
Efficient Garbage Collection Algorithm for Low Latency SSD

Abstract
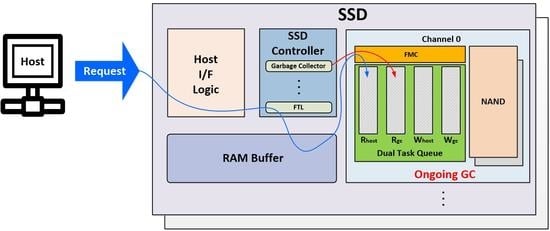
:
1. Introduction
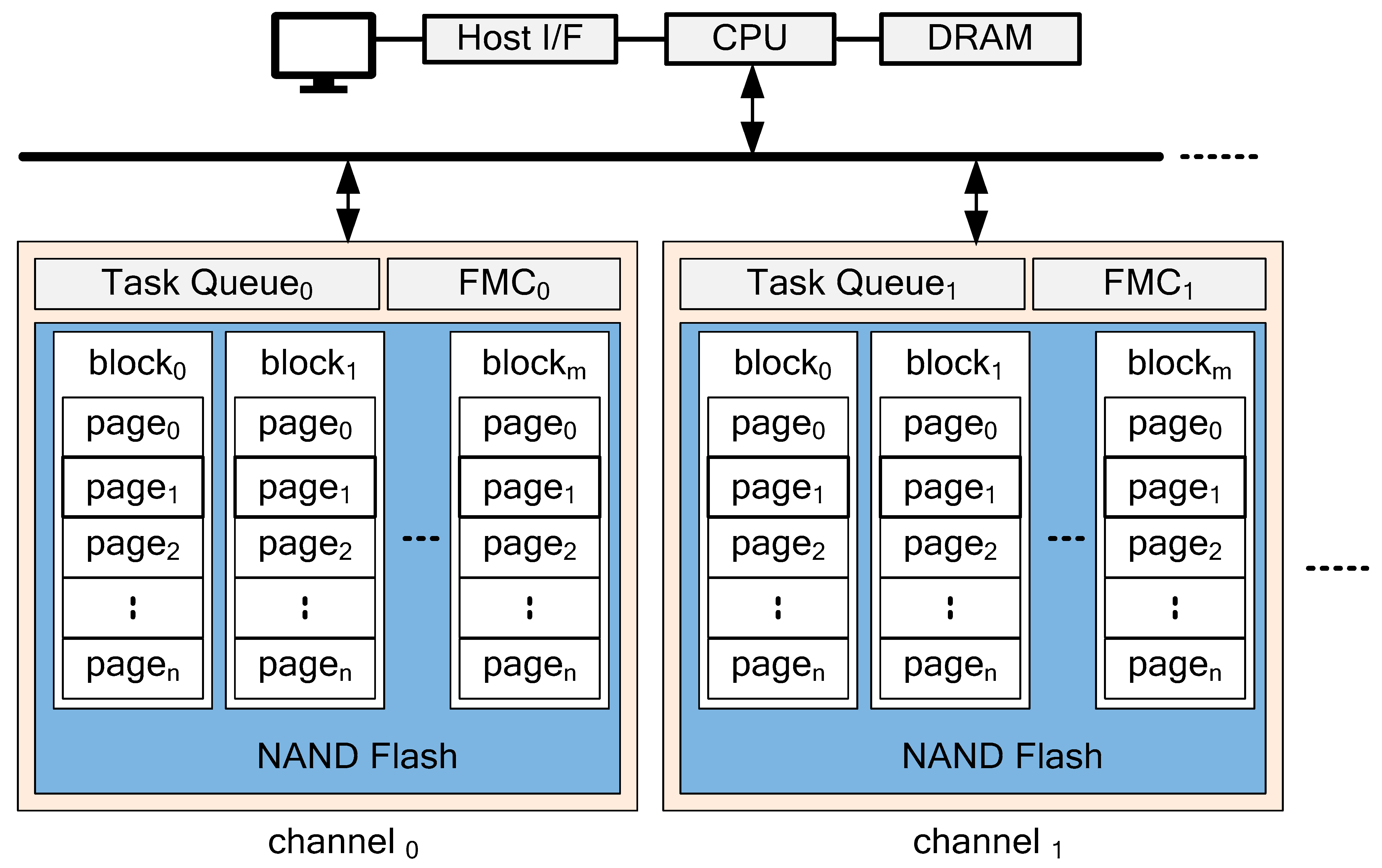
2. Background
3. Related Work
3.1. RW Blocking Level
3.2. Pre-Emption
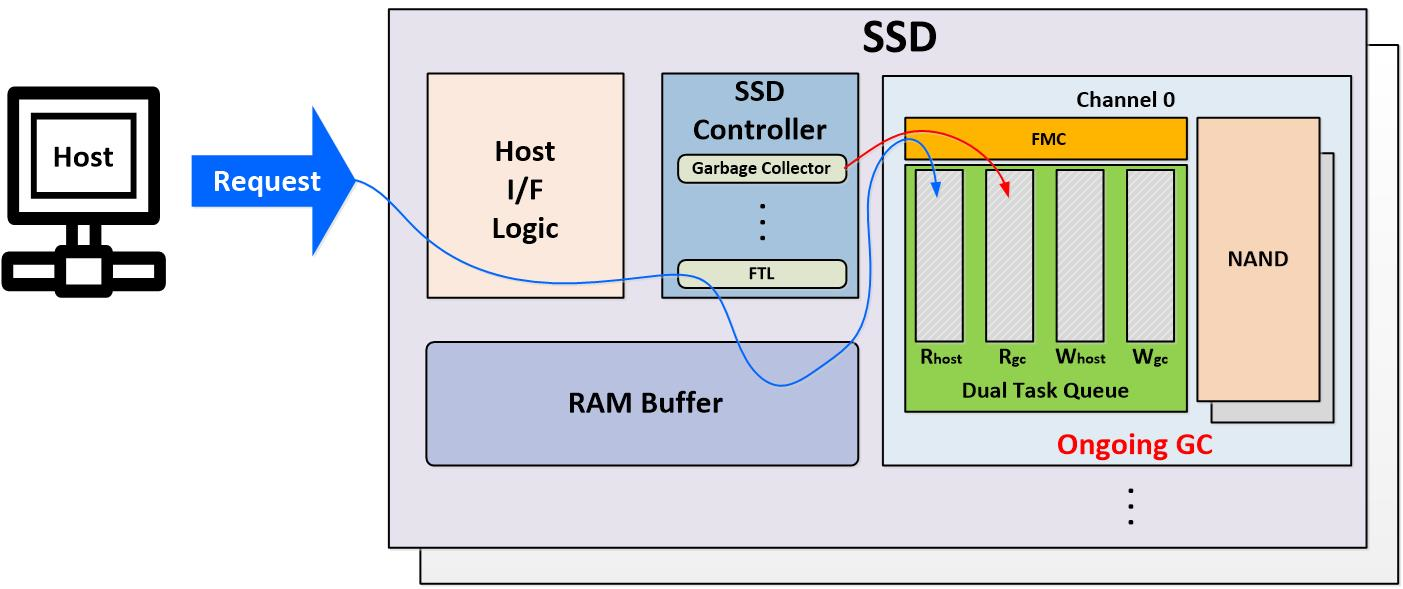
4. Proposed Garbage Collection Algorithm
4.1. Motivation
4.2. Block-Level Blocking
4.3. Dual-Task Queues (DTQ) for Priority Control
5. Evaluation
5.1. Experimental Setup
| Algorithm 1: Enqueue CopyBack request to DualTaskQueue GC |
|
| Algorithm 2: Enqueue file-write request to DualTaskQueue |
|
| Algorithm 3: Enqueue file-read request to DualTaskQueue |
|
5.2. Trace File Analysis
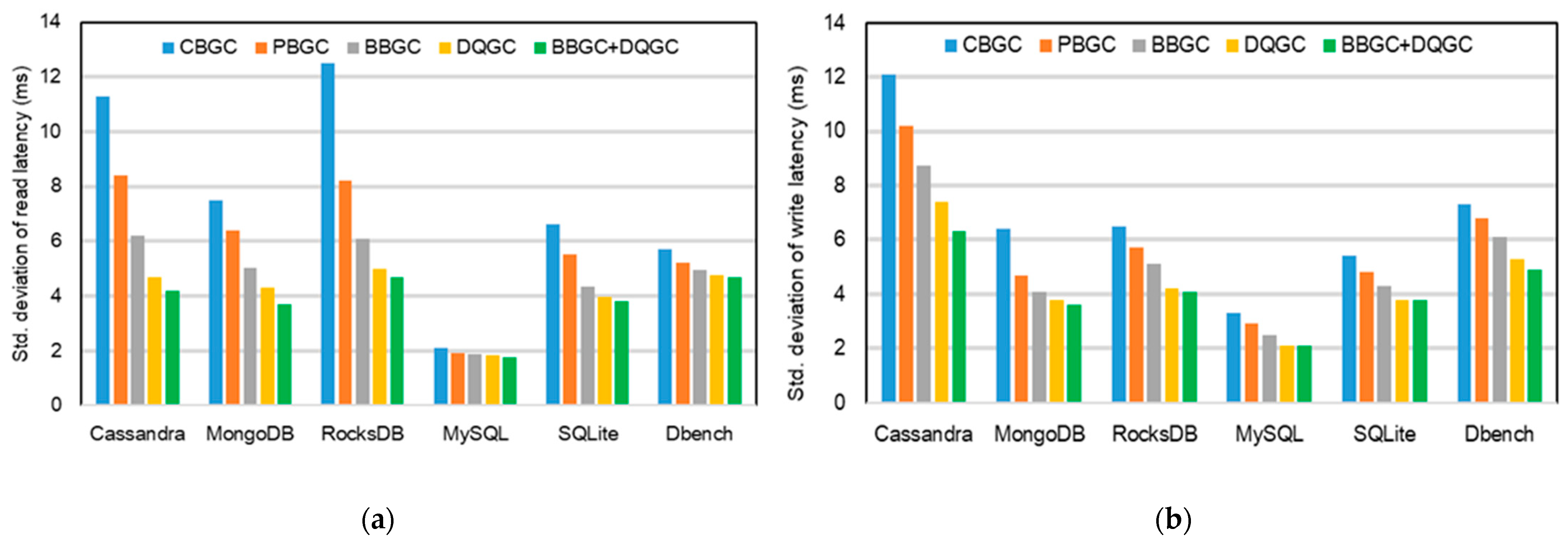
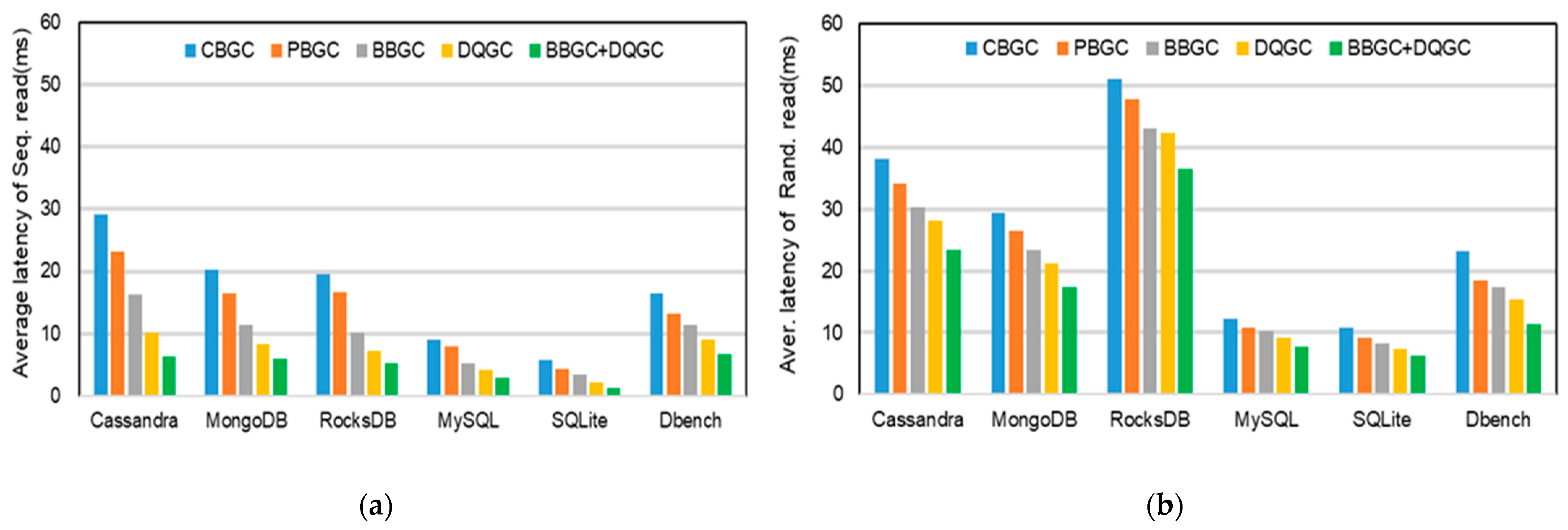
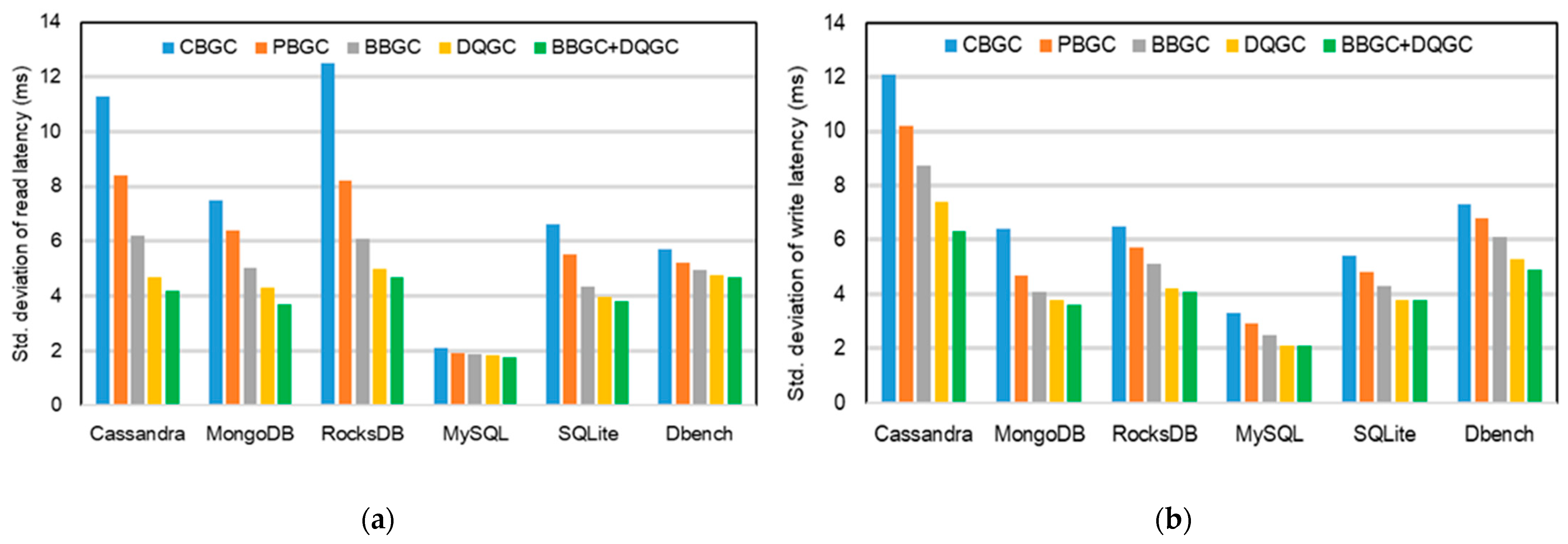
5.3. Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, F.; Koufaty, D.A.; Zhang, X. Understanding Intrinsic Characteristics and System Implications of Flash Memory Based Solid State Drives. In Proceedings of the 11th International Joint Conference on Measurement and Modeling of Computer Systems (SIGMETRICS 09), Seatle, WA, USA, 15–19 June 2009. [Google Scholar]
