
SCNN-Attack: A Side-Channel Attack to Identify YouTube Videos in a VPN and Non-VPN Network Traffic

 ,
,  , , , and
, , , and 
Abstract
:1. Introduction
- A side-channel attack that uses a Sequential Convolutional Neural Network is proposed to identify videos in a VPN and non-VPN network traffic.
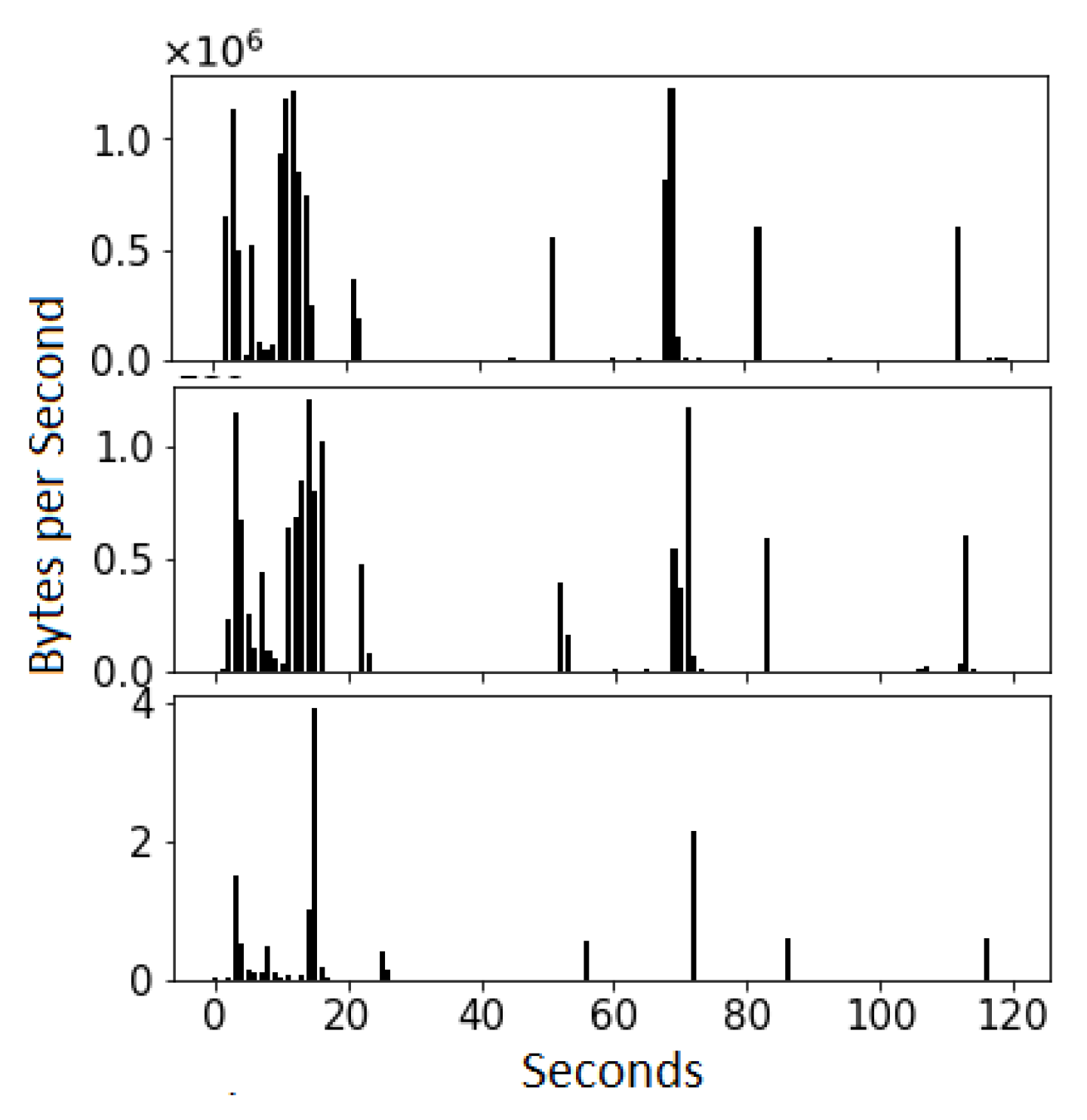
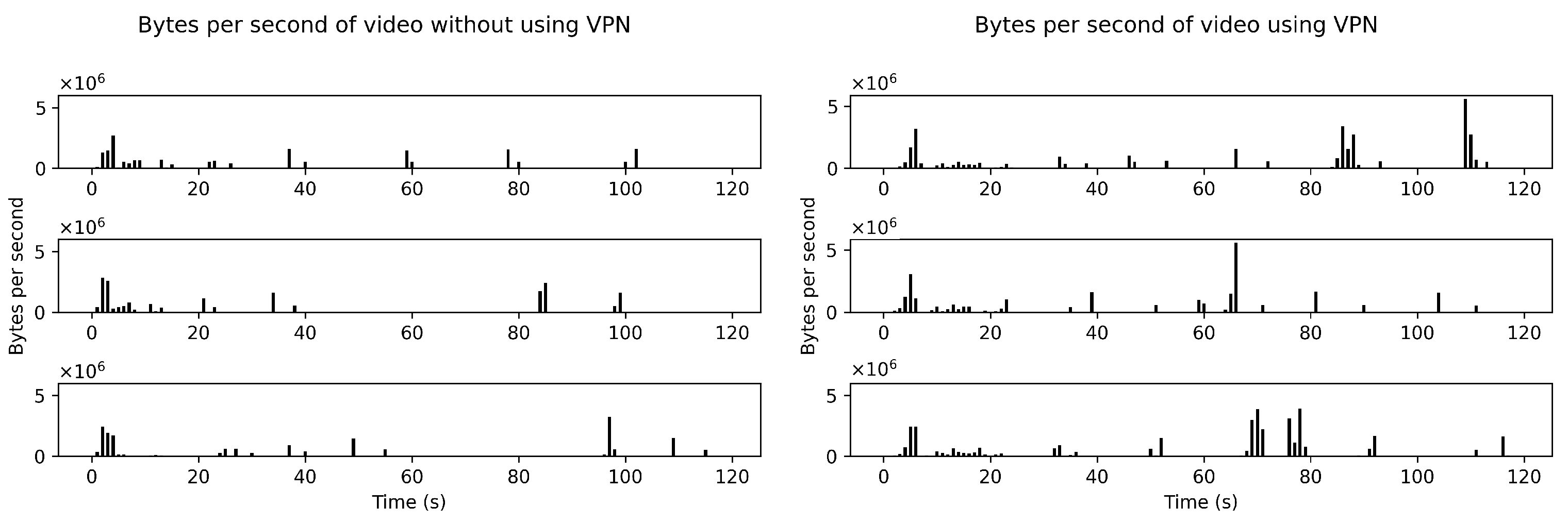
- A sequence of bytes per second (BPS) from two-minute video traffic is shown as a feature to identify the video.
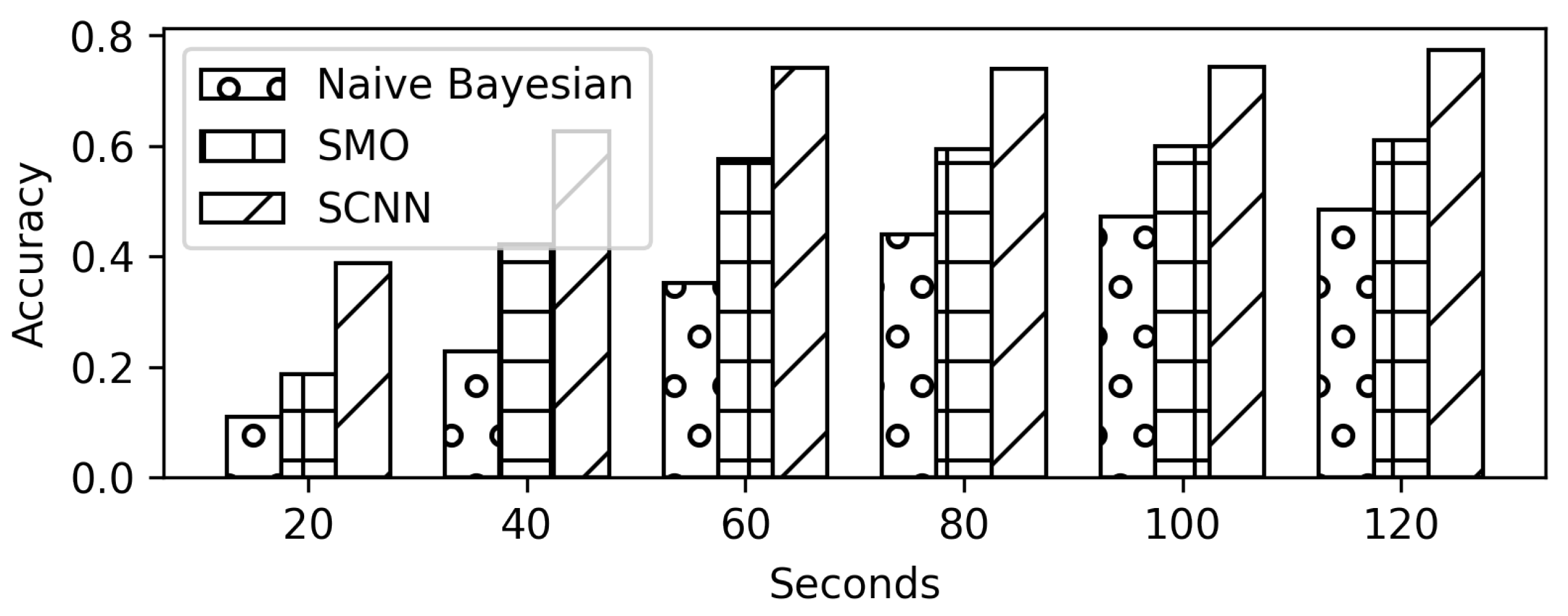
- The paper demonstrates that even one-minute sniffing of network traffic can help in predicting the YouTube videos with high accuracy.
