Abstract
This paper studies the plan recognition problem of multi-agent systems with temporal logic tasks. The high-level temporal tasks are represented as linear temporal logic (LTL). We present a probabilistic plan recognition algorithm to predict the future goals and identify the temporal logic tasks of the agent based on the observations of their states and actions. We subsequently build a plan library composed of Nondeterministic Bchi Automation to model the temporal logic tasks. We also propose a Boolean matrix generation algorithm to map the plan library to multi-agent trajectories and a task recognition algorithm to parse the Boolean matrix. Then, the probability calculation formula is proposed to calculate the posterior goal probability distribution, and the cold start situation of the plan recognition is solved using the Bayes formula. Finally, we validate the proposed algorithm via extensive comparative simulations.
1. Introduction
Mulit-agent plan recognition (MAPR) is the problem of predicting the goal or recognizing the task of multi-agent systems based on observations of their states and actions [1,2]. This paper considers the multi-agent plan recognition problem concerning attack and defense tasks in real-time strategy (RTS) games [3]. In RTS games, the opponents’ tasks possess certain temporal logic properties, e.g., an enemy can only attack the base after the bunker is destroyed. In order to improve the dynamic adaptability of the RTS game’s intelligence, it is necessary to predict the future goal and identify the opponent’s current task under temporal logic constraints.
A wide range of works have tackled the MAPR problem based on a plan library, including the Bayesian model [4,5,6,7], hidden Markov algorithms [8,9], specialized procedures [10], and parsing algorithms [11,12]. They all required a suitable plan library or a set of rules to establish their model. Banerjee et al. [2] proposed the formulation of the MAPR problem, proving it to be NP-complete. The plan library was modeled by a matrix, and Knuth’s Algorithm X was used to build their model. Based on the Abstract Hidden Markov Model, Saria et al. [13] provided an MAPR model consisting of a hierarchical dynamic Bayes network, which required a lot of manual drawing in advance. Synnaeve et al. [4,5] proposed a simple Bayesian model for predicting the goal of the opponent and used machine learning algorithms to calculate the parameters of the model by replaying the data multiple times. The proposed Bayesian model’s prediction accuracy is closely related to the size of the dataset, which is hard to obtain for confrontation scenarios such as wars.
Other researchers have tackled the MAPR problem based on domain theories. Ramirez et al. [14,15] used LPG-d and top-k planners to transform the plan recognition problem into a planning problem and calculated the posterior probability distribution of goals with an action cost. Sohrabi et al. [16] proposed the relaxation of the plan-recognition-as-planning formulation and compared the planned trajectory with a wide range of high-quality plans. Zhuo et al. [17] constructed the domain using an action model and solved soft (likelihood of various activities) and hard (observed or causal) constraints based on the MAX-SAT. Nevertheless, these algorithms cannot solve the plan recognition problem under temporal logic tasks due to the lack of a plan library.
To perform collaborative tasks in a multi-agent system, the dynamic team structures of the system need to be identified with an MAPR solution. In the simplest case, when all the agents in the multi-agent system perform the same task, the MAPR can be treated as a single agent plan recognition problem by matching the observations to the plan library [18]. However, this condition is rarely met in realistic applications since all the agents of a multi-agent system may dynamically join or leave their current team during the entire operation period. Kaminka et al. [19] identified the team structures and plans by considering the static social structures (such as YOYO). Zilberbrand et al. [20] built the plan library for a single agent instead of multiple agents and identified the dynamic team structures, assuming that agents in a team performed the same task.
Hence, we propose a probabilistic plan recognition algorithm while considering the complexity and temporal logic constraints of actual tasks. Different from [19,20], in order to deal with the fact that multiple ways of completing the same task exist when multiple agents cooperate, we solve the plan recognition problem using the probabilistic notion. Different from the algorithms in [14,15], we establish a plan library based on the theory of LTL in order to model the temporal logic tasks. Compared with [2], our model is more adaptable to complex multi-agent tasks [21].
The main contributions of this paper are as follows:
- For task recognition, we propose an algorithm to map the planning library and the planned multi-agent trajectories into a Boolean matrix. The complexity of the matrix is reduced by introducing the automata graph model. We optimize the calculation of the task completion degree and identify the multi-agent organization structure dynamics by analyzing the Boolean matrix.