- Bux, W.; Iliadis, I. Performance of greedy garbage collection in flash-based solid-state drives. Perform. Eval. 2010, 67, 1172–1186. [Google Scholar] [CrossRef]
- Jang, K.H.; Han, T.H. Efficient garbage collection policy and block management method for NAND flash memory. In Proceedings of the 2010 2nd International Conference on Mechanical and Electronics Engineering (ICMEE), Kyoto, Japan, 1–3 August 2010. [Google Scholar]
- Zhang, Q.; Li, X.; Wang, L.; Zhang, T.; Wang, Y.; Shao, Z. Optimizing deterministic garbage collection in NAND flash storage systems. In Proceedings of the 21st IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS), Seatle, WA, USA, 13–16 April 2015. [Google Scholar]
- Seppanen, E.; O’Keefe, M.T.; Lilja, D.J. High-performance solid-state storage under Linux. In Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Nevada, NV, USA, 3–7 May 2010. [Google Scholar]
- Guo, J.; Hu, Y.; Mao, B.; Wu, S. Parallelism and Garbage Collection Aware I/O Scheduler with Improved SSD Performance. In Proceedings of the 2017 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Orlando, FL, USA, 29 May–2 June 2017. [Google Scholar]
- Rho, E.; Joshi, K.; Shin, S.U.; Shetty, N.J.; Hwang, J.; Cho, S.; Lee, D.D.; Jeong, J. Fstream: Managing flash streams in the file system. In Proceedings of the 16th USENIX Conference on File and Storage Technologies (FAST 18), Oakland, CA, USA, 12–15 February 2018. [Google Scholar]
- Yan, S.; Li, H.; Hao, M.; Tong, M.H.; Sundararaman, S.; Chien, A.A.; Gunawi, H.S. Tiny-tail flash: Near-perfect elimination of garbage collection tail latencies in NAND SSDs. In Proceedings of the 15th USENIX Conference on File and Storage Technologies (FAST’17), Santa Clara, CA, USA, 27 February–2 March 2017. [Google Scholar]
- Lee, J.; Kim, Y.; Shipman, G.M.; Oral, S.; Kim, J. Preemptible I/O Scheduling of Garbage Collection for Solid State Drives. IEEE Trans. Comput.-Aided Des. Integr. Circ. Syst. 2013, 32, 247–260. [Google Scholar] [CrossRef]
- Yu, S.; Chen, P.Y. Emerging Memory Technologies: Recent Trends and Prospects. IEEE Solid-State Circ. Mag. 2016, 8, 43–56. [Google Scholar] [CrossRef]
- Spinelli, A.S.; Compagnoni, C.M.; Lacaita, A.L. Reliability of NAND Flash Memories: Planar Cells and Emerging Issues in 3D Devices. Computers 2017, 6, 16. [Google Scholar] [CrossRef]
- Jung, M.; Choi, W.; Srikantaiah, S.; Yoo, J.; Kandemir, M.T. HIOS: A host interface I/O scheduler for solid state disks. ACM SIGARCH Comput. Archit. News 2014, 42, 289–300. [Google Scholar] [CrossRef]
