
RobustSTL and Machine-Learning Hybrid to Improve Time Series Prediction of Base Station Traffic


Abstract
:1. Introduction
- We propose a single traffic load prediction model of the base station based on RobustSTL and 1DCNN-GRU. This method can extract dynamics patterns of traffic data and more accurately predict the base station traffic;
- The main contribution is the hybrid model of the decomposition of time series data using RobustSTL technique, instead of the standard STL, with 1DCNN-GRU;
- The proposed model can give the reference for sleeping control operation in the base station by estimating the future internet traffic.
2. Materials and Methods
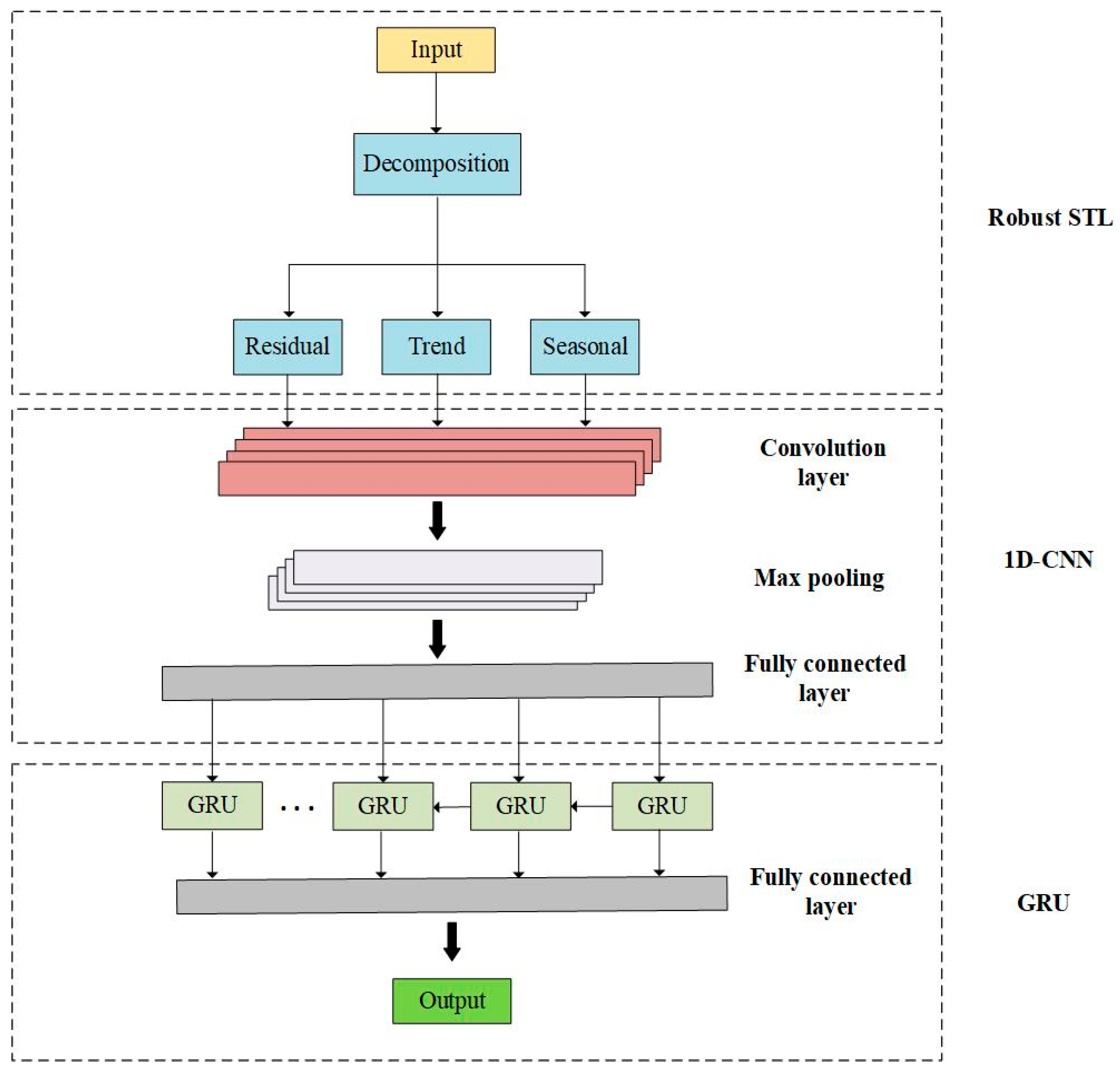
2.1. RobustSTL and 1DCNN-GRU
2.2. Standard STL
2.3. RobustSTL
| Algorithm 1: RobustSTL decomposition summary. |
| Input: , parameter configuration |
| Output: |
| 1: Denoise the network traffic data by bilateral filtering to obtain denoised data |
| 2: Obtain the relative trend and apply this equation to denoised data |
