
Effects on Co-Presence of a Virtual Human: A Comparison of Display and Interaction Types



Abstract
:1. Introduction
2. Related Works
2.1. Interactive Virtual Human
2.2. Display Types for the Virtual Human
2.3. Interaction Types for the Virtual Human
2.4. Co-Presence for the Virtual Human
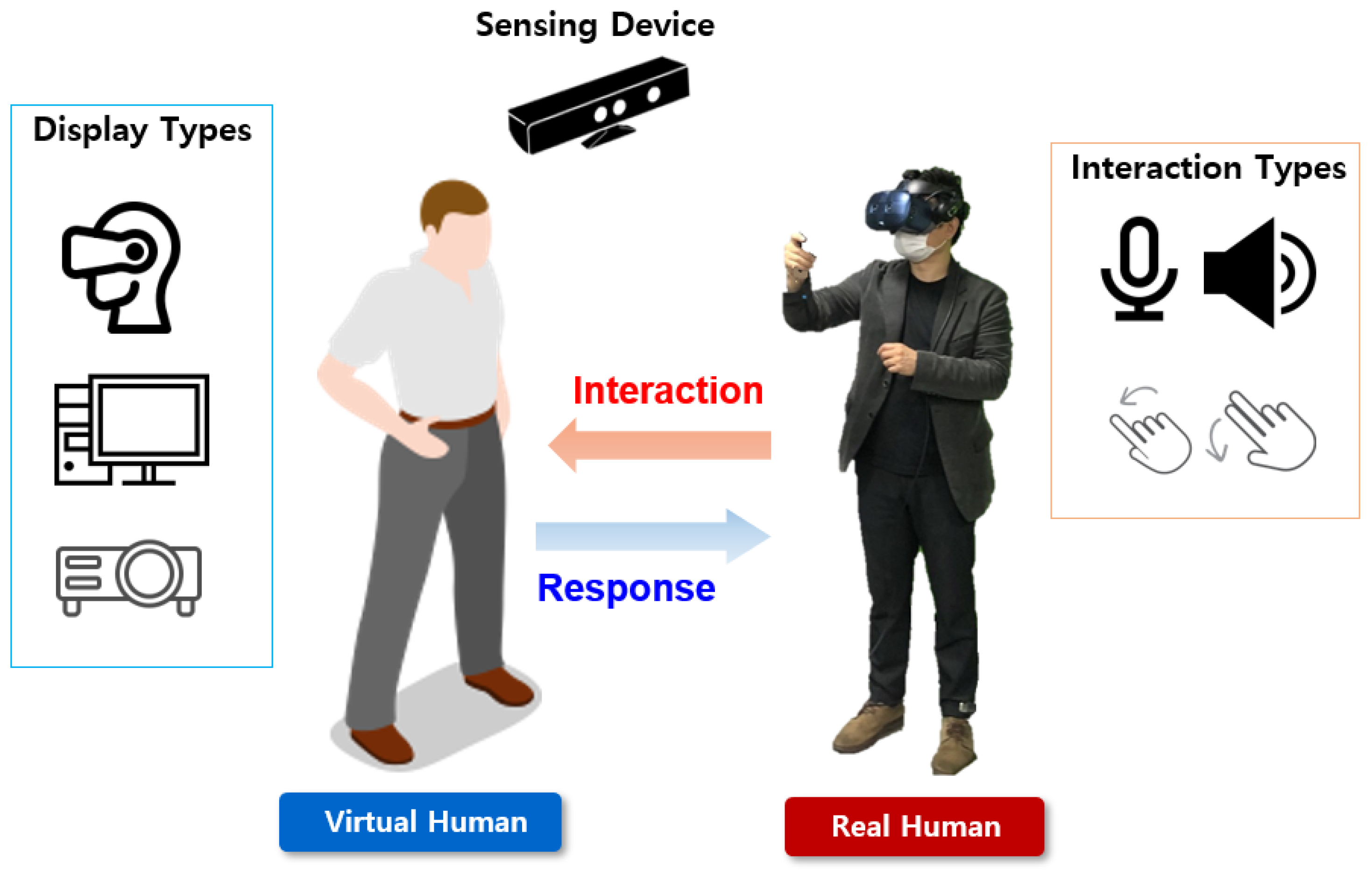
3. System Overview
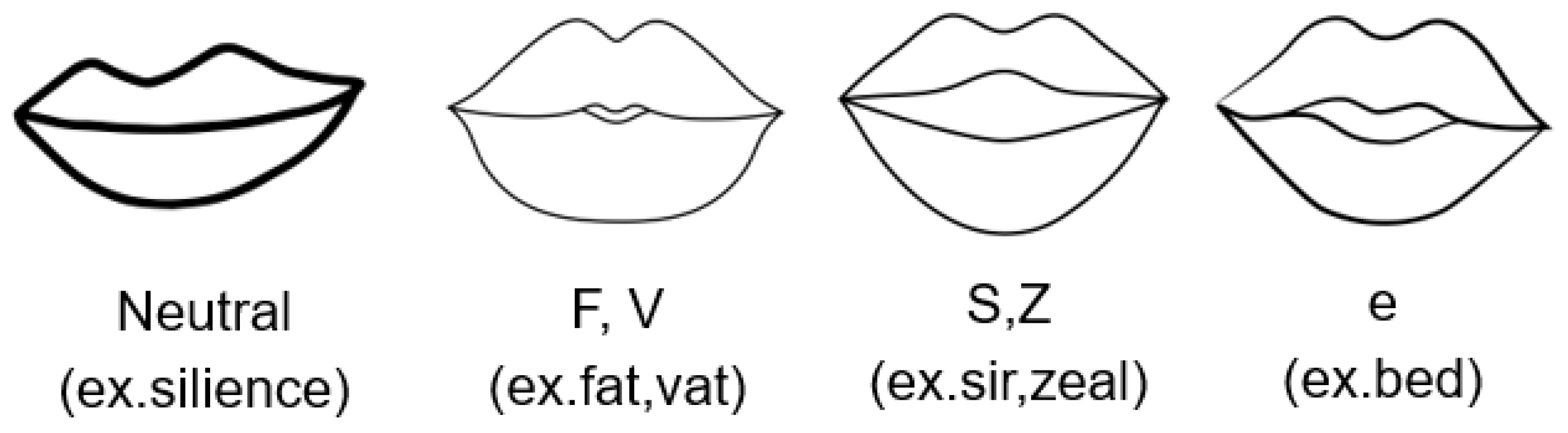
4. Implementation
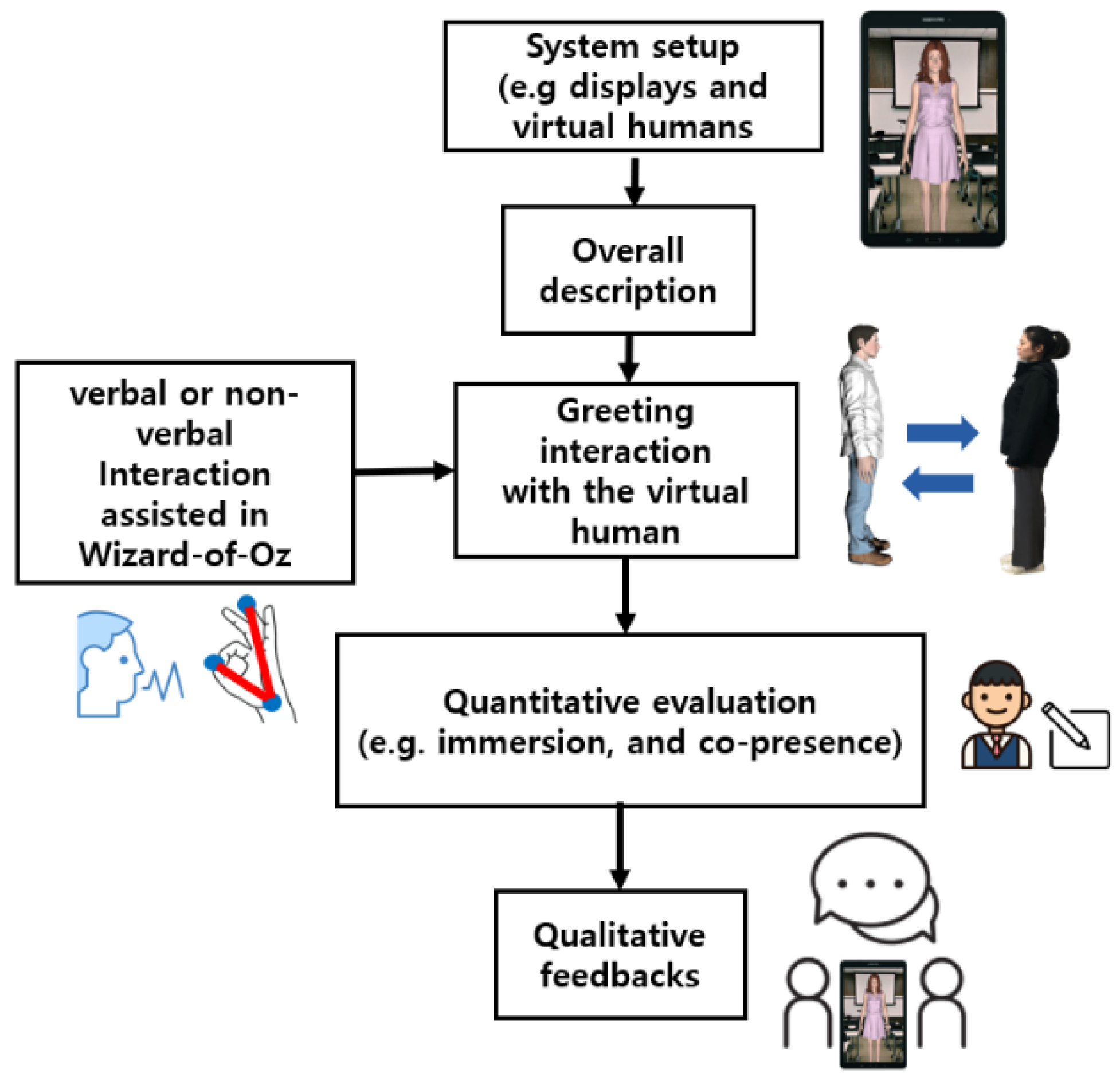
5. Experiment to Determine Effects on Co-Presence
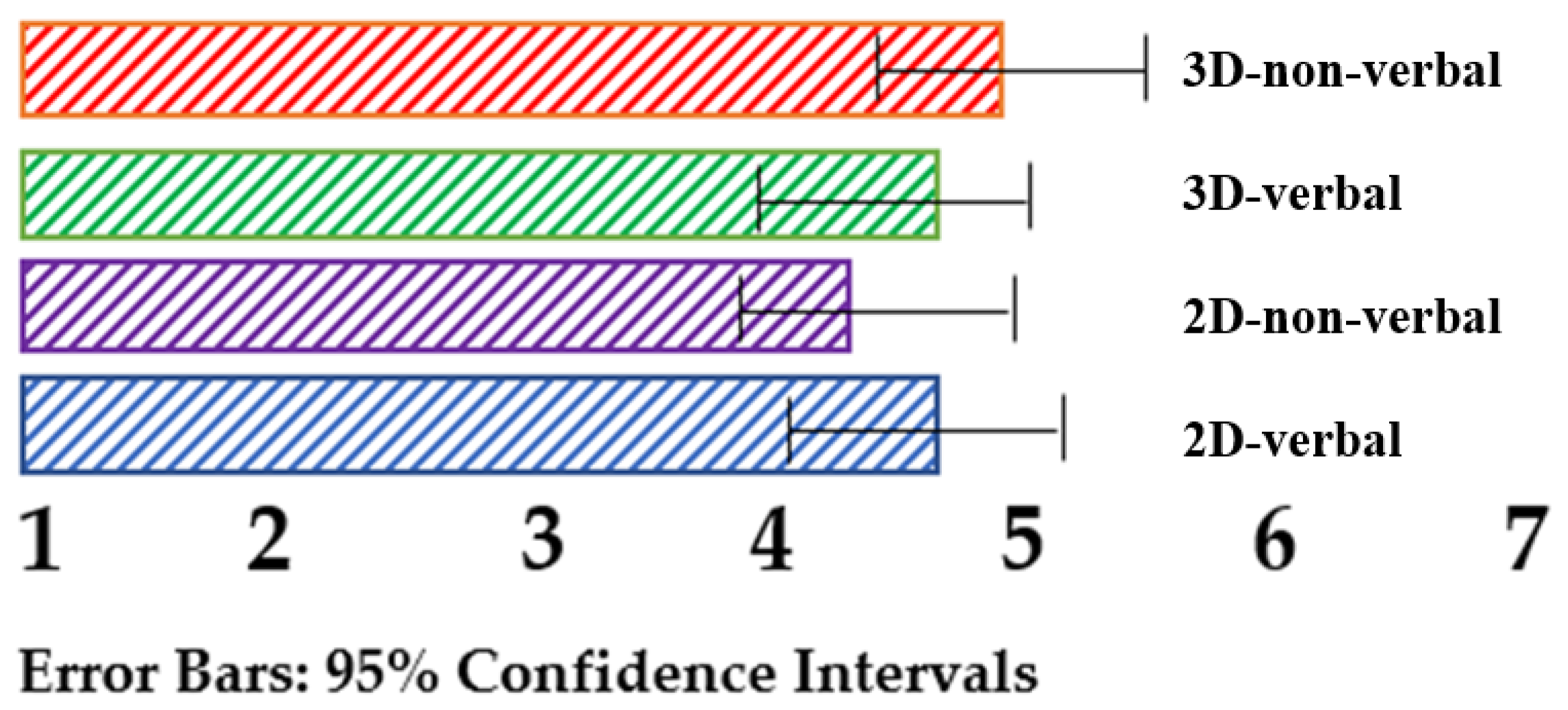
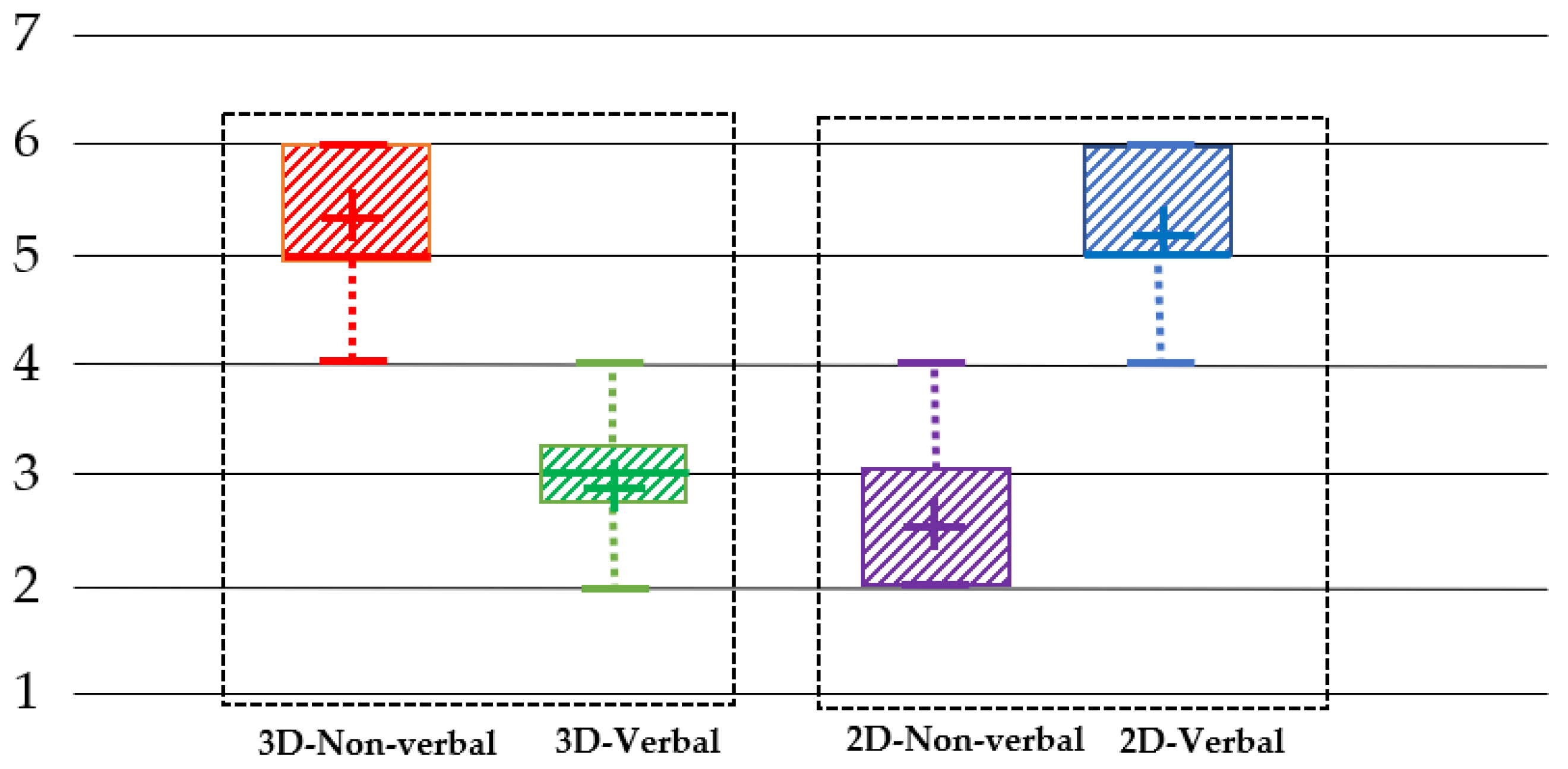
6. Results and Discussion
7. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jo, D.; Kim, K.-H.; Kim, G.J. Spacetime: Adaptive control of the teleported avatar for improved AR tele-conference experience. Comput. Animat. Virtual Worlds 2015, 26, 259–269. [Google Scholar] [CrossRef]
- Xue, H.; Sharma, P.; Wild, F. User satisfaction in augmented reality-based training using Microsoft Hololens. Computers 2019, 8, 9. [Google Scholar] [CrossRef] [Green Version]
- Shin, K.-S.; Kim, H.; Lee, J.; Jo, D. Exploring the effects of scale and color difference on users’ perception for everyday mixed reality (MR) experience: Toward comparative analysis using MR devices. Electronics 2020, 9, 1623. [Google Scholar] [CrossRef]
- Robb, A.; Kopper, R.; Ambani, R.; Qayyum, F.; Lind, D.; Su, L.-M.; Lok, B. Leveraging virtual humans to effectively prepare learners for stressful interpersonal experiences. IEEE Trans. Vis. Comput. Graph. 2013, 19, 662–670. [Google Scholar] [CrossRef] [PubMed]