- For goal prediction, we propose a probability calculation algorithm based on the Bayesian formula, considering information such as task constraints, agent trajectories, and potential collaborative relationships. Combined with the Bayesian inference theory, the probability calculation algorithm overcomes the problem of multi-agent plan recognition under cold start conditions.
The remainder of the paper is structured as follows. We introduce the linear temporal logic and workspace model and present the definition of the multi-agent plan recognition problem in Section 2. A multi-agent probabilistic plan recognition algorithm is proposed to solve the plan recognition problem in Section 3. We provide the comparative simulation to illustrate the effectiveness of the algorithm and analyze the advantages of the proposed algorithm in Section 4. Finally, we conclude the paper in Section 5.
2. Preliminaries and Problem Formulation
2.1. Linear Temporal Logic
Linear temporal logic (LTL) [22,23,24] provides a concise and formal way of defining propositions and temporal constraints for the robot task, which consists of atomic propositions (APs), boolean operators, and temporal operators. LTL formulas can be formed based on the following syntax definition:
where , , , and are boolean operators, while , U (until), , and are temporal operators. The Boolean operators are used to denote negation, disjunction, and conjunction, respectively. U is the Until operator, and indicates that is true until becomes true. and represent Eventually and Always, respectively. These operators are called future operators. An LTL formula can be transformed into a corresponding Nondeterministic Bchi Automation (NBA) [25]:
Definition 1.
(NBA): The NBA over is a tuple , where Q is the finite set of states, indicates the alphabet, indicates the transition relation, is the set of initial states, and is the set of accepting states.
We define the accepting run of the NBA as an infinite sequence that follows the transition relation from the initial state, i.e., , where , , and , while denotes the set of states that infinitely appear in r.
2.2. Workspace Model
The workspace can be represented by a weighted Finite Transition System (FTS), defined as follows.
Definition 2.
(FTS) [25]: An FTS is a tuple , where is the set of workspace regions that have a special sign. is the transition relation, is the set of APs, is the labeling function, i.e., the AP that the region has, and is the weighted function, i.e., the transition cost of .
In order to model the robot motion and task, we compose Definitions 1 and 2 to the weighted product Bchi automation (PBA), defined as follows.
Definition 3.
(PBA) [25]: A PBA is a tuple , , while . is the set of initial states. if and . is the set of accepting states. is the weighted function, and .
2.3. Problem Formulation
Considering the defense problem in an RTS game, it is necessary to give a goal prediction and identify the enemy’s intention by analyzing the states of the enemy units. However, due to the non-cooperation of the enemy units, we cannot know the enemy’s attack goals and current task. The enemy plan has a temporal logic property, e.g., , indicating that the base cannot be attacked until the bunker has been destroyed. The MAPR problem under temporal logic tasks can be defined as follows.
Definition 4.
The MAPR problem under temporal logic tasks: The multi-agent system consists of n agents, while the plan library contains tasks that may be performed by the multi-agent system and specified in the form of Formula (1). According to the observed multi-agent trajectory, , where indicates the action executed by in time i. The MAPR needs to predict the future goals and identify the current execution tasks of each agent.
In this paper, three key sub-problems need to be considered to solve the above problem.
- Problem 1: Description of multi-agent collaborative tasks. We consider the situation where multiple agents cooperate to complete the same task, so there are multiple ways of completing the same task. For the modeling and description of each task, it is necessary to consider the cooperation among multiple agents. Furthermore, the increase in the number of agents creates difficulties for the task description.
- Problem 2: Matching of multi-agent action sequences and the plan library. We consider the multi-agent system with deceptive behaviors, where the agent will interrupt the current task to perform others and then return to the execution of the unfinished task. Therefore, it is difficult to judge whether the agent abandons the current task and reasonably sets the current task abandonment threshold.
- Problem 3: Calculation of goal prediction probability for multiple agents. We extend Ramirez and Geffner’s [14] Plan Recognition as Planning (PRAP) approach to temporal logic tasks. Therefore, it is necessary to consider the temporal logic task cost calculation caused by multi-agent cooperation. Moreover, in the case of cold start, where the trajectory matrix M is empty, how to identify the task currently being performed by the agent and give the target probability is a difficult point.