- Jin, Y.; Lee, B. Chapter One—A comprehensive survey of issues in solid state drives. In Advances in Computers; Elsevier: Amsterdam, The Netherlands, 2019; Volume 114, pp. 1–69. [Google Scholar]
- Wang, M.; Hu, Y. Exploit real-time fine-grained access patterns to partition write buffer to improve SSD performance and life-span. In Proceedings of the 32nd IEEE International Performance Computing and Communications Conference(IPCCC), San Diego, CA, USA, 6–8 December 2013. [Google Scholar]
- Li, J.; Xu, X.; Peng, X.; Liao, J. Pattern-based Write Scheduling and Read Balance-oriented Wear-Leveling for Solid State Drives. In Proceedings of the 35th Symposium on Mass Storage Systems and Technologies (MSST), Santa Clara, CA, USA, 20–24 May 2019. [Google Scholar]
- Park, J.K.; Kim, J. An MTS-CFQ I/O scheduler considering SSD garbage collection on virtual machine. In Proceedings of the 14th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Phuket, Thailand, 27–30 June 2017. [Google Scholar]
- Shi, X.; Liu, W.; He, L.; Jin, H.; Li, M.; Chen, Y. Optimizing the SSD Burst Buffer by Traffic Detection. ACM Trans. Archit. Code Optim. 2020, 17, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Hitcachi Global Storage Technologies Hard Disk Drive Specification Deskstar P7K500, CinemaStar P7K500 3.5 Inch Hard Disk Drive. Available online: https://www.manualslib.com/manual/280071/Hitachi-Cinemastar-P7k500.html?page=33#manual (accessed on 13 December 2021).
- Micron NAND Flash Memory MT29F16G08ABABA 16Gb Asynchronous/Synchonous NAND Features datasheet. Available online: https://www.micron.com/products/nand-flash/slc-nand/part-catalog/mt29f16g08ababawp-ait (accessed on 15 July 2020).
- Chung, T.S.; Park, D.J.; Park, S.; Lee, D.H.; Lee, S.W.; Song, J.H. A survey of Flash Translation Layer. J. Syst. Archit. 2009, 55, 332–343. [Google Scholar] [CrossRef]
- Park, C.; Cheon, W.; Kang, J.; Roh, K.; Cho, W.; Kin, J.S. A reconfigurable FTL (flash translation layer) architecture for NAND flash-based applications. ACM Trans. Embed. Comput. Syst. 2008, 7, 1–23. [Google Scholar] [CrossRef]
- Song, Y.; So, H.; Chun, Y.; Kim, H.S.; Hong, Y. An implementation of low latency address-mapping logic for SSD controllers. IEICE Electron. Express 2019, 16, 20190521. [Google Scholar] [CrossRef] [Green Version]
