
Machine-Learning-Based Uplink Throughput Prediction from Physical Layer Measurements


Abstract
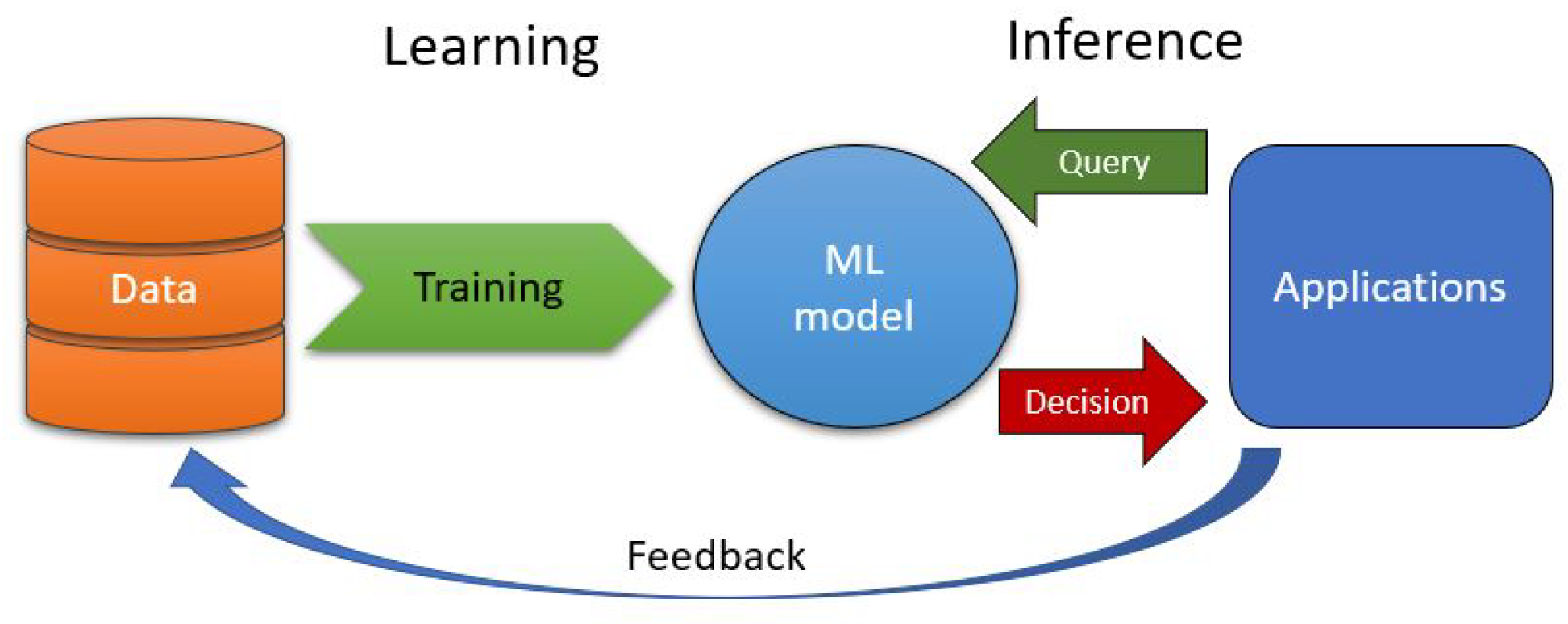
1. Introduction
2. Literature Review
3. Understanding Machine Learning Algorithms
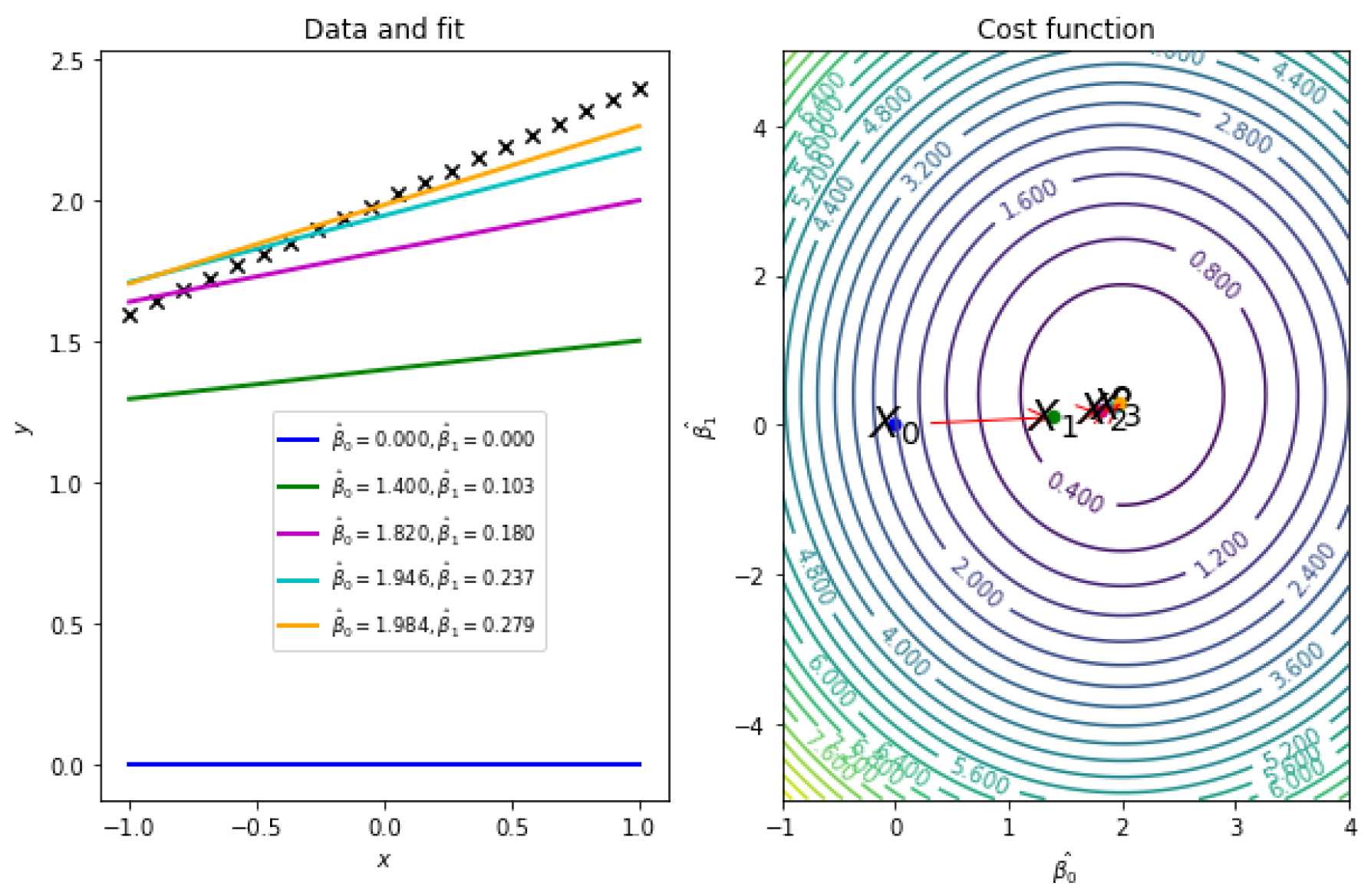
3.1. Linear Regression
3.2. Gradient Descent
| Algorithm 1 The Gradient Descent Algorithm |
| for do end for |
3.3. Gradient Boosting Regression
| Algorithm 2 The GBR Algorithm |
| 1. Initialize model with a constant value: 2. i=1:M 1. Compute the so-called pseudo-residuals: 3. Fit a weak learner to pseudo-residuals, i.e., train it using the training set 4. Compute multiplier by solving the following one-dimensional optimization problem: 5. Update the model: 6. Output where is an intended function. represents the learning rate. |
3.4. Decision Tree Regression (DTR)
3.5. K-Nearest Neighbors (KNN)
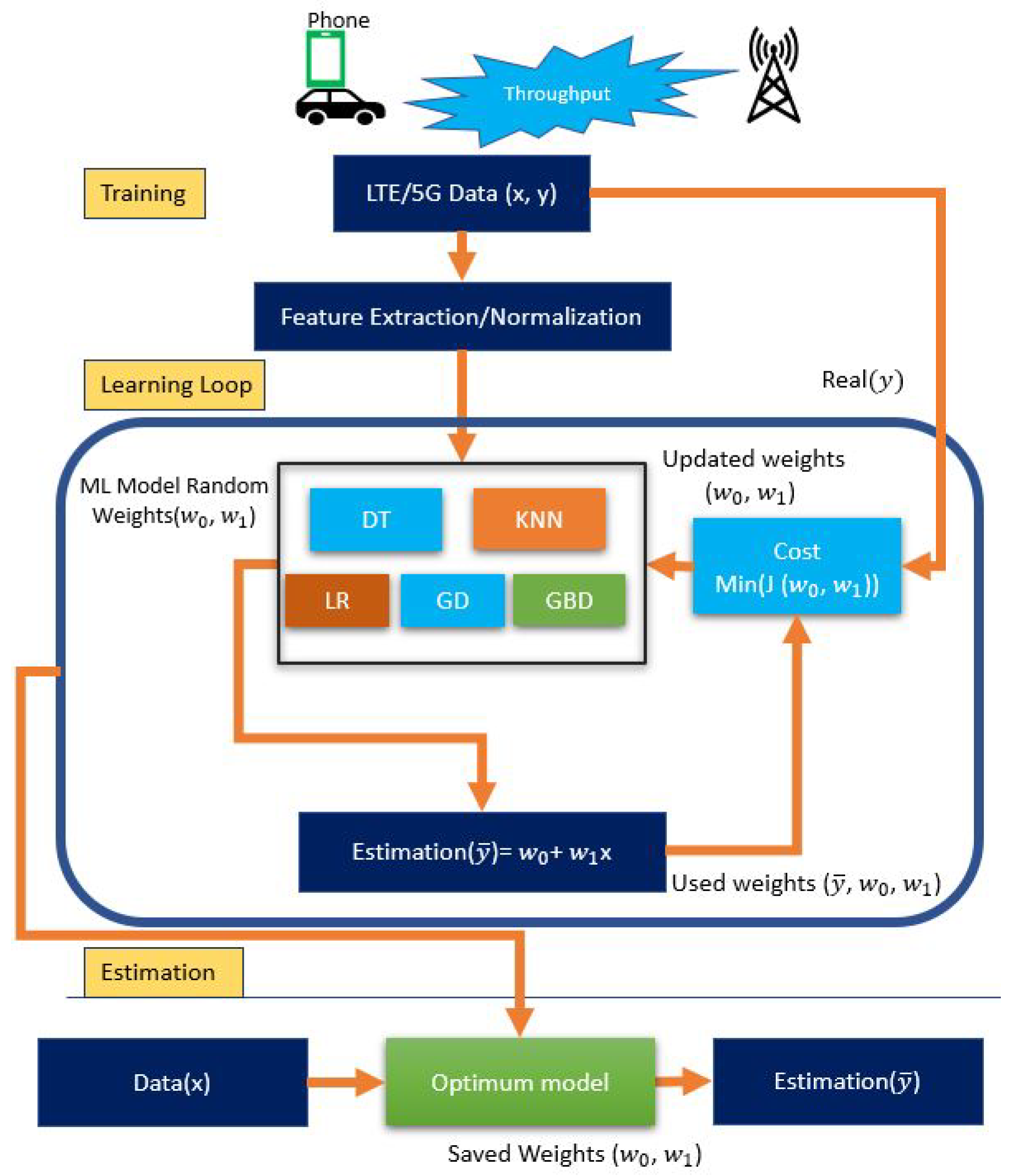
4. Modeling Uplink Throughput Prediction
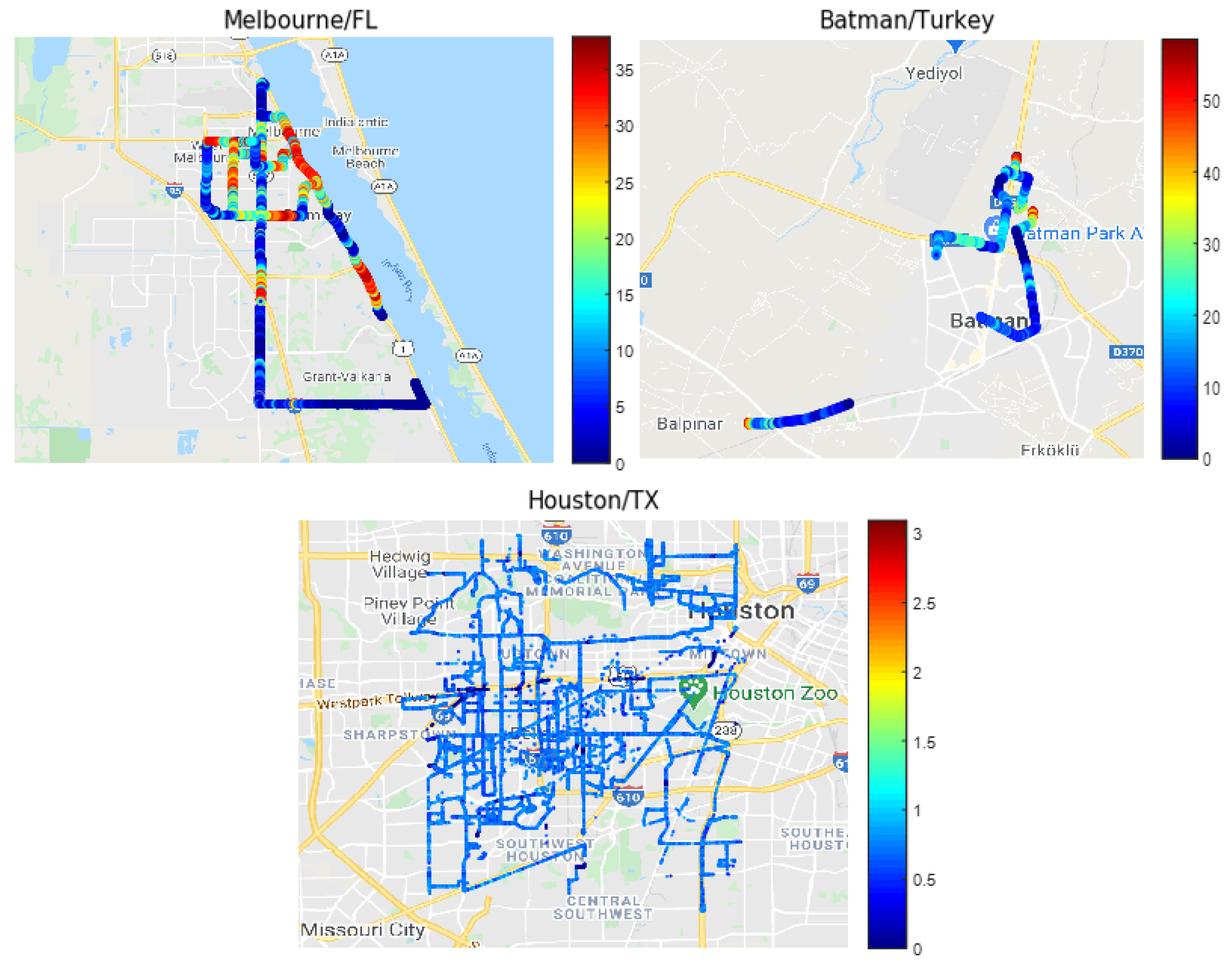
4.1. Data Collection
- RSRP (reference signal received power) is the average power of cell-specific signals in the channel bandwidth. RSRP is used for cell selection and coverage since it has signal strength information. The range of RSRP values is between −140 dBm and −44 dBm;
- RSRQ (received signal received quality) indicates the quality of the signal;
- SNR (signal-to-noise ratio) is used directly in the modulation and coding scheme to select one in 77 modulation schemes.
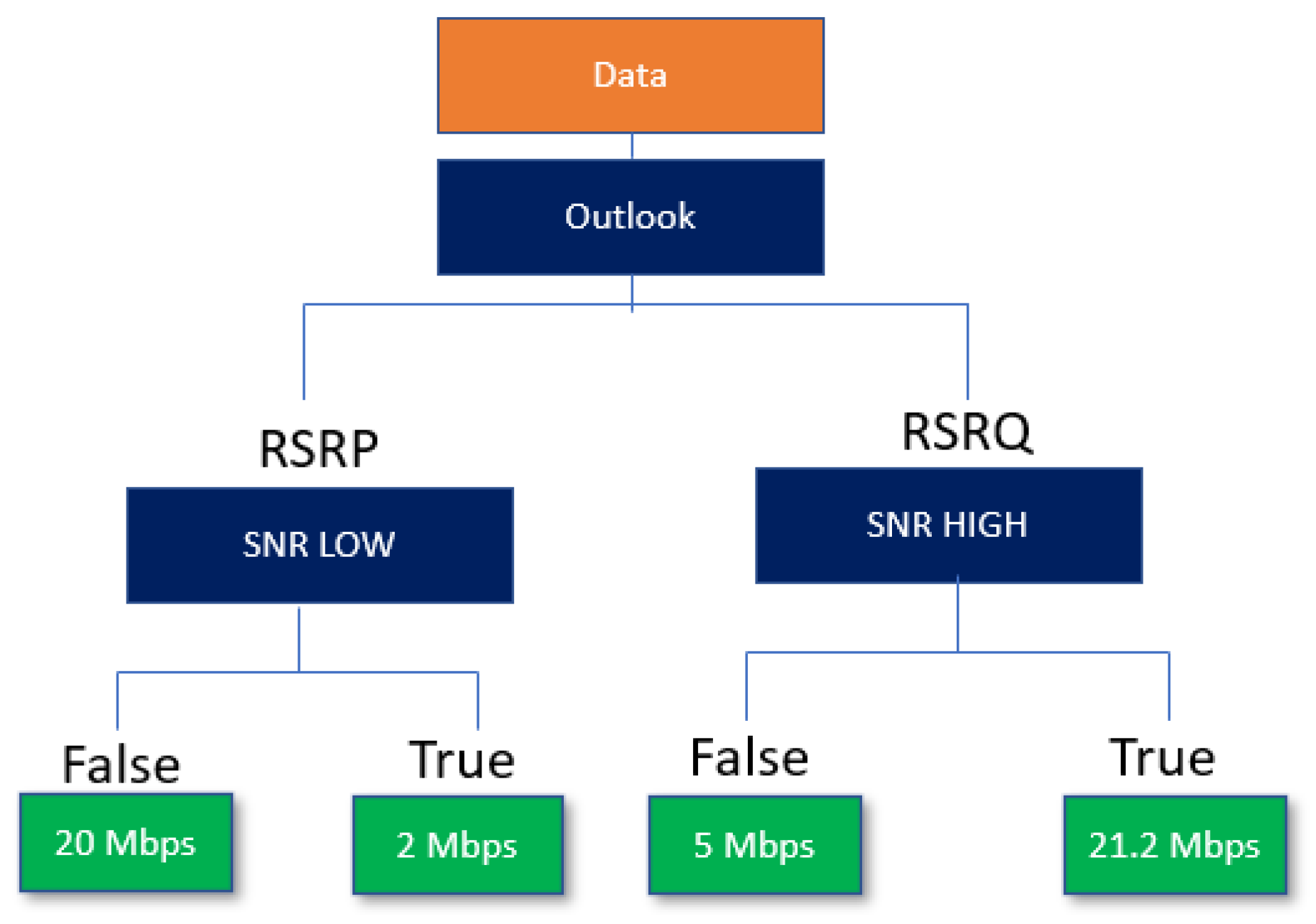
