5. Research Results and Discussion
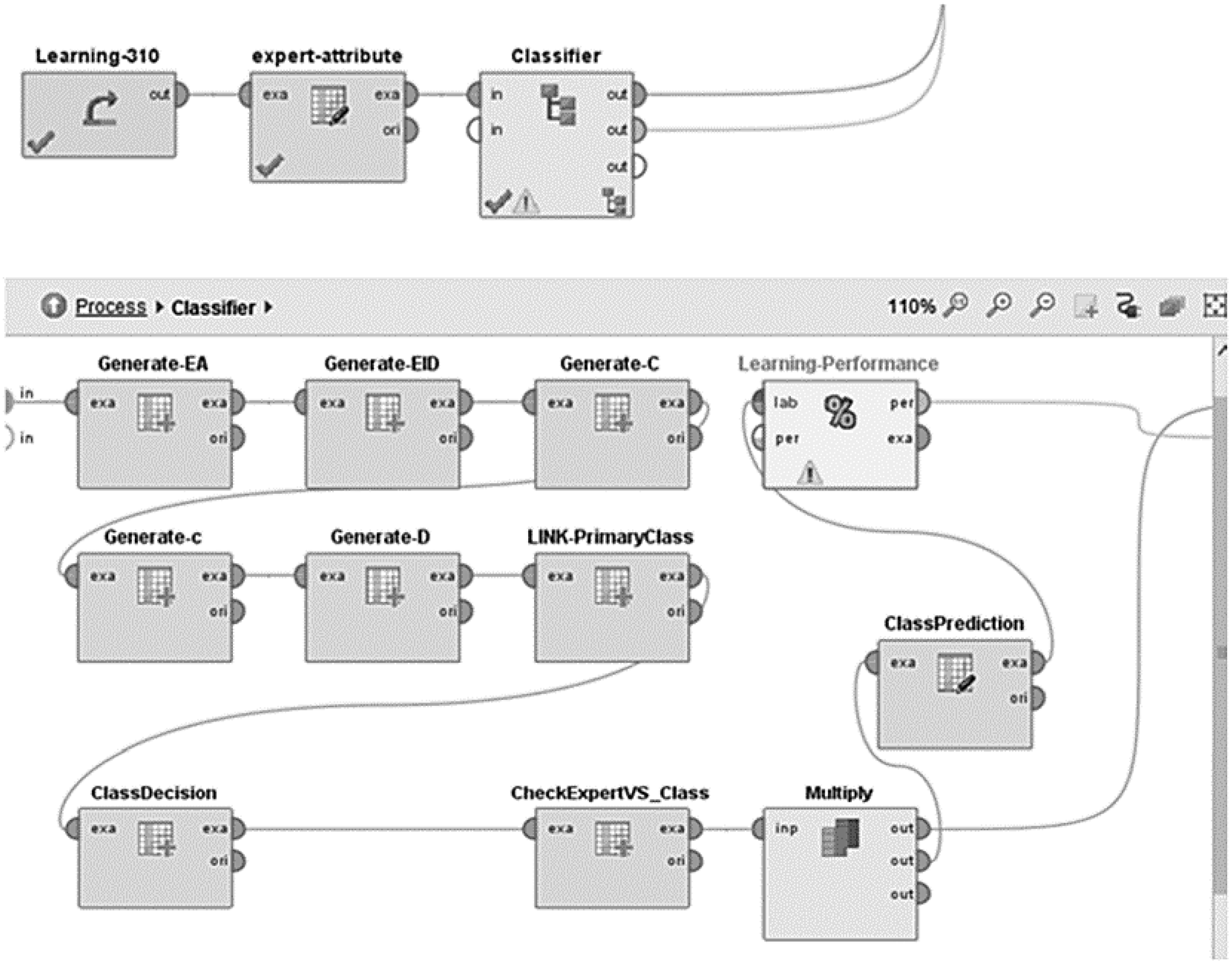
Figure 1 shows a classifier developed in RapidMiner. To create the classifier, all 310 sentences were entered for the learning process (operator Learning 310) and the expert attribute was defined as a dependent variable (Expert column from the Excel spreadsheet) to determine the performance of the classifier. Then, the operator Subprocess was used, which was renamed to Classifier. To identify the features of the primary classes and the final translation classes, seven new attributes were created (using the Generate Attributes operator). The first five attributes were for the primary classes EA, EID, C, c, and D. The sixth attribute, LINK -Primary-class, was created to provide rules for the sentences’ final translation class and to assign an ER category to a primary class resulting from the elimination of other classes. The rules were created by the process of generating the seventh, ClassDecision attribute, and, in this way, a final translation class was obtained.
In the first part of the classifier, the sentences are analysed, and characteristics that define a certain primary class can be observed. Sentence characteristics are detected based on certain strings (one or more words with certain characters, such as blank spaces or commas). The characteristics of classes are described using the logic and textual functions of RapidMiner software. As a result of the analysis, the sentence is classified into one or more primary classes, according to the specific characteristics of a certain primary class.
