1. Introduction
As wireless applications continue to grow, spectrally efficient modulation schemes will continue to be highly valuable [
1,
2,
3]. The classical binary modulation schemes such as amplitude shift keying (ASK), frequency shift keying (2FSK) and phase-shift keying (2PSK, or BPSK) are spectrally inefficient. In the past two decades, a number of bandwidth efficient modulation techniques have been proposed. Wu et al. proposed an extended binary phase shift keying (EBPSK) scheme [
4] which is much more flexible and has a more compact spectral structure than conventional BPSK modulation. It is shown that, by tuning the modulation parameters, EBPSK could achieve the same bit error rate (BER) performance as the conventional BPSK, but has higher spectrum utilization efficiency than the latter for wireless applications. EBPSK is also extended to M-ary phase position shift keying (MPPSK) [
5] to achieve higher transmission rates. An improved MPPSK modulation with a simpler demodulator and a better performance than the original MPPSK scheme is presented [
6].
Existing demodulators of MPPSK systems use back propagation (BP) [
7], support vector machine (SVM) [
8], joint amplitude and waveforms detection (JAWD) [
9], and the phase locked loop (PLL) techniques [
5]. However, the symbol error rate (SER) performance of MPPSK signaling could be further improved by using more advanced detection techniques. The demodulator for MPPSK signaling described in [
5] uses a special impact filter (SIF) which could have a strong impact on the signal amplitude at the phase transition instants to significantly improve the output signal-to-noise ratio (
SNR).
Deep learning has been successfully applied to a variety of problems [
10,
11,
12]. The success of deep learning algorithms generally depends on how data are represented. For communication signals such as MPPSK, since the SIF affects the signal amplitude more appreciably at the phase transition points, the impacted amplitudes of MPPSK waveforms contain abundant features. The features can be learned and used as classifiers to significantly improve detection performance. To date and to our knowledge, there is little research on unsupervised learning for detection in communication systems. Deep learning models include supervised models and unsupervised models. Compared with labeled data in supervised models, unlabeled data in the unsupervised models are easier to obtain when large-scale data are needed. Unsupervised feature learning consists of several basic modules, such as restricted Boltzmann machine (RBM) [
13], autoencoder (AE) [
10] and sparse coding [
11]. It has been employed in the fields of computer visual perception, speech recognition, natural language processing, etc. Feature learning of unsupervised models has a great potential to improve the detection performance in communication systems [
13,
14,
15]. For MPPSK signals, the AE algorithm could be employed to find the correlation characteristics among the input signals.
In this paper, we developed a detector for MPPSK systems based on the AE learning algorithm, improving the detection performance by learning the useful representations or features. Each possible transmission scenario is considered as a sub-model of deep learning, and a large number of cases are included in its database. We also commonly use training data from the database that contain samples of the modulation signals. The similarity between the training and test data is built by a feature representation to exploit. AE learning networks is categorized into sparse autoencoders (SAEs) and denoising autoencoders (DAEs). The SAE and DAE networks [
16,
17,
18] are combined to form the stacked denoising sparse autoencoders (DSAEs) network, further improving the detection performance of MPPSK signals.
The remainder of this paper is organized as follows.
Section 2 describes the improved MPPSK modulation and the novel demodulator based on the stacked DSAE network.
Section 3 describes the principle of the proposed stacked DSAE network. The SER and computational complexity of the proposed MPPSK systems are obtained in
Section 4. The database and the experimental analysis and results are proposed in
Section 5. Conclusions are given in
Section 6.
2. The Improved MPPSK Signaling
The demodulator of MPPSK systems uses a narrowband SIF [
5] which can produce a strong impact at the phase jumping point, resulting in significant improvement in the output
SNR. The SIF is followed by a threshold decision device or a geometric characteristic-based nonlinear decision device [
19,
20]. There are many variations of the demodulator [
21] and they all require a specific threshold to distinguish zero and non-zero symbols. The position information is utilized to decode the non-zero symbols. The threshold is critical for these demodulators to function properly, and it will cause a performance degradation in practice. An issue with the MPPSK signal is that there is no phase jump for an incoming symbol “0”. Consequently, the SIF response to the symbol “0” cannot produce a similar change on the amplitude as the non-zero symbols. Therefore, the detection between the zero and non-zero symbols must exploit the amplitude information.
