Abstract
As a dynamic jamming pattern, random pulse jamming is stochastic, sudden, and not easily perceived or addressed. Random pulse jamming can exert a negative influence on the quality of wireless communication. This paper models an anti-jamming communication under random pulse jamming as a Markov Decision Process and proposes a SARSA-based Time-domain Anti-jamming Algorithm (STAA). Differently from previous research, this study attempts to use the SARSA algorithm to counter random pulse jamming in the time domain. The proposed STAA can achieve high-quality transmission while maintaining small fluctuations in transmission performance when the risk of external interference is high.
1. Introduction
As a kind of interference signal, pulse jamming has the characteristics of a short duration and high instantaneous power. According to its law in the time domain, we can divide it into periodic pulse jamming and random pulse jamming. Periodic pulses can send interference signals at constant time intervals to affect and interrupt communication transmissions [1]. However, periodic pulse jamming has a high degree of regularity, which means that the target communication system can easily sense it and take targeted anti-jamming measures. Because of its randomness and abruptness, random pulse jamming occupies an important position in wireless communication systems, and its threat to wireless communication systems is greater than periodic pulse jamming [2,3]. So, the question of how to effectively counter random pulse interference is a difficult problem that wireless communication systems must face and overcome.
1.1. Related Works
Machine learning provides a feasible new way to solve the problem of anti-random pulse jamming. Reinforcement learning, as an important branch of machine learning, can optimize the anti-jamming transmission strategy by relying only on agent action selection and feedback from the external environment without modeling the interference itself [4], which has advantages in realizing intelligent anti-jamming transmission strategies. The Q-learning algorithm, as the most-used classical model-free reinforcement learning algorithm, has been studied in anti-interference communication problems [5,6,7,8,9,10,11]. The other model-free reinforcement learning algorithm—the SARSA algorithm—is not as widely used as the Q-learning algorithm. Studies [12,13,14] show that the SARSA algorithm is suitable for single agent scenarios, but current studies mainly focus on the channel allocation of wireless communication networks [12,13]. Studies on anti-interference strategies are relatively rare.
Intelligent anti-jamming algorithms based on Q-learning continuously learn from the environmental feedback caused by their own transmission actions (such as the channel, the power, and the coding method) without modeling the external environment, and finally achieve optimal transmission. They focus more on scenario-specific applications, but not enough on the most critical parameter—the benefit–risk of transmission—which plays the most fundamental and important role in anti-interference transmission. In previous work, Q-learning was used to counter random pulse interference in the time domain; however, the other value iteration algorithm (the SARSA algorithm) has received little attention.
1.2. Contribution and Structure
The contributions of this paper are as follows:
- This paper uses the SARSA-based algorithm to counter random pulse jamming in the time domain, filling the gap in the literature on the use of the SARSA-based algorithm in anti-jamming strategies in the time domain.
- The proposed algorithm improves the robustness in countering random pulse jamming in the time domain and can achieve high-quality transmission while maintaining small fluctuations in transmission performance when the risk of external interference is high.
The remainder of this paper is organized as follows. Section 2 presents the system model and problem formulation. In Section 3, we introduce the SARSA-based Time-domain Anti-jamming Algorithm (STAA). The simulation results and an analysis are presented in Section 4. Our concluding remarks are given in Section 5.
2. System Model and Problem Formulation
2.1. System Model
As shown in Figure 1, the model in this paper consists of three elements: a legitimate communication transmitter, a corresponding communication receiver, and a malicious jammer whose jamming signal can cover the receiver. For convenience, the following assumptions were made in this study.
