
Bidimensional and Tridimensional Poincaré Maps in Cardiology: A Multiclass Machine Learning Study

 ,
,  ,
,  ,
,  , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Poincaré Plot Analysis
2.3. Statistical Analysis
2.4. Machine Learning Tool and Algorithms
3. Results
3.1. Statistical Analysis
3.2. Machine Learning Analysis
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Donisi, L.; Ricciardi, C.; Cesarelli, G.; Pagano, G.; Amitrano, F.; D’Addio, G. Machine Learning applied on Poincaré Analyisis to discriminate different cardiac issues. In Proceedings of the 2020 11th Conference of the European Study Group on Cardiovascular Oscillations (ESGCO), Pisa, Italy, 15 July 2020; Pernice, R., Ed.; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- La Rovere, M.T.; Pinna, G.D.; Maestri, R.; Mortara, A.; Capomolla, S.; Febo, O.; Ferrari, R.; Franchini, M.; Gnemmi, M.; Opasich, C.; et al. Short-Term Heart Rate Variability Strongly Predicts Sudden Cardiac Death in Chronic Heart Failure Patients. Circulation 2003, 107, 565–570. [Google Scholar] [CrossRef] [PubMed]
- Cusenza, M.; Accardo, A.; D’Addio, G.; Corbi, G. Relationship between fractal dimension and power-law exponent of heart rate variability in normal and heart failure subjects. In Proceedings of the 2010 Computing in Cardiology, Belfast, UK, 26–29 September 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 935–938. [Google Scholar]
- Maestri, R.; Pinna, G.D.; Balocchi, R.; D’Addio, G.; Ferrario, M.; Porta, A.; Sassi, R.; Signorini, M.G.; Rovere, M.T.L. Clinical correlates of non-linear indices of heart rate variability in chronic heart failure patients. Biomed. Tech. 2006, 51, 220–223. [Google Scholar] [CrossRef] [PubMed]
- Ding, H.; Crozier, S.; Wilson, S. A New Heart Rate Variability Analysis Method by Means of Quantifying the Variation of Nonlinear Dynamic Patterns. IEEE Trans. Biomed. Eng. 2007, 54, 1590–1597. [Google Scholar] [CrossRef] [PubMed]
- Kamen, P.W.; Krum, H.; Tonkin, A.M. Poincaré Plot of Heart Rate Variability Allows Quantitative Display of Parasympathetic Nervous Activity in Humans. Clin. Sci. 1996, 91, 201–208. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dudchenko, A.; Ganzinger, M.; Kopanitsa, G. Machine Learning Algorithms in Cardiology Domain: A Systematic Review. Open Bioinform. J. 2020, 13, 25–40. [Google Scholar] [CrossRef]
- Dey, D.; Slomka, P.J.; Leeson, P.; Comaniciu, D.; Shrestha, S.; Sengupta, P.P.; Marwick, T.H. Artificial Intelligence in Cardiovascular Imaging: JACC State-of-the-Art Review. J. Am. Coll. Cardiol. 2019, 73, 1317–1335. [Google Scholar] [CrossRef]
