
Adversarial Attack and Defense: A Survey


Abstract
:1. Introduction
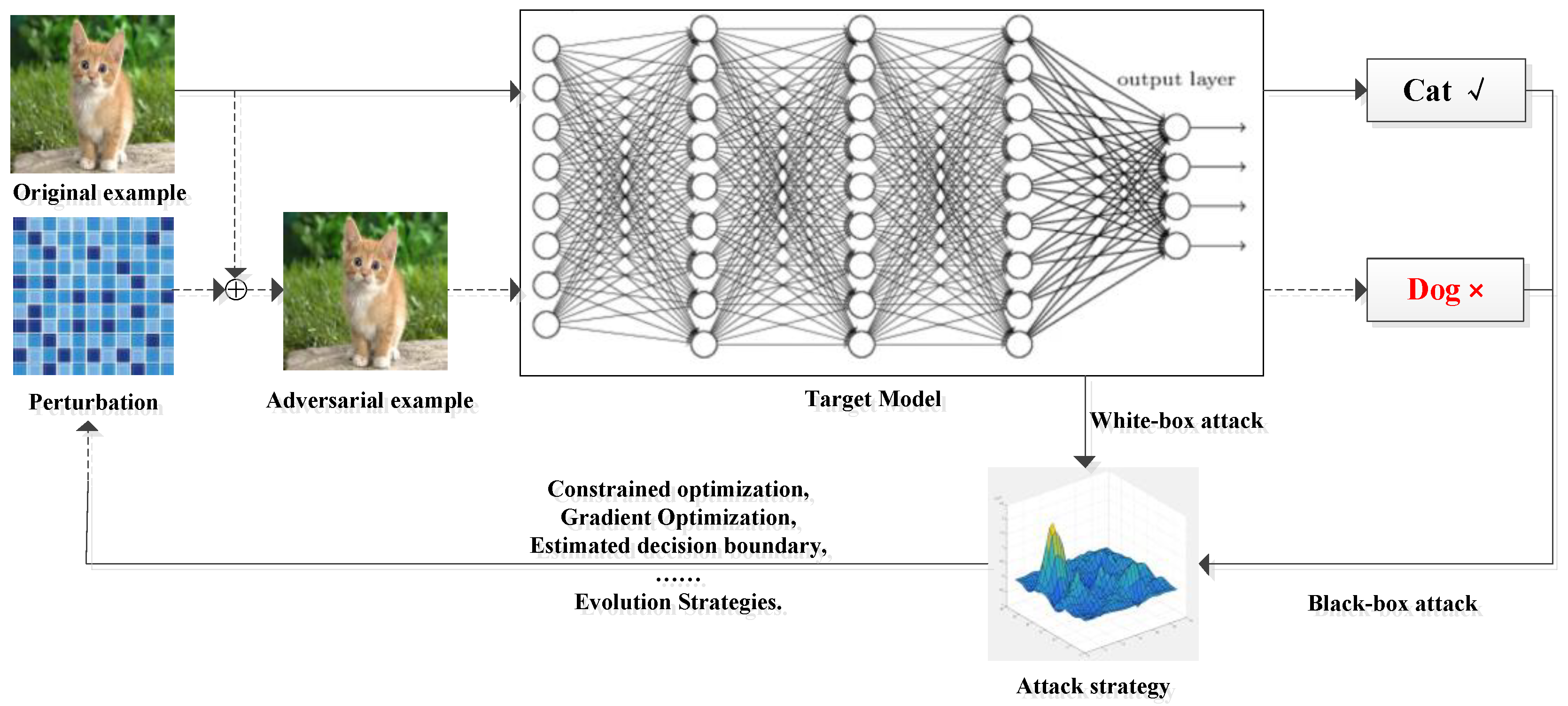
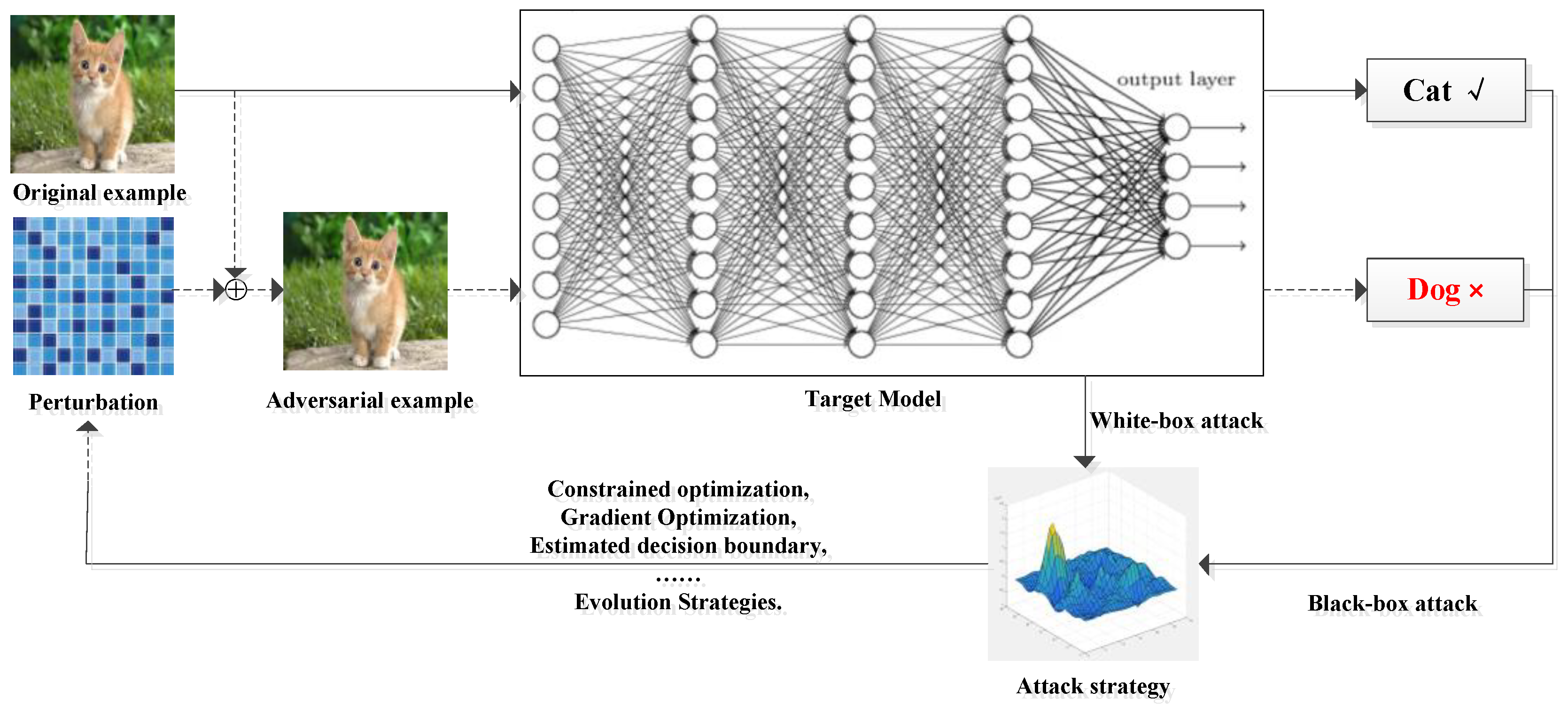
2. Adversarial Attack
2.1. Common Terms
2.2. Adversarial Attacks
2.2.1. L-BFGS
2.2.2. FGSM
2.2.3. JSMA
2.2.4. C&W
2.2.5. One-Pixel
2.2.6. DeepFool
2.2.7. ZOO
2.2.8. UAP
2.2.9. advGAN
2.2.10. ATNs
2.2.11. UPSET and ANGRI
2.2.12. Houdini
