Spectral Data Analysis for Forgery Detection in Official Documents: A Network-Based Approach




Abstract

1. Introduction
- The level of complexity and computational burden;
- Efficiency and detection rates;
- Ease of use and accessibility by non-experts;
- Adoption costs.
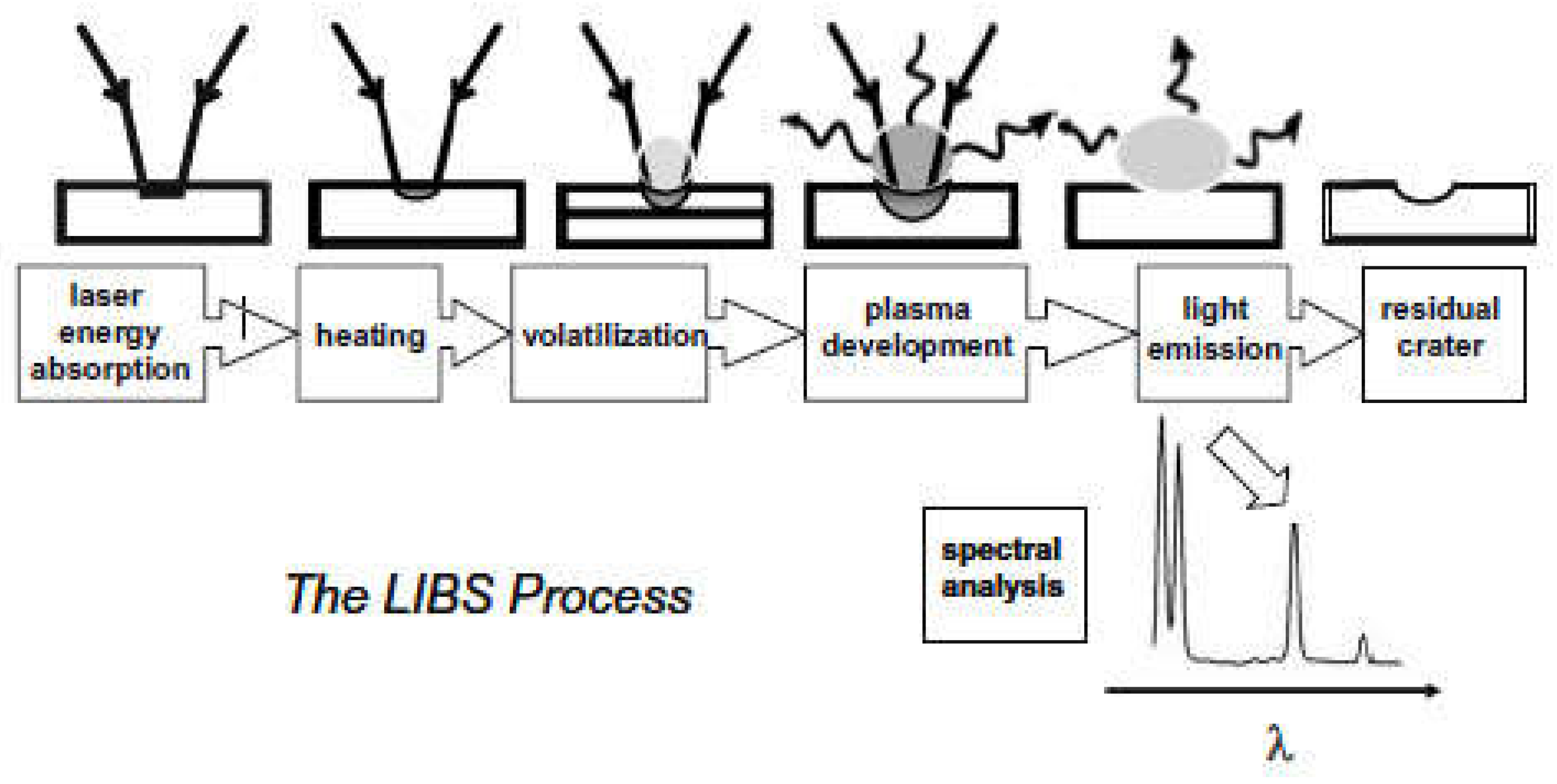
2. Laser-Induced Breakdown Spectroscopy
- Laser source: generates the light pulses used to create the plasma plume;
- Focusing optics: the optical system used to focus the laser beam on the target material;
- Target container: place a sample that needs to be hit by the laser;
- Sample: the sample to be tested (this component relates mostly to the test);
- Light collection unit: collects and transports the plasma spectrum wavelengths to the detection system through fiber optical cable;
- Spectral analysis unit: a detection system (or spectrum analyzer) used to provide the spectral analysis of the emitted light of the target by spectrally dispersing the light;
- Detector: collects and records the resulting spectrum records them in terms of intensity and wavelength;
- Computer: to control the laser synchronization, detector gating, and other configurations and store the spectrum;
- Delay-gate generator: used to provide a specific time delay before the spectrum analyzer starts to collect the emitted light from the plasma.
