
A Data Aggregation Approach Exploiting Spatial and Temporal Correlation among Sensor Data in Wireless Sensor Networks

 ,
,  , and
, and 
Abstract
:1. Introduction
- A spatial correlation-based data aggregation protocol named STCDRR which works in two levels namely source level and aggregator level is considered [6].
- To eliminate data redundancy and to enhance the smooth functioning of WSN applications, STCDRR is implemented.
- The protocol is extensively exterminated using different parameters such as aggregation ratio, time complexity, and energy consumption.
- This protocol outperforms in the context of the above parameters compared to the KAB (K-means algorithm based on the ANOVA model and Bartlett test) and ED (Euclidian distance) techniques.
2. Literature Review
3. Background Study
3.1. Spatial Correlation
3.2. Temporal Correlation
3.3. Data Aggregation
4. Presumptions and Network Structuring
4.1. Presumptions
4.2. Network Structuring
4.3. State of the Art
4.3.1. Data Aggregation at Source Level
4.3.2. Data Aggregation Using Similarity Function (JACCARD)
4.3.3. Data Aggregation Using the Variance Method (KAB)
4.3.4. Data Aggregation Using the Distance Function (ED)
5. STCDRR Protocol
5.1. Eliminating Temporal Data Redundancy at Source Level
- (I)
- Assume that the root node observes the homogeneous (or identical) input estimate when the discerning neighborhood changes periodically or the time slot (j) is minimal. For reduction in dimensions, the juncture recognizes the identical data measurements.
- (II)
- These duplicate data are eliminated using the JACCARD similarity [36] match function.
- (III)
- The poundage of the input estimate is denoted by wt which is the numeral of the successive phenomenon of the identical or same measurement in the same set.
- (IV)
- After the accomplishment of the time interval, the root node converts the native vector of input estimates into a set accommodating the dissimilar input estimate as derived in Equation (3),where k ≤ t.
- (V)
- The weighted cardinality of can be denoted as which is the grand total of all the input estimates in which can be denoted as described in Equation (4).
| Algorithm 1: Data redundancy reduction using JACCARD |
| Input: new data measure, |
| Output: reduced dataset with unique values |
| Require: Existing data measurement valuein time period |
| Ensure: to forage homogeneous values in |
| Start: |
| Stop |
5.2. Eliminating Spatial Data Redundancy at Aggregator Level
- (1)
- This technique is a covariance measurement of the correlation degree between two input set estimates. Sensor data sets associated with their weights can be evaluated using this technique. Its value varies from −1 to 1. A negative correlation exists when the data set results in the value of −1. Getting a resulting value of 0 means there is no correlation. The positive correlation is derived when a value of 1 is obtained among two input sets.
- (2)
- We can formulate this correlation function for two sensor input sets and along with their weights as follows:where,
- The weighted covariance between and ,
- n = Gross number of input estimates in every data set,
- The weighted mean of ,
- The weighted mean of .
- (3)
- Here is the threshold value that is decided by the type of application. Two input measures are highly correlated if and only if it satisfies Equation (8) as follows:
- (4)
- The agglomerated value is derived for every single pair of received data sets. The correlation coefficient value less than the threshold value indicates redundancy among the two data sets and repudiates such pairs containing either one or two sets.
- (5)
- Then, it computes the new weight value among the two compared input sets. Then the aggregator picks the one which has the highest cardinality among the two. Then the new aggregated value along with its latest weight is added to the record.
| Algorithm 2: Pearson’s Correlation Coefficient |
| Input: Data measure set |
| Output: Aggregated data set along with weigh with highest cardinality |
| Require: set of input measures,(threshold value) |
| Ensure: vector of selected input set Q |
| initialize Q, , H = {} |
| Start: |
| forevery input setdo |
| end for |
| rerun |
| for respective pairs of input sets () do |
| if then |
| consider |
| discard each set of input sets which include either or from H |
| = number of dropped pairs incremented to 1 |
| Q = Q |
| else |
| H = H |
| end if |
| end for |
| tillnone of the setin H |
| return Q |
| Stop |
6. Performance Evaluation
6.1. Key Parameters
6.1.1. Threshold Function Value
6.1.2. Data Measures
6.2. Performance Metrics
7. Experimental Results
- (1)
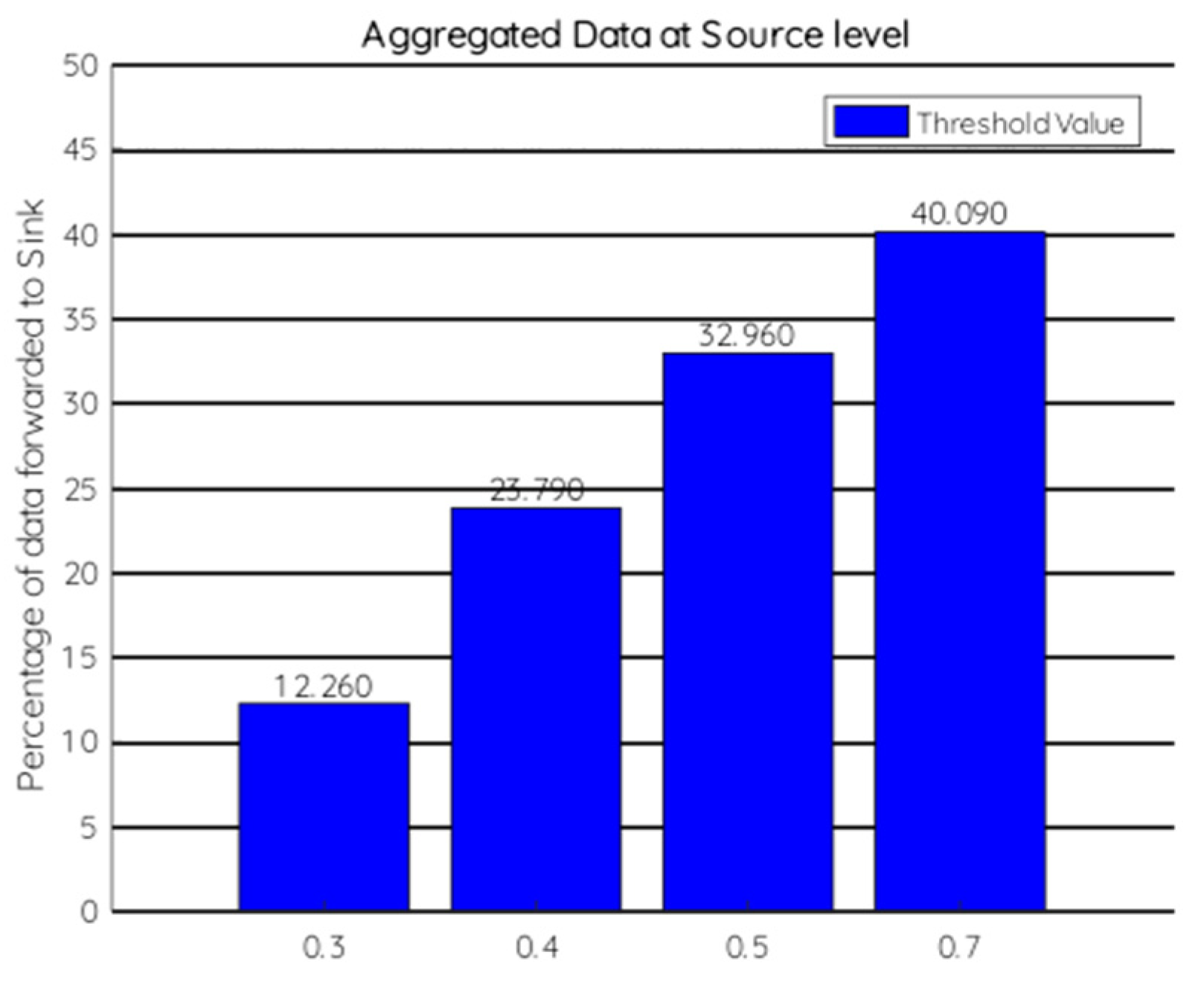
- The number of sensors calculated by individual sensor node for a period has some values. Here we have taken 3 values 50, 100, 200. It is denoted by α.
- (2)
- The threshold value for the distance function is denoted by . We have taken 4 different values 0.3, 0.4, 0.5, 0.7 to check the difference in results for each value.