| 3: Perform the seasonality extraction to using non-local seasonal filtering to obtain |
| value |
| 4: Obtain trend, seasonality, and residual components |
| , , |
| 5: Repeat steps 1–4 to obtain more accurate estimation |
2.4. 1DCNN
2.4.1. Convolutional Layer
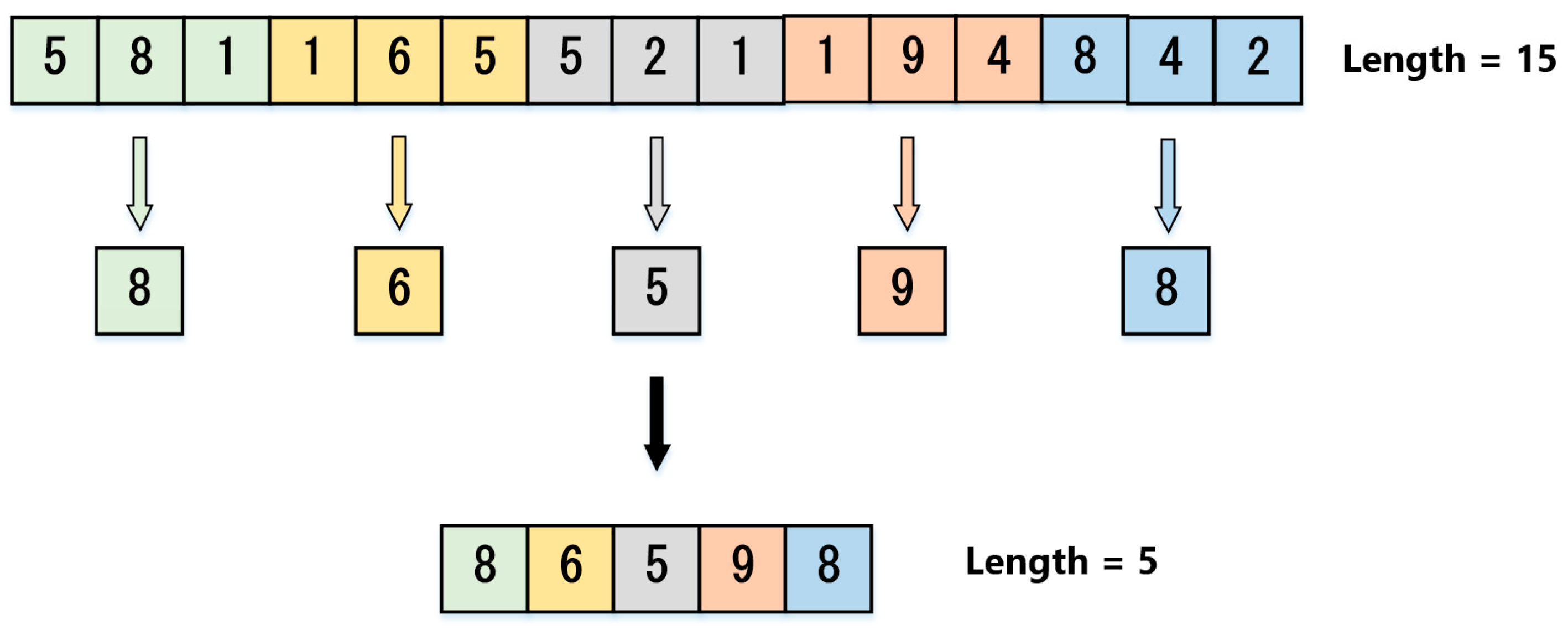
2.4.2. Max Pooling Layer
2.4.3. Fully Connected Layer
2.5. GRU
3. Numerical Results and Performance Analysis
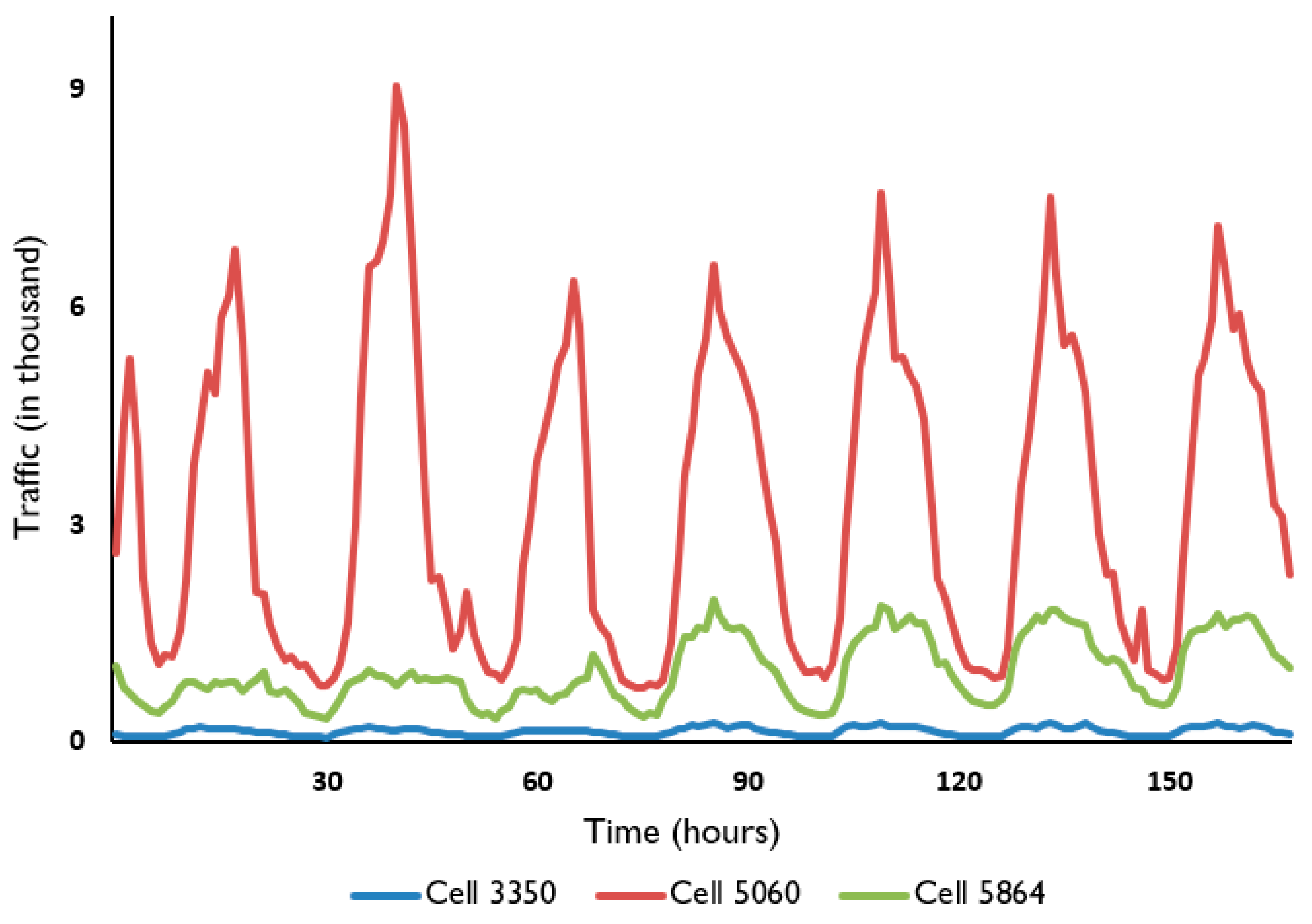
3.1. Preparation Stage
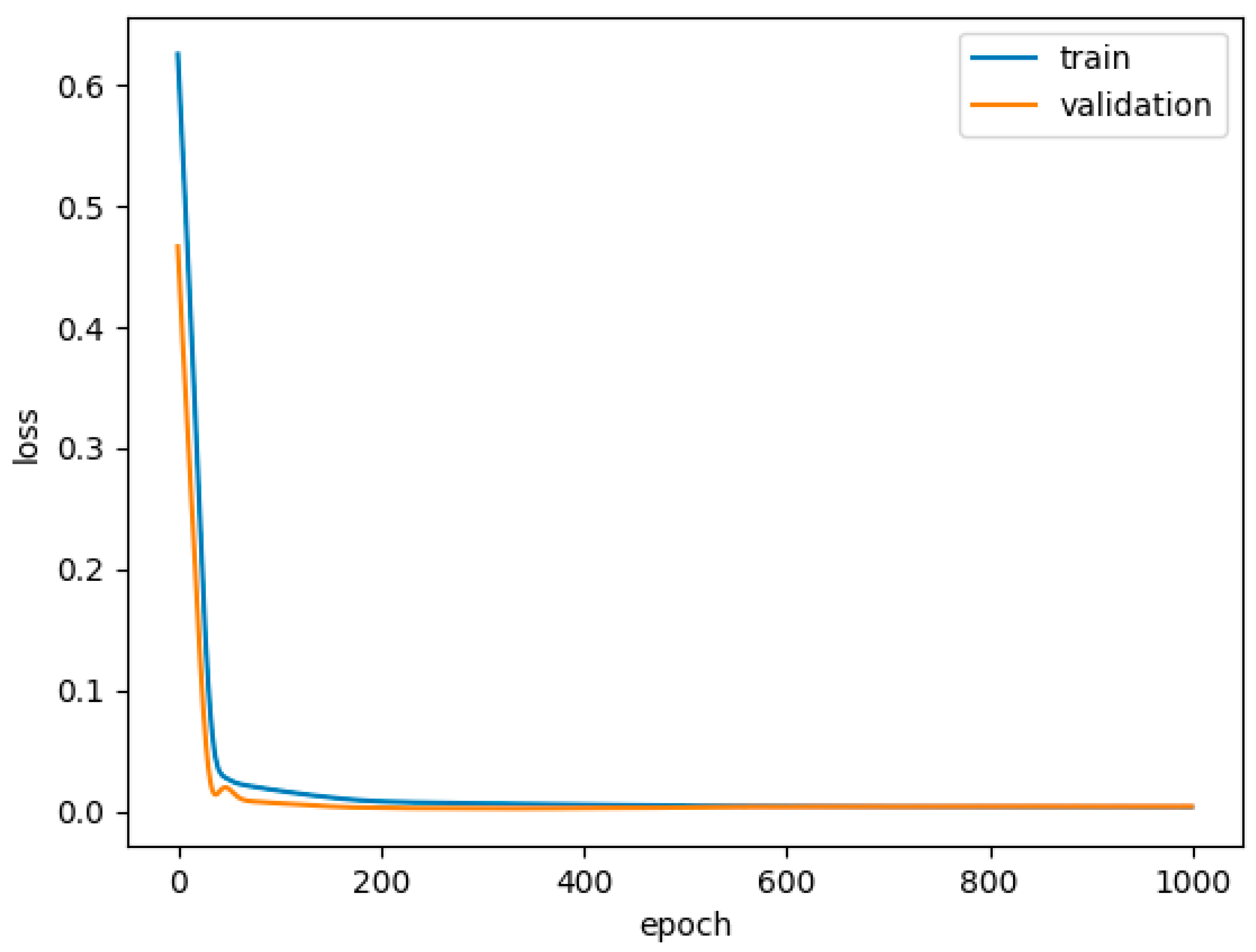
3.2. Training Process
3.3. Evaluation Metrics
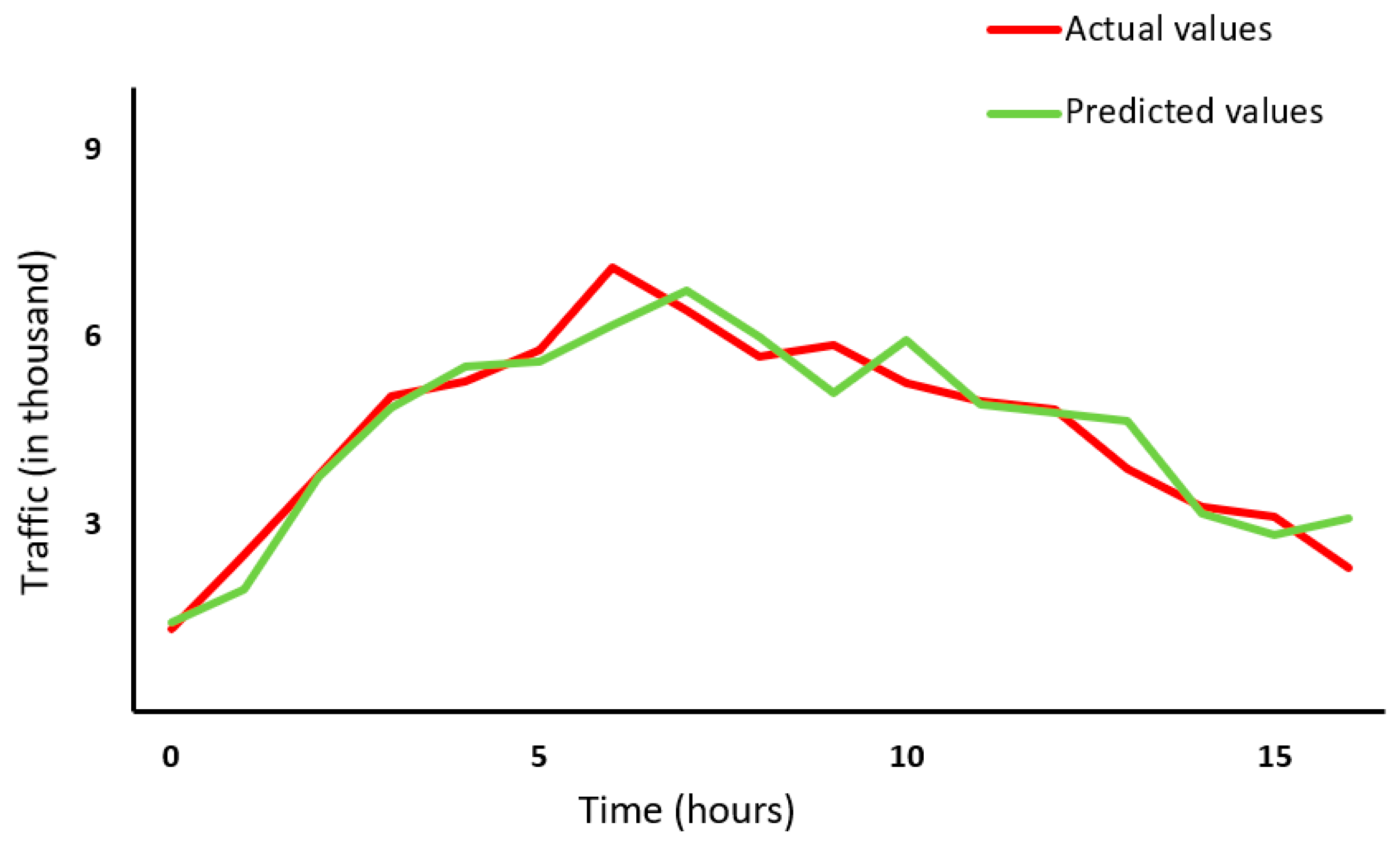
3.4. Results and Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, S.; Zhao, S.; Yuan, M.; Zeng, J.; Yao, J.; Lyu, M.R.; King, I. Traffic prediction based power saving in cellular networks. In Proceedings of the 25th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Los Angeles, CA, USA, 7–10 November 2017; Association for Computing Machinery: New York, NY, USA, 2017. No. 29. pp. 1–10. [Google Scholar]
