1. Introduction
License plate recognition is an important topic, due to the increasing interest in robust intelligent surveillance and security systems in modern technological societies. With the concept of smart cities, Intelligent Transportation Systems (ITS) have become a mandatory requirement, with several applications, such as automatic toll collection [
1], traffic law enforcement [
2], private access control [
3], border control [
4], and road traffic monitoring [
5]. Every vehicle carries a unique license plate (LP), which can serve as the primary key in a database, containing information about the vehicle without requiring the use of other recognizable technologies, i.e., external cards, tags, or transmitters. Therefore, Automatic License Plate Recognition (ALPR) has become an active research field and an integral part of ITSs. ALPRs rely on complex computer vision techniques to detect and recognize the license plates; hence, their accuracy and ability to deal with different LP types still has room for improvement. This is evident from the fact that practically available solutions are still not robust for real-world challenging circumstances, as they impose environmental constraints, such as a fixed background, camera location, distance, and angle.
ALPR systems typically consist of the following three stages: LP detection [
6], character segmentation [
7], and character recognition [
8]. The earlier stages particularly require higher accuracy or almost perfection, because their poor performance would lead to compounding the error in the subsequent stages. Many approaches first search for the vehicle and then its LP, which, although increases processing time, helps to eliminate false positives (wrongly categorized license plates) [
1]. The initial works on ALPR rely on optical character recognition-based (OCR) algorithms, incorporated with morphological operations [
9], binarization [
2], connected component analysis (CCA) [
10,
11], and template matching [
12] for the recognition and segmentation of characters, alongside the detection of license plates.
Most existing ALPR techniques are primarily designed to work in constrained backgrounds [
13], by using stationary/fixed cameras placed on the ground, bridges, or utility poles [
14,
15]. The fixed cameras cannot cover the entire road; therefore, a camera mounted on a mobile platform, such as a vehicle, is a desirable solution. However, in a mobile ALPR system, significant background and camera angle variations make the recognition task more difficult. In addition, there are some other challenges, such as the fact that in some countries, the LPs are written in two languages; for example, in Saudi Arabia, the text is embossed in English and Arabic. Moreover, the dimensions and designs of LPs also vary from country to country and in some cases, between regions or provinces of the same country. Therefore, there is a need to develop a robust mobile ALPR system that not only incorporates multi-lingual LPs along with all diversities, but is also pliant to the different backgrounds and other real-world environmental factors, such as illumination, camera angles, noise, and distortion.
Many recent object detection and recognition systems, including ALPR, have employed deep convolutional neural networks (CNN) because of their superior performance. A well-trained CNN can recognize visual patterns in a given image using local receptive fields, shared weights, and spatial subsampling. Moreover, CNNs can learn the hierarchy of attributes by extracting both the high-level and low-level features to describe patterns or objects. The weights in any CNN model are initialized randomly, and they are updated as the model learns from the provided data. AlexNet [
16], the winner of the ImageNet Large Scale Visual Recognition Challenge in 2012, achieved an error rate of just 15.3% and is an effective CNN model in complex image recognition scenarios. The current state-of-the-art CNN models can perform object classification on the ImageNet dataset at much lower error rates of 3.5% or less [
17]. Therefore, for recognizing license plates in an unconstrained environment, CNNs become an obvious choice.
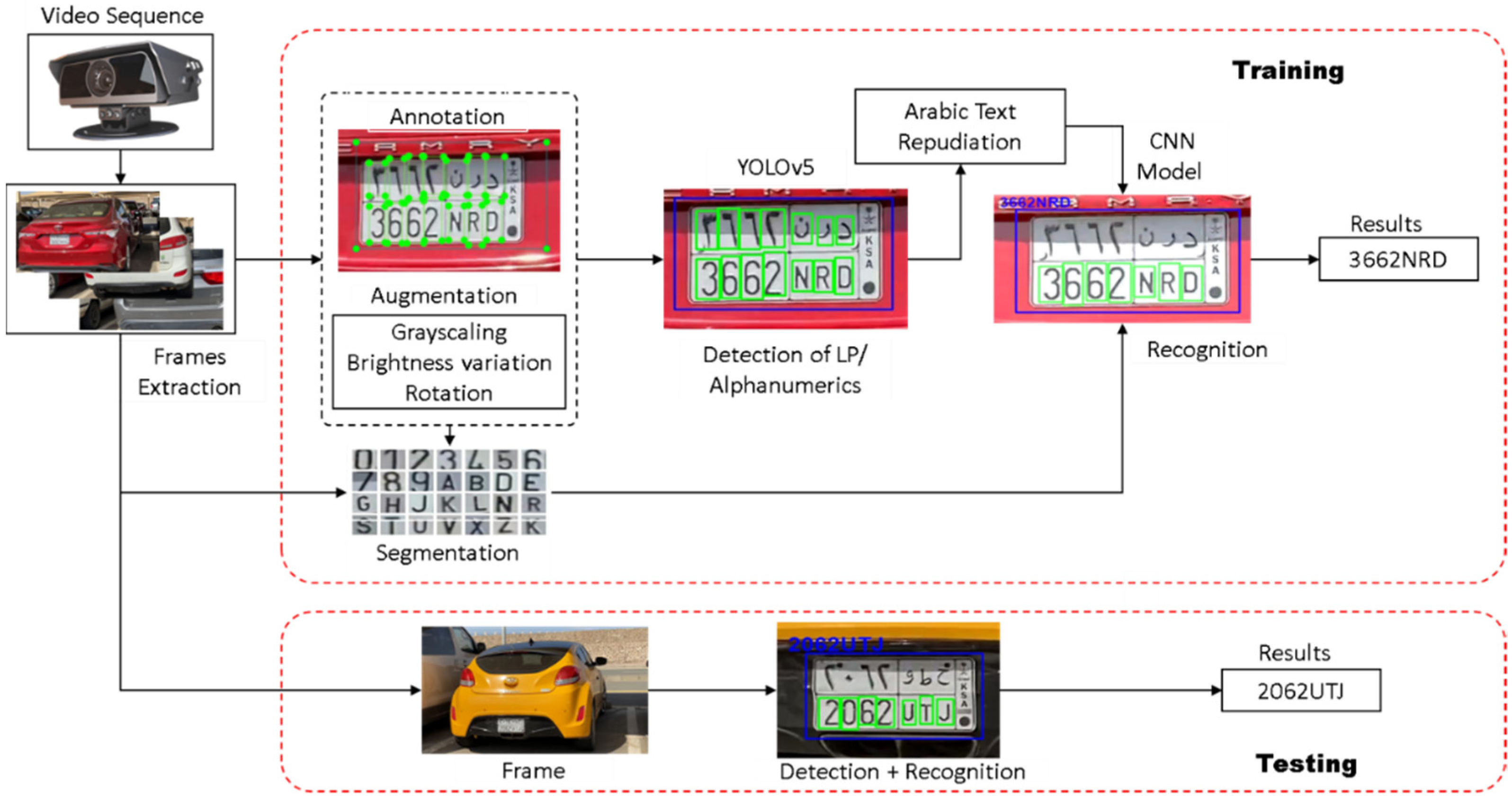
In this paper, we propose a deep learning-based solution for the detection and recognition of license plates in videos of real-world traffic, in unconstrained environments. The main contributions of the work are listed below.
We present a two-stage deep learning-based model for license plate detection and recognition.
