Abstract
With the maturity of computer vision and natural language processing technology, we are becoming more ambitious in image captioning. In particular, we are more ambitious in generating longer, richer, and more accurate sentences as image descriptions. Most existing image caption models use an encoder—decoder structure, and most of the best-performing models incorporate attention mechanisms in the encoder—decoder structure. However, existing image captioning methods focus only on visual attention mechanism and not on keywords attention mechanism, thus leading to model-generated sentences that are not rich and accurate enough, and errors in visual feature extraction can directly lead to generated caption sentences that are incorrect. To fill this gap, we propose a combination attention module. This module comprises a visual attention module and a keyword attention module. The visual attention module helps in performing fast extractions of key local features, and the keyword attention module focuses on keywords that may appear in generated sentences. The results generated by the two modules can be corrected for each other. We embed the combination attention module into the framework of the Transformer, thus constructing a new image caption model CAT (Combination Attention Transformer) to generate more accurate and rich image caption sentences. Extensive experiments on the MSCOCO dataset demonstrate the effectiveness and superiority of our method over many state-of-the-art methods.
1. Introduction
A long-term goal in the development of artificial intelligence is to develop agents that can perceive and understand rich visual environments around us and communicate with us using natural language [1]. Therefore, it is vital to research image descriptions.
Image caption is a typical multimodal learning problem, as shown in Figure 1, which is a process from vision to language and contains several core problems of representation, alignment, translation, and integration. Image caption requires us to combine techniques and knowledge from multiple fields, such as computer vision and natural language processing. Early image caption models are based on templates that generate description sentences by identifying objects, object attributes, and object relationships in images to match language templates. Existing models gradually get rid of the limitations of earlier target recognition methods and template-based text generation, and most of them adopt an encoder-decoder structure. The best-performing models mostly incorporate the attention mechanism in the encoder–decoder structure. However, regardless of whether the attention mechanism is channel-based or space-based, it is a visual attention mechanism. In the domain of image caption, if only visual features are attended to, errors in visual features will directly lead to errors in the generated description statements.
Figure 1.
The core challenges of multimodal problems.
To solve the above problems, we propose a combination attention module that contains a visual attention sub-module and a keyword attention sub-module. The visual attention sub-module can use image spatial features with a high degree of abstraction to guide the model to focus on key regions of the image. The keyword attention sub-module extracts keyword semantic information to guide the generation of richer and more accurate image description statements. We embedded the combination attention module into the Transformer framework and constructed the CAT (Combination Attention Transformer) model to help generate richer and more accurate image description statements. CAT solves the traditional image caption method’s neglect of global background information and keyword information, which often leads to inaccurate and rich description sentences. We evaluated our method on the MSCOCO image caption dataset, and CAT improved the CIDEr score by 0.2% over the current state-of-the-art method.
2. Related Work
2.1. Image Caption
Image caption is a technique that attempts to “translate” images into text using machine learning methods [2,3]. The research history of the image caption problem is only ten years old, but the image caption model has experienced many major changes. Kiros et al. [4] proposed a method to solve the image caption problem using neural networks. A multimodal embedding space model based on a deep visual model and a long short-term memory unit can accomplish retrieval ranking as well as the image caption task. After that, many scholars tried to use deeper neural networks [5] or other network structures such as gated recurrent units (GRU), long short-term memory units (LSTM) [6], bidirectional LSTM [7], and phi-LSTM [8] to solve the image caption problem. Yao et al. [9] proposed an attribute-based long short-term memory network (LSTM-A) that added advanced attribute features to the combined model of CNN and LSTM and used a weakly supervised multi-instance learning method to complete the image caption task. In the last two years, there have been many attempts directed toward introducing attention mechanisms into the field of image caption research [10,11,12], among which the M2 Transformer model [10], designed by Cornia et al., achieved the most advanced image caption results so far. They used a multi-layer attention mechanism to extract features of images and text and used mesh connections to learn the connection between the two features. At the same time, various decision-making methods of reinforcement learning and generative adversarial networks have also been used in the study of image captioning problems [13], increasing the naturalness and diversity of the generated texts.