- Materials’ elemental analysis in solids, gases, and liquids;
- Can detect and analyze all sample elements simultaneously with a single laser pulse;
- It is low cost compared to other conventional techniques (e.g., LA-ICP-MS);
- Can be miniaturized and portable to allow the field analysis of evidence to be at or near a crime scene;
- Analysis of solid materials directly, without the need to solubilize the material;
- Because each laser pulse ablates a small quantity of material (in the nanograms to picograms range) during the LIBS operation, the technology is deemed non-destructive;
- LIBS is a speedy technique; the ablation and evaporation processes are executed in one step;
- Possible multi-elemental simultaneous analysis;
- LIBS technique does not require sample preparation as in other spectroscopic techniques.
- Difficult to get suitable standards (semi-quantitative);
- Precision decreases by (usually 5–10%) as compared with other spectroscopic techniques;
- It cannot be believed that spectra acquired from the same material using different LIBS instruments would match perfectly. This is because the strength of emission lines is determined by the specific system settings and components employed (spectrometer, detector, laser, optics);
- Other limitations such as spectral matrix interference, sample heterogeneity, and differences in physical properties of the sample (e.g., reflectivity and hardness of the surface).
3. Research Method
3.1. General Workflow and Testing Scenarios
3.1.1. Scenario 1: Comparing a Questioned Document with an Original Document
| Algorithm 1: General workflow of the proposed approach. |
| Input: two documents: Original (DO) and Questioned (DQ) Output: Whether the DQ is forged START Step1: SET LIBS configurations Step2: ACQUIRE 5 LIBS spectra for each DO and DQ Step3: CREATE the Correlation Matrix (CM) among the acquired spectra Step4: CONVERT the CM into Adjacency Matrix (AM) Step5: FORMALIZE AM into a dataset of nodes and edges and create the network in Cytoscape software Step6: APPLY Clustering algorithms Step7: IF # of Clusters =1 THEN DQ is Original ELSE DQ is Forged END |
3.1.2. Scenario 2: Detecting Partially Forged Documents
3.1.3. Scenario 3: Identification of Printer Type
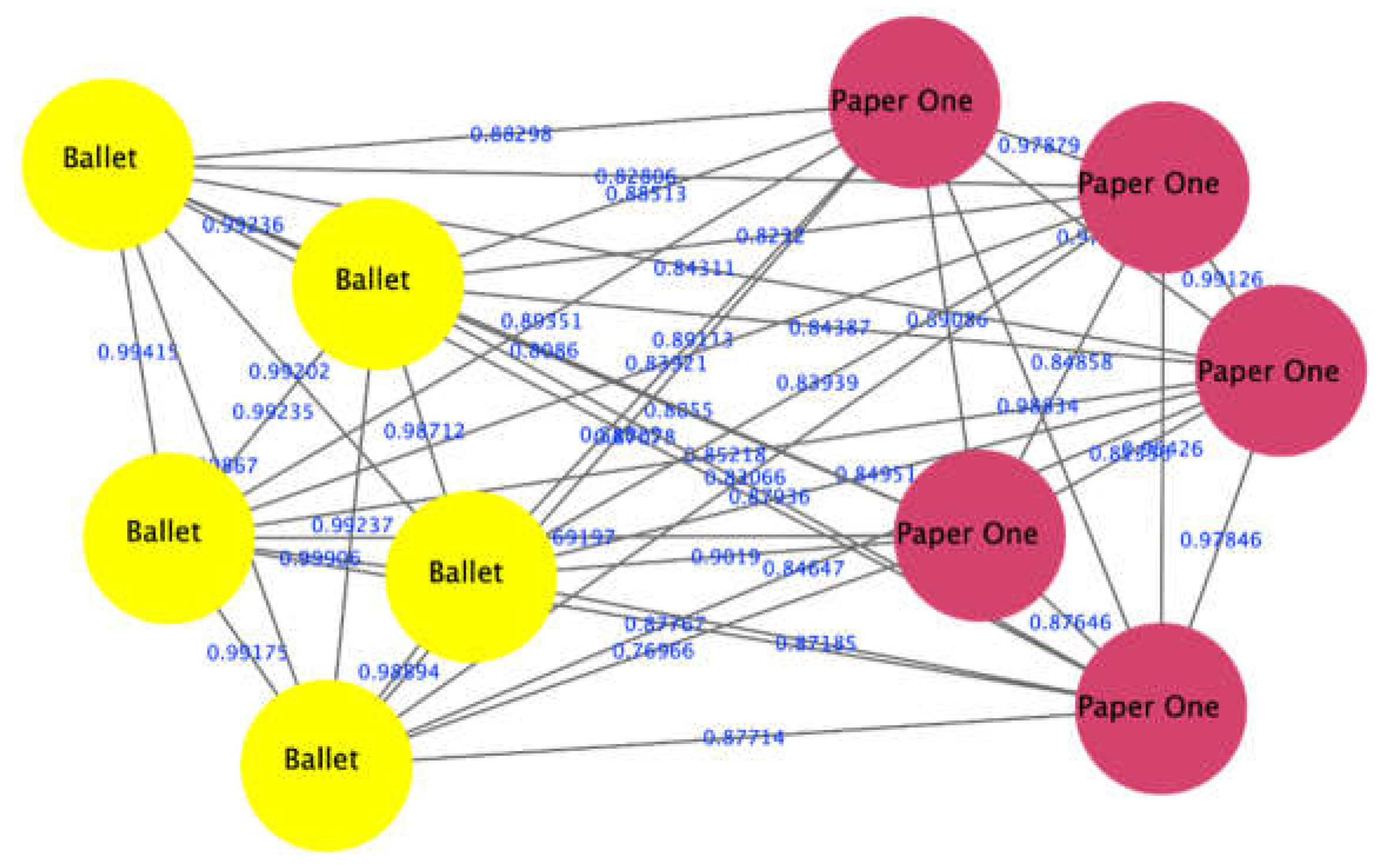
3.1.4. Scenario 4: Identification of Paper Types
3.1.5. Scenario 5: Comparing Different Clustering Algorithms
3.2. LIBS Setup and Spectroscopy of Samples
- The plasma was produced using a Q-switch Nd: YAG laser generating 1064 nm with a pulse length of 10 ns;
- The measurements were made using a laser pulse energy of 120 mJ;
- The laser beam was focused onto the sample surface using a converging lens with a focal length of 100 mm;
- The target was put in the sampling stand, with a separation of 10 cm between the focusing lens and the sample;