2. Background
2.1. DASH Video Streaming
2.2. Virtual Private Networks (VPNs)
3. Related Works
4. Methodology
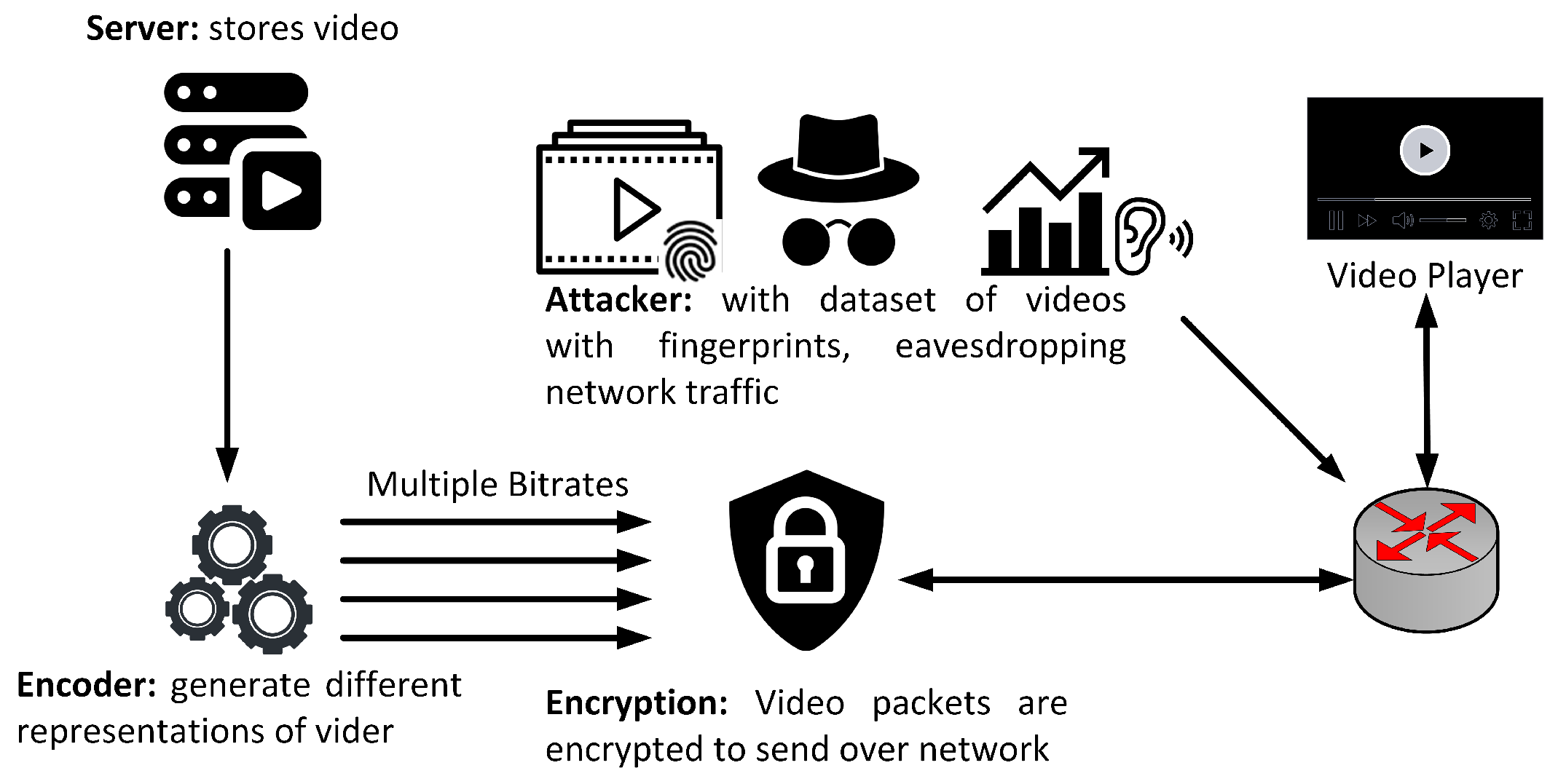
4.1. Threat Model
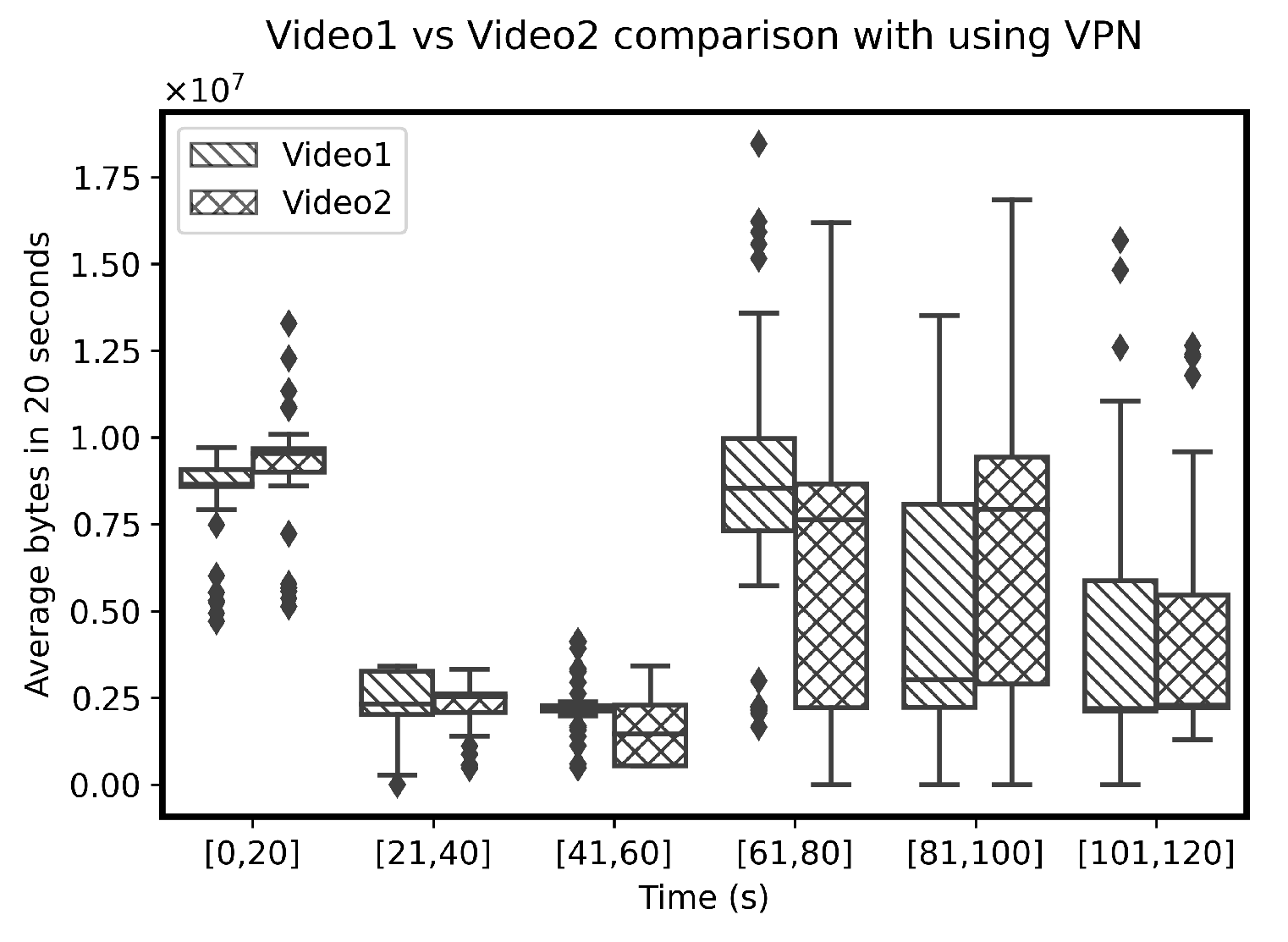
4.2. Feature Extraction
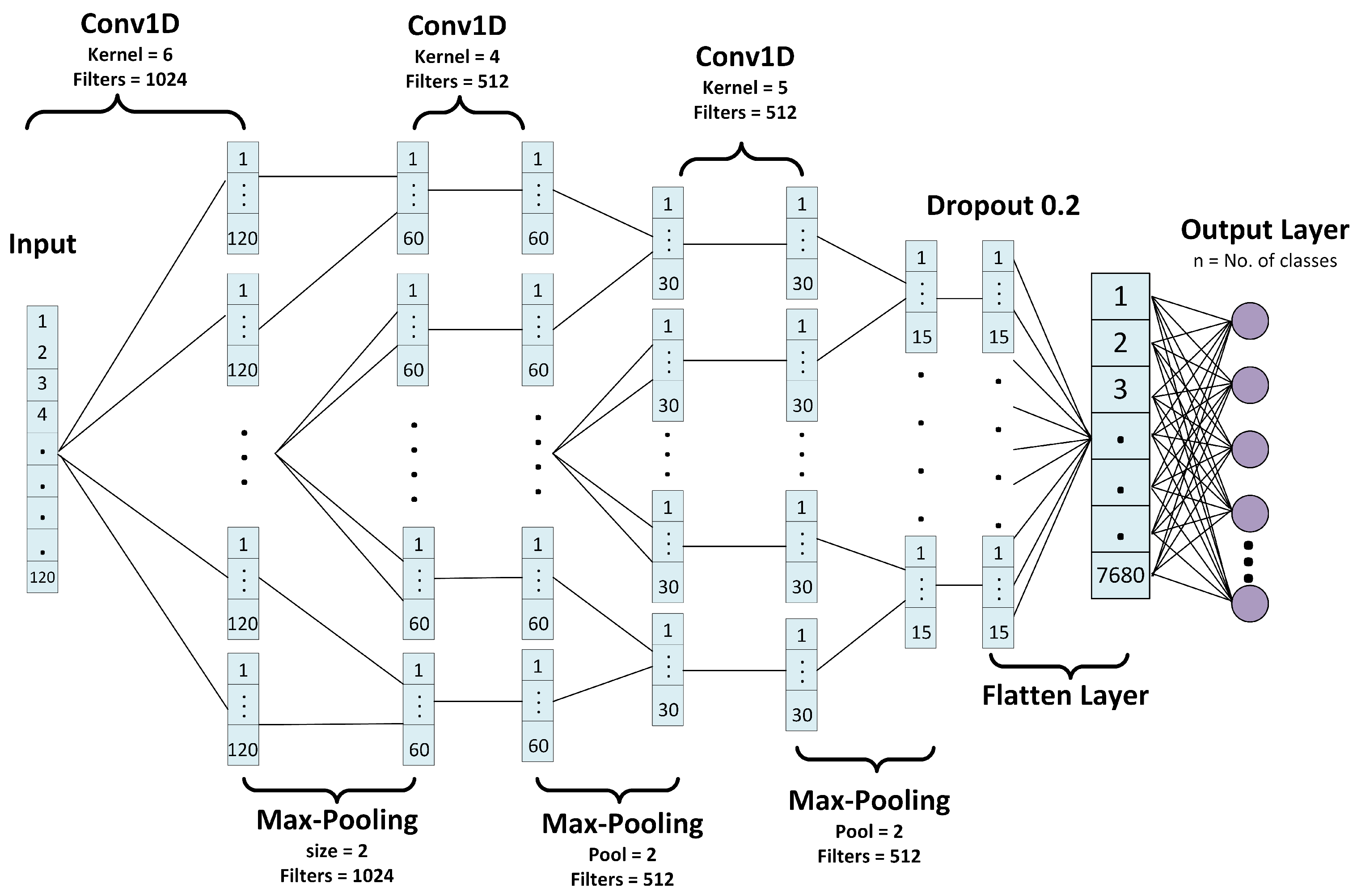
4.3. CNN Model
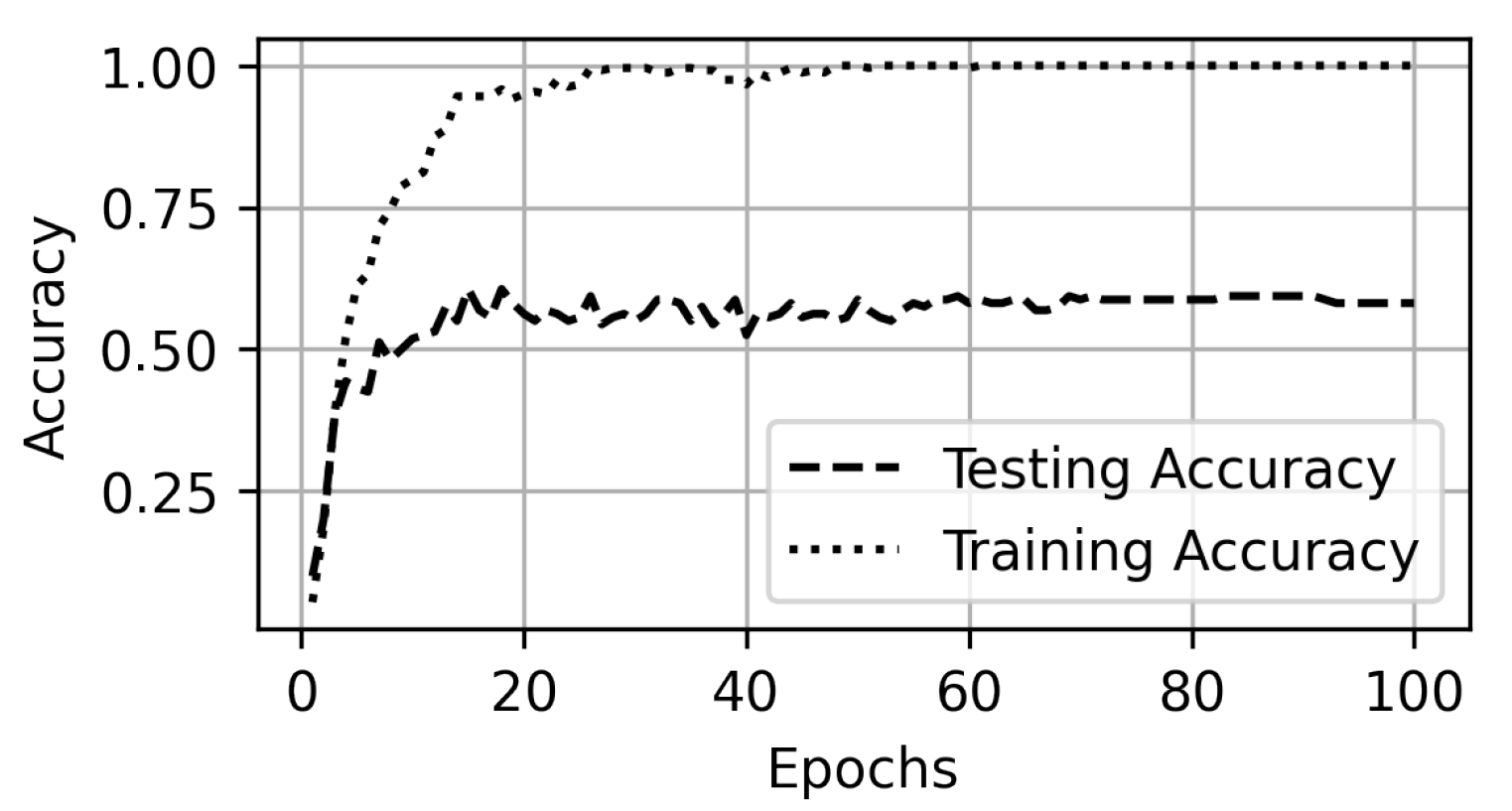
4.4. Dataset and Performance Evaluation
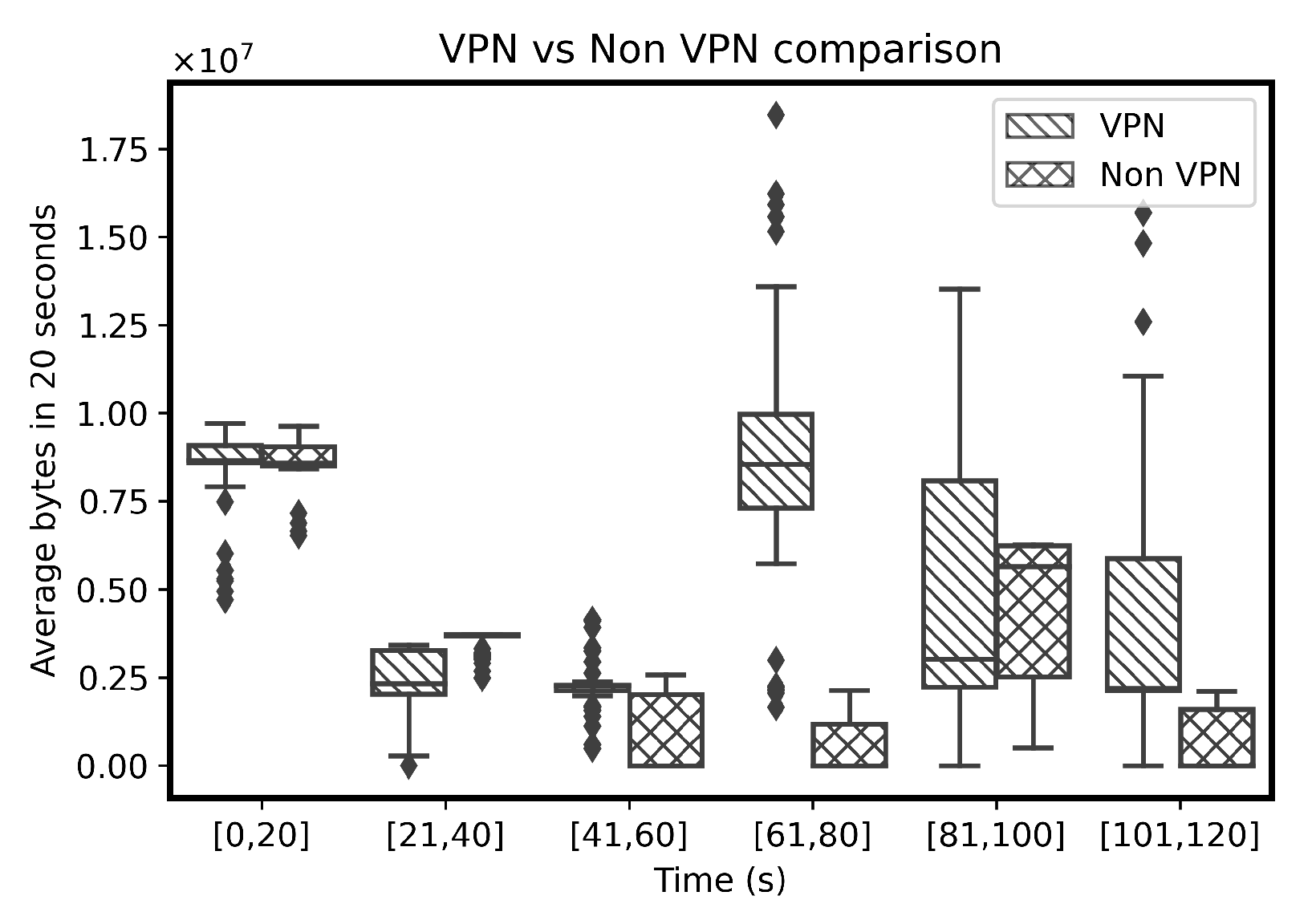
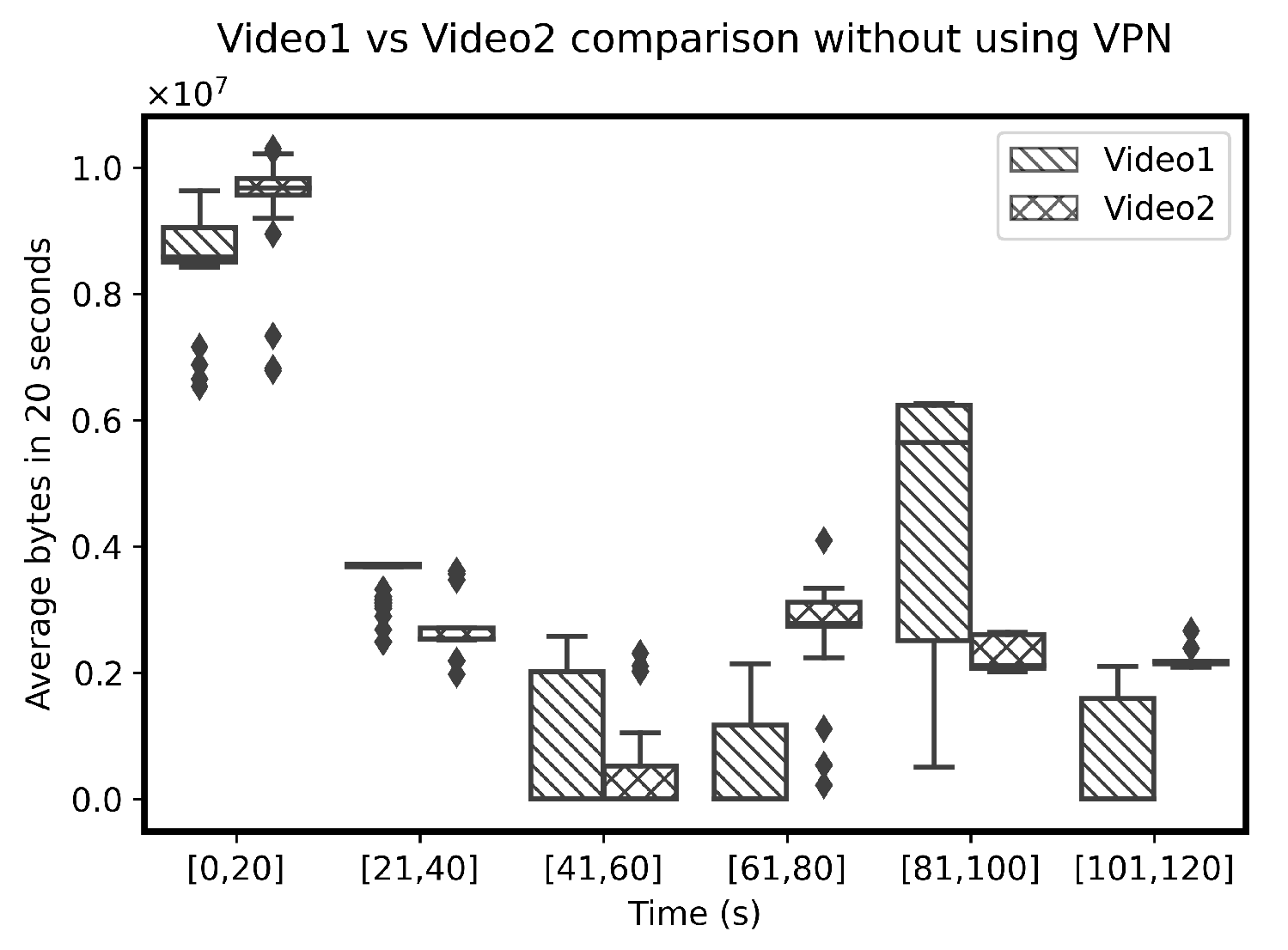
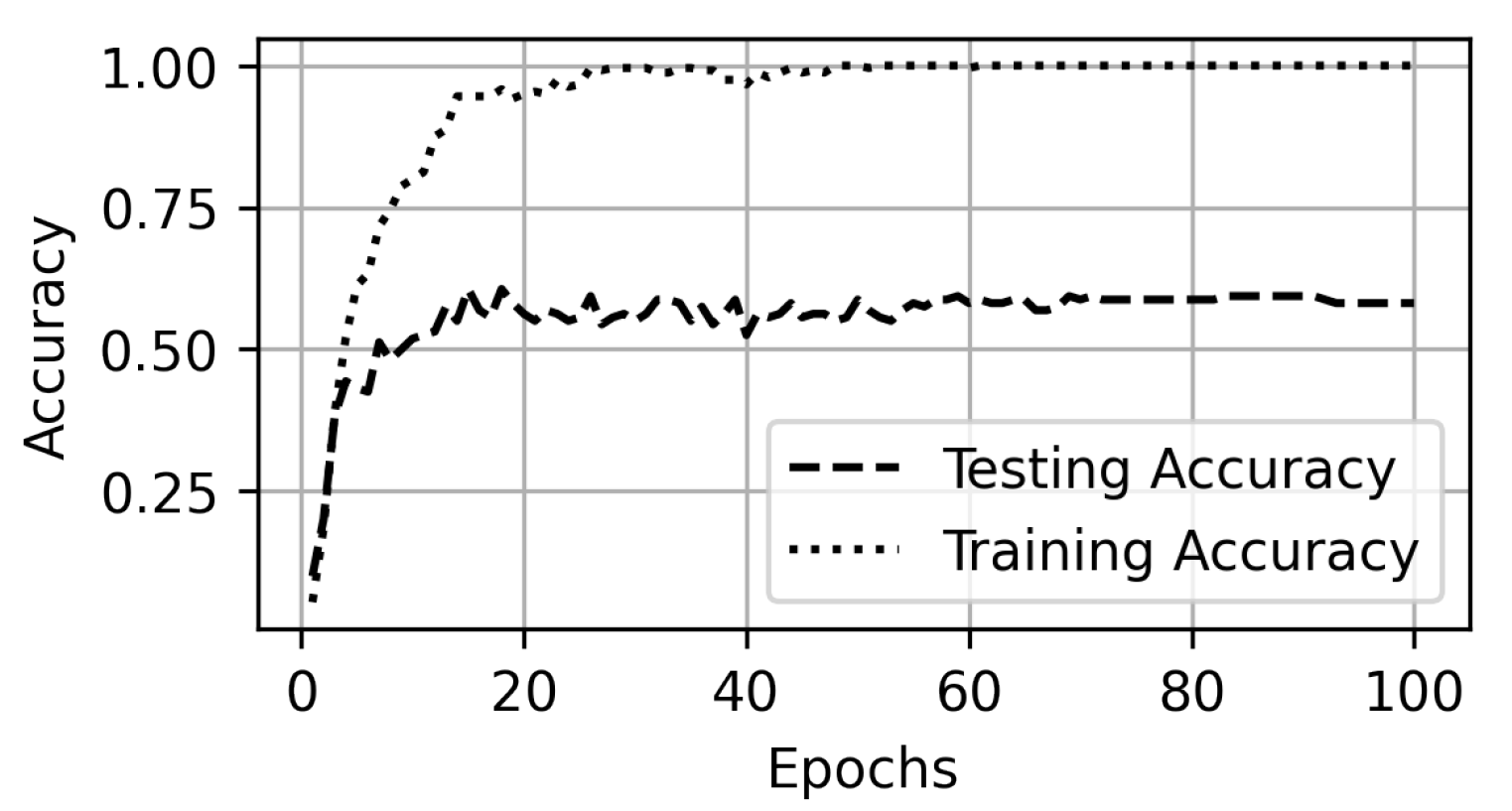
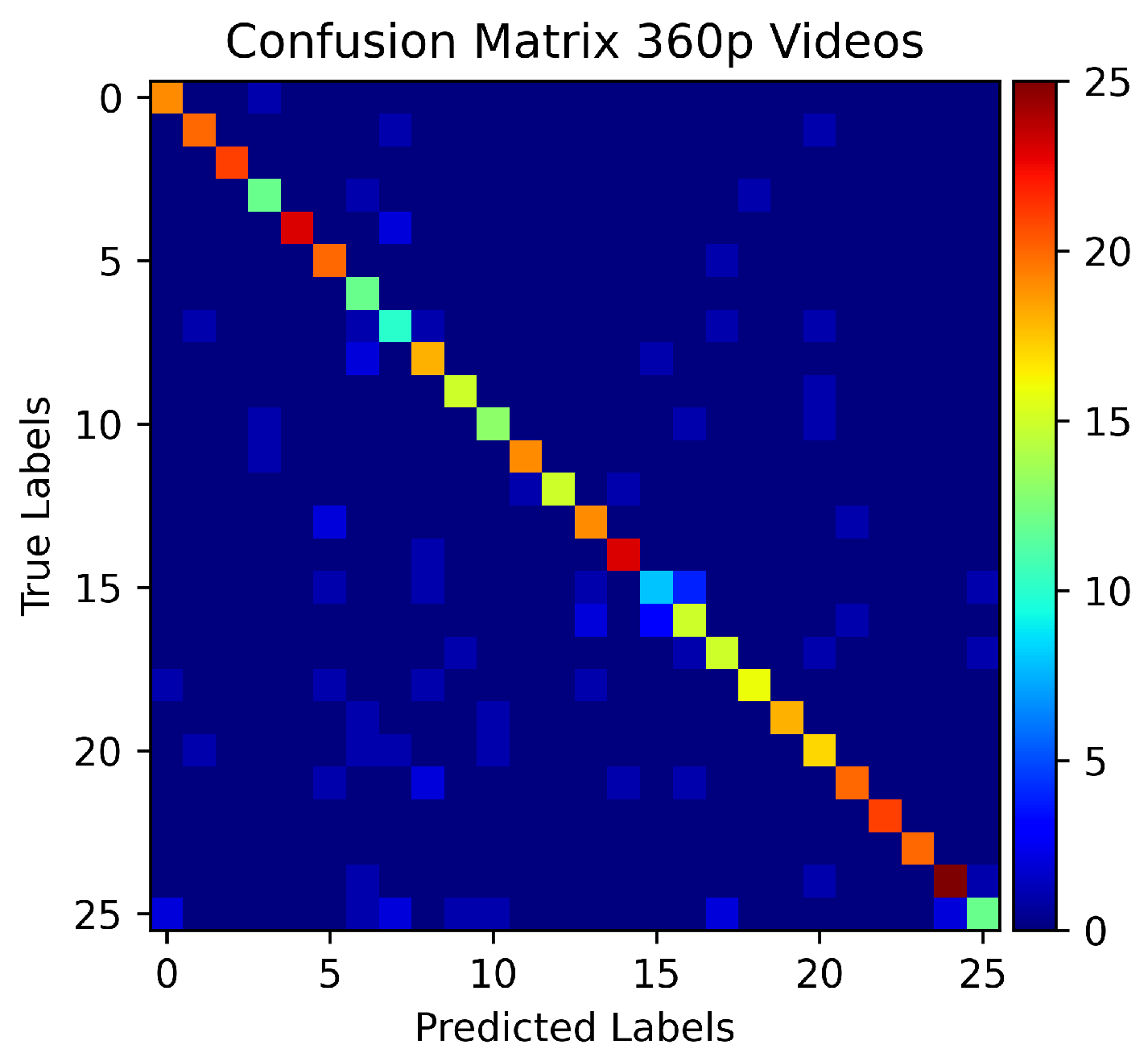
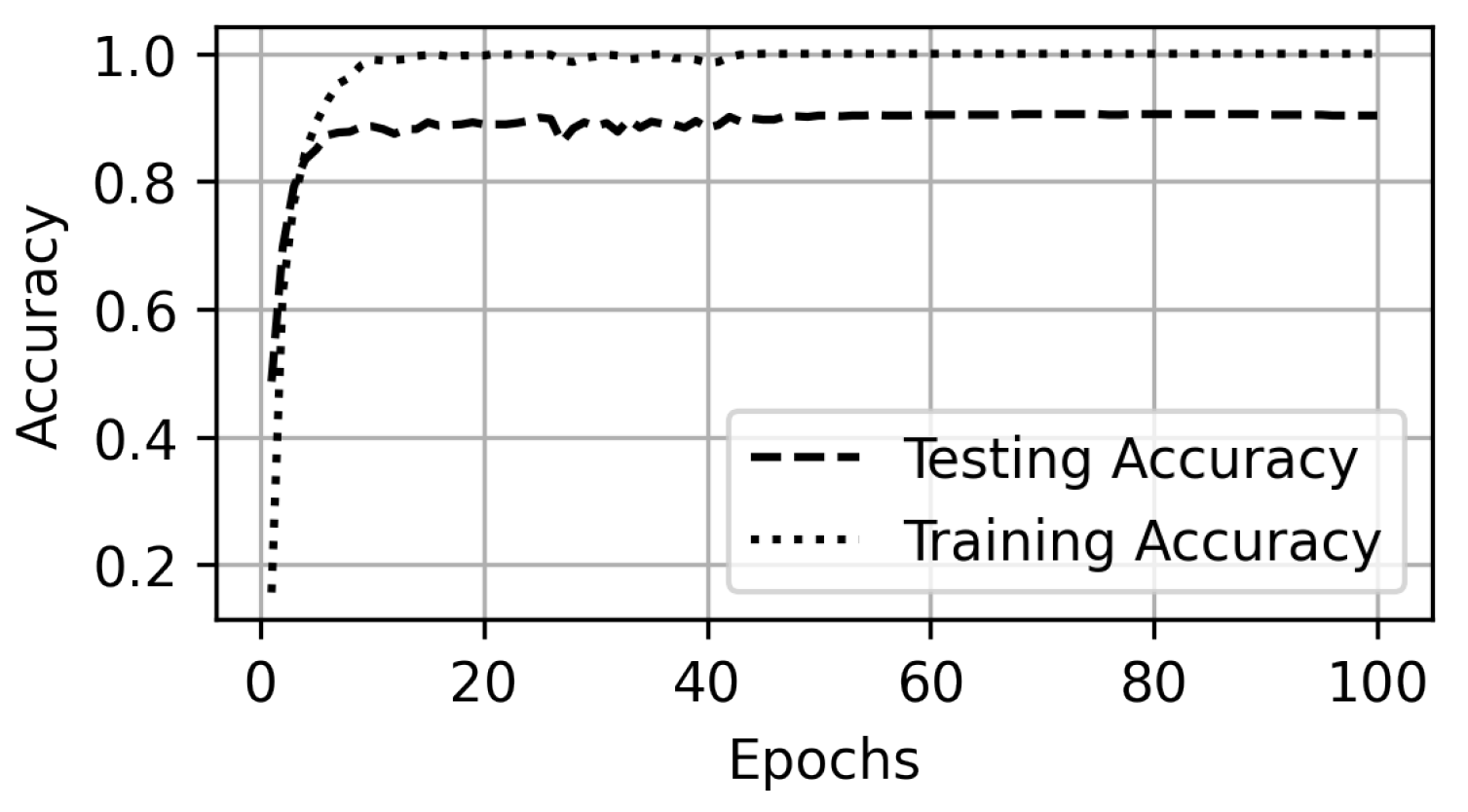
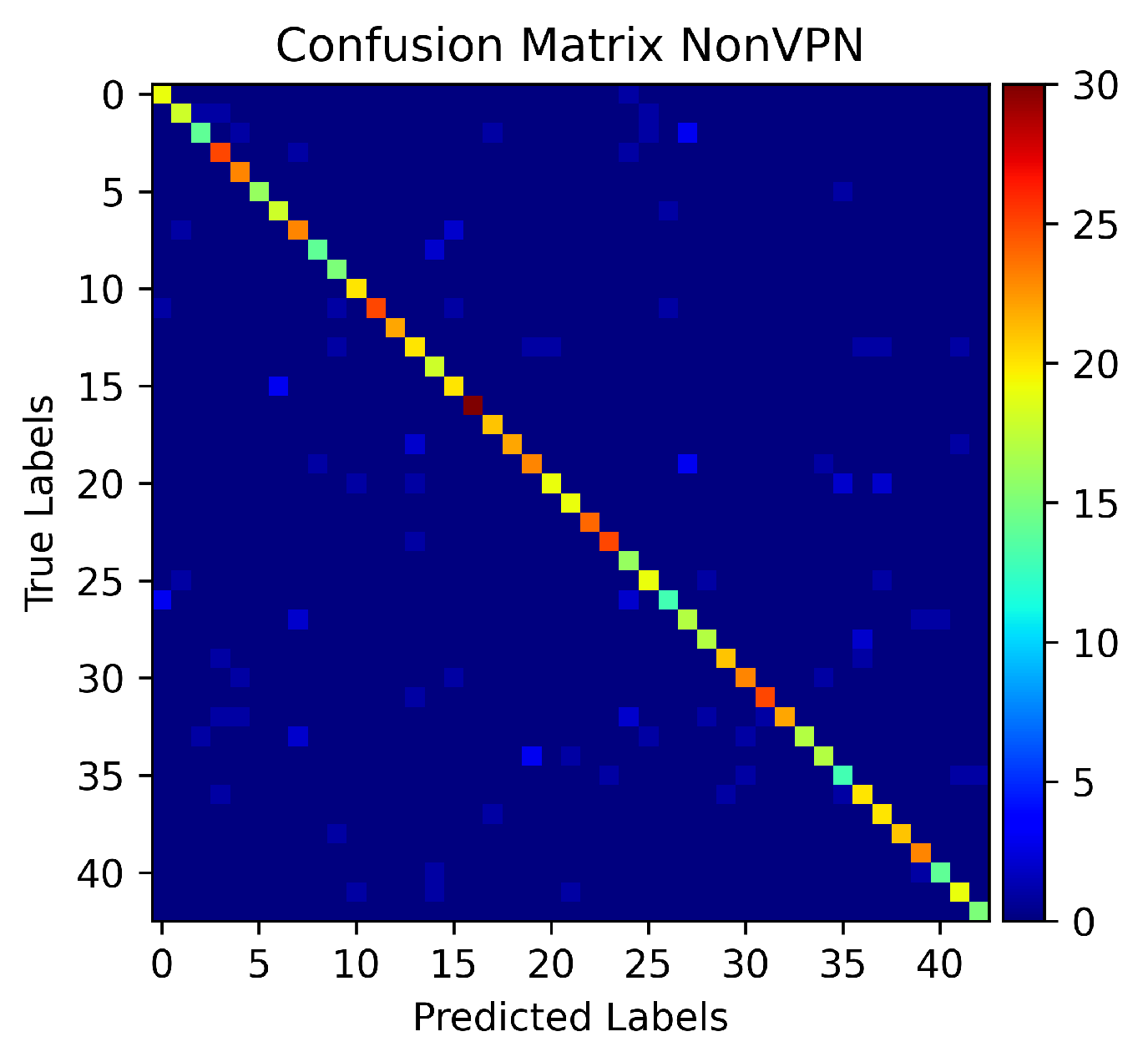
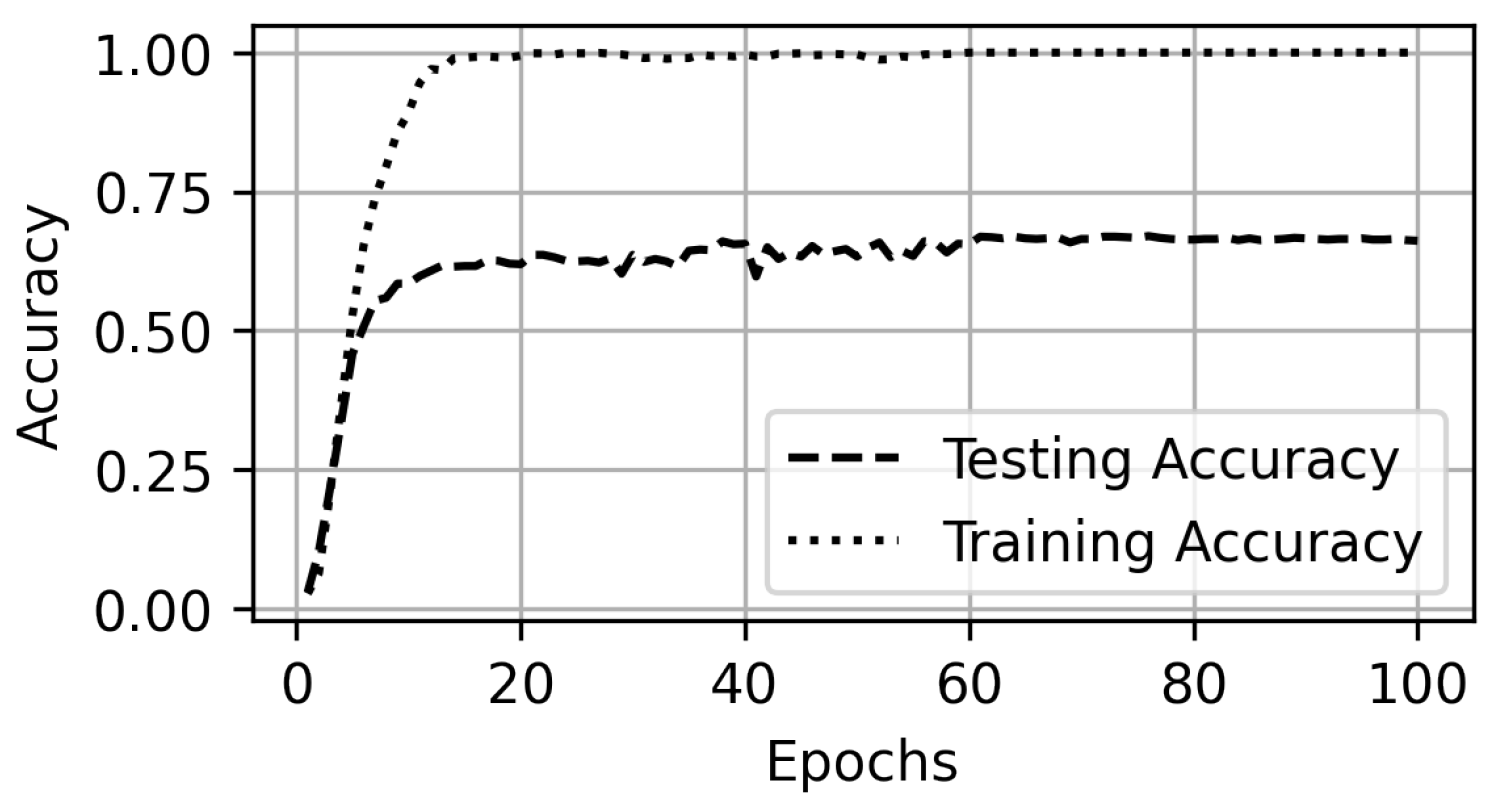
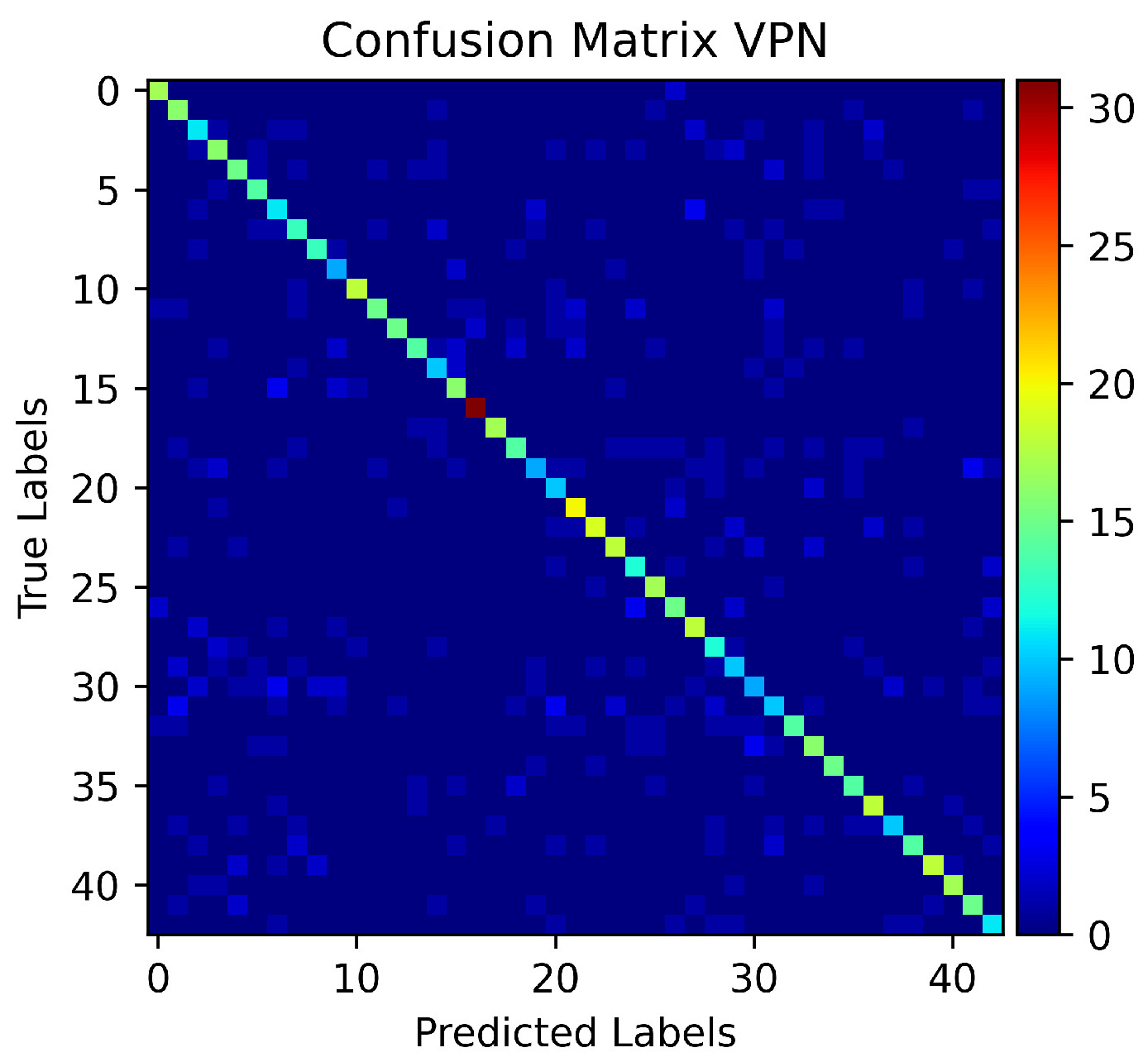
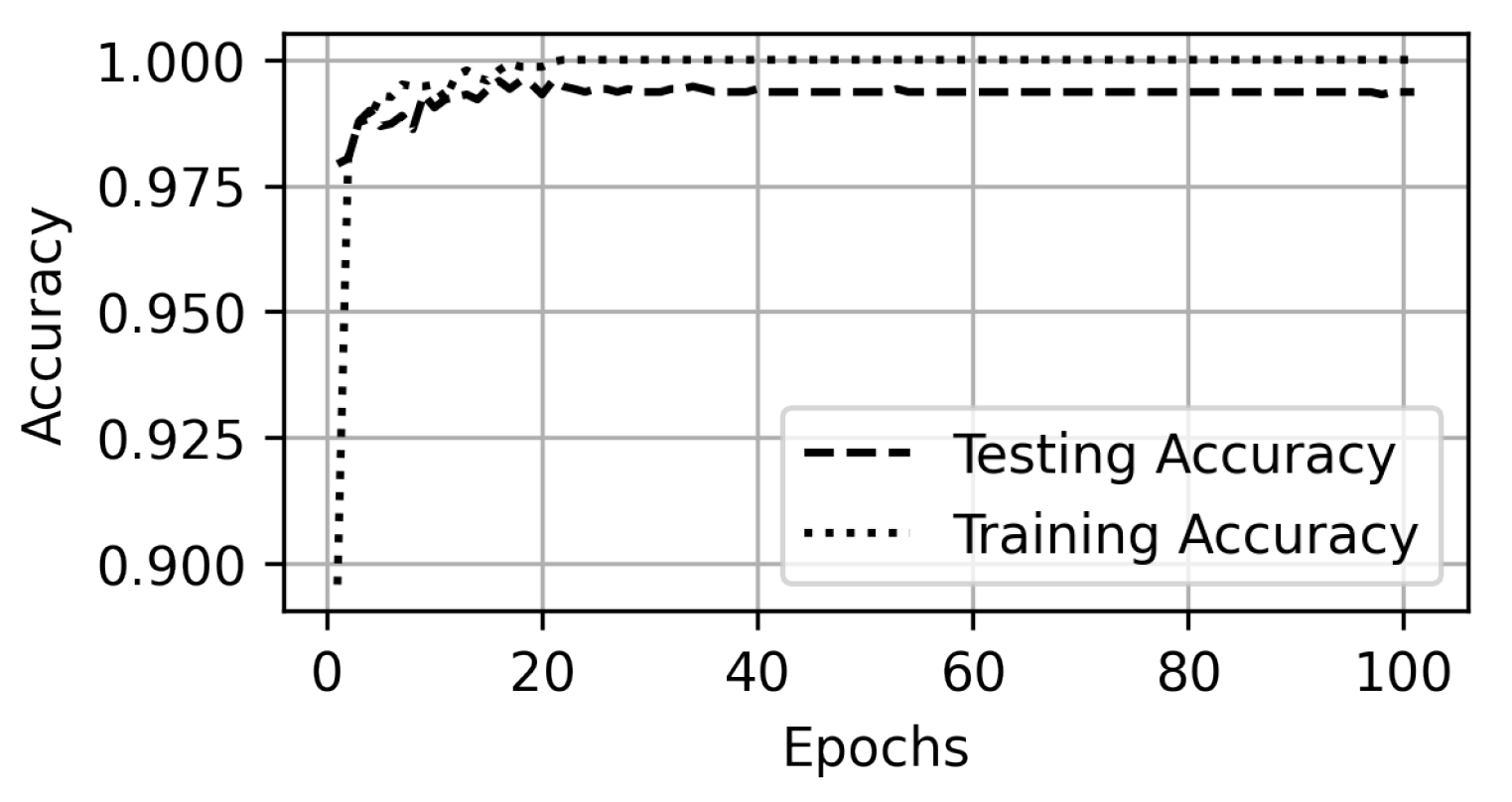
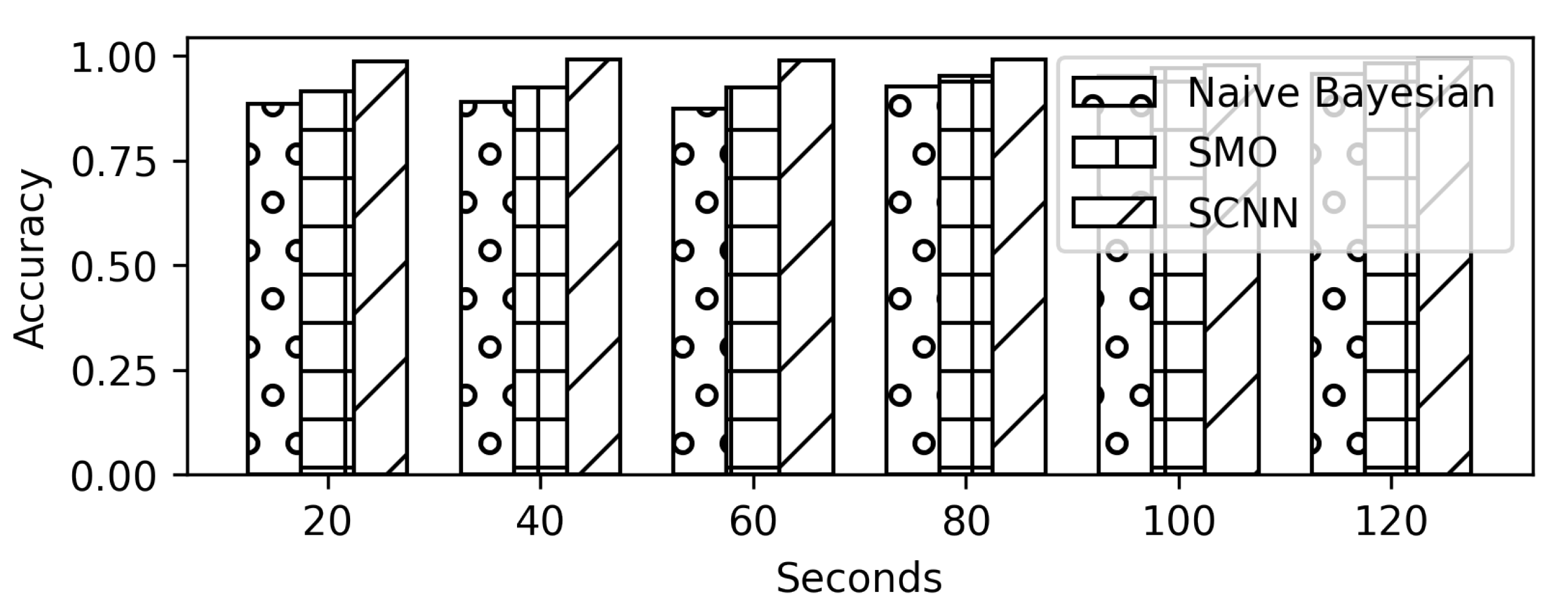
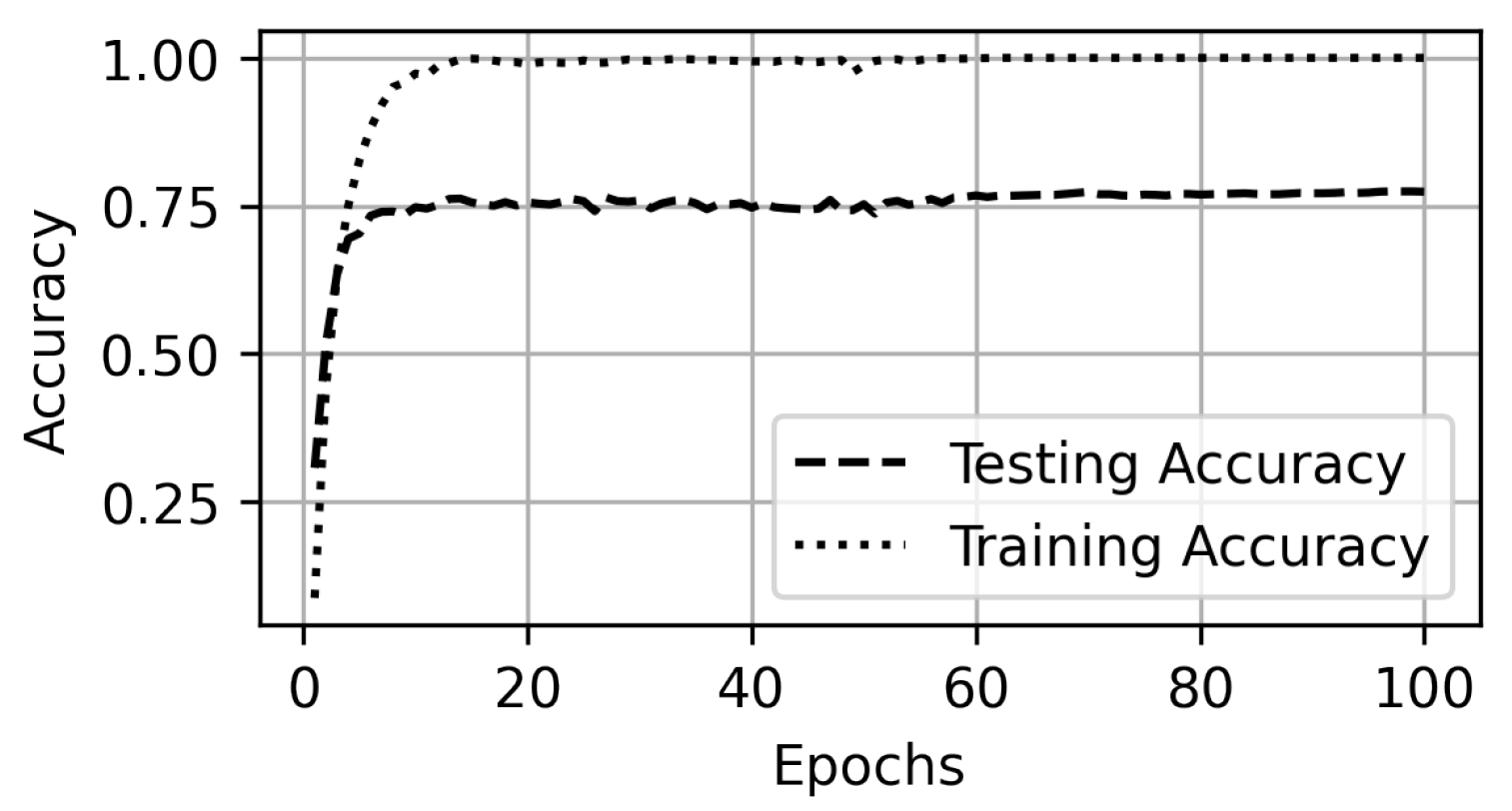
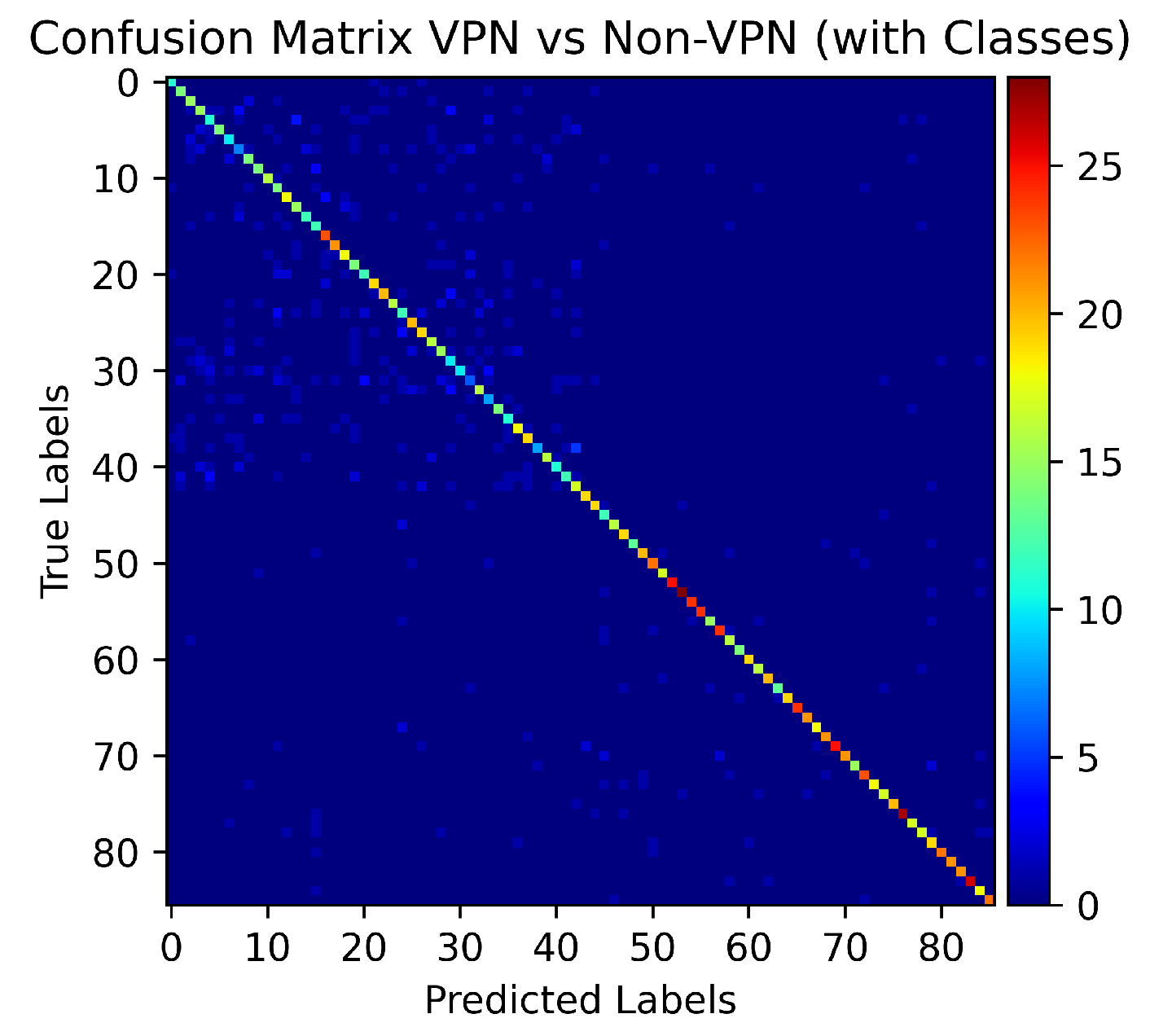
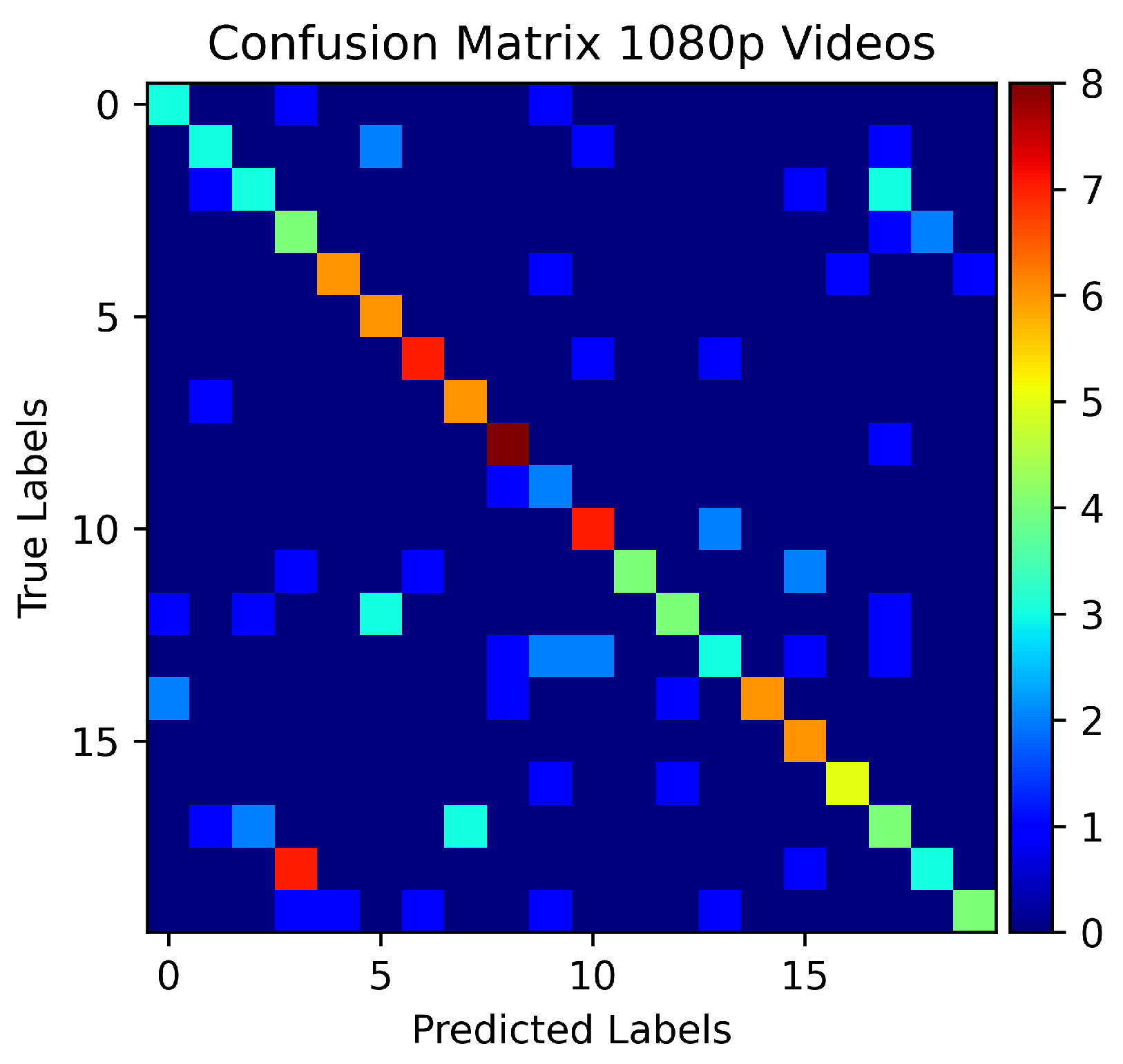
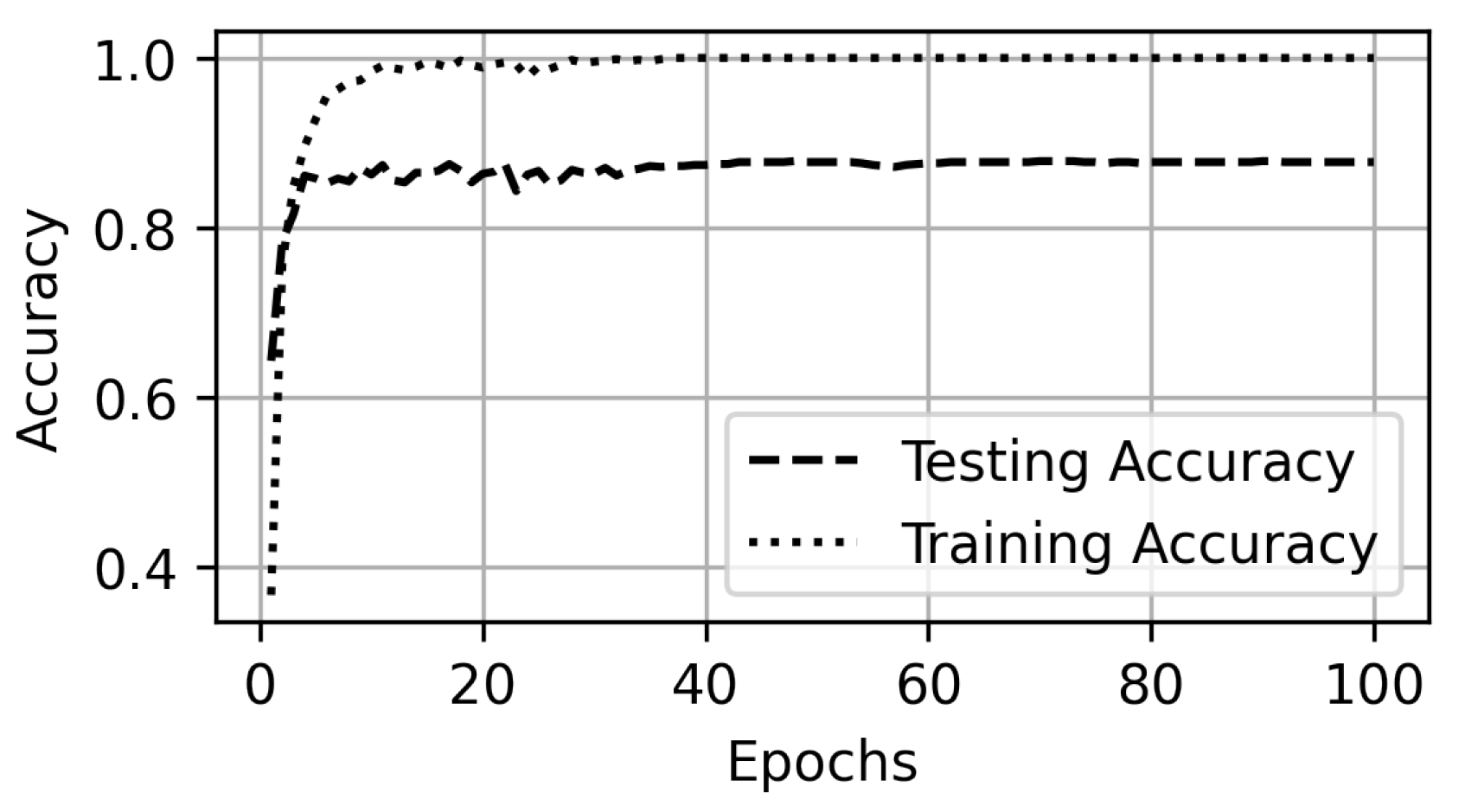
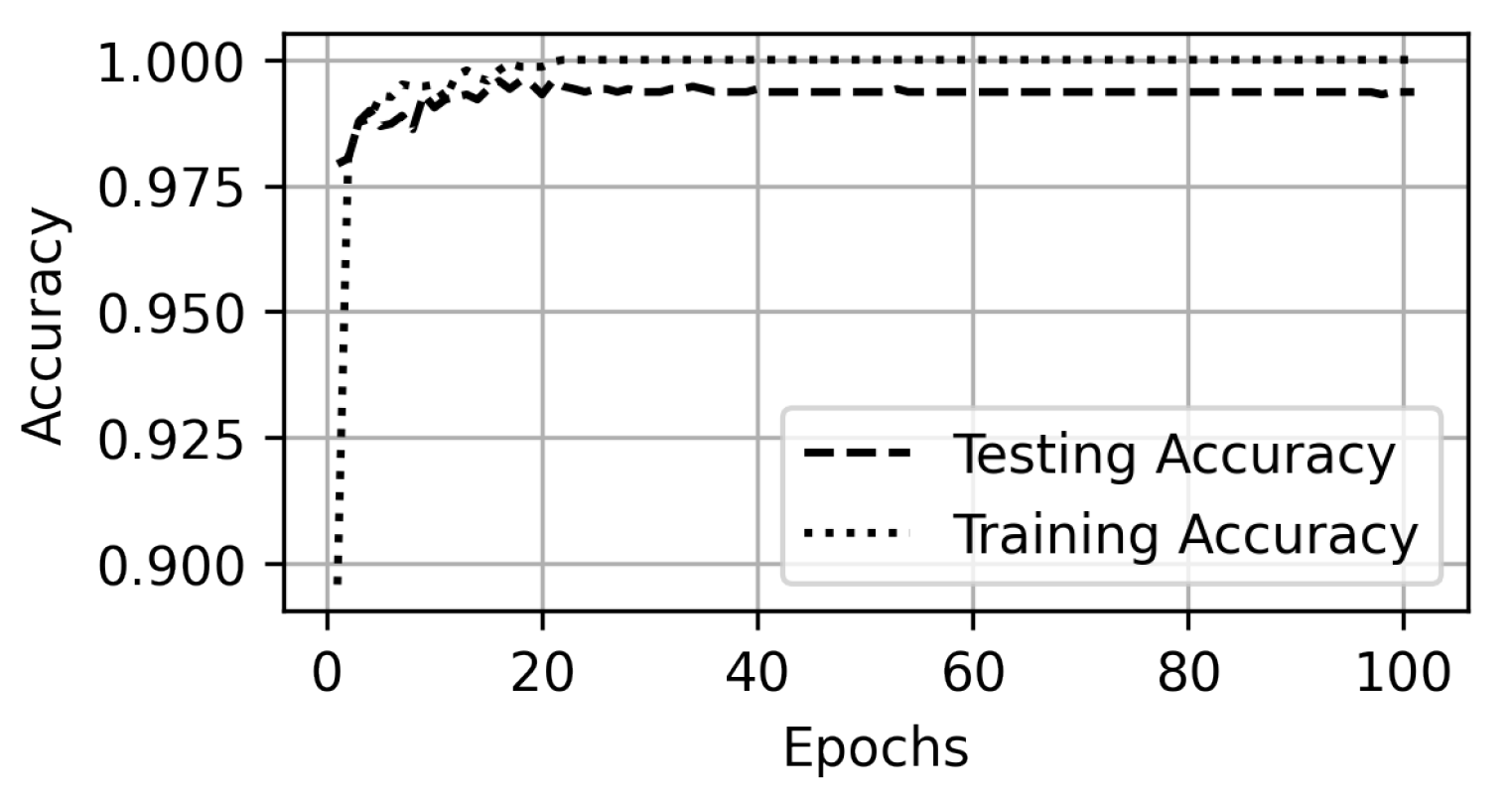
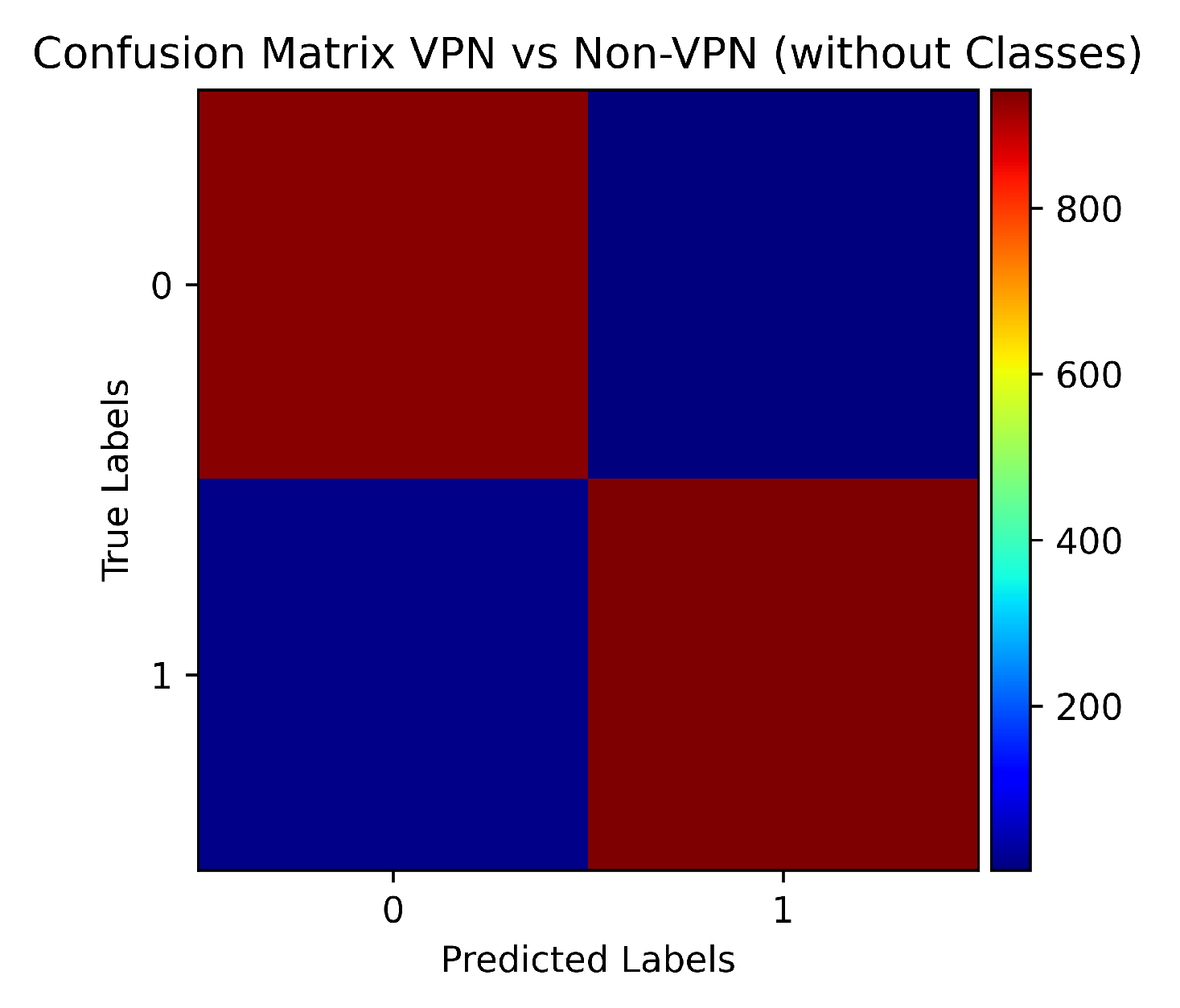
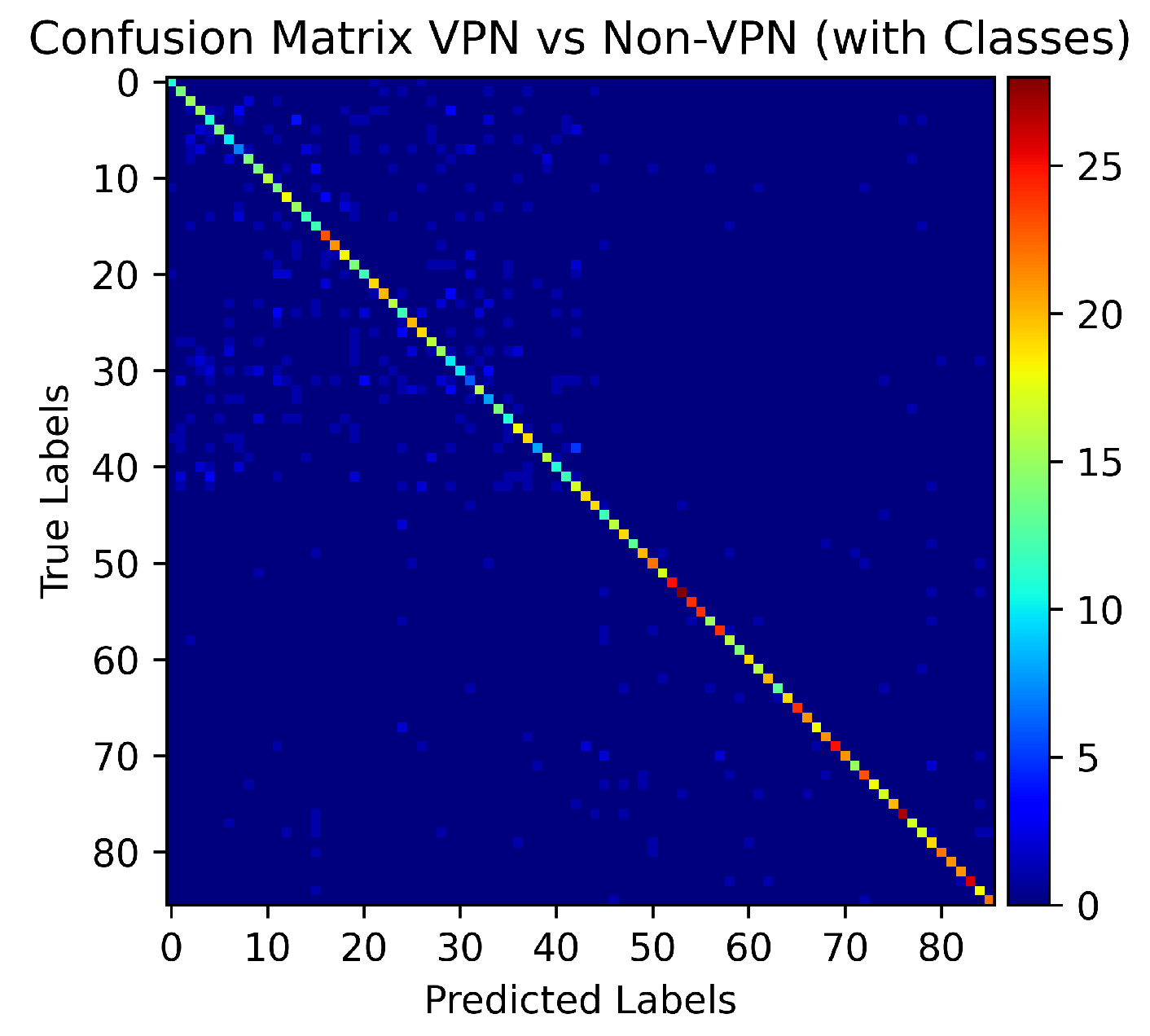
5. Experiments and Results
6. Conclusions and Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gu, J.; Wang, J.; Yu, Z.; Shen, K. Walls have ears: Traffic-based side-channel attack in video streaming. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 1538–1546. [Google Scholar]
- Ghayvat, H.; Pandya, S.N.; Bhattacharya, P.; Zuhair, M.; Rashid, M.; Hakak, S.; Dev, K. CP-BDHCA: Blockchain-based Confidentiality-Privacy preserving Big Data scheme for healthcare clouds and applications. IEEE J. Biomed. Health Inform. 2021. [Google Scholar] [CrossRef] [PubMed]