2.2. Attention Mechanism
The attention mechanism was initially a human-specific means of using limited cognitive resources to quickly sift through large amounts of information. Humans would learn the target areas to focus on by quickly scanning the global image and then they would devote more attentional resources to the target areas to obtain more detailed information about the target of attention.
The attention mechanism was first applied in the field of computer vision [14], and Xu et al. [15] first applied the attention mechanism to the image captioning algorithm. Its inspiration comes from machine translation, which compares image-to-language translation to language-to-language translation. The encoder–decoder framework is used, but the method of processing text is replaced by the method of processing images in the encoder and then the images are inputted into the decoder to generate natural language.
The model based on the attention mechanism can not only log the positional relationship between information but also measure the importance of different information features according to the weight of the information. Dynamic weight parameters are established by making relevant and irrelevant choices for information features to strengthen key information and weaken useless information, thereby improving the efficiency of deep learning algorithms and improving some of the defects of traditional deep learning. However, whether it is a channel-based or a spatial-based attention mechanism, it is a visual attention mechanism. Image understanding methods that use only a visual attention mechanism may not necessarily extract all the features that need attention effectively. Inaccurate visual features may be extracted, so using only a visual attention mechanism may lead to the problem of generated descriptive statements that are inaccurate and not rich.
2.3. Transformer
In 2017, Vaswani et al. [16] proposed Transformer and applied it to the field of machine translation. Transformer consists of an encoder and a decoder, where the encoder is responsible for mapping the input sequence to the hidden layer after positional encoding, and then the decoder maps the hidden layer to the output sequence. The encoder and decoder each consists of several Transformer blocks with the same structure. Each Transformer block consists of a multi-headed attention layer, a feedforward neural network, residual connection, and layer normalization.
Transformer was first applied in the field of natural language processing (NLP) [16]. After that, Devlin et al. [17] proposed Bidirectional Encoder Representations from Transformers (BERT), which is pre-trained on unlabeled text considering the context of each word. Brown et al. [18] pre-trained a Transformer-based model named Generative Pre-trained Transformer 3 with 175 billion parameters on 45TB of compressed plaintext data. It showed excellent performance without any fine-tuning. These Transformer-based models have achieved major breakthroughs in NLP because of their powerful representational capabilities.
Inspired by the powerful representational capabilities of the Transformer, researchers have started to apply the Transformer to object detection [19,20], image processing [21], semantic segmentation [22], and video captioning [23] tasks. Dosovitskiy et al. [24] proposed ViT, which applies a pure transformer directly to a sequence of image patches to classify the entire image, and it achieved state-of-the-art performances on several image recognition benchmarks. Ji et al. [25] proposed a globally enhanced transformer and applied it to solve the image description problem, which achieved exciting results.
Transformer solves many problems by utilizing the encoder–decoder framework, attention mechanism, layer normalization, and feedforward neural network. However, Transformer also has other drawbacks, such as only being able to efficiently process long sequences, while the processing performance of short sequences has not been improved. For the image caption problem, the transformer encodes the object region and then transforms it into a vector representation to guide the decoding of the description statement. This approach only obtains region-level information but not global information. In this paper, we propose a combination attention module that incorporates a visual attention module and a keyword attention module. The visual attention sub-module can use the spatial features of the image with a high degree of abstraction to guide the model to focus on the key regions of the image, and the keyword attention sub-module extracts keyword semantic information to guide the generation of richer and more accurate image description statements. The results generated by both attention sub-modules can be corrected for each other. After that, we embedded the combination attention module into the Transformer framework and built the CAT image description module to generate richer and more accurate image description statements.
