
Lightweight Path Recovery in IPv6 Internet-of-Things Systems


Abstract
:1. Introduction
- As the nodes in the network are always undergoing unpredictable failures and state changes, the topology of the network is in constant change, making the path from the same source node to the destination node diverse.
- The IoT is highly resource-limited in terms of the packet payload, which leaves little space for carrying path recovery information.
- In most IoT scenarios, both the working status of nodes and the packets routing are time-varying.
- We propose a lightweight path recovery scheme that explores the potential correlations of routing paths between different nodes using the node information of the parent and grandparent.
- We propose a modulated observation window size for path recovery based on the activity level of the nodes. This enables effective path recovery with appropriate computational effort for network scenarios with different traffic sizes.
- We propose new algorithms and obtain good performance in simulation experiments, compared to the state-of-the-art. In addition, we analyze the performance improvement of each highlight in the algorithm.
2. Related Work

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Year | Overhead | Key Idea | Limitation |
|---|---|---|---|---|
| Path [19] | 2019 | 8B | Exploits compression-aware techniques and path correlations | Not suitable for networks with inactive nodes |
| RTI [18] | 2019 | 12B | Exploits packet tracing and local probing to reconstruct the route path | (1) Sensitive to nodes fails (2) High storage overhead |
| PAT [17] | 2017 | 11B | Exploits path compression and correlations | (1) Initialization phase to reconstruct the network topologies are needed (2) High storage overhead |
| iPath [12] | 2016 | 6B | Exploits path correlations | Not suitable for networks with inactive nodes |
| CSPR [13] | 2016 | 8B | Exploits compression-aware technique | (1) Not suitable for dynamic networks (2) Not suitable for networks with inactive nodes |