- Ricciardi, C.; Improta, G.; Amato, F.; Cesarelli, G.; Romano, M. Classifying the type of delivery from cardiotocographic signals: A machine learning approach. Comput. Methods Programs Biomed. 2020, 196, 105712. [Google Scholar] [CrossRef]
- Kannan, E.; Ravikumar, S.; Anitha, A.; Kumar, S.; Vijayasarathy, M. Analyzing uncertainty in cardiotocogram data for the prediction of fetal risks based on machine learning techniques using rough set. J. Ambient Intell. Humaniz. Comput. 2021, 1–13. [Google Scholar] [CrossRef]
- Alsaggaf, W.; Cömert, Z.; Nour, M.; Polat, K.; Brdesee, H.; Toğaçar, M. Predicting fetal hypoxia using common spatial pattern and machine learning from cardiotocography signals. Appl. Acoust. 2020, 167, 107429. [Google Scholar] [CrossRef]
- Recenti, M.; Ricciardi, C.; Gìslason, M.; Edmunds, K.; Carraro, U.; Gargiulo, P. Machine Learning Algorithms Predict Body Mass Index Using Nonlinear Trimodal Regression Analysis from Computed Tomography Scans. In Proceedings of the XV Mediterranean Conference on Medical and Biological Engineering and Computing—MEDICON 2019, Coimbra, Portugal, 26–28 September 2019; Henriques, J., Neves, N., de Carvalho, P., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 839–846. [Google Scholar]
- Recenti, M.; Ricciardi, C.; Edmunds, K.; Gislason, M.K.; Gargiulo, P. Machine learning predictive system based upon radiodensitometric distributions from mid-thigh CT images. Eur. J. Transl. Myol. 2020, 30, 8892. [Google Scholar] [CrossRef] [Green Version]
- Ricciardi, C.; Cuocolo, R.; Cesarelli, G.; Ugga, L.; Improta, G.; Solari, D.; Romeo, V.; Guadagno, E.; Cvallo, L.M.; Cesarelli, M. Distinguishing Functional from Non-functional Pituitary Macroadenomas with a Machine Learning Analysis. In Proceedings of the XV Mediterranean Conference on Medical and Biological Engineering and Computing—MEDICON 2019, Coimbra, Portugal, 26–28 September 2019; Henriques, J., Neves, N., de Carvalho, P., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 1822–1829. [Google Scholar]
- Park, J.E.; Kim, H.S.; Kim, D.; Park, S.Y.; Kim, J.Y.; Cho, S.J.; Kim, J.H. A systematic review reporting quality of radiomics research in neuro-oncology: Toward clinical utility and quality improvement using high-dimensional imaging features. BMC Cancer 2020, 20, 29. [Google Scholar] [CrossRef] [PubMed]