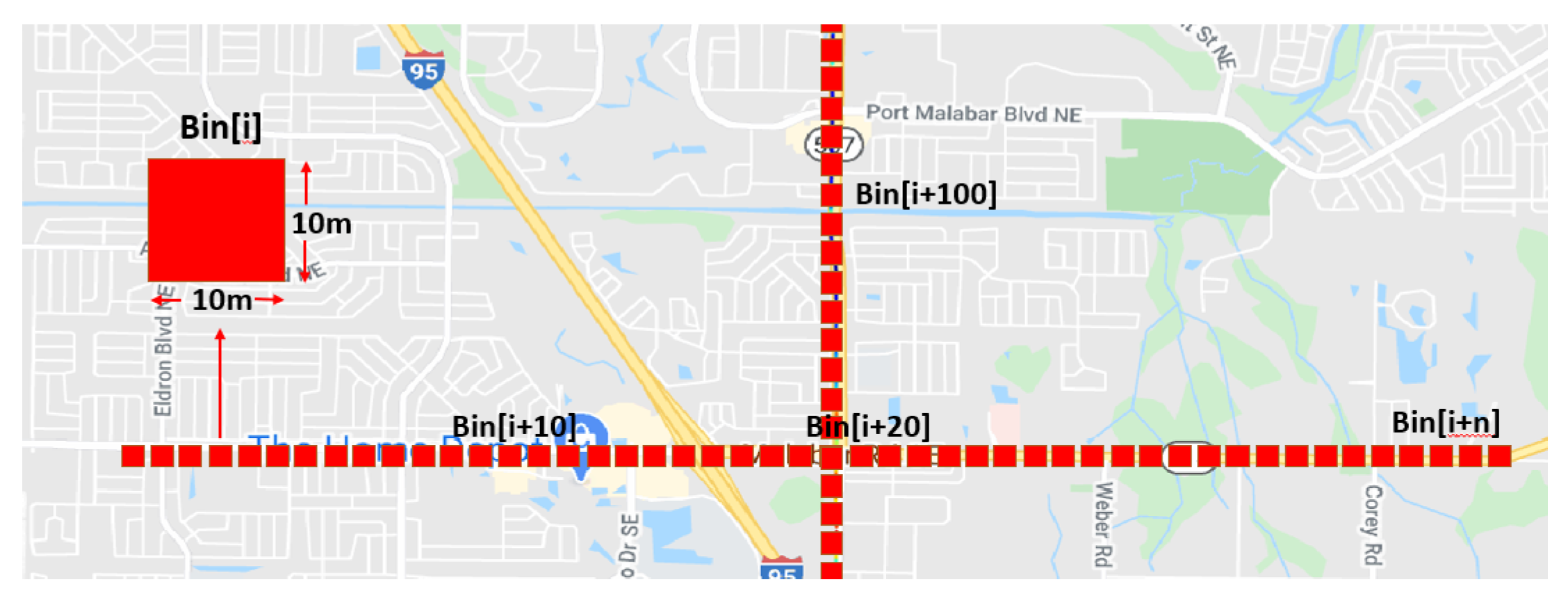
4.2. Data Binning
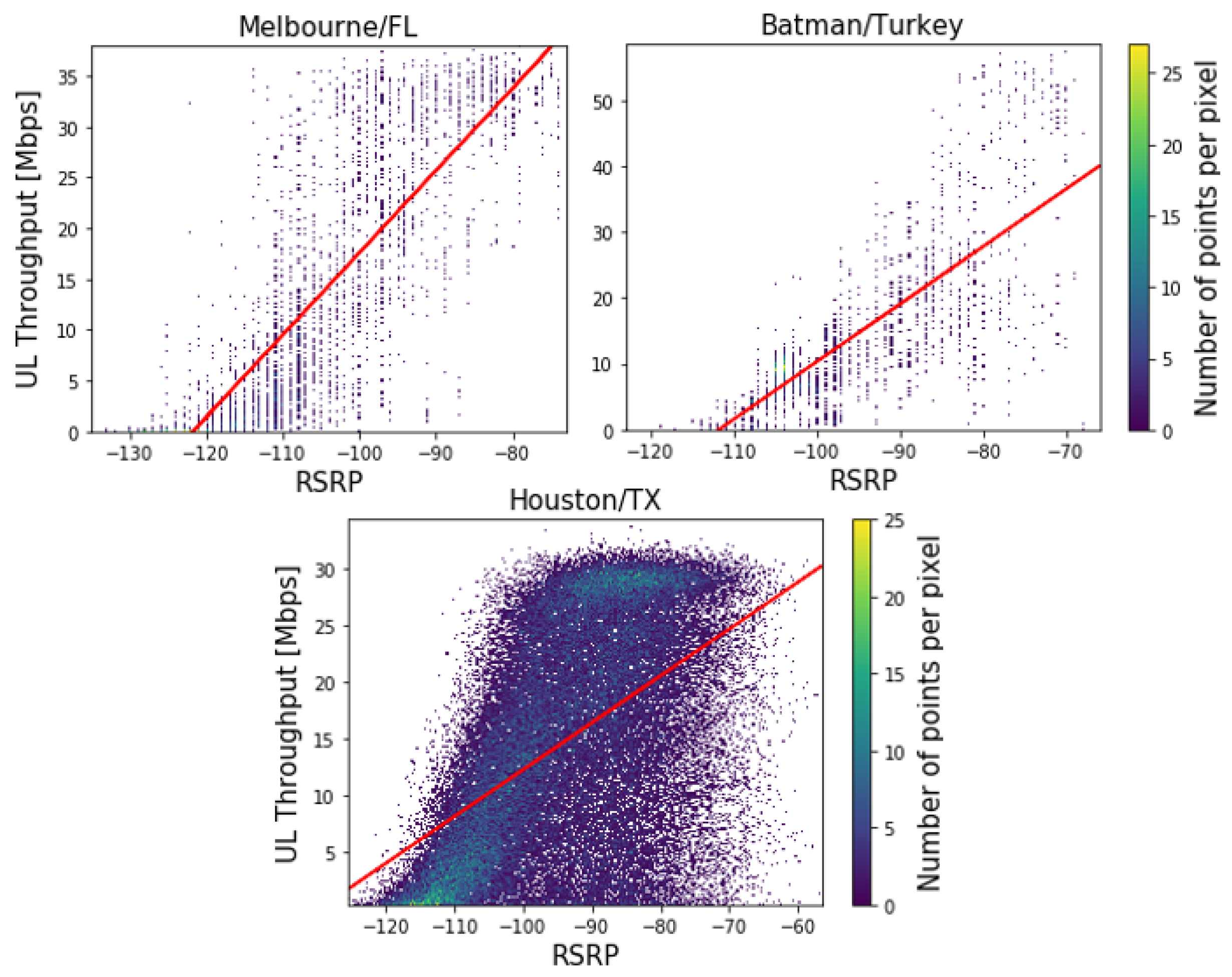
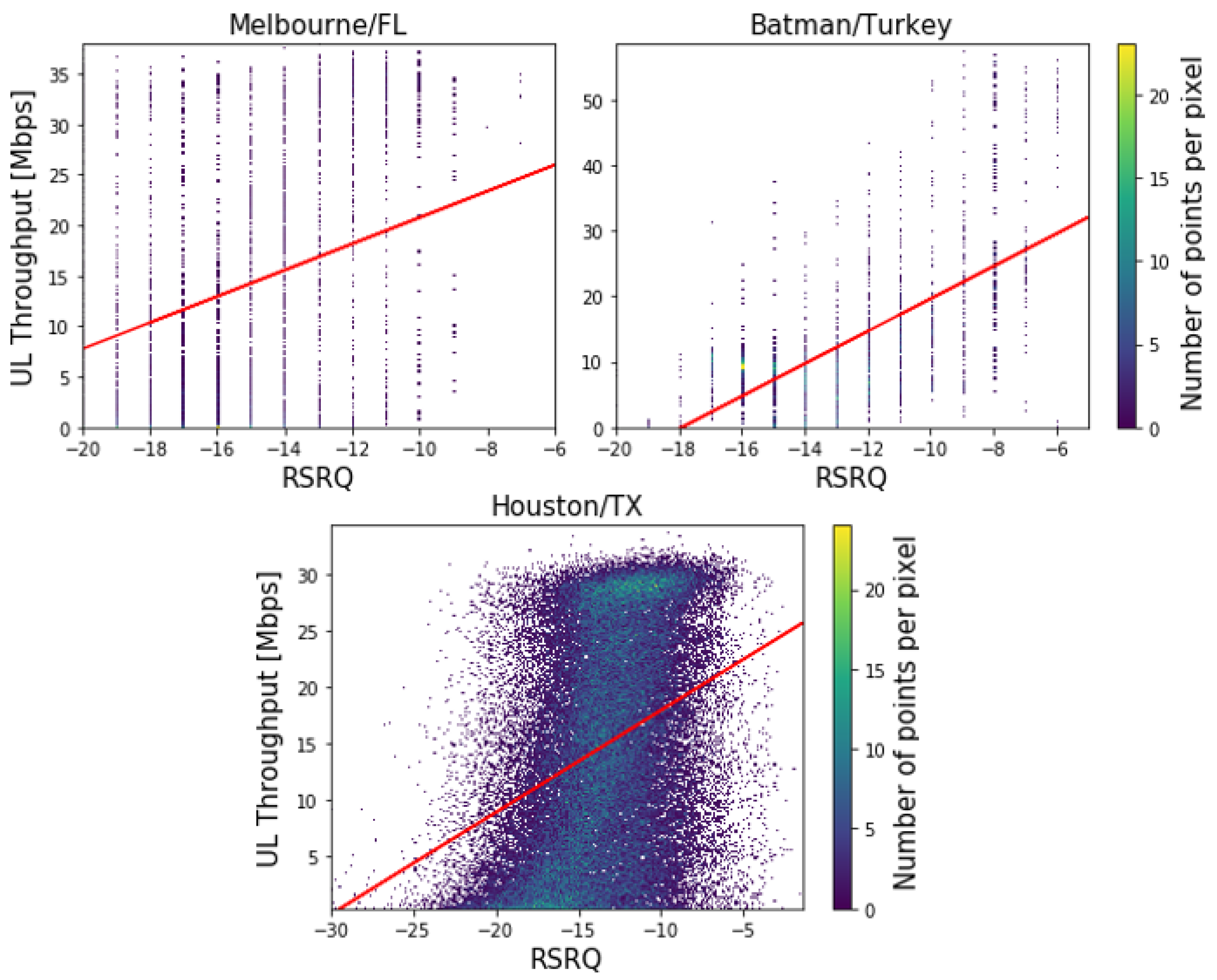
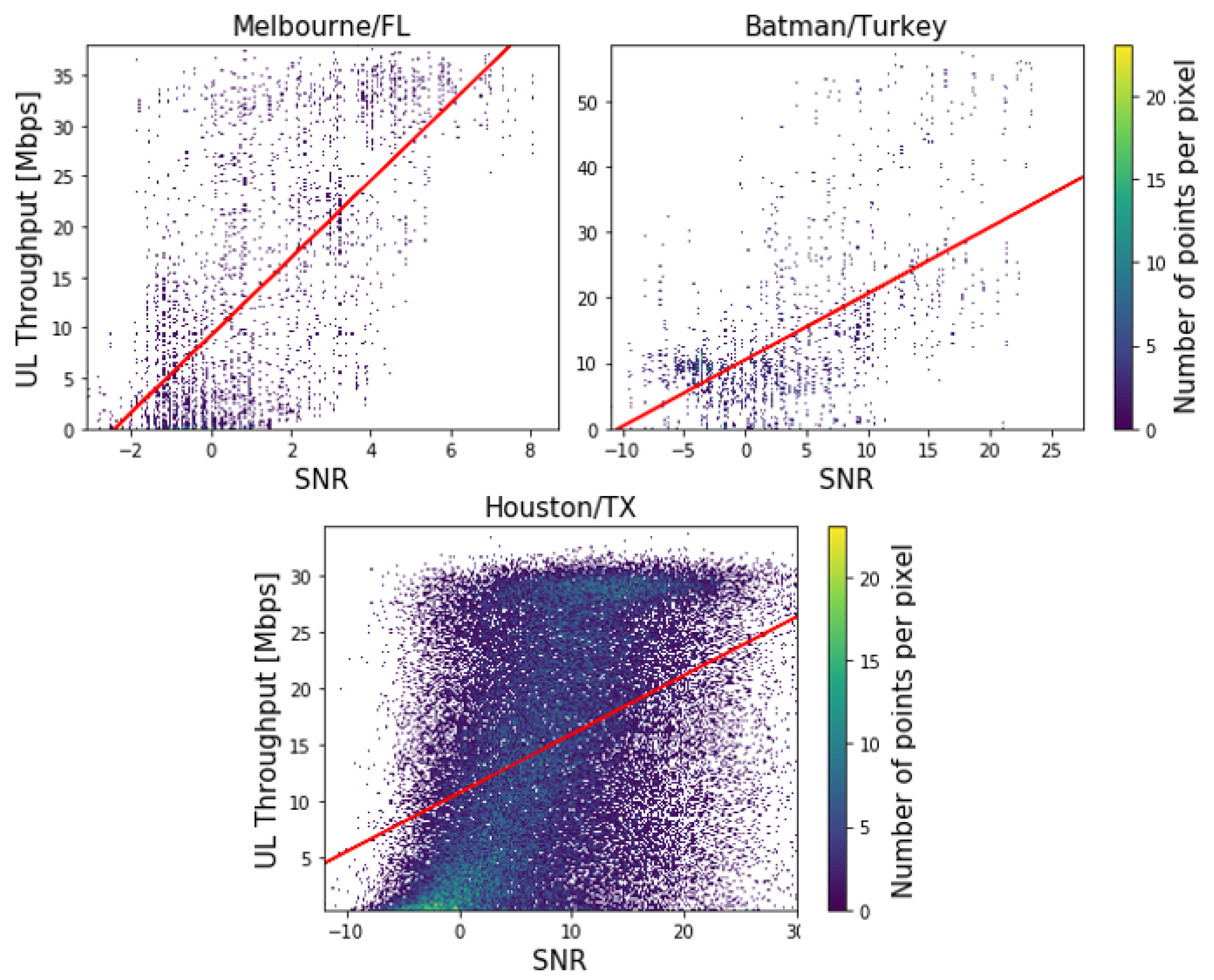
4.3. Correlation Analysis
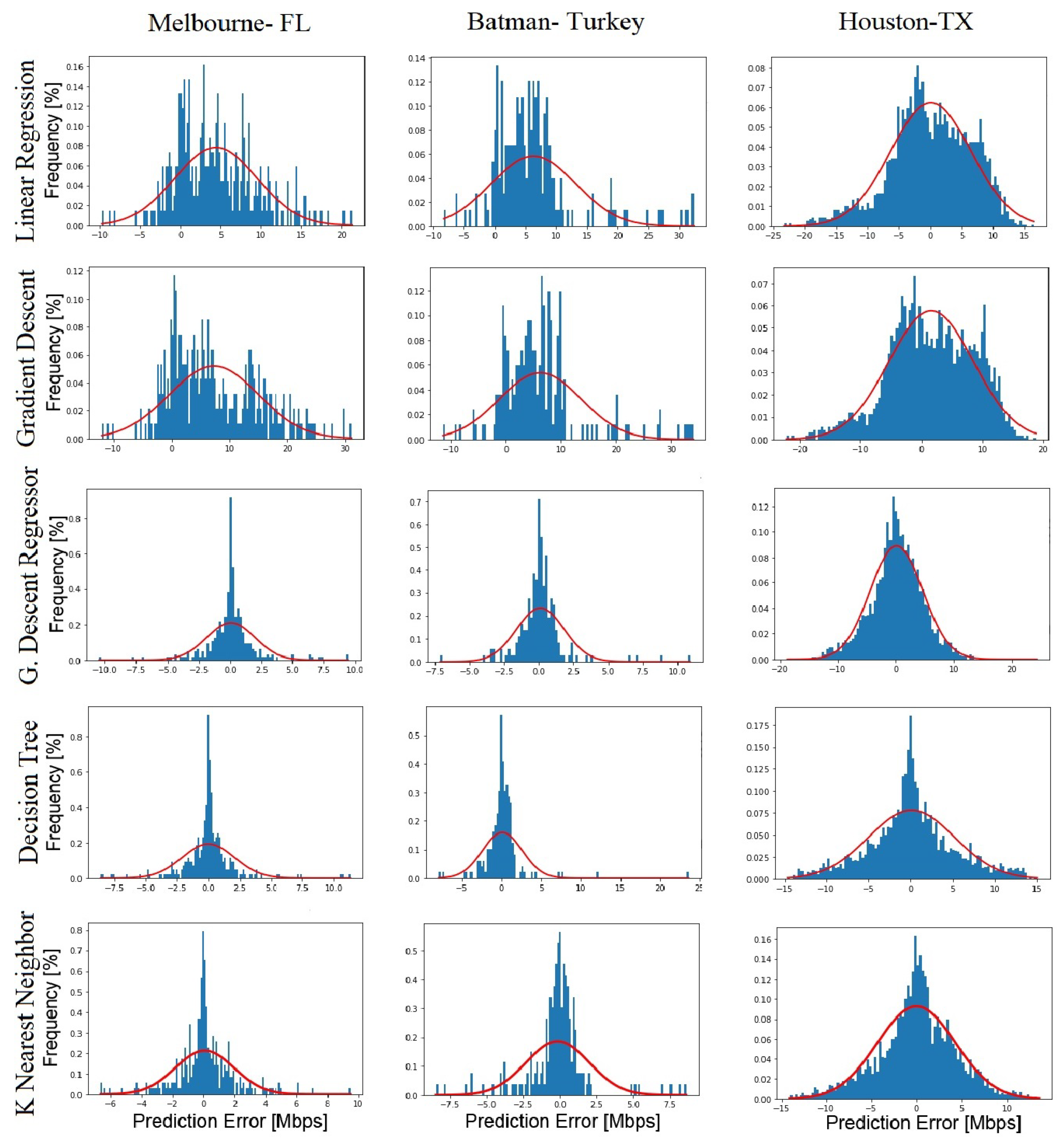
5. Prediction Results and Analysis
6. Limitation and Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LTE | Long Term Evolution |
| RSRP | Reference Signal Received Power |
| RSRQ | Reference Signal Received Quality |
| SNR | Signal to Noise Ratio |
| UL | Uplink |
| DL | Downlink |
| KNN | K-Nearest Neighbor |
| 4G | 4th Generation |
| 5G | 5th Generation |
| GSM | Global System for Mobile Communications |
| OFDM | Orthogonal Frequency Division Multiple Access |
| QAM | Quadrature Amplitude Modulation |
| Iot | Internet of Things |
| ML | Machine Learning |
| ANN | Artificail Neural Network |
| QoS | Quality of Service |
| SON | Self Organizing Network |
| DT | Decision Trees |
| GBR | Gradient Boosting Regression |
References
- Kim, Y.; Kim, Y.; Oh, J.; Ji, H.; Yeo, J.; Choi, S.; Ryu, H.; Noh, H.; Kim, T.; Lee, J.; et al. New Radio (NR) and its Evolution toward 5G-Advanced. IEEE Wirel. Commun. 2019, 26, 2–7. [Google Scholar] [CrossRef]
- Hajlaoui, E.; Khlifi, A.; Zaier, A.; Ghodhbane, J.; Hamed, M.B.; Sbita, L. Performance Evaluation of LTE Physical Layer. In Proceedings of the 2019 International Conference on Internet of Things, Embedded Systems and Communications (IINTEC), Tunis, Tunisia, 20–22 December 2019; pp. 106–111. [Google Scholar] [CrossRef]