| Pathfinder [24] | 2015 | 9B | Exploits path correlations and inconsistency of packets | Not suitable for sparse networks |
| INS-RTR [25] | 2015 | 11B | Exploits path correlations | (1) Not suitable for networks with inactive nodes (2) High storage overhead |
| PathZip [14] | 2014 | 8B | Exploits path compression with topology-aware and geometry-assistant techniques | (1) Sensitive to nodes fails (2) High storage overhead |
| MNT [16] | 2012 | 6B | Exploits path correlations | Not suitable for networks with inactive nodes |
3. System Model and Problem Statement
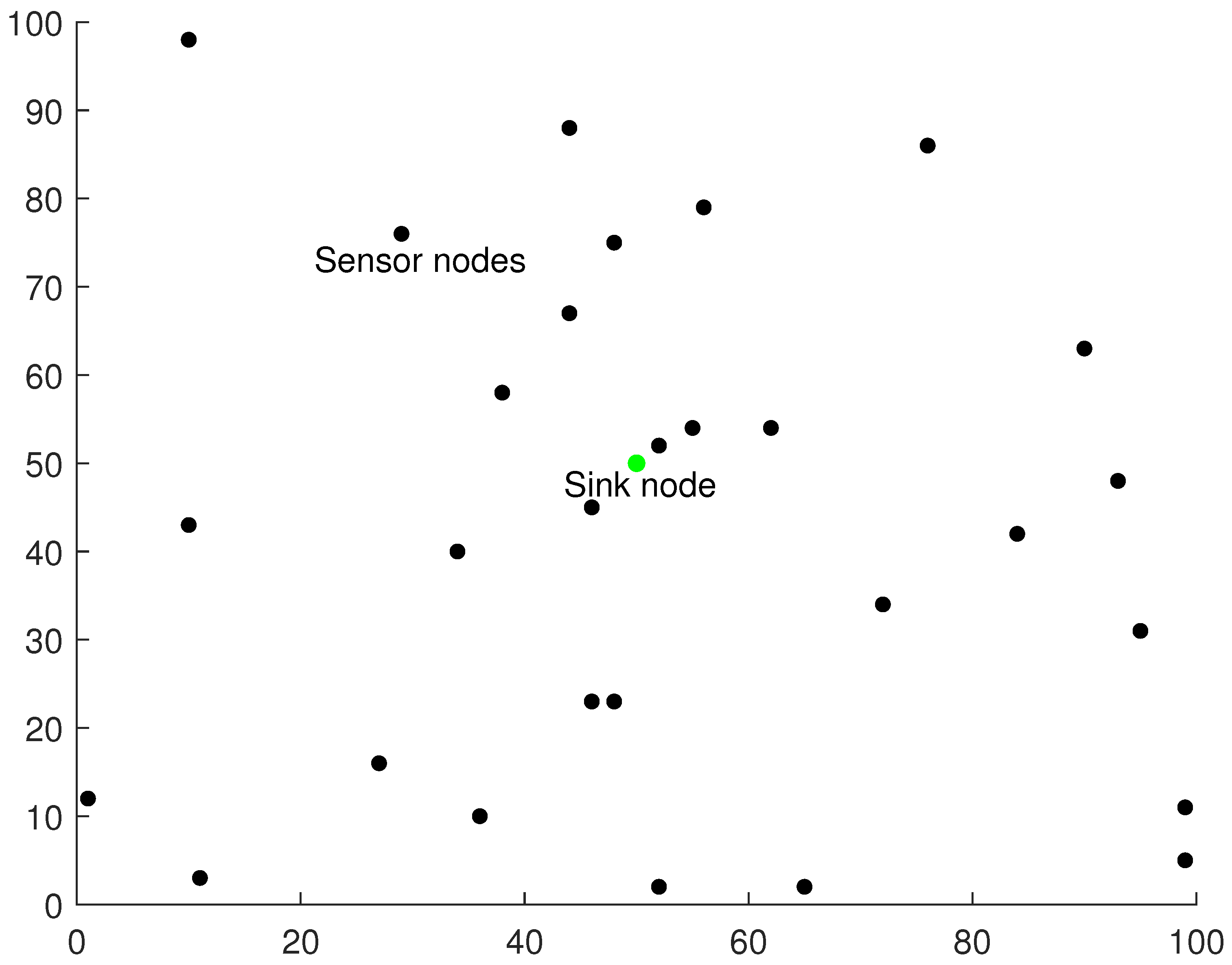
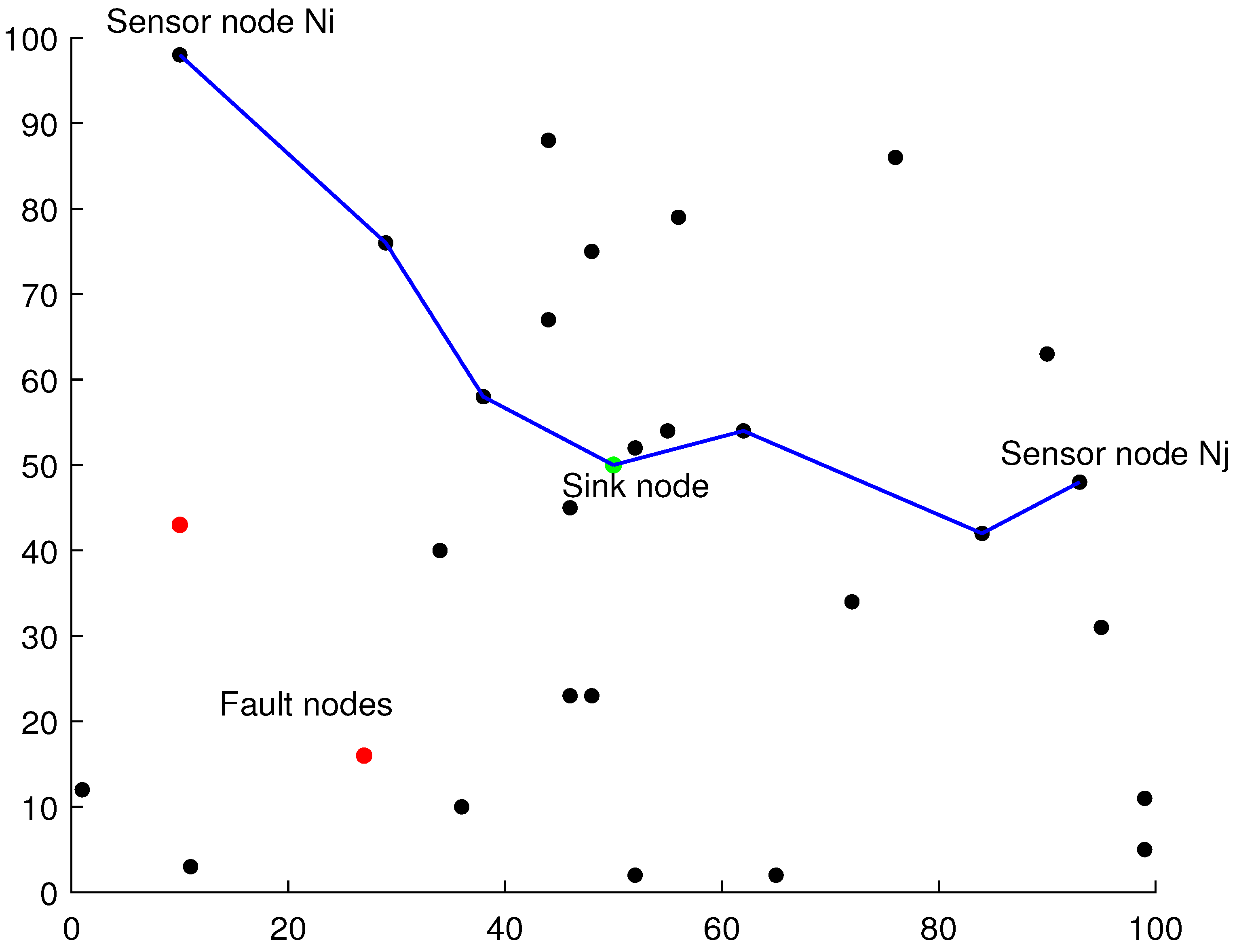
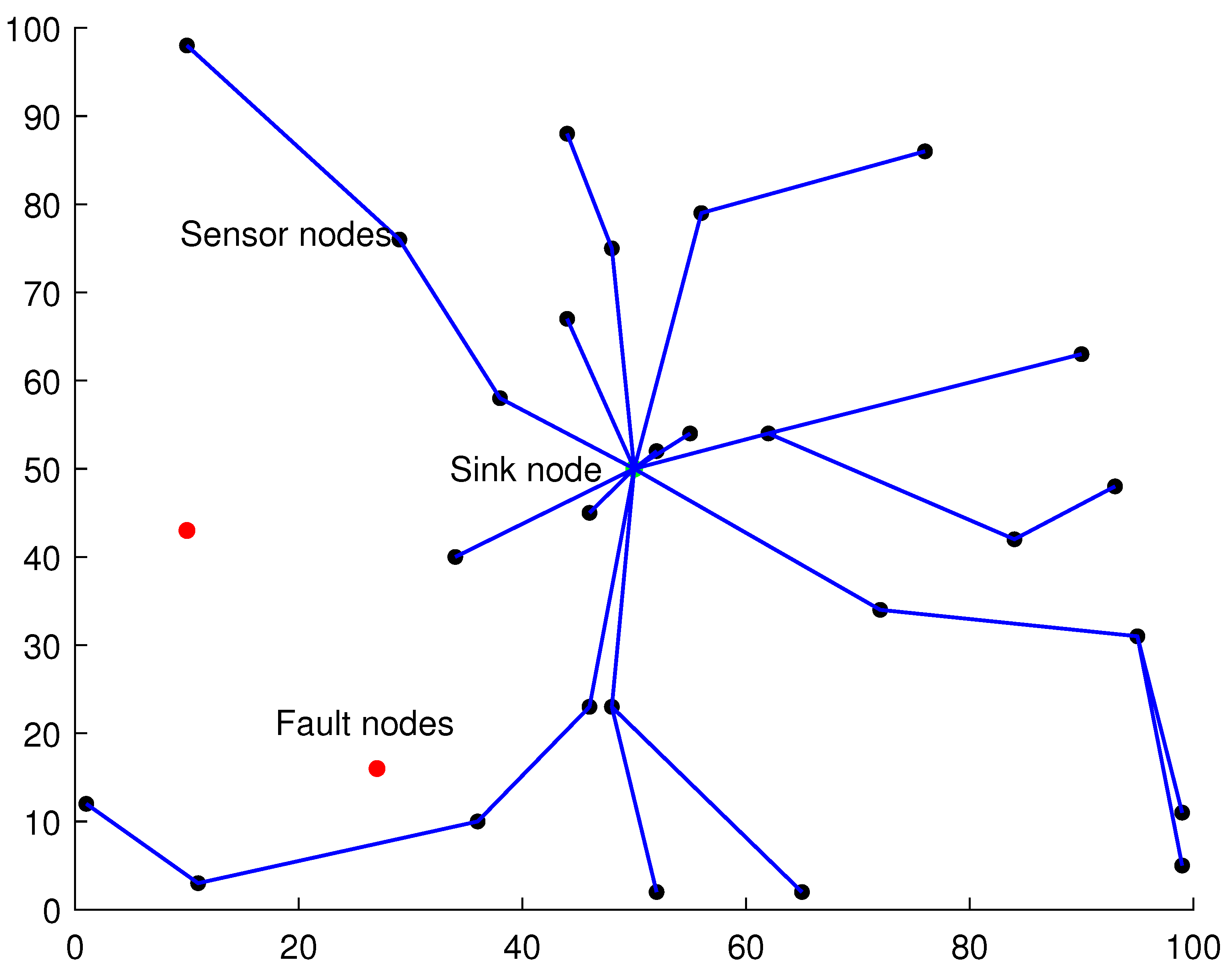
3.1. Network Model
3.2. Problem Statement
- The source node and destination node . These can be retrieved by the sink node based on the IPv6 address of the packet header, not requiring additional space overhead for the packet.
