
Energy Efficient Distance Computing: Application to K-Means Clustering


Abstract
:1. Introduction
2. Related Works
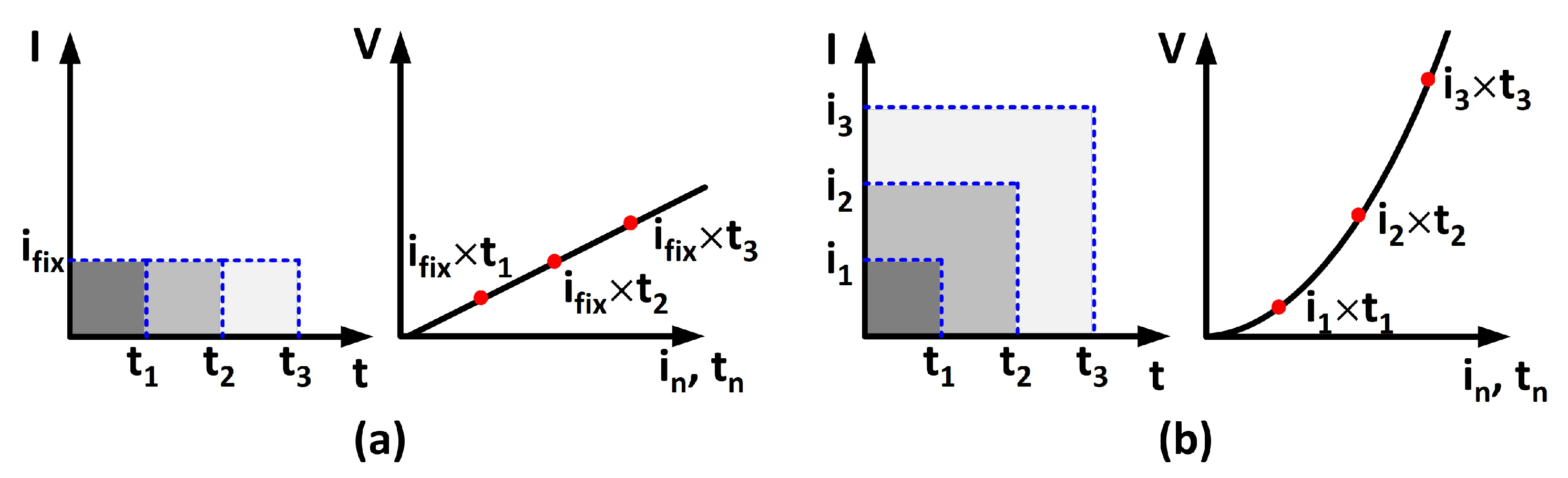
3. Basic Distance Metrics
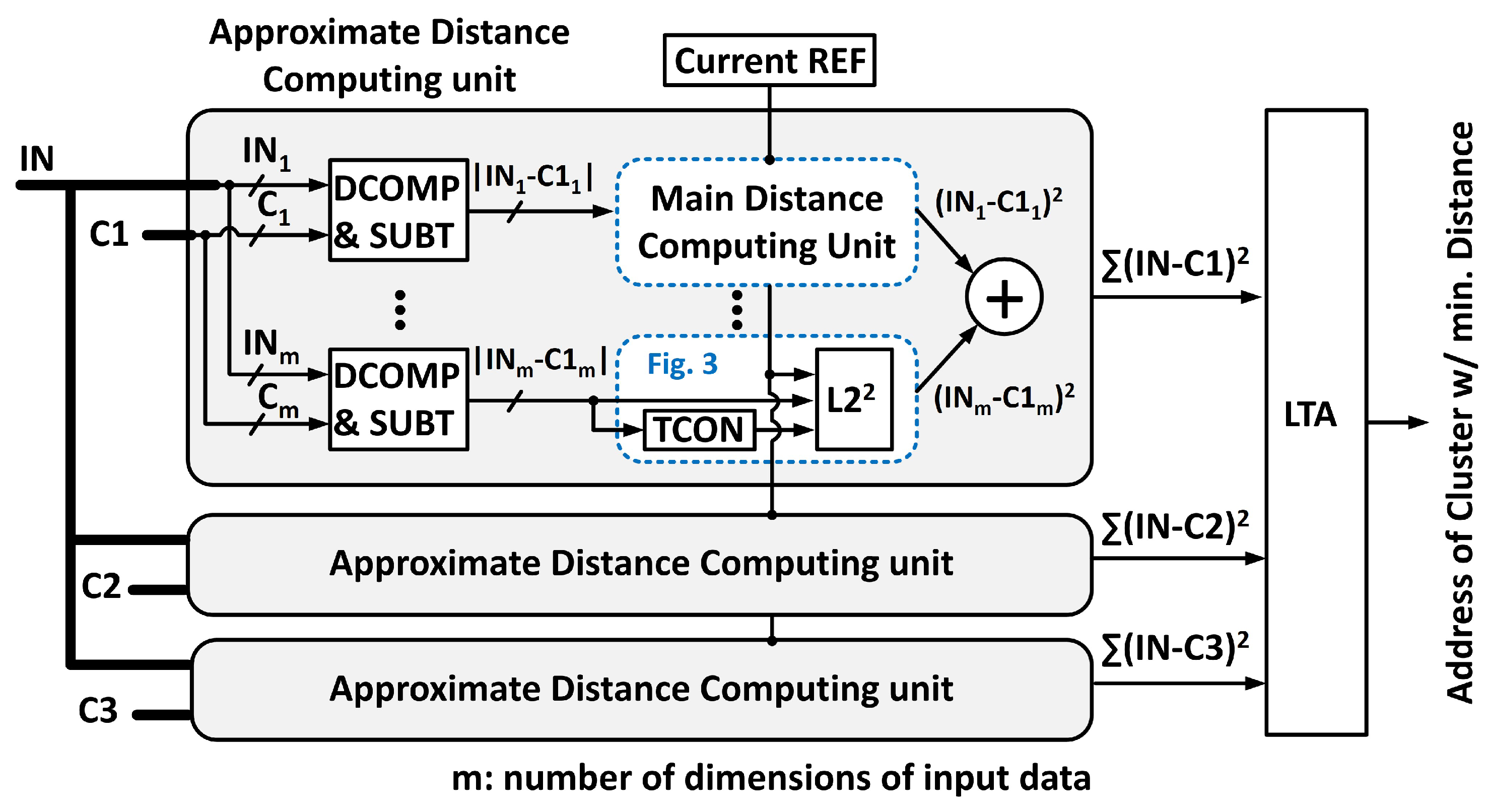
Proposed Approximate Distance Computing Unit
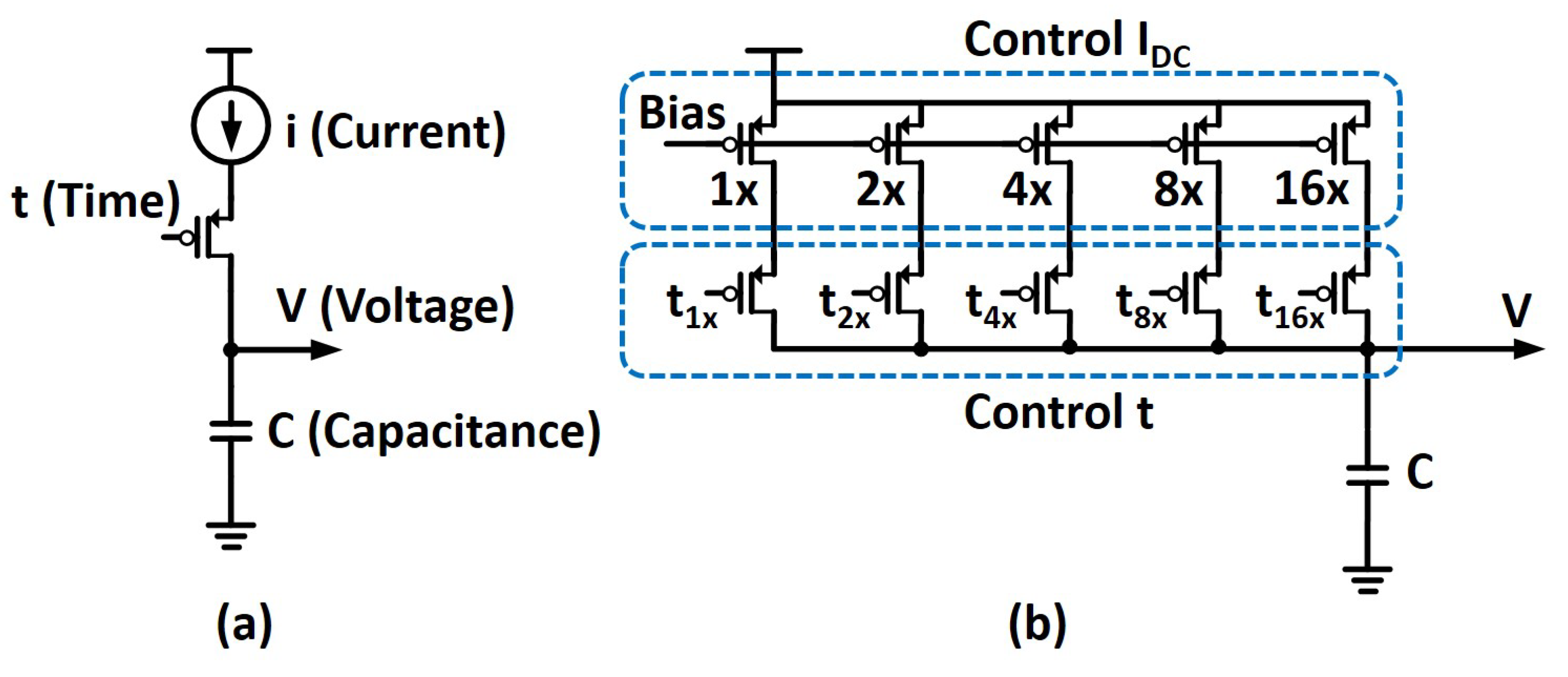
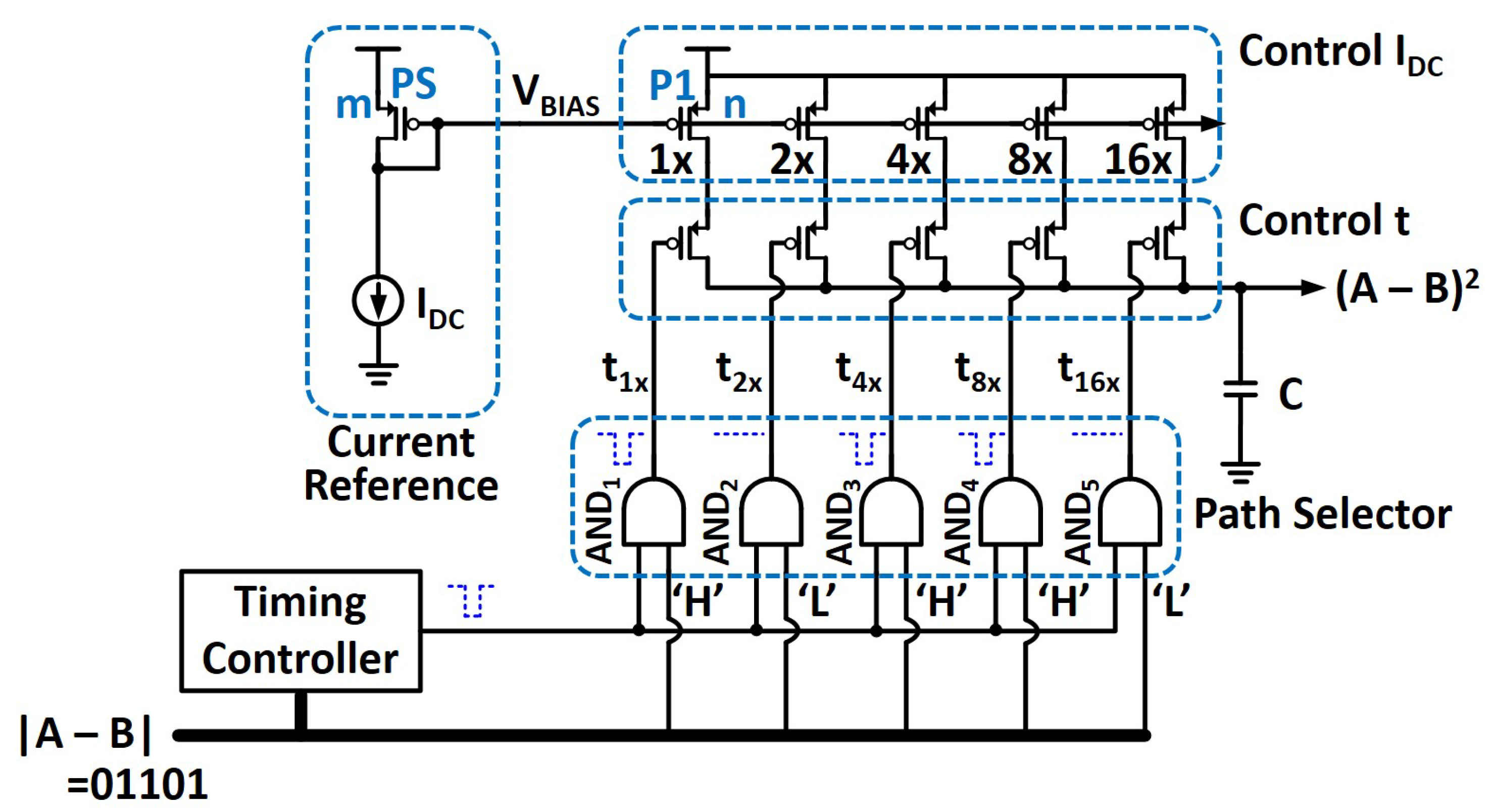
4. Circuit Details for the Distance Computing Unit
4.1. Main Distance Computing Unit
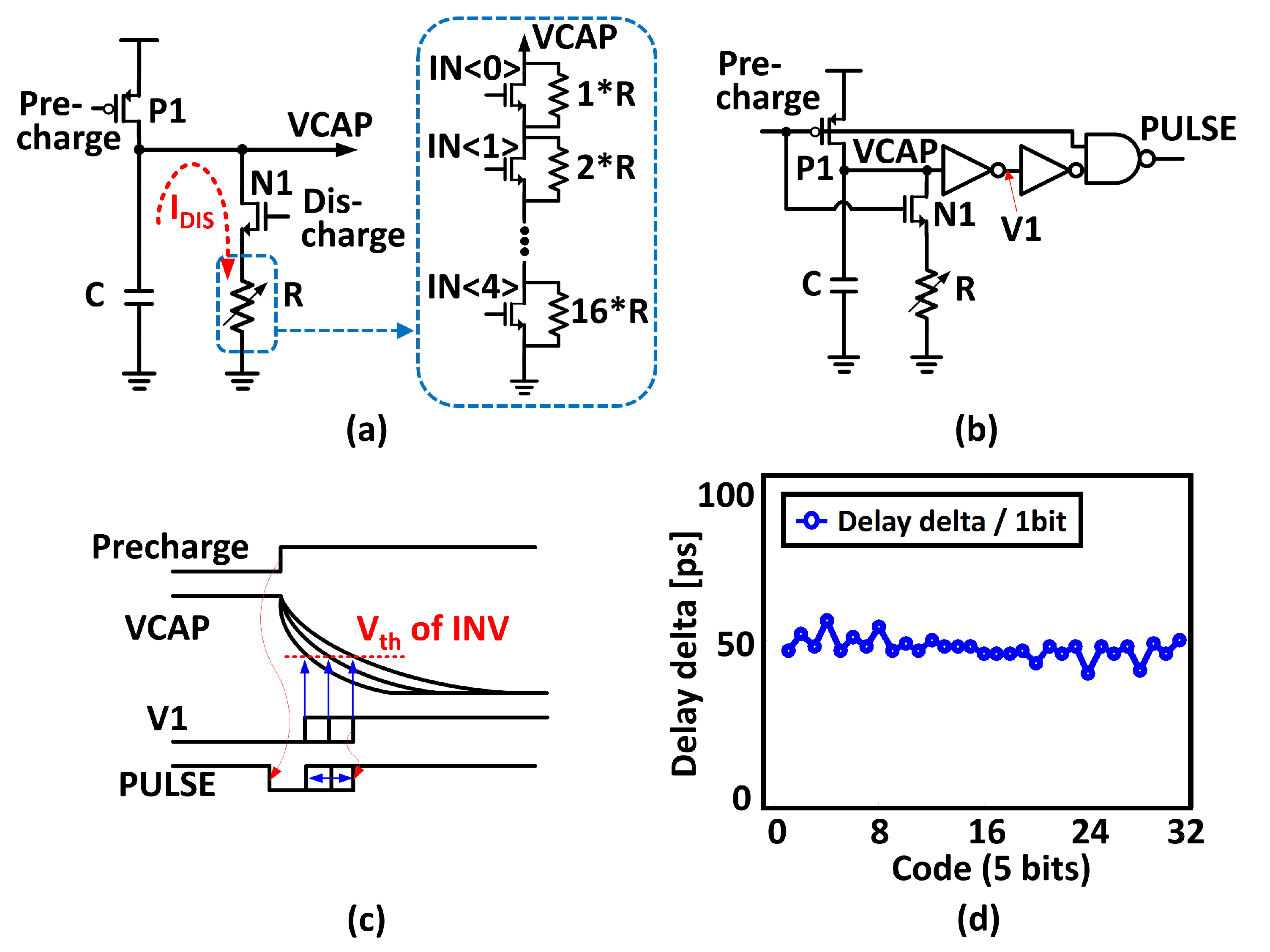
4.2. Timing Controller
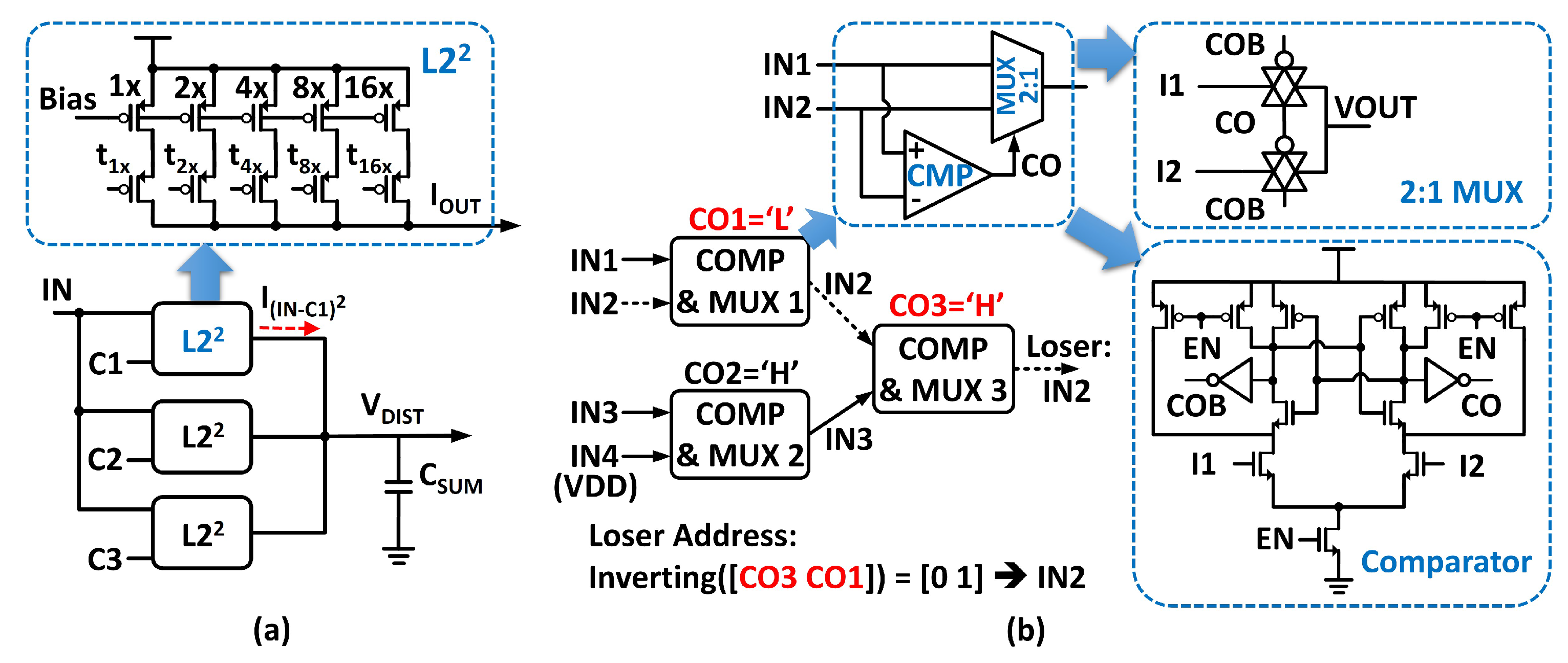
4.3. Generation of Distance Norms
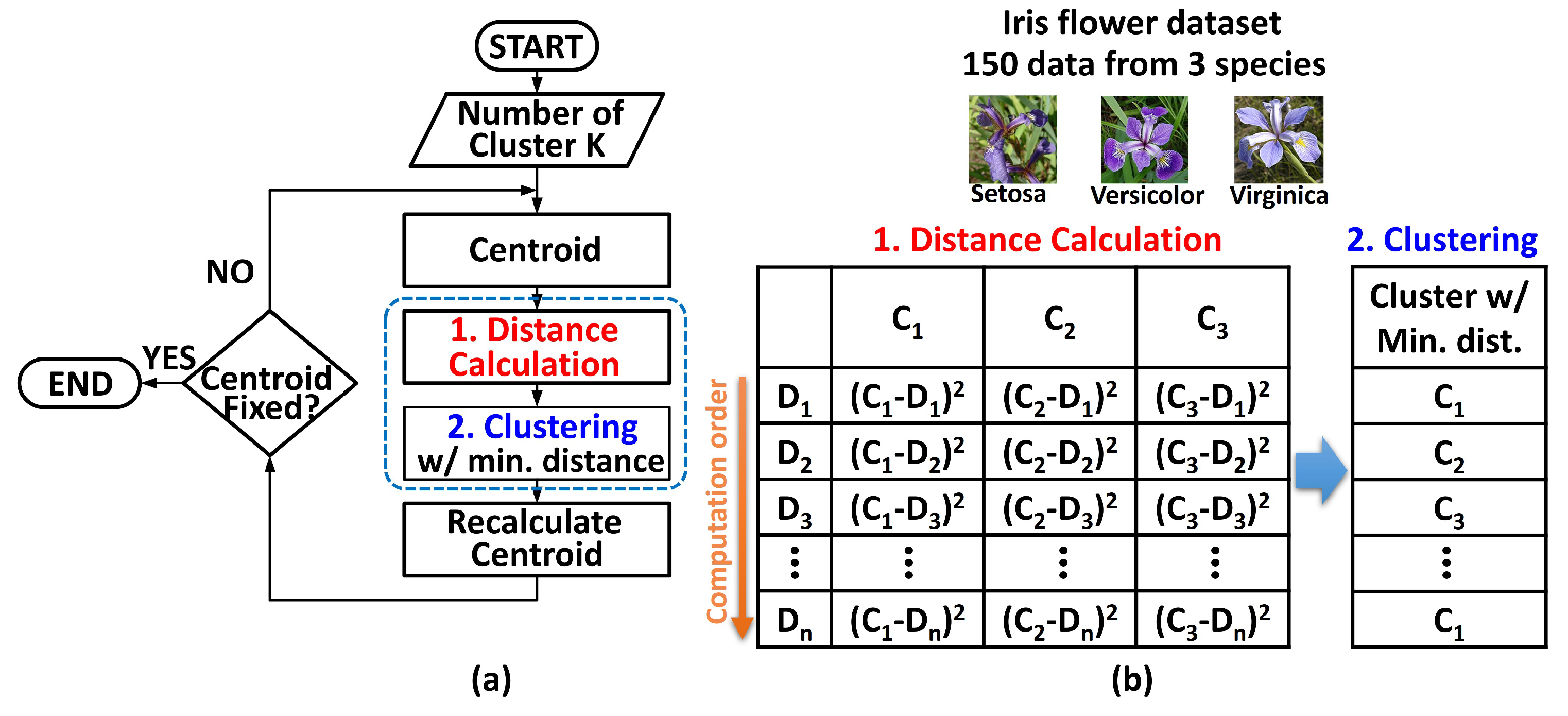
5. Application to K-Means Clustering
5.1. General K-Means Clustering Algorithm for Iris Dataset
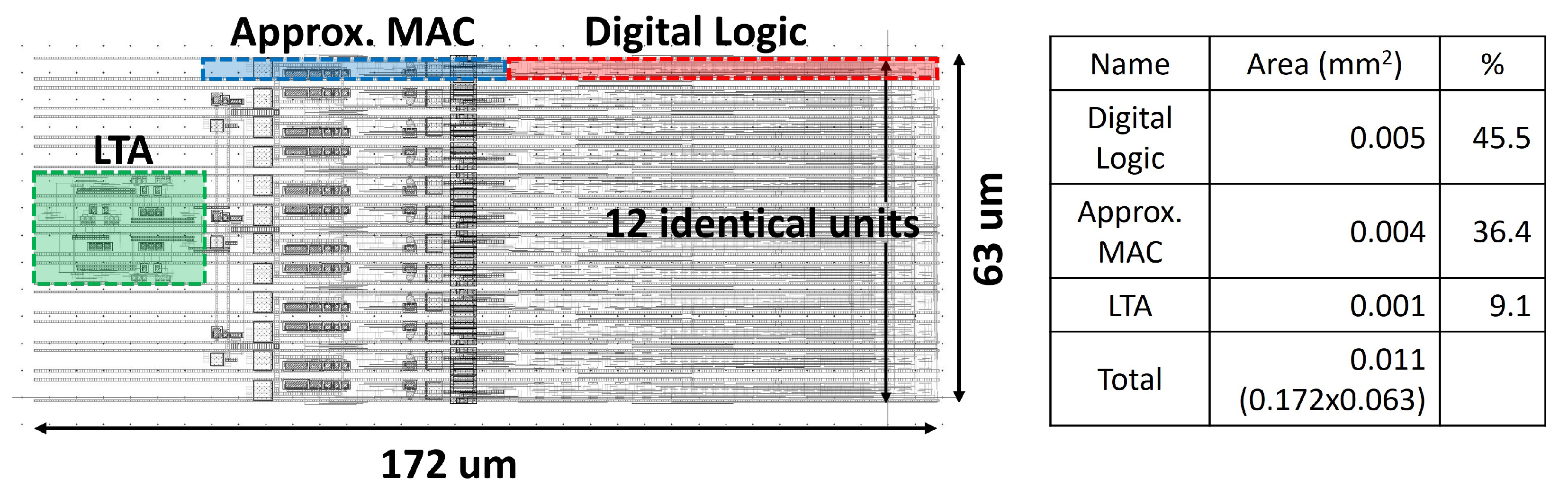
5.2. Architecture of the Proposed K-Means Clustering Unit
5.3. Additional Circuitry
6. Performance Analysis
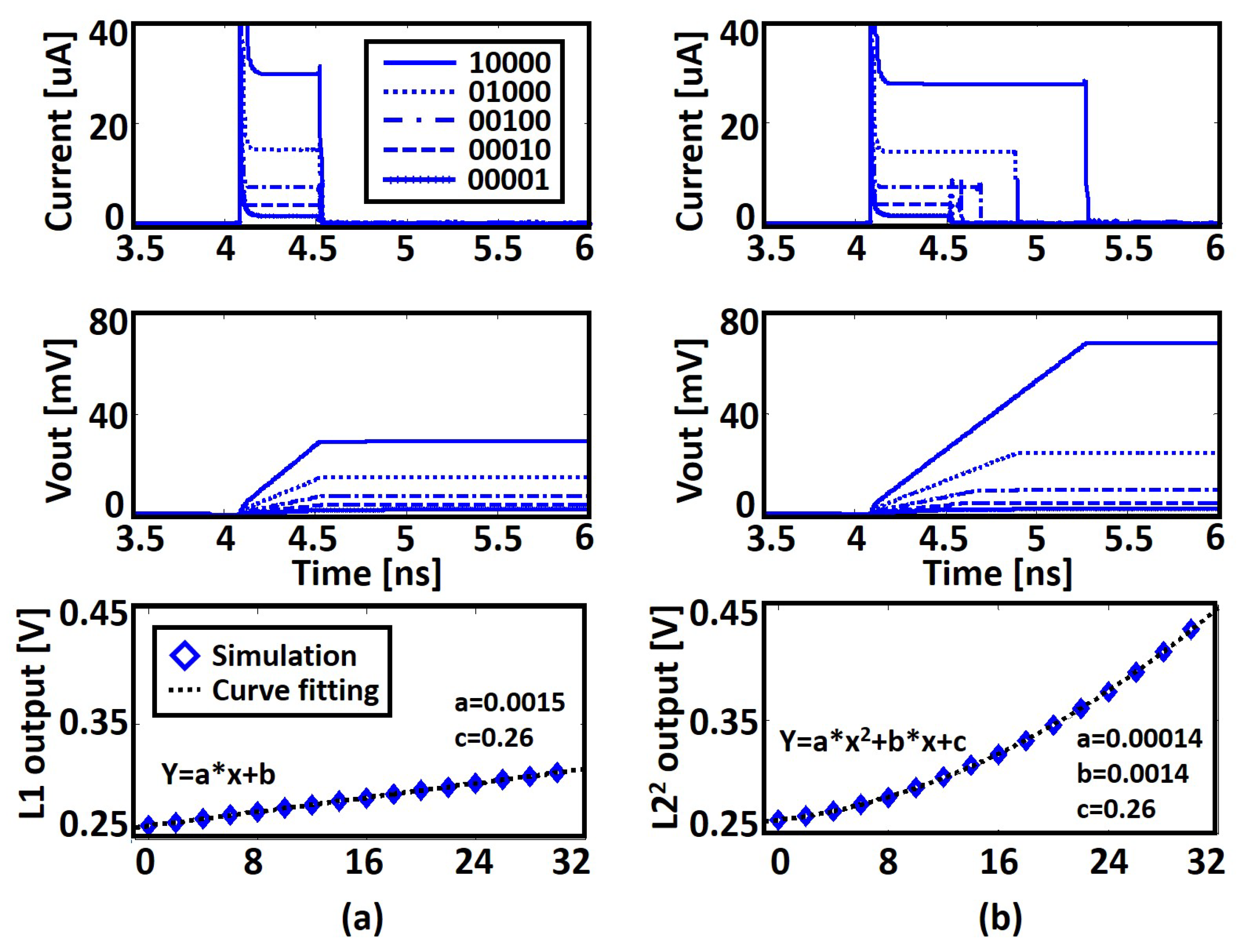
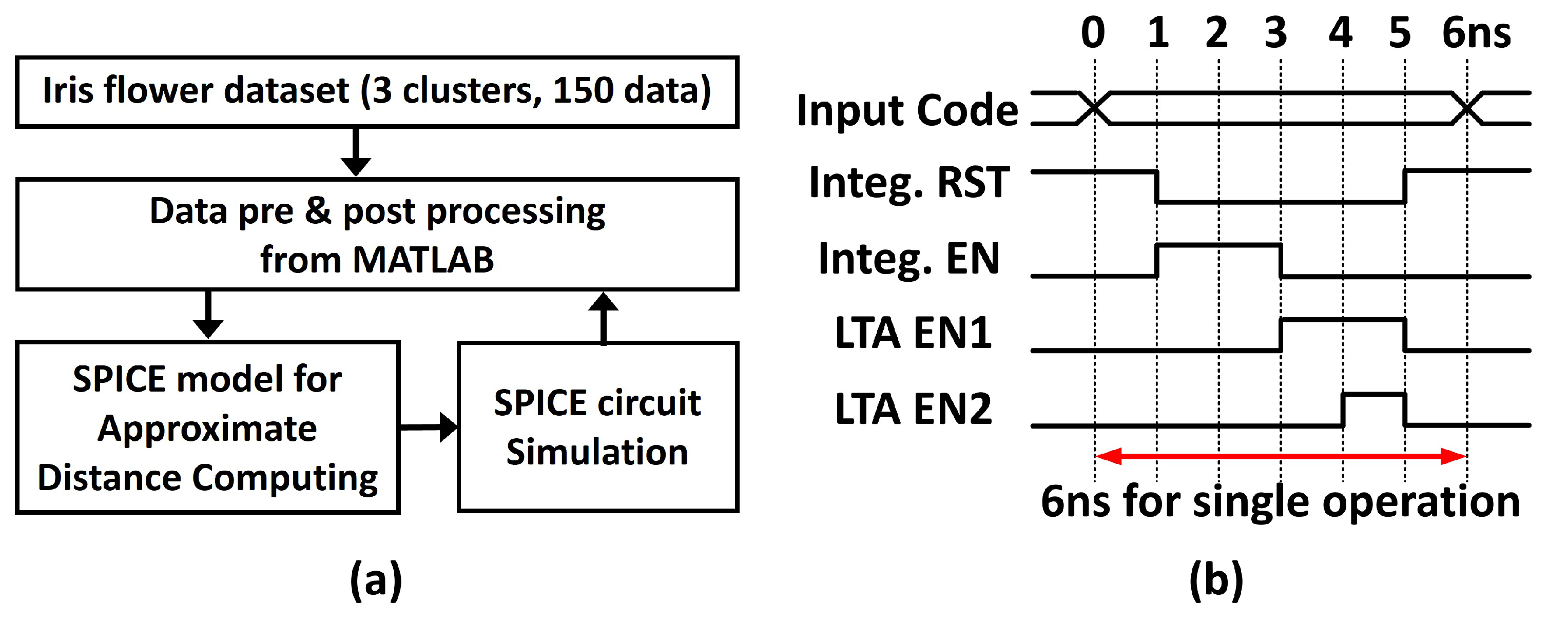
6.1. Simulation Framework and Timing Diagram
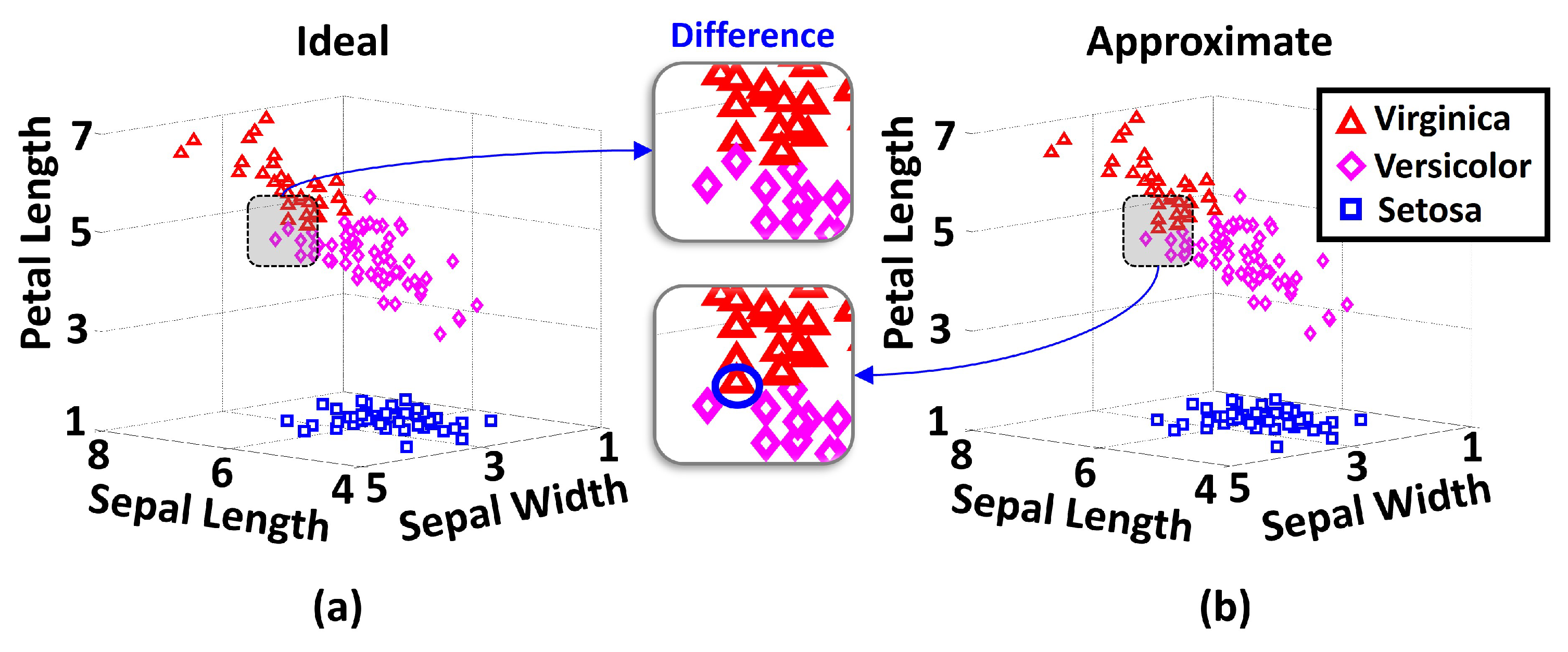
6.2. Clustering Result
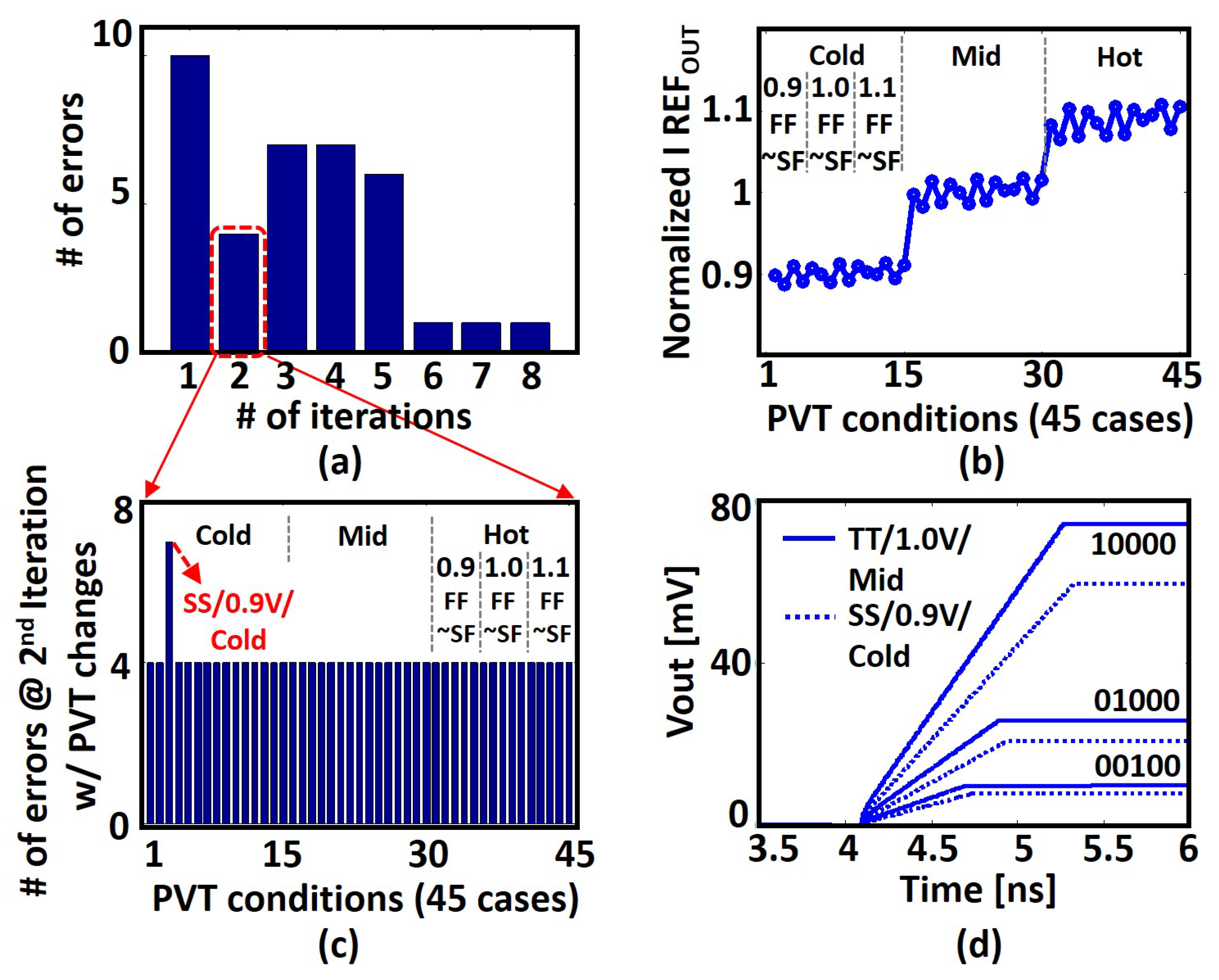
6.3. Clustering under Different PVT Conditions