3. Methods
3.1. Combination Attention Module
The attention mechanisms used in current image understanding methods are all visual attention mechanisms. This may lead to the incomplete extraction of features that need attention and the extraction of incorrect visual features. Thus, using only visual attention mechanism may lead to the problem of inaccurate and rich generated description statements. Therefore, we propose using a combination attention module. As shown in Figure 2, the combination attention module consists of a keyword attention module and a visual attention module. The keyword attention module allows the model to focus on the important keyword text by associating keywords with visual features to generate richer and more accurate descriptive statements. The visual attention module uses spatial features with a high degree of abstraction to direct the model’s attention to key regions of the image and generate more accurate descriptive sentences. The results generated by the two attention modules can be corrected for each other, resulting in more accurate and richer image caption statements.
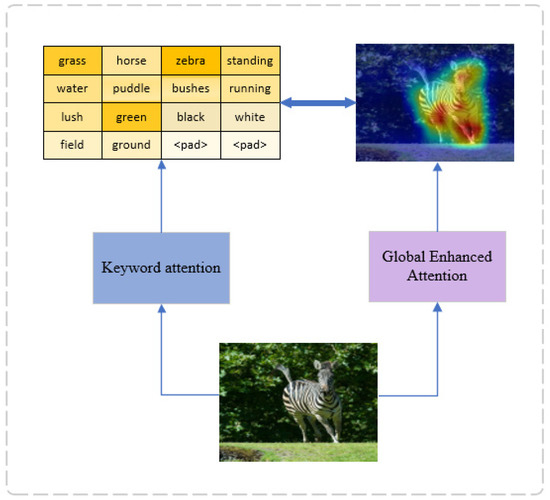
Figure 2.
Schematic diagram of the combination attention module.
3.1.1. Keywords Attention Module
The existing dataset of image caption domain contains only images and their corresponding description statements. To train our proposed combination attention model, we additionally constructed a keyword dataset based on the image caption dataset. In the process of constructing the keyword dataset, we picked out high-frequency words, merged synonyms in descriptive statements, and increased the weight of some words on which the dataset needed to focus on. The process of constructing the keyword dataset is shown in Figure 3.
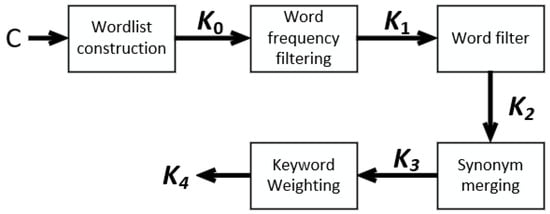
Figure 3.
The construction process of keyword dataset.
In Figure 3, denotes any of the caption sentences in the dataset . Firstly, we constructed a word list from the image caption sentence , where denotes the number of occurrences of word in all descriptive statements , and m denotes the total number of words. We selected the words with greater than to form to pick out the words with high frequency, and then we selected and picked out some words of lexical nature (e.g., coronal words and adverbs) in the word list , keeping nouns, verbs, and adjectives in order to obtain the keyword word list . The keyword word list was obtained by merging the synonyms in , e.g., courage and gut were merged into courage. Finally, the keyword dataset is obtained by providing appropriate weights to the keywords by utilizing weakly supervised learning and fine-tuning. The dataset can be expanded into a dataset with keyword data by performing the above operations on all description statements in the dataset .
Different keyword weights indicate that the model pays different levels of attention to the words. The greater weight of the words indicates that they are more important, and their impact on the generated description statements is greater. Keyword weighting is calculated as follows:
where ReLU is the modified linear unit activation function. is the th component of the keyword vector feature matrix, and is the weight to be learned. and are weight matrices; is the hidden state of the th word; is the keyword weight of the th word; is the unnormalized weight vector; is the number of components of keyword feature ; is the unnormalized weight vector; is the keyword feature value corresponding to the th word.
Figure 4 is a schematic diagram of the keyword attention module. Keywords are representative words in description statements. Introducing keyword attention not only can result in better image features, but it can also guide the generation of description statements to formulate more accurate and richer generated description statements [26].