- (3)
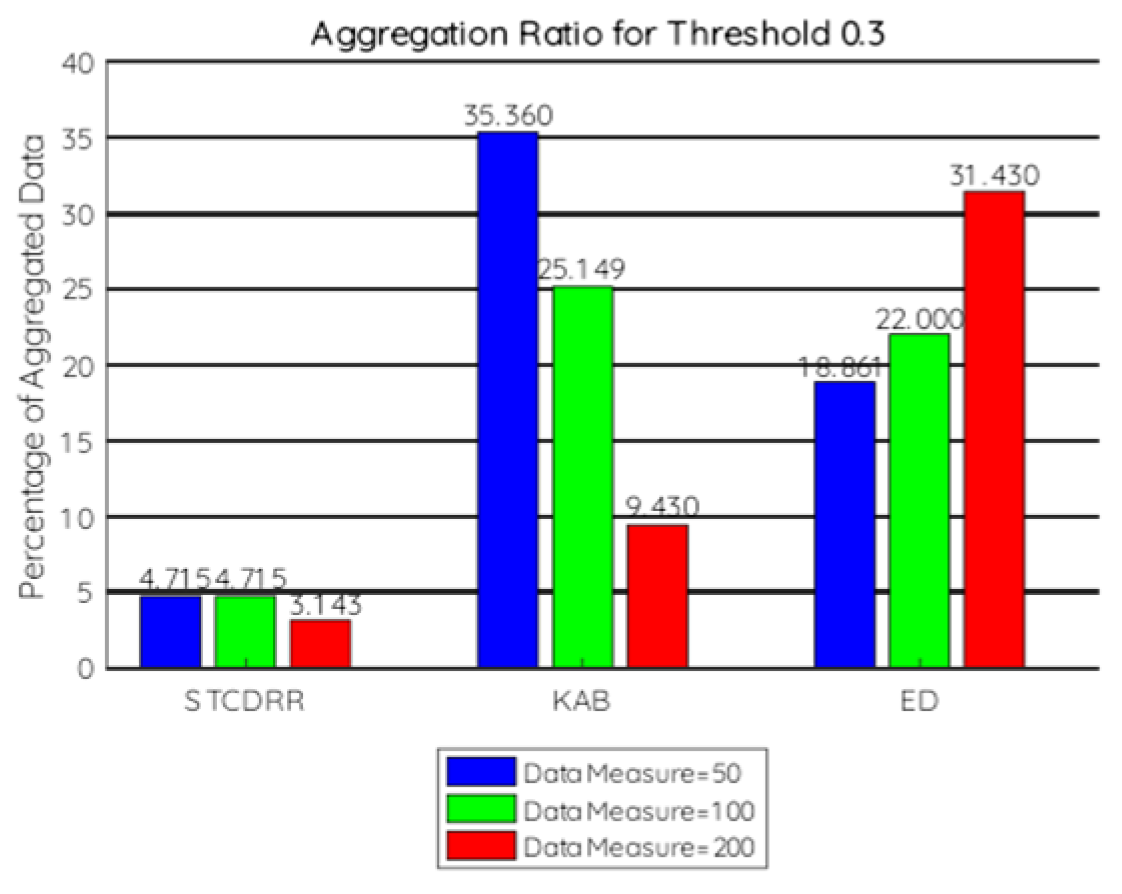
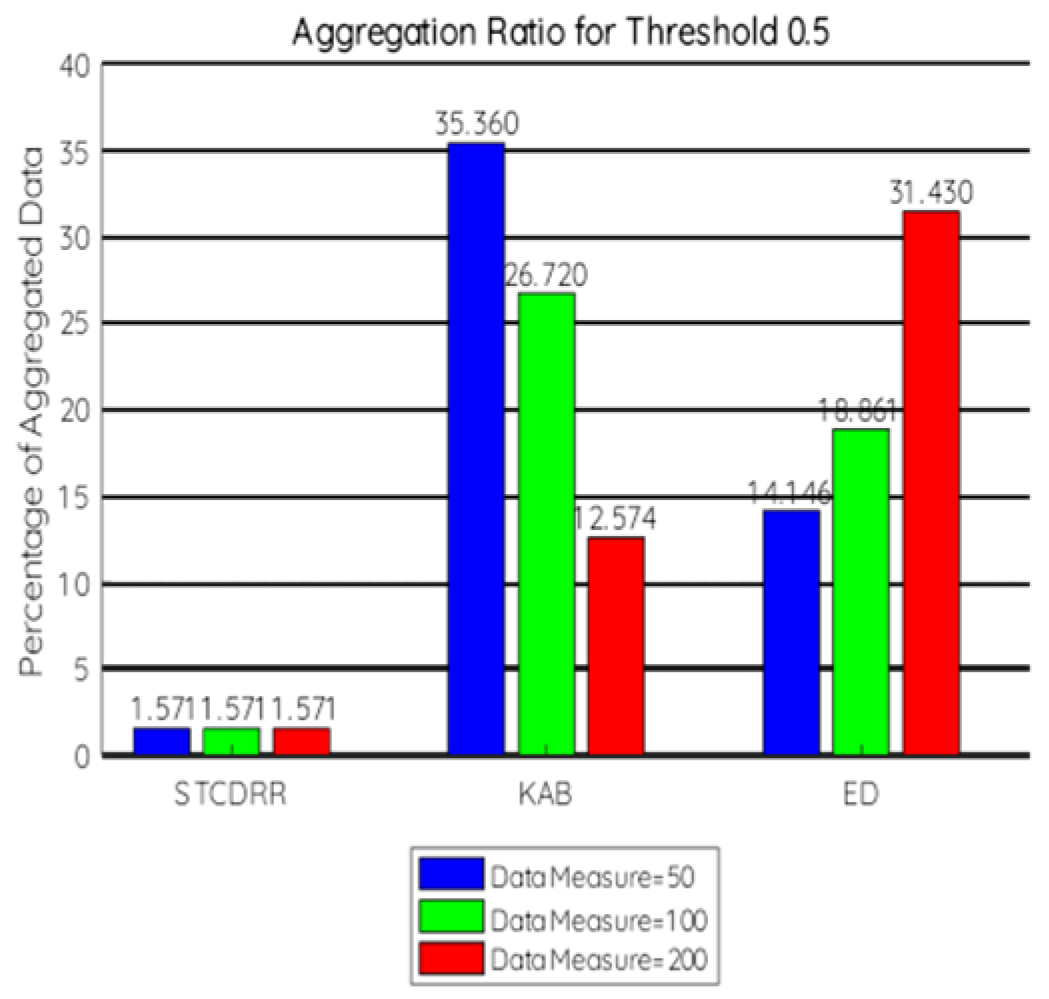
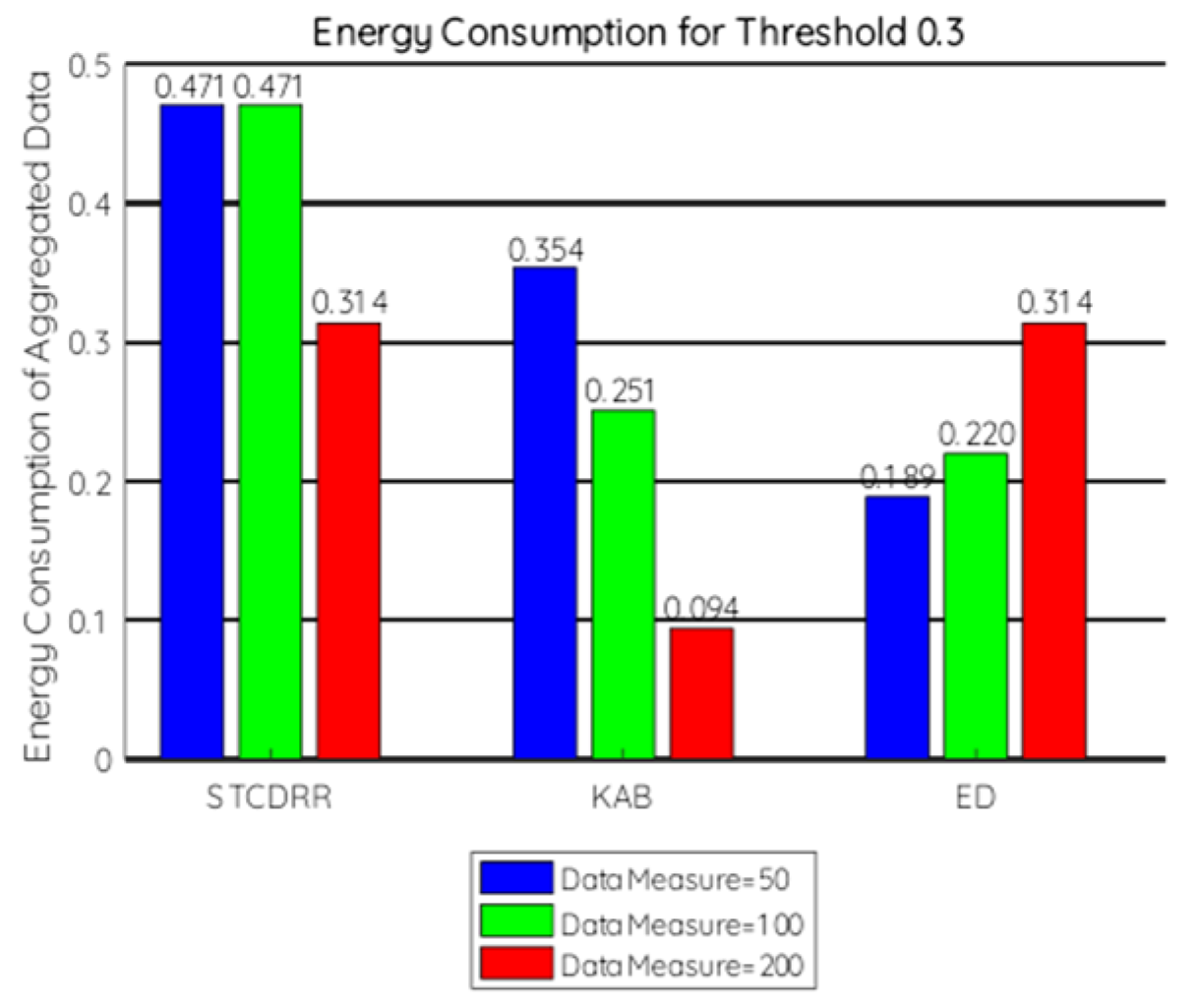
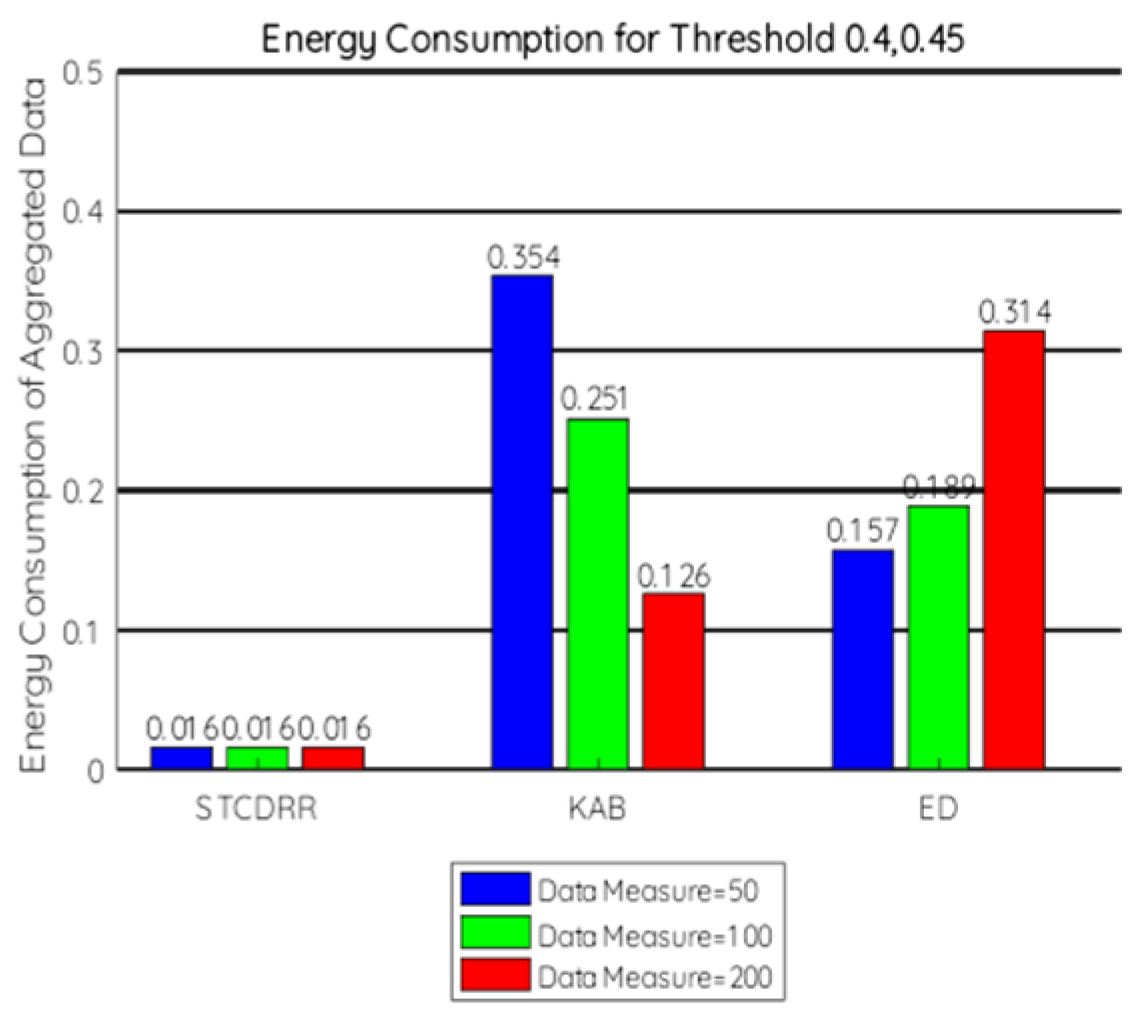
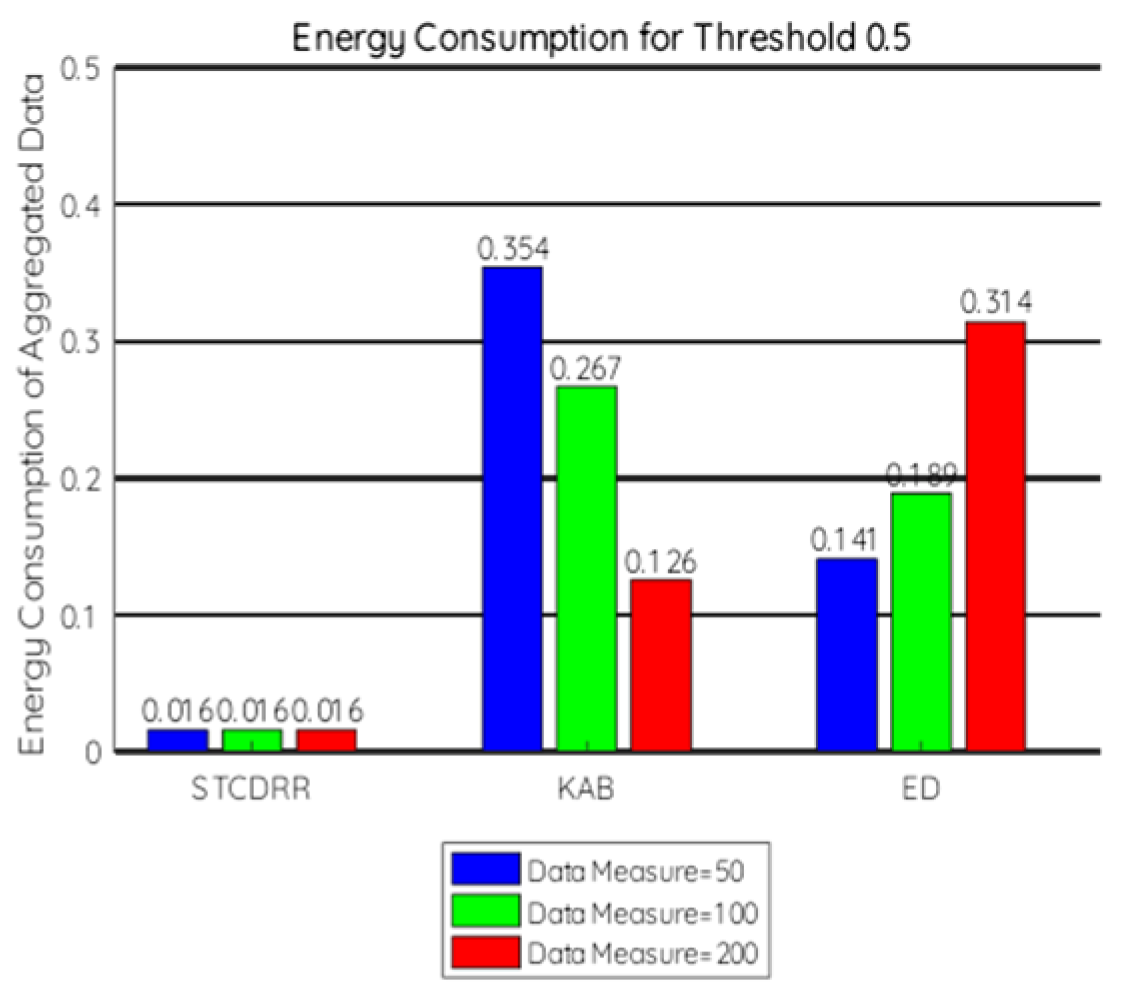
