
Evaporation Forecasting through Interpretable Data Analysis Techniques

 , , , , and
, , , , and 
Abstract
:1. Introduction
- Saving water in evaporation scenarios: The main objective of this work is to design and deploy a hardware and software infrastructure that, based on the monitoring of different meteorological components in irrigated plots, can predict the evaporation rate in following days to take actions that reduce water loss.
- Using an accurate and interpretable model: To achieve the above objective, the use of a multivariate DT model is proposed and subsequently evaluated to provide daily predictions of the evaporation rate. A white box model has been chosen; i.e., the influence of the input variables on the evaporation prediction can be understood.
- Data characterization: A two-year dataset of data from a real irrigated agricultural plot has been generated. This dataset has been used to develop the exposed models and is made available for the reproducibility of the results presented here.
- Assessment with black box methods: In addition to the interpretable method, a black box method has been used, specifically ANN, that is the most commonly used for this type of problem in the literature. The aim is to validate the interpretable model results by means of the black box method results.
2. Background
3. Materials and Methods
3.1. IoT Infrastructure
- Apogee SQ-100x: Collects photosynthetically active radiation expressed as photosynthetic photon flux density (photon flux in units of micromoles per square meter per second).
- Meter ATMOS 14: Measures air temperature in Celsius degrees, air humidity in percent, barometric pressure, and vapour pressure in kilo Pascals.
- Teros 12: Measures soil temperature in Celsius degrees, soil conductivity, and soil permeability in deciSiemens.
- MaxiMet GMX: Measures wind velocity in meters per second.
3.2. Dataset
3.3. Techniques Used, Their Configuration, and Measures to Assess Results
3.3.1. Artificial Neural Network Technique
3.3.2. Decision Tree Technique
3.3.3. Measures Used to Assess Results, Validating Experiments
- Coefficient of determination () between two samples, observed values X and predictor values Y, measures the proportion of the variance in the sample X that is predictable from the sample Y. It is defined as where is the mean of the sample. High values of the measure indicate a behaviour highly reliable for future forecast of X by Y.