The expressions that are used to describe belonging to a certain primary class or connecting primary classes (Link-Primary Class attribute) as well as the rules for determining a final class (ClassDecision attribute) for translation based on primary classes and some specific words (e.g., each, every, various…) are given below:
Primary Class EA—membership criteria description
if((((contains(sentence,” have”)||contains(sentence,” has”)) && !(contains(sentence,”unique”)) && !(contains(sentence,”may”))&&
!(contains(sentence,”could”)) && !(contains(sentence,”can “))) ||
contains(sentence,”categor”) || contains(sentence,”name”) || contains(sentence,”address”) || contains(sentence,”date”) ||
contains(sentence,”title”)||
((contains(sentence,”,”) || contains(sentence,” and”)) &&
(contains(sentence,” include”)||contains(sentence,” has “) ||
contains(sentence,” have “) ||contains(sentence,” described”) ||
contains(sentence,” record”) ||contains(sentence,” store”) ||
contains(sentence,”name”) || contains(sentence,”date”) ||
contains(sentence,”address”) || contains(sentence,” type”) ||
contains(sentence,”Type”)))),”EA”,”“)
Primary Class EID—membership criteria description
if((contains(sentence,”unique”) || contains(sentence,”uniquely”) ||
contains(sentence,” identified “) || contains(sentence,” id, “) ||
contains(sentence,”-id”) || contains(sentence,” id.”) ||
contains(sentence,” id “) || contains(sentence,”_id”) ||
contains(sentence,” ID”) || contains(sentence,”id,”) ||
contains(sentence,” identifier”) || contains(sentence,” identification”)),”EID”,”“)
Primary Class C—membership criteria description
if((contains(sentence,” most “) || contains(sentence,” every”) ||
contains(sentence,” most”) || contains(sentence,”Many “) ||
contains(sentence,” many “) || contains(sentence,” any “) ||
contains(sentence,” more “) || contains(sentence,” or more “) ||
contains(sentence,” exactly “) || contains(sentence,” several”) ||
contains(sentence,”only one “) || contains(sentence,” exactly one “) ||
contains(sentence,” exactly 1 “) || contains(sentence,” most 1 “) ||
contains(sentence,” most one “) || contains(sentence,” maximum 1”) ||
(contains(sentence,” one”) && !(contains(sentence,” least “) ||
contains(sentence,” most “) || contains (sentence,” more “) ||
contains(sentence,” one of “) || contains(sentence,” maximum “))) ||
(contains(sentence,” 1”) && !(contains(sentence,” least “))) ||
contains(sentence,” most “) || contains (sentence,” more “) ||
contains(sentence,” maximum “) || contains (sentence,” various “)),”C”,”“)
Primary Class c—membership criteria description
if(((contains(sentence, “ one “) && !(contains(sentence,” more than one “) ||
contains(sentence, “one of “))) || contains(sentence,” none “) ||
contains(sentence,” minimum “) || contains(sentence,” exactly “) ||
contains(sentence,” every”) || contains(sentence,”Exactly “) ||
contains(sentence,” zero “) || contains(sentence,” one or “) ||
contains(sentence,” only one “) || contains(sentence,”Only one “) ||
contains(sentence,” any “) || contains(sentence,” any number “) ||
contains(sentence,”Any number”) || contains(sentence,” least “) ||
contains(sentence,” some “) || contains(sentence,”Some “)),”c”,”“)
Primary Class D—membership criteria description
if( (contains(sentence,” information”) || contains(sentence,”Information “) ||
contains(sentence,” to know “) || contains(sentence,” be known “) ||
(contains(sentence,” keep”) && contains(sentence,” past “)) ||
contains(sentence,” previous “) || contains(sentence,” historical “) ||
contains(sentence,” history “) || contains(sentence,” record “) ||
contains(sentence,” document “) || contains(sentence,”Document”) ||
contains(sentence,” is a “)),”D”,”“)
The description of the attribute LINK creation is given below, which connects labels of the existing primary classes and assigns the label ER if the connection results in an empty string.
A functional expression of the attribute LINK is as follows:
LINK=if (concat(EA,EID,C,c,D)==“”, “ER”, concat (EA, EID, C, c, D)).
Based on the value of the attribute LINK and additional word expressions in a sentence, the description of an expression, which unambiguously determines a translation class label to which the given sentence belongs, is given below:
if(((LINK==“EAC”||LINK==“EAc”||LINK==“EAEIDC”||LINK==“EACc”||LINK==“EAEIDCc”) &&
(!((contains(word,”every”) || contains(word,”each”) || contains(word,”different”) ||
contains(word,”several”) ))) || LINK==“C”||LINK==“Cc”||LINK==“c”), “ECR”,
“if((LINK==“EAEID” && (contains(word,”and”) && !(contains(word,”identified”)))), “EA/EID”,
if((LINK==“EAEID” && ((contains(word,”and”)) && contains(word,”identified”))),”EID”,
if(LINK==“ER”,”ECR”,
if((LINK==“EIDC”||LINK==“EIDc”||LINK==“EIDCc”),”EID”,
if(LINK==“EAD”,”EA”,
if(((LINK==“EAC”||LINK==“EAc”||LINK==“EAEIDC”||LINK==“EACc”||LINK==“EAEIDCc”) &&
(contains(word,”every”)||contains(word,”each”)||
contains(word,”different”)||contains(word,”several”))),
concat(EA,EID),LINK)))))))
In
Figure 1, the operator named expert-attribute sets the target role label (represents a dependent, goal variable). The target role of the attribute ClassDecision, which is generated based on classification conditions, is set as a prediction role. In this way, operator classification performance can determine multiclass performance using the parameters precision, recall and accuracy.
