
Fully Automatic Analysis of Muscle B-Mode Ultrasound Images Based on the Deep Residual Shrinkage U-Net


Abstract
1. Introduction
- We analyzed the existing muscle ultrasound image analysis methods, including those using image processing technology and deep learning technology, and summarized their advantages and limitations.
- We propose a fully automatic muscle ultrasound image analysis method based on RS-Unet. It can analyze muscle ultrasound images with complex noise more accurately without any manual preprocessing. The parameters of muscle thickness, pennation angle and fascicle length can be easily calculated.
- A new network model called RS-Unet is proposed for muscle ultrasound image segmentation. It is stable and robust. In the future, it has the potential to be applied in other ultrasonic image analysis fields.
2. Materials and Methods
2.1. Network Architecture of RS-Unet
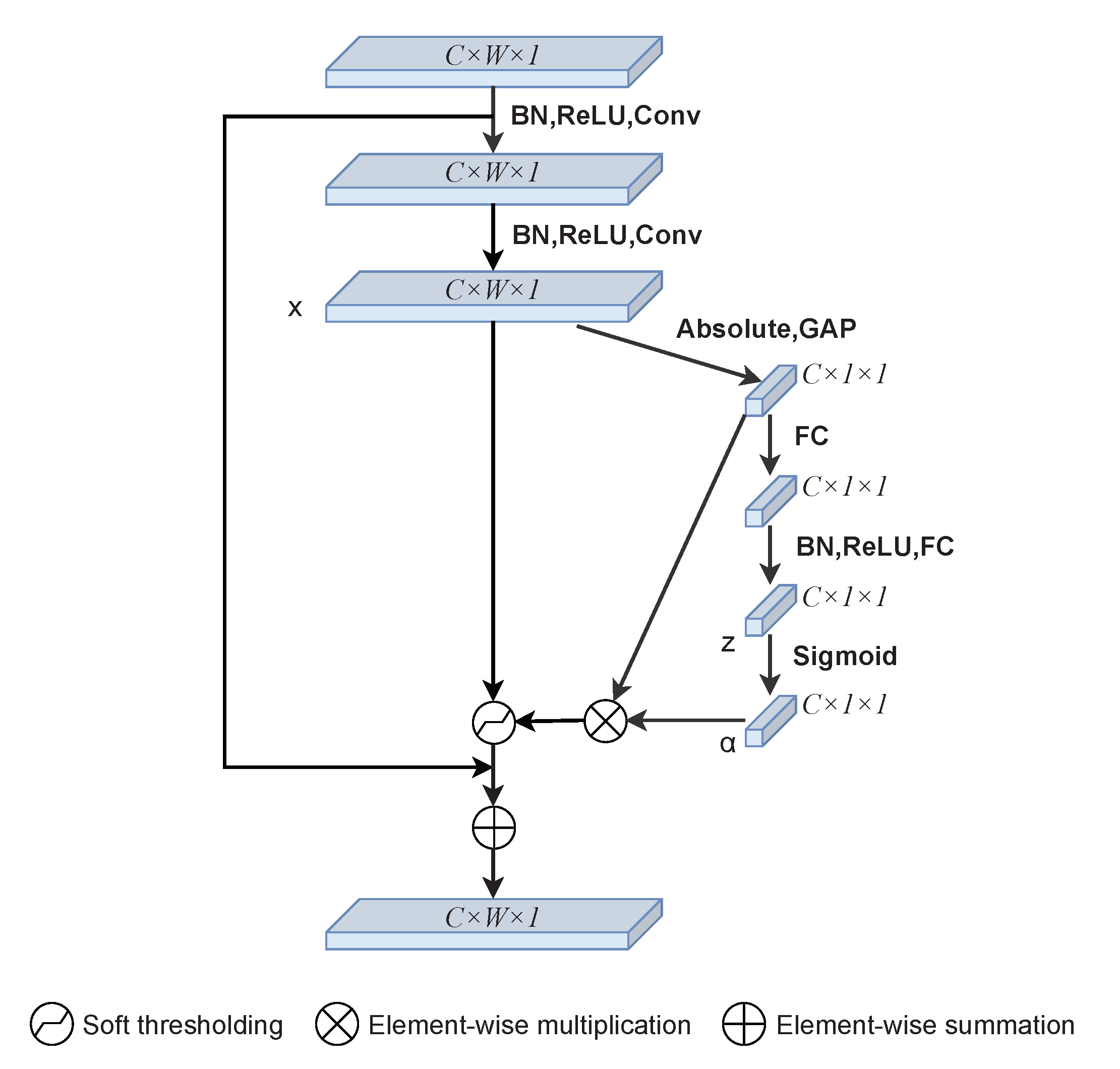
2.2. Deep Residual Shrinkage Block
2.3. Loss Function
3. Results
3.1. Datasets
3.2. Details and Training
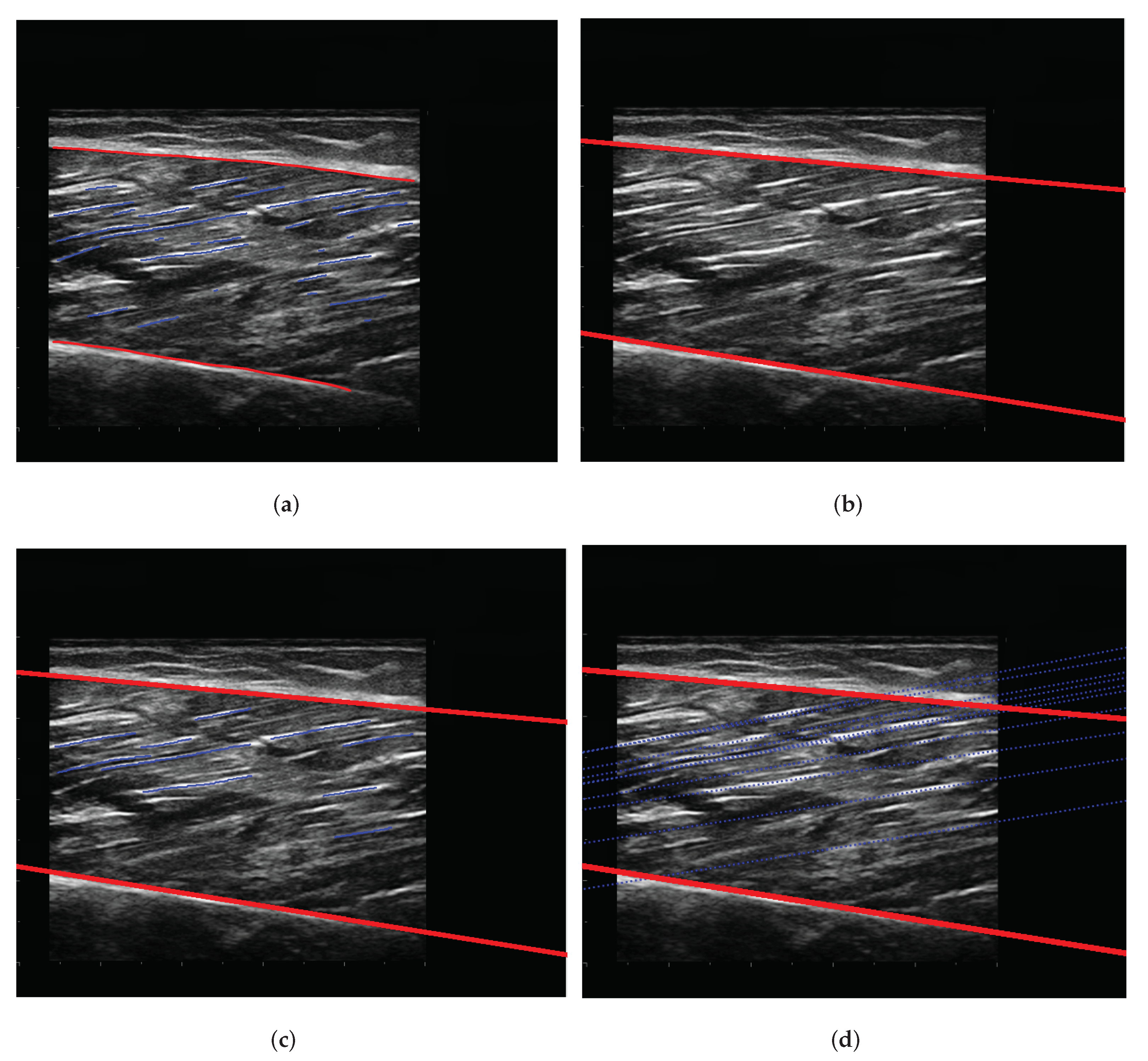
3.3. Segmentation results
3.4. Post-Processing
|
|
|
|
4. Discussion
4.1. Analysis of the Network Model
4.2. Analysis of Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Frontera, W.R.; Ochala, J. Skeletal muscle: A brief review of structure and function. Calcif. Tissue Int. 2015, 96, 183–195. [Google Scholar] [CrossRef]
- Yuan, C.; Chen, Z.; Wang, M.; Zhang, J.; Sun, K.; Zhou, Y. Dynamic measurement of pennation angle of gastrocnemius muscles obtained from ultrasound images based on gradient Radon transform. Biomed. Signal Processing Control 2020, 55, 101604. [Google Scholar] [CrossRef]
- Nicolson, M.; Fleming, J.E. Imaging and Imagining the Fetus: The Development of Obstetric Ultrasound; JHU Press: Baltimore, MD, USA, 2013. [Google Scholar]
- Havlice, J.F.; Taenzer, J.C. Medical ultrasonic imaging: An overview of principles and instrumentation. Proc. IEEE 1979, 67, 620–641. [Google Scholar] [CrossRef]