- Singh, H.; Prasad, R.; Bonev, B. The Studies of Millimeter Waves at 60 GHz in Outdoor Environments for IMT Applications: A State of Art. Wireless Pers. Commun. 2018, 100, 463–474. [Google Scholar] [CrossRef]
- Isyaku, B.; Mohd Zahid, M.S.; Bte Kamat, M.; Abu Bakar, K.; Ghaleb, F.A. Software Defined Networking Flow Table Management of OpenFlow Switches Performance and Security Challenges: A Survey. Future Internet 2020, 12, 147. [Google Scholar] [CrossRef]
- Lutu, A.; Perino, D.; Bagnulo, M.; Frias-Martinez, E.; Khangosstar, J. A Characterization of the COVID-19 Pandemic Impact on a Mobile Network Operator Traffic. In Proceedings of the IMC ’20: ACM Internet Measurement Conference, Virtual Event, USA, 27–29 October 2020. [Google Scholar]
- Edler, G.; Wang, L.; Horiuchi, A. Special Subframe Configuration for Latency Reduction. U.S. Patent Application No. 16/089,279, 26 October 2021. [Google Scholar]
- Rayal, F. LTE in a Nutshell. 2020. Available online: https://home.zhaw.ch/kunr/NTM1/literatur/LTE%20in%20a%20Nutshell%20-%20Physical%20Layer.pdf (accessed on 24 October 2020).
- Teng, Y.; Yan, M.; Liu, D.; Han, Z.; Song, M. Distributed Learning Solution for Uplink Traffic Control in Energy Harvesting Massive Machine-Type Communications. IEEE Wirel. Commun. Lett. 2020, 9, 485–489. [Google Scholar] [CrossRef]
- Kim, T.; Jung, B.C. Performance Analysis of Grant-Free Multiple Access for Supporting Sporadic Traffic in Massive IoT Networks. IEEE Access 2019, 7, 166648–166656. [Google Scholar] [CrossRef]
