
Parallelism-Aware Channel Partition for Read/Write Interference Mitigation in Solid-State Drives



Abstract
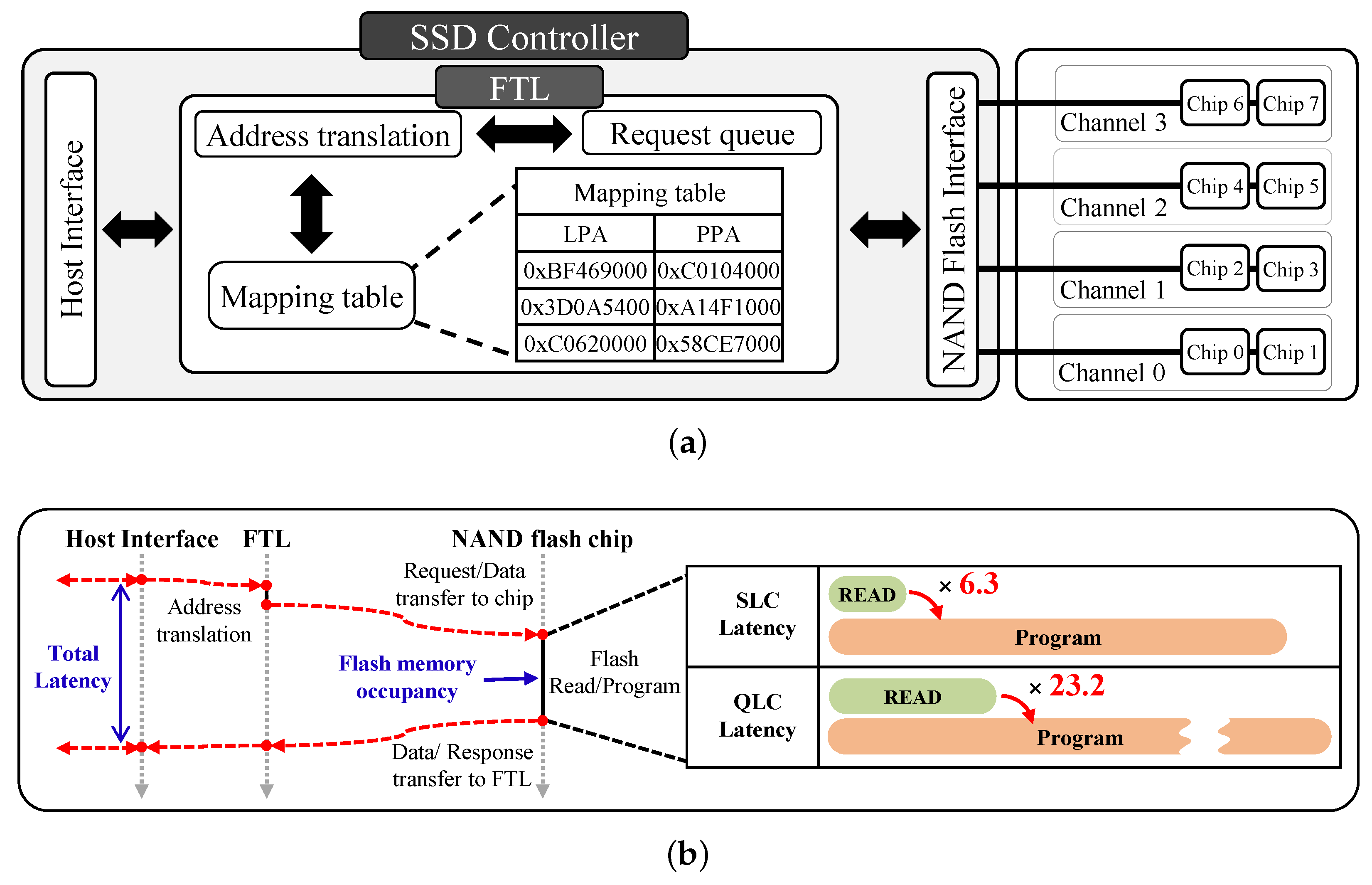
:1. Introduction
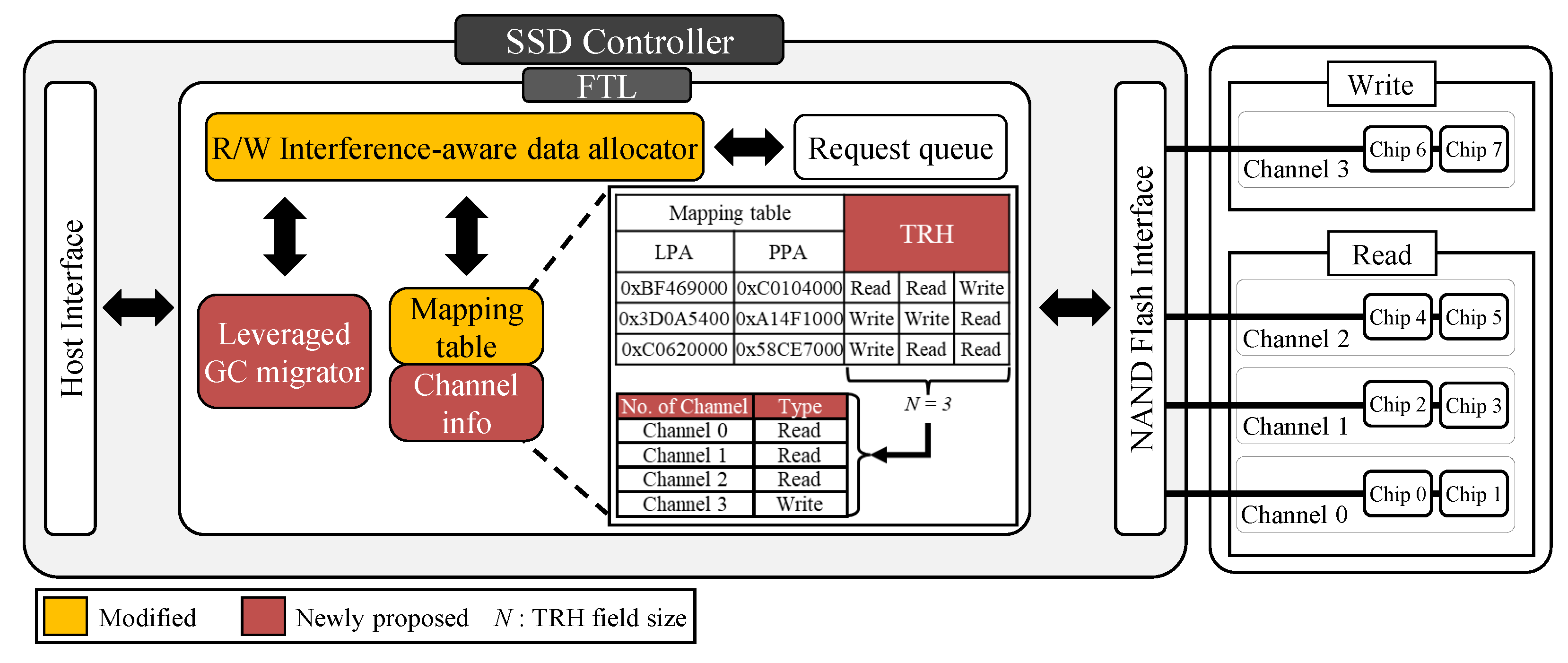
- SSD is partitioned at the channel level using the parallelism-aware channel partition technique to mitigate R/W interference, and latency is reduced by allocating pages leveraging transaction histories.
- The allocated channel is dynamically updated to maximally utilize the flash memory, even when the workload has highly imbalanced access characteristics.