2.2.13. BPDA
2.2.14. DaST
2.2.15. GAP++
2.2.16. CG-ES
2.3. Adversarial Attacks Comparison
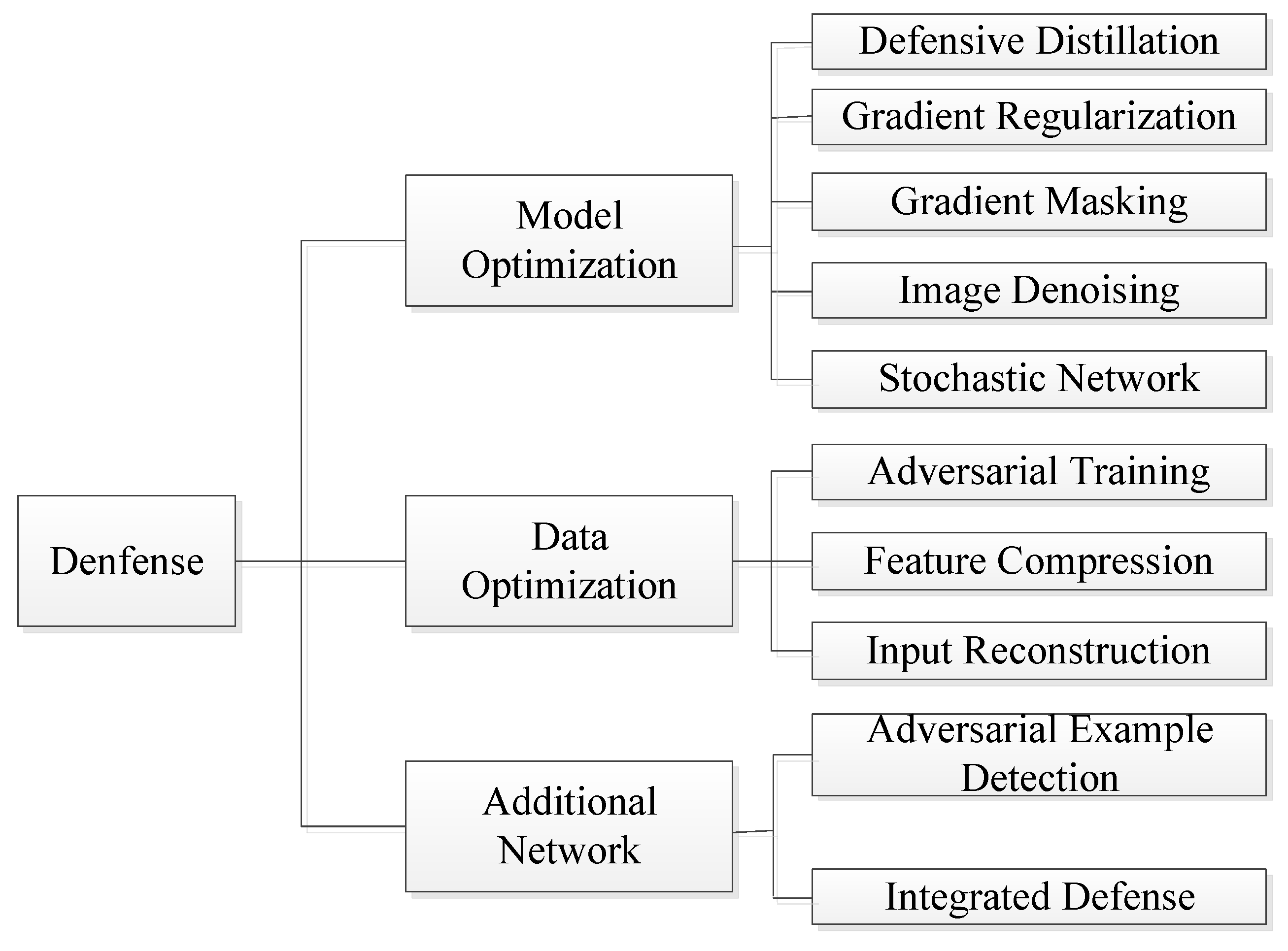
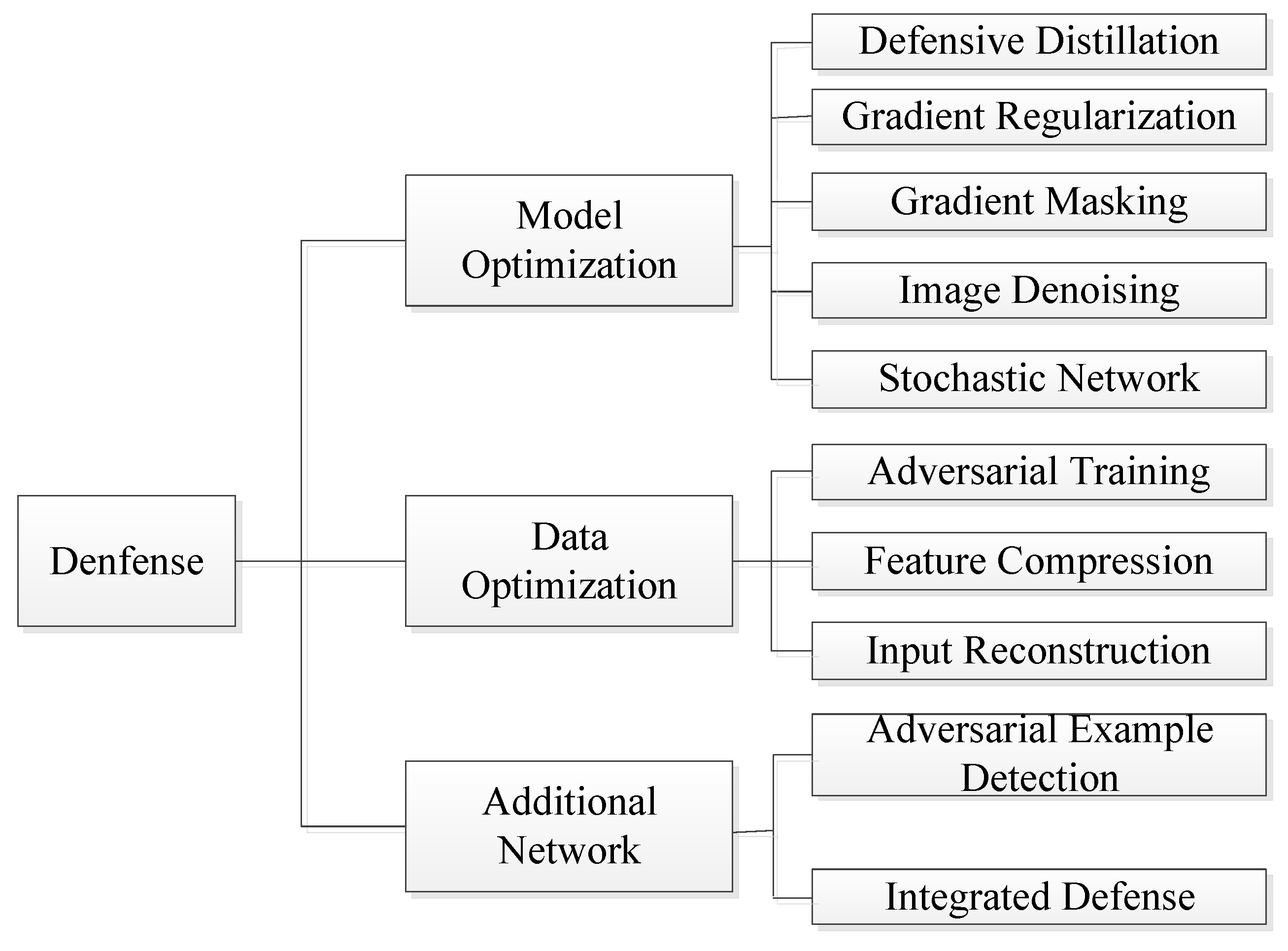
3. Adversarial Example Defense
3.1. Model Optimization
3.1.1. Defensive Distillation
3.1.2. Gradient Regularization
3.1.3. Gradient Masking
3.1.4. Image Denoising
3.1.5. Stochastic Network
3.2. Data Optimization
3.2.1. Adversarial Training
3.2.2. Feature Compression
3.2.3. Input Reconstruction
3.3. Additional Network
3.3.1. Adversarial Example Detection
3.3.2. Integrated Defense
4. Challenge
4.1. Adversarial Attack
- (1)
- Existing adversarial example generation models are all trained on specific datasets, lacking transferability, and need to verify the attack effect in real physical scenarios, such as security systems in smart cities, etc.
- (2)
- The computational complexity of some adversarial example generation techniques is too high. Although a relatively high attack success rate is achieved, it increases the amount of computation, resulting in an excessively large trained model. The adversarial example generation model cannot be transplanted into lightweight devices.
