
SpotFuzz: Fuzzing Based on Program Hot-Spots

Abstract
:1. Introduction
- We study the hot-spot issues in the program and prove that different inputs cause varying distributions of hot-spots in the program, thus affecting the fuzzing efficiency of AFL.
- We propose a new favored seed selection algorithm and power schedule strategy based on the hot-spots ratio of each seed. The seeds with a high ration will be tested less and delayed.
- We implement two modules in our coverage-guided fuzzer SpotFuzz. SpotFuzz-h studies the influence of program hot-spots caused by the hit counts of edge, while SpotFuzz-t focuses on the time-consuming edge. We combine those two strategies together and optimize the final result.
- Our fuzzer find 45.86% more unique crashes than AFL and prove that reducing the occurrence of hot-spots in test cases can improve the efficiency of the fuzzer.
2. Background
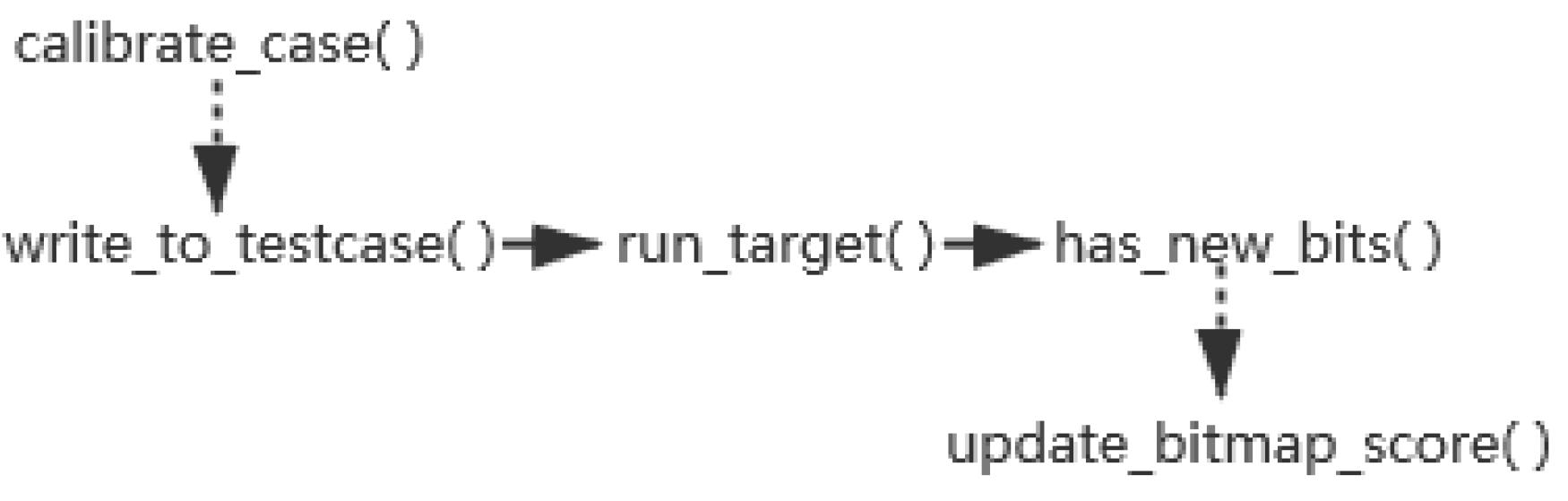
2.1. Coverage-Guided Fuzzing

2.2. Code Coverage
2.3. Seed Selection & Power Schedule
2.4. Motivation of SpotFuzz
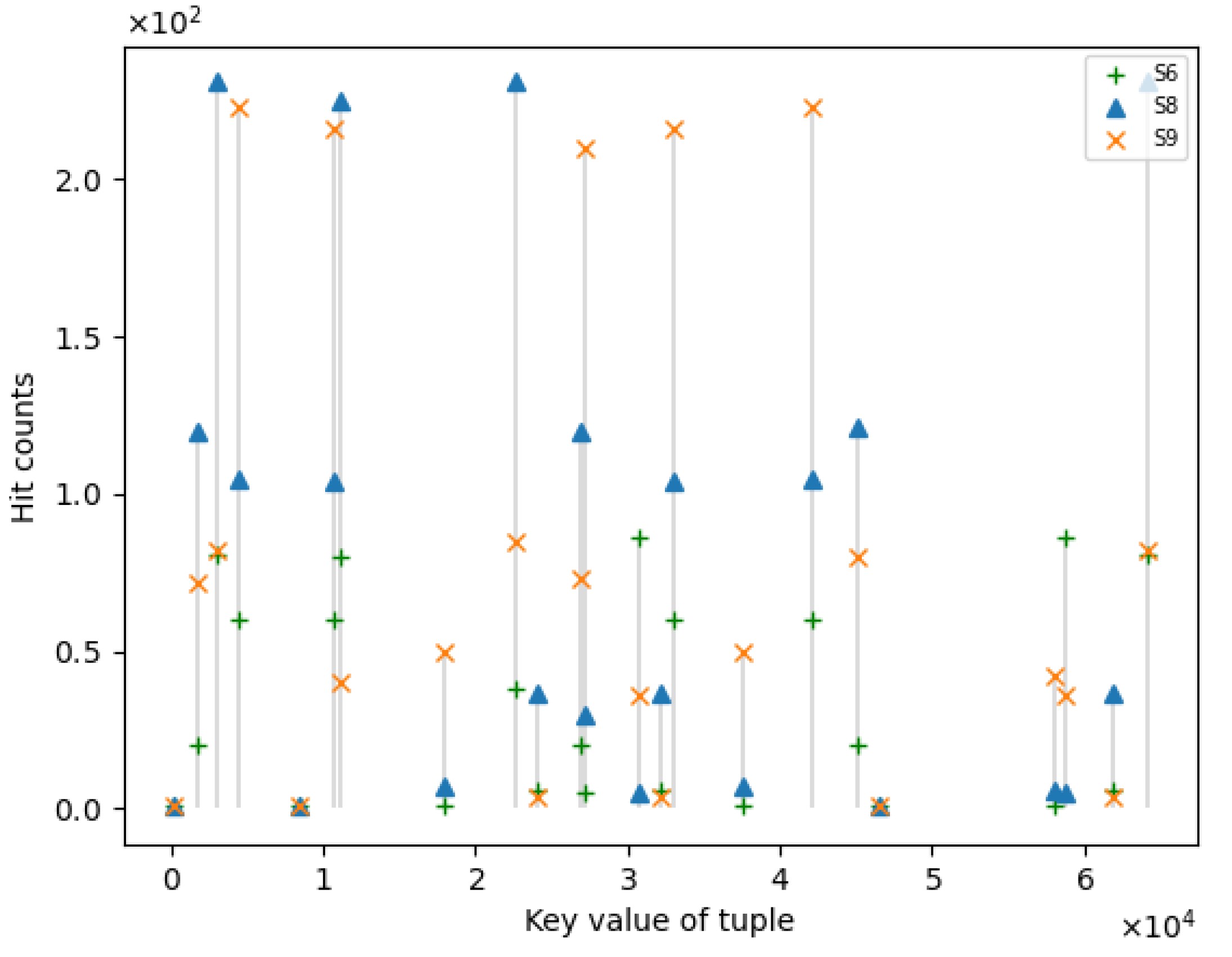
2.4.1. The Seeds Repeatedly Exercise Certain Edges and Cause Energy Waste
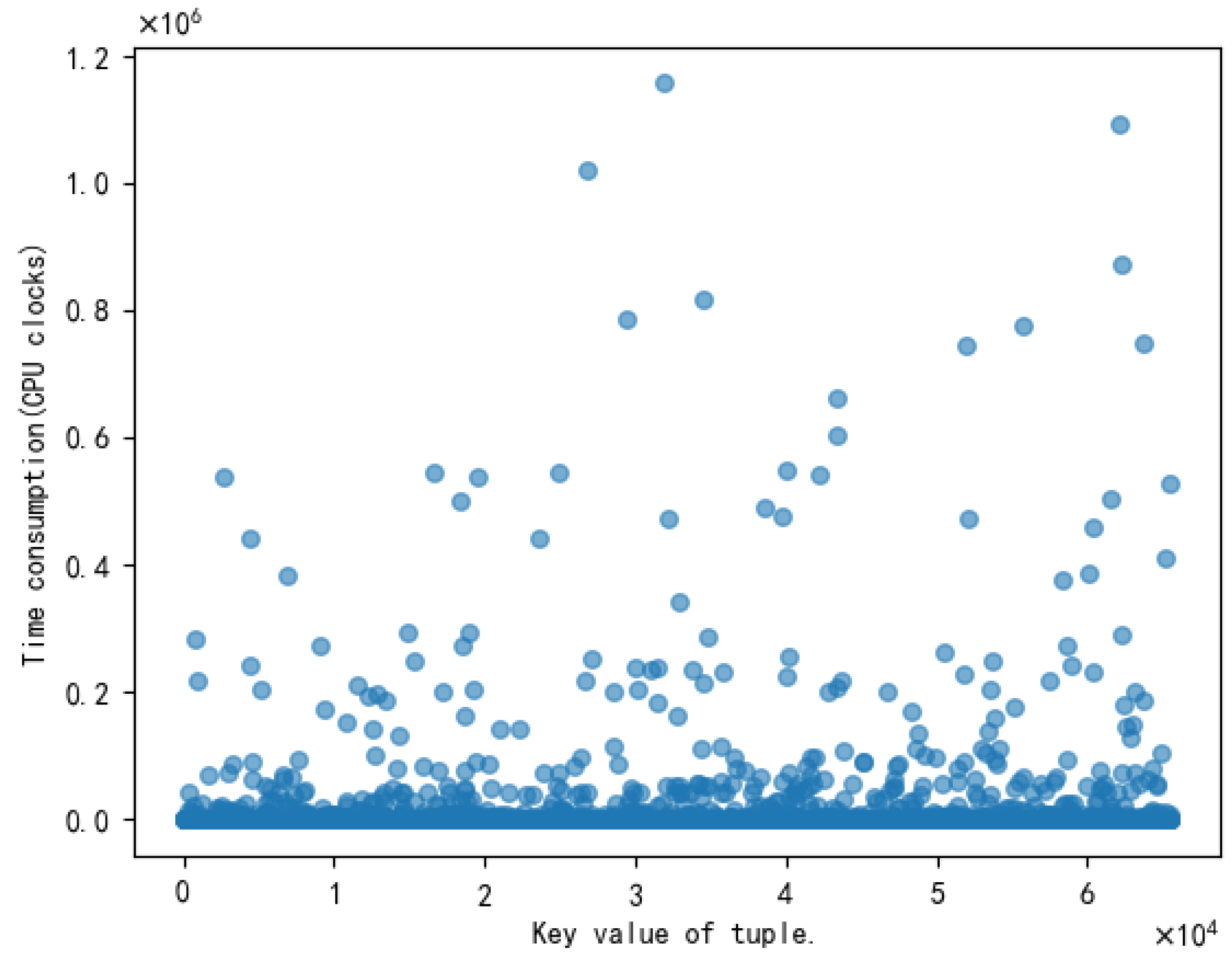
2.4.2. Time-Consuming Edges Are Executed Excessively, Which Affect the Fuzzing Efficiency
3. Methodology
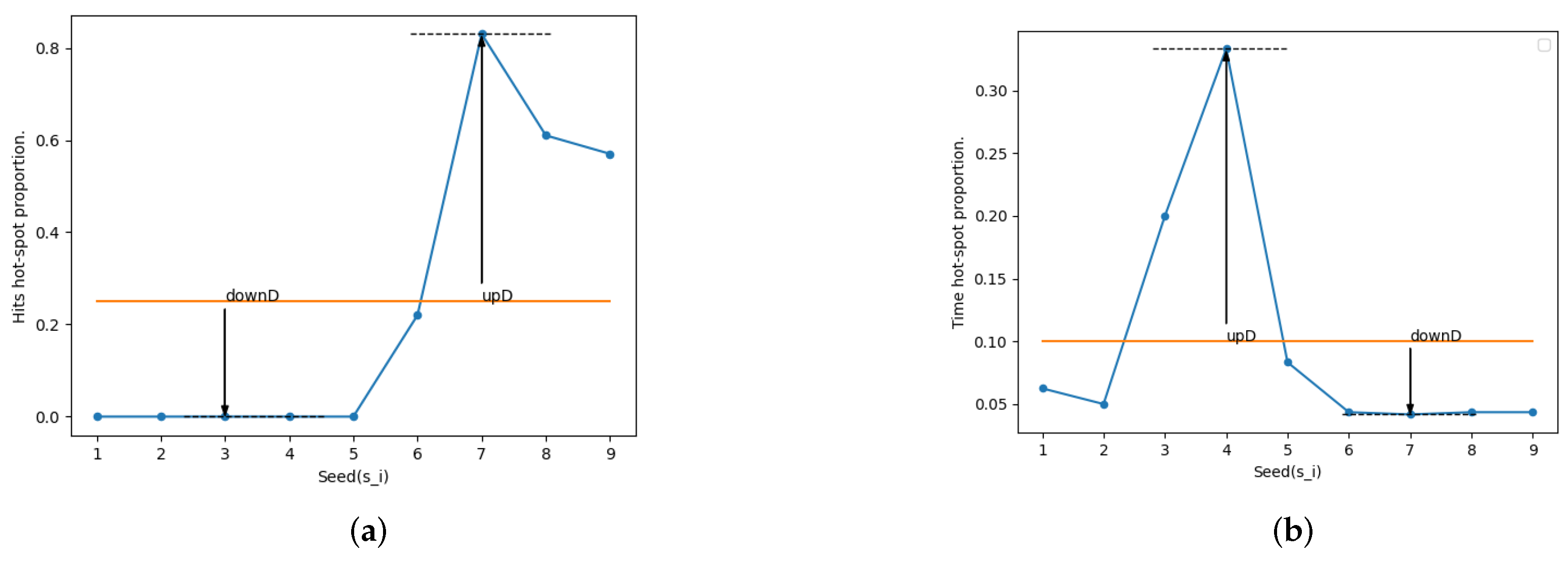
3.1. Definition of Seed Hot-Spots
3.2. Seed Hot-Spots Ratio Model
3.3. Challenges of Schedule Algorithms
| Algorithm 1 Hot-spots ratio update strategy |
|
3.4. Seed Selection Algorithm
| Algorithm 2 Favored seed selection algorithm |
| Input: Seed s; |
|
| Output: Favored seed set F |
3.5. Power Schedule Strategy
4. Implementation