- Zheng, Y.P.; Chan, M.; Shi, J.; Chen, X.; Huang, Q.H. Sonomyography: Monitoring morphological changes of forearm muscles in actions with the feasibility for the control of powered prosthesis. Med. Eng. Phys. 2006, 28, 405–415. [Google Scholar] [CrossRef]
- Cronin, N.J.; Lichtwark, G. The use of ultrasound to study muscle–tendon function in human posture and locomotion. Gait Posture 2013, 37, 305–312. [Google Scholar] [CrossRef]
- Guo, J.Y.; Zheng, Y.P.; Xie, H.B.; Koo, T.K. Towards the application of one-dimensional sonomyography for powered upper-limb prosthetic control using machine learning models. Prosthetics Orthot. Int. 2013, 37, 43–49. [Google Scholar] [CrossRef][Green Version]
- Zhao, H.; Zhang, L.Q. Automatic tracking of muscle fascicles in ultrasound images using localized radon transform. IEEE Trans. Biomed. Eng. 2011, 58, 2094–2101. [Google Scholar] [CrossRef]
- Zhou, Y.; Zheng, Y.P. Estimation of muscle fiber orientation in ultrasound images using revoting hough transform (RVHT). Ultrasound Med. Biol. 2008, 34, 1474–1481. [Google Scholar] [CrossRef]
- Namburete, A.I.; Rana, M.; Wakeling, J.M. Computational methods for quantifying in vivo muscle fascicle curvature from ultrasound images. J. Biomech. 2011, 44, 2538–2543. [Google Scholar] [CrossRef]
- Cronin, N.J.; Carty, C.P.; Barrett, R.S.; Lichtwark, G. Automatic tracking of medial gastrocnemius fascicle length during human locomotion. J. Appl. Physiol. 2011, 111, 1491–1496. [Google Scholar] [CrossRef]
- Zhou, G.Q.; Chan, P.; Zheng, Y.P. Automatic measurement of pennation angle and fascicle length of gastrocnemius muscles using real-time ultrasound imaging. Ultrasonics 2015, 57, 72–83. [Google Scholar] [CrossRef]
- Caresio, C.; Salvi, M.; Molinari, F.; Meiburger, K.M.; Minetto, M.A. Fully automated muscle ultrasound analysis (MUSA): Robust and accurate muscle thickness measurement. Ultrasound Med. Biol. 2017, 43, 195–205. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Shen, D.; Wu, G.; Suk, H.I. Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef]
