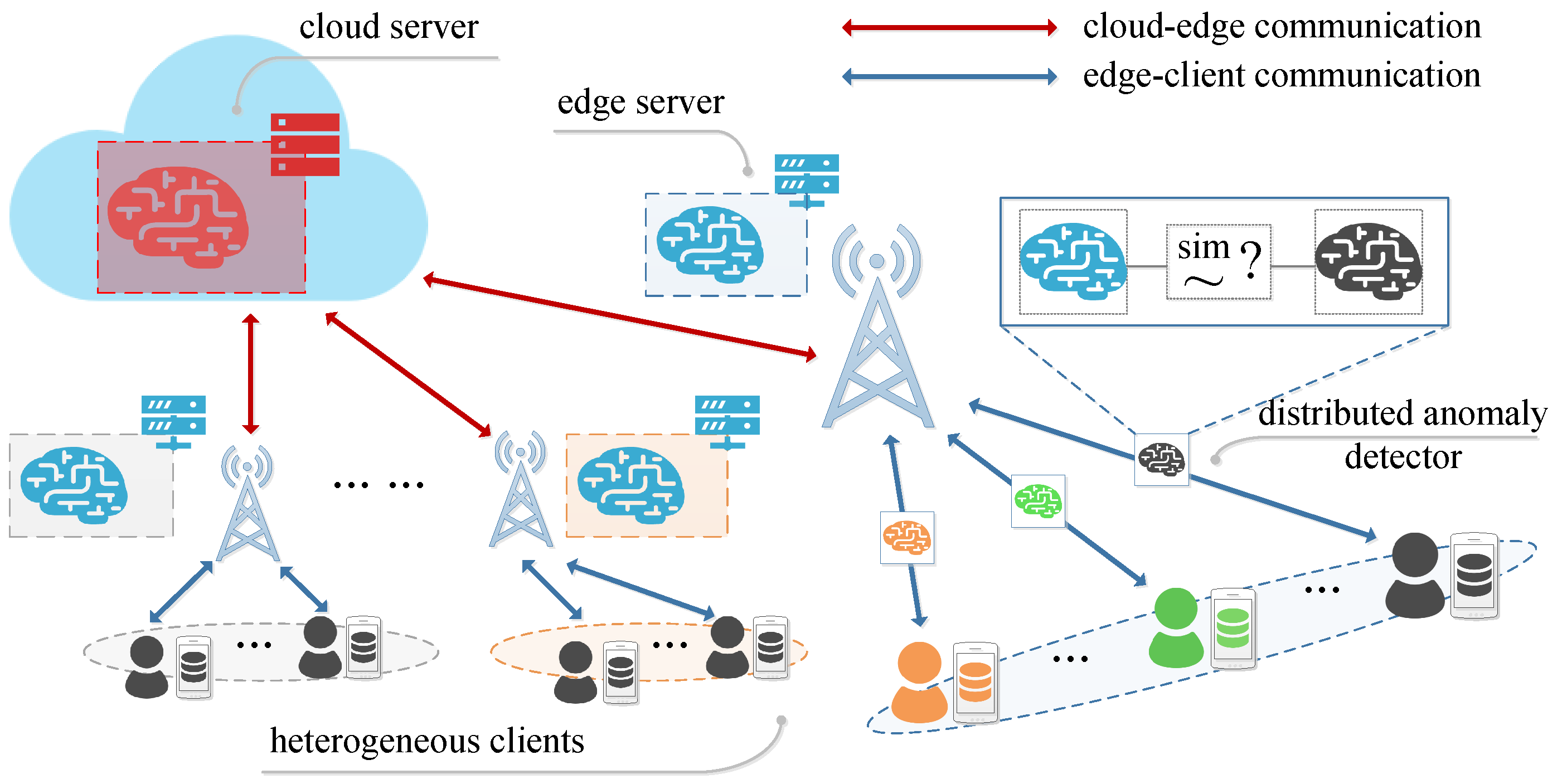
3. Learning System Architecture
3.1. Traditional Federated Learning
| Algorithm 1 Traditional Client-Server FL. |
| Input: local update step , total communication round K Output: optimized global model |
|
3.2. Hierarchical Federated Learning
| Algorithm 2 Hierarchical cloud–edge–client FL. |
| Input: local update step , total communication round K, edge server set , fractions of clients Output: optimized global model |
|
4. A Lightweight Detection Mechanism for Hierarchical Federated Learning
| Algorithm 3 R-HFL: Robust Hierarchical FL. |
|
5. Further Analysis on Partial Cosine Similarity
6. Experiment Results
6.1. Experiment Setup
6.1.1. Model and Dataset
6.1.2. Adversarial Attacks
- (i)
- Additive Noise of Model Parameter (ANMP) adds Gaussian noise to local model parameters, where the noise obeys . That is, for client i, any component of the local model parameters satisfy that , where .