- Tseng, H.-H.; Wei, L.; Cui, S.; Luo, Y.; Ten Haken, R.K.; El Naqa, I. Machine Learning and Imaging Informatics in Oncology. Oncology 2020, 98, 344–362. [Google Scholar] [CrossRef] [PubMed]
- Scrutinio, D.; Ricciardi, C.; Donisi, L.; Losavio, E.; Battista, P.; Guida, P.; Cesarelli, M.; Pagano, G.; D’Addio, G. Machine learning to predict mortality after rehabilitation among patients with severe stroke. Sci. Rep. 2020, 10, 20127. [Google Scholar] [CrossRef]
- Le Berre, C.; Sandborn, W.J.; Aridhi, S.; Devignes, M.-D.; Fournier, L.; Smaïl-Tabbone, M.; Danese, S.; Peyrin-Biroulet, L. Application of Artificial Intelligence to Gastroenterology and Hepatology. Gastroenterology 2020, 158, 76–94. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sirsat, M.S.; Fermé, E.; Câmara, J. Machine Learning for Brain Stroke: A Review. J. Stroke Cerebrovasc. Dis. 2020, 29, 105162. [Google Scholar] [CrossRef] [PubMed]
- Woo, M.A.; Stevenson, W.G.; Moser, D.K.; Trelease, R.B.; Harper, R.M. Patterns of beat-to-beat heart rate variability in advanced heart failure. Am. Heart J. 1992, 123, 704–710. [Google Scholar] [CrossRef]
- Brouwer, J.; van Veldhuisen, D.J.; Man In ’t Veld, A.J.; Haaksma, J.; Dijk, W.A.; Visser, K.R.; Boomsma, F.; Dunselman, P.H.J.M.; Lie, K.I. Prognostic value of heart rate variability during long-term follow-up in patients with mild to moderate heart failure. J. Am. Coll. Cardiol. 1996, 28, 1183–1189. [Google Scholar] [CrossRef] [Green Version]
- Marciano, F.; Migaux, M.L.; Acanfora, D.; Furgi, G.; Rengo, F. Quantification of Poincare’ maps for the evaluation of heart rate variability. In Proceedings of the Computers in Cardiology 1994, Bethesda, MD, USA, 25–28 September 1994; IEEE: Piscataway, NJ, USA, 1994; pp. 577–580. [Google Scholar]
- D’Addio, G.; Acanfora, D.; Pinna, G.; Maestri, R.; Furgi, G.; Picone, C.; Rengo, F. Reproducibility of short- and long-term Poincare plot parameters compared with frequency-domain HRV indexes in congestive heart failure. In Proceedings of the Computers in Cardiology 1998, Cleveland, OH, USA, 13–16 September 1998; IEEE: Piscataway, NJ, USA; pp. 381–384. [Google Scholar]
- Isler, Y.; Narin, A.; Ozer, M.; Perc, M. Multi-stage classification of congestive heart failure based on short-term heart rate variability. Chaos Solitons Fractals 2019, 118, 145–151. [Google Scholar] [CrossRef]
- Isler, Y.; Narin, A.; Ozer, M. Comparison of the Effects of Cross-validation Methods on Determining Performances of Classifiers Used in Diagnosing Congestive Heart Failure. Meas. Sci. Rev. 2015, 15, 196–201. [Google Scholar] [CrossRef] [Green Version]