We show that a transfer learning approach with the existing YOLOv5 model can achieve very high detection rates for LPs and their alphanumerics with minimal training.
We propose the second stage for recognition of alphanumerics as a custom CNN trained on a custom-generated dataset of images of vehicles’ front and rears.
We show that this two-stage approach can achieve significantly high accuracy, compared to a single-stage detection and recognition solution.
We present a new dataset of plates captured in real-world urban traffic in Saudi Arabia, with unconstrained dynamic backgrounds. The dataset represents some very challenging scenarios not covered in the available datasets.
We show that, despite the small size of the training dataset, our system achieves a quite high accuracy compared to some state-of-the art ALPR systems on existing benchmark datasets, as well as our custom dataset.
The rest of the paper is organized as follows.
Section 2 discusses the related work for each ALPR stage.
Section 3 describes the steps involved in preparing the training dataset extracted from the real-world traffic videos. The steps of detecting LP and recognizing its alphanumeric characters are discussed in
Section 4 and
Section 5, respectively. The experimental evaluation, through comparison with OCR and learning-based ALPR solutions, is carried out in
Section 6. Finally, the conclusions of this work and future recommendations are given in
Section 7.
2. Literature Review
Various techniques have been proposed in the literature for LP detection, segmentation, and recognition. Many have addressed LP detection as a general object detection problem. Laroca et al. [
1,
18] presented a real-time end-to-end ALPR system using the YOLO object detector, incorporated with the following two CNNs: one used for vehicle detection in the given input image and the other used for LP detection in the detected vehicle. Despite its good performance in constrained scenarios, the given technique is not adequate for real-world ALPR applications. Shohei et al. [
19] used a two-stage YOLOv2 model for accurate LP detection in night scenes, which helped overcome the YOLOv2’s problem of not being able to detect smaller objects like an LP, which is typically just around 1% of the whole frame. The first stage detects the vehicle and the second stage detects its license plate. Despite achieving good accuracy in the nighttime, it not only wrongly detected some signboards as LPs, but also faced difficulty in detecting distant LPs. Liu et al. [
20] used a YOLOv3 detector, which divides the image into rectangular regions. Each region predicts bounding boxes around potential objects and class probability to calculate the confidence value. For higher precision, non-maximal suppression is applied to the Intersection over Union (IOU), a ratio of the overlap between the predicted and the annotated (ground truth) bounding boxes. Despite being fast and accurate, the model is biased towards the object’s size in an image. The objects encountered with bigger sizes while training cannot be detected accurately if they appear as a smaller size while testing.
Ozbay et al. [
2] used a smearing algorithm for extracting text areas in a given image, using vertical and horizontal scan lines. It was then followed by the morphological operation of dilation, applied on a binarized image to specify the plate location. The limitation of this algorithm involves its non-robustness for real-world scenarios. There are a few other limitations of this algorithm as well, particularly its dependency on manually setting the vertical and horizontal gap (in pixels) between the characters.
Jain et al. [
21] extracted LP candidates using edge information, by finding the high vertical edge density. Then, morphological operations, binarization, CCA, and geometric properties filtered out the false positives to ensure high recall. The limitation of this method is that it requires capturing the vehicle from a fixed direction and viewpoint, as even a slight tilt can cause misdetection. Gou et al. [
15] used top-hat morphological transformation, a non-linear filter, and vertical edge detection using the Sobel filter for LP detection in a given frame. The main limitation of this method lies in the use of vertical edges calculated by the Sobel filter, which is highly prone to generating false gradients due to noise. Wang et al. [
22] used a single shot multi-box detector for detecting LP using a single deep neural network. Despite its excellent performance, the detector is not suitable for severe real-world scenarios, due to its lower frame rate (frames per second).
