
AAPFE: Aligned Assembly Pre-Training Function Embedding for Malware Analysis


Abstract
:1. Introduction
- A data augmentation method with aligned assembly functions to generate a triple dataset aligned assembly triplet function (AATF) for binary function embedding was proposed.
- A multi-level embedding network framework that can simultaneously capture sequence information at the instruction level and structure information at the block level was designed.
- Aligned assembly pre-training function embedding (AAPFE) was pre-trained based on the created triple dataset AATF and triplet loss function.
- Extensive experiments were conducted, and the results demonstrated that the proposed model outperformed the state-of-the-art models in terms of precision, p@N, and area under the curve.
2. Related Work
2.1. Sequence-Based Embedding Methods
2.2. Graph-Based Embedding Methods
2.3. Embedding Methods Based on a Hybrid Structure
3. Proposed Approach
3.1. Overview
- The first part is the aligned assembly generation. The anchor assembly ASMa is generated by the compilation of a source code, and the positive assembly ASMp is obtained by the disassembly of the binary file Bin. Bin is derived from the same code. ASMa and ASMp are homologous assemblies with the same functionality and semantics; however, their syntax and structure are different. Next, the name is used as the index for alignment and preprocessing to obtain the aligned assembly functions. Meanwhile, random sampling from ASMn is adopted to obtain the negative functions to generate the assembly function triplet.
- The second part involves the function embedding net, which accepts triplets. Using multi-granularity embedding fusion, these three embedding nets have the same structures. The instruction sequence and basic block jump relationship information is embedded as a real-valued vector representing the assembly function at the instruction level and the basic block levels. After summing and normalizing the function vectors, the vector representing the assembly function is output.