- Yang, H. Wavelet neural network with SOA based on dynamic adaptive search step size for network traffic prediction. Optik 2020, 224, 165322. [Google Scholar] [CrossRef]
- Li, M.; Wang, Y.; Wang, Z.; Zheng, H. A deep learning method based on an attention mechanism for wireless network traffic prediction. Ad Hoc Netw. 2020, 107, 102258. [Google Scholar] [CrossRef]
- Bao, X.; Jiang, D.; Yang, X.; Wang, H. An improved deep belief network for traffic prediction considering weather factors. Alex. Eng. J. 2021, 60, 413–420. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, H.; Tang, Q.; Dong, P.; Zhao, Z.; Wei, Y.; Mei, J.; Xue, K. LNTP: An End-to-End Online Prediction Model for Network Traffic. IEEE Netw. 2021, 35, 226–233. [Google Scholar] [CrossRef]
- Aldhyani, T.H.H.; Alrasheedi, M.; Alqarni, A.A.; Alzahrani, M.Y.; Bamhdi, A.M. Intelligent Hybrid Model to Enhance Time Series Models for Predicting Network Traffic. IEEE Access 2020, 8, 130431–130451. [Google Scholar] [CrossRef]
- Zheng, X.; Lai, W.; Chen, H.; Fang, S. Data Prediction of Mobile Network Traffic in Public Scenes by SOS-vSVR Method. Sensors 2020, 20, 603. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sebastian, K.; Gao, H.; Xing, X. Utilizing an Ensemble STL Decomposition and GRU Model for Base Station Traffic Forecasting. In Proceedings of the 59th Annual Conference of the Society of Instrument and Control Engineers of Japan (SICE), Chiang Mai, Thailand, 23–26 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 314–319. [Google Scholar]
- Wang, W.; Zhou, C.; He, H.; Wu, W.; Zhuang, W.; Shen, X. Cellular Traffic Load Prediction with LSTM and Gaussian Process Regression. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Wen, Q.; Gao, J.; Song, X.; Sun, L.; Xu, H.; Zhu, S. RobustSTL: A Robust Seasonal-Trend Decomposition Algorithm for Long Time Series. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence (AAAI-19), Hilton Hawaiian Village, HI, USA, 27 January–1 February 2019; AAAI Press: Palo Alto, CA, USA, 2019; pp. 5409–5416. [Google Scholar]