For segmenting alphanumeric characters, Shen-Zheng et al. [
10] used plate orientation normalization, by measuring the major axis to evaluate the possibility of characters in the LP region from the gradients of the input car image. Zang et al. [
23] used the traditional projection method to segment LPs into seven blocks. The characters were identified using the approximate height through the horizontal and vertical projections to segment the characters based on pixel width. Wang et al. [
22] also used the vertical projection method for segmenting characters, which scans from left to right until a projection area beyond a defined threshold is found. Ozbay et al. [
2] filtered noises and unwanted spots in the image and separated closely spaced characters by applying dilation. Vertical and horizontal smearing algorithms are used to find character regions, resulting in fine-grained segmentation.
For recognition, Jain et al. [
21] used a CNN-classifier, trained for individual characters using the spatial transformation network by performing string recognition on the whole image, avoiding the challenging segmentation. It also sped up the process of recognition. Gou et al. [
15] used an offline trained pattern classifier, based on character-specific extremal regions, and restricted the Boltzmann machine to recognize characters. It is a probabilistic non-linear model, with a bipartite connectivity graph between the hidden and visible units. It describes the distribution of edges in the image. The limitation of this method is its slower behavior during backpropagation, causing unnecessary delays in weight adjustments. Ozbay et al. [
2] used a statistical-based alphanumeric recognition method, where each character is refined and fit to a predefined fix size, before template matching with the prior defined database. It sometimes becomes challenging, as it requires exact correspondence during matching between the specified database and the recognized digit. Duan et al. [
3] used an end-to-end CNN using an inception structure, efficiently utilizing computational resources through dimensionality reduction. A deep birth algorithm was used to make the CNN effective for real-time analysis. This dimensionality reduction can affect the recognition accuracy, due to noise in the given dataset while dealing with real scenarios.
Izidio et al. [
24] trained a CNN model on synthetic LP images using an Adam optimizer and transfer learning and fine-tuned it with actual LP images to allow the network to adjust for the real world. The use of transfer learning helps to save time by fetching better performances from pre-trained models on the custom dataset. Hui Li et al. [
25] used a recurrent neural network with long short-term memory to recognize the sequential features extracted from the whole LP, avoiding segmentation. However, it requires a large number of labeled LPs for training, limiting its use as a practical ALPR solution in real-world circumstances.
Spanhel et al. [
26,
27] used a CNN that processes the whole image holistically, avoiding segmentation, thus, decreasing the computational time of recognition. LPs captured at certain angles were used for training to make the fully connected layers of CNN more robust under the variation in the capturing angle. Moreover, control points were also estimated to rectify the image, so that the LP can be aligned well before the holistic recognition of alphanumerics. Goncalves et al. [
28] also did not perform explicit character segmentation, but used separate networks to perform detection and recognition tasks. It helped to reduce the error propagation significantly, but the detection task in non-static backgrounds is rather difficult, which affects the overall performance.
Silva et al. [
29] used a CNN to detect and rectify distorted LPs, before passing them to the recognition module. It provided good recognition results, but the dataset used for testing did not represent very challenging scenarios. Hui li et al. [
30] used an end-to-end CNN approach to avoid separate training of the detection and training models and to reduce the intermediatory errors of separate models. Masood et al. [
31] used a sequence of CNNs to perform the recognition task under different variations in the background, LP sizes, fonts, and other factors, which increased the accuracy, but computational complexity as well.
Zhuang et al. [
32] used a human level semantic approach, avoiding detection and sliding window recognition by processing the whole image at once, which increased model robustness, but at the cost of additional complexity. Henry et al. [