- Pluss, C.; Ranieri, N.; Bazin, J.-C.; Martin, T.; Laffont, P.-Y.; Popa, T.; Gross, M. An immersive bidirectional system for life-size 3D communication. In Proceedings of the 29th International Conference on Computer Animation and Social Agents, Geneva, Switzerland, 23–25 May 2016. [Google Scholar]
- Susumu, T. Telexistence: Enabling humans to be virtually ubiquitous. IEEE Comput. Graph. Appl. 2016, 36, 8–14. [Google Scholar]
- Kang, S.; Krum, D.; Khooshabeh, P.; Phan, T.; Kevin Chang, C.; Amir, O.; Lin, R. Social Influence of Humor in Virtual Human Counselor’s Self-Disclosure. J. Comput. Animat. Virtual Worlds 2017, 28, e1763. [Google Scholar] [CrossRef]
- Casanueva, J.; Blake, E. The effects of avatars on co-presence in a collaborative virtual environment. In Proceedings of the Annual Conference of the South African Institute of Computer Scientists and Information Technologists, Pretoria, South Africa, 25–28 September 2001. [Google Scholar]
- Beck, S.; Kunert, A.; Kulik, A.; Froehlich, B. Immersive group-to-group telepresence. IEEE Trans. Vis. Comput. Graph. 2013, 19, 616–625. [Google Scholar] [CrossRef] [PubMed]
- Johnson, S.; Orban, D.; Runesha, H.; Meng, L.; Juhnke, B.; Erdman, A.; Samsel, F.; Keefe, D. Bento Box: An Interactive and Zoomable Small Multiples Technique for Visualizing 4D Simulation Ensembles in Virtual Reality. Front. Robot. AI 2019, 6, 61. [Google Scholar] [CrossRef] [Green Version]
- Carraro, M.; Munaro, M.; Menegatti, E. Skeleton estimation and tracking by means of depth camera fusion form depth camera networks. Robot. Auton. Syst. 2018, 110, 151–159. [Google Scholar] [CrossRef] [Green Version]