- Pearson Correlation Coefficient () between two samples, X and Y, measures the linear statistical correlation between X and its prediction Y. This measure is defined as where is the covariance between X and Y, and and are the standard deviation of X and Y, respectively. If , there is a strong positive correlation (when X is increased, there is also an increase in Y) and if , there is a strong negative correlation (there is a inverse relation between X and Y, when X is increased, Y is decreased).
- Mean absolute error () between samples of observed values X and predictor values Y is defined as .
- Mean squared error () between samples of observed values X and predictor values Y is defined as .
4. Results and Discussion
4.1. Preliminary Analysis
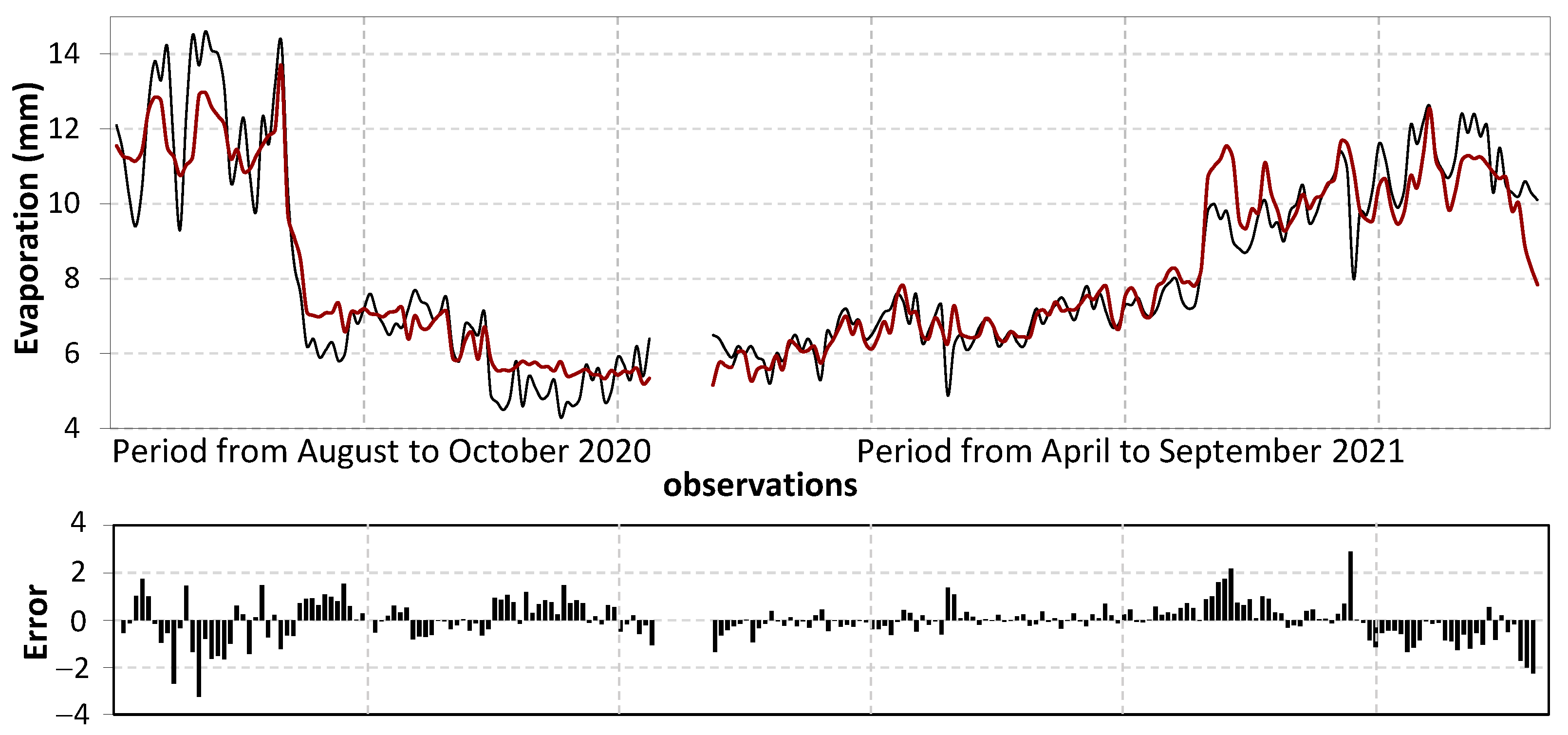
4.2. Black Box and Interpretable Models
- : Obtained from nine variables (all variables of the dataset except the variable ) to predict the output variable E.
- : Obtained from eight variables (all variables of the dataset except the variables and ) to predict the output variable E.
4.2.1. Artificial Neural Networks for Regression
4.2.2. Decision Tree for Regression
4.3. Analysis and Discussion
- The climate variables used in the model are Soil Temperature, Soil Permeability, Soil Conductivity, Air Temperature, Vapour Pressure, Air Pressure, and Solar Radiance.
- The climate variables that the model does not use are Relative Humidity and Wind Velocity. Therefore, these measures do not need to be collected.
- The discriminant climate variables are: Soil Temperature, Air Temperature, Soil Conductivity, Air Pressure, Soil Permeability, and Vapour Pressure.
- The most important climate variable is Soil Temperature.
- At a second level of importance, the climatic variables are Air Temperature and Vapour Pressure.
- If Soil Temperature is greater than 24.837 °C, then 37% of the predictions only use that variable with the support of the variable Vapour Pressure.
- If Soil Temperature is smaller than 24.837 °C, then 63% of the predictions are made with the support of the variables Air Temperature, Soil Conductivity, Air Pressure, and Soil Permeability.
- -
- If Air Temperature is smaller than 27.25 °C, then 32% of the predictions are made with the support of the variables Soil Conductivity and Air Pressure.
- -
- If Air Temperature is greater than 27.25 °C, then 31% of predictions are made with the support of the variable Soil Permeability.