- Gong, X.; Long, B.; Wang, Z.; Zhang, H.; Nandi, A.K. Faster Detection of Abnormal Electrocardiogram (ECG) Signals Using Fewer Features of Heart Rate Variability (HRV). J. Comput. Sci. Syst. Biol. 2018, 12, 19–27. [Google Scholar] [CrossRef]
- Zhao, L.; Liu, C.; Wei, S.; Liu, C.; Li, J. Enhancing Detection Accuracy for Clinical Heart Failure Utilizing Pulse Transit Time Variability and Machine Learning. IEEE Access 2019, 7, 17716–17724. [Google Scholar] [CrossRef]
- Sassi, R. Analysis of Heart Rate Variability Complexity through Fractal and Multivariate Approaches. Ph.D. Dissertation, Politecnico di Milano, Milan, Italy, 31 October 2000. [Google Scholar]
- Romano, M.; Bifulco, P.; Ruffo, M.; Improta, G.; Clemente, F.; Cesarelli, M. Software for computerised analysis of cardiotocographic traces. Comput. Methods Programs Biomed. 2016, 124, 121–137. [Google Scholar] [CrossRef] [PubMed]
- D’Addio, G.; Pinna, G.D.; La Rovere, M.T.; Maestri, R.; Furgi, G.; Rengo, F. Prognostic value of Poincare/spl acute/plot indexes in chronic heart failure patients. In Proceedings of the Computers in Cardiology 2001, Rotterdam, The Netherlands, 23–26 September 2001; IEEE: Piscataway, NJ, USA; pp. 57–60. [Google Scholar]
- D’Addio, G.; Pinna, G.D.; Maestri, R.; Corbi, G.; Ferrara, N.; Rengo, F. Quantitative Poincare plots analysis contains relevant information related to heart rate variability dynamics of normal and pathological subjects. In Proceedings of the Computers in Cardiology 2004, Chicago, IL, USA, 19–22 September 2004; IEEE: Piscataway, NJ, USA; pp. 457–460. [Google Scholar]
- Sheng, P.; Chen, L.; Tian, J. Learning-based road crack detection using gradient boost decision tree. In Proceedings of the 2018 13th IEEE Conference on Industrial Electronics and Applications (ICIEA), Wuhan, China, 31 May–2 June 2018; IEEE: Piscataway, NJ, USA; pp. 1228–1232. [Google Scholar]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Weinberger, K.Q.; Saul, L.K. Distance Metric Learning for Large Margin Nearest Neighbor Classification. J. Mach. Learn. Res. 2009, 10, 207–244. [Google Scholar]
- Sun, S.; Huang, R. An adaptive k-nearest neighbor algorithm. In Proceedings of the 2010 Seventh International Conference on Fuzzy Systems and Knowledge Discovery, Yantai, China, 10–12 August 2010; IEEE: Piscataway, NJ, USA; pp. 91–94. [Google Scholar]