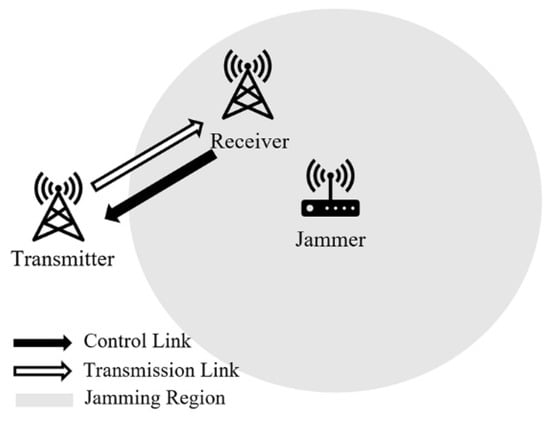
Figure 1.
Schematic diagram of the system model.
- Transmission period: we assume that the time slot with a length of is the smallest unit of continuous transmission. A complete transmission period is composed of continuous time slots. This paper assumes that there are time slots, equivalent to periods.
- Jammer: we assume that the jammer grasps the information of the transmitter, such as the possible frequency of communication, the width of the time slot, and the transmission period of the wireless communication system, in advance through reconnaissance. The random pulse jamming signal is able to cover the channel of communication completely, and the duration of a single pulse is equal to the length of the communication time slot .
- Jamming period: in this paper, the jammer is assumed to set the interference period to be the same as and synchronous with the communication transmission period. It consists of time slots in one period, in which the jammer selects time slot to conduct jamming according to a specific probability distribution. The discrete probability density function is defined as , and the probability of jamming in the period can be expressed as follows:where represents the slot number in one jamming period, and represents the probability that the jammer selects the time slot in the period to conduct pulse jamming.
2.2. Problem Formulation
This paper models the problem of anti-random-pulse jamming as a Markov Decision Process (MDP). The definition of the four elements in the MDP is shown as follows, where is the state space, is the action space, is the state transition probability, and is the immediate reward that the transmitter can receive from the system.
- 1.
- : The state space is defined as follows:
Considering that the state of the environment depends on external malicious interference, we define the state space as a compound variable ,, where represents the slot number in a single interference period, and represents the identification of pulse jamming, i.e., represents the perception of pulse jamming in a single interference period; otherwise.
The principle of the compound variable is that records the number of slots and initializes to 0 in a single interference period. If the transmitter detects pulse jamming in the slot, will keep 1 from the slot to the end of the same period, and will reset to 0 if next the period starts, which is shown in Figure 2a.
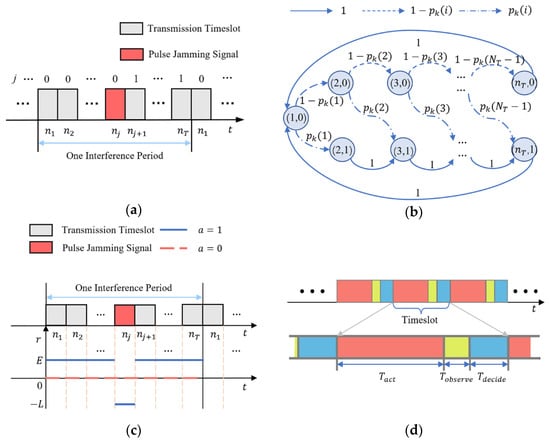
Figure 2.
Schematic diagram of the elements in this model. (a) Schematic diagram of the state parameters; (b) State transition diagram; (c) Diagram of the immediate reward function; (d) Schematic diagram of the time slot structure.
- 2.
- : The action space is defined as follows:
We define the action that the receiver will perform as a dichotomous problem, i.e., represents the transmitter remaining silent; otherwise.
- 3.
- : , whose definition is the probability of transitioning from state to state by executing action . Figure 2b shows the state transition of the system, where is the probability of the timeslot selection in Equation (1). For instance, the current state of the timeslot is , and the transmitter performs an action that is required; afterwards, the external environment transitions into the next state . The next sequence number can be expressed as follows:
Obviously, the value of is related to the current state only.
The next sequence number can be expressed as follows:
where represents the consequence of interference, i.e., represents no pulse jamming in the current timeslot and otherwise.
According to the foregoing content, the next state of the environment is related to the current state only. So, the system modeled in this paper is Markovian.