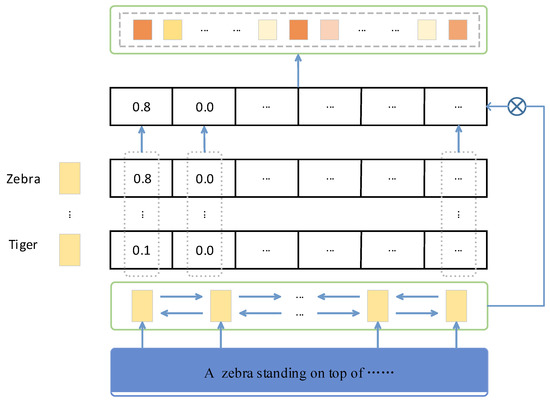
Figure 4.
Schematic diagram of the keyword attention module. Let the sequence of words generated based on visual attention interact with the sequence of words in the keyword dataset to identify which words are highly similar to the words in the keyword list and increase the weight of the part of words that require focus.
is a sequence of words generated based on visual attention, and is a sequence of keywords. The two representations are made to interact with each other to learn a similarity measure that discriminates whether the generated words of visual attention are relative to the word pairs in the keyword list, and then we take the following maximum value:
where denotes the dot product, denotes the th word in , and denotes the th word in . Then, the word sequence is represented by the and dot product .
After the softmax operation, we completed the operation of probabilistically encoding the words in the dictionary.
3.1.2. Visual Attention Module
The visual attention module can help in quickly extracting key local features. Early attention mechanisms only feed region information into the encoder to extract their vector representations. These vector representations only contain image information features at the region-of-interest level, even though the vector representations of individual regions are computed hierarchically through all regions in the image. This paper adopts the globally enhanced attention mechanism proposed by Ji et al. [25], which solves the problem of Transformer’s poor global attention to a certain extent.
As shown in Figure 5, to capture the global representation information, we fed both regional feature and global feature into the visual attention module. In this way, we captured global information within the feature layer. Specifically, the output of the layer was inputted into the visual attention module of the layer, followed by residual connection and layer normalization, which are computed as shown below:
where . represents the output of after passing through the multi-head attention layer. The output of the layer can be obtained by performing residual connections between and and then performing layer normalization. The residual connection helps in avoiding gradient disappearances during the training phase. Then, the final feedforward neural network is used to perform additional processing on the output.
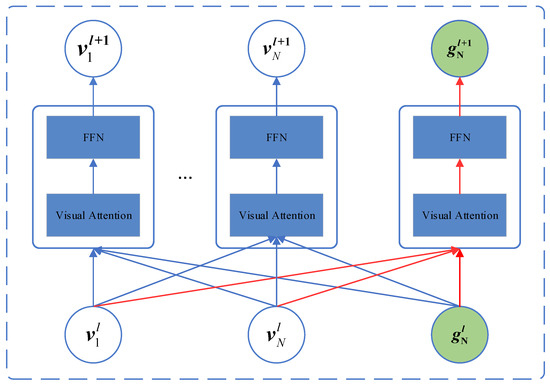
Figure 5.
Schematic diagram of the global visual attention module.
The representations of different layers have different meanings. Therefore, we integrated global representations from different layers by pooling to fuse all information. The process of integration also eases the flow of information in the stack.
3.2. Framework
3.2.1. Encoder
The overall architecture of CAT is shown in Figure 6. Firstly, we resized the input image into resolution. After that, we divided the resized image into patches, , and is the set patch size. Then, we reshaped each patch as a sequence of one-dimensional patches . We used a linear embedding layer to map the patch sequences into the feature space and embedded learnable location information into patch features [27], after which we obtained the final input of CAT, which is denoted as .
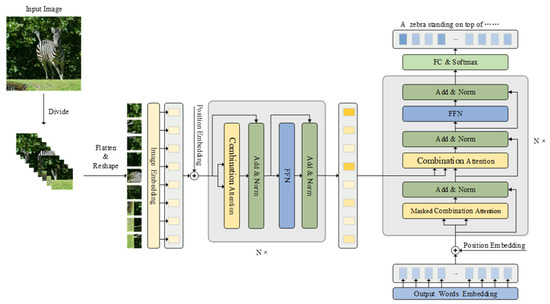
Figure 6.
Schematic diagram of the overall architecture of the CAT model.