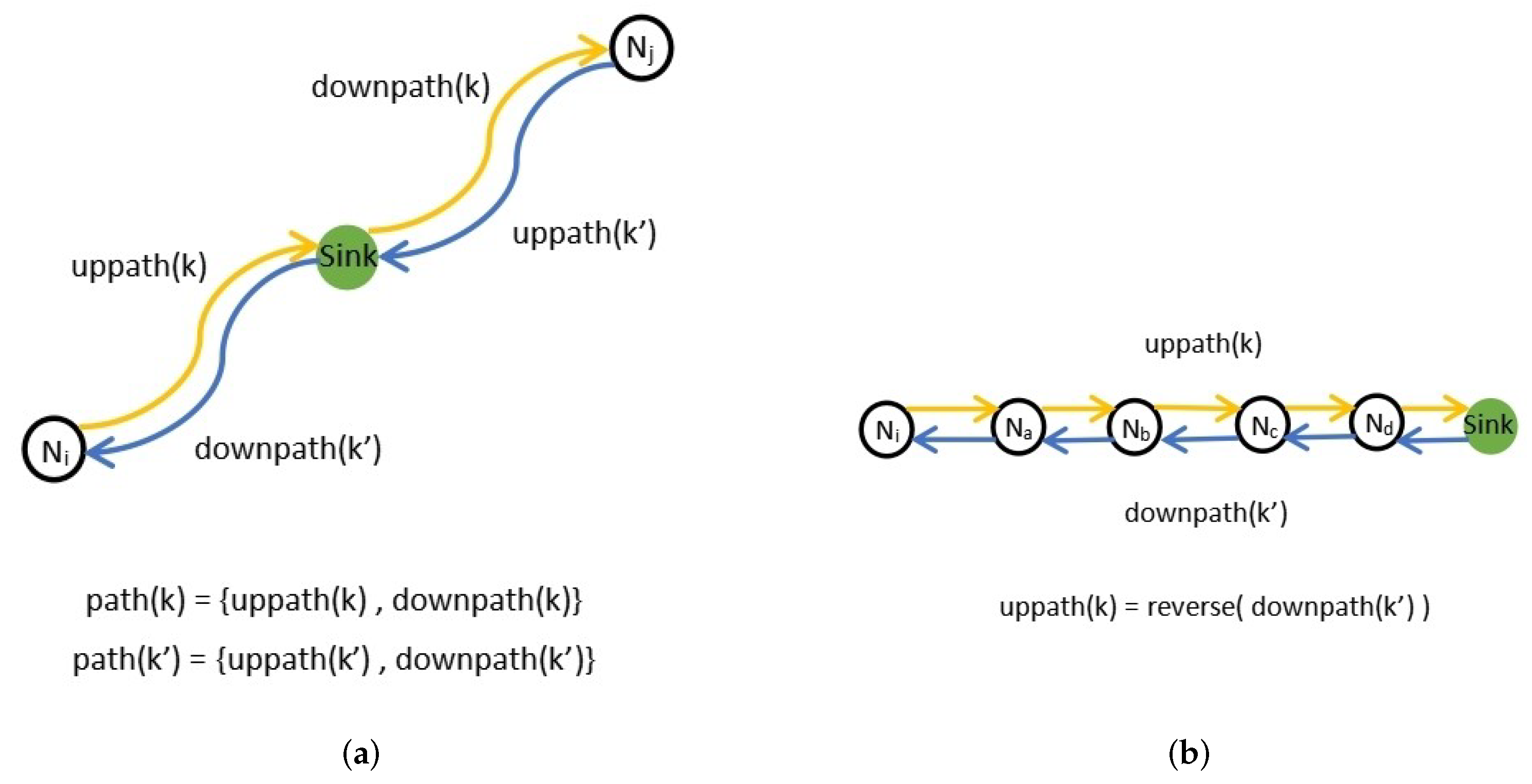
- The parent node and grandparent node . The parent node is the next hop of the source node, and the grandparent node is the next hop of . To record the IDs of and , an extra 4B of space is needed for a packet. The default values of and are empty. When the forwarder is the parent or grandparent node of the source node, its ID will be written into the corresponding field.