33] used spatial pyramid pooling, along with a CNN model, so that it would not require fixed-size images to be processed for recognition. However, despite good performance, it takes a longer time to gather images of the same size for an incoming batch. Moreover, it does not work well in a completely unconstrained environment.
4. Detection of License Plate
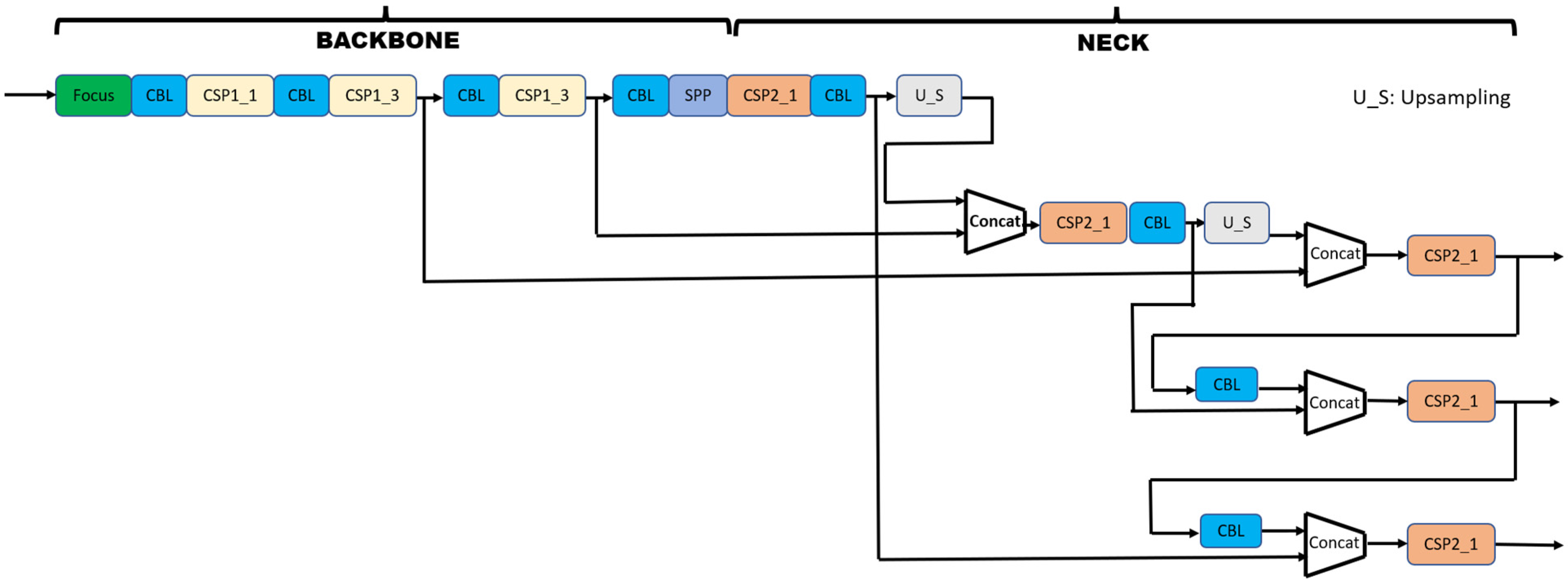
LP detection refers to locating the license plate’s bounding box in any input image and is the key to the success of an ALPR system. Traditionally, LPs were detected using color, mathematical morphology, depth, or text-based features in any given frame. These features can be used to train a detection model, and there have been many models used for this purpose. The YOLO family is one of the most widely used models for detection-related tasks, which outperforms other detection-oriented algorithms in computational complexity and accuracy since its introduction [
37]. Many versions of YOLO are available. The most recent one is YOLOv5 [
38]. It is an open-source pre-trained model on the Common Objects in Context (COCO) dataset, an extensive data for object detection research purposes. It is an improved version of its predecessors in terms of model storage, speed, and auto anchoring, along with mosaic data enhancement and a newly embedded focus structure [
39]. YOLOv5 reduces the inference time by attributing and duplicating gradient information within network optimization. It also keeps the variability in the gradients, by integrating feature maps from the beginning to the end of a network stage. YOLOv5 uses a Path Aggregation Network (PANet) [
40] to obtain a feature pyramid, shortening the information path between the lower and topmost feature layers. Similarly, two cross-stage partial (CSP) networks [
41] are used in the YOLOv5 model, one at the backbone trunk network and the other one is applied to the neck, as shown in
Figure 5. It also addresses the duplicate gradient problems in larger ConvNet-based backbones, resulting in fewer parameters and less floating-point operation per second (FLOPS), by reducing it from 32-bit to 16-bit precision for training. It reduces the number of calculations and memory costs, eventually increasing the learning ability of the model [
39]. Moreover, YOLOv5 drives its performance improvements from PyTorch training procedures instead of the Darknet framework, which despite offering fine control over the performed operations encoded into the network, still makes it slower to port in new research insights, as everyone writes custom gradient calculations with each following new edition of the model. This makes YOLOv5 faster for detection purposes in unconstrained real-world scenarios, by using the framework of PyTorch.
YOLOv5 augments data automatically in the following three stages: scaling, color space adjustment, and mosaic augmentation. Mosaic augmentation helps to overcome the limitations of its older version, not detecting smaller objects by combining four images into four tiles of random ratios [
39]. A single CNN is mainly used to perform multiple predictions for multiple classes, along with their probabilities. Non-maximal suppression then makes sure that each object, including the desired one, is only detected once.
In our approach, transfer learning [
42] is used to run this pre-trained model of YOLOv5 on a custom dataset. It is a well-known technique, helping in tunning a pre-trained model for a new task, by extracting and utilizing the rich features from a limited custom dataset. It is computationally inexpensive and performs better for detection with more transferred feature layers, without considering the substantial amount of dataset, training, and numerous calculations, which consume a large amount of time. For the LP detection module, the dataset of 5500 images is split into the training, validation, and testing sets, with ratios given in
Table 1.
The YOLOv5 model is trained with 416 × 416 × 3 images at the input, using the annotated dataset. It then outputs the bounding box of the detected LP. The LP region in the image is cropped automatically and fed again to the same YOLOv5 model with the same input dimension of 416 × 416 × 3 to find the alphanumerics within it. The bounding boxes are transformed to find out their positions in the original frame, at a resolution of 1920 × 1080 pixels. Some results on the actual sized frame are shown in
Figure 6.
After training the model, predictions are made using the test dataset comprising 600 unseen frames, separated before augmentation. The model successfully detected the front or rear plates in these images, with a mean average precision (mAP) of 95%. The detection module gives the exact coordinates of the LP and alphanumeric positions within it, which are used in the next stage of alphanumeric recognition explained in the next section.