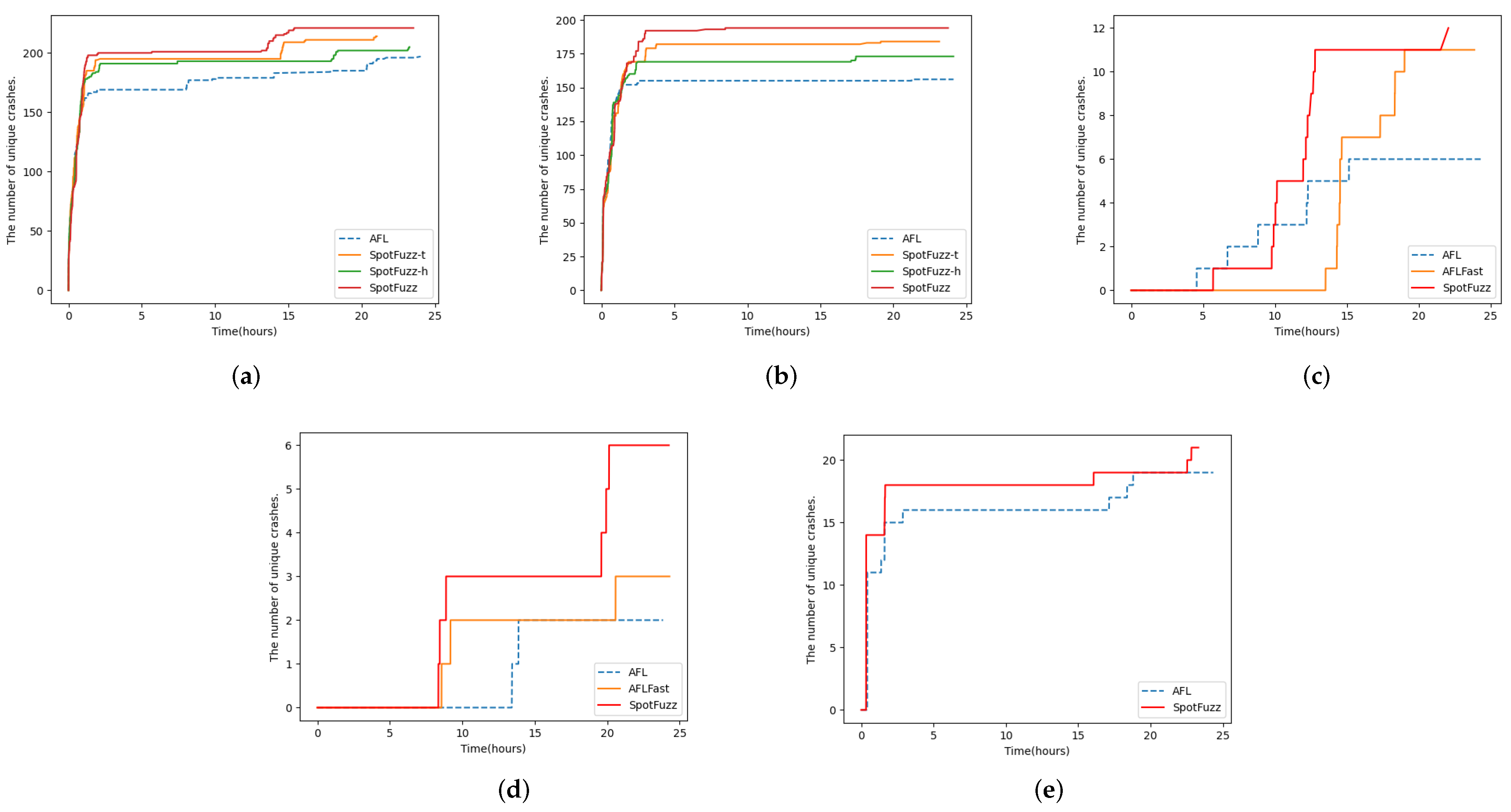
5. Evaluation
5.1. Configuration of Evaluation
5.2. Evaluation on YAML-CPP
5.3. Evaluation on GNU Binutils and Other Tools
5.4. Evaluation Summery
6. Related Work
6.1. Unscientific Power Schedule Strategy & Improve Seed Selection Algorithm
6.2. AFL Is Harder to Break through Special Boundaries
6.3. AFL Has High Overhead for No Source Code Fuzzing
6.4. Inaccurate Path Coverage Information
6.5. Invalid Test Cases
6.6. Waste Too Many Resources in a Bug-Free Place
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| /us | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 90.509 | ||
| 1 | 4 | 0 | 0 | 0 | 20 | 64 | 120 | 72 | 0.014 | ||
| 4 | 16 | 0 | 0 | 1 | 81 | 144 | 231 | 82 | 0.014 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1.996 | ||
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 7.165 | ||