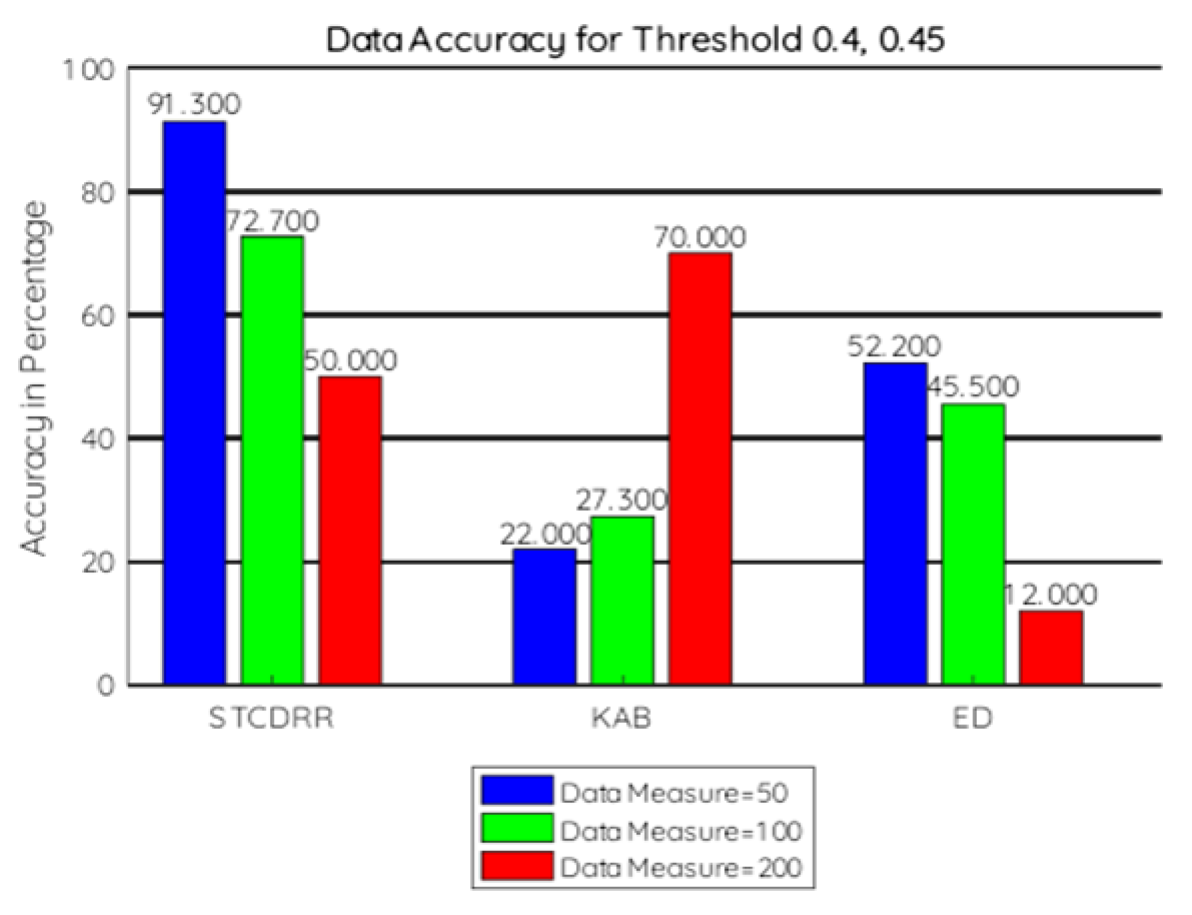
- To compare at the aggregator level the threshold values are taken to be 0.3, 0.4, 0.45, 0.5.
- (4)
- The thresholds for the match function are 0.02, 0.04, 0.06, 0.1.