3. Probabilistic Plan Recognition Algorithm
Based on Definition 4, we divide the planning recognition into two parts: task identification and goal prediction. The task recognition algorithm aims to identify two categories of tasks: task completed and task in progress. Based on the task recognition results, we calculate the goal probability while considering the temporal logic constraints, the trajectory, and the potential team setup. In particular, we tackle the problem of plan recognition in the cold start situation. Before that, we need to establish an appropriate model for the description of collaborative tasks.
3.1. Automata-Based Model
Generally, we can describe the tasks in the planning library as a matrix by artificial coding. However, this is only adapted to the scenario of simple tasks where one task consists of only a few actions. For complex temporal tasks, artificial coding is time-consuming and error-prone. Therefore, the automata-based model is introduced to describe the tasks [26,27].
The conversion relationship in automaton is composed of specific actions, which can be a single action or a combination of actions. Therefore, the automata-based model can represent the cooperative execution of tasks by multi-agents. The conversion relationship of a single action requires a single agent to be completed, and the conversion relationship of a combined action requires a corresponding number of multi-agents to be completed collaboratively. Automata is modeled for tasks, and the conversion relationship has a non-directivity relative to multi-agent systems, that is, the actions corresponding to each edge can be executed by different agents. Therefore, for complex temporal logic tasks with multiple priorities, the temporal logic language is used for task description, and the planning library P is composed of corresponding automaton models.
Since it is acceptable for machines and readable for humans, we use LTL to describe temporal logic tasks [28]. According to the preliminaries, LTL formulas can be transformed into a corresponding Nondeterministic Bchi Automation (NBA). Therefore, we use the NBA to model the task in plan library P, called . As a formal language, LTL is sound and complete. Similarly, NBA inherits these properties. The action sequence corresponding to any path from the initial state to the acceptable state is correct for the task, and the model contains all possible action sequences to complete the task.
3.2. Task Recognition for Temporal Logic Tasks
After modeling the collaborative tasks in the plan library, we map the plan library P to the trajectory M and obtain a boolean matrix E, which contains task execution information and multi-agent behavior information. The boolean matrix E contains columns, where n is the number of agents and T is the time period. For task , the corresponding row in the boolean matrix can be defined as follows:
where means the agent is executing task at time t.
Since the NBA is a graph model, the trajectory matrix M can be put into the graph model and compared with the transition relation to determine whether it is consistent with the task. The Boolean matrix generation algorithm is shown in Algorithm 1. First, extract the sub-matrix according to the starting time (steps 2–4). Then, combine the agent actions and extract the parts that are completely equal to the transition relation of (steps 6–11). Finally, form the Boolean matrix according to Formula (2) (step 15–21). It should be noted that represents the transition relation required from the to in the NBA . The time complexity of the algorithm is , where represents the number of states of the NBA.
| Algorithm 1 Boolean matrix generation algorithm | |
| Input: The trajectory M, Plan library P, Number of agents n, Time period T | |
| Output: Boolean matrix E | |
| 1: | |
| 2: | for each NBA do |
| 3: | for do |
| 4: | |
| 5: | |
| 6: | = the initial state of the NBA |
| 7: | for do |
| 8: | for do |
| 9: | if then |
| 10: | |
| 11: | break |
| 12: | if then |
| 13: | Calculate the completion degree and the last state in the NBA of N, and add S. |
| 14: | Sort the elements in the set S in descending order according to the completion degree. |
| 15: | fordo |
| 16: | |
| 17: | Parse the agent number i, start time , and last time from N. |
| 18: | for do |
| 19: | |
| 20: | |
| 21: | , where I is the identity matrix. |
| 22: | return E |
The state in the NBA indicates the progress of the task. The task completion degree of state q can be measured as follows:
where represents the number of actions to be performed from the initial state to the acceptable state F. The completion degree increases as the remaining actions decrease .
Due to different task progress states, the focus of the task recognition algorithm is different. For completed tasks, the completion degree is 1, and there is no subsequent execution cost. The focus is to find the unique explanation as much as possible. For the task in progress with possible subsequent execution, it is necessary to consider the task completion degree and the subsequent execution cost.