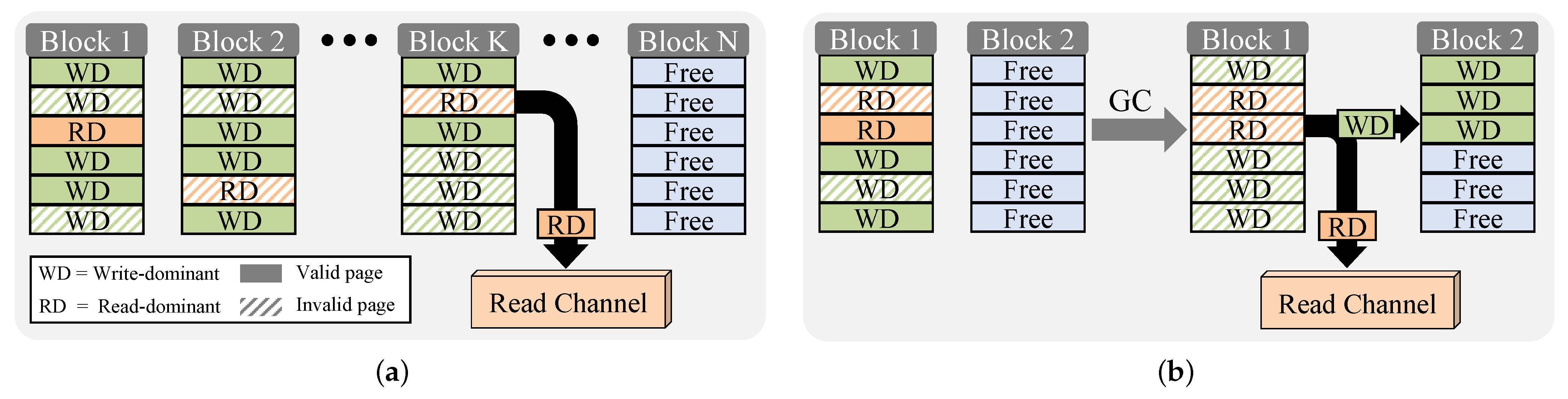
- Reallocating some pages vulnerable to R/W interference through a migration scheme is performed to address worst-case scenarios where latency can increase and leveraged garbage collection (GC) to minimize SSD performance overhead.
2. Related Work
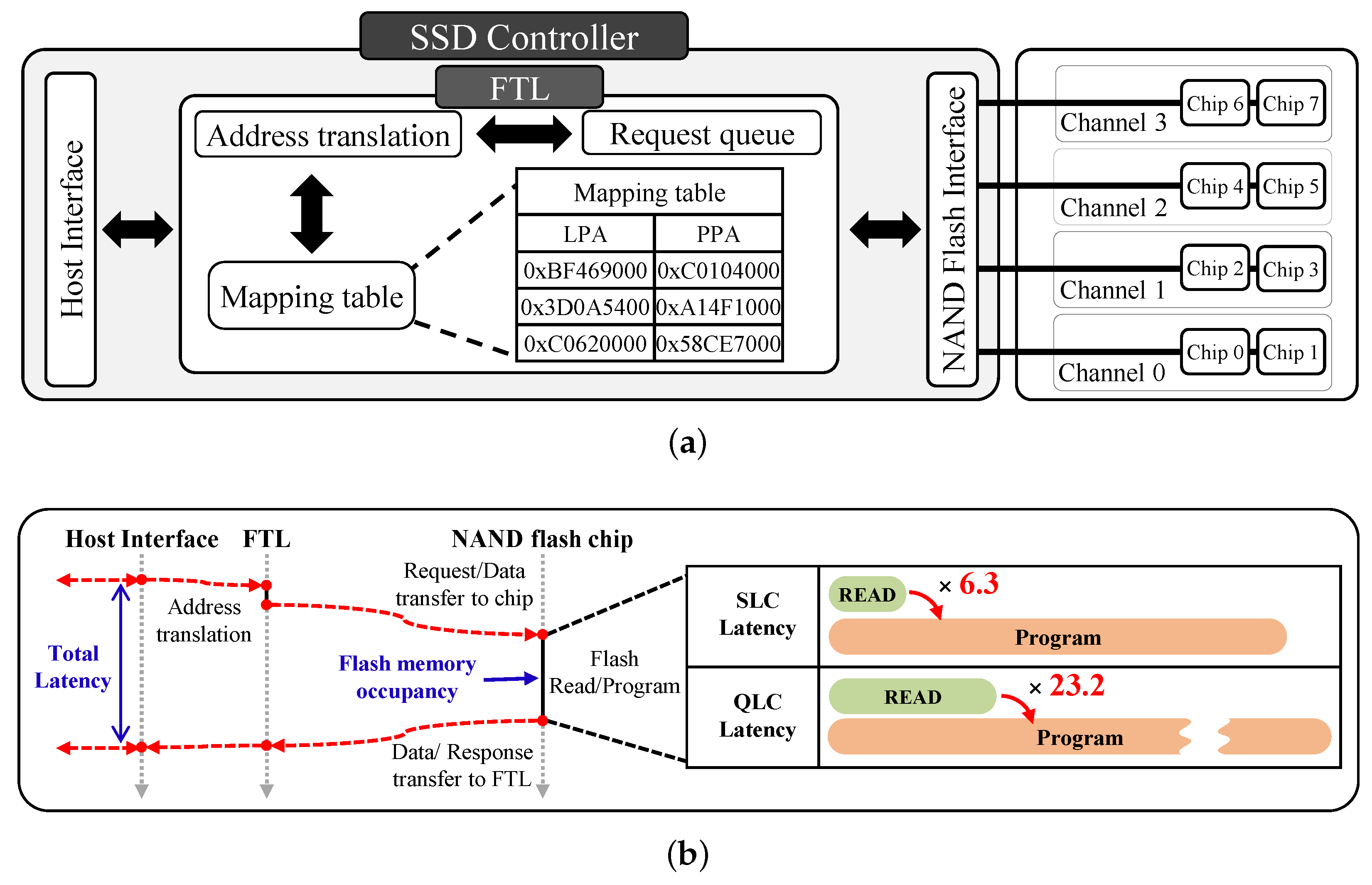
3. Parallelism-Aware-Channel-Partition (PACP)
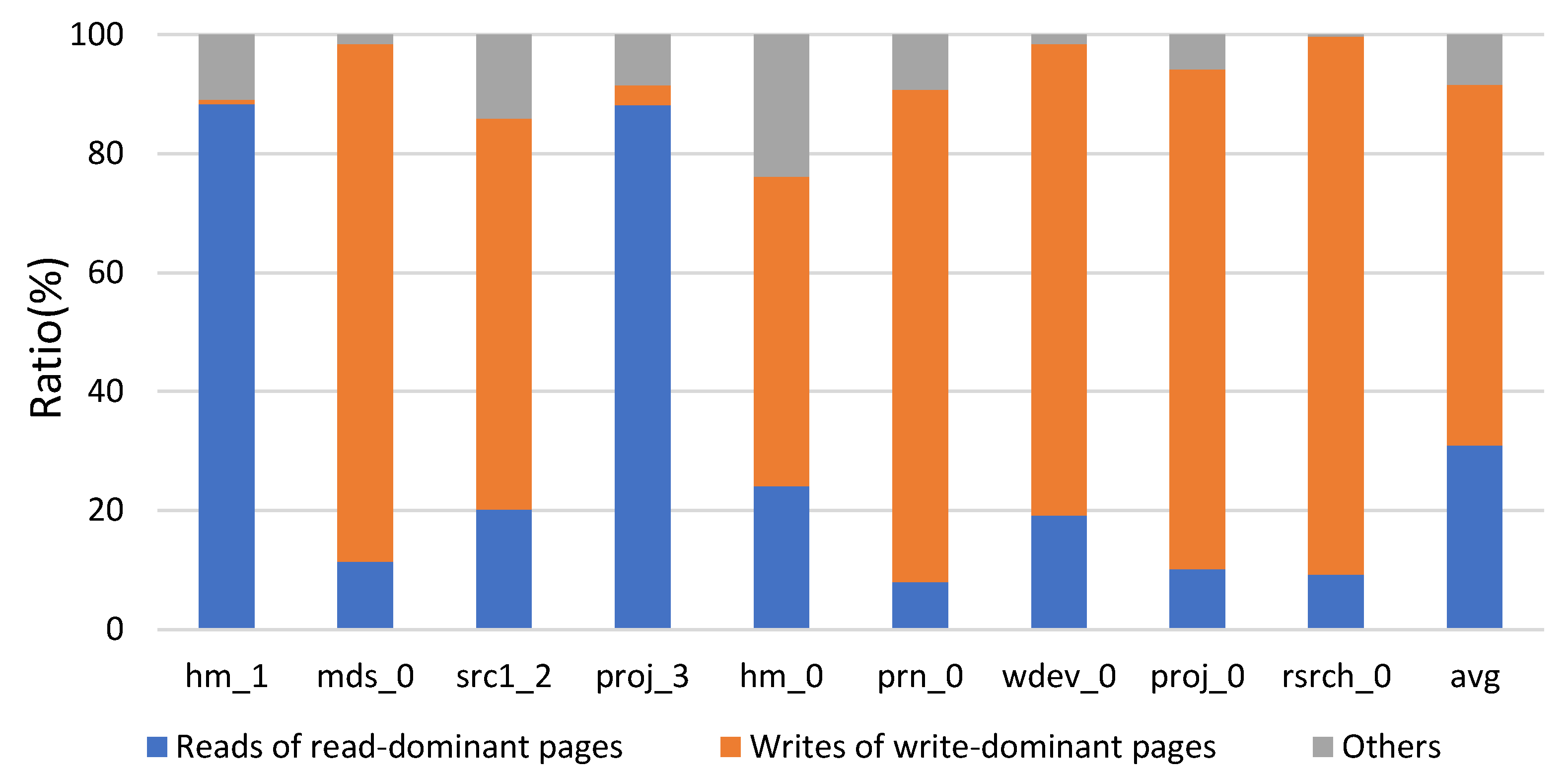
3.1. Request Prediction on Page
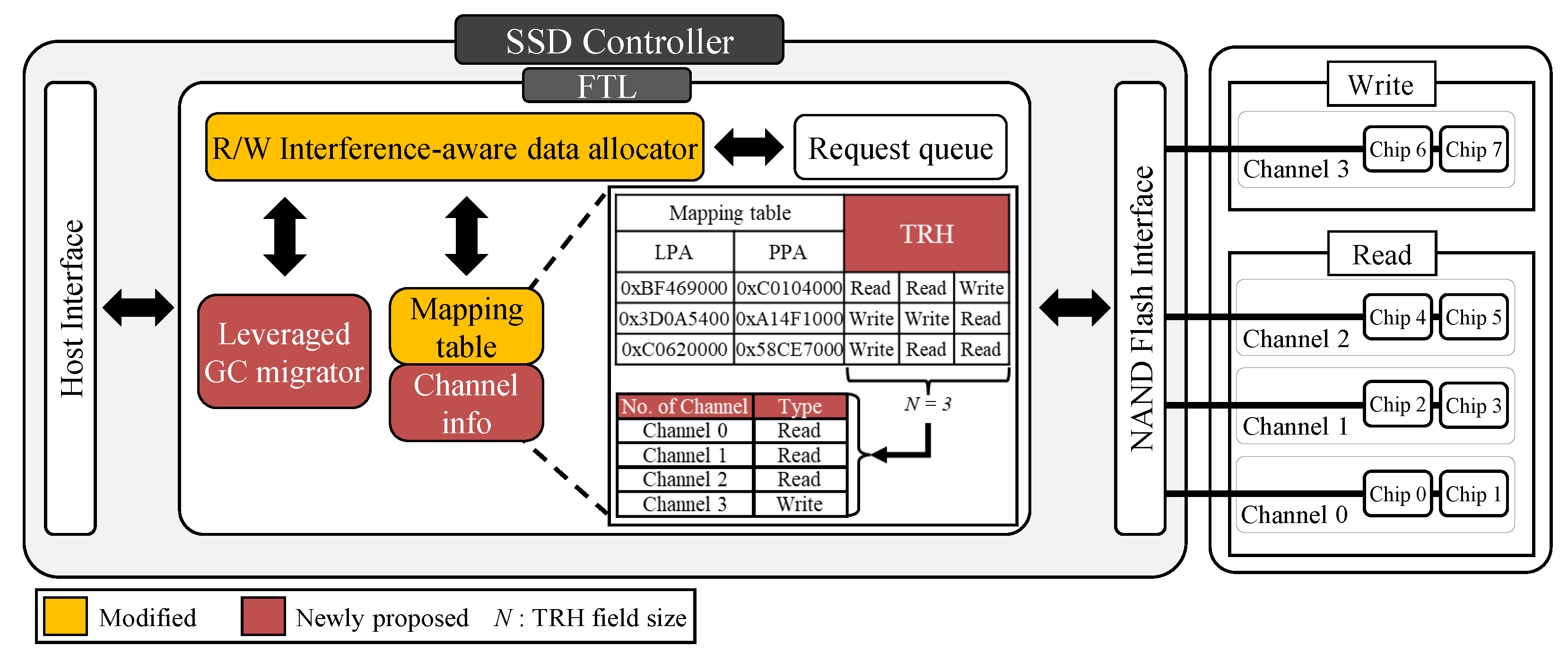
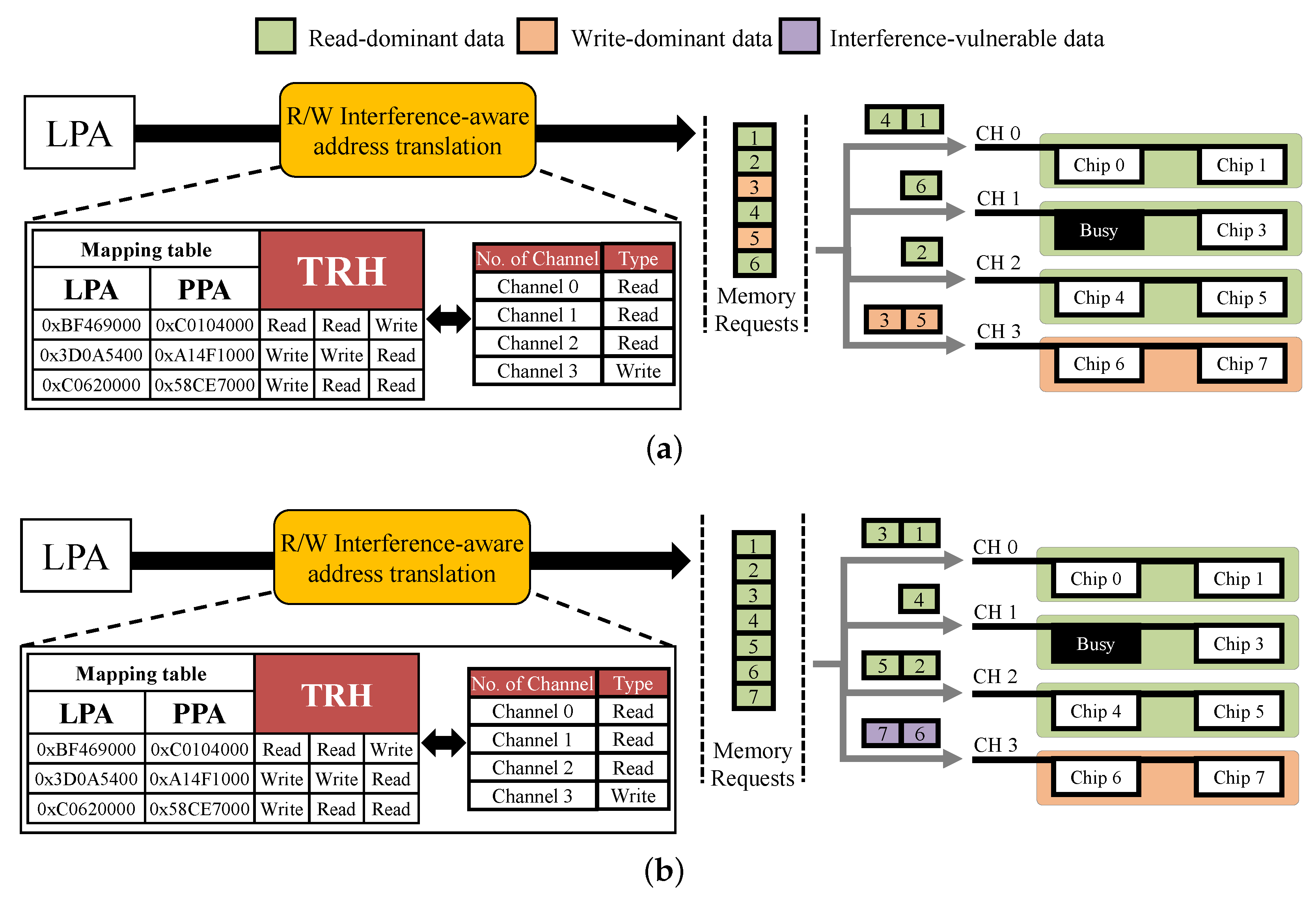
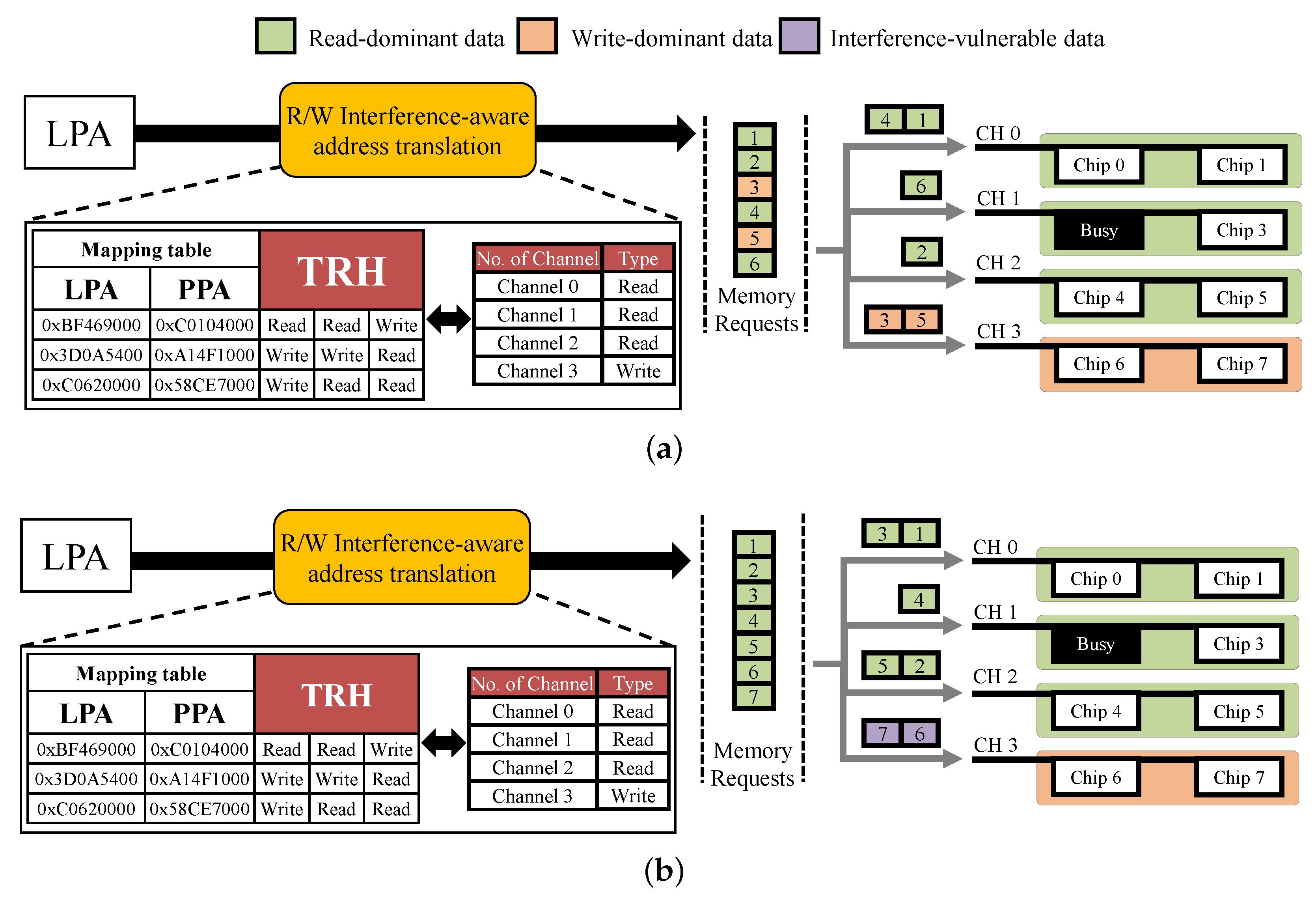
3.2. R/W-Interference-Aware Page Allocation
| Algorithm 1 R/W-interference-aware data allocation. |
| Input: Each channel type info: C = {C, C} Logical page address: LPA N transaction histories of the LPA: TRH Output: Physical page address: PPA
|
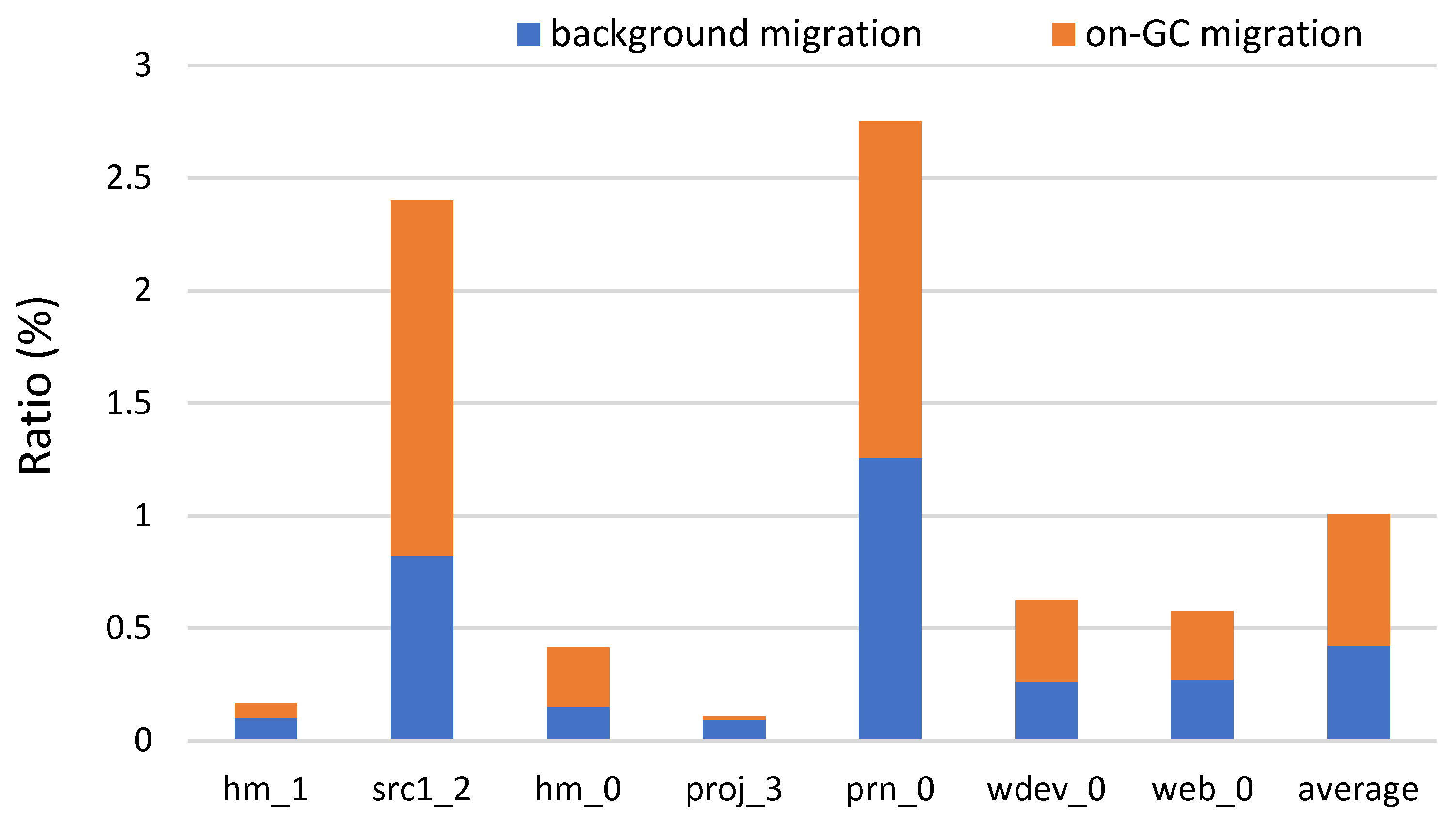
3.3. Leveraged GC Migration
3.4. Lifespan Discussion
4. Evaluation
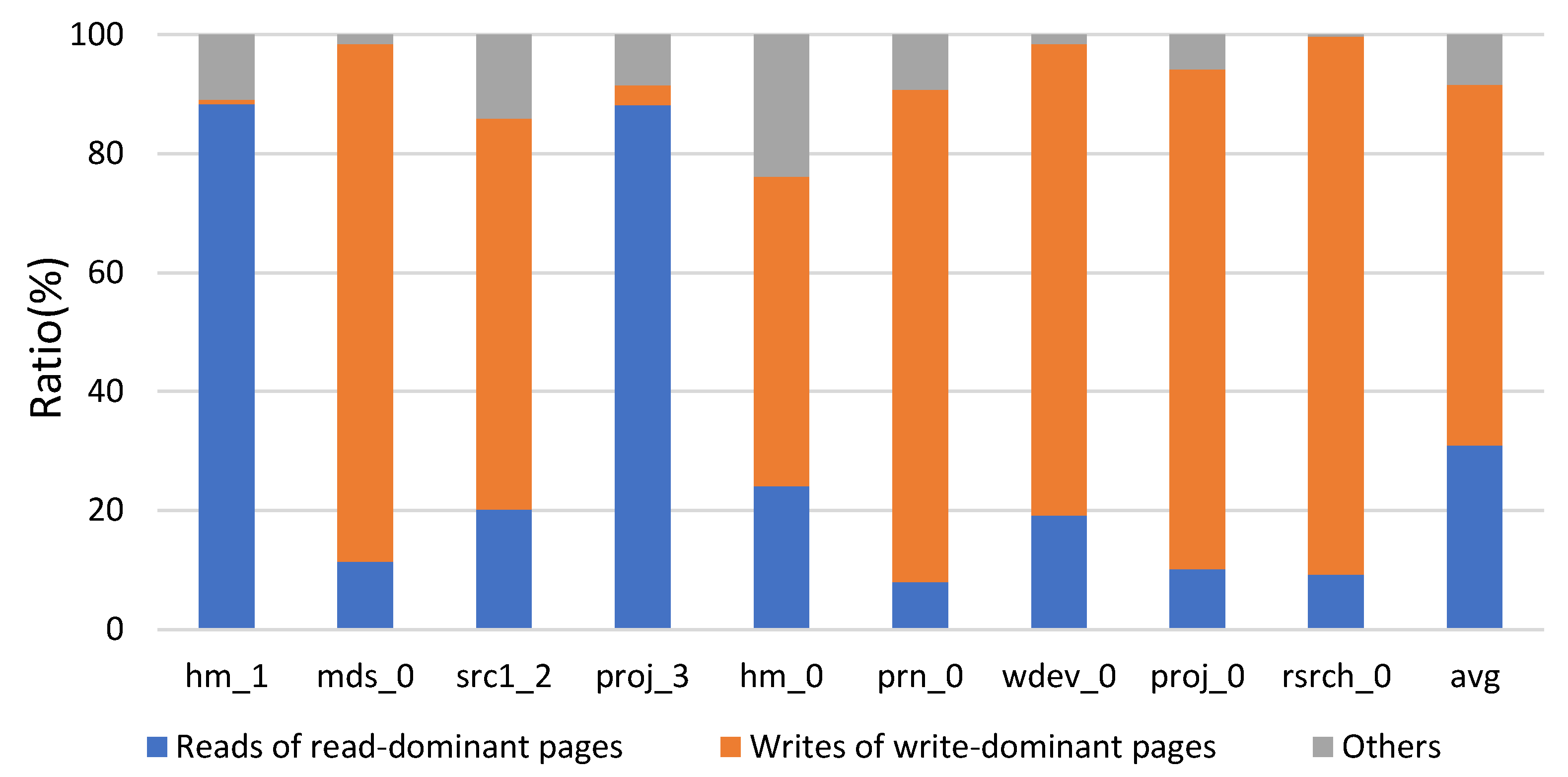
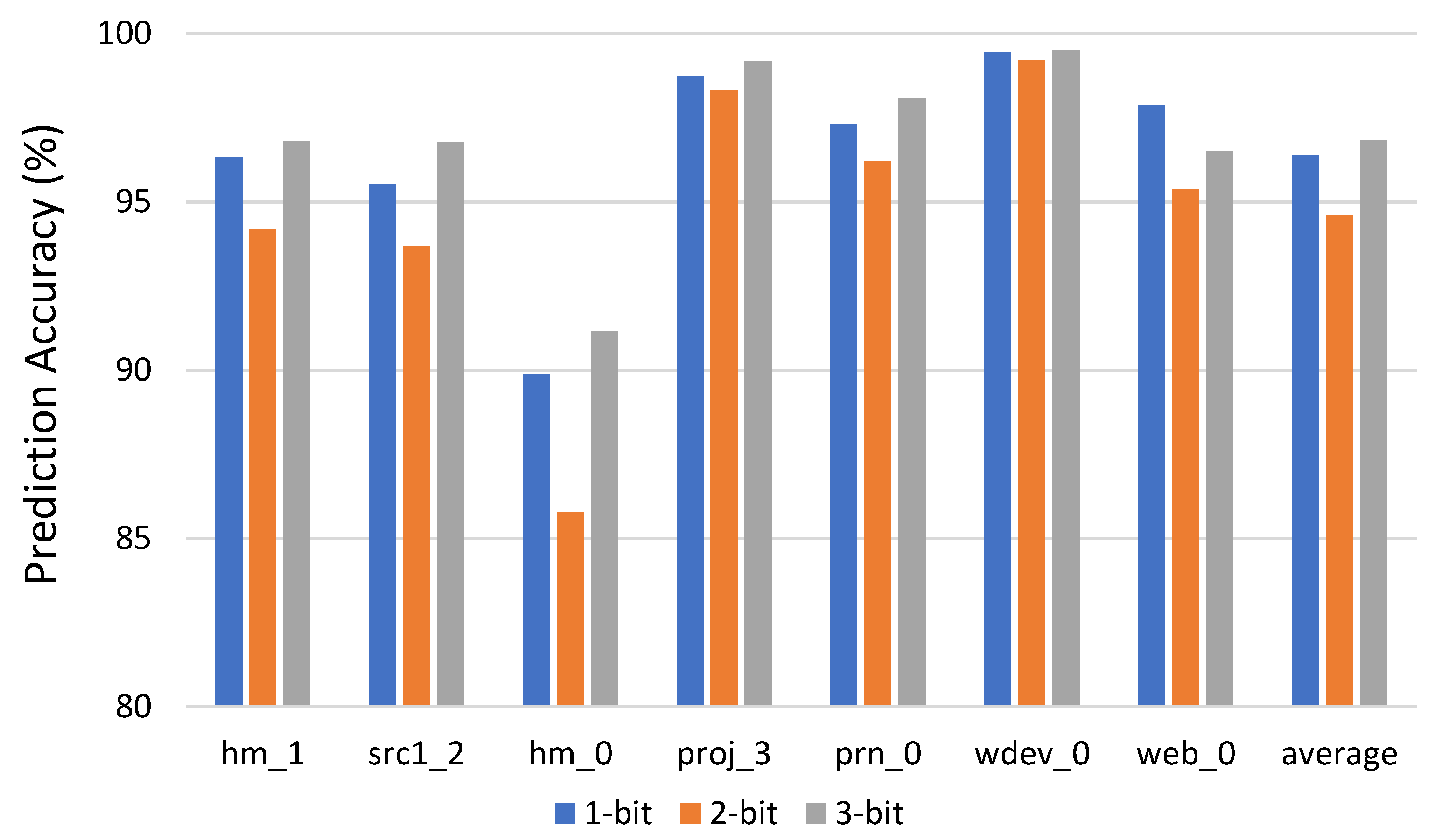
4.1. Prediction Accuracy Based on TRH
4.2. PACP Latency Compared to Ideal
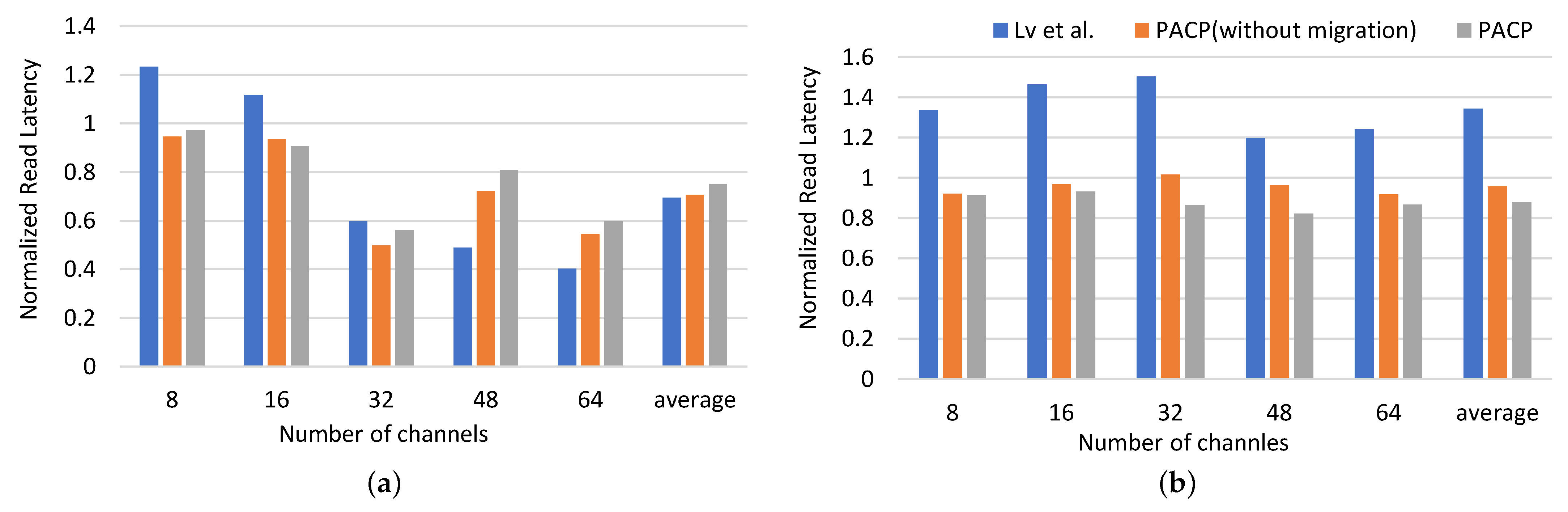
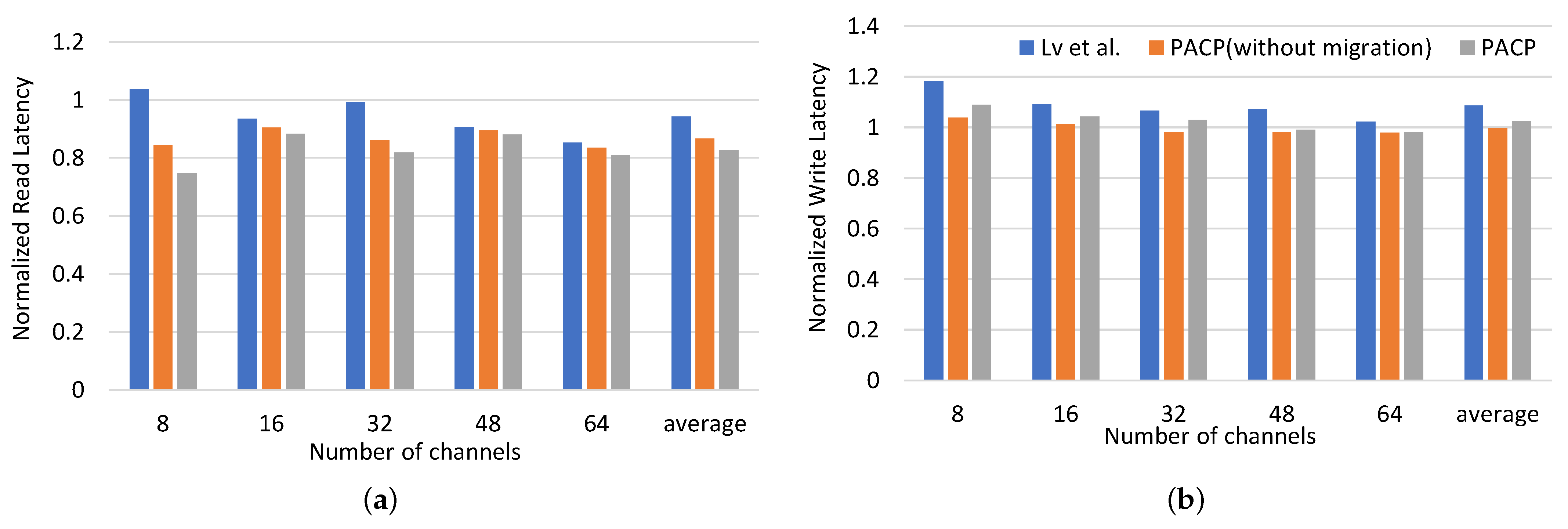
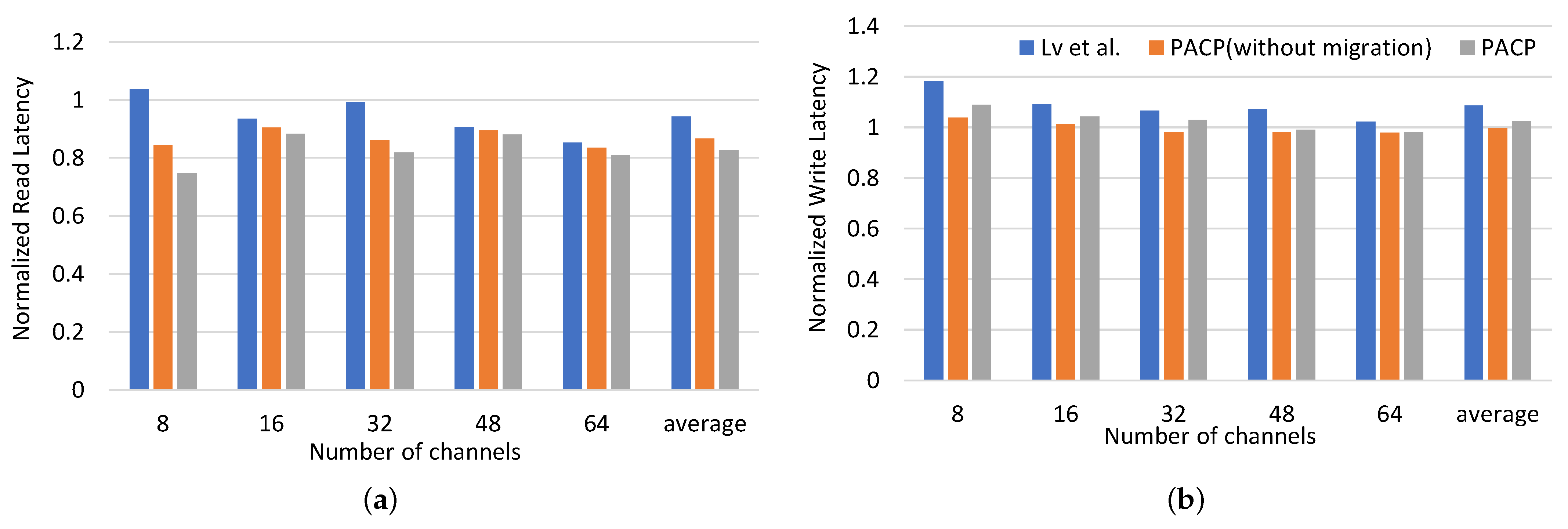
4.3. Overall Comparison with Existing Solution
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhao, C.; Jin, L.; Li, D.; Xu, F.; Zou, X.; Zhang, Y.; Song, Y.; Wei, H.; Chen, Y.; Li, C.; et al. Investigation of threshold voltage distribution temperature dependence in 3D NAND flash. IEEE Electron Device Lett. 2018, 40, 204–207. [Google Scholar] [CrossRef]