Given the above, we define the probability of a state transition from to by a conduction action as follows:
- 4.
- : The immediate reward function is that the transmitter takes action in state to obtain immediate benefits from environmental feedback. According to different states and actions, the following four types of instant reward R in specific scenes are distinguished, and the definition formula is as follows:
- If , , and , there is no pulse jamming signal in this interference period and the transmitter conducts the transmission successfully and reaps rewards from the system.
- If , , and , in this timeslot, a pulse jamming signal appears and the transmitter insists on the transmission, which will be a failure, leading to the loss from the system.
- If , , and , according to the principle of ‘One period, One pulse’, there will not be a pulse jamming signal in this single period, so the transmitter will perform the transmission successfully and gain the reward .
- If , the transmitter remains silent no matter the external environment, and there will be neither a reward nor a loss.
Figure 2c shows the immediate rewards vividly, in which the blue line and the red line in the figure represent the immediate reward situation of the “continuous transmission” and “keep silent” strategies, respectively.
- 5.
- The structure of the timeslot:
This paper divides a single timeslot into three parts chronologically: the conducted action , the observation , and the decision .
- : the transmitter conducts the action that was decided in the last .
- : the transmitter observes the external environment and senses whether there is a pulse jamming signal right now.
- : after updating the Q table, the policy of the next time slot is obtained and transmitted back to the transmitter.
According to the above, the goal of the MDP is to find the optimal strategy corresponding to the maximum long-term cumulative reward under a discount condition. The state-action function (also called the Q value) corresponding to any strategy can be expressed as:
represents the accumulated discount reward that the agent can obtain by executing the action before using the strategy starting from the corresponding state at the time . As mentioned above, if the optimal Q values corresponding to all state-action groups are obtained, the optimal strategy can be obtained.
3. SARSA-Based Time-Domain Anti-Jamming Algorithm
This paper proposes a SARSA-based Time-domain Anti-jamming Algorithm (STAA).
When the STAA is in state , it will perform the action decided in the last , observing the immediate reward and the next state . Therefore, based on the derivation strategy (here set as the ε- greedy strategy), the STAA selects the next action . The principle of updating the Q value is as follows:
In other cases, the Q value remains unchanged. At this point, the STAA has completed one iteration, and it will iterate until the end of the loop. Each complete timeslot corresponds to a complete iteration of the algorithm.
After the completion of initialization, the algorithm repeats the following operations in each full timeslot. According to the policy instruction returned by the receiver at the end of the last timeslot, in sub-slot the transmitter performs ‘keep silent’ or ‘transmission’ and calculates the immediate reward and the probability of the state transition (line 3). In sub-slot , the receiver senses the presence of pulse jamming in the current environment using the perceptual interference technique (line 4). In the decision sub-slot, the receiver deduces the next action according to the update criterion (line 5), and then updates the current Q table according to the equation (line 9). Finally, after receiving the update, the receiver generates the new strategy (line 10) and sends the strategy of the next time slot to the transmitter (line 11). The cycle repeats until the end of the iteration.
In order to achieve a reasonable transition between “dare to explore” at the early stage of decision-making and “rational use” at the later stage of decision-making, closer to the reality of intelligent decision-making, we set , where represents the number of timeslots (Algorthm 1).
The steps of the STAA are as follows:
| Algorthm 1: STAA |
| Initialize,,,, |
| The transmitter performs and calculates and in sub-slot |
| The receiver senses the presence of pulse jamming in sub-slot |
| The receiver deduces the next action according to the update criterion in and the |
| rule is as follows |
|
|
| The receiver updates the Q value according to the above formula. |
| The receiver generates the new strategy |
| The receiver sends the strategy () of the next time slot to the transmitter |
| Outputs |
4. Simulation Result and Analysis
4.1. Parameter Settings
We set the parameters related to the simulation in Table 1 as follows:

Table 1.
Settings of model-related parameters.
This paper proposes a SARSA-based Time-domain Anti-jamming Algorithm (STAA).