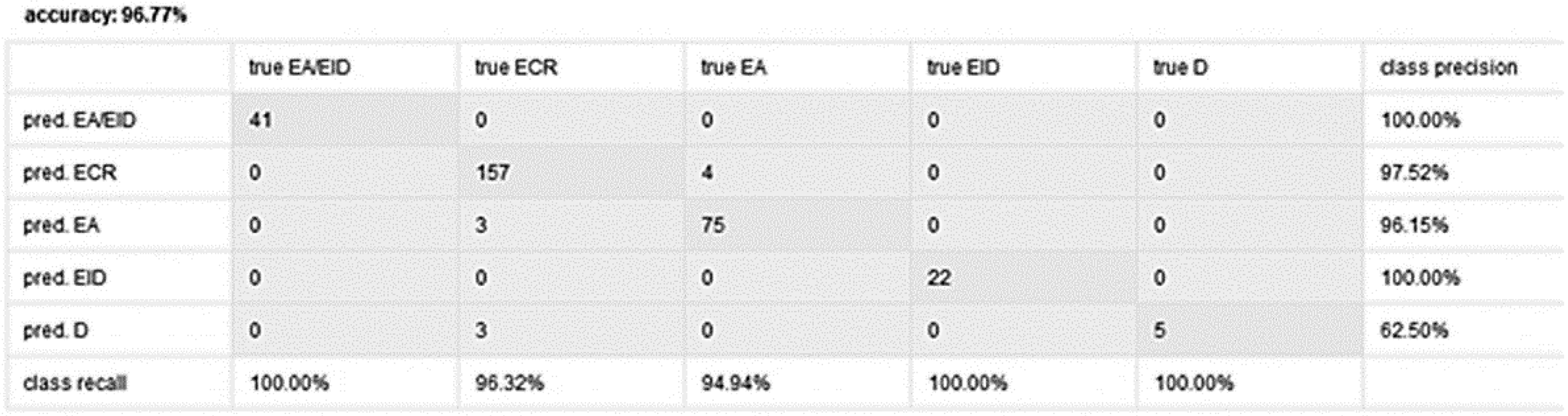
As it is clear from
Figure 2 that the class performance parameters are high (aside from category D, precision and recall are higher than 95%), which proves that class characteristics are, to a large extent, encompassed by a classifier (for sentences of 30 BDs). Although the entire accuracy of the learning process and classifier building is 96.77%, it was not that high in the first version of the classifier. The procedure for tracking the classifier performance results and subsequently all the adjustments were carried out in several steps. The initial performance of classifier creation was around 90%. This reduced accuracy was the result of, for example, overlooking some characteristics of a class (a semantic slip), inaccurate description of the observed characteristics (a syntactic slip), a failure to include keywords and expressions or not precisely determining characteristics due to functional expression errors using logical operators.
Therefore, some sentences are entirely falsely classified, while some others are incompletely classified into final translation classes or only partially accurately classified.
A list of sentences whose characteristics the classifier did not identify in the same manner as the expert is given in
Table 4.
The first four sentences in
Table 4 are examples in which the experts classified the sentences as EA and the classifier as ECR. Hence, it can be concluded that the experts, based on the meaning of the noun after the verb, determined that it was not the second entity in the relationship but rather an attribute (so, they used their previously stored experience and knowledge). Currently, such a semantic characteristic has not been installed in the classifier. Such semantics could be identified after all the BD sentences have been classified and translated (when some previously identified “entity” resulted in having no attributes → then this “entity” would be transformed in an attribute). The classifier classified the sentences that were classified as ECR either as EA (first and foremost due to the verb
to have, which characterises attribute sentences) or as D, given that it detected one of the characteristics of the class
description (“is a” or “information”). In relation to incompatibility, the classifier does not recognise plurals, and thus it could not conclude that the combination of the verb “to have” and the plural noun refers to ECR characteristics. The experts considered the sentence “A primary doctor is a doctor” to be ECR because it refers to the entity hierarchy
primary doctor and
doctor. The classifier labels this situation as class
D-description. Still, translation rules that would be applied to category D sentences would also lead to detecting the hierarchy of the entities
doctor and
primary doctor. Thus, despite an apparent accuracy of 96.77%, by adding a POS tag as a predictor value and resolving “is a” hierarchical relationships with the rules applied for a D and not for the ECR class (where other hierarchical relationship rules will be applied, as described in
Our system novelties), the classifier learning performance would be almost 100%.