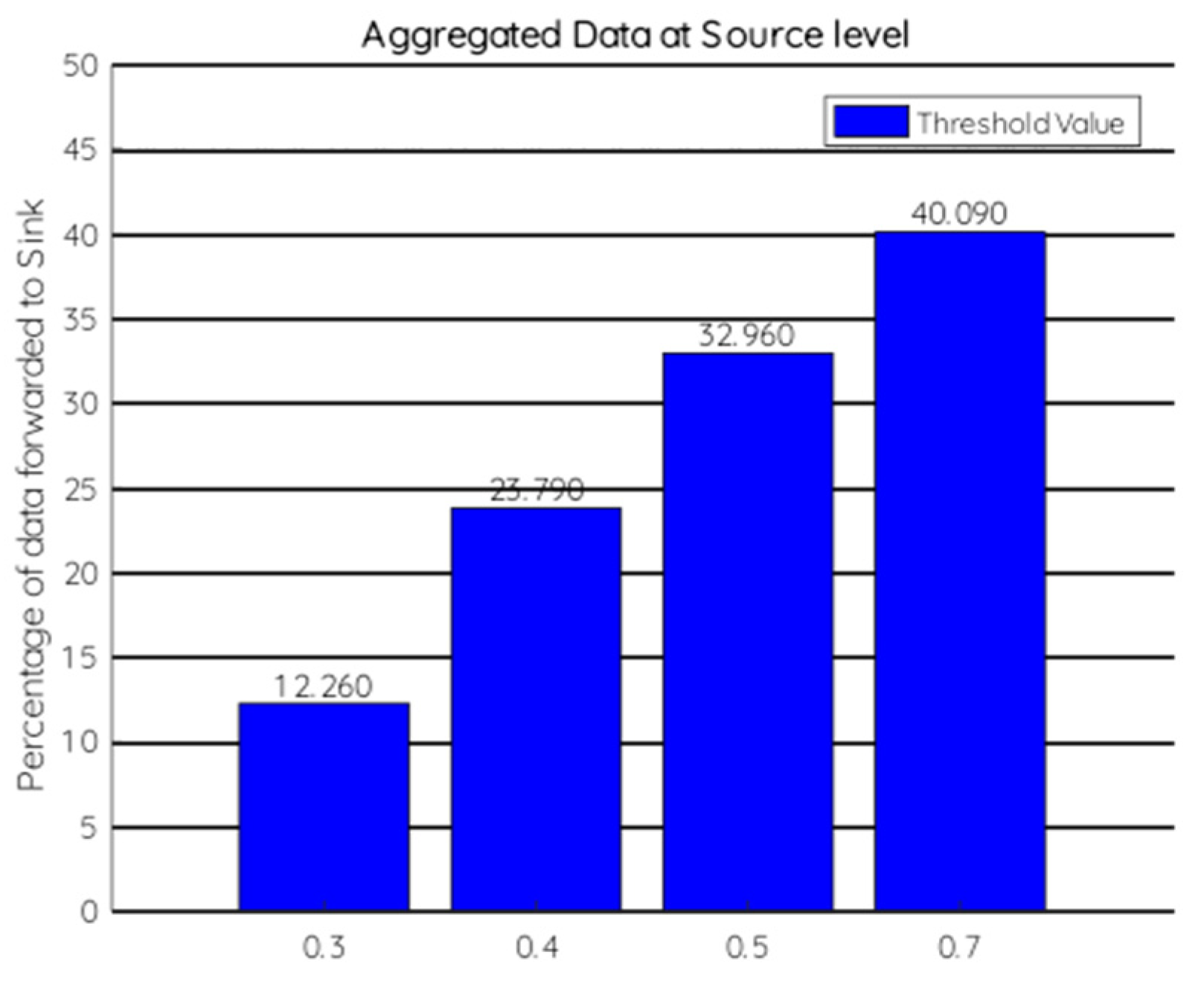
7.1. Source Level Experiment
7.2. Sink Level Experiment
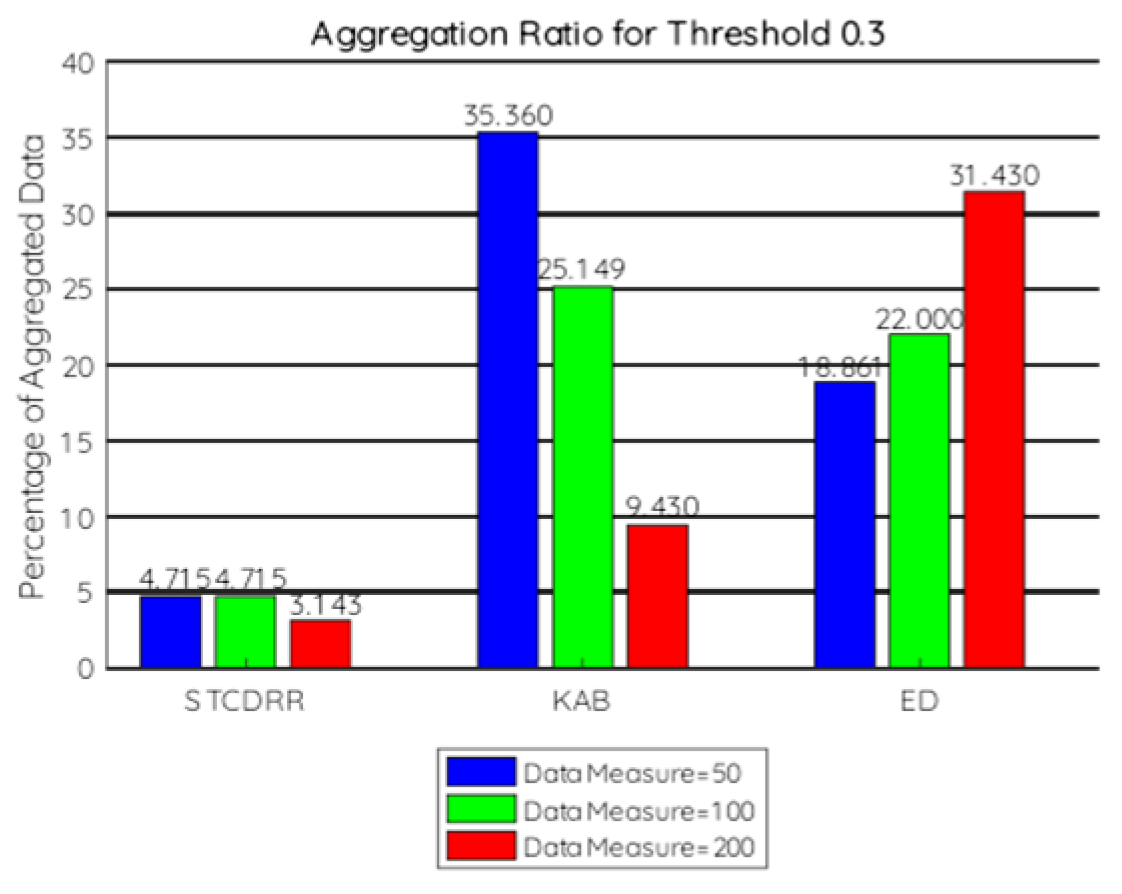
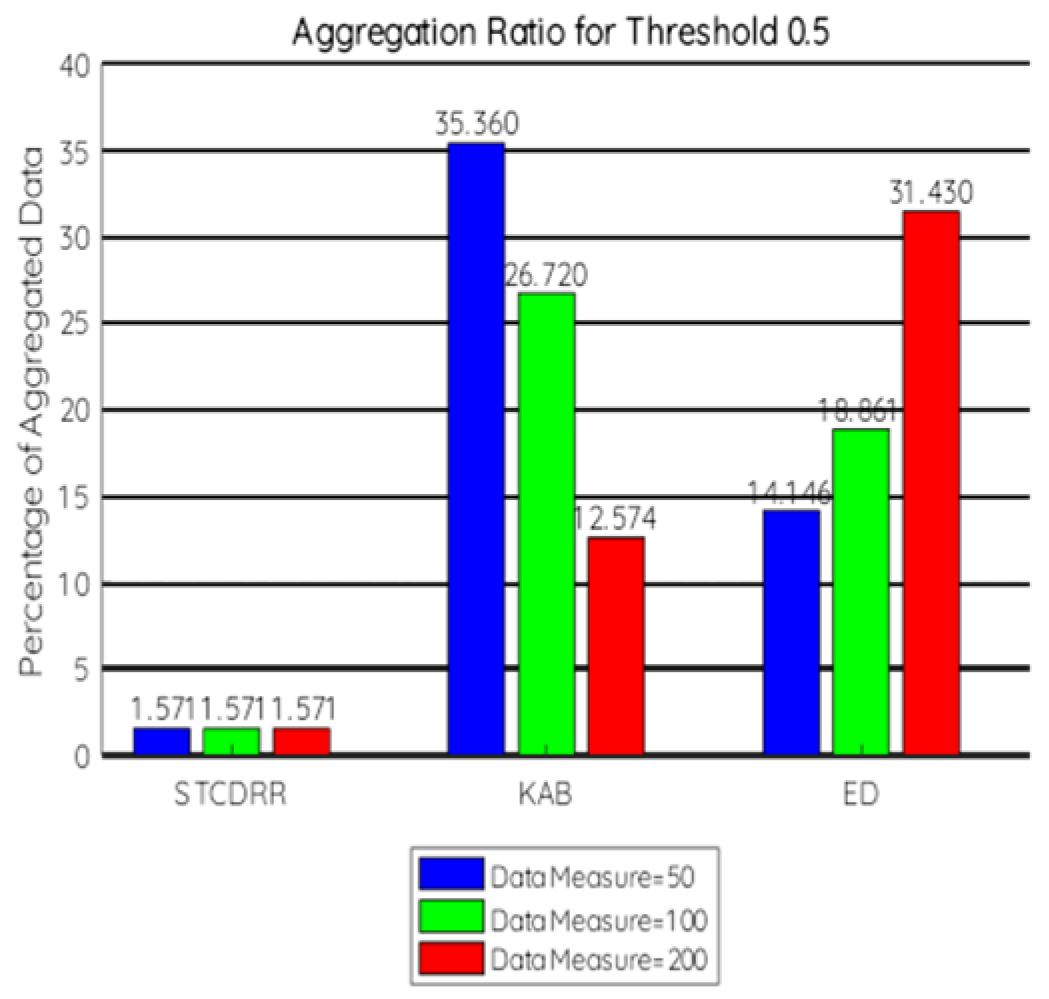
7.2.1. Aggregation Ratio
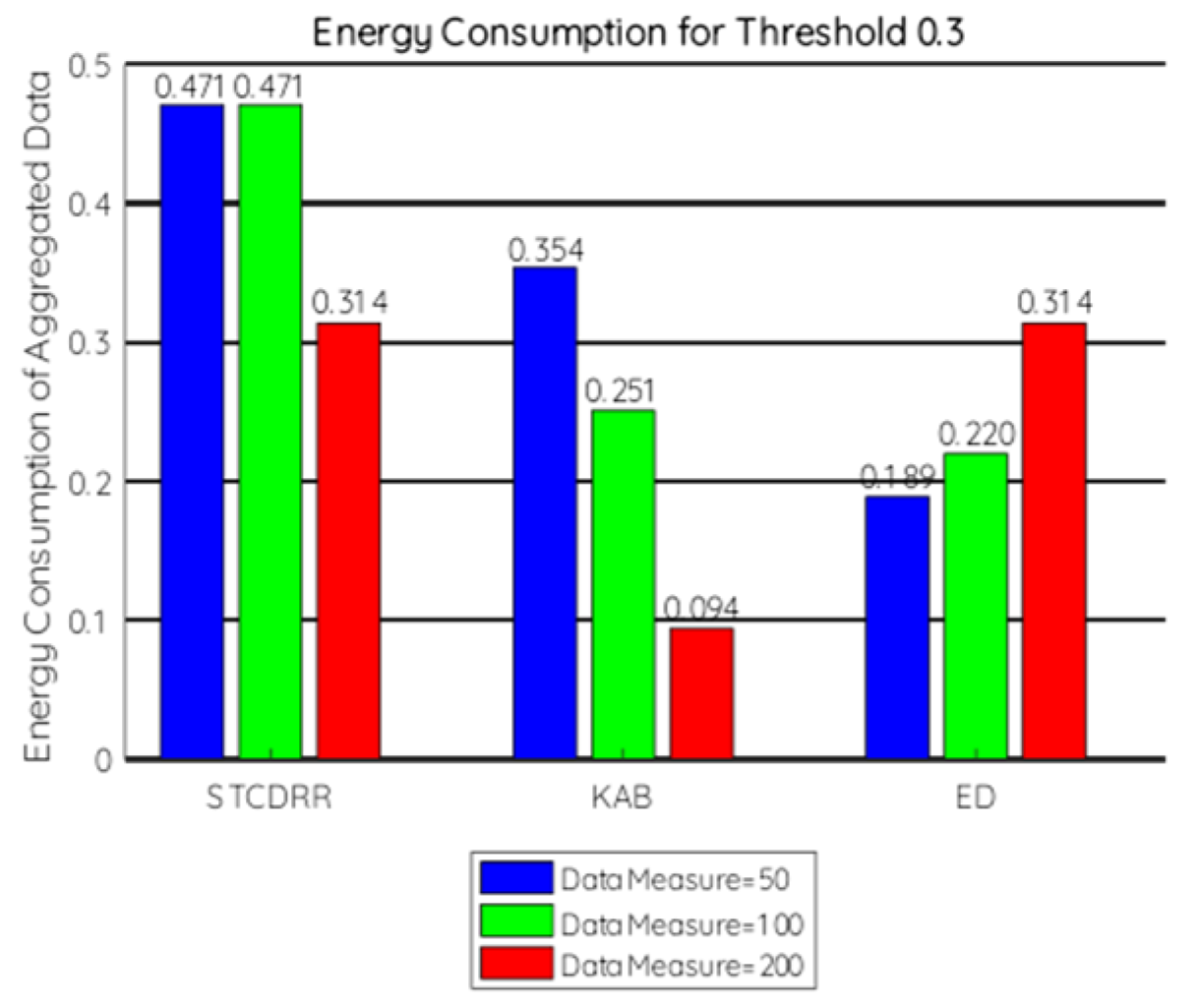