- Pejsa, T.; Kantor, J.; Benko, H.; Ofek, E.; Wilson, A. Room2Room: Enabling life-size telepresence in a projected augmented reality environment. In Proceedings of the 19th ACM Conference on Computer-Supported Cooperative Work and Social Computing, San Francisco, CA, USA, 27 February–2 March 2016. [Google Scholar]
- Volante, M.; Babu, S.-V.; Chaturvedi, H.; Newsome, N.; Ebrahimi, E.; Roy, T.; Daily, S.-B.; Fasolino, T. Effects of virtual human appearance fidelity on emotion contagion in affective inter-personal simulations. IEEE Trans. Vis. Comput. Graph. 2016, 22, 1326–1335. [Google Scholar] [CrossRef]
- Maimone, A.; Fuchs, H. A First Look at a Telepresence System with Room-Sized Real-Time 3D Capture and Large Tracked Display Wall. In Proceedings of the 21st International Conference on Artificial Reality and Telexistence (ICAT), Osaka, Japan, 28–30 November 2011. [Google Scholar]
- Kwon, J.-H.; Powell, J.; Chalmers, A. How level of realism influences anxiety in virtual reality environments for a job interview. Int. J. Hum.-Comput. Stud. 2013, 71, 978–987. [Google Scholar] [CrossRef]
- Robb, A.; Cordar, A.; Lampotang, S.; White, C.; Wendling, A.; Lok, B. Teaming up with virtual humans: How other people change our perceptions of and behavior with virtual teammates. IEEE Trans. Vis. Comput. Graph. 2015, 21, 511–519. [Google Scholar] [CrossRef] [PubMed]
- Duguleana, M.; Briciu, V.-A.; Duduman, I.-A.; Machidon, O. A virtual assistant for natural interactions in museums. Sustainability 2020, 12, 6958. [Google Scholar] [CrossRef]
- Yoon, L.; Yang, D.; Chung, C.; Lee, S.-H. A mixed reality telepresence system for dissimilar spaces using full-body avatar. In Proceedings of the SIGGRAPH ASIA XR, Online, 10–13 December 2020. [Google Scholar]