- Al-Aidaroos, K.M.; Bakar, A.A.; Othman, Z. Naïve bayes variants in classification learning. In Proceedings of the 2010 International Conference on Information Retrieval Knowledge Management (CAMP), Shah Alam, Malaysia, 17–18 March 2010; IEEE: Piscataway, NJ, USA; pp. 276–281. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Ishaq, A.; Sadiq, S.; Umer, M.; Ullah, S.; Mirjalili, S.; Rupapara, V.; Nappi, M. Improving the Prediction of Heart Failure Patients’ Survival Using SMOTE and Effective Data Mining Techniques. IEEE Access 2021, 9, 39707–39716. [Google Scholar] [CrossRef]
- Kohavi, R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection. In Proceedings of the Fourteenth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995; Morgan Kaufmann Publishers: San Francisco, CA, USA; pp. 1137–1143. [Google Scholar]
- Zinati, Z.; Zamansani, F.; KayvanJoo, A.H.; Ebrahimi, M.; Ebrahimi, M.; Ebrahimie, E.; Dehcheshmeh, M.M. New layers in understanding and predicting α-linolenic acid content in plants using amino acid characteristics of omega-3 fatty acid desaturase. Comput. Biol. Med. 2014, 54, 14–23. [Google Scholar] [CrossRef]
- Ebrahimie, E.; Ebrahimi, F.; Ebrahimi, M.; Tomlinson, S.; Petrovski, K.R. Hierarchical pattern recognition in milking parameters predicts mastitis prevalence. Comput. Electron. Agric. 2018, 147, 6–11. [Google Scholar] [CrossRef]
- Ebrahimie, E.; Ebrahimi, F.; Ebrahimi, M.; Tomlinson, S.; Petrovski, K.R. A large-scale study of indicators of sub-clinical mastitis in dairy cattle by attribute weighting analysis of milk composition features: Highlighting the predictive power of lactose and electrical conductivity. J. Dairy Res. 2018, 85, 193–200. [Google Scholar] [CrossRef]
- Ebrahimi, M.; Mohammadi-Dehcheshmeh, M.; Ebrahimie, E.; Petrovski, K.R. Comprehensive analysis of machine learning models for prediction of sub-clinical mastitis: Deep Learning and Gradient-Boosted Trees outperform other models. Comput. Biol. Med. 2019, 114, 103456. [Google Scholar] [CrossRef]
- Tougui, I.; Jilbab, A.; El Mhamdi, J. Heart disease classification using data mining tools and machine learning techniques. Health Technol. 2020, 10, 1137–1144. [Google Scholar] [CrossRef]
- Berthold, M.R.; Cebron, N.; Dill, F.; Gabriel, T.R.; Kötter, T.; Meinl, T.; Ohl, P.; Thiel, K.; Wiswedel, B. KNIME—The Konstanz information miner: Version 2.0 and beyond. SIGKDD Explor. Newsl. 2009, 11, 26–31. [Google Scholar] [CrossRef] [Green Version]