- (ii)
- Sign-Flipping of Model Parameter (SFMP) flips the sign of local model parameters, i.e., for client i, the local model parameters .
- (iii)
- Additive Noise of Data Distribution (ANDD) adds Gaussian noise to local datasets, where the noise obeys , which is similar to ANMP.
6.1.3. Hyper-Parameters
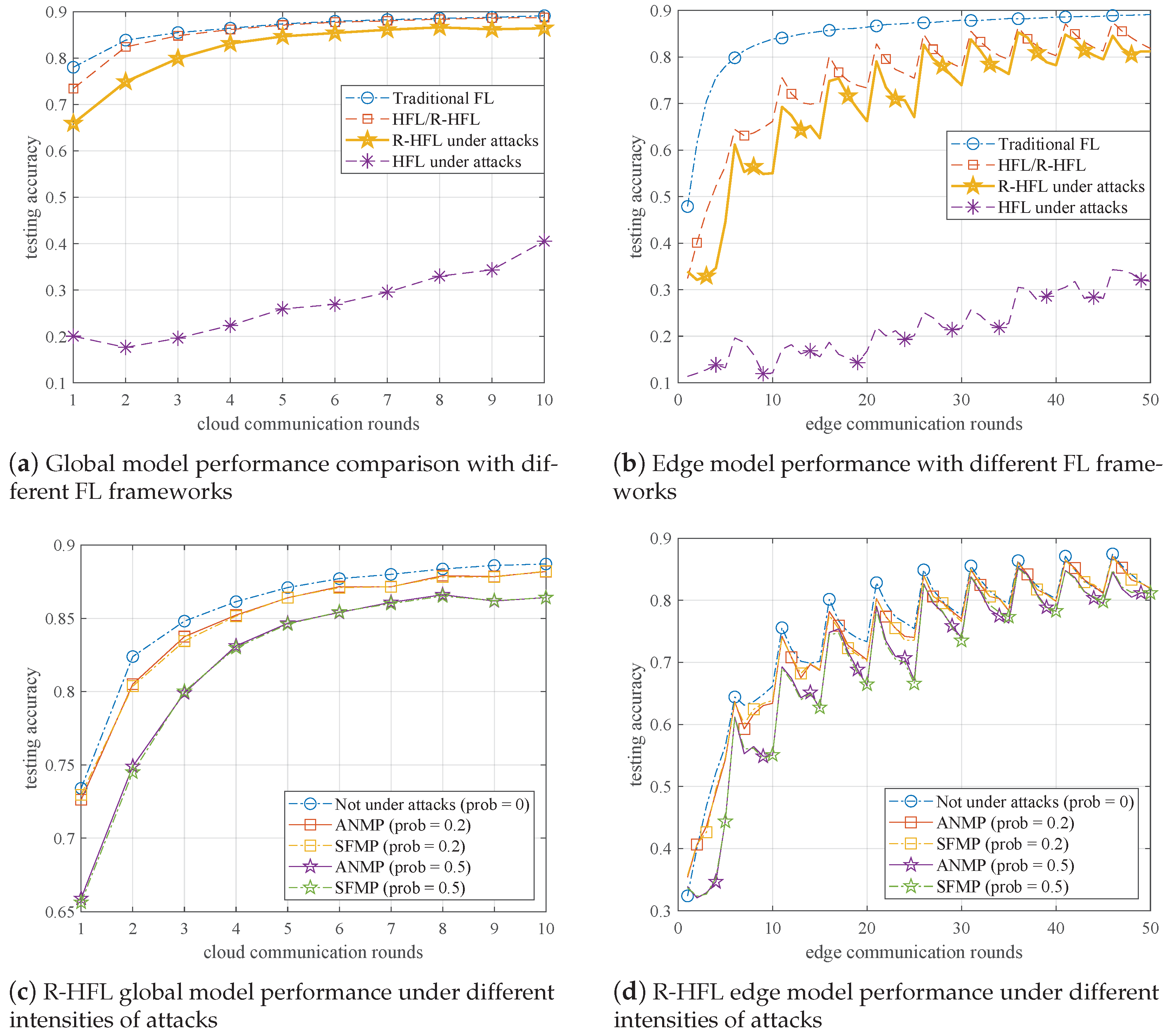
6.2. Numerical Results
6.2.1. Performance Evaluation under Different Attacks
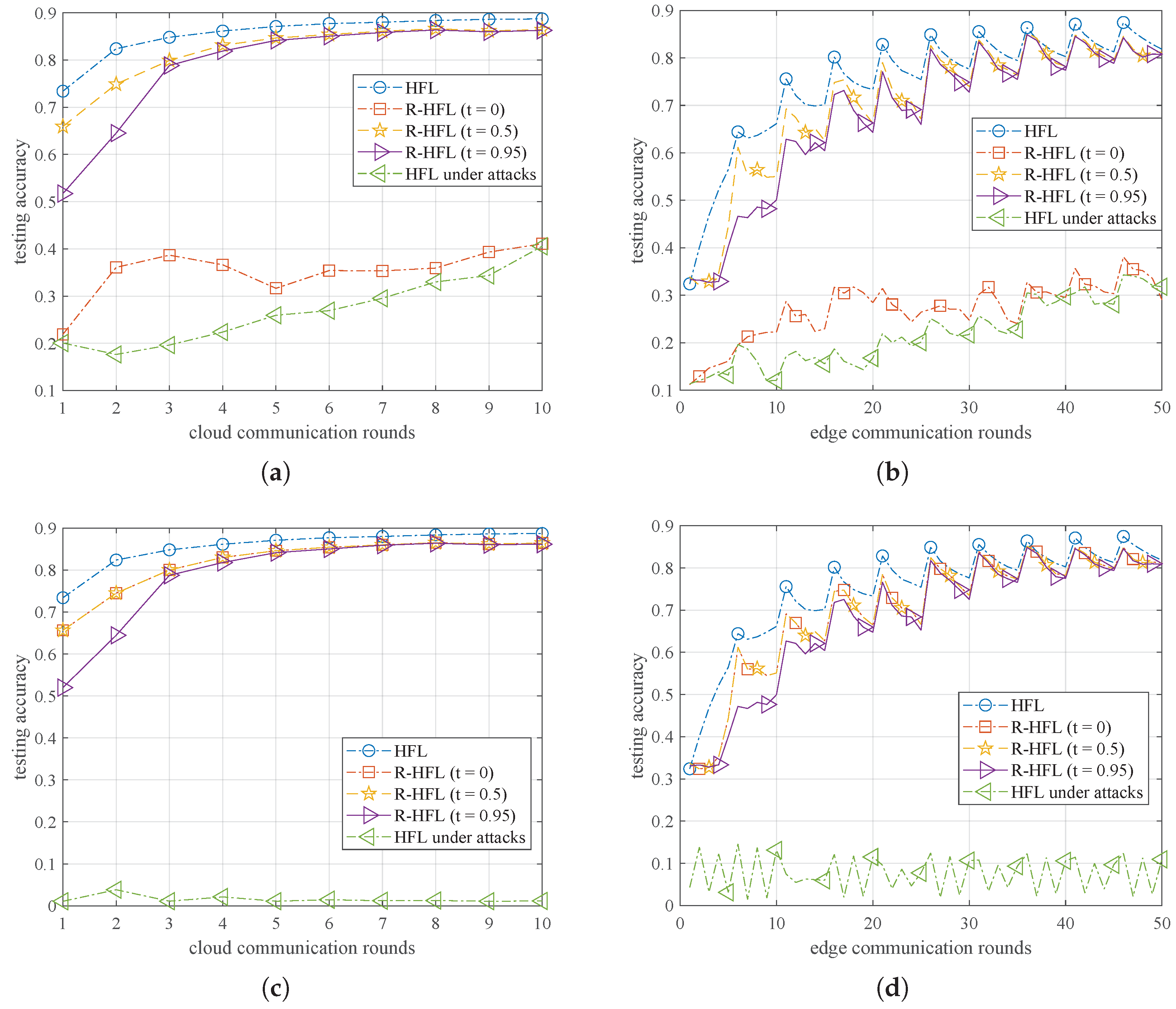
6.2.2. Effect of the Key Factor: Threshold t
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ML | Machine Learning |
| FL | Federated Learning |
| HFL | Hierarchical Federated Learning |
| R-HFL | Robust Hierarchical Federated Learning |
| SGD | Stochastic Gradient Descent |
| PCS | Partial Cosine Similarity |
| ANMP | Additive Noise of Model Parameter |
| SFMP | Sign-Flipping of Model Parameter |
| ANDD | Additive Noise of Data Distribution |
| MLP | Multilayer Perceptron |
Appendix A. Proof of Theorem 1
Appendix B. Proof of Theorem 2
Appendix C. Proof of Corollary 1
References
- Wang, X.; Han, Y.; Wang, C.; Zhao, Q.; Chen, X.; Chen, M. In-edge ai: Intelligentizing mobile edge computing, caching and communication by federated learning. IEEE Netw. 2019, 33, 156–165. [Google Scholar] [CrossRef]
- Zhou, Z.; Chen, X.; Li, E.; Zeng, L.; Luo, K.; Zhang, J. Edge intelligence: Paving the last mile of artificial intelligence with edge computing. Proc. IEEE 2019, 107, 1738–1762. [Google Scholar] [CrossRef]
- Fan, B.; Wu, Y.; He, Z.; Chen, Y.; Quek, T.Q.; Xu, C.Z. Digital Twin Empowered Mobile Edge Computing for Intelligent Vehicular Lane-Changing. IEEE Netw. 2021, 35, 194–201. [Google Scholar] [CrossRef]
- Wang, Z.; Gao, Y.; Fang, C.; Liu, L.; Zeng, D.; Dong, M. State-Estimation-Based Control Strategy Design for Connected Cruise Control With Delays. IEEE Syst. J. 2022, 1–12. [Google Scholar] [CrossRef]