- Salakhutdinov, R. Learning deep generative models. Annu. Rev. Stat. Its Appl. 2015, 2, 361–385. [Google Scholar] [CrossRef]
- Suk, H.I.; Lee, S.W.; Shen, D.; Alzheimer’s Disease Neuroimaging Initiative. Hierarchical feature representation and multimodal fusion with deep learning for AD/MCI diagnosis. NeuroImage 2014, 101, 569–582. [Google Scholar] [CrossRef]
- Suk, H.I.; Wee, C.Y.; Lee, S.W.; Shen, D. State-space model with deep learning for functional dynamics estimation in resting-state fMRI. NeuroImage 2016, 129, 292–307. [Google Scholar] [CrossRef]
- Dou, Q.; Chen, H.; Yu, L.; Zhao, L.; Qin, J.; Wang, D.; Mok, V.C.; Shi, L.; Heng, P.A. Automatic detection of cerebral microbleeds from MR images via 3D convolutional neural networks. IEEE Trans. Med. Imaging 2016, 35, 1182–1195. [Google Scholar] [CrossRef]
- Brosch, T.; Tang, L.Y.; Yoo, Y.; Li, D.K.; Traboulsee, A.; Tam, R. Deep 3D convolutional encoder networks with shortcuts for multiscale feature integration applied to multiple sclerosis lesion segmentation. IEEE Trans. Med. Imaging 2016, 35, 1229–1239. [Google Scholar] [CrossRef]
- Roux, L.; Racoceanu, D.; Loménie, N.; Kulikova, M.; Irshad, H.; Klossa, J.; Capron, F.; Genestie, C.; Le Naour, G.; Gurcan, M.N. Mitosis detection in breast cancer histological images An ICPR 2012 contest. J. Pathol. Inform. 2013, 4, 8. [Google Scholar] [CrossRef]
- Cunningham, R.; Harding, P.; Loram, I. Deep residual networks for quantification of muscle fiber orientation and curvature from ultrasound images. In Proceedings of the Annual Conference on Medical Image Understanding and Analysis, Edinburgh, UK, 11–13 July 2017; Springer: Cham, Switzerland, 2017; pp. 63–73. [Google Scholar]
- Cunningham, R.; Sánchez, M.B.; May, G.; Loram, I. Estimating full regional skeletal muscle fibre orientation from B-mode ultrasound images using convolutional, residual, and deconvolutional neural networks. J. Imaging 2018, 4, 29. [Google Scholar] [CrossRef]