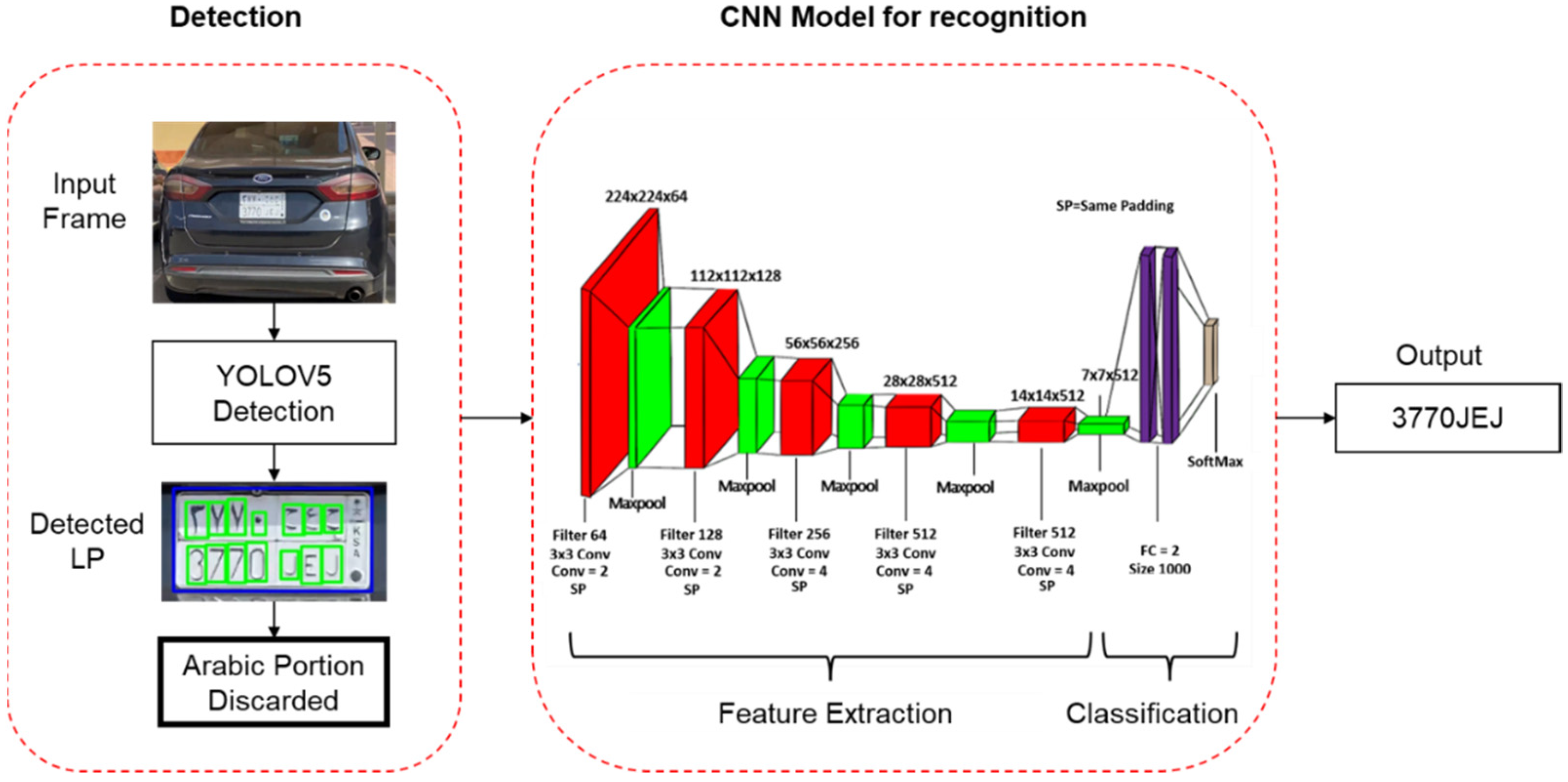
5. CNN Model for License Plate Alphanumeric Recognition
The proposed CNN model for recognition receives cropped and resized windows of LP and alphanumerics, as inputted from the YOLOv5 detection algorithm. Its detailed architecture is shown in
Figure 7 and explained in the section below.
The main advantage of choosing CNN architecture is that it automatically extracts the important distinctive features of every defined class, without human intervention [
17]. The proposed architecture of CNN starts with 16 convolution layers with a filter size of 64, 128, 256, and 512 to extract the high-level features in given data, as these layers are smart feature detectors. Each convolutional layer is succeeded by a maxpool layer of size 2 × 2 pixels. In total, five maxpool layers were used. In the end, two fully connected (FC) layers were embedded instead of using a conventional classifier, such as SVM, so that the model can remain end-to-end trainable. The same padding (SP) was used with a stride size of 1. An Adam optimizer was used in the proposed model, as it is regarded highly for non-convex optimization problems that affect the learning ability of the model.
Using two FC layers helped the model increase its capacity to gather responses from the previously detected features in the early layers. The two smaller FC layers were used rather than one large FC layer, as it would require more memory. The SoftMax function was then used as an activation function at the output layer, due to its ability to deal with multi-class classification problems [
17].
The training of the model was carried out using our dataset of segmented alphanumeric characters from the original and augmented LPs, as discussed above. All 27 classes of alphanumerics were placed into their respective folders for training. These alphanumeric glyphs were split with the same ratio as used for the detection dataset. The split ratio is shown in
Table 2.
In the CNN, the convolutional kernel is 3 × 3, and the size of each segmented digit is resized to 224 × 224 × 3. The alternating structure of the multiple convolutional and non-linear activation layers extracts the rich features of a given alphanumeric sample. The Rectified Linear Unit (ReLU) activation function is used. The stride size of 1 pixel is used for the convolutional layers and 2 pixels for the maxpool layers. The output goes to two fully connected layers, with 1000 neurons each. SoftMax is used to make the final decision to recognize and classify any alphanumeric character. The output of the proposed CNN is the recognized alphanumeric. In Saudi license plates, there are Arabic and English alphanumeric characters. We trained our character recognition network with only English alphanumeric characters, as shown in
Figure 8.