- Takai, Y.; Fukuchi, M.; Kinoshita, R.; Matsui, C.; Takeuchi, K. Analysis on heterogeneous ssd configuration with quadruple-level cell (qlc) nand flash memory. In Proceedings of the 2019 IEEE 11th International Memory Workshop (IMW), Monterey, CA, USA, 12–15 May 2019; pp. 1–4. [Google Scholar]
- Shin, J.Y.; Xia, Z.L.; Xu, N.Y.; Gao, R.; Cai, X.F.; Maeng, S.; Hsu, F.H. FTL design exploration in reconfigurable high-performance SSD for server applications. In Proceedings of the 23rd International Conference on Supercomputing, Heights, NY, USA, 8–12 June 2009; pp. 338–349. [Google Scholar]
- Hu, Y.; Jiang, H.; Feng, D.; Tian, L.; Luo, H.; Zhang, S. Performance impact and interplay of SSD parallelism through advanced commands, allocation strategy and data granularity. In Proceedings of the International Conference on Supercomputing, Tucson, AN, USA, 31 May–4 June 2011; pp. 96–107. [Google Scholar]
- Jung, M.; Kandemir, M.T. An Evaluation of Different Page Allocation Strategies on High-Speed SSDs. In Proceedings of the HotStorage, Boston, MA, USA, 13–14 June 2012. [Google Scholar]
- Hu, Y.; Jiang, H.; Feng, D.; Tian, L.; Luo, H.; Ren, C. Exploring and exploiting the multilevel parallelism inside SSDs for improved performance and endurance. IEEE Trans. Comput. 2012, 62, 1141–1155. [Google Scholar] [CrossRef]