The improved MPPSK signaling in [
6] allows demodulation by only using the position information of the received signal passed through the SIF. The basic idea is to eliminate the symbol “0”. That is, the alphabet is changed from [0, 1, 2, …, M−1] to [1, 2, …, M]. In this improved MPPSK signaling scheme, over the time period [0,
T], the modulation signal is expressed as
where
T is the period of the carrier signal,
,
is the carrier frequency,
is the symbol period,
N is the ratio of the symbol period to the carrier period,
K is the number of carrier periods with a phase jump,
is the modulation angle,
, and
is the control factor for the symbol protection interval. For simplicity, set
in this paper.
The improved MPPSK modulation given in Equation (
1) is not strictly bandwidth-limited signals, since information is embedded into the position of a full carrier signal cycle. Furthermore, each symbol period consists
N cycles of the carrier signal. Many BER bounds are obtained from information theory, assuming strictly bandwidth-limited signals designed according to the Nyquist criterion for zero inter-symbol interference (ISI). It might not be directly applicable. For the improved MPPSK signaling, the relationship between
SNR and
is
where
is a symbol rate,
is sampling rate, and
is the effective noise bandwidth, although the signal is not strictly bandlimited.
is the received energy per bit,
is the single-sided noise power spectral density.
The existing MPPSK demodulators include the decision threshold-based approach [
5], the adaptive threshold integral discriminator [
20], the coherent processing technique [
21], the phase locked loop (PLL) scheme [
22] and the matched filtering scheme [
23,
24]. As shown in
Figure 1, we develop a new demodulation scheme for the improved MPPSK modulation aiming to significantly improve detection performance. In the proposed system, there are the forward error correction (FEC) encoding before improved MPPSK modulation, and the FEC decoding after stacked DSAE demodulator. The stacked DSAE network is used for automatic feature extraction and detection. The architecture is first trained using unlabeled improved MPPSK signals. There are two detection schemes. One is the SIF directly followed by the stacked DSAE. Another is SIF, a coherent processing block and a low pass filter (LPF) followed by the stacked DSAE in the receiver.
3. Stacked DSAE Network
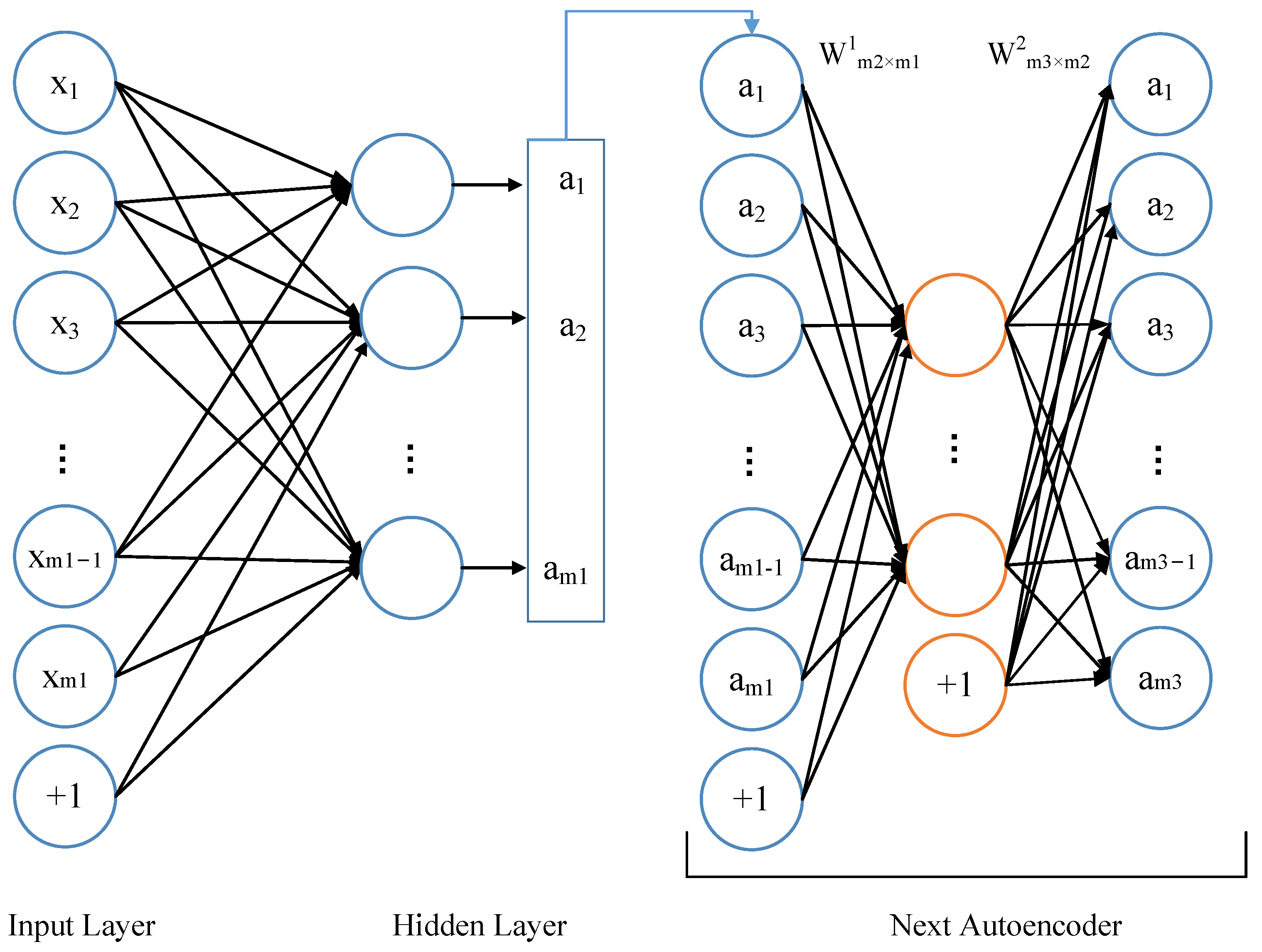
The stacked autoencoder network is composed of multiple layers of sparse autoencoders. Furthermore, the output of the previous layer of autoencoders is used as the input of the latter layer of autoencoders. The weights of the existing neural networks are random initialization. However, in the stacked autoencoder network, the weights are learned by the autoencoder instead of that in the traditional neural network as shown in