To address the issue of the Arabic alphanumeric characters, we adopted a simple location-based strategy. We observed that all LPs have a rectangular shape, and Arabic characters and numerals occupy the top half of the license plate. Hence, we used the minimum and maximum values of the y-coordinates to discard the Arabic portion from the license plate, as shown in
Figure 9. The Arabic portion within all the LPs was reannotated, as we required the bounding boxes to implement the defined logic. In this way, we gathered all the required annotations of LP, alphanumeric, and their corresponding Arabic portion in XML format, which again converted into YOLOv5 defined .txt format. YOLOv5 then trained again on this reannotated dataset, with the same split ratio as defined earlier in
Table 1. After detecting all the LPs and English and Arabic alphanumeric bounding boxes in a given frame, the technique mentioned above was used to reject the upper portion of LP.
After this, the proposed model was applied to the processed LP for the recognition of alphanumerics. After extracting the features through the convolutional layers, all features were flattened to create a single long feature vector, which was fed as an input to the fully connected layers to learn a nonlinear combination of these extracted features. Finally, a SoftMax activation function was used to obtain the probabilities of every input against all of the possible 27 classes. The recognized results were ordered, based on their distance from the left end of the LP. Some examples of correctly read plates with their respective appended results are shown in
Figure 10. The green bounding boxes were drawn using window weight bias and position coordinates, generated by the YOLOv5 model.
6. Experimental Evaluations
In this section, we explain the details of the training and validation process. Next, we compare the proposed method with traditional image processing and OCR-based approach for LP recognition. This is followed by a comparison with existing deep learning-based approaches, using some existing benchmark datasets. Then, we show some challenging scenarios in the proposed dataset and evaluate the proposed and some existing methods on this custom dataset. We also present the computational speed of the proposed method on different datasets.
6.1. Training and Validation
The training of YOLOv5 and the proposed recognition model was conducted using a GeForce GTX 1080 8GB on the Linux operating system of Ubuntu 20.04.3 LTS, using the IDE of PyCharm, due to its dynamic computation graph support and hybrid front-end, providing model insights and flexibility of use. For detection, the open-source code of YOLOv5 [
38] was used. The model of YOLOv5 has 213 layers, along with 7,225,885 parameters. The batch size was set to 32, with an epoch of 100. For license plate detection, IOU was used to measure the ratio of the predicted bounding box of the LP to the annotated ground truth. It helps in evaluating the accuracy of the model on a particular dataset. An IOU of >0.5–0.9 was considered acceptable, while rectangles predicted with IOU below 0.5 were discarded.
A commonly used metric to quantify the detection accuracy of an object detection algorithm is the mean average precision (mAP), with a value between 0 and1. The higher the score, the more accurate the model will be. Precision tells us how exact the model is in its predictions. It can be given as the following equation:
True-positive (
TP) refers to a situation when the model correctly predicts an LP or an alphanumeric character. In contrast, false-positive (
FP) refers to an incorrect prediction of LP or an alphanumeric character. Recall measures how well the model can find all the positives in the dataset. It can be given as the following equation:
False-negative (
FN) means when the model fails to predict any object. It depends on the health of data and proper ground truth annotations fed to the model. On the custom test dataset, an overall mAP of 95% is achieved by our trained YOLOv5 model, while detecting an LP and its characters. The performance can be observed through the graphs of various performance metrics shown in
Figure 11.
The following two different types of losses are shown in
Figure 11: box loss and objectness loss. The box loss shows how well the detection algorithm locates the center of the detected object and covers the region of interest (ROI). Objectness is a measure of the probability that an object exists in a proposed ROI. A high value indicates that the image window is likely to contain an object. Moreover, it can be observed in
Figure 11 that the model swiftly improved, in terms of precision and recall. The box and objectness losses of the given validation data show a rapid decline. We used early stopping to select the best weights to be fed for the further recognition process.
The network is trained by using 12,000 samples of alphanumerics with a batch size of 64, along with gradient descent to observe loss. We began with a hyperparameter of a learning rate of 0.001, as we do not want to slow the learning every time the weight is updated. We trained the models for 100 epochs, as more than this can lead to model overfitting. Moreover, this was the point at which our proposed network converged. The proposed convolutional neural network achieved 92.8% accuracy in the testing process with minimal loss, as shown in
Figure 12. This learning curve also gives us insights into how the model behaves in the respective modes of training and testing.