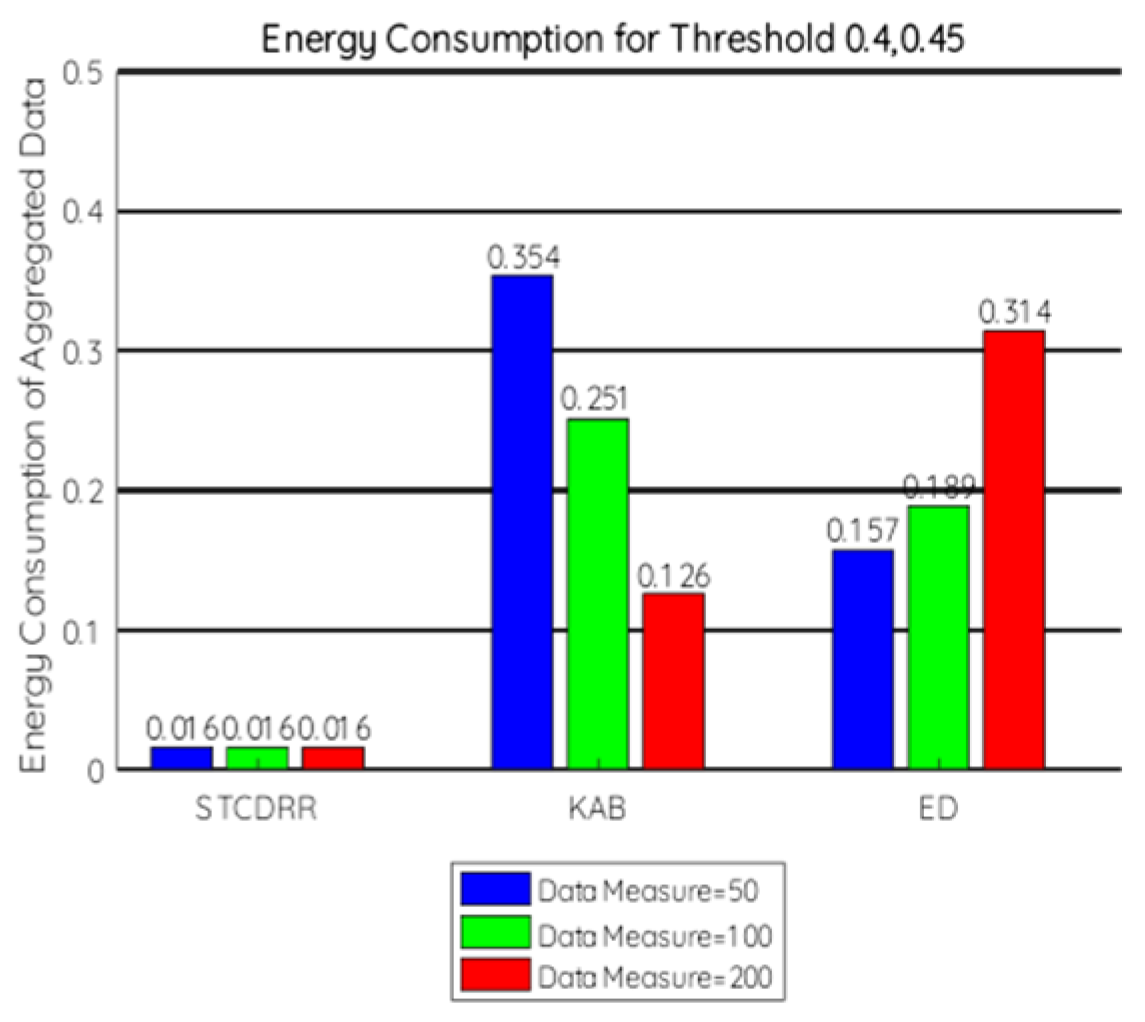
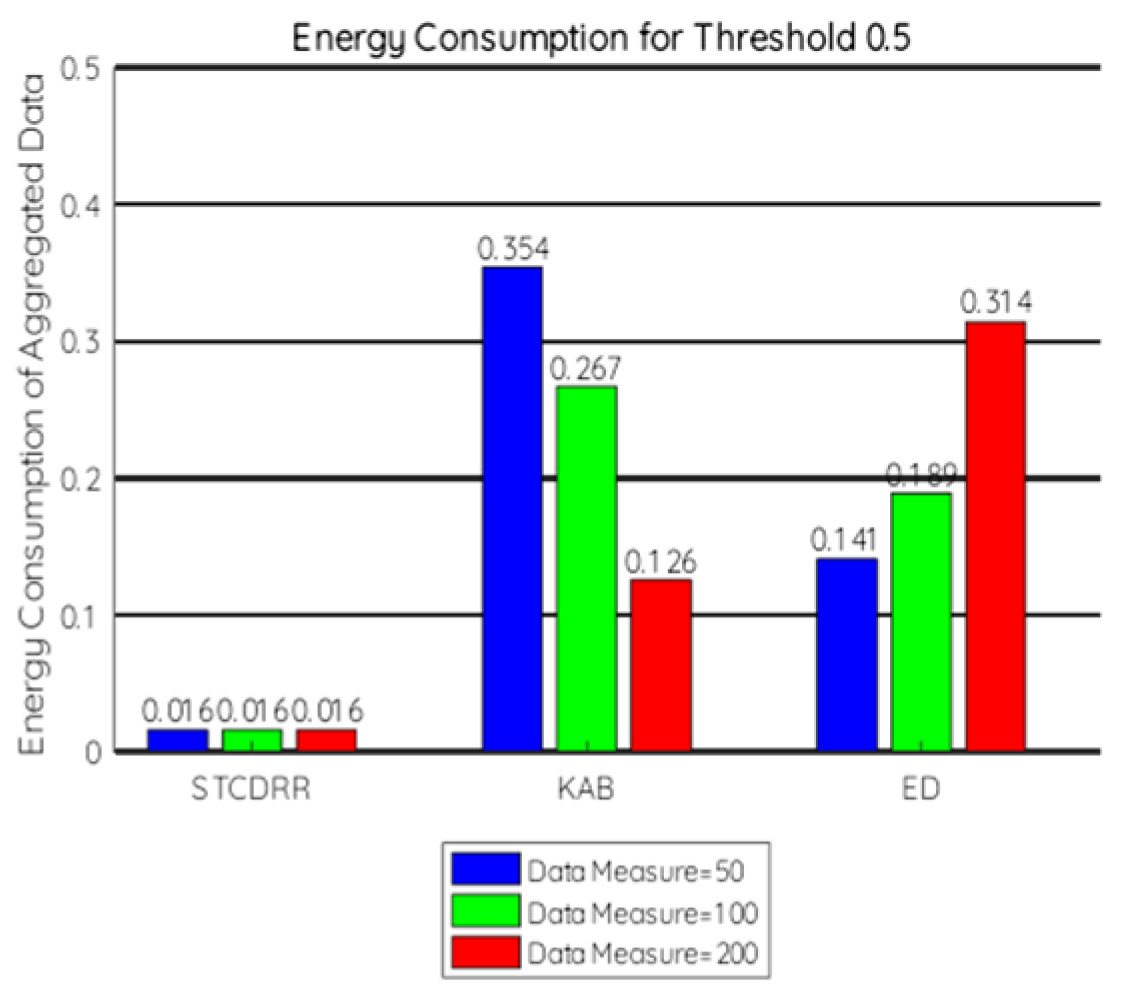
7.2.2. Energy Consumption
- = Energy measured in miliJoules (mJ) or in Kilowatt-hours (Kwh),
- = Power units in Watts,
- = Time over which the power or energy was consumed.