Figure 2. Furthermore, the noise is added to the training database to improve the generalization ability and robustness. Before training, the noised modulation signal is down-sampled and converted without a tag, which forms a part of the DSAE network database. After training, the weight matrices, which are learned by the network, are used to transform the data. The transformed data are used as features to train the softmax classifier. In the testing phase, the raw test data are transformed by the stacked DSAE network, and the output is fed into the softmax classifier for detection.
The input is the noised improved MPPSK vector
and the neurons are arranged in a column vector
where the superscript
denotes transposition. It can be written in vector-matrix form as
where the matrix
is weights and the vector
is the bias in the input layer. The network has two nonlinear functions. One is in the second layer and the other one is in the output layer. This allows the network to capture higher order statistics from the input data, leading to a higher kurtosis in the coded representation.
In the proposed stacked DSAE network, the
learned by the first autoencoder is used to link the input layer and the first hidden layer. Furthermore, the
learned by the second autoencoder is used to link the first hidden layer and the second hidden layer. Furthermore, the weights are stacked on the top of the first autoencoder, as shown in
Figure 3. The encoding process of the stacked DSAE network is used to execute the coding steps of each layer of autoencoders from front to back. It can be expressed as
Similarly, the decoding process is used to perform the decoding steps of each layer of autoencoders from back to front. It can be represented as
where
is the activation value of the deepest hidden unit. It contains the information of our interest, and it is also a higher-order representation of the input value.
The cost function of the stacked DSAE network is given by
where
m is the numbers of input vectors,
is a sparsity parameter as well as a hyper-parameter and
is a parameter that controls the amount of regularization.
is a weight to control the sparsity penalty factor. The Kullback–Leibler (KL) divergence penalty is
is the average activation of the
jth hidden unit over the training set. The weights and biases in the input layer are updated by gradient descent.
The input features from the stacked DSAE can be used for detecting the improved MPPSK modulation signals. It is fed by the output to a softmax classifier, and is a sigmoid function. Thus, the originally generated layers can be used for feature extraction. When the dataset is sent into the stacked DSAE network, every hidden layer transforms the feature data until the last hidden layer. Then, the last set of the extracted feature is fed into the softmax layer for detection. After the construction of the whole network is complete, the cost function is finally optimized by the limited-memory Broyden–Fletcher–Goldfarb–Shanno (L-BFGS) algorithm.