- Kim, D.; Jo, D. Exploring the effects of gesture interaction on co-presence of a virtual human in a hologram-like system. J. Korea Inst. Inf. Commun. Eng. 2020, 24, 1390–1393. [Google Scholar]
- Maimone, A.; Yang, X.; Dierk, N.; State, A.; Dou, M.; Fuchs, H. General-purpose telepresence with head-worn optical see-through displays and projector-based lighting. In Proceedings of the IEEE Virtual Reality, Orlando, FL, USA, 16–20 March 2013. [Google Scholar]
- Jones, A.; Lang, M.; Fyffe, G.; Yu, X.; Busch, J.; Mcdowall, I.; Debevec, P. Achieving eye contact in a one-to-many 3D video teleconferencing system. ACM Trans. Graph. 2009, 28, 64. [Google Scholar] [CrossRef]
- Orts, S.; Rhemann, C.; Fanello, S.; Kim, D. Holoportation: Virtual 3D teleportation in real-time. In Proceedings of the 29th ACM User Interface Software and Technology Symposium (UIST), Tokyo, Japan, 16–19 October 2016. [Google Scholar]
- Shin, K.-S.; Kim, H.; Jo, D. Exploring the effects of the virtual human and physicality on co-presence and emotional response. J. Korea Soc. Comput. Inf. 2019, 24, 67–71. [Google Scholar]
- Gao, H.; Xu, F.; Liu, J.; Dai, Z.; Zhou, W.; Li, S.; Yu, Y. Holographic three-dimensional virtual reality and augmented reality display based on 4K-spatial light modulators. Appl. Sci. 2019, 9, 1182. [Google Scholar] [CrossRef] [Green Version]
- Kim, K.; Schubert, R.; Hochreiter, J.; Bruder, G.; Welch, G. Blowing in the wind: Increasing social presence with a virtual human via environmental airflow interaction in mixed reality. Elsevier Comput. Graph. (CAG) 2019, 83, 23–32. [Google Scholar] [CrossRef]