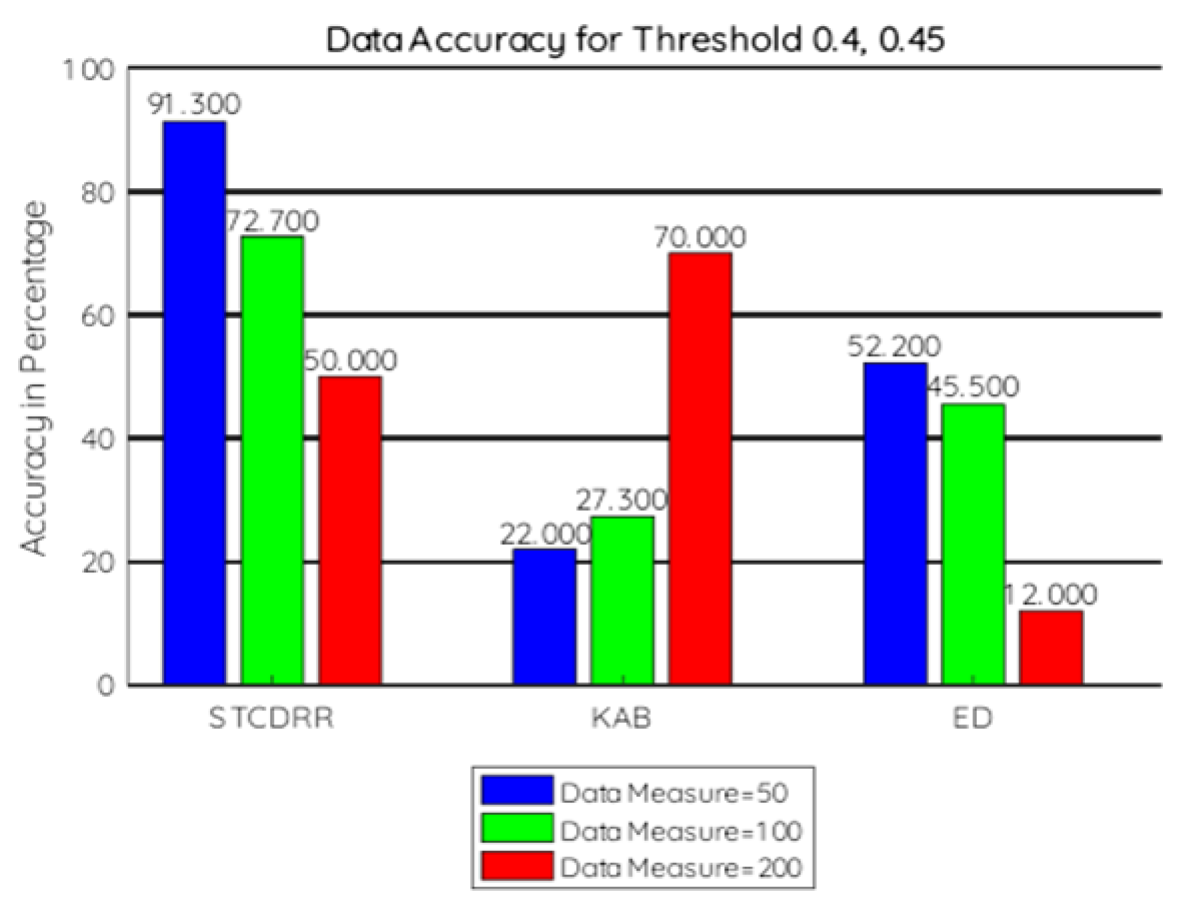
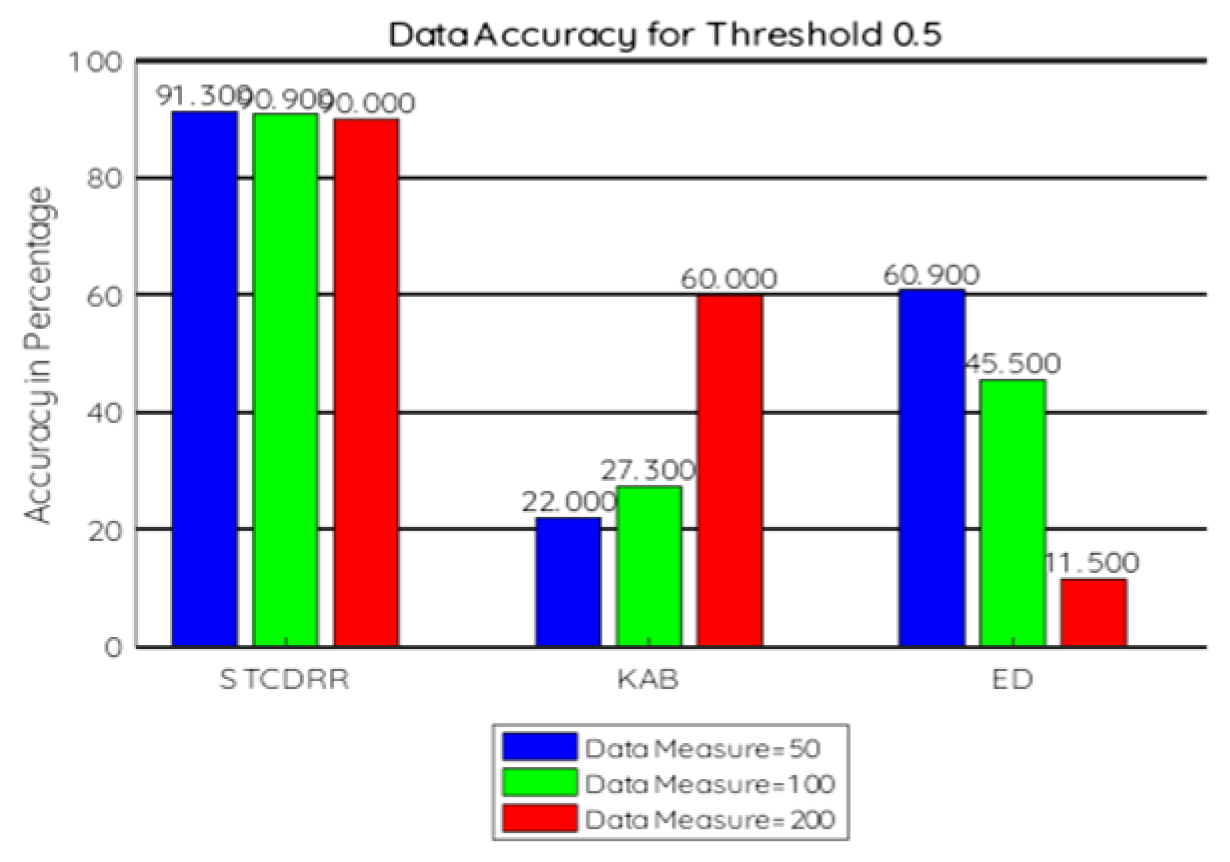
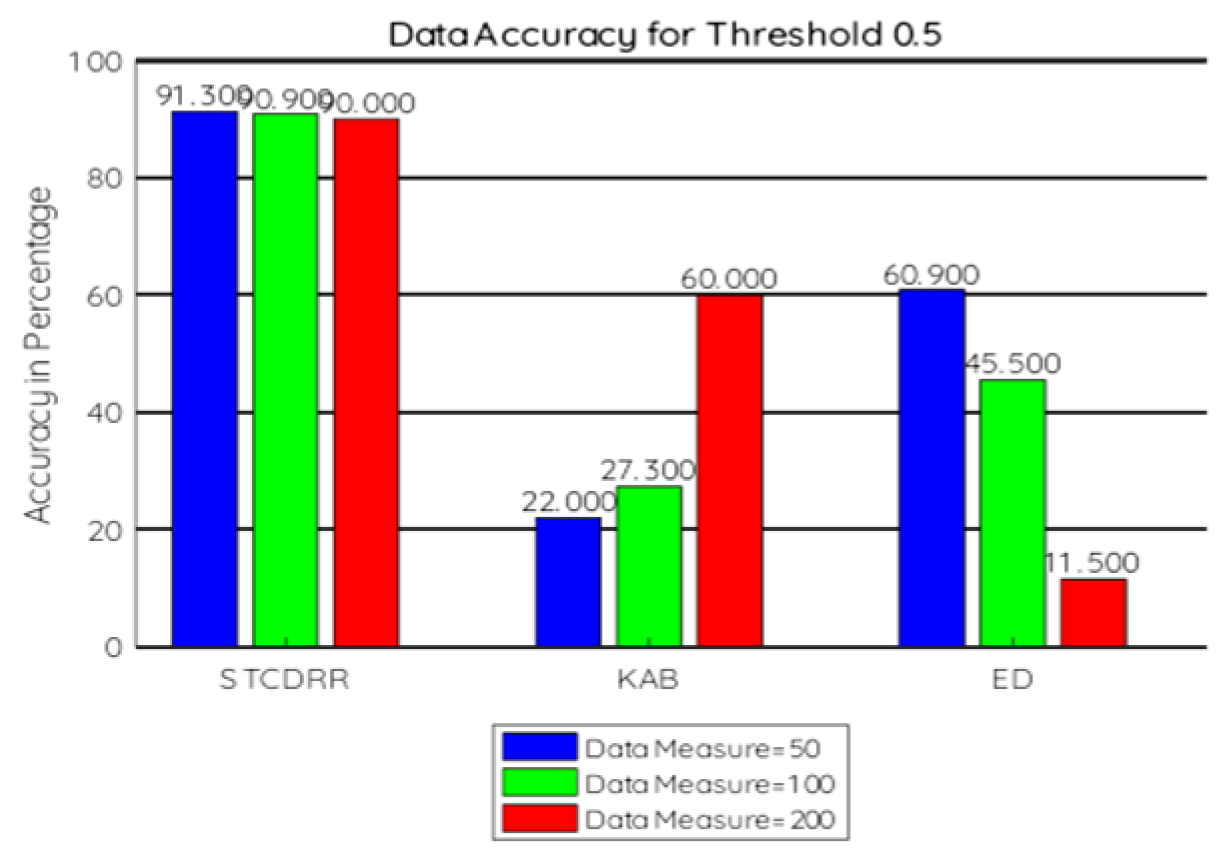
7.2.3. Data Accuracy
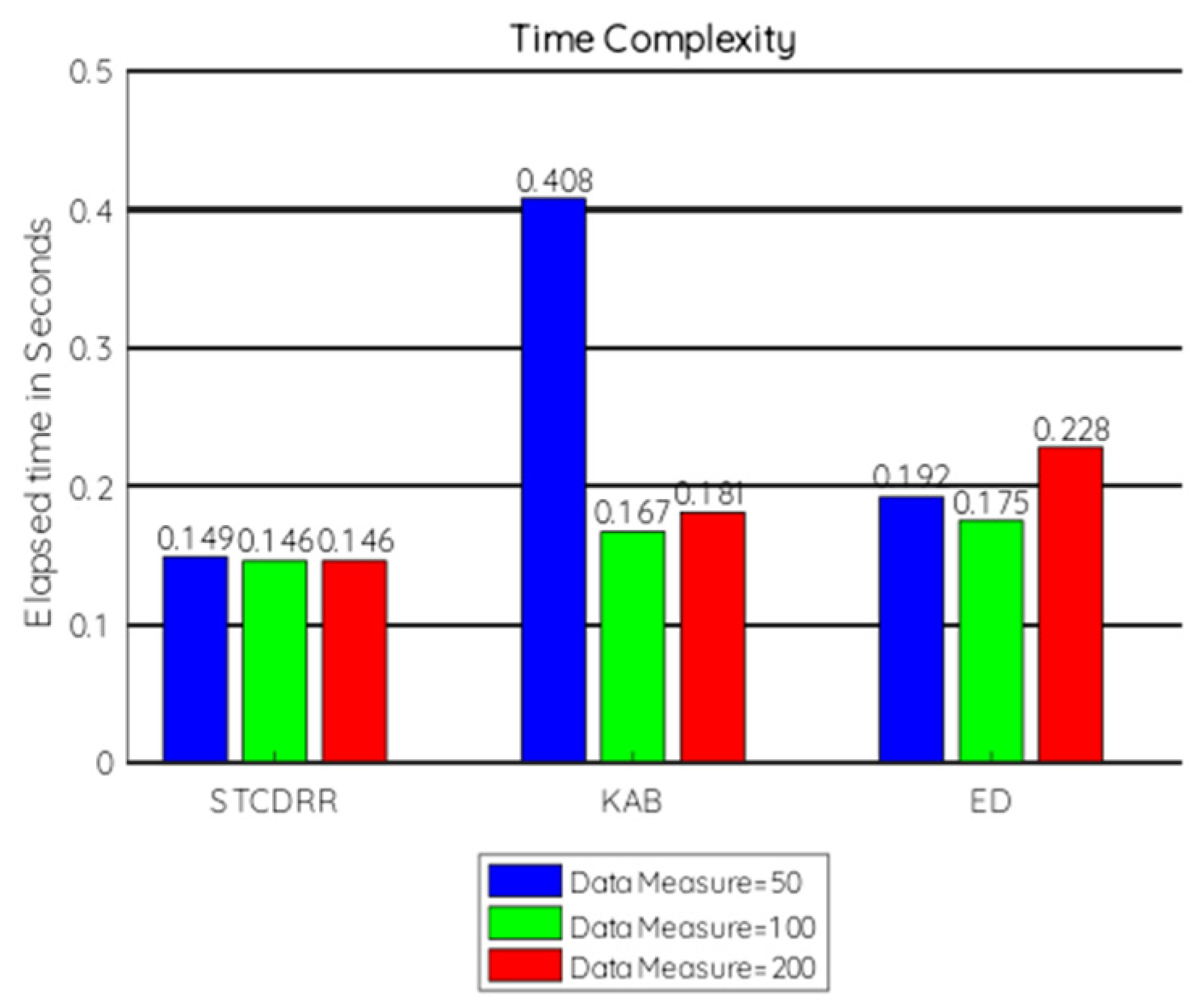
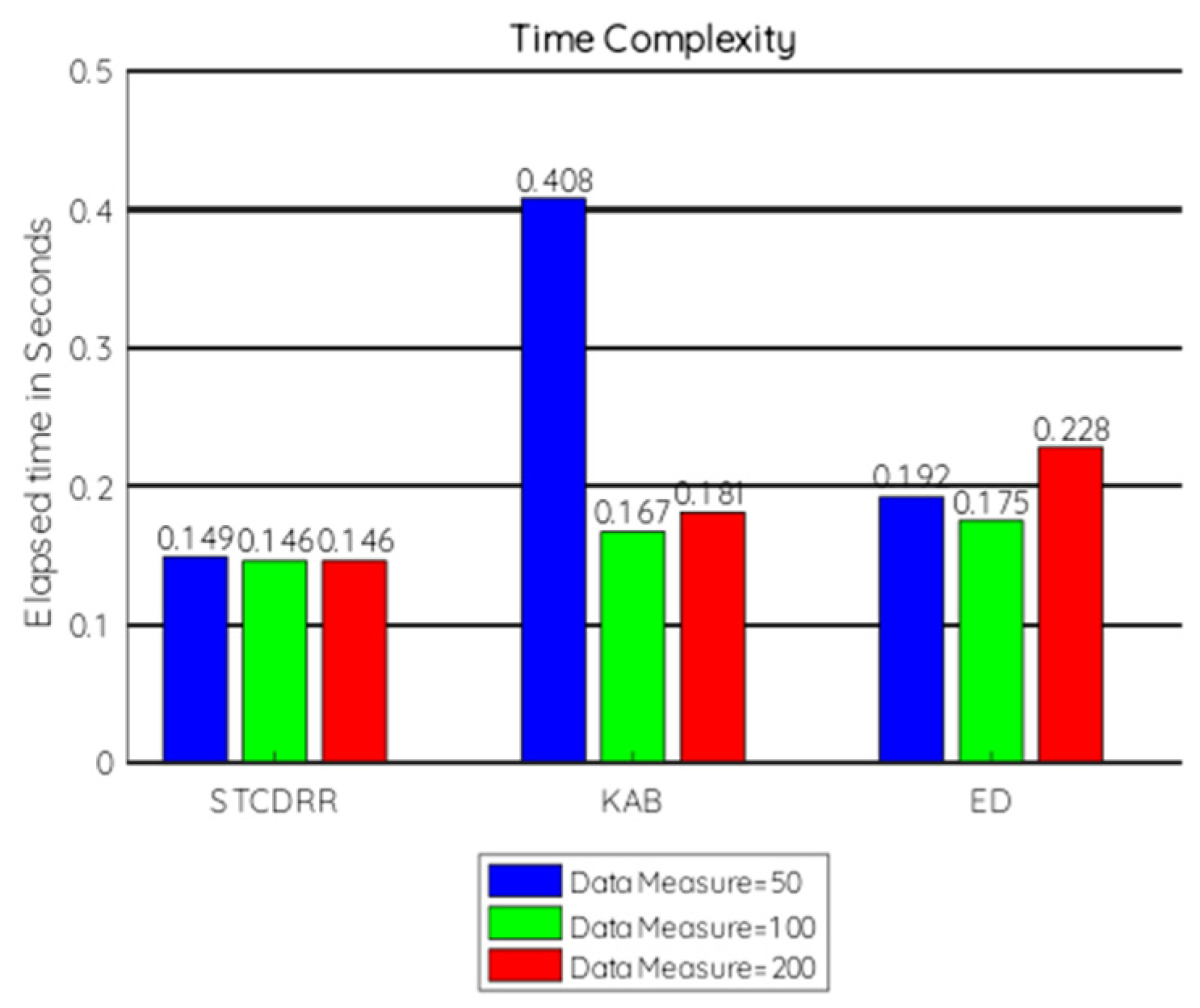
7.2.4. Time Complexity
7.2.5. Discussion
8. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lazarescu, M.T. Design of a WSN platform for long-term environmental monitoring for IoT applications. IEEE J. Emerg. Sel. Top. Circuits Syst. 2013, 3, 45–54. [Google Scholar] [CrossRef] [Green Version]
- Chi, Q.; Yan, H.; Zhang, C.; Pang, Z.; Xu, L.D. A reconfigurable smart sensor interface for industrial WSN in IoT environment. IEEE Trans. Ind. Inf. 2014, 10, 1417–1425. [Google Scholar]
- Akyildiz, I.F.; Su, W.; Sankarasubramaniam, Y.; Cayirc, E. Wireless sensor networks: A survey. Comput. Netw. 2002, 38, 393–422. [Google Scholar] [CrossRef] [Green Version]
- Villas, L.A.; Boukerche, A.; de Oliveira, H.A.; de Araujo, R.B.; Loureiro, A.A. A spatial correlation aware algorithm to perform efficient data collection in wireless sensor networks. Ad Hoc Netw. 2014, 12, 69–85. [Google Scholar] [CrossRef]
- Varun, M.C.; Akan, O.B.; Akyildiz, I.F. Spatio-temporal correlation: Theory and applications for wireless sensor networks. Comput. Netw. 2004, 45, 245–259. [Google Scholar]
- Maivizhi, R.; Yogesh, P. Spatial correlation based data redundancy elimination for data aggregation in wireless sensor networks. In Proceedings of the 2020 International Conference on Innovative Trends in Information Technology (ICITIIT), Kottayam, India, 13–14 February 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Yemeni, Z.; Wang, H.; Ismael, W.M.; Wang, Y.; Chen, Z. Reliable spatial and temporal data redundancy reduction approach for WSN. Comput. Netw. 2021, 185, 107701. [Google Scholar] [CrossRef]
- Yadav, S.; Yadav, R.S. Redundancy elimination during data aggregation in wireless sensor networks for IoT systems. In Recent Trends in Communication, Computing, and Electronics; Springer: Singapore, 2019; pp. 195–205. [Google Scholar]
- Zhou, Y.; Yang, L.; Yang, L.; Ni, M. Novel energy-efficient data gathering scheme exploiting spatial-temporal correlation for wireless sensor networks. Wirel. Commun. Mob. Comput. 2019, 2019, 4182563. [Google Scholar] [CrossRef]
- Tayeh, G.B.; Makhoul, A.; Perera, C.; Demerjian, J. A spatial-temporal correlation approach for data reduction in cluster-based sensor networks. IEEE Access 2019, 7, 50669–50680. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, S.; Tsai, P.W.; Zou, F.; Ji, X. Directional virtual backbone based data aggregation scheme for Wireless Visual Sensor Networks. PLoS ONE 2018, 13, e0196705. [Google Scholar] [CrossRef]
- Lu, Y.; Sun, N. A resilient data aggregation method based on spatio-temporal correlation for wireless sensor networks. Eur. J. Wirel. Commun. Netw. 2018, 1, 157. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Zheng, X.; Liu, J.; Hu, N.; Yang, G. Application of energy-efficient data gathering to wireless sensor network by exploiting spatial correlation. Sens. Mater. 2018, 30, 577–585. [Google Scholar] [CrossRef]
- Patil, P.; Kulkarni, U. SVM based data redundancy elimination for data aggregation in wireless sensor networks. In Proceedings of the 2013 International Conference on Advances in Computing, Communications and Informatics (ICACCI), New York, NY, USA, 22–25 August 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1309–1316. [Google Scholar]
- Yuan, F.; Zhan, Y.; Wang, Y. Data density correlation degree clustering method for data aggregation in WSN. IEEE Sens. J. 2013, 14, 1089–1098. [Google Scholar] [CrossRef]
- Khedo, K.; Doomun, R.; Aucharuz, S. READA: Redundancy elimination for accurate data aggregation in wireless sensor networks. Wirel. Sens. Netw. 2010, 2, 300. [Google Scholar] [CrossRef] [Green Version]
- Yousefi, H.; Yeganeh, M.H.; Alinaghipour, N. Structure-free real-time data aggregation in wireless sensor networks. Comput. Commun. 2012, 35, 1132–1140. [Google Scholar] [CrossRef]