(1) Task completed
We use Knuth’s Algorithm X to solve the completed task recognition problem. Algorithm X finds a set of rows of E, such that for every column of E, there is exactly one row that contains 1. The details are shown in Algorithm 2. The result represents the position of the selected rows in the initial Boolean matrix E, indicating that the corresponding task is completed. For instance, if , it means that task is completed.
| Algorithm 2 Task recognition based on Algorithm X |
|
(2) Task in progress
Once the task completion degree has been obtained by the Boolean matrix generation algorithm, the cost of the subsequent task execution can be calculated with the use of the following procedure.
- Step 1: According to Definition 3, for every task in the plan library, construct a PBA, called .
- Step 2: In every , we use Dijkstra’s algorithm to calculate the minimum cost of each state to accept state , called . Step 1 and 2 can be calculated off-line without the requirement for trajectory.
- Step 3: According to the Boolean matrix E, the set of tasks that the agent i may perform at time t can be defined as and , where indicates the current state in the NBA .
In the case of multi-agent cooperative task execution, the number of agents performing task at time t is called ,
Details of the subsequent task cost calculation is shown in Algorithm 3.
| Algorithm 3 The subsequent task cost calculation |
|
The most probable task is determined by considering the task completion degree and the subsequent execution cost of the task in progress. The probability of the task increases with a higher task completion degree and a lower subsequent execution cost. The task to be executed by agent i at time t is formulated as follows:
3.3. Goal Prediction with Multi-Agent Cooperation
At the current time t, according to the task recognition algorithm, the task performed by the agent i is , the current state of the corresponding NBA is , and the task completion degree is . If , the next state of the agent i is divided into two cases: the agent i continues to execute the task , recorded as the event , or interrupts the task to perform other tasks, recorded as event .
On the trajectory defined as M, the goal prediction conditional probability is calculated as follows:
where , , , and represents the probability of selecting under the task . In the case of a multi-agent collaboration scenario:
where , and represents the possibility of selecting the action set in the case of task :
where is the cost of the multi-agent cooperative executing the action set with agent i and can be defined according to steps 1–4 of Algorithm 3 as:
indicates the probability of selecting in the action set of agent i.
where is the cosine of the angle between agent i and , while is the distance between agent i and , and is a constant.
measures the possibility that agent i interrupts task . The goal prediction algorithm is an online real-time prediction, while the task recognition results of the current moment t are the same as the previous moment most of the time. Consequently, we can infer by comparing and :
where is a tuning parameter for the effect of cost on the possibility to interrupt task , and the initial value of needs to be set manually. It can be seen that if the cost of executing task increases at the current time t as compared to the previous time , the possibility of continuing the execution of task decreases.
represents the target prediction probability when agents interrupt task to perform other tasks:
where is shown in Formula (7), represents the possibility of choosing another task and is defined as follows:
where the task execution cost is calculated according to Algorithm 3.
In summary, the framework of the multi-agent plan recognition algorithm under a temporal logic task is shown in Figure 1.
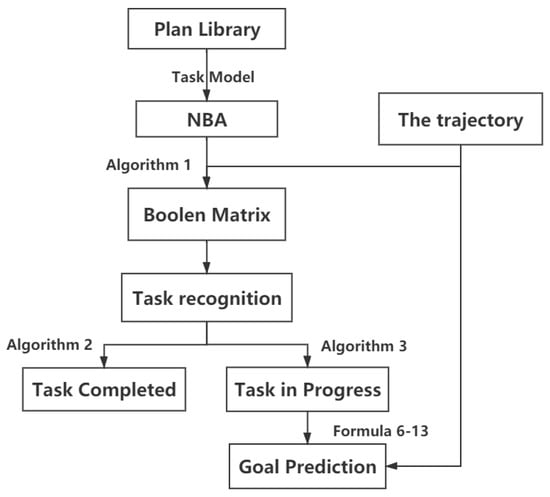
Figure 1.
Multi-agent plan recognition framework.
3.4. Cold Start
In the situation of cold start, where the trajectory and the task recognition result cannot be obtained through the Boolean matrix E, the goal probability calculation formula is as follows:
Based on the Bayesian formula [29,30], it can be inferred that the probability of the agent i is the following:
where , , and is calculated by Formula (7).