5.1. Testing the Sentence Classifier
To test the classifier with new sentences, the remaining 20 descriptions were used (214 sentences), processed in exactly the same way as when the classifier was created (the input procedure with text processing, the conversion of word lists into a range of attribute values, and printouts in the Excel database). In addition, the primary and final classes were assigned by the experts, followed by a group decision and the creation of the attribute named expert, to verify the success of the testing.
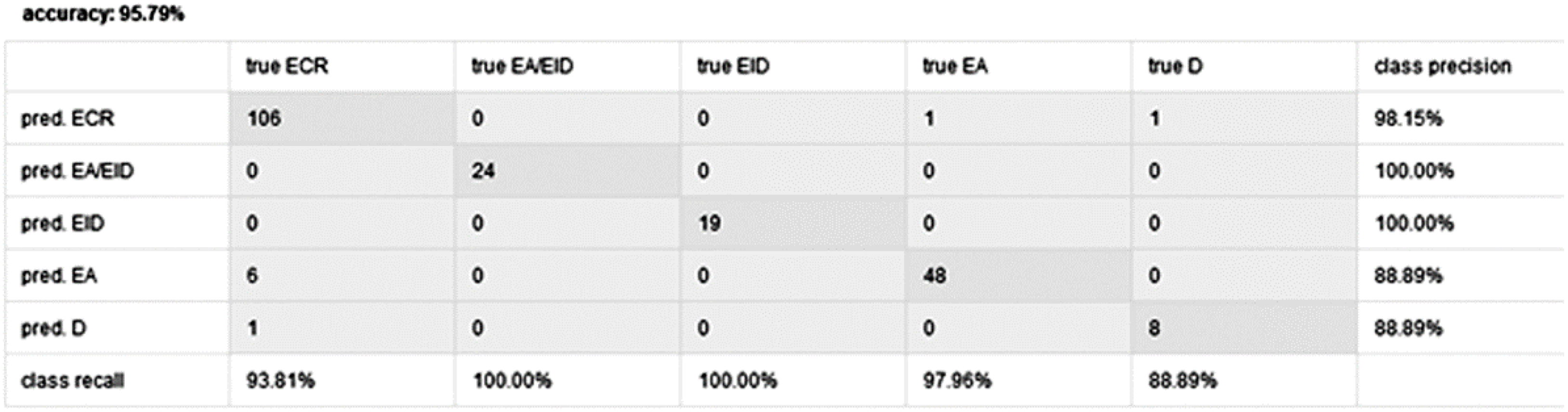
The testing was performed by applying the previously created Classifier subprocess to loaded sentences of 20 BDs. The results of the testing are shown in
Figure 3 (overall accuracy of 95.79%).
The sentences to which the classifier did not assign the same class as the experts did are shown in
Table 5.
As shown in
Table 5, the experts classified the first seven sentences as ECR, whereas the classifier (besides the third sentence, which was classified as D) classified the sentences as EA. In this phase, the classifier did not recognise plurals or the syntax category of numbers, and thus it did not assign ECR class as the experts did. Other incompatibilities (sentences 8 and 9) are disputable, given that the structure of the eighth sentence could actually refer to the entity hierarchy in the ECR category, and the ninth sentence could refer to additional information (that is not registered within the data model) in relation to the entity visitor.
5.2. An Example of Applying the Translation Rules
The basic idea of the authors in the translation of BDs in CEN into a data model in the EARC language is the application of translation rules based on patterns for a certain sentence class.
An example of implementing translation rules after the classification of the following sentence shows this more clearly:
The sentential form of the sentence is:
The classifier assigned this sentence to the EA/EID class; thus, it has EA and EID class characteristics.
In relation to the EA class, the following patterns (
Table 6) have been identified, which are used in translation into an EARC sentence:
By generalising, the following translation rules for category EA can be established for this type of sentence:
Given that the sentence also possesses characteristics of the EID class, pattern characteristics of that class were observed. Therefore, in this sentence, the word identifier was identified as a predictor value–characteristic that assigned the sentence to the EID class (
Table 7).