When the STAA is in state , it will perform the action decided in the last , observing the immediate reward and the next state . Therefore, based on the derivation strategy (here set as the ε- greedy strategy), the STAA selects the next action . The principle of updating the Q value is given in Equation (9).
In order to evaluate the performance of the proposed algorithm, this section compares the performance of the proposed algorithm with that of the following two transmission schemes:
- Continuous Transmission (CT): the transmitter continues to send data to the receiver without taking any anti-interference measures;
- The Time Domain anti-jamming Algorithm (TDAA) based on Q-learning: the anti-jamming algorithm based on Q-learning is used by the transmitter to cope with external interference and realize data communication with the receiver. For a detailed description of the algorithm, see [11].
It is worth mentioning that although Q-learning and SARSA are both reinforcement learning algorithms, they differ from each other, especially in terms of the iteration strategy. Figure 3 vividly shows the difference in the iteration strategy between Q-learning and SARSA. Q-learning’s strategy is to try possible actions in each iteration, select the prescribed action with the highest immediate return with the probability of , and try actions randomly in the other cases. It is easier to obtain the optimal action quickly at the beginning of the iteration, but the high risk brought about by the high returns makes the TDAA fluctuate easily. SARSA, on the other hand, is more inclined to choose the safe and conservative strategy. The differences in the two core strategies suggest that the STAA will perform better in terms of stability and reliability than the TDAA.
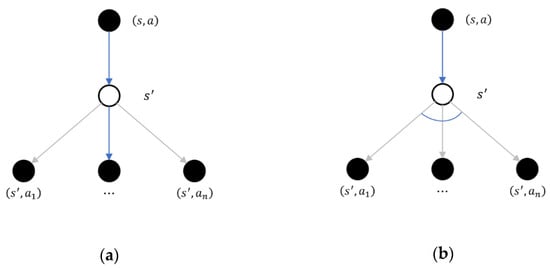
Figure 3.
Schematic diagram of the differences in the iteration strategies. (a) SARSA’s iteration strategy; (b) Q-learning’s iteration strategy.
In order to investigate the performance of the STAA and compare the two schemes, we set the following four indicators to investigate the survival ability, the transmission stability, and the learning of the anti-jamming algorithm, respectively.
- Final Collision Rate of Jamming (FCRJ). Firstly, we define the collision rate of jamming , where , which is used to describe the change in the collision probability of transmission and pulse jamming in each interference period, where represents the number of timeslots that are jammed in the interference period when iterating times. represents the number of iterations that the STAA performed; in this paper, we set it to 1000. Finally, we select the final value of the collision rate of jamming, the so-called FCRJ, at the end of an iteration, which is used to describe the algorithm’s ability to survive when jammed.
- Average Reward in Each Period (AREP). Firstly, we define the cumulative rewards in a single period. . Further, we define the average reward in each period, where , , which is used to describe the algorithm’s transmission ability after the interference period.
- Dynamic Fluctuation Ratio (DFR). To describe the stability during transmission, we define , where , which is used to describe the algorithm’s degree of fluctuation during transmission.
- Velocity of Learning Anti-jamming (VLA). In this paper, we define , where . is the number of pre-stable disturbance periods of dynamic fluctuations, which is used to describe how fast the algorithm learns external disturbances.
Last, but not least, the distribution of the pulse jamming selection is a vital parameter. We set the jamming selection to have a normal distribution. The probability density function in the period can be expressed as follows:
To ensure a normal distribution in the corresponding interference period with respect to the median axis symmetry, the value of the mathematical expectation can be expressed as follows:
where is the number of timeslots when the jammer starts to work. As the other element in the normal distribution , to make sure that the probability distribution of pulse jamming can strictly correspond to each jamming cycle, that is, the pulse interference falls within the interference cycle, we set according to the Pauta Criterion.
According to the above two factors, the probability of pulse interference occurring in the timeslot of the interference cycle can be expressed as follows:
Figure 4 shows the schematic diagram of the probability distribution of time slot interference.