- Zheng, W.; Liu, S.; Chai, Q.W.; Pan, J.S.; Chu, S.C. Automatic Measurement of Pennation Angle from Ultrasound Images using Resnets. Ultrason. Imaging 2021, 43, 74–87. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Cronin, N.J.; Finni, T.; Seynnes, O. Fully automated analysis of muscle architecture from B-mode ultrasound images with deep learning. arXiv 2020, arXiv:2009.04790. [Google Scholar]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2528–2535. [Google Scholar]
- Zhao, M.; Zhong, S.; Fu, X.; Tang, B.; Pecht, M. Deep residual shrinkage networks for fault diagnosis. IEEE Trans. Ind. Inform. 2019, 16, 4681–4690. [Google Scholar] [CrossRef]
- Donoho, D.L. De-noising by soft-thresholding. IEEE Trans. Inf. Theory 1995, 41, 613–627. [Google Scholar] [CrossRef]
- Isogawa, K.; Ida, T.; Shiodera, T.; Takeguchi, T. Deep shrinkage convolutional neural network for adaptive noise reduction. IEEE Signal Processing Lett. 2017, 25, 224–228. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Schindelin, J.; Arganda-Carreras, I.; Frise, E.; Kaynig, V.; Longair, M.; Pietzsch, T.; Preibisch, S.; Rueden, C.; Saalfeld, S.; Schmid, B.; et al. Fiji: An open-source platform for biological-image analysis. Nat. Methods 2012, 9, 676–682. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Bland, J.M.; Altman, D. Statistical methods for assessing agreement between two methods of clinical measurement. Lancet 1986, 327, 307–310. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Acc (%) | IoU (%) | DSC (%) |
|---|---|---|---|
| RS-Unet (without shrinkage) | 98.19 | 97.81 | 72.95 |
| RS-Unet (with shrinkage) | 98.32 | 97.95 | 73.72 |
| Models | Acc (%) | IoU (%) | DSC (%) |
|---|---|---|---|
| RS-Unet (hard thresholding) | 98.09 | 97.77 | 70.90 |
| RS-Unet (soft thresholding) | 98.32 | 97.95 | 73.72 |
| Models | Acc (%) | IoU (%) | DSC (%) | Precision (%) | Recall (%) | F-Score (%) |