Furthermore, since the pattern for identifying attributes does not exclude attribute/attributes that comprise a primary key, there is an additional necessary rule:
If the attribute that makes up the primary key (
api) is also in the list of
m attributes of a certain entity
Ei that are not part of the primary key, then it is excluded from the group of attributes that do not make up the primary key; a set
Ai excludes that element
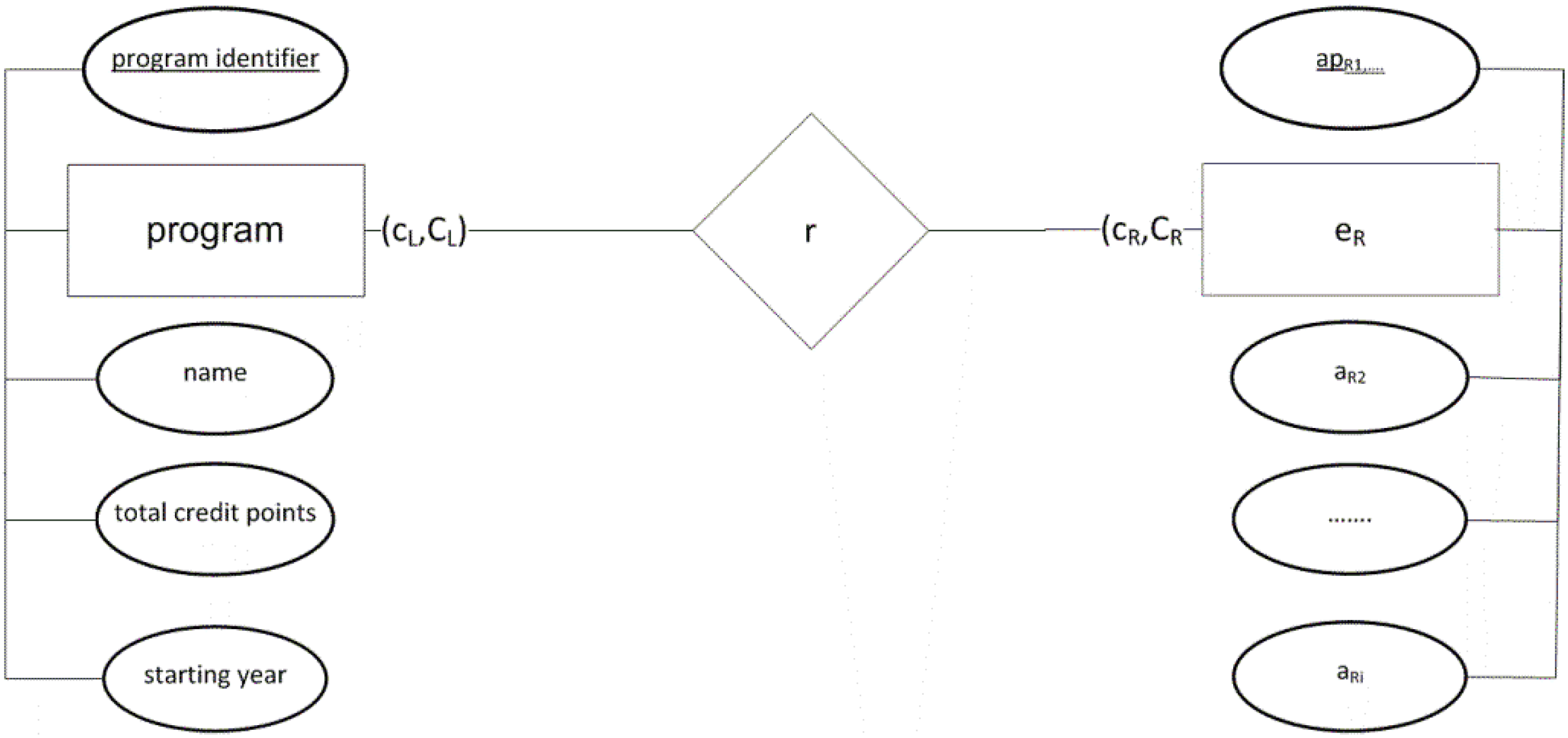
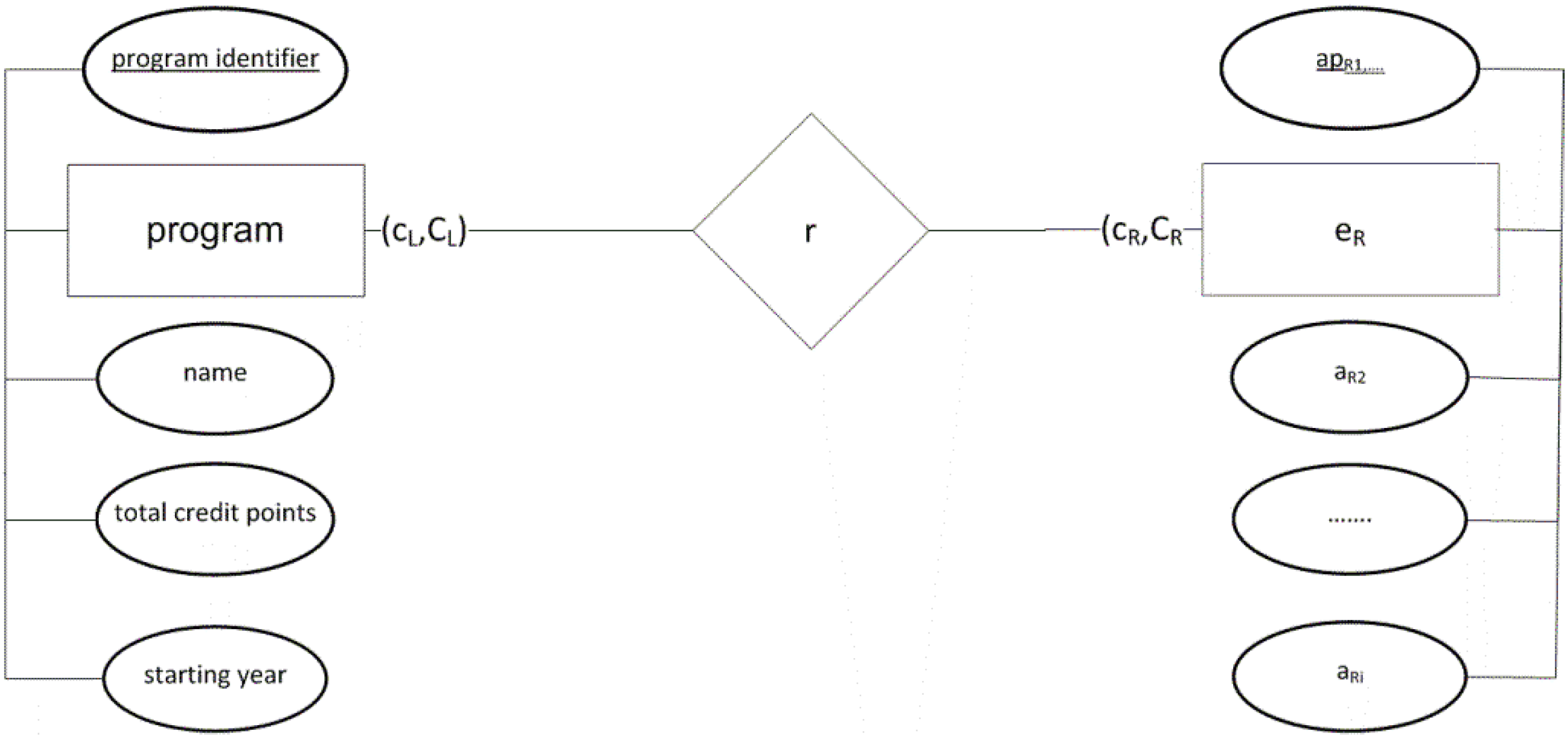
api.The final translation of sentence (1) into an EARC sentence is provided below. The complete sentence in the EARC language (all EARC constructs are known) takes the following form:
eL(ApL, AL)(cL, CL) r (cR, CR)eR(ApR, AR)
eL = program
ApL = {program identifier}
AL = {name, total credit points, starting year}
Therefore, an EARC sentence is:
An ER model that resulted from sentence classification and the translation are shown in
Figure 4.
Parts of an EARC sentence that remained untranslated will be translated in one of the following ways:
translating other sentences of a BD and integrating identified/translated EARC constructs,
getting users’ responses to specifically formulated targeted questions for every missing EARC construct (our KB system will have a question-answering system),
using examples from previous cases (case-based reasoning, explained in the next section our system’s novelties).
5.3. Our System’s Novelties
We agree with Lucassen et al. [
27,
28], who argue that accuracy is more important than trying to formalise and automate the translation of every detail of the requirements. In this section, we present the main translation problems of our approach—in general, the main problems in translating requirements texts into data models. We also present the proposed translation rules and highlight the features, differences, and innovations of our approach. Our translation and pre-translation rules are expressed using strings of morphosyntactic word descriptions. Some of our rules are similar to those we have collected in [
27], but most of them are completely new or have been refined. We present only some of the most important rules and principles, since there are many for each translation class. Attempting to formalise natural (or some kind of constrained natural) language and provide the desirable 100% automation inevitably leads to a model with many language semantics that depend on context, and thus to a huge number of rules. In general, the less constrained a natural language is with respect to the requirements expressed in the input text, the more rules are needed for complete and accurate translation.