- Kim, T.; Song, T.; Kim, W.; Pack, S. Phase-Divided MAC Protocol for Integrated Uplink and Downlink Multiuser MIMO WLANs. IEEE Trans. Veh. Technol. 2018, 67, 3172–3185. [Google Scholar] [CrossRef]
- Xu, C.; Wu, M.; Xu, Y.; Xu, Y. Shortest Uplink Scheduling for NOMA-Based Industrial Wireless Networks. IEEE Syst. J. 2020, 14, 5384–5395. [Google Scholar] [CrossRef]
- Ma, Z.; Feng, L.; Wang, Z. Supporting Asymmetric Transmission for Full-Duplex Smart-Home Networks. IEEE Access 2019, 7, 34807–34822. [Google Scholar] [CrossRef]
- Sun, K.; Wu, J.; Huang, W.; Zhang, H.; Hsieh, H.-Y.; Leung, V.C.M. Uplink Performance Improvement for Downlink-Uplink Decoupled HetNets with Non-Uniform User Distribution. IEEE Trans. Veh. Technol. 2020, 69, 7518–7530. [Google Scholar] [CrossRef]
- Jiménez, L.R.; Solera, M.; Toril, M.; Luna-Ramírez, S.; Bejarano-Luque, J.L. The Upstream Matters: Impact of Uplink Performance on YouTube 360° Live Video Streaming in LTE. IEEE Access 2021, 9, 123245–123259. [Google Scholar] [CrossRef]
- Homssi, B.A.; Al-Hourani, A. Modeling Uplink Coverage Performance in Hybrid Satellite-Terrestrial Networks. IEEE Commun. Lett. 2021, 25, 3239–32431. [Google Scholar] [CrossRef]
- Ali, S.; Rajatheva, N.; Saad, W. Fast Uplink Grant for Machine Type Communications: Challenges and Opportunities. IEEE Commun. Mag. 2019, 57, 97–103. [Google Scholar] [CrossRef]