- (3)
- At present, adversarial attack technology is developing rapidly in the field of computer vision, but it is still in its infancy in the fields of NLP and speech recognition. It is necessary to increase the research on attack technology in these fields to provide theoretical and technical support to ensure that AI technology can play a safe and efficient role in the construction of smart city.
4.2. Adversarial Example Defense
- (1)
- For the vulnerability of deep neural networks, the academic community has not come up with a recognized scientific explanation, so it is impossible to fundamentally defend against the attack of adversarial examples;
- (2)
- The applicability and adaptability of adversarial example defense technology needs to be improved. Research has proved that even the defense technology with the best defense effect will be broken by an endless stream of adversarial attack technologies. How to improve the self-iteration capability of defense technology is an urgent problem to be solved.
- (3)
- The current defense technology research lacks the practice in the real world. How to convert the advanced defense theory and technology into the defense method in the physical scene is a major challenge for researchers.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, L.; Xu, C.; Koch, P.; Corso, J.J. Watch What You Just Said: Image Captioning with Text-Conditional Attention. In Proceedings of the Thematic Workshops of ACM Multimedia, New York, NY, USA, 23–27 October 2017; pp. 305–313. [Google Scholar]
- You, Q.; Jin, H.; Wang, Z.; Fang, C.; Luo, J. Image captioning with semantic attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4651–4659. [Google Scholar]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honululu, HI, USA, 21–26 July 2017; pp. 375–383. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.; Jiang, H.; Penn, G. Applying convolutional neural networks concepts to hybrid NN-HMM model for speech recognition. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 27–29 March 2012; IEEE: New York, NY, USA, 2012; pp. 4277–4280. [Google Scholar]
- Kim, S.; Lane, I. Recurrent models for auditory attention in multi-microphone distance speech recognition. arXiv 2015, arXiv:1511.06407. [Google Scholar]
- Han, W.; Zhang, Z.; Zhang, Y.; Yu, J.; Chiu, C.C.; Qin, J.; Wu, Y. ContextNet: Improving Convolutional Neural Networks for Automatic Speech Recognition with Global Context. arXiv 2020, arXiv:2005.03191v3. [Google Scholar] [CrossRef]
- Yu, A.W.; Dohan, D.; Luong, T.; Zhao, R.; Chen, K.; Norouzi, M.; Le, Q.V. QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension. arXiv 2018, arXiv:1804.09541. [Google Scholar]
- Yin, W.; Schütze, H. Task-specific attentive pooling of phrase alignments contributes to sentence matching. arXiv 2017, arXiv:1701.02149. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Las Vegas, NV, USA, 27–30 June 2016; IEEE: New York, NY, USA, 2016; pp. 372–387. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (sp), Honululu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 39–57. [Google Scholar]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef] [Green Version]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Chen, P.Y.; Zhang, H.; Sharma, Y.; Yi, J.; Hsieh, C.J. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 15–26. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honululu, HI, USA, 21–26 July 2017; pp. 1765–1773. [Google Scholar]
- Xiao, C.; Li, B.; Zhu, J.Y.; He, W.; Liu, M.; Song, D. Generating adversarial examples with adversarial networks. arXiv 2018, arXiv:1801.02610. [Google Scholar]
- Baluja, S.; Fischer, I. Adversarial transformation networks: Learning to generate adversarial examples. arXiv 2017, arXiv:1703.09387. [Google Scholar]
- Sarkar, S.; Bansal, A.; Mahbub, U.; Chellappa, R. UPSET and ANGRI: Breaking high performance image classifiers. arXiv 2017, arXiv:1707.01159. [Google Scholar]
- Cisse, M.; Adi, Y.; Neverova, N.; Keshet, J. Houdini: Fooling deep structured prediction models. arXiv 2017, arXiv:1707.05373. [Google Scholar]