In our approach, we followed principles synthesised in [
48] where they highlight some principles of automated transformation of requirements description to further software development models. Regardless of which format is used, the requirements should be easy to understand to facilitate communication between different stakeholders (e.g., users, developers):
proposed analysis models should be complete;
the number of transformation steps should be minimised;
the approach should be automated;
the approach should support traceability management.
Our KB system is composed of four main subsystems that are specialised to perform its main functions.
- 1.
Textual requirements for data model translation
Requirements update;
Syntactic analysis and validation of requirements;
ER construct identification and ER model formation (textual form);
Automated question generation to ask users about missing constructs and integrate the answers into the model.
- 2.
A data model for textual requirements translation
- 3.
View, explanation and analysis—provides the user with a complete list of all the steps performed from the input to the output and represents a core part of the learning (educational dimension).
- 4.
Knowledge base updates—as the knowledge base with all its constituents (translating rules, PSGs, lexicons) represents the brain and the engine of the system, it must be monitored and updated by the KB system engineer(s).
The KB system has a system–user interaction module. We expect to reduce the user interaction with the KB system by expanding and updating its knowledge base. Using the classifier described in this paper, we expect that the translation steps should be minimised. We also expect to achieve completeness of the model with knowledge base evolution during the testing and use of the KB system, although on explicitly expressed requirements (in this phase of the research, we cannot translate implicit semantics). Traceability will be enabled by storage of all requirements sentences with their corresponding ER sentences and all translation steps from the original sentence to the ER sentence (specifying which rules were applied).
What follows is a brief description of the main translation issues and how we dealt with them in our approach.