- Shen, H.; Ye, Q.; Zhuang, W.; Shi, W.; Bai, G.; Yang, G. Drone-Small-Cell-Assisted Resource Slicing for 5G Uplink Radio Access Networks. IEEE Trans. Veh. Technol. 2021, 70, 7071–7086. [Google Scholar] [CrossRef]
- Ruan, L.; Dias, M.P.I.; Wong, E. SmartBAN With Periodic Monitoring Traffic: A Performance Study on Low Delay and High Energy Efficiency. IEEE J. Biomed. Health Inform. 2018, 22, 471–482. [Google Scholar] [CrossRef]
- Carson, S.; Lundvall, A. Mobility on The Pulse of The Networked Society; Ericsson: Stockholm, Sweden, 2016; pp. 1–36. [Google Scholar]
- Kato, N.; Mao, B.; Tang, F.; Kawamoto, Y.; Liu, J. Ten Challenges in Advancing Machine Learning Technologies toward 6G. IEEE Wirel. Commun. 2020, 27, 96–103. [Google Scholar] [CrossRef]
- Egi, Y.; Otero, C.E. Machine-Learning and 3D Point-Cloud Based Signal Power Path Loss Model for the Deployment of Wireless Communication Systems. IEEE Access 2019, 7, 42507–42517. [Google Scholar] [CrossRef]
- Ray, P.P.; Nguyen, K. A Review on Blockchain for Medical Delivery Drones in 5G-IoT Era: Progress and Challenges. In Proceedings of the 2020 IEEE/CIC International Conference on Communications in China (ICCC Workshops), Chongqing, China, 9–11 August 2020; pp. 29–34. [Google Scholar] [CrossRef]
- Yue, C.; Jin, R.; Suh, K.; Qin, Y.; Wang, B.; Wei, W. LinkForecast: Cellular Link Bandwidth Prediction in LTE Networks. IEEE Trans. Mob. Comput. 2018, 17, 1582–1594. [Google Scholar] [CrossRef]