|---|---|---|---|---|---|---|
| U-Net | 98.13 | 97.67 | 72.00 | 97.37 | 97.36 | 97.36 |
| ResU-Net | 97.98 | 97.87 | 69.90 | 97.31 | 97.33 | 97.31 |
| RS-CBAM-Unet | 98.18 | 97.82 | 73.20 | 97.32 | 97.31 | 97.33 |
| RS-Unet | 98.32 | 97.95 | 73.72 | 98.74 | 98.74 | 99.25 |
| Methods | RMSEs | SD | The 95% Confidence Limits | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pennation | Length | Thickness | Pennation | Length | Thickness | Pennation | Length | Thickness | ||
| human2 | DL | 1.1367 | 2.7652 | 0.9456 | 1.1482 | 2.3793 | 0.3911 | −0.3153∼0.3373 | −2.1248∼−0.7725 | −0.9728∼−0.7516 |
| Proposed | 1.0090 | 2.5086 | 0.8942 | 0.9956 | 2.3417 | 0.3688 | −0.4992∼0.0667 | −1.6244∼−0.2934 | −0.9210∼−0.7114 | |
| human3 | DL | 1.3912 | 3.3116 | 0.7354 | 1.4404 | 3.2581 | 0.3238 | −0.3506∼0.4477 | −1.9526∼−0.1495 | −0.7539∼−0.5699 |
| Proposed | 1.3218 | 3.2738 | 0.6903 | 1.3230 | 3.1723 | 0.3160 | −0.5547∼0.1973 | −1.4872∼0.3647 | −0.7052∼−0.5256 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, W.; Zhou, L.; Chai, Q.; Xu, J.; Liu, S. Fully Automatic Analysis of Muscle B-Mode Ultrasound Images Based on the Deep Residual Shrinkage U-Net. Electronics 2022, 11, 1093. https://doi.org/10.3390/electronics11071093
Zheng W, Zhou L, Chai Q, Xu J, Liu S. Fully Automatic Analysis of Muscle B-Mode Ultrasound Images Based on the Deep Residual Shrinkage U-Net. Electronics. 2022; 11(7):1093. https://doi.org/10.3390/electronics11071093
Chicago/Turabian StyleZheng, Weimin, Linxueying Zhou, Qingwei Chai, Jianguo Xu, and Shangkun Liu. 2022. "Fully Automatic Analysis of Muscle B-Mode Ultrasound Images Based on the Deep Residual Shrinkage U-Net" Electronics 11, no. 7: 1093. https://doi.org/10.3390/electronics11071093
APA StyleZheng, W., Zhou, L., Chai, Q., Xu, J., & Liu, S. (2022). Fully Automatic Analysis of Muscle B-Mode Ultrasound Images Based on the Deep Residual Shrinkage U-Net. Electronics, 11(7), 1093. https://doi.org/10.3390/electronics11071093