Input format (CEN restricted language). We described our controlled natural language used for BD with the phrase structure grammar and 70,000 words of a MULTEXT-East Lexicon. However, for the person (analyst or a business domain specialist) who wants to write requirements (BD) conforming to our CEN language, we can simplify the restrictions in the form of rules and a less rigorous set of guidelines.
Use sentences with only one main verb in the present or in the past tenses, in the infinitive, passive or conditional. If there is a need to express more relations among more entities, do this with more sentences. Example: the sentence “Students enrol in a course that is taught by only one teacher” can be written as two sentences:
Sentence 1: “Students enrol in a course”, and
Sentence 2: “A course (or each course) is taught by only one teacher”.
Auxiliary and modal verbs are not seen as main verbs, so expressions such as “could be”, “is given”, “is giving”, “can be sold” or “could be selling” are all acceptable.
Use expressions that quantify whenever possible: use “at least” or “more than” quantifiers for including semantics that will provide valuable information about cardinalities.
Generally, use the singular form when listing attributes and/or primary key(s).
Limit expressions to third singular and plural person.
Avoid explanations and rich descriptions. If there is some important information, express it with a separate sentence.
Compounds. We call these noun blocks and define them with a string class of the form ({Nc} [Sp] [Dd |Di])|{Af} Nc). For example: “name of the student” (Nc Sp Dd Nc), “student name” (Nc Nc), “account development manager” (Nc Nc Nc). Only if the various types of entity cases are encountered (e.g., “existing user”, “new user”, “senior user”) will the attribute named type be defined of the entity user.
Attributes. For the purpose of easier rule formulation and code implementation, we introduce a general sentence format α V β, where V represents a verb expression. Then, we define the following rule: attributes are identified from noun blocks separated with a comma and/or conjunction: {[Sp][Dd |Di] {Nc}Nc [,| Cc]}, which can be in:
α part (then, a noun block from β represents the entity whose attributes are identified),
β part (then, a noun block from the α part represents the entity whose attributes are identified).
Example: “A customer has a name, a surname and a date of birth”. The sentence is classified as EA class, and the attributes are found in the β part. Applying the rule, we receive a part of an EARC sentence: eL(ApL, AL), customer (ApL,{name, surname, date of birth}).
Primary key(s). The rules for primary key(s) identification are the same as for attributes. Hence, if the sentence is classified as EID, we can encounter one or more primary key elements. If there is more than one, they can be in the α or in β part as noun blocks separated with a comma and/or conjunction. Example: “Every room is identified with a floor and a number”. The sentence is classified as EID class, and primary keys are found in the β part. Applying the rule, we receive a part of an EARC sentence: eL (ApL, AL), room (,{floor, number}, AL }).
Verbs. In the grammar production of the CEN language, verbs can have the following form: [Vo | [Vo] Va [Rmp]] Vm. Thus, the following combinations are all supported: Vo Vm (“can call”), Vo Va Vm (“could have called”), Vo Va RmpVm (“could have totally sold”), Va Vm (“is calling” or “is sold”), Vo Sp Vm (“need to sell”) and Vo Sp Va Vm (“need to be stored”).
Conjunctions. Two different situations can be described with conjunctions:
listing attributes; for example: “The loan has a title, starting day and an expiration day” (where attributes of the entity loan are title, starting day, expiration day)
listing entities (requires a rule of sentence splitting); for example, splitting the sentence “The catalogue contains food and beverages” is performed by leaving the α V part of the sentence and adding one noun block in each new sentence separated by a comma or conjunction (from the β part):
Adverbs and adjectives. They are supported within the CEN language, but adjectives are rarely used (as they should represent values of some attribute, we assume that important attributes should be declared specifically in the requirements). Adverbs, however, are frequently used (see the cardinalities issue below).
Syntax errors. To check for syntactically correct sentences in our PSG, we implement finite state automata transition tables (using Python). Syntax errors are attributed to specific sentence parts, so the user has the ability to rewrite the sentence and then repeat the syntax analysis.
Hierarchy cases. The hierarchy-capturing implementation follows in the next research phase, although some of the cases are described with rules. We present three hierarchy scenarios:
(First scenario)
IF
α = [Every | Each | Di | Dd] {Nc} Nc
V = ((is a) | (is also a) | (is one of [Dd]) | (can | could) be)
β = [Dd |Di] {Nc} Nc [Sp [Rmp] Mc]{Nc}
THEN
eL = {Nc} Nc from α part
eR = [Dd |Di] {Nc} Nc [Sp] {Nc} Nc from β part
Cardinalities are: cL = 0, CL = 1, cR = 1, CR = 1.
The relationship name: (is a |is also a| is one of [Dd] | (can | could) be).
EXAMPLE: “The doctor is also a staff of the hospital”.
(Second scenario)
IF
α = {Nc} Nc
V = (are | are also)
β = {Nc} Nc, and both in α and β parts are nouns in plural
THEN
eL = {Nc} Nc from α part
eR = {Nc} Nc from β part
Cardinalities are: cL = 0, CL = 1, cR = 1, CR = 1.