- Wang, I.; Ruiz, J. Examining the use of nonverbal communication in virtual agents. Int. J. Hum.-Comput. Interact. 2021, 37, 1–26. [Google Scholar] [CrossRef]
- Zhao, Y. Research on virtual human animation based on motion capture data. In Proceedings of the International Conference on Data Processing Techniques and Applications for Cyber-Physical Systems, Guangxi, China, 11–12 December 2020. [Google Scholar]
- Mathis, A.; Schneider, S.; Lauer, J.; Mathis, M. A primer on motion capture with deep learning principles, pitfalls, and perspectives. Neuron 2020, 108, 44–65. [Google Scholar] [CrossRef]
- Chentanez, N.; Muller, M.; Macklin, M.; Makoviychuk, V.; Jeschke, S. Physics-based motion capture imitation with deep reinforcement learning. In Proceedings of the 13th Annual ACM SIGGRAPH Conference on Motion, Interaction and Games (MIG), Limassol, Cyprus, 8–10 November 2018. [Google Scholar]
- Mathis, F.; Vaniea, K.; Khamis, M. Observing virtual avatars: The impact of avatars’ fidelity on identifying interactions. In Proceedings of the Mindtrek 2021, Tampere, Finland, 1–3 June 2021; pp. 154–164. [Google Scholar]
- Slater, M.; Pertaub, D.; Steed, A. Public speaking in virtual reality: Facing an audience of avatars. IEEE Comput. Graph. Appl. 1999, 19, 6–9. [Google Scholar] [CrossRef] [Green Version]
- Zanbaka, C.; Ulinski, A.; Goolkasian, P.; Hodges, L.F. Effects of virtual human presence on task performance. In Proceedings of the 14th International Conference on Artificial Reality and Telexistence (ICAT), Seoul, Korea, 30 November 2004. [Google Scholar]