- Mishra, N.; Pandya, S. Internet of Things Applications, Security Challenges, Attacks, Intrusion Detection, and Future Visions: A Systematic Review. IEEE Access 2021, 9, 59353–59377. [Google Scholar] [CrossRef]
- Khan, M.U.S.; Abbas, A.; Rehman, A.; Nawaz, R. HateClassify: A Service Framework for Hate Speech Identification on Social Media. IEEE Internet Comput. 2020, 25, 40–49. [Google Scholar] [CrossRef]
- Ledwich, M.; Zaitsev, A. Algorithmic extremism: Examining YouTube’s rabbit hole of radicalization. arXiv 2019, arXiv:1912.11211. [Google Scholar] [CrossRef] [Green Version]
- Khan, M.U.S.; Bukhari, S.M.A.H.; Khan, S.A.; Maqsood, T. ISP can identify YouTube videos that you just watched. In Proceedings of the 18th International Conference on Frontiers of Information Technology (FIT 2021), Islamabad, Pakistan, 13–14 December 2021. [Google Scholar]
- Khan, M.U.S.; Jawad, M.; Khan, S.U. Adadb: Adaptive Diff-Batch Optimization Technique for Gradient Descent. IEEE Access 2021, 9, 99581–99588. [Google Scholar] [CrossRef]
- Irfan, R.; Khalid, O.; Khan, M.U.S.; Rehman, F.; Khan, A.U.R.; Nawaz, R. SocialRec: A Context-Aware Recommendation Framework With Explicit Sentiment Analysis. IEEE Access 2019, 7, 116295–116308. [Google Scholar] [CrossRef]
- Zaidi, K.S.; Hina, S.; Jawad, M.; Khan, A.N.; Khan, M.U.S.; Pervaiz, H.B.; Nawaz, R. Beyond the Horizon, Backhaul Connectivity for Offshore IoT Devices. Energies 2021, 14, 6918. [Google Scholar] [CrossRef]
- Dubin, R.; Dvir, A.; Pele, O.; Hadar, O. I know what you saw last minute—encrypted http adaptive video streaming title classification. IEEE Trans. Inf. Forensics Secur. 2017, 12, 3039–3049. [Google Scholar] [CrossRef] [Green Version]
- Miller, S.; Curran, K.; Lunney, T. Detection of Virtual Private Network Traffic Using Machine Learning. Int. J. Wirel. Netw. Broadband Technol. (IJWNBT) 2020, 9, 60–80. [Google Scholar] [CrossRef]