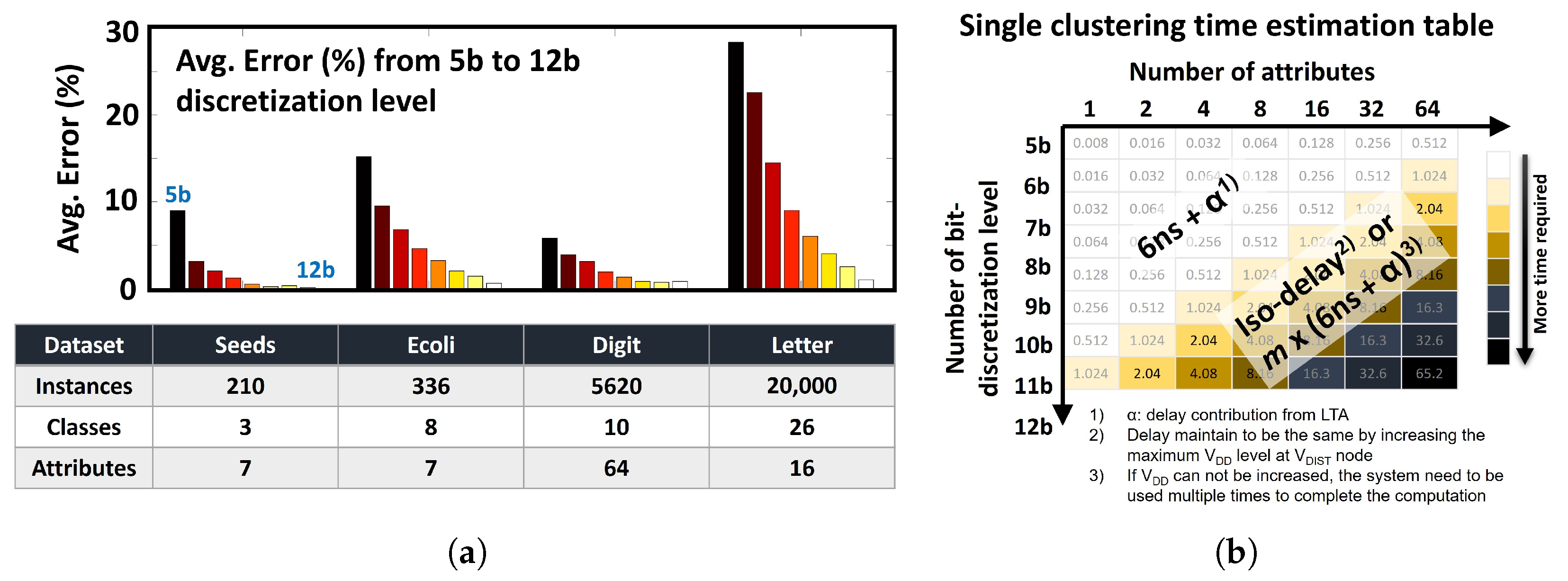
6.4. Clustering Results with Other Datasets
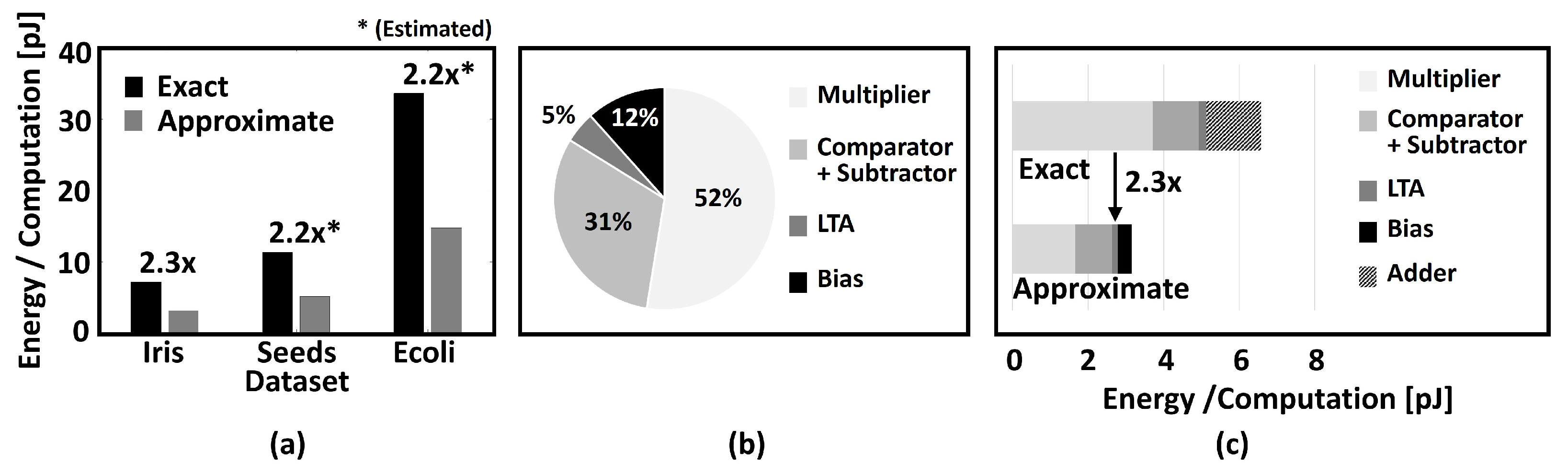
6.5. Energy Analysis
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sinaga, K.P.; Yang, M.S. Unsupervised K-Means Clustering Algorithm. IEEE Access 2020, 8, 80716–80727. [Google Scholar] [CrossRef]
- Ding, C.; He, X. K-Means Clustering via Principal Component Analysis. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; p. 29. [Google Scholar] [CrossRef]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Mat Isa, N.A.; Salamah, S.A.; Ngah, U.K. Adaptive fuzzy moving K-means clustering algorithm for image segmentation. IEEE Trans. Consum. Electron. 2009, 55, 2145–2153. [Google Scholar] [CrossRef]
- Chen, T.W.; Chien, S.Y. Bandwidth Adaptive Hardware Architecture of K-Means Clustering for Video Analysis. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2010, 18, 957–966. [Google Scholar] [CrossRef]
- He, Z.; Yu, C. Clustering Stability-Based Evolutionary K-Means. Soft Comput. 2019, 23, 305–321. [Google Scholar] [CrossRef]
- Sharma, K.K.; Seal, A. Clustering analysis using an adaptive fused distance. Eng. Appl. Artif. Intell. 2020, 96, 103928. [Google Scholar] [CrossRef]