- The hash value of the upstream path of packet k is denoted as . It also refers to where represents a series of nodes ID. We set a hash function to identify an upstream path, which requires additional 2B space for a packet. Each node forwards packet k with a small computational overhead to update the , and the final received by the sink node is the hash value that records an entire upstream path. The packets with the same hash value can be considered as going through the same path.
- The length of the uplink path, denoted as . This can be inferred from the Hop Limit of the IPv6 header without the additional space overhead of the packet.
- The timestamp . This can be inferred from the packet arrival time to which the packet belongs to the collection cycle, without the additional space overhead of the packet.
- . We define the of the path recovery problem as:where denotes the number of all successfully communicated packets, and denotes the number of all correctly recovered packets whose paths were correctly recovered. The purpose of path recovery is to improve the as much as possible.
- . The meaning of this metric is how many bytes of gain we can exchange for one byte of overhead, which is defined as:whereandThe is the number of bytes occupied by a node ID, i.e., 2 bytes in our network model, and is the path length of the packet i. The is an indicator variable of the packet i where means the packet path was correctly recovered, while means the packet path does not exist or has not been recovered correctly. The is the extra overhead added to each packet for path recovery in this algorithm. As seen in the previous section, the overhead is 6 bytes in our network model, including 2 bytes for the parent node ID, 2 bytes for the grandparent node ID, and 2 bytes for the hash value. represents the packets generated by all active nodes, although some source nodes could not be successfully communicated to the destination node due to a failure of the original route node, which is limited by the transmission distance.
4. Design of LiPa
4.1. Solution Overview
4.2. Path Correlation Inference
| Algorithm 1 The Recovery Core Algorithm. |
| Require:k: a packet whose path has been recovered; i: a packet whose path is unknown; Output:True or False: whether packet k can be used to recover the path of packet i;
|
4.3. Iterative Path Recovery
| Algorithm 2 The Lightweight Path Recovery Algorithm. |
| Require:: a set of packets during whose paths have been recovered; : a set of packets during whose paths are unknown; Output: : a set of packets during whose paths are recovered;