- Jomrich, F.; Herzberger, A.; Meuser, T.; Richerzhagen, B.; Steinmetz, R.; Wille, C. Cellular bandwidth prediction for highly automated driving evaluation of machine learning approaches based on real-world data. In Proceedings of the VEHITS 2018—International Conference on Vehicle Technology and Intelligent Transport Systems, Funchal-Madeira, Portugal, 16–18 March 2018; pp. 121–132. [Google Scholar]
- Bojovic, B.; Meshkova, E.; Baldo, N.; Riihijarvi, J.; Petrova, M. Machine learning-based dynamic frequency and bandwidth allocation in self-organized LTE dense small cell deployments. Eurasip J. Wirel. Commun. Netw. 2016, 2016, 1–16. [Google Scholar] [CrossRef]
- Oussakel, I.; Owezarski, P.; Berthou, P. Experimental Estimation of LTE-A Performance. In Proceedings of the 2019 15th International Conference on Network and Service Management (CNSM), Halifax, NS, Canada, 21–25 October 2019. [Google Scholar]
- Awad, W.A.; ELseuofi, S.M. Machine Learning methods for E-mail Classification. Int. J. Comput. Appl. 2011, 16, 39–45. [Google Scholar] [CrossRef][Green Version]
- Hasan, M.; Islam, M.M.; Zarif, M.I.I.; Hashem, M.M.A. Attack and anomaly detection in IoT sensors in IoT sites using machine learning approaches. Internet Things 2019, 7, 100059. [Google Scholar] [CrossRef]
- Olukan, T.A.; Chiou, Y.C.; Chiu, C.H.; Lai, C.Y.; Santos, S.; Chiesa, M. Predicting the suitability of lateritic soil type for low cost sustainable housing with image recognition and machine learning techniques. J. Build. Eng. 2000, 29, 101175. [Google Scholar] [CrossRef]
- Ketkar, N. Stochastic Gradient Descent. In Deep Learning with Python; Apress: Berkeley, CA, USA, 2017; pp. 113–132. [Google Scholar]