| 3 | 12 | 0 | 0 | 1 | 60 | 248 | 105 | 223 | 0.012 | ||
| 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1.982 | ||
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1.049 | ||
| 3 | 12 | 0 | 0 | 1 | 60 | 192 | 104 | 216 | 0.167 | ||
| 4 | 16 | 0 | 0 | 1 | 80 | 64 | 225 | 40 | 0.013 | ||
| 0 | 0 | 0 | 0 | 0 | 1 | 144 | 7 | 50 | 1.354 | ||
| 1 | 7 | 0 | 0 | 0 | 38 | 174 | 231 | 85 | 0.995 | ||
| 0 | 1 | 0 | 0 | 0 | 6 | 34 | 37 | 4 | 2.035 | ||
| 1 | 4 | 0 | 0 | 0 | 20 | 72 | 120 | 73 | 1.018 | ||
| 0 | 1 | 0 | 0 | 0 | 5 | 145 | 30 | 210 | 1.952 | ||
| 4 | 17 | 1 | 0 | 1 | 86 | 33 | 5 | 36 | 0.023 | ||
| 0 | 1 | 0 | 0 | 0 | 6 | 33 | 37 | 4 | 0.013 | ||
| 3 | 12 | 0 | 0 | 1 | 60 | 192 | 104 | 216 | 0.165 | ||
| 0 | 0 | 0 | 0 | 0 | 1 | 144 | 7 | 50 | 1.285 | ||
| 0 | 12 | 0 | 0 | 1 | 60 | 248 | 105 | 223 | 0.010 | ||