- Misra, Sudip, and Subarna Chatterjee. Social choice considerations in cloud-assisted WBAN architecture for post-disaster healthcare: Data aggregation and channelization. Inf. Sci. 2014, 284, 95–117. [Google Scholar] [CrossRef]
- Curiac, D.I.; Volosencu, C.; Pescar, D.; Jurca, L. Redundancy and its applications in wireless sensor networks: A survey. WSEAS Trans. Comput. 2009, 8, 705–714. [Google Scholar]
- Pielli, C.; Zucchetto, D.; Zanella, A. An interference-aware channel access strategy for WSNs exploiting temporal correlation. IEEE Trans. Commun. 2019, 67, 8585–8597. [Google Scholar] [CrossRef]
- Buckler, M.; Bedoukian, P.; Jayasuriya, S. EVA2: Exploiting temporal redundancy in live computer vision. In Proceedings of the 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, CA, USA, 1–6 June 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Xu, X.; Ansari, R.; Khokhar, A.; Vasilakos, A.V. Hierarchical data aggregation using compressive sensing (HDACS) in WSNs. ACM Trans. Sens. Netw. 2015, 11, 1–25. [Google Scholar] [CrossRef]
- Sengupta, A.; Kachave, D. Spatial and temporal redundancy for transient fault-tolerant datapath. IEEE Trans. Aerosp. Electron. Syst. 2017, 54, 1168–1183. [Google Scholar] [CrossRef]
- Neha, B.; Panda, S.K.; Sahu, K.P.; Sahoo, K.S.; Gandomi, A.H. A Systematic Review on Osmotic Computing. ACM Trans. Internet Things 2022, 3, 1–30. [Google Scholar] [CrossRef]
- Verma, N.; Singh, D. Data redundancy implications in wireless sensor networks. Procedia Comput. Sci. 2018, 132, 1210–1217. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, J.; Guo, K.; Wu, F.; Min, G. Multi-functional secure data aggregation schemes for WSNs. Ad Hoc Netw. 2018, 69, 86–99. [Google Scholar] [CrossRef]
- Alzaid, H.; Foo, E.; Nieto, J.G. RSDA: Reputation-based secure data aggregation in wireless sensor networks. In Proceedings of the Ninth International Conference on Parallel and Distributed Computing, Applications and Technologies, Dunedin, New Zealand, 1–4 December 2008; IEEE: Piscataway, NJ, USA, 2008. [Google Scholar]
- Ghosh, S.; De, S.; Chatterjee, S.; Portmann, M. Learning-based adaptive sensor selection framework for multi-sensing WSN. IEEE Sensors Journal 2021, 21, 13551–13563. [Google Scholar] [CrossRef]
- Jesus, P.; Baquero, C.; Almeida, P.S. A survey of distributed data aggregation algorithms. IEEE Commun. Surv. Tutor. 2014, 17, 381–404. [Google Scholar] [CrossRef] [Green Version]
- Madden, S.; Franklin, M.J.; Hellerstein, J.M. TAG: A tiny aggregation service for ad-hoc sensor networks. ACM Sigops Oper. Syst. Rev. 2002, 36, 131–146. [Google Scholar] [CrossRef]
- Ujawe, P.V.; Khiani, S. Review on data aggregation techniques for energy efficiency in wireless sensor networks. Int. J. Emerg. Technol. Adv. Eng. 2014, 4, 7. [Google Scholar]
- Perrig, A.; Szewczyk, R.; Tygar, J.D.; Wen, V.; Culler, D.E. SPINS: Security protocols for sensor networks. Wirel. Netw. 2002, 8, 521–534. [Google Scholar] [CrossRef]
- Tobarra, L.; Cazorla, D.; Cuartero, F. Formal analysis of sensor network encryption protocol (snep). In Proceedings of the 2007 IEEE International Conference on Mobile Adhoc and Sensor Systems, Pisa, Italy, 8–11 October 2007; IEEE: Piscataway, NJ, USA, 2007. [Google Scholar]
- Li, X.; Ruan, N.; Wu, F.; Li, J.; Li, M. Efficient and enhanced broadcast authentication protocols based on multilevel μTESLA. In Proceedings of the 2014 IEEE 33rd International Performance Computing and Communications Conference (IPCCC), Austin, TX, USA, 5–7 December 2014; IEEE: Piscataway, NJ, USA, 2014. [Google Scholar]
- Harb, H.; Abdallah, M.; Couturier, R. An enhanced K-means and ANOVA-based clustering approach for similarity aggregation in underwater wireless sensor networks. IEEE Sens. J. 2015, 15, 5483–5493. [Google Scholar] [CrossRef] [Green Version]
- Bag, S.; Kumar, S.K.; Tiwari, M.K. An efficient recommendation generation using relevant Jaccard similarity. Inf. Sci. 2019, 483, 53–64. [Google Scholar] [CrossRef]
- Zhou, H.; Deng, Z.; Xia, Y.; Fu, M. A new sampling method in particle filter based on Pearson correlation coefficient. Neurocomputing 2016, 216, 208–215. [Google Scholar] [CrossRef]