- Karlekar, A.; Seal, A.; Krejcar, O.; Gonzalo-Martin, C. Fuzzy K-Means Using Non-Linear S-Distance. IEEE Access 2019, 7, 55121–55131. [Google Scholar] [CrossRef]
- Seal, A.; Karlekar, A.; Krejcar, O.; Gonzalo-Martin, C. Fuzzy c-means clustering using Jeffreys-divergence based similarity measure. Appl. Soft Comput. 2020, 88, 106016. [Google Scholar] [CrossRef]
- Seal, A.; Herrera Viedma, E. Performance and Convergence Analysis of Modified C-Means Using Jeffreys-Divergence for Clustering. Int. J. Interact. Multimed. Artif. Intell. 2021, 7, 141–149. [Google Scholar] [CrossRef]
- Liu, B.D.; Chen, C.Y.; Tsao, J.Y. A modular current-mode classifier circuit for template matching application. Circuits Syst. II Analog. Digit. Signal Process. IEEE Trans. 2000, 47, 145–151. [Google Scholar]
- Vlassis, S.; Fikos, G.; Siskos, S. A floating gate CMOS Euclidean distance calculator and its application to hand-written digit recognition. In Proceedings of the 2001 International Conference on Image Processing (Cat. No.01CH37205), Thessaloniki, Greece, 7–10 October 2001; Volume 3, pp. 350–353. [Google Scholar]