The encoder of CAT consists of a stack of identical modules, with each layer consisting of a combination attention sub-layer and a position feedforward sub-layer. The combined attention sub-layer contains a visual attention module and a keyword attention module, with each corresponding to an independent scaled dot product attention function [16], which allows the model to jointly focus on different subspaces. We used a linear transformation to aggregate the keyword attention module and visual attention module attention results, and this process can be represented by the following equation:
where , , and are the query, key, and value matrix, respectively. consists of query vectors, and and both contain keys and values. denotes the scaled dot product attention function corresponding to the keyword attention module, and denotes the scaled dot product attention function corresponding to the visual attention module.
The scaled dot-product attention function is one of the core components of Transformer, and all intra- and inter-modal interactions between words and image features are modeled by the scaled dot product attention function. It can be computed in the following manner:
where is the dimension of , , and .
The following position feedforward sub-layer comprises two linear layers with a GELU activation function and dropout between them to further transform the features.
In each sub-layer, we used a residual connection around each sub-layer and then performed layer normalization:
where and are the input and output of a sub-layer, which can be an attention layer or a feedforward layer, respectively.
3.2.2. Decoder
The decoder of CAT is also formed by stacking identical modules. Each layer contains a masked self-attention, a combination attention module, and a position feedforward sub-layer. Similarly to the encoder, we used a residual connection around each sub-layer and then performed layer normalization. We added the position information of the word to the features of the word and used the result of addition and the encoder’s output features as the input to the decoder.
The output of the previous decoding layer is utilized to predict the next word by a linear layer with an output dimension equal to the vocabulary size.
3.3. Training Details
Following the standard practice of image captioning [28,29,30], we utilized the word-level cross-entropy loss (XE) to pre-train our model and used reinforcement learning to fine-tune sequence generation. In the pre-training process, given the ground truth sequence and the prediction of the captioning model with parameter , the following cross-entropy loss function was minimized.
In the fine-tuning stage, we employed a self-critical sequence training method on sequences sampled using beam search. For decoding, we drew the top words from the decoder’s probability distribution at each time step and always kept the one with the highest probability. The top sequences and final gradients for a sample can be computed in the following ways:
where is the th sentence in the beam, and can be the score of any evaluation metric; we use the score of CIDEr-D as the reward. is the baseline. It is calculated as the average of the rewards obtained by the sampling sequence. At the prediction phase, we performed decoding again using beam search and kept the sequence with the highest predicted probability in the last beam.
4. Experiments
4.1. Dataset and Implementation Details
Our experiments were all conducted on the MSCOCO [31] dataset, which contains 123,287 images, including 82,783 training images, 40,504 validation images, and 40,775 test images. Each image is equipped with five ground truth sentences. We reported the results of the offline evaluation on the “Karpathy” test split [32] and the results of the online evaluation on the MSCOCO test server.
We trained our model in end-to-end fashion with the encoder initialized by a pre-trained ViT model. The input image was resized to a resolution of , the encoder contained 12 layers, and the decoder contained 4 layers. The feature size is 768, and after each attention and feedforward layer, we used a dropout with a probability of 0.9. We fine-tuned the model using self-critical training [30] for 10 epochs with an initial learning rate of 0.01, decaying to after the last 2 epochs. During CIDEr-D optimization, we used a fixed learning rate of . We used the Adam optimizer with a batch size of 32. Using beam search, the beam size was 3.
We used BLEU [33], METEOR [34], ROUGE-L [35], and CIDEr [36] to evaluate our model.
4.2. Performance Comparison
We compared the performance of CAT with SCST [30], LSTM-A [9], Up-Down [28], RFNet [37], GCN-LSTM [38], SGAE [39], and ETA [40]. All the methods mentioned use the image features of CNN or an object detector as input, while our model takes the original image directly as input. Table 1 shows the performance comparison results in the online MSCOCO test server, where CAT improves CIDEr by 0.2% over the current state-of-the-art method, achieving a CIDEr score of 127.6. The evaluation results in the offline “Karpathy” test split shown in Figure 7, which also demonstrates the validity of our CAT model.