- Tang, T.; Li, L.; Wu, X.; Chen, R.; Li, H.; Lu, G.; Cheng, L. TSA-SCC: Text Semantic-Aware Screen Content Coding With Ultra Low Bitrate. IEEE Trans. Image Process. 2022, 31, 2463–2477. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Zhu, N.; Wu, D.; Wang, H.; Wang, R. Energy-Efficient Mobile Edge Computing Under Delay Constraints. IEEE Trans. Green Commun. Netw. 2022, 6, 776–786. [Google Scholar] [CrossRef]
- Li, Z.; Gao, X.; Li, Q.; Guo, J.; Yang, B. Edge Caching Enhancement for Industrial Internet: A Recommendation-Aided Approach. IEEE Internet Things J. 2022, 9, 16941–16952. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- Luo, B.; Xiao, W.; Wang, S.; Huang, J.; Tassiulas, L. Tackling System and Statistical Heterogeneity for Federated Learning with Adaptive Client Sampling. In Proceedings of the IEEE INFOCOM 2022-IEEE Conference on Computer Communications, London, UK, 2–5 May 2022; pp. 1739–1748. [Google Scholar] [CrossRef]
- Yang, H.H.; Liu, Z.; Quek, T.Q.; Poor, H.V. Scheduling policies for federated learning in wireless networks. IEEE Trans. Commun. 2019, 68, 317–333. [Google Scholar] [CrossRef]
- Xue, Q.; Liu, Y.J.; Sun, Y.; Wang, J.; Yan, L.; Feng, G.; Ma, S. Beam Management in Ultra-dense mmWave Network via Federated Reinforcement Learning: An Intelligent and Secure Approach. In IEEE Transactions on Cognitive Communications and Networking; IEEE: Piscataway, NJ, USA, 2022; p. 1. [Google Scholar] [CrossRef]
- Wang, S.; Tuor, T.; Salonidis, T.; Leung, K.K.; Makaya, C.; He, T.; Chan, K. Adaptive federated learning in resource constrained edge computing systems. IEEE J. Sel. Areas Commun. 2019, 37, 1205–1221. [Google Scholar] [CrossRef]
- Li, Z.; Zhou, Y.; Wu, D.; Tang, T.; Wang, R. Fairness-Aware Federated Learning With Unreliable Links in Resource-Constrained Internet of Things. IEEE Internet Things J. 2022, 9, 17359–17371. [Google Scholar] [CrossRef]