- The final part is the learning target, which compares the output of the embedded vectors in pairs. The objective is to have the distance of the vector of the aligned assembly be lower than that of the unaligned assembly. The distance is used as part of the loss function for the gradient propagation. After training, the converged model parameters are obtained, and the AAPFE model is finally stored.
3.2. Dataset Collection
3.2.1. Aligned Assembly Generation
| Algorithm 1. Aligned Assembly Triplet Functions (AATF) Generation. |
 |
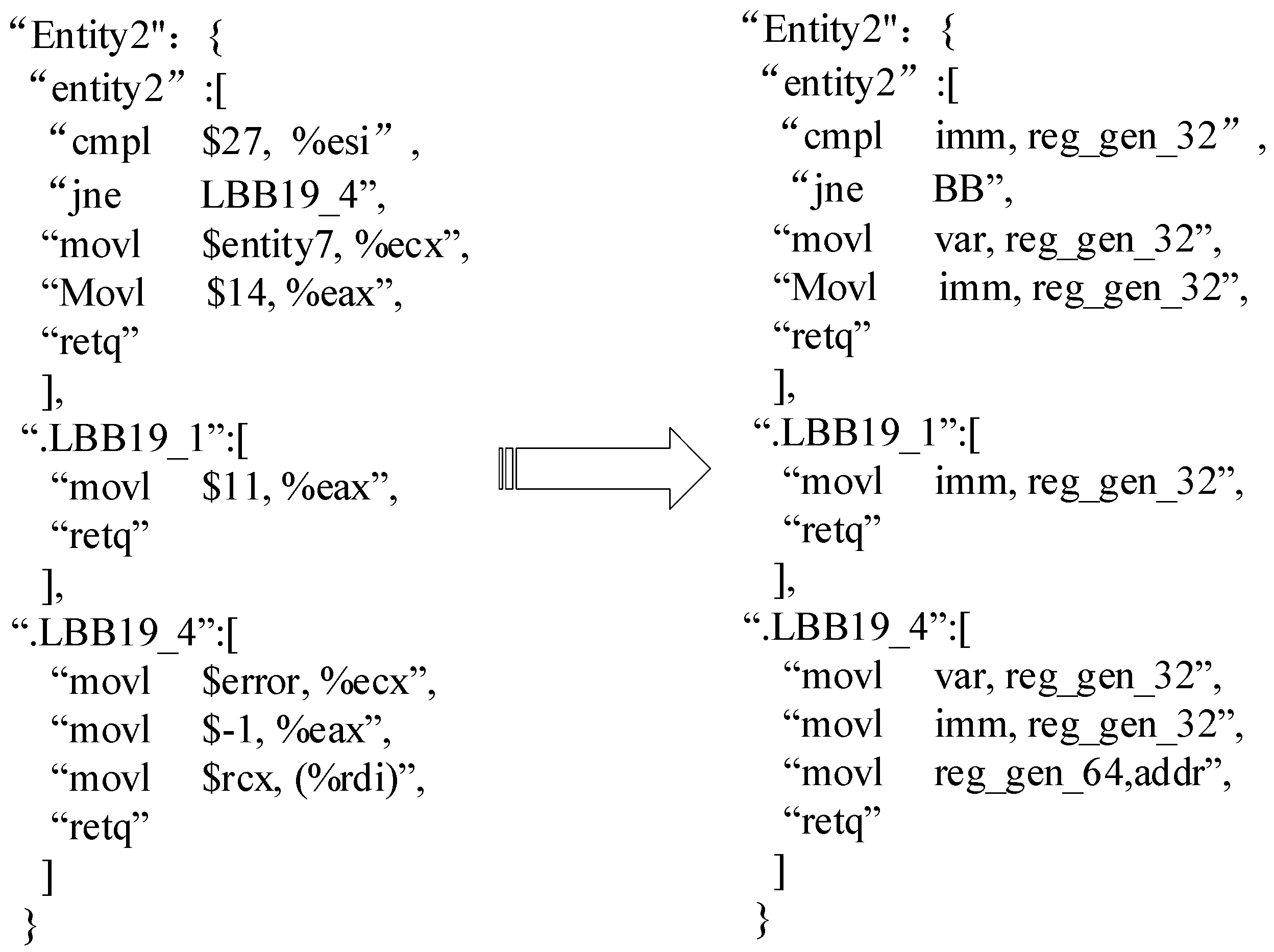
3.2.2. Preprocess
3.3. Function Embedding Sub-Network
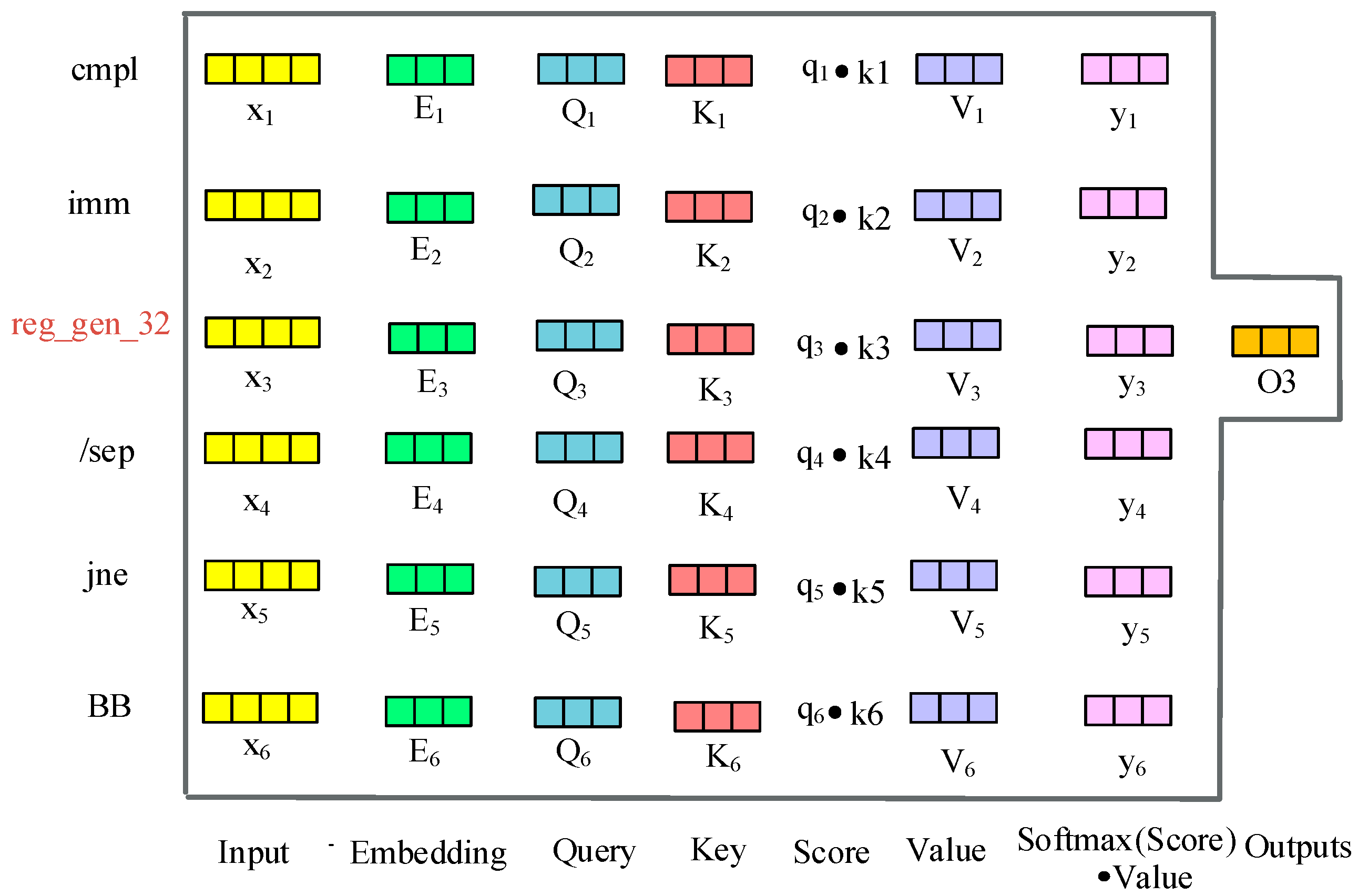
3.3.1. Self-Attention-Based Instruction Embedding
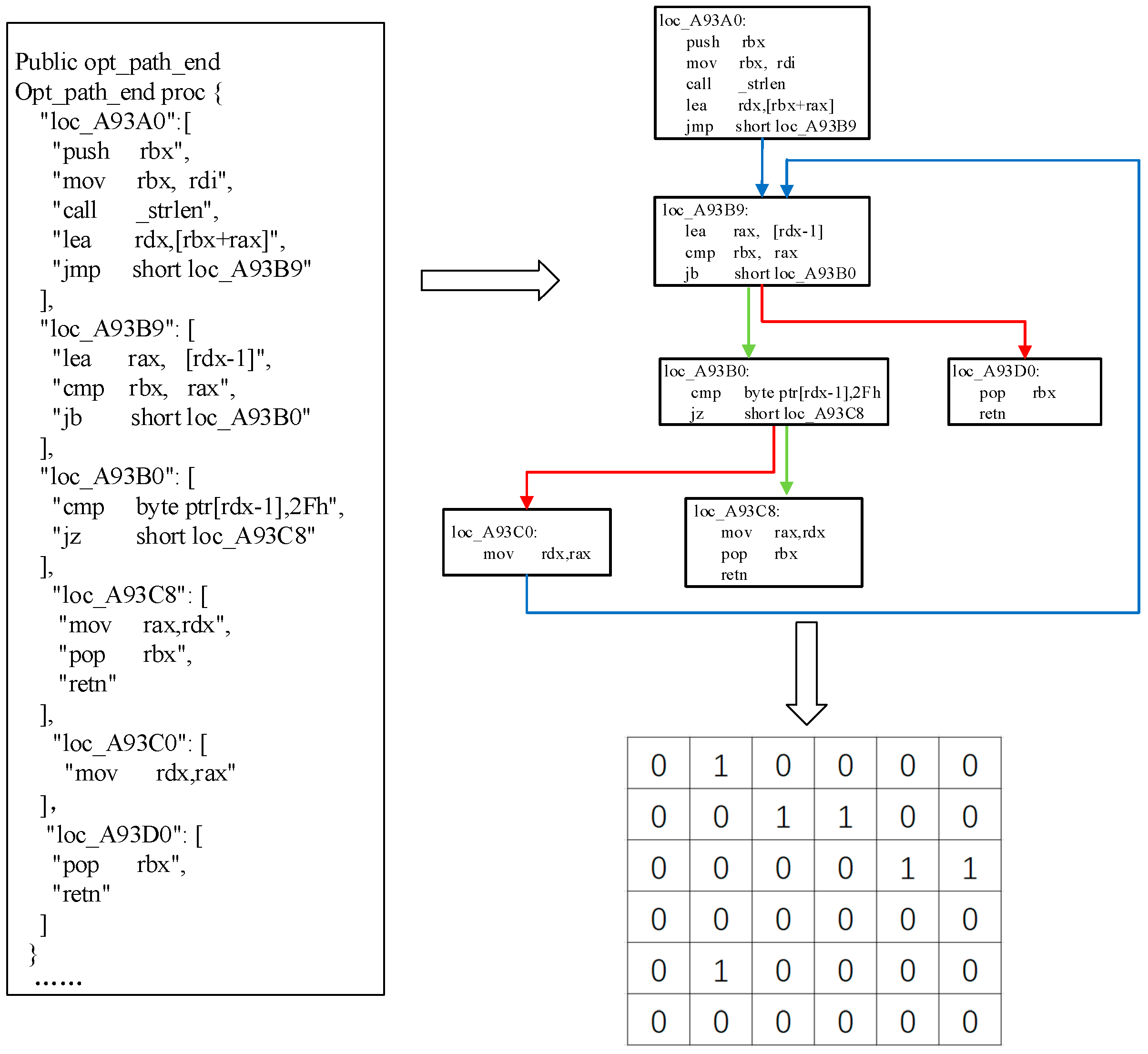
3.3.2. GCN-Based Basic Block Embedding
3.4. Model Training
3.4.1. Training Objective
3.4.2. Model Deployment
4. Experiments and Evaluation
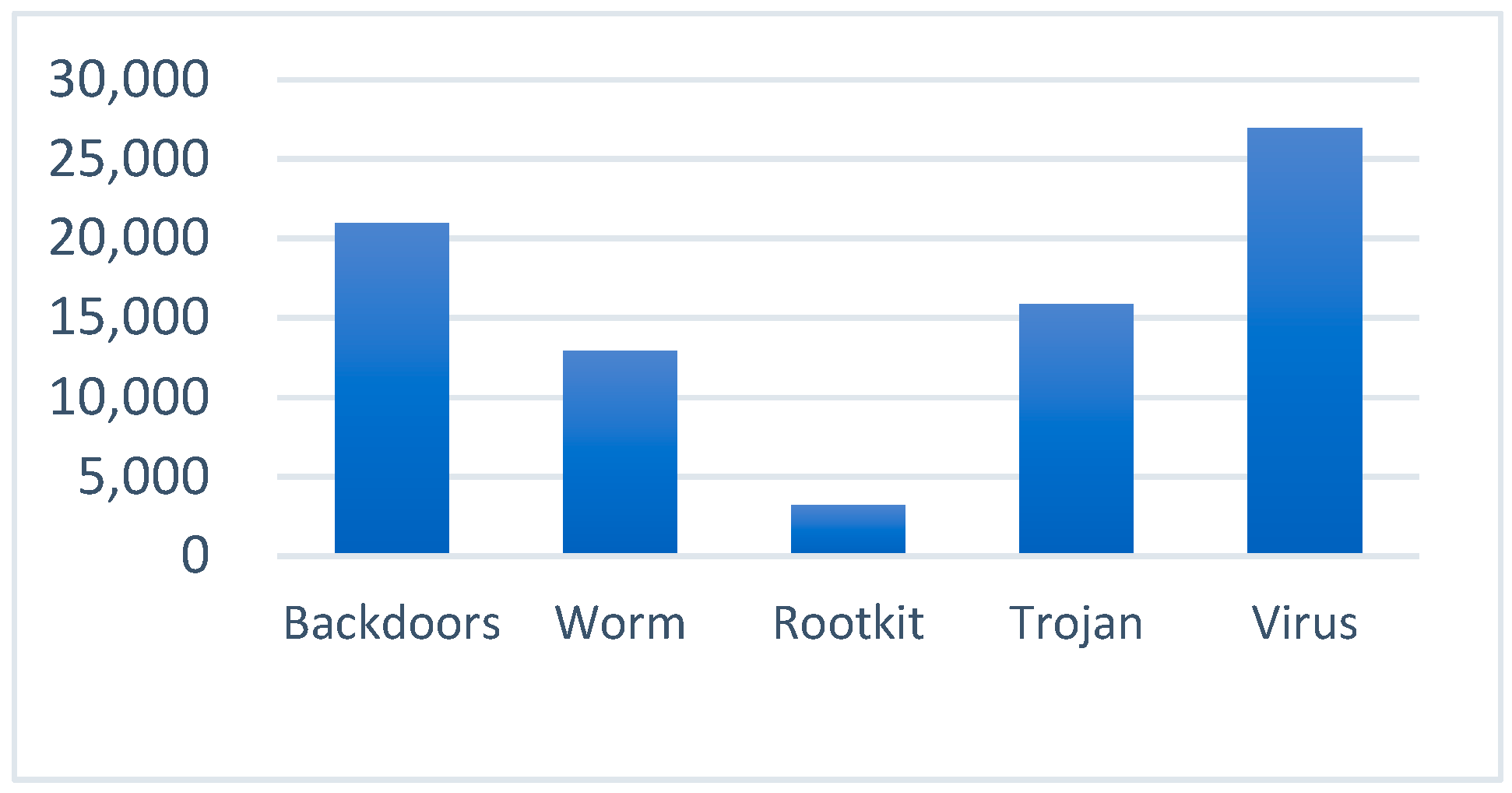
4.1. Experimental Setup
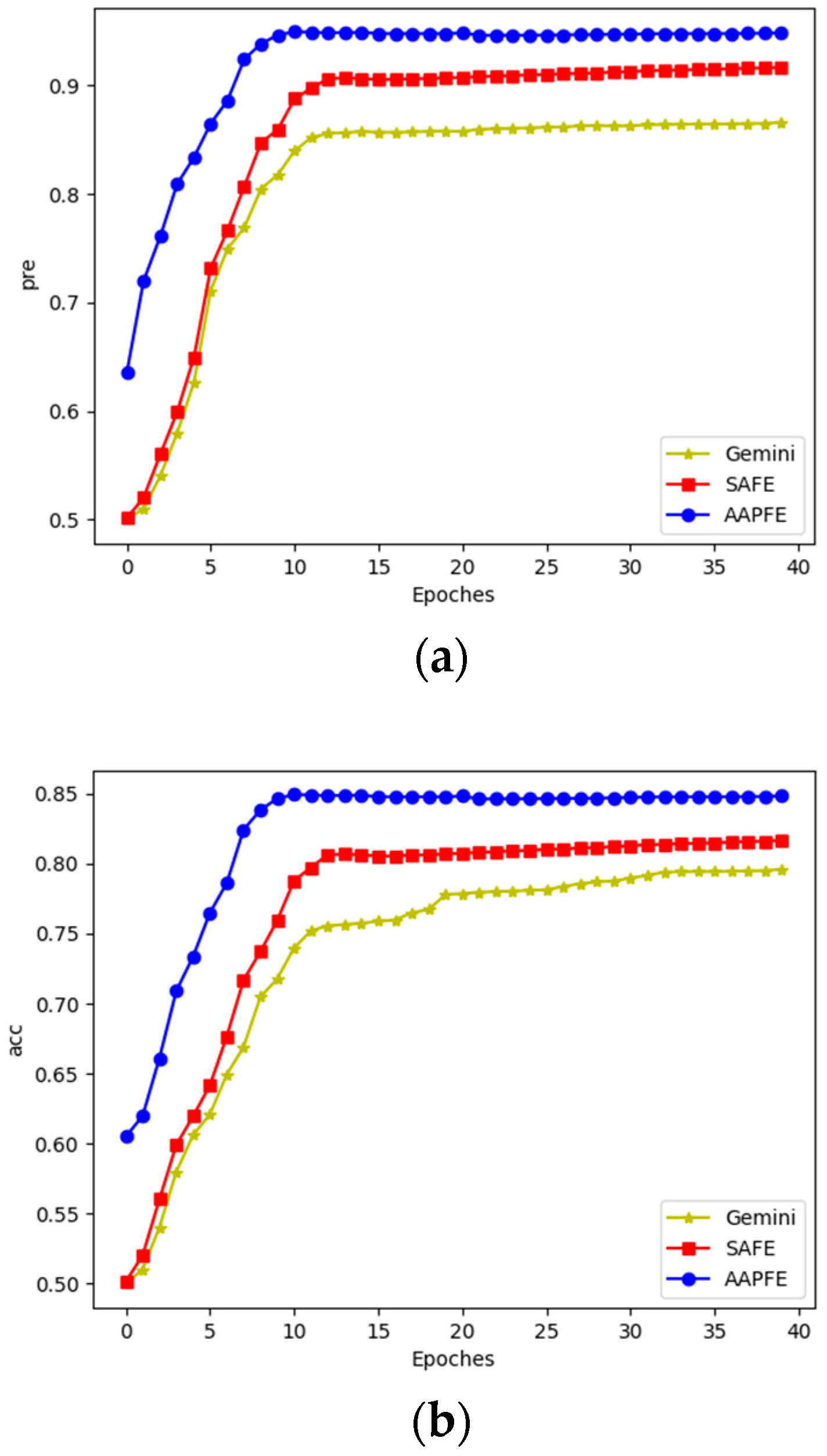
4.2. Performance Evaluation
- Similarity comparison task: The objective of this task was to have the Euclidean distance of the aligned assembly functions be lower than that of the unaligned assembly functions. Precision and accuracy were used as indicators to measure task performance; the dataset used was AATF.
- Function search task: This task was consistent with the pre-training task; given a source function, the target was to rank the aligned function as far as possible. The evaluation metric of the task was p@N, which represents the precision ranking of the objective function equivalent to the source function in this function set. The aligned assembly triplet function extension (AATFX) dataset with 10,000 function sets was obtained by augmenting AATF. Each function set contained a pair of aligned assembly functions in the form of triplet data from AATF; the other 99 functions were randomly selected samples, which were treated as negative samples. The source function was equivalent to the aligned objective function. The distance to the positive sample vector was the smallest. The source function was not equivalent to an unaligned assembly function; therefore, the distance should be greater than that of the aligned function.