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Garrick, D.E.; Hanemann, M.; Hepburn, C. Rethinking the economics of water: An assessment. Oxf. Rev. Econ. Policy 2020, 36, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Pahl-Wostl, C. An evolutionary perspective on water governance: From understanding to transformation. Water Resour. Manag. 2017, 31, 2917–2932. [Google Scholar] [CrossRef]
- Kamienski, C.; Soininen, J.P.; Taumberger, M.; Dantas, R.; Toscano, A.; Salmon Cinotti, T.; Filev Maia, R.; Torre Neto, A. Smart water management platform: IoT-based precision irrigation for agriculture. Sensors 2019, 19, 276. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Meier, J.; Zabel, F.; Mauser, W. A global approach to estimate irrigated areas–a comparison between different data and statistics. Hydrol. Earth Syst. Sci. 2018, 22, 1119–1133. [Google Scholar] [CrossRef] [Green Version]
- Zhang, P.; Guo, Z.; Ullah, S.; Melagraki, G.; Afantitis, A.; Lynch, I. Nanotechnology and artificial intelligence to enable sustainable and precision agriculture. Nat. Plants 2021, 7, 864–876. [Google Scholar] [CrossRef]
- Melgarejo-Moreno, J.; López-Ortiz, M.I.; Fernández-Aracil, P. Water distribution management in South-East Spain: A guaranteed system in a context of scarce resources. Sci. Total Environ. 2019, 648, 1384–1393. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ghorbani, M.; Deo, R.C.; Yaseen, Z.M.; Kashani, M.H.; Mohammadi, B. Pan evaporation prediction using a hybrid multilayer perceptron-firefly algorithm (MLP-FFA) model: Case study in North Iran. Theor. Appl. Climatol. 2018, 133, 1119–1131. [Google Scholar] [CrossRef]
- Goyal, M.K.; Bharti, B.; Quilty, J.; Adamowski, J.; Pandey, A. Modeling of daily pan evaporation in sub tropical climates using ANN, LS-SVR, Fuzzy Logic, and ANFIS. Expert Syst. Appl. 2014, 41, 5267–5276. [Google Scholar] [CrossRef]
- Kumar, N.; Arakeri, J.H. A fast method to measure the evaporation rate. J. Hydrol. 2021, 594, 125642. [Google Scholar] [CrossRef]
- Utset, A.; Farre, I.; Martínez-Cob, A.; Cavero, J. Comparing Penman–Monteith and Priestley–Taylor approaches as reference-evapotranspiration inputs for modeling maize water-use under Mediterranean conditions. Agric. Water Manag. 2004, 66, 205–219. [Google Scholar] [CrossRef] [Green Version]
- Yaseen, Z.M.; Al-Juboori, A.M.; Beyaztas, U.; Al-Ansari, N.; Chau, K.W.; Qi, C.; Ali, M.; Salih, S.Q.; Shahid, S. Prediction of evaporation in arid and semi-arid regions: A comparative study using different machine learning models. Eng. Appl. Comput. Fluid Mech. 2020, 14, 70–89. [Google Scholar] [CrossRef] [Green Version]
- Allawi, M.F.; Binti Othman, F.; Afan, H.A.; Ahmed, A.N.; Hossain, M.S.; Fai, C.M.; El-Shafie, A. Reservoir evaporation prediction modeling based on artificial intelligence methods. Water 2019, 11, 1226. [Google Scholar] [CrossRef] [Green Version]
- Carleo, G.; Cirac, I.; Cranmer, K.; Daudet, L.; Schuld, M.; Tishby, N.; Vogt-Maranto, L.; Zdeborová, L. Machine learning and the physical sciences. Rev. Mod. Phys. 2019, 91, 045002. [Google Scholar] [CrossRef] [Green Version]
- Benos, L.; Tagarakis, A.C.; Dolias, G.; Berruto, R.; Kateris, D.; Bochtis, D. Machine Learning in Agriculture: A Comprehensive Updated Review. Sensors 2021, 21, 3758. [Google Scholar] [CrossRef] [PubMed]
- Yvoz, S.; Petit, S.; Biju-Duval, L.; Cordeau, S. A framework to type crop management strategies within a production situation to improve the comprehension of weed communities. Eur. J. Agron. 2020, 115, 126009. [Google Scholar] [CrossRef]
- Khaki, S.; Wang, L. Crop yield prediction using deep neural networks. Front. Plant Sci. 2019, 10, 621. [Google Scholar] [CrossRef] [Green Version]
- Anagnostis, A.; Tagarakis, A.C.; Asiminari, G.; Papageorgiou, E.; Kateris, D.; Moshou, D.; Bochtis, D. A deep learning approach for anthracnose infected trees classification in walnut orchards. Comput. Electron. Agric. 2021, 182, 105998. [Google Scholar] [CrossRef]