- He, Z.; Zhou, J.; Dai, H.N.; Wang, H. Gold price forecast based on LSTM-CNN model. In Proceedings of the IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Fukuoka, Japan, 5–8 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1046–1053. [Google Scholar]
- Zhao, X.; Lv, H.; Lv, S.; Sang, Y.; Wei, Y.; Zhu, X. Enhancing robustness of monthly streamflow forecasting model using gated recurrent unit based on improved grey wolf optimizer. J. Hydrol. 2021, 601, 126607. [Google Scholar] [CrossRef]
- Sajjad, M.; Khan, Z.A.; Ullah, A.; Hussain, T.; Ullah, W.; Lee, M.Y.; Baik, S.W. A Novel CNN-GRU-Based Hybrid Approach for Short-Term Residential Load Forecasting. IEEE Access 2020, 8, 143759–143768. [Google Scholar] [CrossRef]
- Jiao, F.; Huang, L.; Song, R.; Huang, H. An improved STL-LSTM model for daily bus passenger flow prediction during the COVID-19 pandemic. Sensors 2021, 21, 5950. [Google Scholar] [CrossRef] [PubMed]
- Ouyang, Z.; Ravier, P.; Jabloun, M. STL Decomposition of Time Series Can Benefit Forecasting Done by Statistical Methods but Not by Machine Learning Ones. Eng. Proc. 2021, 5, 42. [Google Scholar]
- Ragab, M.G.; Abdulkadir, S.J.; Aziz, N.; Al-Tashi, Q.; Alyousifi, Y.; Alhussian, H.; Alqushaibi, A. A Novel One-Dimensional CNN with Exponential Adaptive Gradients for Air Pollution Index Prediction. Sustainability 2020, 12, 10090. [Google Scholar] [CrossRef]
- Chi, D.J.; Chu, C.C. Artificial Intelligence in Corporate Sustainability: Using LSTM and GRU for Going Concern Prediction. Sustainability 2021, 13, 11631. [Google Scholar] [CrossRef]
- Mateus, B.C.; Mendes, M.; Farinha, J.T.; Assis, R.; Cardoso, A.M. Comparing LSTM and GRU Models to Predict the Condition of a Pulp Paper Press. Energies 2021, 14, 6958. [Google Scholar] [CrossRef]
- Analysis and Modeling of Internet Usage. Available online: https://www.kaggle.com/andrewfager/analysis-and-modeling-of-internet-usage/data (accessed on 15 November 2021).