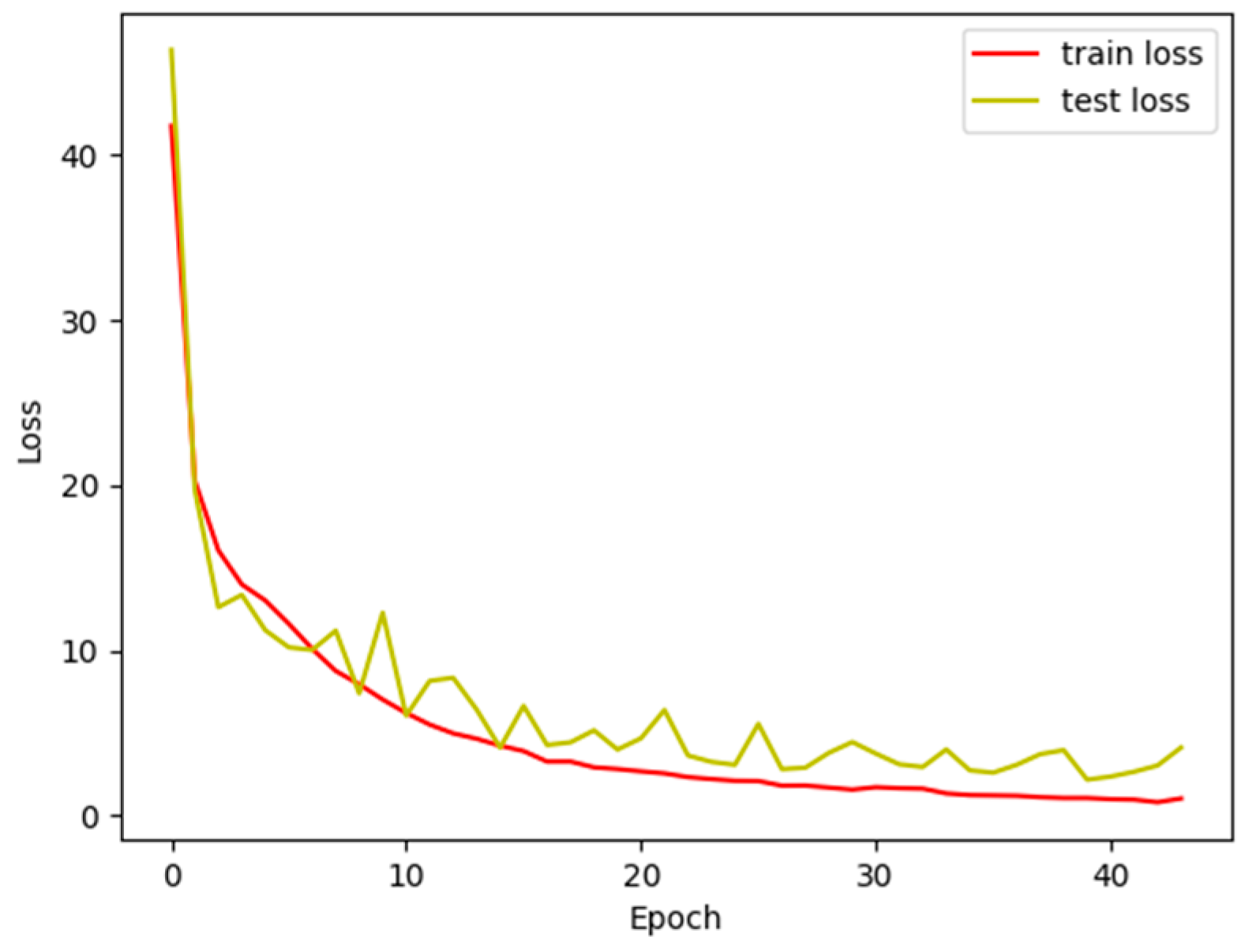
4.3. Training Evaluation
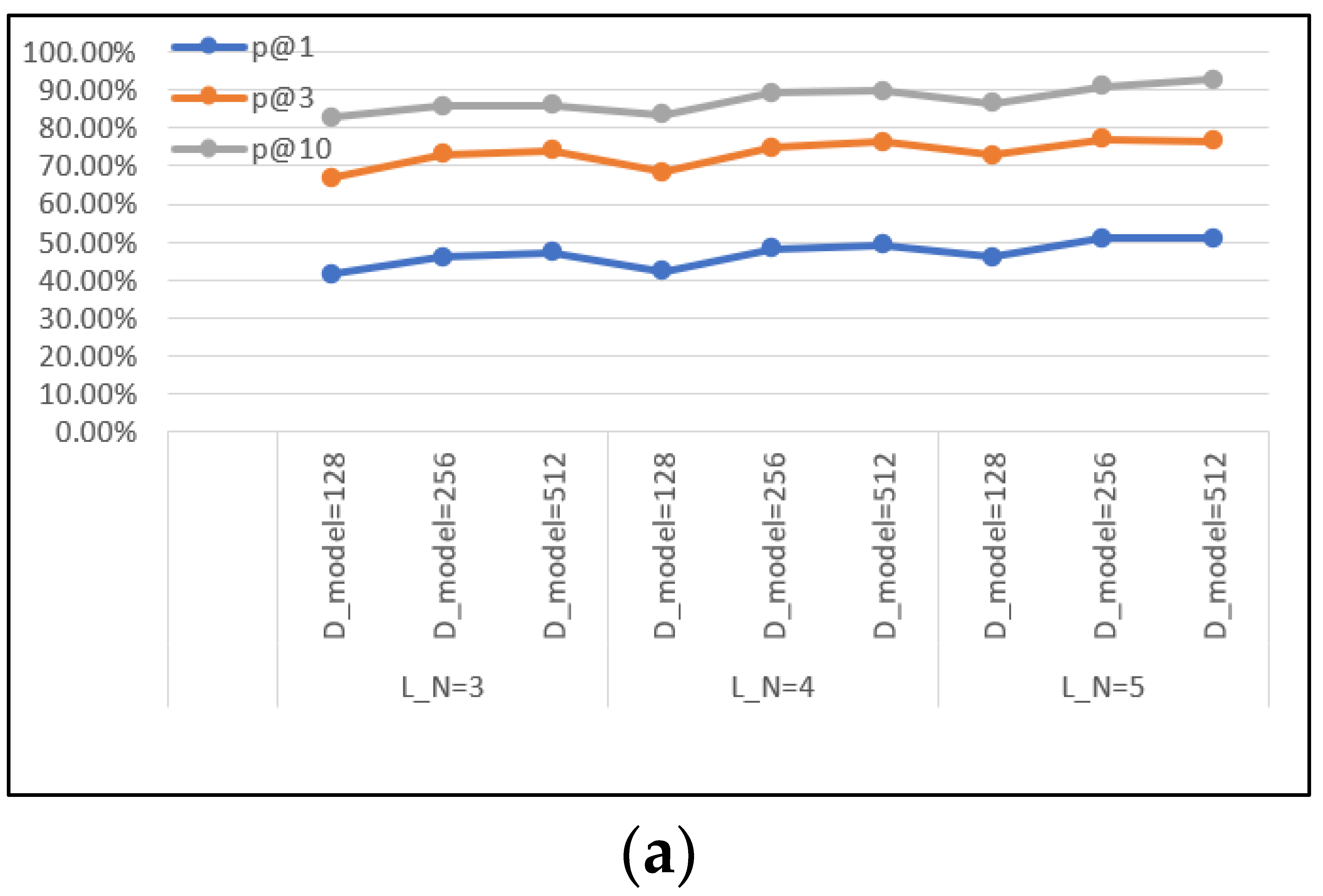
4.3.1. Hyperparameter Test
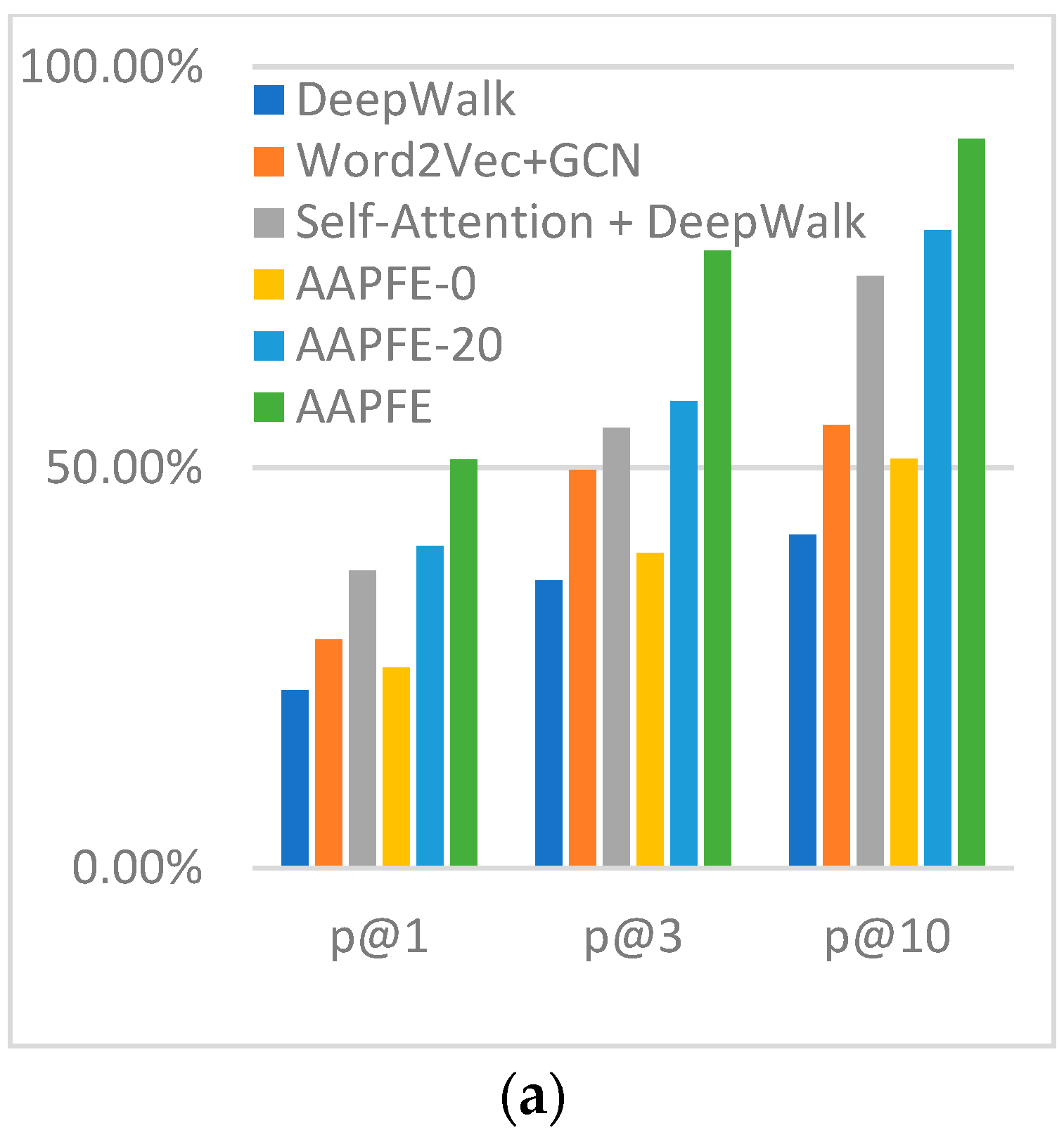
Ablation Evaluation
4.4. Application Evaluation
4.4.1. Malware Detection
4.4.2. Malware Classification
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yakdan, K.; Dechand, S.; Gerhards-Padilla, E.; Smith, M. Helping Johnny to Analyze Malware: A Usability-Optimized Decompiler and Malware Analysis User Study. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 23–25 May 2016; pp. 158–177. [Google Scholar]
- Xu, Z.; Ray, S.; Subramanyan, P.; Malik, S. Malware Detection Using Machine Learning Based Analysis of Virtual Memory Access Patterns. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Lausanne, Switzerland, 27–31 March 2017; pp. 169–174. [Google Scholar]
- Liu, L.; Wang, B.; Yu, B.; Zhong, Q. Automatic malware classification and new malware detection using machine learning. Front. Inf. Technol. Electron. Eng. 2017, 18, 1336–1347. [Google Scholar] [CrossRef]
- Kong, D.; Yan, G. Discriminant Malware Distance Learning on Structural Information for Automated Malware Classification. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1357–1365. [Google Scholar]
- Ding, S.H.; Fung, B.C.; Charland, P. Asm2vec: Boosting Static Representation Robustness for Binary Clone Search Against Code Obfuscation and Compiler Optimization. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–22 May 2019; pp. 472–489. [Google Scholar]
- Massarelli, L.; Di Luna, G.A.; Petroni, F.; Baldoni, R.; Querzoni, L. SAFE: Self-Attentive Function Embeddings for Binary Similarity. In Proceedings of the International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment, Gothenburg, Sweden, 19–20 June 2019; Springer: Berlin, Germany, 2019; pp. 309–329. [Google Scholar]