- Donisi, L.; Coccia, A.; Amitrano, F.; Mercogliano, L.; Cesarelli, G.; D’Addio, G. Backpack Influence on Kinematic Parameters related to Timed Up and Go (TUG) Test in School Children. In Proceedings of the 2020 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Bari, Italy, 15 June 2020; IEEE: Piscataway, NJ, USA; pp. 1–5. [Google Scholar]
- Preetha, S.; Chandan, N.; Darshan, N.K.; Gowrav, P.B. Diabetes Disease Prediction Using Machine Learning. Int. J. Mod. Trends Eng. Res. 2020, 6, 37–43. [Google Scholar] [CrossRef]
- Goh, K.H.; Wang, L.; Yeow, A.Y.K.; Poh, H.; Li, K.; Yeow, J.J.L.; Tan, G.Y.H. Artificial intelligence in sepsis early prediction and diagnosis using unstructured data in healthcare. Nat. Commun. 2021, 12, 711. [Google Scholar] [CrossRef]
- Guleria, P.; Sood, M. Intelligent Learning. In Machine Learning with Health Care Perspective: Machine Learning and Healthcare, 1st ed.; Jain, V., Chatterjee, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 39–55. ISBN 978-3-030-40850-3. [Google Scholar]
- An, J.Y.; Seo, H.; Kim, Y.-G.; Lee, K.E.; Kim, S.; Kong, H.-J. Codeless Deep Learning of COVID-19 Chest X-Ray Image Dataset with KNIME Analytics Platform. Healthc. Inform. Res. 2021, 27, 82–91. [Google Scholar] [CrossRef] [PubMed]
- Tuerkova, A.; Zdrazil, B. A ligand-based computational drug repurposing pipeline using KNIME and Programmatic Data Access: Case studies for rare diseases and COVID-19. J. Cheminform. 2020, 12, 71. [Google Scholar] [CrossRef] [PubMed]
- van Smeden, M.; Moons, K.G.; de Groot, J.A.; Collins, G.S.; Altman, D.G.; Eijkemans, M.J.; Reitsma, J.B. Sample size for binary logistic prediction models: Beyond events per variable criteria. Stat. Methods Med. Res. 2019, 28, 2455–2474. [Google Scholar] [CrossRef] [Green Version]
- Karimi Moridani, M.; Setarehdan, S.K.; Motie Nasrabadi, A.; Hajinasrollah, E. Non-linear feature extraction from HRV signal for mortality prediction of ICU cardiovascular patient. J. Med. Eng. Technol. 2016, 40, 87–98. [Google Scholar] [CrossRef]
- Rezaei, S.; Moharreri, S.; Abdollahpur, M.; Parvaneh, S. Heart Arrhythmia Classification Using Extracted Features in Poincare Plot of RR Intervals. In Proceedings of the Computers in Cardiology 2017, Rennes, France, 24–27 September 2017; IEEE: Piscataway, NJ, USA. [Google Scholar]
- Agliari, E.; Barra, A.; Barra, O.A.; Fachechi, A.; Vento, L.F.; Moretti, L. Detecting cardiac pathologies via machine learning on heart-rate variability time series and related markers. Sci. Rep. 2020, 10, 8845. [Google Scholar] [CrossRef]