- Zhang, L.; Li, R.; Li, Z.; Meng, Y.; Liang, J.; Fu, L.; Jin, X.; Li, S. A Quadratic Traversal Algorithm of Shortest Weeding Path Planning for Agricultural Mobile Robots in Cornfield. J. Robot. 2021, 2021, 6633139. [Google Scholar] [CrossRef]
- Zhang, S.; Huang, W.; Huang, Y.A.; Zhang, C. Plant species recognition methods using leaf image: Overview. Neurocomputing 2020, 408, 246–272. [Google Scholar] [CrossRef]
- Papageorgiou, E.I.; Aggelopoulou, K.; Gemtos, T.A.; Nanos, G.D. Development and evaluation of a fuzzy inference system and a neuro-fuzzy inference system for grading apple quality. Appl. Artif. Intell. 2018, 32, 253–280. [Google Scholar] [CrossRef]
- Guillén-Navarro, M.A.; Martínez-España, R.; López, B.; Cecilia, J.M. A high-performance IoT solution to reduce frost damages in stone fruits. Concurr. Comput. Pract. Exp. 2019, 33, e5299. [Google Scholar] [CrossRef]
- Lampridi, M.G.; Sørensen, C.G.; Bochtis, D. Agricultural sustainability: A review of concepts and methods. Sustainability 2019, 11, 5120. [Google Scholar] [CrossRef] [Green Version]
- Fournel, S.; Rousseau, A.N.; Laberge, B. Rethinking environment control strategy of confined animal housing systems through precision livestock farming. Biosyst. Eng. 2017, 155, 96–123. [Google Scholar] [CrossRef]
- Azodi, C.B.; Tang, J.; Shiu, S.H. Opening the Black Box: Interpretable machine learning for geneticists. Trends Genet. 2020, 36, 442–455. [Google Scholar] [CrossRef] [PubMed]
- Hall, P.; Gill, N.; Kurka, M.; Phan, W. Machine Learning Interpretability with H2O Driverless AI; H2O.ai: Mountain View, CA, USA, 2017. [Google Scholar]
- Molnar, C. Interpretable Machine Learning; Lulu Press: Morrisville, NC, USA, 2020. [Google Scholar]
- Ashrafzadeh, A.; Ghorbani, M.A.; Biazar, S.M.; Yaseen, Z.M. Evaporation process modelling over northern Iran: Application of an integrative data-intelligence model with the krill herd optimization algorithm. Hydrol. Sci. J. 2019, 64, 1843–1856. [Google Scholar] [CrossRef]
- Abed, M.; Imteaz, M.A.; Ahmed, A.N.; Huang, Y.F. Application of long short-term memory neural network technique for predicting monthly pan evaporation. Sci. Rep. 2021, 11, 20742. [Google Scholar] [CrossRef]
- Malik, A.; Kumar, A.; Kisi, O. Daily pan evaporation estimation using heuristic methods with gamma test. J. Irrig. Drain. Eng. 2018, 144, 04018023. [Google Scholar] [CrossRef]
- Qasem, S.N.; Samadianfard, S.; Kheshtgar, S.; Jarhan, S.; Kisi, O.; Shamshirband, S.; Chau, K.W. Modeling monthly pan evaporation using wavelet support vector regression and wavelet artificial neural networks in arid and humid climates. Eng. Appl. Comput. Fluid Mech. 2019, 13, 177–187. [Google Scholar] [CrossRef] [Green Version]
- Wu, L.; Huang, G.; Fan, J.; Ma, X.; Zhou, H.; Zeng, W. Hybrid extreme learning machine with meta-heuristic algorithms for monthly pan evaporation prediction. Comput. Electron. Agric. 2020, 168, 105115. [Google Scholar] [CrossRef]
- Mohamadi, S.; Ehteram, M.; El-Shafie, A. Accuracy enhancement for monthly evaporation predicting model utilizing evolutionary machine learning methods. Int. J. Environ. Sci. Technol. 2020, 17, 3373–3396. [Google Scholar] [CrossRef]
- Shabani, S.; Samadianfard, S.; Sattari, M.T.; Mosavi, A.; Shamshirband, S.; Kmet, T.; Várkonyi-Kóczy, A.R. Modeling pan evaporation using gaussian process regression k-nearest neighbors random forest and support vector machines; Comparative analysis. Atmosphere 2020, 11, 66. [Google Scholar] [CrossRef] [Green Version]
- Guillén-Navarro, M.A.; Martínez-España, R.; Bueno-Crespo, A.; Morales-García, J.; Ayuso, B.; Cecilia, J.M. A decision support system for water optimization in anti-frost techniques by sprinklers. Sensors 2020, 20, 7129. [Google Scholar] [CrossRef] [PubMed]