|
5. Performance Evaluation and Analysis
5.1. Evaluation Setup
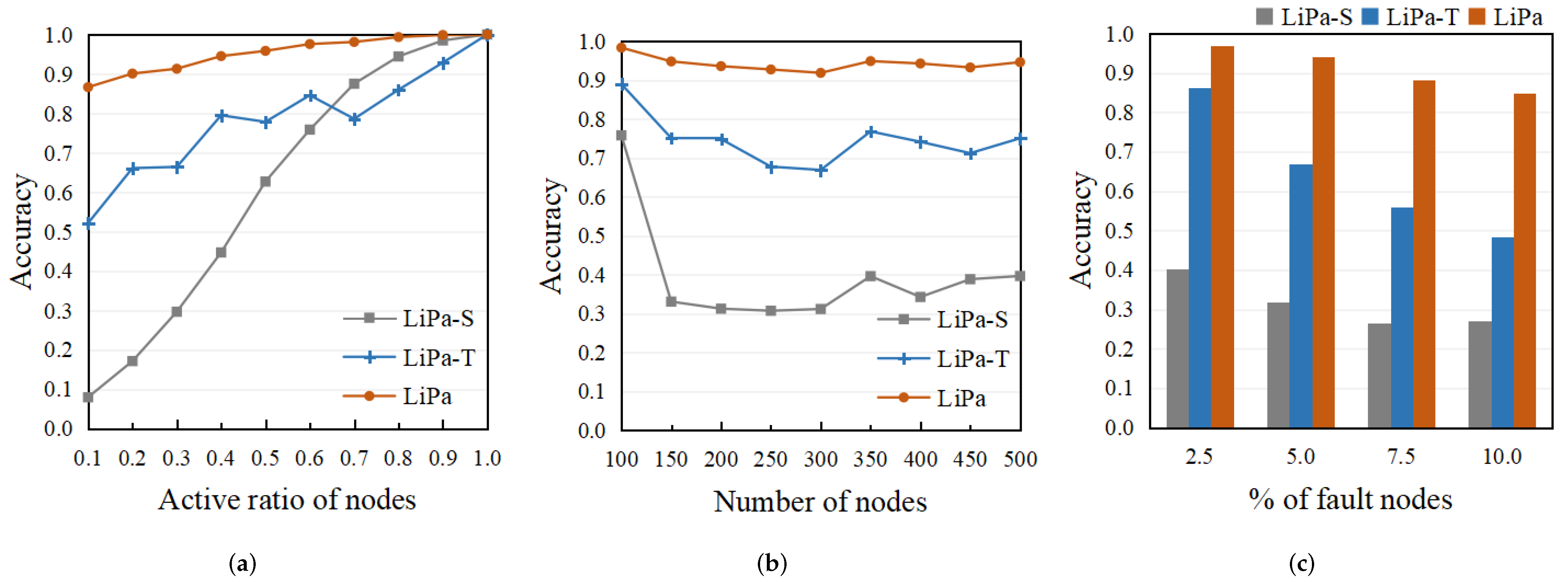
5.2. Performance Improvement Analysis
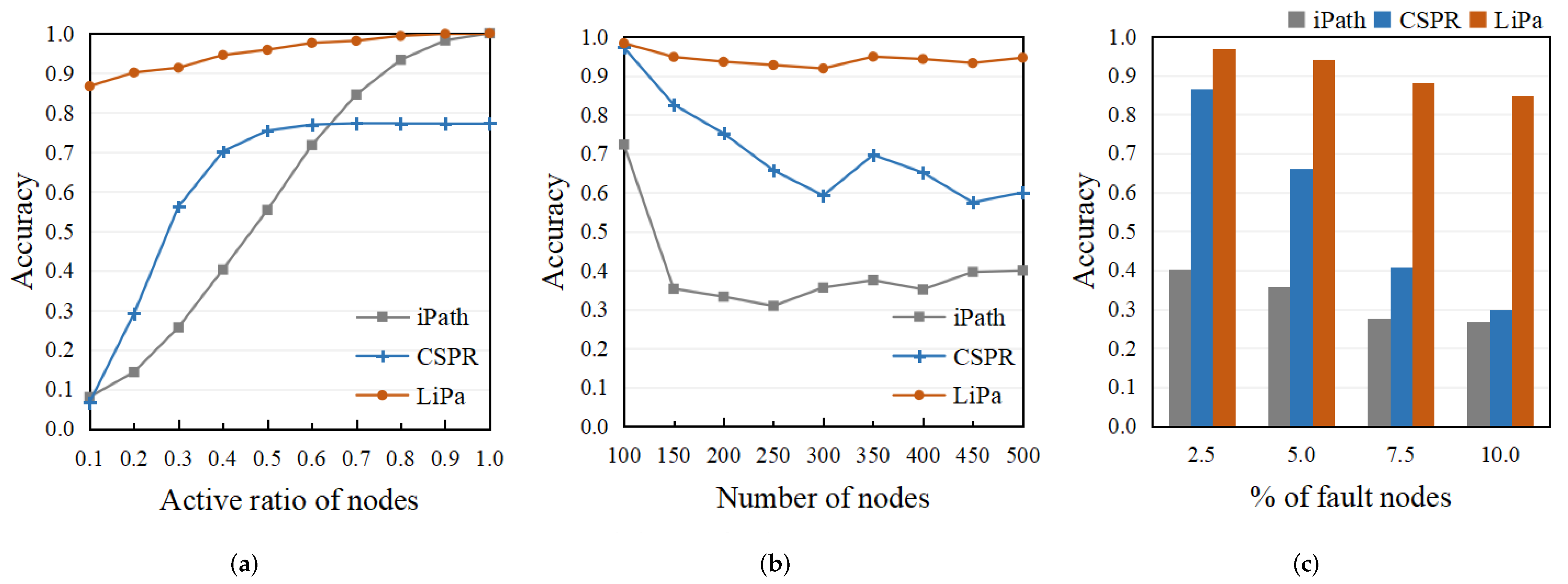
5.3. Comparison of the Accuracy
5.4. Comparison of the Gain–Loss Ratio
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Winter, T.; Thubert, P.; Brandt, A.; Hui, J.W.; Kelsey, R.; Levis, P.; Pister, K.; Struik, R.; Vasseur, J.P.; Alexander, R.K.; et al. RPL: IPv6 Routing Protocol for Low-Power and Lossy Networks. RFC 2012, 6550, 1–157. [Google Scholar]
- Glissa, G.; Rachedi, A.; Meddeb, A. A Secure Routing Protocol Based on RPL for Internet of Things. In Proceedings of the 2016 IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Hashemi, S.Y.; Shams Aliee, F. Dynamic and comprehensive trust model for IoT and its integration into RPL. J. Supercomput. 2019, 75, 3555–3584. [Google Scholar] [CrossRef]
- Hariharakrishnan, J.; Natarajan, B. Adaptability Analysis of 6LoWPAN and RPL for Healthcare applications of Internet-of-Things. J. ISMAC 2021, 2, 69–81. [Google Scholar] [CrossRef]
- Caldeira, J.M.; Rodrigues, J.J.; Lorenz, P. Toward ubiquitous mobility solutions for body sensor networks on healthcare. IEEE Commun. Mag. 2012, 50, 108–115. [Google Scholar] [CrossRef]
- Abdel Hakeem, S.A.; Hady, A.A.; Kim, H. RPL Routing Protocol Performance in Smart Grid Applications Based Wireless Sensors: Experimental and Simulated Analysis. Electronics 2019, 8, 186. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Tao, Z.; Zhang, J.; Abouzeid, A.A. RPL based routing for advanced metering infrastructure in smart grid. In Proceedings of the 2010 IEEE International Conference on Communications Workshops, Capetown, South Africa, 23–27 May 2010; pp. 1–6. [Google Scholar]
- Istomin, T.; Kiraly, C.; Picco, G.P. Is RPL Ready for Actuation? A Comparative Evaluation in a Smart City Scenario. In Wireless Sensor Networks; Abdelzaher, T., Pereira, N., Tovar, E., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 291–299. [Google Scholar]
- Handigol, N.; Heller, B.; Jeyakumar, V.; Mazières, D.; McKeown, N. I Know What Your Packet Did Last Hop: Using Packet Histories to Troubleshoot Networks. In Proceedings of the 11th USENIX Conference on Networked Systems Design and Implementation (NSDI’14), Seattle, WA, USA, 2–4 April 2014; USENIX Association: Berkeley, CA, USA, 2014; pp. 71–85. [Google Scholar]