- Madden, S. Intel Berkeley Research Lab. 2004. Available online: http://db.csail.mit.edu/labdata/labdata.html (accessed on 15 August 2021).
- Amjad, M.; Sharif, M.; Afzal, M.K.; Kim, S.W. TinyOS-new trends, comparative views, and supported sensing applications: A review. IEEE Sens. J. 2016, 16, 2865–2889. [Google Scholar] [CrossRef]
- Kim, D.O.; Liu, L.; Shin, I.S.; KimKim, J.J. Spatial TinyDB: A spatial sensor database system for the USN environment. Int. J. Distrib. Sens. Netw. 2013, 9, 512368. [Google Scholar] [CrossRef]
- Mikkili, S.; Panda, A.K.; Prattipati, J. Review of real-time simulator and the steps involved for implementation of a model from MATLAB/SIMULINK to real-time. J. Inst. Eng. Ser. B 2015, 96, 179–196. [Google Scholar] [CrossRef]
- Harb, H.; Makhoul, A.; Tawbi, S.; Couturier, R. Comparison of different data aggregation techniques in distributed sensor networks. IEEE Access J. 2017, 5, 4250–4263. [Google Scholar] [CrossRef]
- Rout, S.; Sahoo, K.S.; Patra, S.S.; Sahoo, B.; Puthal, D. Energy Efficiency in Software Defined Networking: A Survey. SN Comput. Sci. 2021, 2, 308. [Google Scholar] [CrossRef]
- Panda, B.S.; Bhatta, B.K.; Mishra, S.K. Improved energy-efficient target coverage in wireless sensor networks. In Proceedings of the International Conference on Computational Science and Its Applications, Trieste, Italy, 3–6 July 2017; Springer: Cham, Switzerland, 2017; pp. 350–362. [Google Scholar]
- Nayak, R.P.; Sethi, S.; Bhoi, S.K.; Sahoo, K.S.; Jhanjhi, N.; Tabbakh, T.A.; Almusaylim, Z.A. TBDDoSA-MD: Trust-Based DDoS Misbehave Detection Approach in Software-defined Vehicular Network (SDVN). Comput. Mater. Contin. 2021, 69, 3513–3529. [Google Scholar] [CrossRef]
- Pande, S.K.; Panda, S.K.; Das, S.; Sahoo, K.S.; Luhach, A.K.; Jhanjhi, N.Z.; Alroobaea, R.; Sivanesan, S. A resource management algorithm for virtual machine migration in vehicular cloud computing. Comput. Mater. Contin. 2021, 67, 2647–2663. [Google Scholar] [CrossRef]
- Mishra, S.K.; Mishra, S.; Alsayat, A.; Jhanjhi, N.Z.; Humayun, M.; Sahoo, K.S.; Luhach, A.K. Energy-aware task allocation for multi-cloud networks. IEEE Access 2020, 8, 178825–178834. [Google Scholar] [CrossRef]
- Maity, P.; Saxena, S.; Srivastava, S.; Sahoo, K.S.; Pradhan, A.K.; Kumar, N. An Effective Probabilistic Technique for DDoS Detection in OpenFlow Controller. IEEE Syst. J. 2021, 1–10. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sl.No. | Parameter | Notation | Value |
|---|---|---|---|
| 1 | No. of Data Measurements | 50, 100, 200 | |
| 2 | Threshold of Distance Function | 0.3, 0.4, 0.5, 0.7 | |
| 3 | Threshold of Correlation Coefficient | 0.3, 0.4, 0.45, 0.5 | |
| 4 | Threshold of Match Function | 0.02, 0.04, 0.06, 0.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dash, L.; Pattanayak, B.K.; Mishra, S.K.; Sahoo, K.S.; Jhanjhi, N.Z.; Baz, M.; Masud, M. A Data Aggregation Approach Exploiting Spatial and Temporal Correlation among Sensor Data in Wireless Sensor Networks. Electronics 2022, 11, 989. https://doi.org/10.3390/electronics11070989
Dash L, Pattanayak BK, Mishra SK, Sahoo KS, Jhanjhi NZ, Baz M, Masud M. A Data Aggregation Approach Exploiting Spatial and Temporal Correlation among Sensor Data in Wireless Sensor Networks. Electronics. 2022; 11(7):989. https://doi.org/10.3390/electronics11070989
Chicago/Turabian StyleDash, Lucy, Binod Kumar Pattanayak, Sambit Kumar Mishra, Kshira Sagar Sahoo, Noor Zaman Jhanjhi, Mohammed Baz, and Mehedi Masud. 2022. "A Data Aggregation Approach Exploiting Spatial and Temporal Correlation among Sensor Data in Wireless Sensor Networks" Electronics 11, no. 7: 989. https://doi.org/10.3390/electronics11070989
APA StyleDash, L., Pattanayak, B. K., Mishra, S. K., Sahoo, K. S., Jhanjhi, N. Z., Baz, M., & Masud, M. (2022). A Data Aggregation Approach Exploiting Spatial and Temporal Correlation among Sensor Data in Wireless Sensor Networks. Electronics, 11(7), 989. https://doi.org/10.3390/electronics11070989