4. Simulations and Analysis
In order to verify the effectiveness of the proposed algorithm in task recognition and target prediction, we designed a comparative simulation for multi-agent plan recognition. The environment in the simulation is a two-dimensional continuous system. Furthermore, the agent is considered as a particle with a fixed velocity. In order to accurately describe the moving trajectory of a multi-agent system and consider the increase in computation caused by the number of agents, we abstract the workspace as an FTS, which we defined earlier.
4.1. Scene Introduction
The scene is defined as a defensive game in which the planes need to cooperate with each other to destroy all buildings, while the tanks need to defend the buildings. As shown in Figure 2, red planes are used as the attackers and are controlled by a human operator with a keyboard. The tanks, representing the defensive side, are controlled by an artificial intelligence module composed of the proposed plan recognition algorithm. The yellow circles, blue rectangles, and red diamonds represent buildings of different security levels. For the defensive tanks, their objectives are to identify the attacking plane’s task, to predict their future goal in advance, to reach the corresponding building in time, and to resist the plane.
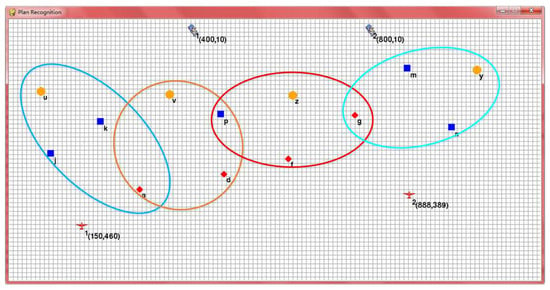
Figure 2.
Simulation scene where the red planes (the attackers controlled by a human operator) go against the tanks controlled by our proposed algorithm.
According to the rules of the game, the building can be attacked if the previous-level buildings are destroyed. Therefore, the planes have the following attack strategies, as described by LTL formulas:
These formulas represent the standard order for the attacking planes to destroy the targeted buildings. Taking as an example, this means attacking a first, then attacking , and finally, destroying u. Other formulas have similar meanings.
4.2. Simulation Verification and Analysis
The simulation is configured to include three attacking planes controlled by humans to verify the accuracy of the plan recognition algorithm. The trajectories of the multi-agent system are shown in Figure 3, which are represented by the red, blue, and green lines. The goal prediction probability curves of the algorithm designed in this paper are shown in Figure 4a, Figure 5a and Figure 6a, while the task recognition probability curves are shown in Figure 7. The parameters of the algorithm are set as and . As a comparison, the curves of the algorithm proposed by Ramirez and Geffner are shown in Figure 4b, Figure 5b and Figure 6b.
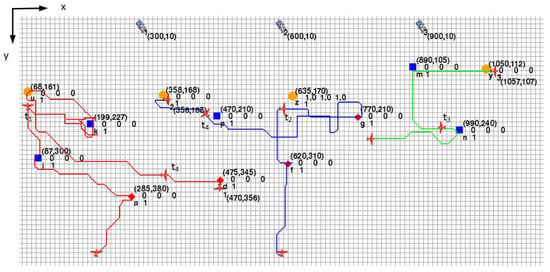
Figure 3.
Simulation scene with the trajectories of planes represented by different colored lines.
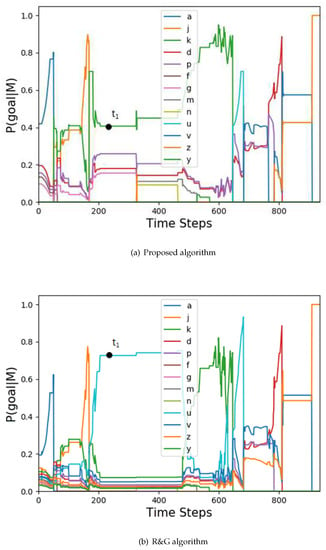
Figure 4.
The goal probability curves of agent 1.
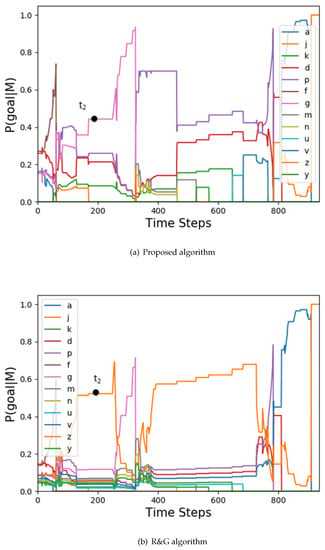
Figure 5.