6.2. Comparison with OCR-Based System
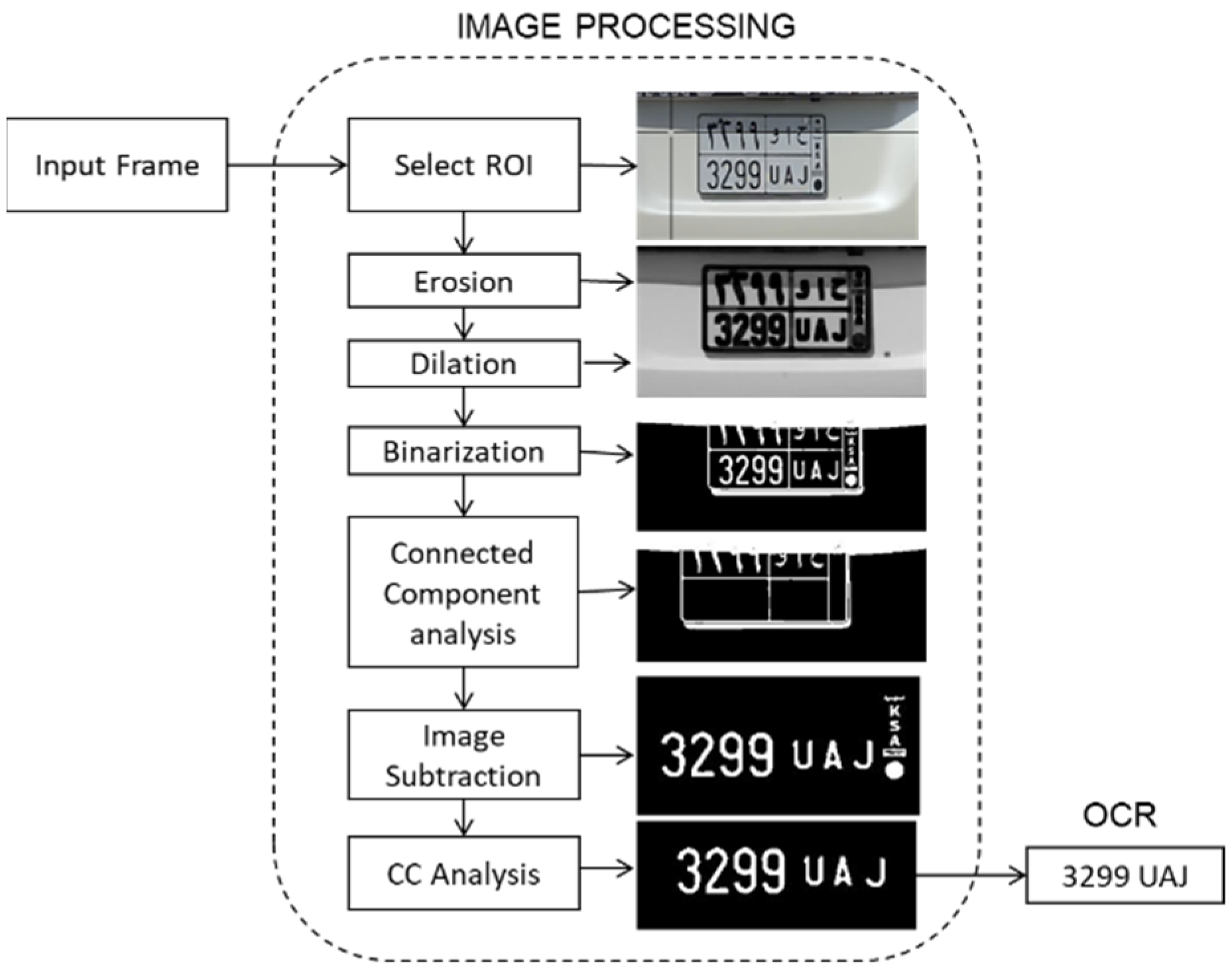
OCR techniques can, in general, read the text in images accurately. The effectiveness of OCR is tested in LP recognition to set a baseline for the evaluation of our method. In conducted experiments, OCR could not read the number plates in any given frame; therefore, the number plate was segmented manually and passed to OCR. There were still very few occasions when the complete LP was read. Then, the text in the plate was enhanced through a series of morphological operations, as described below, to prepare a suitable input for the OCR algorithm.
Figure 13 shows the complete pipeline of the OCR-based ALPR algorithm.
The segmented LP is converted from RGB to a single-channel grayscale image. The compound operations of erosion and dilation, using a 3 × 5 structural element, are then applied to remove the small and narrow regions other than LP, so that the edges of ROI become sharper. A threshold is applied to convert the image into a binary black and white space (black text on a white background or vice versa). Next, the technique of CCA is applied, which scans and labels the pixels of a binarized image into components based on pixel connectivity, using neighboring pixels to identify the larger components. After this, the grid of the lines on the plates is identified using CCA and discarded by subtracting them from the binary image. CCA is applied one more time to remove the coat of arms and the undesired small letters written vertically in the right portion of every LP. At this stage, the text is very clear and ready to be processed by the OCR module.
As can be noted, the above pipeline is explicitly designed to prepare a clear LP input for the OCR. Yet, the recognition accuracy is quite low, and only 60% of LPs were correctly read, 15% were partially read, and 25% went completely unread. In comparison, the proposed CNN model had a very high accuracy of 92.8% on the same test dataset.
The above results show that the OCR approach is not suitable for LP recognition. The OCR reads many characters wrong and often confuses them between similar-looking characters, such as 8 and B. In comparison, a learning-based approach can adapt to different alphanumeric strokes, fonts, backgrounds, and noise levels. Several learning-based solutions are available, and our proposed model is compared with these solutions in this section.
6.3. Comparison with Learning-Based Solutions Using Benchmark Datasets
Here, we show a comparison with the existing state-of-the art methods, using three existing benchmark datasets: Caltech benchmark dataset [
43], UFPR benchmark dataset [
1], and Media Lab benchmark dataset [
44]. The Caltech dataset [
43] consists of 126 US plates captured at the resolution of 896 × 592 pixels, and it has been used in several existing works. We show a comparison of our system with some of these in
Table 3. The proposed system achieved an accuracy of 98.1% and outperformed all competing algorithms.
Next, we use the UFPR dataset [
1], consisting of 4500 images of Brazilian plates taken at 1920 × 1080 resolution. The results comparing our method with some existing methods using this dataset are shown in
Table 4, and again the proposed method achieved a very high accuracy of 95.3% and outperformed the competing methods.
Another benchmark dataset that has been used by many existing methods is the dataset [
44] containing 726 Greek plates. A comparison using this dataset is shown in
Table 5. The proposed method remained second with an accuracy of 97.4%, while the winner had an accuracy of 97.9%. This small difference is not significant and could be due to a difference in the choice of training and testing subsets. It should also be noted that this dataset is less challenging, and all methods achieved very high recognition rates.