Table 1.
Performance comparison on the MSCOCO online test server. All values are reported as percentages (%). All models were fine-tuned by self-critical training.
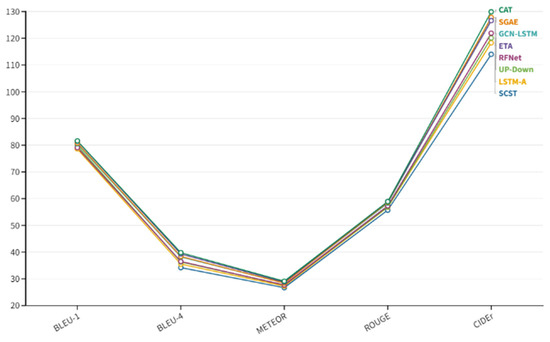
Figure 7.
Performance comparisons on the “Karpathy“ test split. All values are reported as percentages (%). All models are fine-tuned with self-critical training.
4.3. Ablation Study
To verify the effectiveness of CAT, we conducted ablation studies from the following aspects.
Firstly, we investigated the effects of different resolutions of the input image on the output image’s description statements. We found that increasing the resolution of the incoming image from to while keeping the patch size at 16 resulted in a large performance improvement (from 110.3 CIDEr score to 116.6 CIDEr score). We attributed this to the fact that the increase in input resolution allows the length of the patch sequence to increas from 196 to 576, thus allowing more specific delineations of the image and providing more features. Then, we investigated the effects of the number of encoding layers and the number of decoding layers on the output’s description statements. The results are shown in Table 2. When the number of layers gradually increased from 2 to 4, the performance also increases gradually. When the number of layers continued to increase, performance degrades. This may be due to the problems of gradient instability, network degradation, and reduced learning ability at certain shallow layers brought about by the increase in the number of layers. Therefore, we kept the number of encoding layers and decoding layers at four for all subsequent experiments. After that, we investigated the effect of our proposed combination attention module on the output’s description statements. We chose the traditional Transformer as the baseline, we then extended the baseline model by adopting the combination attention module, and the performance also significantly improved (from 126.1 CIDEr score to 128.7 CIDEr score).
Table 2.
Effect of the ablation on the number of coding and decoding layers. All values are reported as percentages (%).
4.4. Attention Visualization
To better evaluate the effectiveness of our proposed method qualitatively, we visualized the process of generating image captions by the CAT model in Figure 8. The results in Figure 7 show that, at shallow layers, the model mainly focuses on the background. In the middle layers, the model tends to focus on the main object or the “man” in the image. The last layer fully utilizes the global background and focuses on all objects in the image that need attention, namely “man”, “wave”, and “surfboard”. In addition, our method can help the model to focus on the target region that requires extraction in order to generate the correct word through the keyword attention mechanism.

Figure 8.
Visualization of the attentional weights. We outlined the image regions with the largest output attributes in white. “A man riding a wave on top of a surfboard” is the caption generated via CAT.
5. Conclusions
In this paper, we proposed a combination attention module and embedded it into the Transformer architecture to build CAT. CAT solves the traditional image caption method’s problem of neglecting global background information and keyword information of the image, and this neglect leads to less accurate and rich generated description statements. Our proposed combination attention module consists of a visual attention module and a keyword attention module. The visual attention module can help with the fast extraction of key local features and capture the global representation within and between layers of image features to provide more comprehensive key feature information. The keyword attention module captures keywords that may appear in the generated sentences, and the results produced by the two modules can be mutually corrected to generate longer, more accurate, and richer caption sentences. The evaluations on the MSCOCO dataset demonstrated the superiority of our method.