| 1 | 4 | 0 | 0 | 0 | 20 | 128 | 121 | 80 | 0.014 | ||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1.205 | ||
| 0 | 0 | 0 | 0 | 0 | 1 | 80 | 6 | 42 | 1.218 | ||
| 4 | 17 | 0 | 0 | 1 | 86 | 33 | 5 | 36 | 0.031 | ||
| 0 | 1 | 0 | 0 | 0 | 6 | 33 | 37 | 4 | 1.019 | ||
| 4 | 16 | 0 | 0 | 1 | 81 | 144 | 231 | 82 | 0.012 | ||
References
- Wang, X.J.; Hu, C.Z.; Ma, R. A Survey of the Key Technology of Binary Program Vulnerability Discovery. Netinfo Secur. 2017, 17, 1–13. [Google Scholar] [CrossRef]
- Li, J.; Zhao, B.; Zhang, C. Fuzzing: A survey. Cybersecurity 2018, 1, 6. [Google Scholar] [CrossRef]
- Liang, H.; Pei, X.; Jia, X.; Shen, W.; Zhang, J.G. Fuzzing: State of the Art. IEEE Trans. Reliab. 2018, 67, 1199–1218. [Google Scholar] [CrossRef]
- American Fuzzy Lop. Available online: https://lcamtuf.coredump.cx/afl/ (accessed on 1 September 2020).