- Li, C. A Gentle Introduction to Gradient Boosting. 2016. Available online: http://www.ccs.neu.edu/home/vip/teach/MLcourse/4boosting/slides/gradient-boosting.pdf (accessed on 5 November 2021).
- Wang, F.; Wang, Q.; Nie, F.; Li, Z.; Yu, W.; Ren, F. A linear multivariate binary decision tree classifier based on K-means splitting. Pattern Recognit. 2020, 107, 107521. [Google Scholar] [CrossRef]
- Kramer, O. K-Nearest Neighbors. In Dimensionality Reduction with Unsupervised Nearest Neighbors. In Intelligent Systems Reference Library; Springer: Berlin/Heidelberg, 2013; Volume 51. [Google Scholar] [CrossRef]
- SinghAn, A. K-Nearest Neighbors Algorithm: KNN Regression Python. 2020. Available online: https://www.analyticsvidhya.com/blog/2018/08/k-nearest-neighbor-introduction-regression-python/ (accessed on 4 November 2020).
- Christodoulou, C.; Moorby, J.M.; Tsiplakou, E.; Kantas, D.; Foskolos, A. Evaluation of nitrogen excretion equations for ryegrass pasture-fed dairy cows. Animal 2021, 15, 100311. [Google Scholar] [CrossRef] [PubMed]
- Egi, Y.; Eyceyurt, E.; Kostanic, I.; Otero, C.E. An Efficient Approach for Evaluating Performance in LTE Wireless Networks. In Proceedings of the International Conference on Wireless Networks (ICWN); The Steering Committee of the World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp): Las Vegas, NV, USA, 2017; pp. 48–54. [Google Scholar]