The goal probability curves of agent 2.
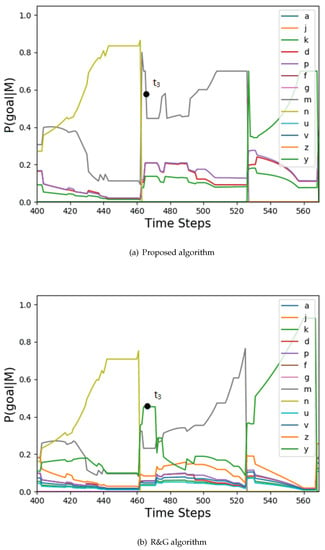
Figure 6.
The goal probability curves of agent 3.
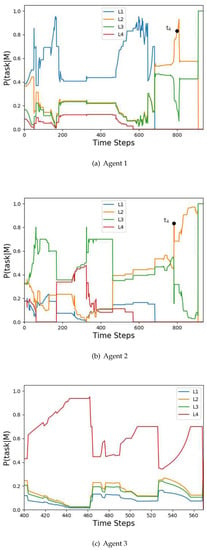
Figure 7.
Task probability curves, where represents the probability of performing task for .
The actual goals of the three agents are: , , . The corresponding arrival times are: , , . The actual tasks of the three agents are: , , . It can be seen that agent 1 and agent 2 cooperatively execute task , and agent 2 and agent 3 cooperatively execute task . The simulation was run 4000 times, and the goal prediction accuracy of the proposed algorithm and the R&G algorithm are shown in Table 1. The task recognition accuracy of the proposed algorithm for the three agents are: 99.88%, 85.01%, and 100%.

Table 1.
Goal prediction accuracy (%).
In terms of goal prediction, it can be seen that the proposed algorithm has a higher accuracy. Because the constraint of temporal logic is considered in the proposed algorithm, the candidate set of actions can be filtered well; for example, time as shown in Figure 3. Although agent 1 is closer to u, according to Formula (8), the action candidate set is . Moreover, we can get the prediction goal k based on Formula (6). The same situation follows for agent 2 with and agent 3 with .
In terms of task recognition, first, the proposed algorithm can determine whether the agent has abandoned the current task. For example, agent 2 shows a trend that moves away from the current task in and performs a new task . Second, the proposed algorithm can predict new tasks after the current task is completed. For example, for agent 1 at , after completing the task , according to Formula (15), the future task is . Third, the proposed algorithm can identify the organization structure of a multi-agent system. For example, agent 1 and agent 2 are cooperating in task at .
In order to verify the effectiveness and real-time performance of the algorithm, we designed 10 comparative experiments using different numbers of agents. The test result is shown in Table 2, where the MAPR indicates the proposed algorithm, RT is the run time, GA represents the goal prediction accuracy, and TA is the task recognition accuracy. The experiment results show that the proposed algorithm has a higher goal prediction accuracy than traditional algorithms for the MAPR problem under temporal logic tasks and completes task recognition with a higher quality. The algorithm run time is linearly related to the number of agents and meet the real-time requirement.
Table 2.
Comparative simulation results (%).
5. Conclusions
We have proposed a multi-agent probabilistic plan recognition algorithm under temporal logic tasks for goal prediction and task identification in a confrontational multi-agent system, in which the opponents could behave confusingly in order to prevent being identified. The task in the plan library has been modeled as Nondeterministic Bchi Automation, and the trajectory of the multi-agent has been transformed into a Boolean matrix. Then, a task recognition algorithm has been proposed to parse the Boolean matrix. In particular, the cold start situation has been solved based on the Bayes formula. The algorithm has been verified in extensive comparative simulations, showing that the proposed algorithm can predict the next goal and identify the task of the multi-agent system effectively and accurately. This paper is based on simulation, but the proposed algorithm has more real-world application scenarios. The algorithm provides ideas not only for adversarial game scenarios, but also for other multi-agent scenarios involving complex temporal logic tasks such as goal recognition in smart home environments[31,32]. In the future, we will apply the algorithm to plan recognition in realistic real-time strategy games.