- Malekzadeh, A.; MacGregor, M.H. Network topology inference from end-to-end unicast measurements. In Proceedings of the 2013 27th International Conference on Advanced Information Networking and Applications Workshops, Barcelona, Spain, 25–28 March 2013; pp. 1101–1106. [Google Scholar]
- Larmore, G.; Harrison, W.K. Active Topology Inference in Store, Code, and Forward Networks. In Proceedings of the 2018 15th International Symposium on Wireless Communication Systems (ISWCS), Lisbon, Portugal, 28–31 August 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Gao, Y.; Dong, W.; Chen, C.; Bu, J.; Wu, W.; Liu, X. iPath: Path Inference in Wireless Sensor Networks. IEEE/ACM Trans. Netw. 2016, 24, 517–528. [Google Scholar] [CrossRef]
- Liu, Z.; Li, Z.; Li, M.; Xing, W.; Lu, D. Path Reconstruction in Dynamic Wireless Sensor Networks Using Compressive Sensing. IEEE/ACM Trans. Netw. 2016, 24, 1948–1960. [Google Scholar] [CrossRef] [Green Version]
- Lu, X.; Dong, D.; Liao, X.; Li, S.; Liu, X. PathZip: A lightweight scheme for tracing packet path in wireless sensor networks. Comput. Netw. 2014, 73, 1–14. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, K.; Li, M. Passive Diagnosis for Wireless Sensor Networks. IEEE/ACM Trans. Netw. 2010, 18, 1132–1144. [Google Scholar] [CrossRef] [Green Version]
- Keller, M.; Beutel, J.; Thiele, L. How Was Your Journey? Uncovering Routing Dynamics in Deployed Sensor Networks with Multi-Hop Network Tomography. In Proceedings of the 10th ACM Conference on Embedded Network Sensor Systems (SenSys’12), Toronto, ON, Canada, 6–9 November 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 15–28. [Google Scholar] [CrossRef]
- Dong, W.; Gao, Y.; Cao, C.; Zhang, X.; Wu, W. Universal Path Tracing for Large-Scale Sensor Networks. IEEE/ACM Trans. Netw. 2020, 28, 447–460. [Google Scholar] [CrossRef]
- Zhu, X.; Lu, Y.; Zhang, J.; Wei, Z. Routing Topology Inference for Wireless Sensor Networks Based on Packet Tracing and Local Probing. IEICE Trans. Commun. 2019, E102.B, 122–136. [Google Scholar] [CrossRef]
- Dong, W.; Cao, C.; Zhang, X.; Gao, Y. Understanding path reconstruction algorithms in multihop wireless networks. IEEE/ACM Trans. Netw. 2018, 27, 1–14. [Google Scholar] [CrossRef]
- Kim, H.S.; Ko, J.; Culler, D.E.; Paek, J. Challenging the IPv6 Routing Protocol for Low-Power and Lossy Networks (RPL): A Survey. IEEE Commun. Surv. Tutor. 2017, 19, 2502–2525. [Google Scholar] [CrossRef]