- Tavakkol, A.; Mehrvarzy, P.; Arjomand, M.; Sarbazi-Azad, H. Performance evaluation of dynamic page allocation strategies in SSDs. ACM Trans. Model. Perform. Eval. Comput. Syst. (TOMPECS) 2016, 1, 1–33. [Google Scholar] [CrossRef]
- Wu, G.; He, X. Reducing SSD read latency via NAND flash program and erase suspension. In Proceedings of the FAST, San Jose, CA, USA, 12–15 February 2013; Volume 12, p. 10. [Google Scholar]
- Park, S.; Shen, K. FIOS: A fair, efficient flash I/O scheduler. In Proceedings of the FAST, San Jose, CA, USA, 12–15 February 2013; Volume 12, p. 13. [Google Scholar]
- Zhang, Q.; Feng, D.; Wang, F.; Xie, Y. An efficient, QoS-aware I/O scheduler for solid state drive. In Proceedings of the 2013 IEEE 10th International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing, Zhangjiajie, China, 13–15 November 2013; pp. 1408–1415. [Google Scholar]
- Gao, C.; Shi, L.; Zhao, M.; Xue, C.J.; Wu, K.; Sha, E.H.M. Exploiting parallelism in I/O scheduling for access conflict minimization in flash-based solid state drives. In Proceedings of the 2014 30th Symposium on Mass Storage Systems and Technologies (MSST), Santa Clara, CA, USA, 2–6 June 2014; pp. 1–11. [Google Scholar]
- Huang, J.; Badam, A.; Caulfield, L.; Nath, S.; Sengupta, S.; Sharma, B.; Qureshi, M.K. {FlashBlox}: Achieving Both Performance Isolation and Uniform Lifetime for Virtualized {SSDs}. In Proceedings of the 15th USENIX Conference on File and Storage Technologies (FAST 17), Santa Clara, CA, USA, 27 February–2 March 2017; pp. 375–390. [Google Scholar]