- Gopalan, A.; Titus, A.H. A new wide range Euclidean distance circuit for neural network hardware implementations. Neural Netw. IEEE Trans. 2003, 14, 1176–1186. [Google Scholar] [CrossRef] [PubMed]
- Bult, K.; Wallinga, H. A class of analog CMOS circuits based on the square-law characteristic of an MOS transistor in saturation. IEEE J. -Solid-State Circuits 1987, 22, 357–365. [Google Scholar] [CrossRef] [Green Version]
- Cauwenberghs, G.; Pedroni, V. A low-power CMOS analog vector quantizer. IEEE J. -Solid-State Circuits 1997, 32, 1278–1283. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.I.; Chang, C.C. A CMOS square-law vector summation circuit. IEEE Trans. Circuits Syst. II Analog. Digit. Signal Process. 1996, 43, 520–523. [Google Scholar] [CrossRef]
- Harada, Y.; Fujimoto, K.; Fukuhara, M.; Yoshida, M. A Minimum Hamming Distance Search Associative Memory Using Neuron CMOS Inverters. Electron. Commun. Jpn. 2017, 100, 10–18. [Google Scholar] [CrossRef]
- Talaśka, T.; Kolasa, M.; Długosz, R.; Pedrycz, W. Analog Programmable Distance Calculation Circuit for Winner Takes All Neural Network Realized in the CMOS Technology. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 661–673. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.; Young, S.; Arel, I.; Holleman, J. An analog online clustering circuit in 130 nm CMOS. In Proceedings of the Solid-State Circuits Conference (A-SSCC), 2013 IEEE Asian, Singapore, 11–13 November 2013; pp. 177–180. [Google Scholar]
- Abedin, M.A.; Tanaka, Y.; Ahmadi, A.; Koide, T.; Mattausch, H.J. Mixed Digital–Analog Associative Memory Enabling Fully-Parallel Nearest Euclidean Distance Search. Jpn. J. Appl. Phys. 2007, 46, 2231. [Google Scholar] [CrossRef]
- An, F.; Akazawa, T.; Yamazaki, S.; Chen, L.; Mattausch, H.J. A coprocessor for clock-mapping-based nearest Euclidean distance search with feature vector dimension adaptability. In Proceedings of the IEEE 2014 Custom Integrated Circuits Conference, CICC 2014, San Jose, CA, USA, 15–17 September 2014; pp. 1–4. [Google Scholar]
- An, F.; Mihara, K.; Yamasaki, S.; Chen, L.; Jurgen, M. K-Nearest Neighbor Associative Memory with Reconfigurable Word-Parallel Architecture. JSTS J. Semicond. Technol. Sci. 2016, 16, 405–414. [Google Scholar] [CrossRef] [Green Version]