- Devi, R.; Tyagi, H.K.; Kumar, D. A novel multi-class approach for early-stage prediction of sudden cardiac death. Biocybern. Biomed. Eng. 2019, 39, 586–598. [Google Scholar] [CrossRef]
- Leite, A.; Silva, M.E.; Rocha, A.P. Classification of HRV using Long Short-Term Memory Networks. In Proceedings of the 2020 11th Conference of the European Study Group on Cardiovascular Oscillations (ESGCO), Pisa, Italy, 15 July 2020; Pernice, R., Ed.; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- D’Addio, G.; Donisi, L.; Cesarelli, G.; Amitrano, F.; Coccia, A.; La Rovere, M.T.; Ricciardi, C. Extracting Features from Poincaré Plots to Distinguish Congestive Heart Failure Patients According to NYHA Classes. Bioengineering 2021, 8, 138. [Google Scholar] [CrossRef] [PubMed]
- Ricciardi, C.; Donisi, L.; Cesarelli, G.; Pagano, G.; Coccia, A.; D’Addio, G. Feasibility of Machine Learning applied to Poincaré Plot Analysis on Patients with CHF. In Proceedings of the 2020 11th Conference of the European Study Group on Cardiovascular Oscillations (ESGCO), Pisa, Italy, 15 July 2020; Pernice, R., Ed.; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- da Silva Pinho, N.; de Azevedo Gomes, D.; dos Santos, A.D.F. Classifying cardiac rhythms by means of digital signal processing and machine learning. J. Commun. Inf. Syst. 2020, 35, 25–33. [Google Scholar] [CrossRef]



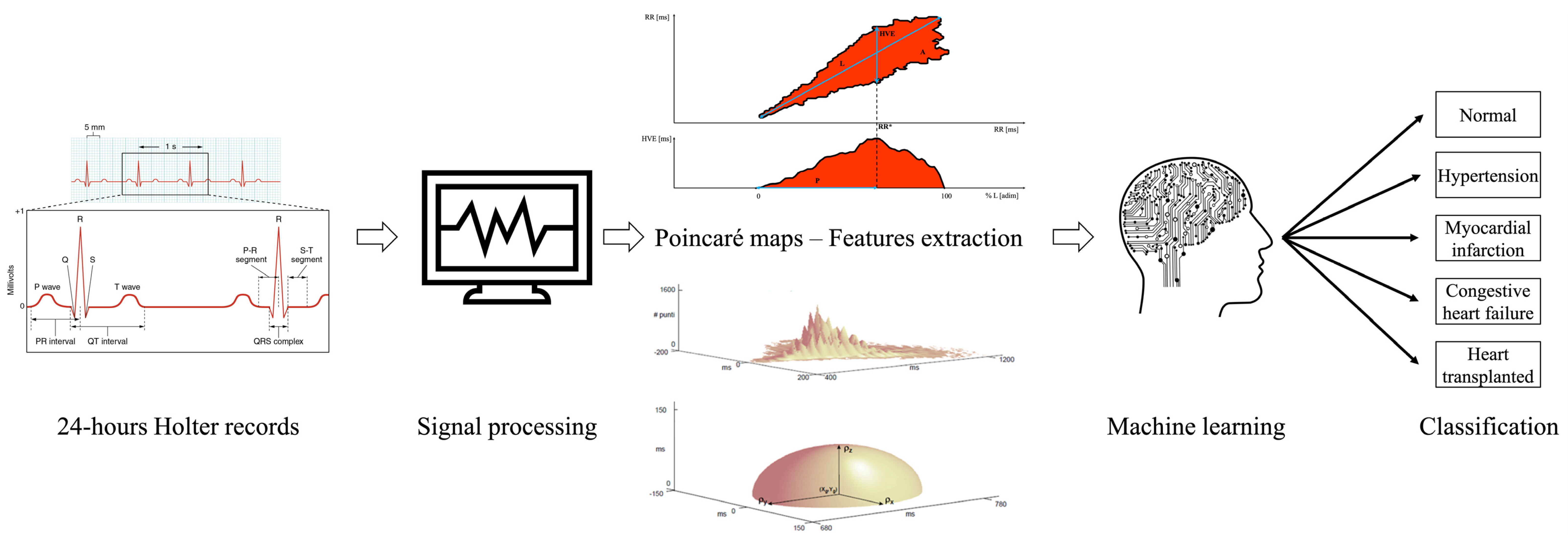{kind=link}
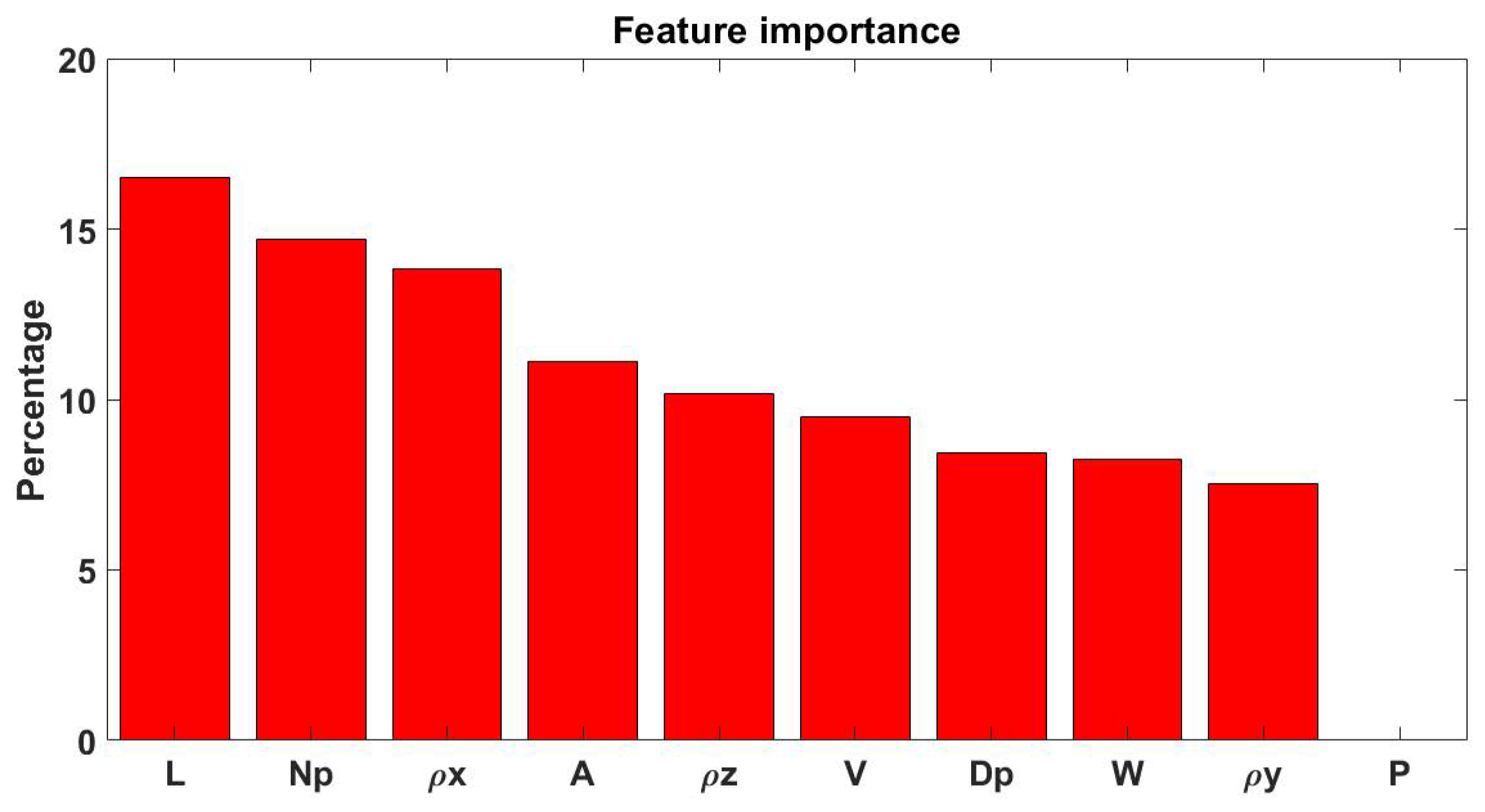{kind=link}
| Par | C | H | M | N | T | p-Value |
|---|---|---|---|---|---|---|
| L | 540.0 ± 113.2 | 801.0 ± 138.2 | 640.0 ± 111.6 | 803.0 ± 107.7 | 360.0 ± 95.8 | *** |
| HVE | 143.6 ± 66.2 | 232.6 ± 70.2 | 176.4 ± 42.2 | 227.9 ± 73.8 | 118.4 ± 39.7 | *** |
| P | 55.3 ± 12.0 | 60.3 ± 13.3 | 61.9 ± 14.7 | 61.5 ± 5.7 | 50.1 ± 16.8 | 0.296 |
| A # | 8.0 ± 4.4 | 17.4 ± 6.4 | 10.5 ± 2.9 | 16.9 ± 6.4 | 4.4 ± 1.5 | *** |
| Np | 15.7 ± 11.7 | 24.9 ± 7.6 | 36.8 ± 18.5 | 44.3 ± 20.6 | 6.1 ± 3.9 | *** |
| Dp | 3.1 ± 2.0 | 1.1 ± 1.1 | 5.2 ± 2.6 | 5.1 ± 1.5 | 0.6 ± 1.3 | *** |
| V ## | 1.1 ± 0.2 | 1.1 ± 0.1 | 1.0 ± 0.2 | 1.0 ± 0.1 | 1.2 ± 0.1 | 0.118 |
| ρx | 49.9 ± 9.0 | 41.1 ± 3.4 | 41.7 ± 10.6 | 39.1 ± 4.6 | 75.5 ± 22.6 | *** |
| ρy | 100.4 ± 13.5 | 139.9 ± 36.7 | 110.0 ± 12.5 | 136.8 ± 19.8 | 106.7 ± 17.8 | *** |
| ρz | 88.1 ± 19.2 | 136.6 ± 38.6 | 103.4 ± 17.8 | 134.6 ± 20.8 | 71.2 ± 27.2 | *** |
| Par | Classes | p-Value |
|---|---|---|
| L | T-M | 0.034 |
| T-H | <0.001 | |
| T-N | <0.001 | |
| C-H | 0.031 | |
| C-N | 0.018 | |
| HVE | T-N | 0.009 |