- Huang, S.M.; Chang, L.P. Providing SLO compliance on NVMe SSDs through parallelism reservation. ACM Trans. Des. Autom. Electron. Syst. (TODAES) 2018, 23, 1–26. [Google Scholar] [CrossRef]
- Lv, Y.; Shi, L.; Li, Q.; Xue, C.J.; Sha, E.H.M. Access characteristic guided partition for read performance improvement on solid state drives. In Proceedings of the 2020 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 20–24 July 2020; pp. 1–6. [Google Scholar]
- Kim, J.; Kim, D.; Won, Y. Fair I/O scheduler for alleviating read/write interference by forced unit access in flash memory. In Proceedings of the 14th ACM Workshop on Hot Topics in Storage and File Systems, Virtual, 27–28 June 2022; pp. 86–92. [Google Scholar]
- Nanavati, M.; Wires, J.; Warfield, A. Decibel: Isolation and Sharing in Disaggregated {Rack-Scale} Storage. In Proceedings of the 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17), Boston, MA, USA, 27–29 March 2017; pp. 17–33. [Google Scholar]
- Song, X.; Yang, J.; Chen, H. Architecting flash-based solid-state drive for high-performance I/O virtualization. IEEE Comput. Archit. Lett. 2013, 13, 61–64. [Google Scholar] [CrossRef]
- Narayanan, D.; Thereska, E.; Donnelly, A.; Elnikety, S.; Rowstron, A. Migrating server storage to SSDs: Analysis of tradeoffs. In Proceedings of the 4th ACM European Conference on Computer Systems, Nuremberg, Germany, 1–3 April 2009; pp. 145–158. [Google Scholar]