- Mangla, T.; Halepovic, E.; Ammar, M.; Zegura, E. Using session modeling to estimate HTTP-based video QoE metrics from encrypted network traffic. IEEE Trans. Netw. Serv. Manag. 2019, 16, 1086–1099. [Google Scholar] [CrossRef]
- Wassermann, S.; Seufert, M.; Casas, P.; Gang, L.; Li, K. Let me decrypt your beauty: Real-time prediction of video resolution and bitrate for encrypted video streaming. In Proceedings of the 2019 Network Traffic Measurement and Analysis Conference (TMA), Paris, France, 19–21 June 2019; pp. 199–200. [Google Scholar]
- Liu, Y.; Li, S.; Zhang, C.; Zheng, C.; Sun, Y.; Liu, Q. Itp-knn: Encrypted video flow identification based on the intermittent traffic pattern of video and k-nearest neighbors classification. In International Conference on Computational Science; Springer: Berlin/Heidelberg, Germany, 2020; pp. 279–293. [Google Scholar]
- Gutterman, C.; Guo, K.; Arora, S.; Wang, X.; Wu, L.; Katz-Bassett, E.; Zussman, G. Requet: Real-time QoE detection for encrypted YouTube traffic. In Proceedings of the 10th ACM Multimedia Systems Conference, Amherst, MA, USA, 18–21 June 2019; pp. 48–59. [Google Scholar]
- Xu, S.; Sen, S.; Mao, Z.M. CSI: Inferring mobile ABR video adaptation behavior under HTTPS and QUIC. In Proceedings of the Fifteenth European Conference on Computer Systems, Heraklion, Greece, 27–30 April 2020; pp. 1–16. [Google Scholar]
- Ameigeiras, P.; Ramos-Munoz, J.J.; Navarro-Ortiz, J.; Lopez-Soler, J.M. Analysis and modelling of YouTube traffic. Trans. Emerg. Telecommun. Technol. 2012, 23, 360–377. [Google Scholar] [CrossRef]