Author Contributions
Conceptualization, W.Y. and S.L.; methodology, W.Y., S.L. and D.T.; software, W.Y. and S.L.; validation, W.Y.; formal analysis, W.Y. and D.T.; investigation, W.Y., S.L. and D.T.; resources, W.Y.; data curation, W.Y.; writing—original draft preparation, W.Y.; writing—review and editing, W.Y., S.L. and J.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the National Natural Science Foundation of China (61573062, 61621063, 61673058), the Projects of Major International (Regional) Joint Research Program NSFC (61720106011), the Beijing Advanced Innovation Center for Intelligent Robots and Systems (Beijing Institute of Technology), and the Key Laboratory of Biomimetic Robots and Systems (Beijing Institute of Technology), Ministry of Education.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Yang, Q. Activity Recognition: Linking low-level sensors to high-level intelligence. In Proceedings of the IEEE International Joint Conference on Artificial Intelligence, Pasadena, CA, USA, 11–17 July 2009; pp. 20–26. [Google Scholar]
- Bikramjit, B.; Landon, K.; Jeremy, L. Multi-agent plan recognition: Formalization and algorithms. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010. [Google Scholar]
- Ontanon, S.; Synnaeve, G.; Uriarte, A.; Richoux, F.; Churchill, D.; Preuss, M. A Survey of Real-Time Strategy Game AI Research and Competition in StarCraft. IEEE Trans. Comput. Intell. Games 2013, 5, 293–311. [Google Scholar] [CrossRef] [Green Version]
- Synnaeve, G.; Bessiere, P. A bayesian model for plan recognition in RTS games applied to starcraft. In Proceedings of the 7th AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, Stanford, CA, USA, 10–14 October 2011; Volume 33, pp. 79–84. [Google Scholar]
- Synnaeve, G.; Bessiere, P. A Bayesian model for RTS units control applied to StarCraft. In Proceedings of the IEEE Conference on Computational Intelligence and AI in Games, Seoul, Korea, 31 August–3 September 2011; pp. 190–196. [Google Scholar]
- Bui, H.H. A general model for online probabilistic plan recognition. In Proceedings of the IEEE International Joint Conference on Artificial Intelligence, Acapulco, Mexico, 9–15 August 2003; pp. 1309–1318. [Google Scholar]
- Liao, L.; Patterson, D.J.; Fox, D.; Kautz, H. Learning and inferring transportation routines. Artif. Intell. 2007, 171, 311–331. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Chen, J.; Fang, H.; Dou, L. A role-based POMDPs approach for decentralized implicit cooperation of multiple agents. In Proceedings of the IEEE International Conference on Control and Automation, Ohrid, North Macedonia, 3–6 July 2017; pp. 496–501. [Google Scholar]
- Ramirez, M.; Geffner, H. Goal recognition over POMDPs: Inferring the intention of a POMDP agent. In Proceedings of the IEEE International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011; pp. 978–983. [Google Scholar]
- Avrahami-Zilberbrand, D.; Kaminka, G.A. Fast and complete symbolic plan recognition. In Proceedings of the IEEE International Joint Conference on Artificial Intelligence, Edinburgh, UK, 30 July–5 August 2005; pp. 653–658. [Google Scholar]
- Geib, C.W.; Goldman, R.P. A probabilistic plan recognition algorithm based on plan tree grammars. Artif. Intell. 2009, 173, 1101–1132. [Google Scholar] [CrossRef] [Green Version]
- Pynadath, D.V.; Wellman, M.P. Generalized queries on probabilistic context-free grammars. Pattern Anal. Mach. Intell. 2002, 20, 65–77. [Google Scholar] [CrossRef] [Green Version]
- Saria, S.; Mahadevan, S. Probabilistic Plan Recognition in Multiagent Systems. In Proceedings of the Fourteenth International Conference on International Conference on Automated Planning and Scheduling, Whistler, Canada, 3–7 June 2004. [Google Scholar]
- Ramirez, M.; Geffner, H. Plan Recognition as Planning. In Proceedings of the IEEE International Joint Conference on Artificial Intelligence, Pasadena, CA, USA, 11–17 July 2009; Volume 38, pp. 1778–1783. [Google Scholar]
- Ramirez, M.; Geffner, H. Probabilistic Plan Recognition Using Off-the-Shelf Classical Planners. In Proceedings of the IEEE National Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010; pp. 1121–1126. [Google Scholar]
- Sohrabi, S.; Riabov, A.V.; Udrea, O. Plan recognition as planning revisited. In Proceedings of the IEEE International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 3258–3264. [Google Scholar]
- Zhuo, H.H.; Yang, Q.; Kambhampati, S. Action-model based multi-agent plan recognition. Adv. Neural Inf. Process. Syst. 2012, 25. Available online: https://proceedings.neurips.cc/paper/2012/file/a597e50502f5ff68e3e25b9114205d4a-Paper.pdf (accessed on 18 February 2022).