- Li, Q.; Shi, L.; Xue, C.J.; Wu, K.; Ji, C.; Zhuge, Q.; Sha, E.H.M. Access characteristic guided read and write cost regulation for performance improvement on flash memory. In Proceedings of the 14th USENIX Conference on File and Storage Technologies (FAST 16), Santa Clara, CA, USA, 22–25 February 2016; pp. 125–132. [Google Scholar]
- Wu, S.; Zhang, W.; Mao, B.; Jiang, H. HotR: Alleviating read/write interference with hot read data replication for flash storage. In Proceedings of the 2019 Design, Automation & Test in Europe Conference & Exhibition (DATE), Florence, Italy, 9–13 March 2019; pp. 1367–1372. [Google Scholar]
- Tavakkol, A.; Gómez-Luna, J.; Sadrosadati, M.; Ghose, S.; Mutlu, O. {MQSim}: A Framework for Enabling Realistic Studies of Modern {Multi-Queue}{SSD} Devices. In Proceedings of the 16th USENIX Conference on File and Storage Technologies (FAST 18), Oakland, CA, USA, 12–15 February 2018; pp. 49–66. [Google Scholar]
- Subramani, R.; Swapnil, H.; Thakur, N.; Radhakrishnan, B.; Puttaiah, K. Garbage collection algorithms for nand flash memory devices–an overview. In Proceedings of the 2013 European Modelling Symposium, Manchester, UK, 20–22 November 2013; pp. 81–86. [Google Scholar]
- Han, K.; Shin, D. Remap-based Inter-Partition Copy for Arrayed Solid-State Drives. IEEE Trans. Comput. 2021. [Google Scholar] [CrossRef]