- Livadariu, I.; Elmokashfi, A.; Dhamdhere, A. Characterizing IPv6 control and data plane stability. In Proceedings of the IEEE INFOCOM 2016—The 35th Annual IEEE International Conference on Computer Communications, San Francisco, CA, USA, 10–14 April 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Lai, G.S. Detection of wormhole attacks on IPv6 mobility-based wireless sensor network. EURASIP J. Wirel. Commun. Netw. 2016, 2016, 274. [Google Scholar] [CrossRef]
- Waddington, D.G.; Chang, F.; Viswanathan, R.; Yao, B. Topology Discovery for Public IPv6 Networks. SIGCOMM Comput. Commun. Rev. 2003, 33, 59–68. [Google Scholar] [CrossRef]
- Gao, Y.; Dong, W.; Chen, C.; Bu, J.; Liu, X. Towards reconstructing routing paths in large scale sensor networks. IEEE Trans. Comput. 2015, 65, 281–293. [Google Scholar] [CrossRef]
- Liu, R.; Liang, Y.; Zhong, X. Monitoring routing topology in dynamic wireless sensor network systems. In Proceedings of the 2015 IEEE 23rd International Conference on Network Protocols (ICNP), San Francisco, CA, USA, 10–13 November 2015; pp. 406–416. [Google Scholar]
- Paszkowska, A.; Iwanicki, K. On Designing Provably Correct DODAG Formation Criteria for the IPv6 Routing Protocol for Low-Power and Lossy Networks (RPL). In Proceedings of the 2018 14th International Conference on Distributed Computing in Sensor Systems (DCOSS), New York, NY, USA, 18–20 June 2018; pp. 43–52. [Google Scholar] [CrossRef]
- Ancillotti, E.; Vallati, C.; Bruno, R.; Mingozzi, E. A reinforcement learning-based link quality estimation strategy for RPL and its impact on topology management. Comput. Commun. 2017, 112, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Gawade, A.U.; Shekokar, N.M. Lightweight Secure RPL: A Need in IoT. In Proceedings of the 2017 International Conference on Information Technology (ICIT), Singapore, 27–29 December 2017; pp. 214–219. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Fu, L.; Pan, M.; Zhao, Z. Lightweight Path Recovery in IPv6 Internet-of-Things Systems. Electronics 2022, 11, 1220. https://doi.org/10.3390/electronics11081220
Liu Z, Fu L, Pan M, Zhao Z. Lightweight Path Recovery in IPv6 Internet-of-Things Systems. Electronics. 2022; 11(8):1220. https://doi.org/10.3390/electronics11081220
Chicago/Turabian StyleLiu, Zhuoliu, Luwei Fu, Maojun Pan, and Zhiwei Zhao. 2022. "Lightweight Path Recovery in IPv6 Internet-of-Things Systems" Electronics 11, no. 8: 1220. https://doi.org/10.3390/electronics11081220
APA StyleLiu, Z., Fu, L., Pan, M., & Zhao, Z. (2022). Lightweight Path Recovery in IPv6 Internet-of-Things Systems. Electronics, 11(8), 1220. https://doi.org/10.3390/electronics11081220