- Tran, N.H.; Bao, W.; Zomaya, A.; Nguyen, M.N.; Hong, C.S. Federated learning over wireless networks: Optimization model design and analysis. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1387–1395. [Google Scholar]
- Liu, L.; Zhang, J.; Song, S.; Letaief, K.B. Client-Edge-Cloud Hierarchical Federated Learning. In Proceedings of the ICC 2020-2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Yu, H.; Yang, S.; Zhu, S. Parallel restarted SGD for non-convex optimization with faster convergence and less communication. arXiv 2018, arXiv:1807.06629. [Google Scholar]
- Stich, S.U. Local SGD Converges Fast and Communicates Little. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wang, J.; Joshi, G. Cooperative SGD: A unified framework for the design and analysis of communication-efficient SGD algorithms. arXiv 2018, arXiv:1808.07576. [Google Scholar]
- Stich, S.U.; Karimireddy, S.P. The error-feedback framework: Better rates for SGD with delayed gradients and compressed communication. arXiv 2019, arXiv:1909.05350. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Lian, X.; Zhang, C.; Zhang, H.; Hsieh, C.J.; Zhang, W.; Liu, J. Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5336–5346. [Google Scholar]
- Li, X.; Yang, W.; Wang, S.; Zhang, Z. Communication efficient decentralized training with multiple local updates. arXiv 2019, arXiv:1910.09126. [Google Scholar]
- Yu, H.; Jin, R.; Yang, S. On the linear speedup analysis of communication efficient momentum SGD for distributed non-convex optimization. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 7184–7193. [Google Scholar]
- Wang, J.; Liu, Q.; Liang, H.; Joshi, G.; Poor, H.V. Tackling the Objective Inconsistency Problem in Heterogeneous Federated Optimization. Adv. Neural Inf. Process. Syst. 2020, 33, 7611–7623. [Google Scholar]