- A Library for Coverage-Guided Fuzz Testing. Available online: http://llvm.org/docs/LibFuzzer.html. (accessed on 4 September 2020).
- Security Oriented Software Fuzzer. Supports Evolutionary, Feedback-Driven Fuzzing Based on Code Coverage (SW and HW Based). Available online: https://honggfuzz.dev/ (accessed on 4 September 2020).
- Böhme, M.; Pham, V.T.; Roychoudhury, A. Coverage-Based Greybox Fuzzing as Markov Chain. IEEE Trans. Software Eng. 2019, 45, 489–506. [Google Scholar] [CrossRef]
- Yue, T.; Wang, P.; Tang, Y.; Wang, E.; Yu, B.; Lu, K.; Zhou, X. EcoFuzz: Adaptive Energy-Saving Greybox Fuzzing as a Variant of the Adversarial Multi-Armed Bandit. In Proceedings of the 29th USENIX Security Symposium, Boston, MA, USA, 12–14 August 2020. [Google Scholar]
- Gan, S.; Zhang, C.; Qin, X.; Tu, X.; Li, K.; Pei, Z.; Chen, Z. CollAFL: Path Sensitive Fuzzing. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 679–696. [Google Scholar]
- Yan, S.; Wu, C.; Li, H.; Shao, W.; Jia, C. PathAFL: Path-Coverage Assisted Fuzzing. In Proceedings of the 15th ACM Asia Conference on Computer and Communications Security, Taipei, Taiwan, 5–9 October 2020. [Google Scholar]
- Ji, C.; Ya, S.; Wa, Z.; Wu, C.; Li, H. Method to improve edge coverage in fuzzing. J. Commun. 2019, 40, 76–85. [Google Scholar] [CrossRef]
- Lemieux, C.; Padhye, R.; Sen, K.; Song, D.X. PerfFuzz: Automatically generating pathological inputs. In Proceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis, Amsterdam, The Netherlands, 16–21 July 2018. [Google Scholar]
- A YAML Parser and Emitter in C++ Matching the YAML. Available online: https://github.com/jbeder/yaml-cpp (accessed on 10 November 2020).
- Binutils Source Code. Available online: https://ftp.gnu.org/gnu/binutils (accessed on 5 May 2021).
- Miller, B.P.; Fredriksen, L.; So, B. An empirical study of the reliability of UNIX utilities. Commun. ACM 1990, 33, 32–44. [Google Scholar] [CrossRef]
- Wang, P.; Zhou, X. SoK: The Progress, Challenges, and Perspectives of Directed Greybox Fuzzing. arXiv 2020, arXiv:2005.11907. [Google Scholar]
- Klees, G.; Ruef, A.; Cooper, B.; Wei, S.; Hicks, M.W. Evaluating Fuzz Testing. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018. [Google Scholar]
- Gopinath, R.; Jensen, C.; Groce, A. Code coverage for suite evaluation by developers. In Proceedings of the 36th International Conference on Software Engineering, Hyderabad, India, 31 May–7 June 2014. [Google Scholar]
- Inozemtseva, L.; Holmes, R. Coverage is not strongly correlated with test suite effectiveness. In Proceedings of the 36th International Conference on Software Engineering, Hyderabad, India, 31 May–7 June 2014. [Google Scholar]
- Tcpdump Source Code. Available online: http://www.tcpdump.org/release/ (accessed on 24 September 2021).