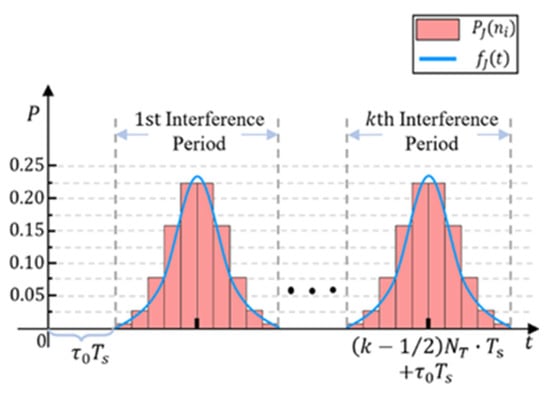
Figure 4.
Schematic diagram of the probability distribution of timeslot interference.
4.2. Analysis of Simulation
4.2.1. Basic Analysis of Indicators
Through the above-described background settings, the collision rate of jamming and the average reward in each period of continuous transmission of the STAA and the TDAA with a normal distribution of random pulse interference in the time domain were compared.
Figure 5 shows that the STAA can effectively reduce the probability of interference collision, which is much lower than the probability of random pulse interference (0.1) within the interference cycle, and the decreasing trend is similar to that of the TDAA. As shown in Figure 6, the STAA steadily improved its throughput, ranking among the top three in performance.
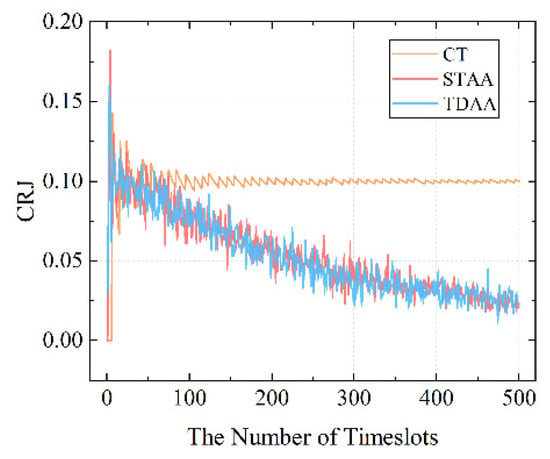
Figure 5.
Schematic diagram comparing the CRJ between continuous transmission (CT), the TDAA [11], and the STAA.
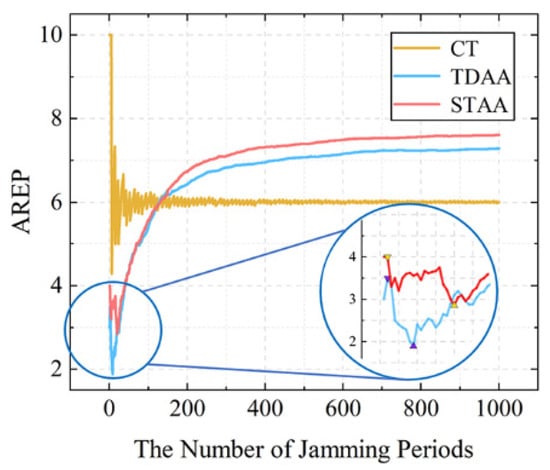
Figure 6.
Schematic diagram comparing the AREP between continuous transmission (CT), the TDAA [11], and the STAA.
In conclusion, the comparison between the collision rate and average cycle return of the three algorithms shows that the STAA has good anti-interference performance and anti-interference transmission performance in this situation.
Figure 6 shows that the AREP curves of the TDAA and STAA both have a decrease in performance at the beginning of the iteration, and then the AREP steadily increases. Local values are magnified, and it was found that the local maximum of performance decline could be uniformly defined as the “Peak Value of Return (PVR)” in this paper. The local minimum was defined as the “Valley Value of Risk” (VVR), and the interval from the PVR to the VVR was called the “Trap of Return”. The reward trap is the performance fluctuation inevitably caused by trial and error in the process of making the optimal decision at the beginning of the iteration, and the absolute difference between the PVR and the VVR of the STAA is larger than that of the TDAA. Therefore, the TDAA in local areas is more volatile and unstable.