- Ayub, M.; El-Alfy, E.-S.M. Impact of normalization on BiLSTM based models for energy disaggregation. In Proceedings of the 2020 International Conference on Data Analytics for Business and Industry: Way Towards a Sustainable Economy (ICDABI), Sakheer, Bahrain, 26–27 October 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Michael, N.E.; Mishra, M.; Hasan, S.; Al-durra, A. Short-term solar power predicting model based on multi-step CNN stacked LSTM technique. Energies 2022, 15, 2150. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | MAPE | RMSE | MAE |
|---|---|---|---|
| ARIMA | 18.96% | 0.026 | 0.023 |
| LSTM | 15.04% | 0.031 | 0.031 |
| LSTM–1DCNN | 11.53% | 0.025 | 0.021 |
| Wavelet-LSTM | 15.52% | 0.030 | 0.026 |
| Standard STL-GRU | 15.43% | 0.029 | 0.025 |
| The Proposed Model | 12.10% | 0.024 | 0.021 |
| Model | MAPE | RMSE | MAE |
|---|---|---|---|
| ARIMA | 25.59% | 0.899 | 0.755 |
| LSTM | 11.73% | 0.589 | 0.480 |
| LSTM–1DCNN | 17.28% | 0.800 | 0.784 |
| Wavelet-LSTM | 16.77% | 0.744 | 0.625 |
| Standard STL-GRU | 16.80% | 0.736 | 0.632 |
| The Proposed Model | 11.02% | 0.564 | 0.455 |
| Model | MAPE | RMSE | MAE |
|---|---|---|---|
| ARIMA | 14.50% | 0.200 | 0.160 |
| LSTM | 13.94% | 0.239 | 0.200 |
| LSTM–1DCNN | 13.86% | 0.237 | 0.199 |
| Wavelet-LSTM | 27.03% | 0.450 | 0.402 |
| Standard STL-GRU | 15.32% | 0.261 | 0.214 |
| The Proposed Model | 17.62% | 0.277 | 0.230 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, C.-H.; Nuha, U. RobustSTL and Machine-Learning Hybrid to Improve Time Series Prediction of Base Station Traffic. Electronics 2022, 11, 1223. https://doi.org/10.3390/electronics11081223
Lin C-H, Nuha U. RobustSTL and Machine-Learning Hybrid to Improve Time Series Prediction of Base Station Traffic. Electronics. 2022; 11(8):1223. https://doi.org/10.3390/electronics11081223
Chicago/Turabian StyleLin, Chih-Hsueh, and Ulin Nuha. 2022. "RobustSTL and Machine-Learning Hybrid to Improve Time Series Prediction of Base Station Traffic" Electronics 11, no. 8: 1223. https://doi.org/10.3390/electronics11081223
APA StyleLin, C.-H., & Nuha, U. (2022). RobustSTL and Machine-Learning Hybrid to Improve Time Series Prediction of Base Station Traffic. Electronics, 11(8), 1223. https://doi.org/10.3390/electronics11081223