- Jo, D.; Kim, K.-H.; Kim, G.J. Effects of avatar and background types on users’ co-presence and trust for mixed reality-based teleconference systems. In Proceedings of the 30th Conference on Computer Animation and Social Agents (CASA), Seoul, Korea, 22–24 May 2017. [Google Scholar]
- Slater, M. Measuring presence: A response to the Witmer and Singer presence questionnaire. Presence Teleoperators Virtual Environ. 1999, 8, 560–565. [Google Scholar] [CrossRef]
- Witmer, B.G.; Singer, M.J. Measuring presence in virtual environments: A presence questionnaire. Presence Teleoperators Virtual Environ. 1998, 7, 225–240. [Google Scholar] [CrossRef]
- Meehan, M.; Razzaque, S.; Whitton, M.-C.; Brooks, F. Effect of latency on presence in stressful virtual environments. In Proceedings of the IEEE Virtual Reality, Los Angeles, CA, USA, 18–22 March 2003. [Google Scholar]
- Banos, R.; Botella, C.; Quero, S.; Garcia-Palacious, A.; Alcaniz, M. Presence and emotions in virtual environments: The influence of stereoscopy. Cyberpsychol. Behav. 2008, 11, 1–8. [Google Scholar] [CrossRef]
- Chung, J.-H.; Jo, D. Authoring toolkit for interaction with a virtual human. In Proceedings of the Korea Information Processing Society Conference, Yeosu, Korea, 4–6 November 2021. [Google Scholar]
- Latoschik, M.; Roth, D.; Gall, D.; Achenbach, J.; Waltemate, T.; Botsch, M. The effects of avatar realism in immersive social virtual realities. In Proceedings of the 23rd ACM Symposium on Virtual Reality Software and Technology 2017, Gothenburg, Sweden, 8–10 November 2017. [Google Scholar]
- Diederick, C.; Li, L.; Lappe, M. The accuracy and precision of position and orientation tracking in the HTC Vive virtual reality system for scientific research. I-Perception 2017, 8, 1–23. [Google Scholar]