- Kim, J.; Lim, K.; Jung, Y.; Lee, S.; Min, C.; Noh, S.H. Alleviating garbage collection interference through spatial separation in all flash arrays. In Proceedings of the 2019 USENIX Annual Technical Conference (USENIX ATC 19), Renton, WA, USA, 10–12 July 2019; pp. 799–812. [Google Scholar]


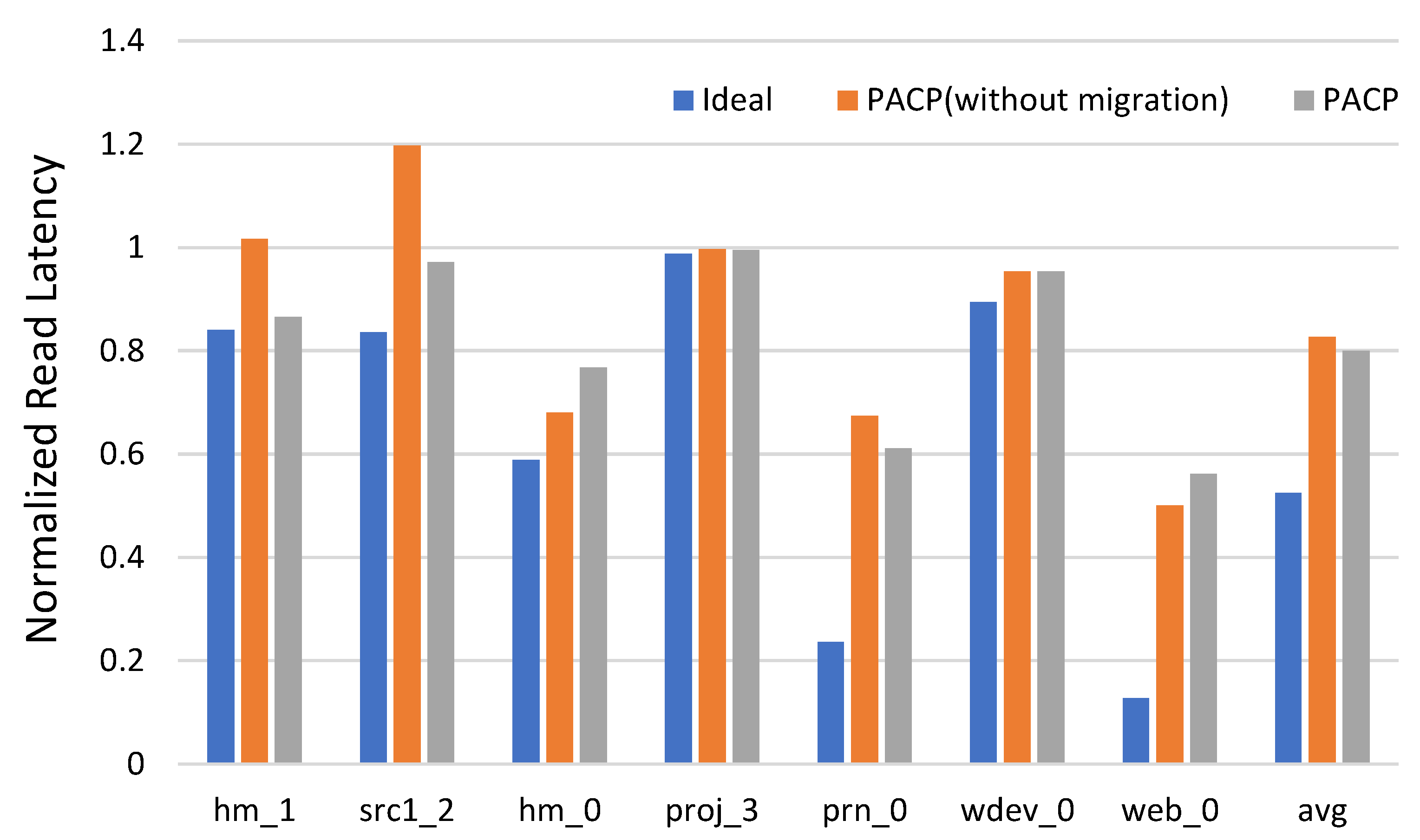


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
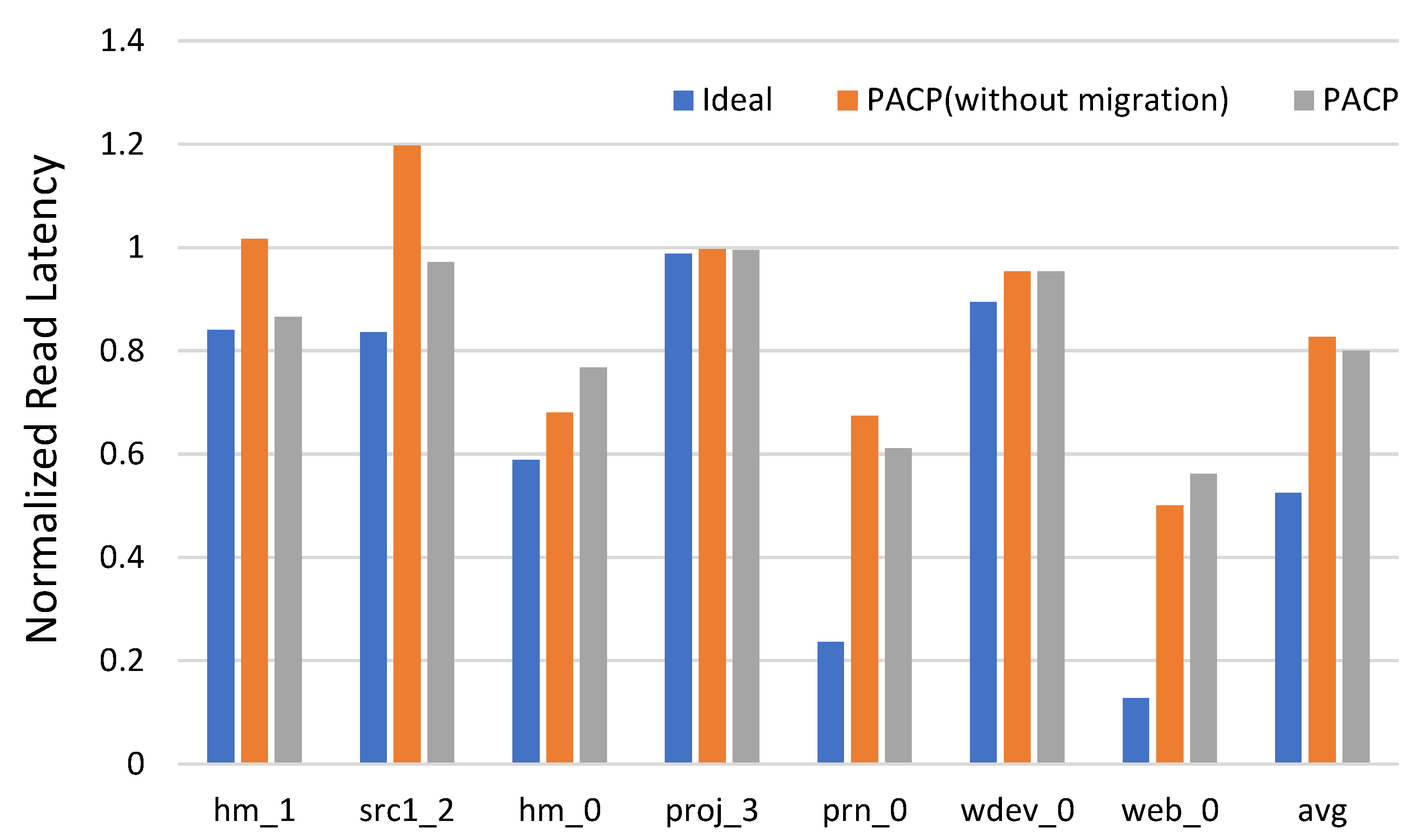{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Scheme | Main Idea | Advantages | Limitations |
|---|---|---|---|---|
| P/E suspension | Wu et al. [8] | Suspend on-going P/E operations | Significantly decrease the read latency | System & hardware overhead Negative impact on the endurance |
| I/O scheduling | FIOS [9] | Separates reads and writes in batches | No hardware modification | Read and write requests only separated in batches |
| BCQ [10] | ||||
| PIQ [11] | ||||
| Performance isolation | Kim et al. [12] | Eliminating interference from different tenants that share the SSD | Significantly decrease R/W interference between tenants | Interference within the workload has not been addressed |
| Huang et al. [13] | ||||
| Lv et al. [14] | Allocate different types of requests into different partitions | Significantly decreases R/W interference | Channel utilization problem has not been given sufficient consideration |
| NAND Flash Parameters | Value |
|---|---|
| Number of Channels | 8–64 (8, 16, 32, 48, 64) |
| Number of Chips per Channel | 2 |