- The optical fiber was set at a 45° angle, with the beam axis 5 cm away from the sample;
- The light emitted from the laser-induced plasma was gathered and focused on the optical fiber apertures, diameter (200 m/0.22 NA) by a collimator lens (perfectly matched with the optical fiber entry);
- A spectrum analyzer (Model Spectra View 2100) with a grating and charge-coupled device (CCD) was used to receive and disperse the emitted spectrum of the target by fiber optical cable and record it in terms of intensity against wavelength;
- For recording the spectrum in the PC, the LIBS was supplemented by Visual Spectra 2.1 software. The wavelength was captured between the wavelengths of 173.0 and 956.0 nm.
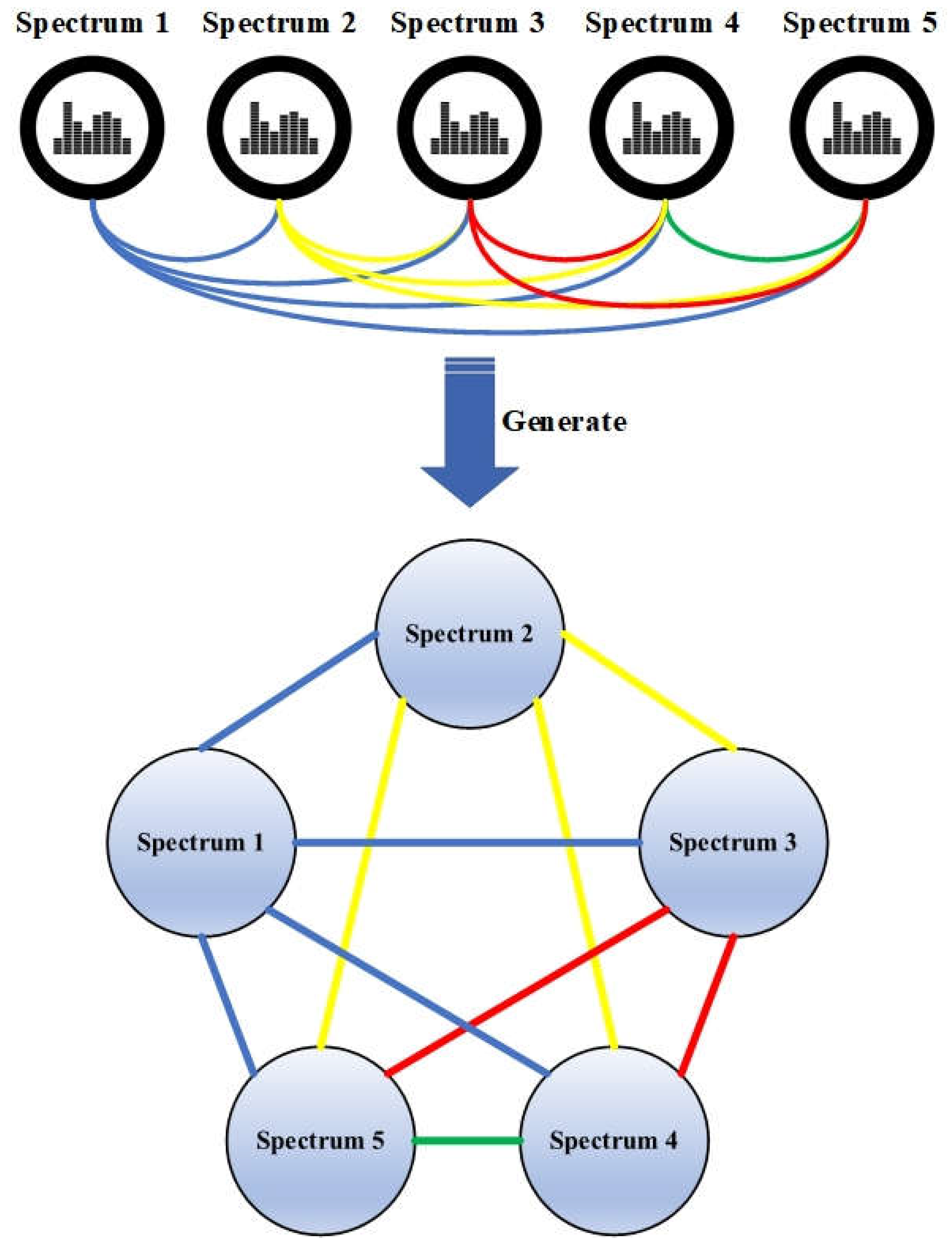
3.3. Data Processing and Network Construction
Calculating the Correlation Matrix
3.4. Network Construction
3.5. Network Clustering
3.6. Louvain Algorithm
3.7. K-Medoids Algorithm