- Available online: https://archive.ics.uci.edu/ml/datasets/ (accessed on 30 November 2021).
- Demosthenous, A.; Smedley, S.; Taylor, J. A CMOS analog winner-take-all network for large-scale applications. Circuits Syst. I Fundam. Theory Appl. IEEE Trans. 1998, 45, 300–304. [Google Scholar] [CrossRef]
- Aksin, D.Y. A high-precision high-resolution WTA-MAX circuit of O (N) complexity. Circuits Syst. II Analog. Digit. Signal Process. IEEE Trans. 2002, 49, 48–53. [Google Scholar] [CrossRef]
- Ito, K.; Ogawa, M.; Shibata, T. A high-performance ramp-voltage-scan winner-take-all circuit in an open loop architecture. Jpn. J. Appl. Phys. 2002, 41, 2301. [Google Scholar] [CrossRef]
- Bottou, L.; Bengio, Y. Convergence Properties of the K-Means Algorithms. In Advances in Neural Information Processing Systems; Tesauro, G., Touretzky, D., Leen, T., Eds.; MIT Press: Cambridge, MA, USA, 1995; Volume 7. [Google Scholar]
- Selim, S.Z.; Ismail, M.A. K-Means-Type Algorithms: A Generalized Convergence Theorem and Characterization of Local Optimality. IEEE Trans. Pattern Anal. Mach. Intell. 1984, PAMI-6, 81–87. [Google Scholar] [CrossRef]