- Ravattu, R.; Balasetty, P. Characterization of YouTube Video Streaming Traffic. 2013. Available online: https://www.diva-portal.org/smash/get/diva2:830691/FULLTEXT01.pdf (accessed on 2 December 2021).
- Miller, B.; Huang, L.; Joseph, A.D.; Tygar, J.D. I know why you went to the clinic: Risks and realization of https traffic analysis. In International Symposium on Privacy Enhancing Technologies Symposium; Springer: Berlin/Heidelberg, Germany, 2014; pp. 143–163. [Google Scholar]
- Dubin, R.; Dvir, A.; Hadar, O.; Pele, O. I Know What You Saw Last Minute-the Chrome Browser Case. Black Hat Europe. 2016. Available online: https://paper.bobylive.com/Meeting_Papers/BlackHat/Europe-2016/eu-16-Dubin-I-Know-What-You-Saw-Last-Minute-The-Chrome-Browser-Case-WP.pdf (accessed on 6 December 2021).
- Rao, A.; Legout, A.; Lim, Y.s.; Towsley, D.; Barakat, C.; Dabbous, W. Network characteristics of video streaming traffic. In Proceedings of the Seventh COnference on emerging Networking EXperiments and Technologies, Tokyo, Japan, 6–9 December 2011; pp. 1–12. [Google Scholar]
- Liu, Y.; Li, S.; Zhang, C.; Zheng, C.; Sun, Y.; Liu, Q. DOOM: A Training-Free, Real-Time Video Flow Identification Method for Encrypted Traffic. In Proceedings of the 2020 27th International Conference on Telecommunications (ICT), Bali, Indonesia, 5–7 October 2020; pp. 1–5. [Google Scholar]
- Wu, H.; Yu, Z.; Cheng, G.; Guo, S. Identification of Encrypted Video Streaming Based on Differential Fingerprints. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 6–9 July 2020; pp. 74–79. [Google Scholar]
- Song, J.; Lee, S.; Kim, B.; Seol, S.; Lee, B.; Kim, M. VTIM: Video Title Identification Using Open Metadata. IEEE Access 2020, 8, 113567–113584. [Google Scholar] [CrossRef]