4. SER and Computational Complexity
The improved MPPSK signal can be expressed as
The probability that symbol
p is erroneously detected as symbol
q can be given as
where
is the Marcum Q-function. Thus, the SER of the improved MPPSK modulation is
The SER of the improved MPPSK modulation is lower than that of the existing MPPSK in [
20].
The computational complexity of the stacked DSAE algorithm is given by
where
and
represent the input size and output size of the stacked DSAE network, respectively.
denotes the parameter dimension in the input layer. In the training stage, it is more efficient with a much shorter training time compared to the conventional decision threshold-based approach [
5], the adaptive threshold integral discriminator [
20], coherent processing technique [
21], the PLL scheme [
22], etc., especially in the unsupervised training stage.
5. Simulation and Analysis
5.1. Database
The database used in this paper contains the training set and the test set. When the database is used to detect the 2PPSK modulation signal, the training set contains 2 classes of 60,000 sampled waveforms, and the test set contains two classes of 10,000 sampled noised waveforms at several
SNR values. For example, as shown in
Figure 4, there are symbol “1”, symbol “2”, and −3dB noised symbol “2”, separately. The main parameters of the improved MPPSK system are
,
,
,
Hz, and a sampling rate of
Hz. When the database was used to detect the improved 4PPSK modulation signal, the training set contained four classes of 60,000 sampled waveforms, and the test set contained four classes of 100,000 sampled noised waveforms at several
SNR values.
5.2. Architecture
In order to obtain a high detection performance, the number of nodes in the hidden layers may be more important than the learning algorithm chosen or the depth of the model. Considering this, we adopted different architectures corresponding to the different MPPSK parameters and then determine the appropriate numbers of the corresponding hidden units. To simplify the problem and focus on the effect of the generated nodes, the stacked architecture is used without pooling and convolution.
The stacked DSAE model proposed for the improved 2PPSK signaling is expressed in forms such as 1050-800-400-200-2, where ‘1050’ indicates 1050 nodes in the input layer; ‘800’ indicates 800 nodes in the first hidden layer; ‘400’ indicates 400 nodes in the second hidden layer; ‘200’ indicates 200 nodes in the third hidden layer; and ‘2’ indicates 2 nodes in the output layer. A 1050-800-400-200-2 network structure means that we train an SAE network of 1050-800-1050 first, then feed forward the input data to the 1050-800 network to obtain the first set of hidden features, and finally train another 800-400-800 network, using 1050-800-400 to obtain the second set of hidden features. After this, we train the 400-200-400 network and use 1050-800-400-200 to obtain the third set of hidden features. After the first SAE network is trained, the activation value of all nodes in the hidden layer is calculated and sent to the second autoencoder as its input. The activation value of each hidden layer is regarded as the extracted features of the original modulation signals. Then, the hierarchical representations of original signals are obtained. Such representations sent to a softmax classifier are effective for detection. Thus, we use softmax to train the 200-2 network, and finally, we cascade all the networks to form the set as 1050-800-400-200-2.
5.3. DSAE Training Optimization
During the pre-training process described above, the parameters of other layers remain fixed when the parameters of one layer are determined. Furthermore, we repeatedly train all unlabeled sample data with randomly initialized weights to minimize the cost function value. Then, the L-BFGS algorithm is employed to solve the non-convex optimization problem of the cost function. For better results, the whole network is fine-tuned using back-propagation and the DAE algorithm and the parameters of the whole network are adjusted.
In order to reduce the training time, we divided all the training samples into many batches, each having 100 samples, and trained with each batch. It was applied to take advantage of the efficient computational techniques available in software and hardware such as matrix multiplication in Matlab.
5.4. Results
5.4.1. Parameters of the Stacked DSAE Network
Using the proposed DSAE model with noisy and noiseless training data, we obtained the detection performance for different numbers of nodes in the hidden layers and different ratios of training and testing sets. The most appropriate ratios of training and testing sets were selected, as well as the stacked network set of the hidden layers.