- Baker, R.J. CMOS: Circuit Design, Layout, and Simulation, 3rd ed.; Wiley: New York, NY, USA, 2010. [Google Scholar]
- He, B.; Qiao, F.; Chen, W.; Wen, Y. Fully convolution neural network combined with K-means clustering algorithm for image segmentation. In Proceedings of the Tenth International Conference on Digital Image Processing (ICDIP 2018), Shanghai, China, 11–14 May 2018; pp. 760–766. [Google Scholar] [CrossRef]
- Cho, M.; Alizadeh-Vahid, K.; Adya, S.; Rastegari, M. DKM: Differentiable K-Means Clustering Layer for Neural Network Compression. arXiv 2021, arXiv:2108.12659. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Analog | Analog | Mixed | Digital | Digital | This Work | |
|---|---|---|---|---|---|---|
| [19] | [18] | [17] | [21] | [22] | (Mixed) | |
| Application | Clustering | Nearest Neighbor | Associative Memory | Nearest Neighbor | Nearest Neighbor | Clustering |
| Dist. Metric | ||||||
| Technology | 130 nm | 180 nm | 180 nm | 180 nm | 180 nm | 45 nm |
| Data size (Centroids/ Dimensions) | 8 bits 32 words | |||||
| VDD | 3 V | 1.8 V | 1.8 V | 1.8 V | 1.8 V | 1.0 V |
| Power (Estimated) | 15 uW mW | 0.22 mW mW | <5.53 mW | mW mW | mW mW | mW |