From local areas to the entire area, fluctuations in the TDAA and STAA in Figure 6 can be observed. It was found that with the increase in the number of interference cycles, both the TDAA and the STAA experienced a period of violent fluctuations and entered a relatively stable fluctuation interval, which was denoted the “Dynamic Stability Interval” in this paper. Taking this case as an example, it was found that the range of the dynamic fluctuation interval (DSI) was about . In Figure 7, the of each algorithm is marked on the X-axis, and it was found that the TDAA can enter the dynamic stability interval earlier than the STAA. As the total number of interference cycles is fixed, the learning speed V is inversely proportional to , so the TDAA has better performance than the STAA in learning the features of the external interference. We calculated the fluctuation value after the DSI and plotted it in a frequency diagram to observe the transmission stability performance as shown in Figure 8.
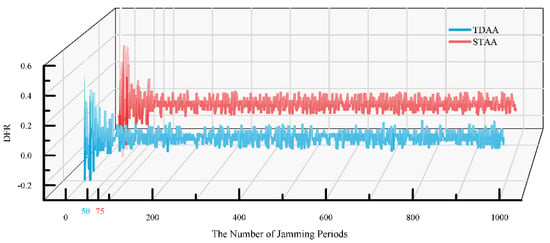
Figure 7.
Schematic diagram comparing the DFR between the TDAA [11] and the STAA.

Figure 8.
Schematic diagram comparing the numerical fluctuation frequency in the DSI between the STAA and the TDAA [11] (red represents the STAA and blue represents the TDAA [11]).
4.2.2. Risk–Return Ratio
The results show that, compared with the TDAA, the fluctuation value of the STAA is more concentrated near the fluctuation value of zero, and the number of unstable fluctuation values exceeding the DSI is less than that of the TDAA. Therefore, the STAA is more stable than the TDAA in terms of transmission performance.
Considering the impact of external interference risks on the performance of the algorithm model, the concept of the risk–benefit ratio [15] is introduced and we define as follows:
We set , respectively, where is the reference value. Here, we analyze the consequences of the compared performance when the STAA and the TDAA face different degrees of the risk–return ratio .
4.2.3. Simulation under Different Conditions
The simulation results of each performance index are shown in Table 2, and a schematic diagram of the performance comparison is shown in Figure 9. In order to verify the STAA’s excellent performance in stable transmission, a diagram comparing the numerical fluctuation frequency under five ω conditions was made and is shown in Figure 9 and Figure 10.
Table 2.
Performance of the TDAA [11] and the STAA under different ω conditions.
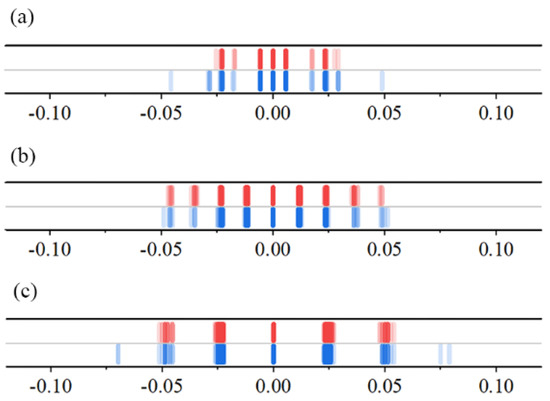
Figure 9.
Schematic diagram comparing the numerical fluctuation frequency in the DSI under : (a) ; (b) ; (c) (red represents the STAA and blue represents the TDAA [11]).