- Initialization: select k random points from n data as medoids m;
- Correspond each data point to the nearest medoid using one of the distance metric methods;
- For each medoid m, while the cost is reduced for each data point p:
- Swap p and m, then correspond each data point to the nearest medoid and recalculate the cost;
- If the cost is higher than the previous step, undo the swap.
3.8. Farthest First Traversal Algorithm (FFT)
| Algorithm 2: The steps of FTT algorithm. |
| START INPUT: P and N points ∈ (M, d) OUTPUT: k-clustering (C) Step 1: SET S←Φ Step 2: For i from 1 to k Find ci∈ P-S that maximizes d(ci,S) SET S←S ∪ {ci} Step 3: Return Partition(P,S); where d(ci,S) represents the minimum distance of ci from a point of S: SET D(ci,S) = min {c∈S: d(ci,c)}; The assignment of points to clusters is achieved by detecting the center in the first loop. END |
3.9. The Proposed Clustering Algorithm
4. Results and Discussions
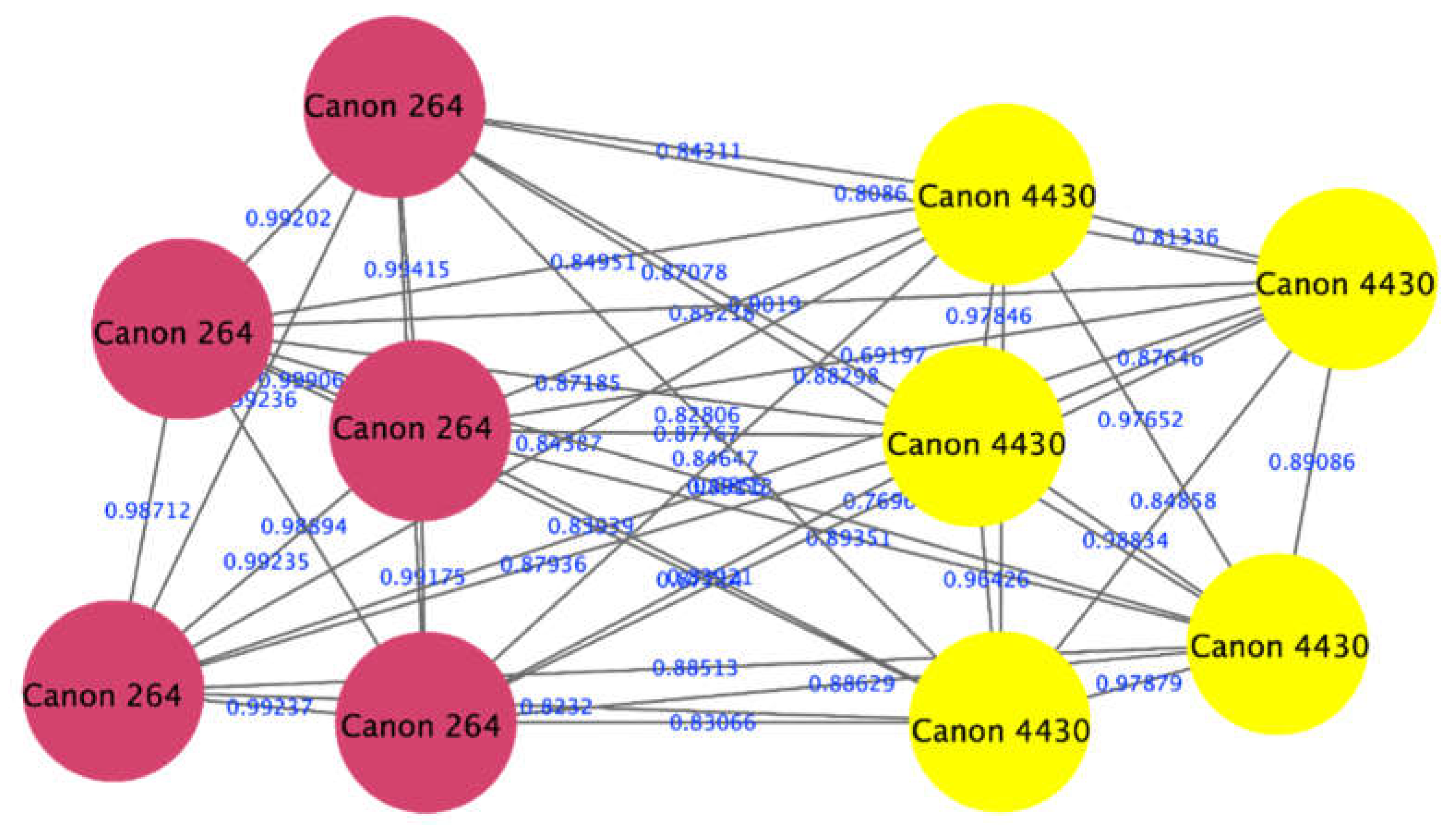