- Chamazcoti, S.A.; Miremadi, S.G. On designing endurance-aware erasure code for SSD-based storage systems. Microprocess. Microsyst. 2016, 45, 283–296. [Google Scholar] [CrossRef]
- Gal, E.; Toledo, S. Algorithms and data structures for flash memories. ACM Comput. Surv. 2005, 37, 138–163. [Google Scholar] [CrossRef]
- Wu, F.; Zhou, J.; Wang, S.; Du, Y.; Yang, C.; Xie, C. FastGC: Accelerate Garbage Collection via an Efficient Copyback-based Data Migration in SSDs. In Proceedings of the 55th ACM/ESDA/IEEE Design Automation Conference (DAC), San Fransisco, CA, USA, 24–28 June 2018. [Google Scholar]
- Agrawal, N.; Prabhakaran, V.; Wobber, T.; Davis, D.J.; Manasse, M.; Panigrahy, R. Design Tradeoffs for SSD Performance. In Proceedings of the 2008 USENIX Annual Technical Conference, Boston, MA, USA, 22–27 June 2008. [Google Scholar]
- Rostedt, S. Ftrace Linux Kernel tracing. In Proceedings of the Linux Conference Japan, Tokyo, Japan, 27–29 September 2010. [Google Scholar]
- Brunelle, A.D. Block i/o layer tracing: Blktrace. In Proceedings of the Gelato-Itanium Conference and Expo (Gelato ICE), San Jose, CA, USA, 23–26 April 2006. [Google Scholar]
- Sysbench Manual. Available online: http://imysql.com/wpcontent/uploads/2014/10/sysbench-manual.pdf (accessed on 22 December 2020).