For 2PPSK, , the ratio of training and testing set is 60,000:10,000 and the corresponding number of nodes in the input layer is 1050 with 2 of these nodes in the output layer. For 4PPSK, ; the ratio of training and testing set is set to 60,000:100,000, and the corresponding number of nodes in the input layer is 100 with 4 of these nodes in the output layer.
The detection performances are compared, assuming different numbers of nodes in the hidden layers. The training datasets are noisy and noiseless, as shown in
Table 1 and
Table 2. H1 is the first hidden layer; H2 is the second hidden layer; H3 is the second hidden layer; ‘−19’ means the channel
dB; ‘(−18) −19’ means the training data
SNR = −18 dB with channel
dB; and ‘(−3) −19’ means training data
dB with channel
dB. The main parameters of the improved MPPSK system are
;
;
;
Hz; sampling rate
Hz; and the ratio of training and testing set is 60,000:10,000. The receiver consists the SIF followed by the stacked DSAE network.
As shown in
Table 1 and
Table 2, the SER values based on training data with
dB are better than that based on the training dataset of −18 dB, the case shown as ‘−3’, ‘−18’. Given this, all experiments below will use the −3 dB noised training data. It is also observed that the detection performance with three hidden layers is better than that with two layers. Therefore, we adopt the combination of hidden layers 600-300-150. This means 600 nodes in the first hidden layer, 300 in the second hidden layer and 150 nodes in the third hidden layer.
5.4.2. SER Performance of the Improved 2PPSK
The main system parameters are ; ; ; Hz; and a sample rate Hz. Corresponding to the set of system parameters, the ratio of the training and testing set is 60,000:10,000, and the structure of stacked DSAE network is 1050-600-300-150-2. There are five layers in the network, with 1050 nodes in the input layer; 600 nodes in the first hidden layer; 300 nodes in the second hidden layer; 150 nodes in the third hidden layer; and 2 nodes in the output layer.
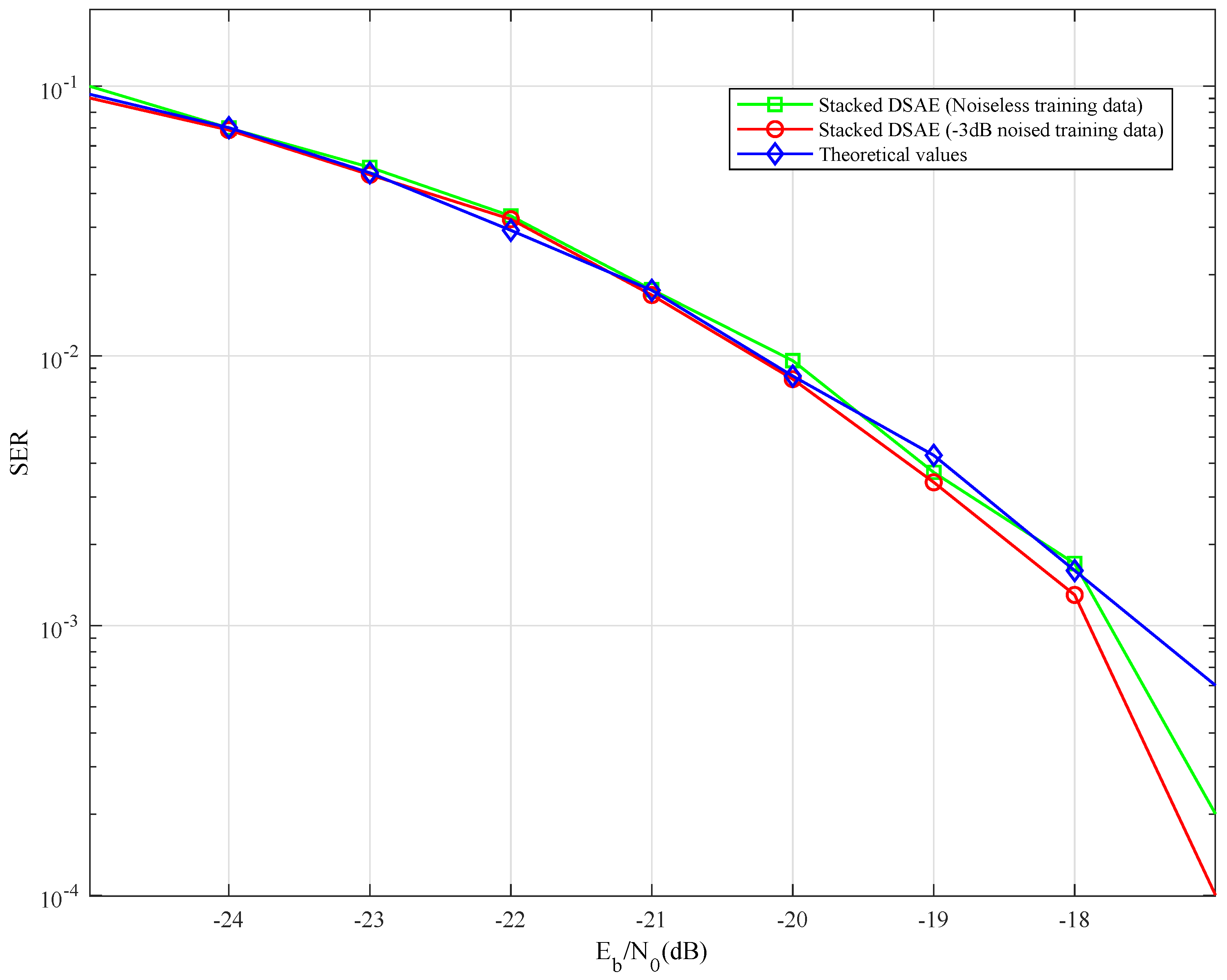
The SER performance of the improved 2PPSK signaling is shown in
Figure 5 where the receiver consists of one SIF followed by the proposed stacked DSAE network. The simulation curves are close to the theoretical curve. The SER simulation values are slightly better than the theoretical values between −17 dB and −18 dB
SNR. This is because the approximate processing is introduced in the calculation of theoretical values in Equation (
10).
This seems to indicate that the result violates the Shannon limit on the
SNR per bit, assuming an unbounded bandwidth. Furthermore, −1.6 dB