- Li, F.; Chung, J.W.; Claypool, M. Silhouette: Identifying YouTube Video Flows from Encrypted Traffic. In Proceedings of the 28th ACM SIGMM Workshop on Network and Operating Systems Support for Digital Audio and Video, Amsterdam, The Netherlands, 12–15 June 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 19–24. [Google Scholar]
- Dvir, A.; Marnerides, A.K.; Dubin, R.; Golan, N. Clustering the Unknown-The Youtube Case. In Proceedings of the 2019 International Conference on Computing, Networking and Communications (ICNC), Honolulu, HI, USA, 18–21 February 2019; pp. 402–407. [Google Scholar]
- Biernacki, A. Identification of adaptive video streams based on traffic correlation. Multimed. Tools Appl. 2019, 78, 18271–18291. [Google Scholar] [CrossRef] [Green Version]
- Shi, Y. Towards Machine Learning Based Source Identification of Encrypted Video Traffic; Michigan State University: East Lansing, MI, USA, 2019. [Google Scholar]
- Shi, Y.; Biswas, S. A deep-learning enabled traffic analysis engine for video source identification. In Proceedings of the 2019 11th International Conference on Communication Systems & Networks (COMSNETS), Bengaluru, India, 7–11 January 2019; pp. 15–21. [Google Scholar]
- Rahman, M.S.; Matthews, N.; Wright, M. Poster: Video fingerprinting in tor. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 2629–2631. [Google Scholar]
- Khalil, H.; Khan, M.U.; Ali, M. Feature Selection for Unsupervised Bot Detection. In Proceedings of the 2020 3rd International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 29–30 January 2020; pp. 1–7. [Google Scholar]
- Mahmood, Z.; Safder, I.; Nawab, R.M.A.; Bukhari, F.; Nawaz, R.; Alfakeeh, A.S.; Aljohani, N.R.; Hassan, S.U. Deep sentiments in roman urdu text using recurrent convolutional neural network model. Inf. Process. Manag. 2020, 57, 102233. [Google Scholar] [CrossRef]