- Athalye, A.; Carlini, N.; Wagner, D. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 274–283. [Google Scholar]
- Zhou, M.; Wu, J.; Liu, Y.; Zhu, C. Dast: Data-free substitute training for adversarial attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 July 2020; pp. 234–243. [Google Scholar]
- Mao, X.; Chen, Y.; Li, Y.; He, Y.; Xue, H. Gap++: Learning to generate target-conditioned adversarial examples. arXiv 2020, arXiv:2006.05097. [Google Scholar]
- Feng, Y.; Wu, B.; Fan, Y.; Li, Z.; Xia, S. Efficient black-box adversarial attack guided by the distribution of adversarial perturbations. arXiv 2020, arXiv:2006.08538. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial examples in the physical world. arXiv 2016, arXiv:1607.02533. [Google Scholar]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a defense to adversarial perturbations against deep neural networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; IEEE: New York, NY, USA, 2016; pp. 582–597. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Mao, X.; Chen, Y.; Li, Y.; Xiong, T.; He, Y.; Xue, H. Bilinear representation for language-based image editing using conditional generative adversarial networks. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2047–2051. [Google Scholar]
- Poursaeed, O.; Katsman, I.; Gao, B.; Belongie, S. Generative adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4422–4431. [Google Scholar]
- Lu, Y.; Huang, B. Structured output learning with conditional generative flows. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5005–5012. [Google Scholar]
- Addepalli, S.; Vivek, B.S.; Baburaj, A.; Sriramanan, G.; Babu, R.V. Towards achieving adversarial robustness by enforcing feature consistency across bit planes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, CA, USA, 14–19 June 2020; pp. 1020–1029. [Google Scholar]
- Ma, A.; Faghri, F.; Farahmand, A. Adversarial robustness through regularization: A second-order approach. arXiv 2020, arXiv:2004.01832. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the International Conference on Learning Representations, Vancover, BC, Canada, 27 November 2017–5 January 2018. [Google Scholar]
- Folz, J.; Palacio, S.; Hees, J.; Dengel, A. Adversarial defense based on structure-to-signal autoencoders. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; IEEE: New York, NY, USA, 2020; pp. 3568–3577. [Google Scholar]
- Liao, F.; Liang, M.; Dong, Y.; Pang, T.; Hu, X.; Zhu, J. Defense against adversarial attacks using high-level representation guided denoiser. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1778–1787. [Google Scholar]
- Wang, S.; Wang, X.; Zhao, P.; Wen, W.; Kaeli, D.; Chin, P.; Lin, X. Defensive dropout for hardening deep neural networks under adversarial attacks. In Proceedings of the International Conference on Computer-Aided Design, Marrakesh, Morocco, 19–21 March 2018; pp. 1–8. [Google Scholar]
- Ang, X.; Wang, S.; Chen, P.Y.; Wang, Y.; Kulis, B.; Lin, X.; Chin, P. Protecting neural networks with hierarchical random switching: Towards better robustness-accuracy trade-off for stochastic defenses. arXiv 2019, arXiv:1908.07116. [Google Scholar]
- Liu, X.; Cheng, M.; Zhang, H.; Hsieh, C.J. Towards robust neural networks via random self-ensemble. In Proceedings of the European Conference on Computer Vision (ECCV), Tel-Aviv, Israel, 23–27 October 2018; pp. 369–385. [Google Scholar]
- Kannan, H.; Kurakin, A.; Goodfellow, I. Adversarial Logit Pairing. arXiv 2018, arXiv:1803.06373. [Google Scholar]
- Wu, T.; Tong, L.; Vorobeychik, Y. Defending against physically realizable attacks on image classification. arXiv 2019, arXiv:1909.09552. [Google Scholar]
- Jia, X.; Wei, X.; Cao, X.; Foroosh, H. Comdefend: An efficient image compression model to defend adversarial examples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 6084–6092. [Google Scholar]
- Guo, C.; Rana, M.; Cisse, M.; Van Der Maaten, L. Countering adversarial images using input transformations. arXiv 2017, arXiv:1711.00117. [Google Scholar]
- Prakash, A.; Moran, N.; Garber, S.; DiLillo, A.; Storer, J. Deflecting adversarial attacks with pixel deflection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 17–22 June 2018; pp. 8571–8580. [Google Scholar]