| Search Time (Estimated) | 250 us (6 ns) | 143 ns (6 ns) | <7.29 ns | <23 ns (9 ns) | us (9 ns) | 6 ns |
| Energy (Estimated) | 3.75 nJ (7.6 pJ) | 31.46 pJ (3.15 pJ) | <72.5 pJ | <115.4 pJ (86.1 pJ) | 53.9 nJ (86.1 pJ) | 3.15 pJ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shim, Y.; Choi, S.-W.; Yang, M.-G.; Chung, K.-Y.; Baek, K.-H. Energy Efficient Distance Computing: Application to K-Means Clustering. Electronics 2022, 11, 298. https://doi.org/10.3390/electronics11030298
Shim Y, Choi S-W, Yang M-G, Chung K-Y, Baek K-H. Energy Efficient Distance Computing: Application to K-Means Clustering. Electronics. 2022; 11(3):298. https://doi.org/10.3390/electronics11030298
Chicago/Turabian StyleShim, Yong, Seong-Wook Choi, Myeong-Gyu Yang, Keun-Yong Chung, and Kwang-Hyun Baek. 2022. "Energy Efficient Distance Computing: Application to K-Means Clustering" Electronics 11, no. 3: 298. https://doi.org/10.3390/electronics11030298
APA StyleShim, Y., Choi, S.-W., Yang, M.-G., Chung, K.-Y., & Baek, K.-H. (2022). Energy Efficient Distance Computing: Application to K-Means Clustering. Electronics, 11(3), 298. https://doi.org/10.3390/electronics11030298