6.4. Scenarios Covered in the Proposed Dataset
Our testing set comprises LPs with and without challenging deformations. Some of the deformations that affected the plates are presented below.
Poor Text Visibility: The dataset consists of 30 cases, where the visibility of alphanumerics within the license plates is poor. Our model still works fine in many such cases, as shown in
Figure 14. In the same set, there are some extreme cases of poor visibility of alphanumerics, as shown in
Figure 15. In such cases, the model found it hard to discern alphanumerics within an LP either completely or partially.
Deteriorated Alphanumeric: This dataset consists of 50 cases that include LPs with either partially or completely deteriorated alphanumerics. A few of these cases, along with their respective recognition results, are shown in
Figure 16. However, there were also some cases where the alphanumerics were completely degraded, and the detection and proposed recognition models found it hard to detect and recognize the LPs completely, as shown in
Figure 17.
Orientation Variation in License Plates: There were 20 LPs captured at an oblique angle and they did not appear rectangular in the image. Despite such a situation, the model works completely fine on them, as shown in
Figure 18.
Cars Moving in Traffic: The traffic-based test dataset consists of 300 LPs. Some of these are shown in
Figure 19.
While testing the proposed model on this dataset, higher accuracy was obtained, as shown in
Figure 20. Some problems were also encountered, due to the over and underexposed regions within the frames because of the glare that was generated, due to the reflection of sunlight from the windshield of vehicles or side mirrors.
Parked Cars: This dataset consists of 200 LPs, captured in different parking lots. The proposed model performed with high accuracy against this set of images, as shown in
Figure 21.
6.5. Comparison with Learning-Based Solutions Using Custom Dataset
In the next experiment, we used our custom dataset extracted from real-world traffic videos, captured in an unconstrained environment using mobile cameras. The frames extracted from these videos contain many challenging scenarios, as explained earlier. Three commercially available solutions, Sighthound [
46], PlateRecognizer [
47] (based on Masood et al. [
31]), and OpenALPR [
45], and a recently proposed method by Silva et al. [
29] designed to work in unconstrained environments, were compared with the proposed system in this experiment. In the commercial tools, the country was set to Saudi Arabia before testing to fine-tune the algorithms for the best results. The overall results are shown in
Table 6, demonstrating that the proposed method performed significantly better than all the other solutions. These algorithms also work fine when plates with better quality were being fed to them, but their performance dropped on the challenging plates. In most cases where these methods failed, they were either unable to detect the plate or could not recognize or discern the alphanumeric characters and digits.
6.6. Comparison with a Single-Stage Deep CNN
In the proposed work, YOLOv5 was used for the detection of license plates and a separate classification CNN was employed for the recognition of characters in the license plate. However, since YOLOv5 is a multi-class detector, one question that may arise is why YOLOv5 is not used directly for the recognition of alphanumeric characters. The reason for this is that YOLOv5 is an object detection framework and needs minimal training for customization to a specific detection task, such as the detection of the LPs in our case. The YOLOv5 model, trained with our small dataset through the transfer learning approach, achieved a very high detection accuracy. However, for the recognition task, more intensive training of YOLOv5 on a large dataset would be required. We carried out this experiment and trained YOLOv5 using the available 12,000 training samples, as given in
Table 2, but obtained an accuracy of only 36% on our test dataset. Therefore, for this limited dataset, we opted for a smaller customized CNN in the second stage of the proposed system, specifically designed and trained for the recognition task, instead of using a YOLOv5-based algorithm. With this approach, the accuracy of recognition improved to 92.8%, using the same training and test datasets.
6.7. Efficiency of the Proposed Method
The proposed method used YOLOv5 for the detection of LPs, which is a well-known system for the efficiency and accuracy of detection. The proposed custom CNN, used for recognition, is relatively small in size; thus, it also works very efficiently. The overall efficiency on the different datasets is shown in
Table 7. It can be observed that the processing time for the entire process of detection and recognition is quite low and the system can work in real time.
7. Conclusions
This paper proposed a CNN model for the recognition of the alphanumeric text in each detected plate. The proposed method is computationally efficient and works in real-world, unconstrained and challenging scenarios.
YOLOv5 is a well-known, deep neural network model trained on a very large dataset for the task of detection and classification of objects. With our small dataset, we successfully trained this large network for the specific task of the detection of license plates and alphanumerics, using the transfer learning approach. However, the classification of each alphanumeric was a challenging task for YOLOv5 with the limited training dataset, and it could only achieve an accuracy of 36% on our test dataset. Therefore, we designed a custom CNN specifically for the recognition task and determined the appropriate number and sizes of layers and correct parameters for optimal performance.
We also proposed a new challenging dataset of KSA license plates, extracted from traffic videos and parking lots captured in an unconstrained environment. These LPs have bilingual text, and to improve the accuracy, we trained the model to discard all candidate alphabets that are not aligned with the main English text. This not only increased the accuracy of our system on the KSA license plates, but also on the other benchmark datasets that have additional text on the plate other than the main string of alphanumerics.
The proposed model achieved high accuracy, better than the existing state-of-the art methods in the literature and several commercially available solutions. The problems encountered during our testing were uneven illumination due to the overexposed and underexposed regions and completely deteriorated and extremely poor visibility of alphanumerics. In our future research, we plan to address these problems using high dynamic range (HDR) images, which can better capture details in extremely bright and dark regions and hence, further improve the accuracy of the system. One other interesting direction would be to use the discarded Arabic part to restore the completely degraded English alphanumerics. We also aim to explore new CNN architecture models to optimize performance, by keeping feasibility intact in terms of speed and accuracy.


 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}