- Böhme, M.; Pham, V.T.; Nguyen, M.D.; Roychoudhury, A. Directed Greybox Fuzzing. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017. [Google Scholar]
- Panwar, A.; Bansal, S.; Gopinath, K. HawkEye: Efficient Fine-grained OS Support for Huge Pages. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, Providence, RI, USA, 13–17 April 2019. [Google Scholar]
- Stephens, N.; Grosen, J.; Salls, C.; Dutcher, A.; Wang, R.; Corbetta, J.; Shoshitaishvili, Y.; Krügel, C.; Vigna, G. Driller: Augmenting Fuzzing Through Selective Symbolic Execution. In Proceedings of the NDSS 2016, San Diego, CA, USA, 21–24 February 2016. [Google Scholar]
- Li, Y.; Chen, B.; Chandramohan, M.; Lin, S.W.; Liu, Y.; Tiu, A. Steelix: Program-state based binary fuzzing. In Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering, Paderborn, Germany, 4–8 September 2017. [Google Scholar]
- Rawat, S.; Jain, V.; Kumar, A.; Cojocar, L.; Giuffrida, C.; Bos, H. VUzzer: Application-aware Evolutionary Fuzzing. In Proceedings of the NDSS 2017, San Diego, CA, USA, 26 February–1 March 2017. [Google Scholar]
- Li, Y.; Ji, S.; Lv, C.; Chen, Y.; Chen, J.; Gu, Q.; Wu, C. V-Fuzz: Vulnerability-Oriented Evolutionary Fuzzing. arXiv 2019, arXiv:1901.01142. [Google Scholar]
- Peng, H.; Shoshitaishvili, Y.; Payer, M. T-Fuzz: Fuzzing by Program Transformation. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 697–710. [Google Scholar]
- Schumilo, S.; Aschermann, C.; Gawlik, R.; Schinzel, S.; Holz, T. kAFL: Hardware-Assisted Feedback Fuzzing for OS Kernels. In Proceedings of the USENIX Security Symposium 2017, Vancouver, BC, Canada, 16–18 August 2017. [Google Scholar]
- Zhang, G.; Zhou, X.; Luo, Y.; Wu, X.; Min, E. PTfuzz: Guided Fuzzing with Processor Trace Feedback. IEEE Access 2018, 6, 37302–37313. [Google Scholar] [CrossRef]
- Lemieux, C.; Sen, K. FairFuzz: A Targeted Mutation Strategy for Increasing Greybox Fuzz Testing Coverage. In Proceedings of the 2018 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE), Montpellier, France, 3–7 September 2018; pp. 475–485. [Google Scholar]
- Lyu, C.; Ji, S.; Zhang, C.; Li, Y.; Lee, W.H.; Song, Y.; Beyah, R.A. MOPT: Optimized Mutation Scheduling for Fuzzers. In Proceedings of the USENIX Security Symposium 2019, Santa Clara, CA, USA, 14–16 August 2019. [Google Scholar]
- You, W.; Wang, X.; Ma, S.; Huang, J.; Zhang, X.; Wang, X.; Liang, B. ProFuzzer: On-the-fly Input Type Probing for Better Zero-Day Vulnerability Discovery. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 769–786. [Google Scholar]
- Pham, V.T.; Böhme, M.; Santosa, A.E.; Caciulescu, A.R.; Roychoudhury, A. Smart Greybox Fuzzing. IEEE Trans. Softw. Eng. 2021, 47, 1980–1997. [Google Scholar] [CrossRef]
- Wang, J.; Chen, B.; Wei, L.; Liu, Y. Superion: Grammar-Aware Greybox Fuzzing. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019; pp. 724–735. [Google Scholar]
- She, D.; Pei, K.; Epstein, D.; Yang, J.; Ray, B.; Jana, S.S. NEUZZ: Efficient Fuzzing with Neural Program Smoothing. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 803–817. [Google Scholar]