- Yumak, Z.; Brink, B.; Egges, A. Autonomous Social Gaze Model for an Interactive Virtual Character in Real-Life Settings. Comput. Animat. Virtual Worlds 2017, 28, e1757. [Google Scholar] [CrossRef] [Green Version]
- Charalambous, C.; Yumak, Z.; Stappen, A. Audio-driven emotional speech animation for interactive virtual characters. Comput. Animat. Virtual Worlds 2019, 30, e1892. [Google Scholar] [CrossRef] [Green Version]
- Bajpai, A.; Kushwah, V. Importance of fuzzy logic and application areas in engineering research. Int. J. Recent Technol. Eng. 2019, 7, 1467–1471. [Google Scholar]
- Ma, C.; Zhang, S.; Wang, A.; Qi, Y.; Chen, G. Skeleton-based dynamic hand gesture recognition using an enhanced network with one-shot learning. Appl. Sci. 2020, 10, 3680. [Google Scholar] [CrossRef]
- Shin, E.; Jo, D. Mixed reality classroom based on multi-camera videos. In Proceedings of the Korea Institute of Information and Communication Engineering, Online, Korea, 30 October 2020; pp. 397–399. [Google Scholar]
- Smith, M.; Ginger, E.; Wright, K.; Wright, M.; Taylor, J.; Humm, L.; Olsen, D.; Bell, M.; Fleming, M. Virtual reality job interview training in adults with autism spectrum disorder. J. Autism Dev. Disord. 2014, 44, 2450–2463. [Google Scholar] [CrossRef] [Green Version]
- Suarez, G.; Jung, S.; Lindeman, R. Evaluating virtual human role-players for the practice and development of leadership skills. Front. Virtual Real. 2021, 2, 658561. [Google Scholar] [CrossRef]