- Zuo, F.; Li, X.; Zhang, Z.; Oung, P.Y.; Luo, L.; Zeng, Q. Neural Machine Translation Inspired Binary Code Similarity Comparison Beyond Function Pairs. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 24–27 February 2019; pp. 24–27. [Google Scholar]
- Redmond, K.; Luo, L.; Zeng, Q. A cross-architecture instruction embedding model for natural language processing-inspired binary code analysis. arXiv Prepr. 2018, arXiv:1812.09652. [Google Scholar]
- Duan, Y.; Li, X.; Wang, J.; Yin, H. DeepBinDiff: Learning Program-Wide Code Representations for Binary Diffing. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 23–26 February 2020. [Google Scholar]
- Xu, X.; Liu, C.; Feng, Q.; Yin, H.; Song, L.; Song, D. Neural Network-Based Graph Embedding for Cross-Platform Binary Code Similarity Detection. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas TX, USA, 30 October–3 November 2017; pp. 363–376. [Google Scholar]
- Qiao, M.; Zhang, X.; Sun, H.; Shan, Z.; Liu, F.; Sun, W.; Li, X. Multi-level cross-architecture binary code similarity metric. Arab. J. Sci. Eng. 2021, 46, 8603–8615. [Google Scholar] [CrossRef]
- Huang, H.; Youssef, A.M.; Debbabi, M. Binsequence: Fast, Accurate and Scalable Binary Code Reuse Detection. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 155–166. [Google Scholar]
- Cauteruccio, F.; Cinelli, L.; Corradini, E.; Terracina, G.; Sa Va Glio, C. A framework for anomaly detection and classification in multiple IoT scenarios. Future Gener. Comput. Syst. 2021, 114, 322–335. [Google Scholar] [CrossRef]
- Liu, J.; Chen, Y.; Liu, K.; Zhao, J. Event Detection Via Gated Multilingual Attention Mechanism. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA; 2018; pp. 4865–4872. [Google Scholar]