Author Contributions
Conceptualization, J.L.; writing—original draft, K.C.; writing—review and editing, H.J.; methodology, Z.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported by National Natural Science Foundation of China. No. 62071145.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Karpathy, A. Connecting Images and Natural Language. Ph.D. Dissertation, Stanford University, Stanford, CA, USA, 2016. [Google Scholar]
- Reichert, D.P.; Series, P.; Storkey, A.J. A hierarchical generative model of recurrent object-based attention in the visual cortex. In Proceedings of the International Conference on Artifical Neural Networks, Berlin, Heidelberg, Germany, 14–17 June 2011; pp. 18–25. [Google Scholar]
- Karpathy, A.; Fei, L. Deep visual-semantic alignments for generating image descriptions. IEEE Trans Pattern Anal. Mach. Intell. 2017, 39, 664–676. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kiros, R.; Salakhutdinov, R.; Zemel, R. Multimodal neural language models. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Kuznetsova, P.; Ordonez, V.; Berg, A.C.; Berg, T.; Choi, Y. Collective generation of natural image descriptions. In Proceedings of the Meeting of the Association for Computational Linguistics: Long Papers, Jeju Island, Korea, 8–14 July 2012. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Yang, H.; Bartz, C.; Meinel, C. Image captioning with deep bidirectional LSTMs. In Proceedings of the ACM on Multimedia Conference, Amsterdam, The Netherlands, 15–19 October 2016. [Google Scholar]
- Tan, Y.H.; Chan, C.S. phi-LSTM:A phrase-based hierarchical LSTM model for image captioning. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 21–23 November 2016. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Qiu, Z.; Mei, T. Boosting image captioning with attributes. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cornia, M.; Stefanini, M.; Baraldi, L.; Cucchiara, L. Meshed-memory transformer for image captioning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, DC, USA, 14–19 June 2020. [Google Scholar]
- Chen, S.; Jin, Q.; Wang, P.; Wu, Q. Say as you wish: Fine-grained control of image caption generation with abstract scene graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, DC, USA, 14–19 June 2020. [Google Scholar]
- Huang, L.; Wang, W.; Chen, J.; Wei, X. Attention on attention for image captioning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Zhou, Y.; Wang, M.; Liu, D.; Hu, Z.; Zhang, H. More grounded image captioning by distilling image-text matching model. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, DC, USA, 14–19 June 2020. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6 July 2015; pp. 2048–2057. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 4 June 2019; pp. 4171–4186. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 5–12 December 2020. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Zhou, L.; Zhou, Y.; Corso, J.J.; Socher, R.; Xiong, C. End-to-end dense video captioning with masked transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8739–8748. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Ji, J.; Luo, Y.; Sun, X.; Chen, F.; Luo, G.; Wu, Y.; Gao, Y.; Ji, R. Improving Image Captioning by Leveraging Intra- and Inter-layer Global Representation in Transformer Network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Shi, X.; Hu, H.; Che, W.; Sun, Z.; Liu, T.; Huang, J. Understanding Medical Conversations with Scattered Keyword Attention and Weak Supervision from Responses. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Liu, W.; Chen, S.; Guo, L.; Zhu, X.; Liu, J. CPTR: Full Transformer Network for Image Captioning. arXiv 2021, arXiv:2101.10804. Available online: https://arxiv.org/abs/2101.10804 (accessed on 28 January 2021).
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ranzato, M.; Chopra, S.; Auli, M.; Zaremba, W. Sequence level training with recurrent neural networks. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Rennie, S.J.; Marcheret, E.; Mroueh, Y.; Ross, J.; Goel, V. Self-critical sequence training for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 21–26 July 2017. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the Association for Computational Linguistics, Ann Arbor, MI, USA, 25–30 June 2005. [Google Scholar]
- Lin, C.-Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics, Barcelona, Spain, 25 July 2004. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Jiang, W.; Ma, L.; Jiang, Y.; Liu, W.; Zhang, T. Recurrent Fusion Network for Image Captioning. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Exploring visual relationship for image captioning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 684–699. [Google Scholar]
- Yang, X.; Tang, K.; Zhang, H.; Cai, J. Auto-Encoding Scene Graphs for Image Captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Los Angeles, CA, USA, 15–20 June 2019. [Google Scholar]
- Li, G.; Zhu, L.; Liu, P.; Yang, Y. Entangled transformer for image captioning. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8928–8937. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).