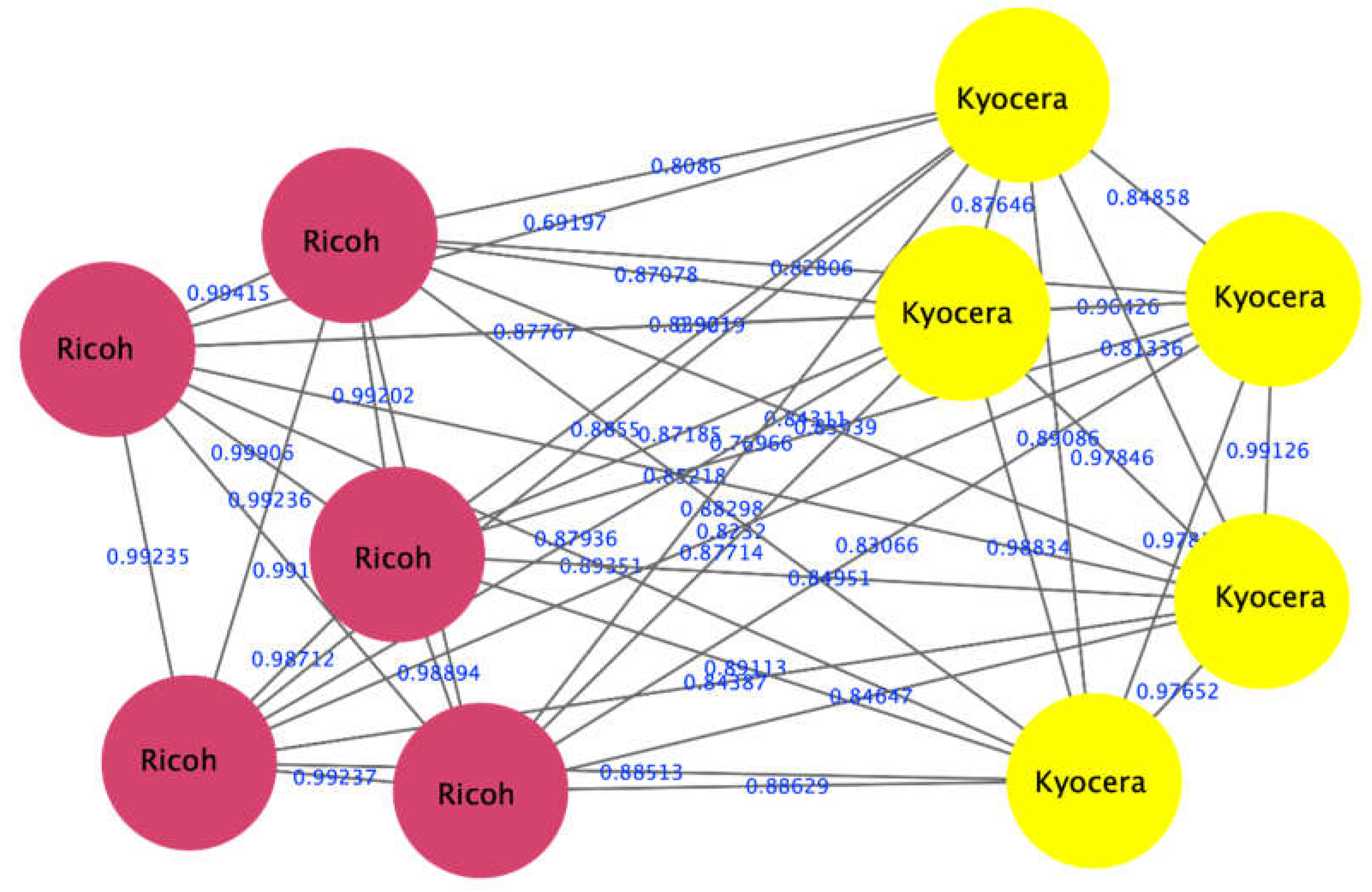
4.1. Laser vs. Laser Printers
4.2. Partially Forged Documents
4.3. Different Paper Types
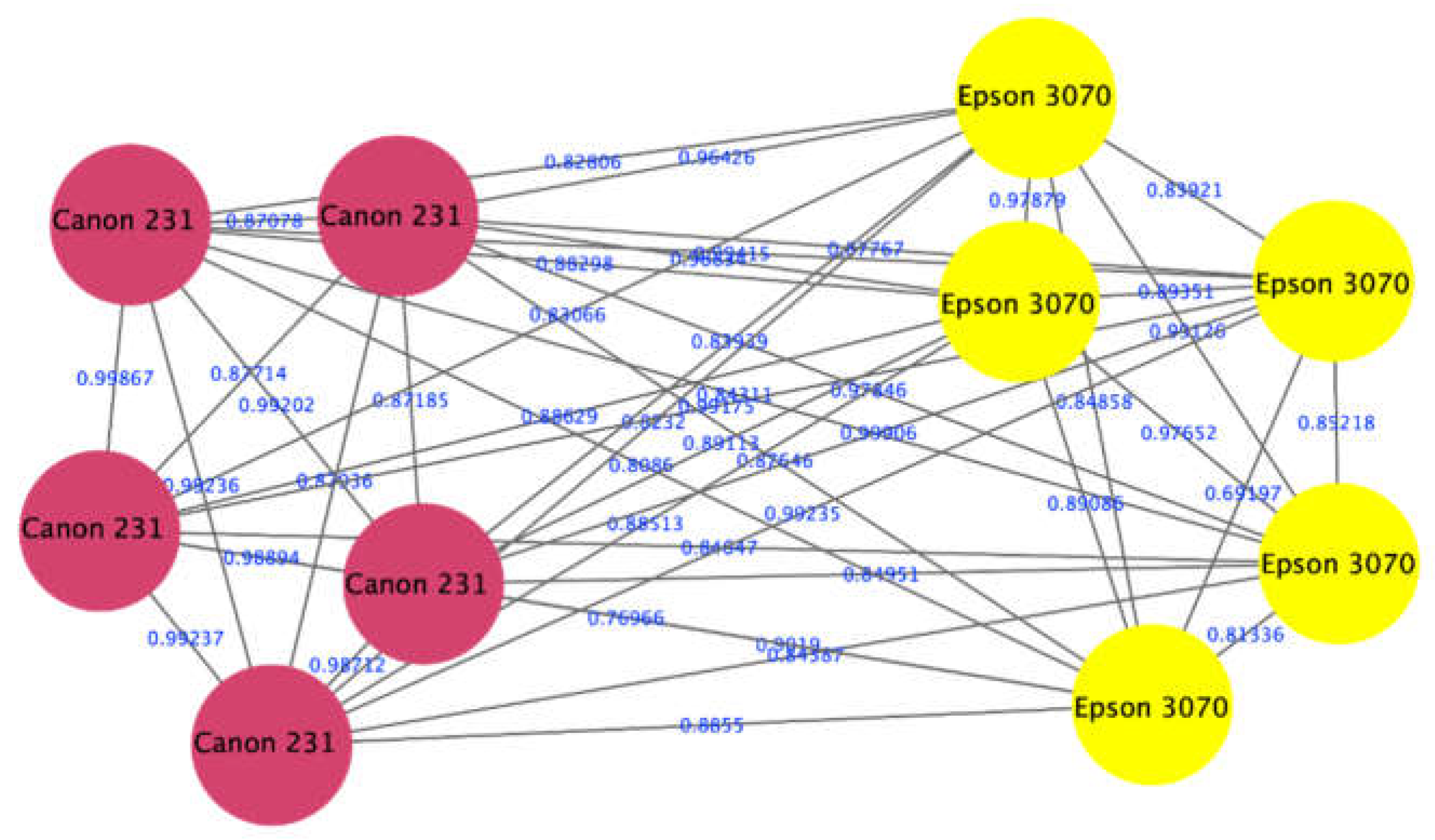
4.4. Laser vs. Inkjet Printers
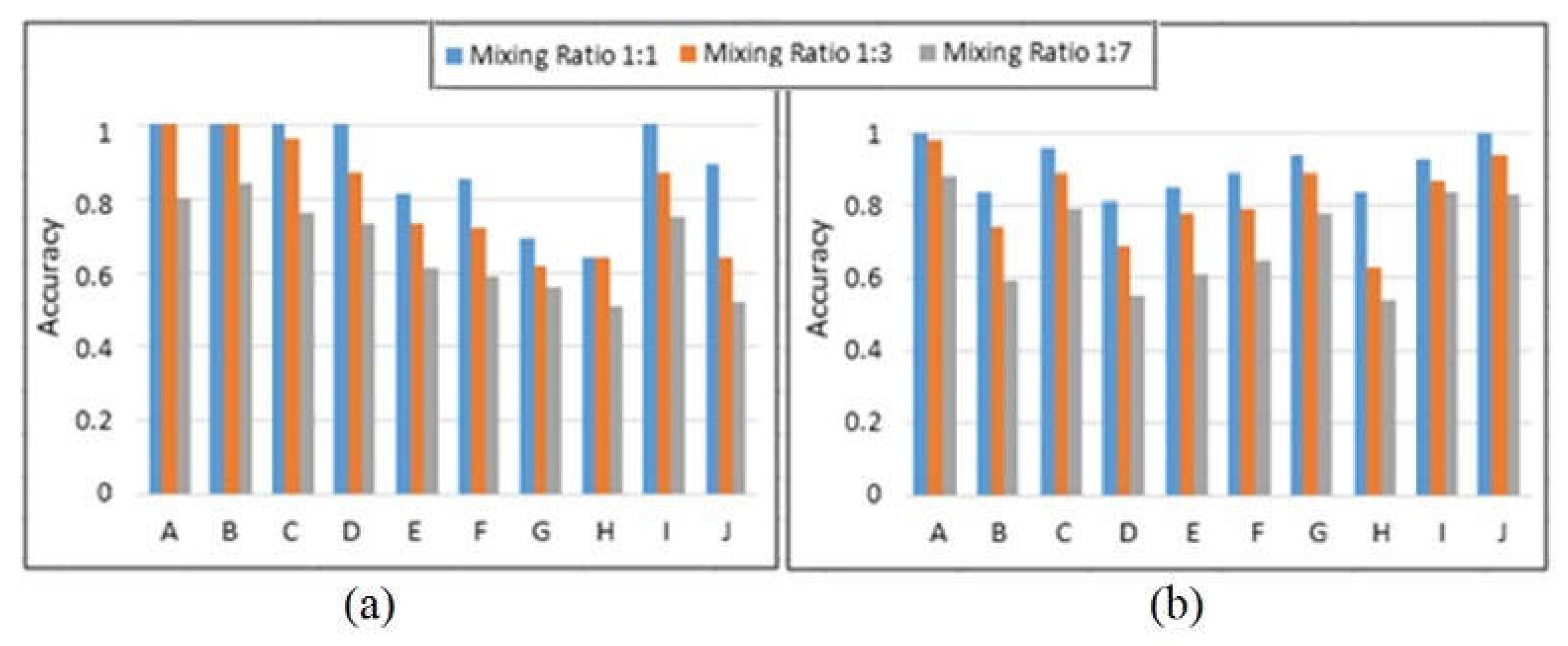
4.5. Benchmarking
4.6. Discussion
- The configuration of the LIBS device should be as described in the methods section. Changing these settings, according to the experiments, will alter the accuracy of the suggested technique;
- The laser used in the LIBS system must have high stability so that it must have an even distribution of energy in each pulse.
- -
- Low level of complexity compared to the benchmarking (see the execution times in Table 3);
- -
- High efficiency and detection rates, which was 92.08%;
- -
- Easy to use, and the results can be interpreted by non-experts through visualization;
- -
- Low adoption costs since it needs only LIBS scans and some semi-automated steps.