SNR with an arbitrarily low error rate is achievable. The result is close to the Shannon limit, with the system parameters are included in the
SNR calculation defined in Equation (
2). The transmission signal based on the
dB noised training data could extract signal features that are closer to reality than the case based on noiseless training data. Thus, the SER performance of the proposed scheme with the case of
dB noised training data is slightly better than that with the case of noiseless training data.
5.4.3. SER Performance of Improved 4PPSK
Compared with BP [
7], SVM [
8] and JAWD [
9], the detection performance of the improved 4PPSK system with the SIF followed by the proposed stacked DSAE network is shown in
Figure 6. The system parameters are
;
;
;
Hz; and a sample rate
Hz, and the training database is noise-free. Corresponding to the set of system parameters, the ratio of the training and testing sets is 60,000:100,000, and the structure of stacked DSAE network is 100-60-20-4. There are four layers in the network, with 100 nodes in the input layer; 60 nodes in the first hidden layer; 20 nodes in the second hidden layer; and 4 nodes in the output layer.
As shown in
Figure 6, the SER of the proposed scheme based on the improved MPPSK modulation in Equation (
1) is better than that based on the existing MPPSK [
5,
6]. It is consistent with the expected results. Furthermore, the proposed scheme performs approximately 3 dB better than the SVM at the SER of
.
We also obtained the performance of the structure that employs the SIF, a coherent processing block, and LPF followed by the proposed stacked DSAE network in the receiver. The major system parameters are the same as above, except that the training database contains both noiseless and
dB noised datasets. The performances of the BP, SVM, JAWD detectors, and this stacked DSAE network are shown in
Figure 6, separately.
The stacked DSAE network, based on both the noisy training database and noiseless training database, performs the best in
Figure 7. In the proposed scheme, the performance with
dB noised training database is approximately 5 dB better than that with the noiseless training database at the SER of
. This is consistent with the results in
Table 1 and
Table 2 and
Figure 5. This is because, in the case of the
dB, noised training data can be extracted with more signal features than with the noiseless training data.
Compared with the SER performance of the 4PPSK system with only SIF in
Figure 6, the required
SNR is reduced by approximately 2 dB at the SER of
in the structure with an SIF, a coherent processing block and an LPF in
Figure 7.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}