- Mehta, D.S.; Chen, S. A spearman correlation based star pattern recognition. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Correlation with UL Throughput | LTE Parameters | ||
|---|---|---|---|
| RSRP | RSRQ | SNR | |
| Batman/Turkey | 0.72 | 0.46 | 0.52 |
| Melbourne/FL/USA | 0.85 | 0.29 | 0.62 |
| Houston/TX/USA | 0.65 | 0.42 | 0.53 |
| ML Algorithms | Melbourne | Batman | Houston | |||
|---|---|---|---|---|---|---|
| RMSE | RMSE | RMSE | ||||
| LR | 0.75 | 6.48 | 0.71 | 6.21 | 0.51 | 10.18 |
| GD | 0.75 | 6.44 | 0.71 | 6.16 | 0.51 | 10.03 |
| GBR | 0.91 | 3.81 | 0.86 | 4.12 | 0.66 | 8.08 |
| DTR | 0.92 | 3.74 | 0.86 | 4.13 | 0.67 | 8.19 |
| KNN | 0.92 | 3.76 | 0.85 | 4.24 | 0.69 | 6.60 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eyceyurt, E.; Egi, Y.; Zec, J. Machine-Learning-Based Uplink Throughput Prediction from Physical Layer Measurements. Electronics 2022, 11, 1227. https://doi.org/10.3390/electronics11081227
Eyceyurt E, Egi Y, Zec J. Machine-Learning-Based Uplink Throughput Prediction from Physical Layer Measurements. Electronics. 2022; 11(8):1227. https://doi.org/10.3390/electronics11081227
Chicago/Turabian StyleEyceyurt, Engin, Yunus Egi, and Josko Zec. 2022. "Machine-Learning-Based Uplink Throughput Prediction from Physical Layer Measurements" Electronics 11, no. 8: 1227. https://doi.org/10.3390/electronics11081227
APA StyleEyceyurt, E., Egi, Y., & Zec, J. (2022). Machine-Learning-Based Uplink Throughput Prediction from Physical Layer Measurements. Electronics, 11(8), 1227. https://doi.org/10.3390/electronics11081227