IF α = “Some [of the]{Nc} Nc”, β and V are translated in the same manner, only cardinalities are changed in: cL = 1, CL = 1, cR = 0, CR = 1.
EXAMPLE: “Some employees are also managers”.
(Third scenario)—Hierarchy sentences with conjunctions must first be processed with the rule for sentence splitting (mentioned above), and then the appropriate hierarchy rule should be applied to each split sentence. Those sentences take the form [Dd | Di] {Nc}Nc (are | is) {[Cc] [Dd |Di] {Nc}Nc }, where the number of derived sentences equals the number of Cc-conjunctions in the original sentence. For each split-derived sentence, the second scenario for entities and relationship is applied, and the cardinalities are: cL = 1, CL = 1, cR = 0, CR = 1.
Example of a sentence: “A staff member is either a professor or an administrator”.
Split sentence 1: “A staff member is a professor”.
Split sentence 2: “A staff member is an administrator”.
Ternary relationships. In the sentences where three entities are encountered (one entity in the α and two in the β part or vice versa), we can observe string classes such as E = “[Dd |Di] {Nc} Nc Sp [Rmp Mc] |Dd | Di] {Nc} Nc”, where entities are identified before and after Sp. We now substitute some parts of E with E1 and E2, so E = E1 Sp [Rmp Mc] E2. The original sentence must be split into two sentences based on the following rules:
- (a)
If E is in β, then the first sentence has the form α V E1 and the second sentence has the form E1 V E2, where V is derived from the verb “to be” + Sp.
Example sentence: “An instructor can be the head of only one department”.
Split sentence 1: “An instructor can be the head”.
Split sentence 2: “The head is of only one department”.
- (b)
If E is in the α part, then the first sentence has the form E1 V E2, where V is derived from a verb “to be” + Sp and the second sentence has the form E1 V β, where V is the main verb of the original sentence.
Example sentence: “A customer of the bank requires a loan”.
Split sentence 1: “A customer is of the bank”.
Split sentence 2: “A customer requires a loan”.
Aggregation (resolving many to many relationships). We propose a general principle to resolve M:M relationships. We introduce a new entity “Agg”, which is composed of left and right entities (Agg = eL_eR), and then we split the original sentence into two sentences assigning cardinalities and primary keys and attributes to a new entity applying ER modelling theory (Agg has a primary key composed of eL and eR primary keys). The first sentence is of the form eL V Agg, with cardinalities cL = 1, CL = 1, cR = 1, CR = M.
The second sentence is of the form Agg V eR, with cardinalities cL = 1, CL = 1, cR = 1, CR = M.
Example sentence: “Products are sold to customers”. The relationship is of the M:M type, so we apply the aggregation rule:
First sentence: “Product is sold to product_customer”.
Second sentence: “Product_customer is sold to customers”.
Cardinalities. We identified many rules for cardinalities, and listing them is beyond the scope of this paper. The semantics of cardinalities are categorised in three main classes: those that carry information about minimum cardinalities, maximum cardinalities and both. We mention only a few rules of each class:
Minimum cardinalities:
- (a)
the word least, generally appears in a string E = Sp least Mc, or E = Mc Sp least (at least four, five at least) → Rule: if E is in α, then cL = Mc; if E is in β, then cR = Mc.
- (b)
the word more, generally appears in a string E = more Cc |Cs Mc, E = Mc Cc more (more than one, one or more) → Rule: if E is in α, then cL = Mc, CL = M; if E is in β, then cR = Mc, CR = M.
Maximum cardinalities:
- (a)
the word most, generally appears in a string E = Sp most Mc, E = Mc * Sp most (at most four, four at most) → Rule: if E in α then CL = Mc, if E in β then CR = Mc.
- (b)
words approximately, around, nearly, generally appear in a string E = *approximately |around| nearly Mc (nearly three professors) → Rule: if E is in α, then CL = Mc; if E is in β, then CR = Mc.
Domain-specific. This NLP approach is not restricted to a specific domain and could be applied in any business or scientific domain.
Case-based. Our approach supports case-based reasoning in a sentential form matching manner. For every translated sentence, its sentential form and the EARC translated sentence are stored in a repository. Thus, when a sentence is entered that is syntactically correct but contains some “out of dictionary” words, if its sentential form corresponds to the sentential form that is already stored, the sentence is translated according to existing translation. An example of an existing and stored tuple of (sentence, sentential form, EARC translated constructs) is as follows:
Sentence: “A borrower can have more than one loan request”.
Sentential form: Di Nc Vo Vm Rmp Cs Mc Nc Nc.
EARC constructs: eL = borrower, r = can have, cR = 1, CR = M, eR = loan request. Case-based reasoning for a new case:
Sentence: “A student could have more than one thesis mentor”.
Sentential form: Di Nc Vo Vm Rmp Cs Mc Nc Nc.
EARC constructs based on a previous stored case: eL = student, r = could have, cR = 1, CR = M, eR = thesis mentor.
User intervention. Our approach supports user intervention as a guided process of targeted questions formulated by a system and the integration of the users’ answers.






{kind=link}
{kind=link}
{kind=link}
{kind=link}