- Safder, I.; Hassan, S.U.; Visvizi, A.; Noraset, T.; Nawaz, R.; Tuarob, S. Deep learning-based extraction of algorithmic metadata in full-text scholarly documents. Inf. Process. Manag. 2020, 57, 102269. [Google Scholar] [CrossRef]
- Mohammad, S.; Khan, M.U.S.; Ali, M.; Liu, L.; Shardlow, M.; Nawaz, R. Bot detection using a single post on social media. In Proceedings of the 2019 Third World Conference on Smart Trends in Systems Security and Sustainablity (WorldS4), London, UK, 30–31 July 2019; pp. 215–220. [Google Scholar]
- Khan, M.U.; Abbas, A.; Ali, M.; Jawad, M.; Khan, S.U. Convolutional neural networks as means to identify apposite sensor combination for human activity recognition. In Proceedings of the 2018 IEEE/ACM International Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE), Washington, DC, USA, 26–28 September 2018; pp. 45–50. [Google Scholar]
- Khan, M.; Baig, D.; Khan, U.S.; Karim, A. Malware Classification Framework using Convolutional Neural Network. In Proceedings of the 2020 International Conference on Cyber Warfare and Security (ICCWS), Islamabad, Pakistan, 20–21 October 2020; pp. 1–7. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Khan, W.; Ali, S.; Muhammad, U.K.; Jawad, M.; Ali, M.; Nawaz, R. AdaDiffGrad: An Adaptive Batch Size Implementation Technique for DiffGrad Optimization Method. In Proceedings of the 2020 14th International Conference on Innovations in Information Technology (IIT), Al Ain, United Arab Emirates, 17–18 November 2020; pp. 209–214. [Google Scholar]