- Nguyen, H.T.; Sehwag, V.; Hosseinalipour, S.; Brinton, C.G.; Chiang, M.; Poor, H.V. Fast-convergent federated learning. IEEE J. Sel. Areas Commun. 2020, 39, 201–218. [Google Scholar] [CrossRef]
- Chen, M.; Yang, Z.; Saad, W.; Yin, C.; Poor, H.V.; Cui, S. Performance optimization of federated learning over wireless networks. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Big Island, HI, USA, 9–13 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Luo, S.; Chen, X.; Wu, Q.; Zhou, Z.; Yu, S. HFEL: Joint edge association and resource allocation for cost-efficient hierarchical federated edge learning. IEEE Trans. Wirel. Commun. 2020, 19, 6535–6548. [Google Scholar] [CrossRef]
- Mhaisen, N.; Abdellatif, A.A.; Mohamed, A.; Erbad, A.; Guizani, M. Optimal User-Edge Assignment in Hierarchical Federated Learning Based on Statistical Properties and Network Topology Constraints. IEEE Trans. Netw. Sci. Eng. 2022, 9, 55–66. [Google Scholar] [CrossRef]
- Li, S.; Cheng, Y.; Liu, Y.; Wang, W.; Chen, T. Abnormal client behavior detection in federated learning. arXiv 2019, arXiv:1910.09933. [Google Scholar]
- Blanchard, P.; El Mhamdi, E.M.; Guerraoui, R.; Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Shen, S.; Tople, S.; Saxena, P. Auror: Defending against Poisoning Attacks in Collaborative Deep Learning Systems. In Proceedings of the 32nd Annual Conference on Computer Security Applications, ACSAC ’16, Los Angeles, CA, USA, 5–9 December 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 508–519. [Google Scholar] [CrossRef]
- Fang, M.; Cao, X.; Jia, J.; Gong, N. Local model poisoning attacks to Byzantine-Robust federated learning. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Boston, MA, USA, 12–14 August 2020; pp. 1605–1622. [Google Scholar]