- Liu, J.; Chen, Y.; Liu, K.; Zhao, J. Neural Cross-Lingual Event Detection with Minimal Parallel Resources. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 738–748. [Google Scholar]
- Zhang, X.; Sun, W.; Pang, J.; Liu, F.; Ma, Z. Similarity Metric Method for Binary Basic Blocks of Cross-Instruction Set Architecture. In Proceedings of the 2020 Workshop on Binary Analysis Research, San Diego, CA, USA, 23 February 2020. [Google Scholar]
- Li, X.; Qu, Y.; Yin, H. Palmtree: Learning an Assembly Language Model for Instruction Embedding. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, Korea, 15–19 November 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 3236–3251. [Google Scholar]
- Li, W.; Jin, S. A Simple Function Embedding Approach for Binary Similarity Detection. In Proceedings of the 2020 IEEE Intl Conference on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom), Exeter, UK, 17–19 December 2020; pp. 570–577. [Google Scholar]
- Feng, Q.; Zhou, R.; Xu, C.; Cheng, Y.; Testa, B.; Yin, H. Scalable Graph-Based Bug Search for Firmware Images. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 480–491. [Google Scholar]
- Yu, Z.; Cao, R.; Tang, Q.; Nie, S.; Huang, J.; Wu, S. Order Matters: Semantic-Aware Neural Networks for Binary Code Similarity Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1145–1152. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACLHLT 2019: Annual Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MI, USA, 3–5 June 2019; pp. 4171–4186. [Google Scholar]
- Hoffer, E.; Ailon, N. Deep Metric Learning Using Triplet Network. In Proceedings of the International Workshop on Similarity-Based Pattern Recognition, Berlin, Germany, 12–14 October 2015; pp. 84–92. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://arxiv.org/abs/1706.03762 (accessed on 13 March 2022).