- Steeman, H.J.; T’Joen, C.; Van Belleghem, M.; Janssens, A.; De Paepe, M. Evaluation of the different definitions of the convective mass transfer coefficient for water evaporation into air. Int. J. Heat Mass Transf. 2009, 52, 3757–3766. [Google Scholar] [CrossRef]
- Tso, G.K.; Yau, K.K. Predicting electricity energy consumption: A comparison of regression analysis, decision tree and neural networks. Energy 2007, 32, 1761–1768. [Google Scholar] [CrossRef]
- Murtagh, F. Multilayer perceptrons for classification and regression. Neurocomputing 1991, 2, 183–197. [Google Scholar] [CrossRef]
- Ramchoun, H.; Idrissi, M.A.J.; Ghanou, Y.; Ettaouil, M. Multilayer Perceptron: Architecture Optimization and Training. Int. J. Interact. Multimedia Artif. Intell. 2016, 4, 26–30. [Google Scholar] [CrossRef]
- Palani, S.; Liong, S.Y.; Tkalich, P. An ANN application for water quality forecasting. Mar. Pollut. Bull. 2008, 56, 1586–1597. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth and Brooks: Monterey, CA, USA, 1984. [Google Scholar] [CrossRef]
- Quinlan, J.R. Learning With Continuous Classes. In Proceedings of the 5th Australian Joint Conference on Artificial Intelligence (AI92), Hobart, Australia, 16–18 November 1992; pp. 343–348. [Google Scholar]
- Wang, Y.; Witten, I.H. Inducing Model Trees for Continuous Classes. In Proceedings of the 9th European Conference on Machine Learning Poster Papers, Prague, Czech Republic, 23–25 April 1997; pp. 128–137. [Google Scholar]
- Frank, E.; Hall, M.A.; Witten, I.H. Data Mining: Practical Machine Learning Tools and Techniques, 4th ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2016. [Google Scholar]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-validation. Encycl. Database Syst. 2009, 5, 532–538. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Variable | Mean | std | Min | Max | CC | |
|---|---|---|---|---|---|---|
| Evaporation (E) | 8.18 | 2.51 | 4.30 | 14.60 | — | |
| Soil Temperature () | 22.54 | 3.69 | 13.61 | 27.80 | 0.7814 | |
| Soil Permeability () | 8.40 | 0.96 | 7.04 | 13.25 | −0.0974 | |
| Soil Conductivity () | 0.02 | 0.03 | 0.00 | 0.16 | −0.2126 | |
| Air Temperature () | 29.18 | 5.25 | 12.20 | 40.60 | 0.7369 | |
| Wind Velocity () | 1.57 | 0.50 | 0.57 | 3.66 | 0.1711 | |
| Vapour Pressure () | 1.53 | 0.40 | 0.63 | 2.59 | 0.4835 | |
| Relative Humidity() | 58.20 | 12.68 | 23.03 | 88.28 | −0.3032 | |
| Air Pressure () | 97.68 | 0.36 | 96.23 | 98.46 | −0.2648 | |
| Solar Radiance () | 484.85 | 156.72 | 10.94 | 949.18 | 0.2314 | |
| Hydrometrical deficit () | 1.16 | 0.53 | 0.16 | 2.72 | 0.6541 | |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| (120, 80, 40) | 0.01 | ||
| relu | 0.0001 | ||
| adam | True | ||
| adaptive | 0.2 | ||
| 3000 |
| Training | Training | |||
|---|---|---|---|---|
| () | () | |||
| () | () | |||
| () | () | |||
| () | () | |||
| Training | Training | |||
|---|---|---|---|---|
| () | () | |||
| () | () | |||
| () | () | |||
| () | () | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Garrido, M.C.; Cadenas, J.M.; Bueno-Crespo, A.; Martínez-España, R.; Giménez, J.G.; Cecilia, J.M. Evaporation Forecasting through Interpretable Data Analysis Techniques. Electronics 2022, 11, 536. https://doi.org/10.3390/electronics11040536
Garrido MC, Cadenas JM, Bueno-Crespo A, Martínez-España R, Giménez JG, Cecilia JM. Evaporation Forecasting through Interpretable Data Analysis Techniques. Electronics. 2022; 11(4):536. https://doi.org/10.3390/electronics11040536
Chicago/Turabian StyleGarrido, M. Carmen, José M. Cadenas, Andrés Bueno-Crespo, Raquel Martínez-España, José G. Giménez, and José M. Cecilia. 2022. "Evaporation Forecasting through Interpretable Data Analysis Techniques" Electronics 11, no. 4: 536. https://doi.org/10.3390/electronics11040536
APA StyleGarrido, M. C., Cadenas, J. M., Bueno-Crespo, A., Martínez-España, R., Giménez, J. G., & Cecilia, J. M. (2022). Evaporation Forecasting through Interpretable Data Analysis Techniques. Electronics, 11(4), 536. https://doi.org/10.3390/electronics11040536