- Intille, S.; Bobick, A. A framework for recognizing multi-agent action from visual evidence. In Proceedings of the AAAI Conference on Artificial Intelligence, Orlando, FL, USA, 18–22 July 1999. [Google Scholar]
- Kaminka, G.; Pynadath, D.; Tambe, M. Monitoring teams by overhearing: A multi-agent plan recognition approach. J. Artif. Intell. Res. 2002, 17, 83–135. [Google Scholar] [CrossRef]
- Zilberbrand, A.; Kaminka, G.A. Towards dynamic tracking of multi-agent teams: An initial report. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22–26 July 2007. [Google Scholar]
- Belta, C.; Sadraddini, S. Formal methods for control synthesis: An optimization perspective. Annu. Rev. Control Robot. Auton. Syst. 2019, 2, 115–140. [Google Scholar] [CrossRef]
- Baier, C.; Katoen, J.P. Principles of Model Checking; The MIT Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Filippidis, I.; Dimarogonas, D.V.; Kyriakopoulos, K.J. Decentralized multi-agent control from local LTL specifications. In Proceedings of the IEEE Conference on Decision and Control, Maui, HI, USA, 10–13 December 2012; Volume 23, pp. 6235–6240. [Google Scholar]
- Guo, M.; Dimarogonas, D.V. Distributed plan reconfiguration via knowledge transfer in multi-agent systems under local LTL specifications. In Proceedings of the IEEE International Conference on Robotics and Automation, Hong Kong, China, 31 May–7 June 2014; Volume 46, pp. 4304–4309. [Google Scholar]
- Guo, M.; Dimarogonas, D.V. Multi-agent plan reconfiguration under local LTL specifications. Int. J. Robot. Res. 2015, 34, 218–235. [Google Scholar] [CrossRef]
- Yokotani, M.; Kondo, T.; Takai, S. Abstraction-Based Verification and Synthesis for Prognosis of Discrete Event Systems. Asian J. Control 2016, 18, 1279–1288. [Google Scholar] [CrossRef]
- Masoumi, B.; Meybodi, M.R. Learning automata based multi-agent system algorithms for finding optimal policies in Markov games. Asian J. Control 2012, 14, 137–152. [Google Scholar] [CrossRef]
- Kress-Gazit, H.; Lahijanian, M.; Raman, V. Synthesis for robots: Guarantees and feedback for robot behavior. Annu. Rev. Control Robot. Auton. Syst. 2018, 1, 211–236. [Google Scholar] [CrossRef]
- Wang, Y.; Hussein, I.I. Bayesian-Based Domain Search using Multiple Autonomous Vehicles. Asian J. Control 2014, 16, 20–29. [Google Scholar] [CrossRef]
- Kim, J.; Muise, C.; Shah, A.J.; Agarwal, S.; Shah, J.A. Bayesian inference of linear temporal logic specifications for contrastive explanations. In Proceedings of the International Joint Conferences on Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar] [CrossRef] [Green Version]
- Ding, Y.; Xin, B.; Chen, J. A review of recent advances in coordination between unmanned aerial and ground vehicles. Unmanned Syst. 2021, 9, 97–117. [Google Scholar] [CrossRef]
- Wilken, N.; Stuckenschmidt, H. Combining symbolic and statistical knowledge for goal recognition in smart home environments. In Proceedings of the 2021 IEEE International Conference on Pervasive Computing and Communications Workshops and Other Affiliated Events (PerCom Workshops), Kassel, Germany, 22–26 March 2021; pp. 26–31. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).