- MySQL 8.0 Reference Manual. Available online: https://dev.mysql.com/doc/refman/8.0/en/ (accessed on 22 December 2020).
- Cooper, B.F.; Silberstein, A.; Tam, E.; Ramakrishnan, R.; Sears, R. Benchmarking cloud serving systems with YCSB. In Proceedings of the 1st ACM Symposium on Cloud Computing (SOCC 10), Indianapolis IN, USA, 10–11 June 2010. [Google Scholar]
- Apache Cassandra Documentation v4.0-beta4. Available online: https://cassandra.apache.org/doc/latest/ (accessed on 22 December 2020).
- MongoDB Documentation v5.0. Available online: https://docs.mongodb.com/manual/ (accessed on 13 July 2021).
- RocksDB Documentation. Available online: http://rocksdb.org/docs/getting-started.html (accessed on 13 July 2021).
- Phoronix Test Suite v10.0.0 User Manual. Available online: https://www.phoronix-test-suite.com/documentation/phoronix-test-suite.pdf (accessed on 22 December 2020).
- Basak, J.; Wadhwani, K.; Voruganti, K. Storage Workload Identification. ACM Trans. Storage 2016, 12, 1–30. [Google Scholar] [CrossRef]
- Kim, J.; Seo, S.; Jung, D.; Kim, J.S.; Huh, J. Parameter-Aware I/O Management for Solid State Disks (SSDs). IEEE Trans. Comput. 2011, 61, 636–649. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of Channels | 4 |
| Planes per Channel | 8 |
| Blocks per Plane | 2048 |
| Pages per Block | 128 |
| Page Size (KB) | 4 |
| Page Read Latency (μs) | 25 |
| Page Write Latency (μs) | 230 |
| Erase Latency (ms) | 0.7 |
| Workloads | Cassandra | MongoDB | RocksDB | MySQL | SQLite | Dbench |
|---|---|---|---|---|---|---|
| Read Ratio (%) | 73.2 | 57.8 | 65.4 | 6.4 | 2.3 | 2.1 |
| Write Ratio (%) | 26.8 | 42.2 | 34.6 | 93.6 | 97.7 | 97.9 |
| Seq. Request (%) | 56.5 | 80.8 | 23.1 | 97.3 | 3.3 | 4.7 |
| Rand. Request (%) | 43.5 | 19.1 | 76.9 | 2.7 | 96.7 | 95.3 |
| Aver. Read Size (KB) | 421.3 | 203.1 | 112.4 | 8.9 | 3.8 | 32.1 |
| Aver. Write Size (KB) | 298.7 | 89.4 | 78.6 | 8.3 | 4.6 | 42.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ae, J.; Hong, Y. Efficient Garbage Collection Algorithm for Low Latency SSD. Electronics 2022, 11, 1084. https://doi.org/10.3390/electronics11071084
Ae J, Hong Y. Efficient Garbage Collection Algorithm for Low Latency SSD. Electronics. 2022; 11(7):1084. https://doi.org/10.3390/electronics11071084
Chicago/Turabian StyleAe, Jin, and Youpyo Hong. 2022. "Efficient Garbage Collection Algorithm for Low Latency SSD" Electronics 11, no. 7: 1084. https://doi.org/10.3390/electronics11071084
APA StyleAe, J., & Hong, Y. (2022). Efficient Garbage Collection Algorithm for Low Latency SSD. Electronics, 11(7), 1084. https://doi.org/10.3390/electronics11071084