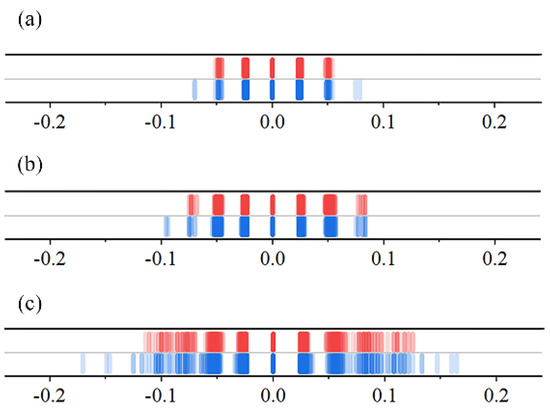
Figure 10.
Schematic diagram comparing the numerical fluctuation frequency in the DSI under : (a) ; (b) ; (c) (red represents the STAA and blue represents the TDAA [11]).
It can be observed from Figure 9 and Figure 10 that the STAA, which has a more conservative iteration strategy, has a narrower fluctuation range and a more concentrated fluctuation value than the TDAA [11], which has a more radical iteration strategy, regardless of whether ≤ 1 or ≥ 1. This is consistent with the conclusion of the initial simulation.
Subsequently, the performance indicators of the TDAA and STAA under different conditions were simulated. The values are shown in Table 2, and a schematic diagram of the performance comparison is shown in Figure 11. It is worth noting that the values of those indicators shown in Table 2 are pure numbers with no units according to the definitions above.
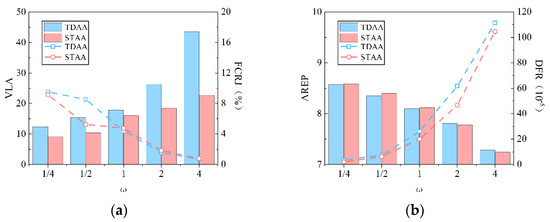
Figure 11.
Schematic diagram of the performance comparison under different ω conditions between the TDAA [11] and the STAA. (a) The contrast between the VLA and FCRJ; (b) The contrast between the AREP and DVR.
An additional verification of the fluctuation confirmed our idea. The final comparison results are consistent with the above conclusions. It was observed that the STAA achieved good communication transmission on the basis of maintaining small fluctuations under different conditions. In particular, under a high risk of interference, the advantages of small fluctuations and high-quality transmission are obvious.
5. Conclusions
In this paper, we proposed a SARSA-based Time-domain Anti-jamming Algorithm (STAA) for countering random pulse jamming in the time domain. By comparing the FCRJ, AREP, DVR, and VLA, the simulation results show that the STAA has small fluctuations, a high degree of determinacy, and good stability. Finally, through the control variable (the risk–benefit ratio ω), an experiment analyzing the performance of the STAA and the TDAA under different risk scenarios was carried out. The simulation shows that in terms of the stability of transmission, the STAA performs better than the TDAA. As the ω changes, its fluctuation range decreases by 6.0% to 40.2% compared with the TDAA, and its transmission performance error compared with the TDAA is between −0.4% and 0.6%, which can be ignored. Hence, the STAA’s value lies in its stable transmission and low volatility during periods of high demand. The simulation results further prove that, under the same interference risk conditions, the STAA’s transmission performance is more stable and less volatile than that of the TDAA. This is due to its tendency to choose conservative strategies when iterating. However, it should be noted that the cost of the stability of the STAA is the lack of an ability to extract more valuable strategies from iterations, which is not the case for the TDAA, resulting in latency in the process of learning the optimal strategy. Our conclusion is that the STAA is much more conservative than the TDAA in terms of iteration strategies. Overall, although the strategy of the STAA is more conservative, the indicators show that the STAA is more stable and reliable, especially in situations where the risk of interference is high.