- Cortes, C.; Argelaguet, F.; Marchand, E.; Lecuyer, A. Virtual shadows for real human in a CAVE: Influence on virtual embodiment and 3D interaction. In Proceedings of the 15th ACM Symposium on Applied Perception 2018, Vancouver, BC, Canada, 10–11 August 2018; pp. 1–8. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Conditions | Methods | Characteristics |
|---|---|---|
| Display Types | Head-mounted display | 3D |
| Life-size supported TV | 2D | |
| Multi-projection | 3D | |
| Holographic Image | 3D | |
| Interaction Types | Voice for Conversation | Verbal |
| Gesture | Non-verbal | |
| Facial Expression | Non-verbal |
| Test Conditions | Display Types | Interaction Types |
|---|---|---|
| 3D–verbal | Head-mounted display (3D) | Voice for Conversation (Verbal) |
| 2D–verbal | Life-size supported TV (2D) | Voice for Conversation (Verbal) |
| 3D–non-verbal | Head-mounted display (3D) | Gesture (Non-verbal) |
| 2D–non-verbal | Life-size supported TV (2D) | Gesture (Non-verbal) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, D.; Jo, D. Effects on Co-Presence of a Virtual Human: A Comparison of Display and Interaction Types. Electronics 2022, 11, 367. https://doi.org/10.3390/electronics11030367
Kim D, Jo D. Effects on Co-Presence of a Virtual Human: A Comparison of Display and Interaction Types. Electronics. 2022; 11(3):367. https://doi.org/10.3390/electronics11030367
Chicago/Turabian StyleKim, Daehwan, and Dongsik Jo. 2022. "Effects on Co-Presence of a Virtual Human: A Comparison of Display and Interaction Types" Electronics 11, no. 3: 367. https://doi.org/10.3390/electronics11030367
APA StyleKim, D., & Jo, D. (2022). Effects on Co-Presence of a Virtual Human: A Comparison of Display and Interaction Types. Electronics, 11(3), 367. https://doi.org/10.3390/electronics11030367