- Samangouei, P.; Kabkab, M.; Chellappa, R. Defense-GAN: Protecting Classifiers Against Adversarial Attacks Using Generative Models. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 27 November 2017–5 January 2018. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Jin, G.; Shen, S.; Zhang, D.; Dai, F.; Zhang, Y. Ape-gan: Adversarial perturbation elimination with gan. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: New York, NY, USA, 2019; pp. 3842–3846. [Google Scholar]
- Cohen, G.; Sapiro, G.; Giryes, R. Detecting adversarial samples using influence functions and nearest neighbors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 14453–14462. [Google Scholar]
- Meng, D.; Chen, H. Magnet: A two-pronged defense against adversarial examples. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 135–147. [Google Scholar]
- Abusnaina, A.; Wu, Y.; Arora, S.; Wang, Y.; Wang, F.; Yang, H.; Mohaisen, D. Adversarial example detection using latent neighborhood graph. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7687–7696. [Google Scholar]
- Choi, S. Malicious PowerShell Detection Using Attention against Adversarial Attacks. Electronics 2020, 9, 1817. [Google Scholar] [CrossRef]
- He, W.; Wei, J.; Chen, X.; Carlini, N.; Song, D. Adversarial example defense: Ensembles of weak defenses are not strong. In Proceedings of the 11th {USENIX} Workshop on Offensive Technologies ({WOOT} 17), Singapore, 16–18 August 2017. [Google Scholar]
- Yu, Y.; Yu, P.; Li, W. AuxBlocks: Defense Adversarial Examples via Auxiliary Blocks. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14 July 2019; IEEE: New York, NY, USA, 2019; pp. 1–8. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Adversarial Attacks | Attack Type | Attack Target | Attack Frequency | Perturbation Type | Perturbation Norm | Attack Strategy |
|---|---|---|---|---|---|---|
| L-BFGS [9] | White-box | Targeted | One-shot | Specific | Constrained optimization | |
| FGSM [10] | White-box | Targeted | One-shot | Specific | Gradient optimization | |
| JSMA [11] | White-box | Targeted | Iterative | Specific | Sensitivity analysis | |
| C&W [12] | White-box | Targeted | Iterative | Specific | Constrained optimization | |
| One-Pixel [13] | Black-box | Non-targeted | Iterative | Specific | Estimated decision boundary | |
| DeepFool [14] | White-box | Non-targeted | Iterative | Specific | Gradient optimization | |
| ZOO [15] | Black-box | Targeted | Iterative | Specific | Migration mechanism | |
| UAP [16] | White-box | Non-targeted | Iterative | Universal | Gradient optimization | |
| AdvGAN [17] | White-box | Targeted | Iterative | Specific | Generative model | |
| ATNs [18] | White-box | Targeted | Iterative | Specific | Generative model | |
| UPSET [19] | Black-box | Targeted | Iterative | Universal | Gradient approximation | |
| ANGRI [19] | Black-box | Targeted | Iterative | Specific | Gradient approximation | |
| Houdini [20] | Black-box | Targeted | Iterative | Specific | Constrained optimization | |
| BPDA [21] | Black-box | Targeted | Iterative | Specific | Gradient approximation | |
| DaST [22] | Black-box | Targeted | Iterative | Specific | Generative model | |
| GAP++ [23] | White-box | Targeted | One-shot | Universal | Generative model | |
| CG-ES [24] | Black-box | Targeted | Iterative | Specific | Evolution Strategies |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, H.; He, E.; Zhao, Y.; Jia, Z.; Li, H. Adversarial Attack and Defense: A Survey. Electronics 2022, 11, 1283. https://doi.org/10.3390/electronics11081283
Liang H, He E, Zhao Y, Jia Z, Li H. Adversarial Attack and Defense: A Survey. Electronics. 2022; 11(8):1283. https://doi.org/10.3390/electronics11081283
Chicago/Turabian StyleLiang, Hongshuo, Erlu He, Yangyang Zhao, Zhe Jia, and Hao Li. 2022. "Adversarial Attack and Defense: A Survey" Electronics 11, no. 8: 1283. https://doi.org/10.3390/electronics11081283
APA StyleLiang, H., He, E., Zhao, Y., Jia, Z., & Li, H. (2022). Adversarial Attack and Defense: A Survey. Electronics, 11(8), 1283. https://doi.org/10.3390/electronics11081283