Author Contributions
Methodology, Y.C. and Y.N.; writing—original draft, Y.C.; software, Y.C. and Q.Z.; supervision, Y.N. and C.C.; writing—review and editing, Y.C.; validation, Y.C. and Q.Z.; funding acquisition, Y.N.; project administration, Y.N. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Science Foundation of China (NSFC grant: U19B2014).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Sampath, A.; Hui, D.; Zheng, H.; Zhao, B.Y. Multi-channel Jamming Attacks using Cognitive Radios. In Proceedings of the 2007 16th International Conference on Computer Communications and Networks, Honolulu, HI, USA, 13–16 August 2007. [Google Scholar]
- Lee, J.J.; Lim, J. Effective and Efficient Jamming Based on Routing in Wireless Ad Hoc Network. IEEE Commun. Lett. 2012, 16, 1903–1906. [Google Scholar] [CrossRef]
- Noels, N.; Moeneclaey, M. Performance of advanced telecommand frame synchronizer under pulsed jamming conditions. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017. [Google Scholar]
- Busoniu, L.; Babuska, R.; Schutter, B.D. A Comprehensive Survey of Multiagent Reinforcement Learning. IEEE Trans. Syst. Man Cybern. Part C 2008, 38, 156–172. [Google Scholar] [CrossRef] [Green Version]
- Slimeni, F.; Chtourou, Z.; Scheers, B.; Nir, V.L.; Attia, R. Cooperative Q-learning based channel selection for cognitive radio networks. Wirel. Netw. 2018, 25, 4161–4171. [Google Scholar] [CrossRef]
- Wang, B.; Wu, Y.; Liu, K.J.R.; Clancy, T.C. An Anti-Jamming Stochastic Game for Cognitive Radio Networks. IEEE J. Sel. Areas Commun. 2011, 29, 877–889. [Google Scholar] [CrossRef] [Green Version]
- Xiao, L.; Lu, X.; Xu, D.; Tang, Y.; Wang, L.; Zhuang, W. UAV Relay in VANETs Against Smart Jamming with Rein-forcement Learning. IEEE Trans. Veh. Technol. 2018, 67, 4087–4097. [Google Scholar] [CrossRef]
- Aref, M.A.; Jayaweera, S.K. A cognitive anti-jamming and interference-avoidance stochastic game. In Proceedings of the 2017 IEEE International Conference on Cognitive Informatics & Cognitive Computing (ICCI*CC), Oxford, UK, 26–28 July 2017. [Google Scholar]
- Machuzak, S.; Jayaweera, S.K. Reinforcement learning based anti-jamming with wide-band autonomous cognitive radios. In Proceedings of the 2016 IEEE/CIC International Conference on Communications in China (ICCC), Chengdu, China, 27–29 July 2016. [Google Scholar]
- Aref, M.A.; Jayaweera, S.K.; Machuzak, S. Multi-Agent Reinforcement Learning Based Cognitive Anti-Jamming. In Proceedings of the 2017 IEEE Wireless Communications and Networking Conference (WCNC), San Francisco, CA, USA, 19–22 March 2017. [Google Scholar]
- Zhou, Q.; Li, Y.; Niu, Y. A Countermeasure Against Random Pulse Jamming in Time Domain Based on Reinforcement Learning. IEEE Access 2020, 8, 97164–97174. [Google Scholar] [CrossRef]
- Lilith, N.; Dogancay, K. Dynamic channel allocation for mobile cellular traffic using reduced-state reinforcement learning. In Proceedings of the Wireless Communications & Networking Conference, Atlanta, GA, USA, 21–25 March 2004. [Google Scholar]
- Lilith, N.; Dogancay, K. Distributed reduced-state SARSA algorithm for dynamic channel allocation in cellular networks featuring traffic mobility. In Proceedings of the IEEE International Conference on Communications, Seoul, Korea, 16–20 May 2005. [Google Scholar]
- Wang, W.; Kwasinski, A.; Niyato, D.; Han, Z. A Survey on Applications of Model-Free Strategy Learning in Cognitive Wireless Networks. IEEE Commun. Surv. Tutor. 2016, 18, 1717–1757. [Google Scholar] [CrossRef]
- Lintner, J. The valuation of risk assets and the selection of risky investments in stock portfolios and capital budgets. Stoch. Optim. Models Financ. 1969, 51, 220–221. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).