| Number of Dies per Flash Chip | 2 |
| Number of Planes per Die | 2 |
| Number of Blocks per Plane | 2048 |
| Number of Pages per Block | 256 |
| Page Size (KB) | 4 |
| Page Read Latency (s) | 140 |
| Page Program Latency (s) | 3102 |
| Block Erase Latency (ms) | 3.5 |
| Workload | Read Ratio (%) | Write Ratio (%) |
|---|---|---|
| hm_1 | 95.3 | 4.7 |
| src1_2 | 25.3 | 74.7 |
| hm_0 | 35.5 | 64.5 |
| proj_3 | 93.5 | 6.5 |
| prn_0 | 10.8 | 89.2 |
| wdev_0 | 20.1 | 79.9 |
| web_0 | 29.9 | 70.1 |
| average | 44.3 | 65.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lim, H.J.; Shin, D.; Han, T.H. Parallelism-Aware Channel Partition for Read/Write Interference Mitigation in Solid-State Drives. Electronics 2022, 11, 4048. https://doi.org/10.3390/electronics11234048
Lim HJ, Shin D, Han TH. Parallelism-Aware Channel Partition for Read/Write Interference Mitigation in Solid-State Drives. Electronics. 2022; 11(23):4048. https://doi.org/10.3390/electronics11234048
Chicago/Turabian StyleLim, Hyun Jo, Dongkun Shin, and Tae Hee Han. 2022. "Parallelism-Aware Channel Partition for Read/Write Interference Mitigation in Solid-State Drives" Electronics 11, no. 23: 4048. https://doi.org/10.3390/electronics11234048
APA StyleLim, H. J., Shin, D., & Han, T. H. (2022). Parallelism-Aware Channel Partition for Read/Write Interference Mitigation in Solid-State Drives. Electronics, 11(23), 4048. https://doi.org/10.3390/electronics11234048