- Li, S.; Cheng, Y.; Wang, W.; Liu, Y.; Chen, T. Learning to detect malicious clients for robust federated learning. arXiv 2020, arXiv:2002.00211. [Google Scholar]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the Convergence of FedAvg on Non-IID Data. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Salehi, M.; Hossain, E. Federated Learning in Unreliable and Resource-Constrained Cellular Wireless Networks. IEEE Trans. Commun. 2021, 69, 5136–5151. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | - | ||||||
|---|---|---|---|---|---|---|---|
| without attacks (FL) | 89.11 (-) | - | - | - | - | - | - |
| without attacks (HFL/R-HFL) | 88.71 (-) | - | - | - | - | - | - |
| ANMP (HFL) | 40.55 (-) | - | - | - | - | - | - |
| ANMP (R-HFL) | - | 41.08 (71.04) | 86.42 (≈100) | - | - | 86.28 (98.24) | 20.61 (≈50) |
| SFMP (HFL) | 1.16 (-) | - | - | - | - | - | - |
| SFMP (R-HFL) | - | 86.41 (≈100) | 86.41 (≈100) | - | - | 86.16 (98.16) | 20.61 (≈50) |
| ANDD (HFL) | 84.69 (-) | - | - | - | - | - | - |
| ANDD (R-HFL) | - | 84.69 (≈50) | 84.70 (≈50) | 82.65 (83.48) | 86.63 (≈100) | 86.43 (98.64) | 20.61 (≈50) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Wang, R.; Mo, X.; Li, Z.; Tang, T. Robust Hierarchical Federated Learning with Anomaly Detection in Cloud-Edge-End Cooperation Networks. Electronics 2023, 12, 112. https://doi.org/10.3390/electronics12010112
Zhou Y, Wang R, Mo X, Li Z, Tang T. Robust Hierarchical Federated Learning with Anomaly Detection in Cloud-Edge-End Cooperation Networks. Electronics. 2023; 12(1):112. https://doi.org/10.3390/electronics12010112
Chicago/Turabian StyleZhou, Yujie, Ruyan Wang, Xingyue Mo, Zhidu Li, and Tong Tang. 2023. "Robust Hierarchical Federated Learning with Anomaly Detection in Cloud-Edge-End Cooperation Networks" Electronics 12, no. 1: 112. https://doi.org/10.3390/electronics12010112
APA StyleZhou, Y., Wang, R., Mo, X., Li, Z., & Tang, T. (2023). Robust Hierarchical Federated Learning with Anomaly Detection in Cloud-Edge-End Cooperation Networks. Electronics, 12(1), 112. https://doi.org/10.3390/electronics12010112