- Chen, J.; Wu, J.; Liang, H.; Mumtaz, S.; Li, J.; Konstantin, K.; Bashir, A.K.; Nawaz, R. Collaborative trust blockchain based unbiased control transfer mechanism for industrial automation. IEEE Trans. Ind. Appl. 2019, 56, 4478–4488. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer ID | Layer (Type) | Output Shape | Param # |
|---|---|---|---|
| 1 | Conv1D | (None, 120, 1024) | 7168 |
| 2 | MaxPooling1 | (None, 60, 1024) | 0 |
| 3 | Conv1D | (None, 60, 512) | 2,097,664 |
| 4 | MaxPooling1 | (None, 30, 512) | 0 |
| 5 | Conv1D | (None, 30, 512) | 1,311,232 |
| 6 | MaxPooling1 | (None, 15, 512) | 0 |
| 7 | Dropout | (None, 15, 512) | 0 |
| 8 | Flatten | (None, 7680) | 0 |
| 9 | Dense | (None, Number of videos = 44) | 337,964 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, M.U.S.; Bukhari, S.M.A.H.; Maqsood, T.; Fayyaz, M.A.B.; Dancey, D.; Nawaz, R. SCNN-Attack: A Side-Channel Attack to Identify YouTube Videos in a VPN and Non-VPN Network Traffic. Electronics 2022, 11, 350. https://doi.org/10.3390/electronics11030350
Khan MUS, Bukhari SMAH, Maqsood T, Fayyaz MAB, Dancey D, Nawaz R. SCNN-Attack: A Side-Channel Attack to Identify YouTube Videos in a VPN and Non-VPN Network Traffic. Electronics. 2022; 11(3):350. https://doi.org/10.3390/electronics11030350
Chicago/Turabian StyleKhan, Muhammad U. S., Syed M. A. H. Bukhari, Tahir Maqsood, Muhammad A. B. Fayyaz, Darren Dancey, and Raheel Nawaz. 2022. "SCNN-Attack: A Side-Channel Attack to Identify YouTube Videos in a VPN and Non-VPN Network Traffic" Electronics 11, no. 3: 350. https://doi.org/10.3390/electronics11030350
APA StyleKhan, M. U. S., Bukhari, S. M. A. H., Maqsood, T., Fayyaz, M. A. B., Dancey, D., & Nawaz, R. (2022). SCNN-Attack: A Side-Channel Attack to Identify YouTube Videos in a VPN and Non-VPN Network Traffic. Electronics, 11(3), 350. https://doi.org/10.3390/electronics11030350