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position representations. arXiv Prepr. 2018, arXiv:1803.02155. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4–24. [Google Scholar] [CrossRef] [Green Version]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; Vandergheynst, P. Geometric deep learning: Going beyond Euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef] [Green Version]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv Prepr. 2016, arXiv:1609.02907. [Google Scholar]
- Marcheggiani, D.; Titov, I. Encoding sentences with graph convolutional networks for semantic role labeling. arXiv Prepr. 2017, arXiv:1703.04826. [Google Scholar]
- Huang, Y.; Qiao, M.; Liu, F.; Li, X.; Gui, H.; Zhang, C. Binary code traceability of multigranularity information fusion from the perspective of software genes. Comput. Sec. 2022, 114, 102607. [Google Scholar] [CrossRef]
- Henaff, M.; Bruna, J.; LeCun, Y. Deep convolutional networks on graph-structured data. arXiv Prepr. 2015, arXiv:1506.05163. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How powerful are graph neural networks. arXiv Prepr. 2018, arXiv:1810.00826. [Google Scholar]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained models for natural language processing: A survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. DeepWalk: Online Learning of Social Representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, New York, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Spitzer, F. Principles of Random Walk; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2001; Volume 34. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv Prepr. 2013, arXiv:1301.3781. [Google Scholar]
- Available online: https://academictorrents.com/details/34ebe49a48aa532deb9c0dd08a08a017aa04d810 (accessed on 10 January 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Year | Embedding Method | Input Granularity | Approach Granularities | Semantic Capturable | Task Transferable | Large-Scale Dataset | Model Complexity | Computation Complexity |
|---|---|---|---|---|---|---|---|---|---|
| GENIUS [19] | 2016 | G | F | BB | × | × | √ | √ | H |
| GEMINI [10] | 2017 | H | F | BB, F | √ | × | √ | × | M |
| ASM2Vec [5] | 2019 | S | F | I | × | × | × | √ | M |
| SAFE [6] | 2019 | S | F | I, BB | √ | × | × | × | M |
| Li’s [18] | 2020 | S | BB | I, BB | × | × | × | × | L |
| DEEPBINDIFF [9] | 2020 | G | P | BB, F | √ | × | √ | √ | H |
| Qiao’s [11] | 2020 | H | BB | I, BB | √ | × | √ | × | M |
| MIRROR [16] | 2020 | S | BB | I | √ | × | √ | √ | M |
| Yu’s [20] | 2020 | H | BB | I, B | √ | √ | √ | × | H |
| PALMTREE [17] | 2021 | S | F | BB | √ | √ | √ | √ | H |
| Type | Character | Normalization |
|---|---|---|
| Constant | Address | addr |
| Variant name | var | |
| Immediate value | imm | |
| Basic block label | BB | |
| Function name | Func | |
| Register | Pointer type | reg_pointer |
| Float type | reg_float | |
| General type (8bit) | reg_gen_8 | |
| General type (32bit) | reg_gen_32 | |
| General type (64bit) | reg_gen_64 | |
| Address type (32bit) | reg_addr_32 | |
| Address type (64bit) | reg_addr_64 | |
| Data type (8bit) | reg_data_8 | |
| Data type (32bit) | reg_data_32 | |
| Data type (64bit) | reg_data_64 |
| Project | Version | Description |
|---|---|---|
| Cmake | 3.19.8 | Cross-platform build tool |
| libtomcrypt | 1.18.2 | Cryptographic toolkit |
| micropython | 1.14 | Python for microcontrollers |
| opencv | 4.5 | CV and ML library |
| Binutils | 2.30 | Binary tool |
| gdb | 10.1 | Debug tool |
| Redis | 4.0.13 | Database of key value |
| FFmpeg | 4.2.2 | Multimedia process tool |
| Libuv | 1.x | Asynchronous I/O library |
| Libpng | 1.6.38 | Graphic r/w library |
| VTK | 9.0.1 | Visualization toolkit |
| Curl | 7.37.1 | Data transmission tool |
| CoreUtils | 4.5.1 | GNU core library |
| Glibc | 2.33 | C runtime library of Linux |
| valgrind | 3.17.0 | Dynamic detection toolkit |
| OpenSSL | 1.1.1b | Cryptographic tool |
| Hyperparameter | Value | Description |
|---|---|---|
| d_model | 256 | Embedding dimension |
| GCN_depth | 5 | Number of GCN layer |
| α | 120 | Margin |
| Max_len | 45 | Maximum length of basic block |
| Max_size | 100 | Maximum length of function |
| lr | 0.001 | Learning rate |
| Dropout | 0.1 | Dropout coefficient |
| Opt | SGD | Optimization algorithm |
| B_size | 32 | Batch size |
| d_ff | 256 | FC-feed-forward dimension |
| Model | # Disassembling Asm Set | # Compiling Asm Set | ||||
|---|---|---|---|---|---|---|
| p@1 | p@3 | p@10 | p@1 | p@3 | p@10 | |
| Gemini | 45.75% | 50.22% | 74.3% | 46.67% | 52.05% | 75.93% |
| SAFE | 47.29% | 63.73% | 86.08% | 49.9% | 63.01% | 87.61% |
| AAPFE | 51.02% | 77.09% | 91.01% | 52.58% | 79.36% | 94.16% |
| Model | Accuracy | Precision | Recall | AUC |
|---|---|---|---|---|
| Gemini | 88.21% | 90.32% | 92.71% | 0.9141 |
| SAFE | 91.6% | 94.09% | 98.44% | 0.93153 |
| AAPFE | 94.28% | 96.36% | 97.05% | 0.9463 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Gemini | 78.33% | 79.81% | 80.61% | 0.802 |
| SAFE | 80.65% | 82.5% | 85.06% | 0.8376 |
| AAPFE | 83.37% | 84.22% | 84.64% | 0.8443 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gui, H.; Tang, K.; Shan, Z.; Qiao, M.; Zhang, C.; Huang, Y.; Liu, F. AAPFE: Aligned Assembly Pre-Training Function Embedding for Malware Analysis. Electronics 2022, 11, 940. https://doi.org/10.3390/electronics11060940
Gui H, Tang K, Shan Z, Qiao M, Zhang C, Huang Y, Liu F. AAPFE: Aligned Assembly Pre-Training Function Embedding for Malware Analysis. Electronics. 2022; 11(6):940. https://doi.org/10.3390/electronics11060940
Chicago/Turabian StyleGui, Hairen, Ke Tang, Zheng Shan, Meng Qiao, Chunyan Zhang, Yizhao Huang, and Fudong Liu. 2022. "AAPFE: Aligned Assembly Pre-Training Function Embedding for Malware Analysis" Electronics 11, no. 6: 940. https://doi.org/10.3390/electronics11060940
APA StyleGui, H., Tang, K., Shan, Z., Qiao, M., Zhang, C., Huang, Y., & Liu, F. (2022). AAPFE: Aligned Assembly Pre-Training Function Embedding for Malware Analysis. Electronics, 11(6), 940. https://doi.org/10.3390/electronics11060940