| T-H | 0.002 | |
| C-H | 0.039 | |
| A | T-N | <0.001 |
| T-H | <0.001 | |
| C-N | 0.034 | |
| C-H | 0.022 | |
| Np | T-M | <0.001 |
| T-N | <0.001 | |
| C-N | 0.020 | |
| Dp | T-M | 0.001 |
| T-N | <0.001 | |
| I-M | 0.012 | |
| H-N | 0.006 | |
| ρx | T-M | <0.001 |
| T-N | <0.001 | |
| T-H | 0.001 | |
| ρy | T-N | 0.021 |
| C-H | 0.010 | |
| C-N | 0.001 | |
| ρz | T-H | 0.002 |
| T-N | <0.001 | |
| C-H | 0.021 | |
| C-N | 0.002 |
| Observed | Predicted | Correctness Percentage | ||||
|---|---|---|---|---|---|---|
| C | H | M | N | T | ||
| C | 7 | 0 | 2 | 0 | 1 | 70,0% |
| H | 0 | 10 | 0 | 0 | 0 | 100.0% |
| M | 3 | 0 | 5 | 2 | 0 | 50.0% |
| N | 1 | 0 | 1 | 8 | 0 | 80.0% |
| T | 2 | 0 | 0 | 0 | 8 | 80.0% |
| Algorithms | Accuracy [%] | Sensitivity [%] | Specificity [%] |
|---|---|---|---|
| GB | 85.0 | 100.0 | 97.5 |
| ADA-B | 91.0 | 90.0 | 97.5 |
| kNN | 92.0 | 95.0 | 100.0 |
| NB | 76.0 | 65.0 | 93.8 |
| Real/Predicted | N | H | M | C | T |
|---|---|---|---|---|---|
| N | 19 | 0 | 0 | 1 | 0 |
| H | 0 | 19 | 1 | 0 | 0 |
| M | 0 | 1 | 16 | 2 | 1 |
| C | 0 | 0 | 1 | 18 | 1 |
| T | 0 | 0 | 0 | 0 | 20 |
| Algorithms | Accuracy [%] | Sensitivity [%] | Specificity [%] |
|---|---|---|---|
| GB | 90.0 | 100.0 | 100.0 |
| ADA-B | 93.3 | 100.0 | 95.8 |
| kNN | 96.7 | 100.0 | 100.0 |
| NB | 86.7 | 100.0 | 91.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Donisi, L.; Ricciardi, C.; Cesarelli, G.; Coccia, A.; Amitrano, F.; Adamo, S.; D’Addio, G. Bidimensional and Tridimensional Poincaré Maps in Cardiology: A Multiclass Machine Learning Study. Electronics 2022, 11, 448. https://doi.org/10.3390/electronics11030448
Donisi L, Ricciardi C, Cesarelli G, Coccia A, Amitrano F, Adamo S, D’Addio G. Bidimensional and Tridimensional Poincaré Maps in Cardiology: A Multiclass Machine Learning Study. Electronics. 2022; 11(3):448. https://doi.org/10.3390/electronics11030448
Chicago/Turabian StyleDonisi, Leandro, Carlo Ricciardi, Giuseppe Cesarelli, Armando Coccia, Federica Amitrano, Sarah Adamo, and Giovanni D’Addio. 2022. "Bidimensional and Tridimensional Poincaré Maps in Cardiology: A Multiclass Machine Learning Study" Electronics 11, no. 3: 448. https://doi.org/10.3390/electronics11030448
APA StyleDonisi, L., Ricciardi, C., Cesarelli, G., Coccia, A., Amitrano, F., Adamo, S., & D’Addio, G. (2022). Bidimensional and Tridimensional Poincaré Maps in Cardiology: A Multiclass Machine Learning Study. Electronics, 11(3), 448. https://doi.org/10.3390/electronics11030448