- Nagy, S.; Hicks, M. Full-Speed Fuzzing: Reducing Fuzzing Overhead through Coverage-Guided Tracing. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 787–802. [Google Scholar]
- Chen, Y.; Li, P.; Xu, J.; Guo, S.; Zhou, R.; Zhang, Y.; Wei, T.; Lu, L. SAVIOR: Towards Bug-Driven Hybrid Testing. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–21 May 2020; pp. 1580–1596. [Google Scholar]
- Wang, Y.; Jia, X.; Liu, Y.; Zeng, K.; Bao, T.; Wu, D.; Su, P. Not All Coverage Measurements Are Equal: Fuzzing by Coverage Accounting for Input Prioritization. In Proceedings of the NDSS 2020, San Diego, CA, USA, 23–26 February 2020. [Google Scholar]

| ⋯ | |||||
|---|---|---|---|---|---|
| ⋯ | |||||
| ... | |||||
| ⋮ | ⋮ | ⋮ | ⋱ | ⋮ | |
| ⋯ | |||||
| Target | Version | Seed 1 | Seed 2 | Options |
|---|---|---|---|---|
| parse | YAML-CPP-0.60 | empty file | test | @@ |
| nm | Binutils-2.28 | empty file | AFL-test | -C @@ |
| objdump | Binutils-2.28 | AFL-test | test | -d @@ |
| readelf | Binutils-2.28 | AFL-test | test | -a @@ |
| tcpdump | tcpdump-4.9.0 | AFL-test | \ | -e-r @@ |
| tcpdump | tcpdump-4.9.0 | \ | test | -nr @@ |
| Test Case | Fuzzer | Average | Max | Grow |
|---|---|---|---|---|
| empty file | AFL | 196.4 | 231 | |
| SpotFuzz-h | 210.1 | 239 | +6.98% | |
| SpotFuzz-t | 212.2 | 254 | +8.04% | |
| SpotFuzz | 216.5 | 255 | +10.23% | |
| test | AFL | 156.1 | 162 | |
| SpotFuzz-h | 174.5 | 198 | +11.79% | |
| SpotFuzz-t | 174.9 | 205 | +12.04% | |
| SpotFuzz | 191.3 | 229 | +22.55% |
| Program | Test Case | Fuzzer | Average | Max | Grow |
|---|---|---|---|---|---|
| nm | empty file | AFL | 6.5 | 18 | |
| AFLFast | 10.1 | 31 | +55.38% | ||
| SpotFuzz | 10.9 | 29 | +67.69% | ||
| AFL-test | AFL | 2.3 | 12 | ||
| AFLFast | 3.7 | 10 | +60.87% | ||
| SpotFuzz | 3.6 | 10 | +56.52% | ||
| tcpdump | AFL-test | AFL | 19.3 | 22 | |
| SpotFuzz | 20.2 | 22 | +4.66% |
| Program | Test Case | Fuzzer | Average | Max | Grow |
|---|---|---|---|---|---|
| objdump | test | AFL | 2593.7 | 3335 | |
| SpotFuzz | 3092.8 | 4265 | +19.24% | ||
| AFL-test | AFL | 3900.9 | 4798 | ||
| SpotFuzz | 4750.8 | 5383 | +21.79% | ||
| readelf | test | AFL | 1553.8 | 1712 | |
| SpotFuzz | 1727.4 | 1825 | +11.17% | ||
| AFL-test | AFL | 9729.8 | 11,600 | ||
| SpotFuzz | 11,230 | 11,800 | +15.42% | ||
| tcpdump | test | AFL | 5910.4 | 6371 | |
| SpotFuzz | 6124.1 | 6563 | +3.62% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pang, H.; Jian, J.; Zhuang, Y.; Ye, Y.; Li, Z. SpotFuzz: Fuzzing Based on Program Hot-Spots. Electronics 2021, 10, 3142. https://doi.org/10.3390/electronics10243142
Pang H, Jian J, Zhuang Y, Ye Y, Li Z. SpotFuzz: Fuzzing Based on Program Hot-Spots. Electronics. 2021; 10(24):3142. https://doi.org/10.3390/electronics10243142
Chicago/Turabian StylePang, Haibo, Jie Jian, Yan Zhuang, Yingyun Ye, and Zhanbo Li. 2021. "SpotFuzz: Fuzzing Based on Program Hot-Spots" Electronics 10, no. 24: 3142. https://doi.org/10.3390/electronics10243142
APA StylePang, H., Jian, J., Zhuang, Y., Ye, Y., & Li, Z. (2021). SpotFuzz: Fuzzing Based on Program Hot-Spots. Electronics, 10(24), 3142. https://doi.org/10.3390/electronics10243142