5. Conclusions
- To test the proposed approach in detecting forgery on writing inks, signatures, seals, and banknotes;
- To test the proposed approach in cases of overlaying different inks;
- To build a large database for various printer types, brands, and models that allows conducting analyses and clustering operations on future questioned documents to identify the printer used to print them.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khan, R.A.; Lone, S.A. A comprehensive study of document security system, open issues and challenges. Multimed. Tools Appl. 2020, 80, 7039–7061. [Google Scholar] [CrossRef]
- Dyer, A.G.; Found, B.; Rogers, D. An Insight into Forensic Document Examiner Expertise for Discriminating Between Forged and Disguised Signatures. J. Forensic Sci. 2008, 53, 1154–1159. [Google Scholar] [CrossRef] [PubMed]
- Parkinson, A.; Colella, M.; Evans, T. The Development and Evaluation of Radiological Decontamination Procedures for Documents, Document Inks, and Latent Fingermarks on Porous Surfaces. J. Forensic Sci. 2010, 55, 728–734. [Google Scholar] [CrossRef] [PubMed]
- Warif, N.B.A.; Wahab, A.W.A.; Idris, M.Y.I.; Ramli, R.; Salleh, R.; Shamshirband, S.; Choo, K.-K.R. Copy-move forgery detection: Survey, challenges, and future directions. J. Netw. Comput. Appl. 2016, 75, 259–278. [Google Scholar] [CrossRef]
- Muthukrishnan, R.; Radha, M. Edge detection techniques for image segmentation. Int. J. Comput. Sci. Inf. Technol. 2011, 3, 259. [Google Scholar] [CrossRef]
- Alshayeji, M.H.; Al-Rousan, M. Detection Method for Counterfeit Currency Based on Bit-Plane Slicing Technique. Int. J. Multimed. Ubiquitous Eng. 2015, 10, 225–242. [Google Scholar] [CrossRef]
- Lamsal, S. Counterfeit Paper Banknote Identification Based on Color and Texture; Pulchowk Campus: Dharan, Nepal, 2015. [Google Scholar]
- Gorai, A.; Pal, R.; Gupta, P. Document fraud detection by ink analysis using texture features and histogram matching. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016. [Google Scholar]
- Valderrama, L.; Março, P.H.; Valderrama, P. Model precision in partial least squares with discriminant analysis: A case study in document forgery through crossing lines. J. Chemom. 2020, 34, e3265. [Google Scholar] [CrossRef]
- Niu, P.; Wang, C.; Chen, W.; Yang, H.; Wang, X. Fast and effective Keypoint-based image copy-move forgery detection using complex-valued moment invariants. J. Vis. Commun. Image Represent. 2021, 77, 103068. [Google Scholar] [CrossRef]
- Markiewicz-Keszycka, M.; Cama-Moncunill, X.; Casado-Gavalda, M.P.; Dixit, Y.; Cama-Moncunill, R.; Cullen, P.J.; Sullivan, C. Laser-induced breakdown spectroscopy (LIBS) for food analysis: A review. Trends Food Sci. Technol. 2017, 65, 80–93. [Google Scholar] [CrossRef]
- Elsherbiny, N.; Nassef, O.A. Wavelength dependence of laser induced breakdown spectroscopy (LIBS) on questioned document investigation. Sci. Justice 2015, 55, 254–263. [Google Scholar] [CrossRef] [PubMed]
- Laserna, J.; Vadillo, J.M.; Purohit, P. Laser-Induced Breakdown Spectroscopy (LIBS): Fast, Effective, and Agile Leading Edge Analytical Technology. Appl. Spectrosc. 2018, 72, 35–50. [Google Scholar] [CrossRef]
- Zięba-Palus, J.; Kunicki, M. Application of the micro-FTIR spectroscopy, Raman spectroscopy and XRF method examination of inks. Forensic Sci. Int. 2006, 158, 164–172. [Google Scholar] [CrossRef] [PubMed]
- Gál, L.; Belovičová, M.; Oravec, M.; Palkova, M.; Ceppan, M. Analysis of Laser and Inkjet Prints Using Spectroscopic Methods for Forensic Identification of Questioned Documents; XIth Symposium on Graphic Arts; University of Pardubice: Pardubice, Czech Republic, 2013. [Google Scholar]
- Ameh, P.O.; Ozovehe, M.S. Forensic examination of inks exracted from printed documents using Fourier transform in-frared spectroscopy. Edelweiss Appl. Sci. Technol. 2018, 2, 10–17. [Google Scholar] [CrossRef]
- Fortes, F.J.; Moros, J.; Lucena, P.; Cabalín, L.M.; Laserna, J.J. Laser-induced breakdown spectroscopy. Anal. Chem. 2013, 85, 640–669. [Google Scholar] [CrossRef]
- Kim, S.J.; Deng, F.; Brown, M.S. Visual enhancement of old documents with hyperspectral imaging. Pattern Recognit. 2011, 44, 1461–1469. [Google Scholar] [CrossRef]
- Balas, C.; Papadakis, V.; Papadakis, N.; Papadakis, A.; Vazgiouraki, E.; Themelis, G. A novel hyper-spectral imaging apparatus for the non-destructive analysis of objects of artistic and historic value. J. Cult. Heritage 2003, 4, 330–337. [Google Scholar] [CrossRef]
- Melessanaki, K.; Papadakis, V.; Balas, C.; Anglos, D. Laser-induced breakdown spectroscopy and hyper-spectral imaging analysis of pigments on an illu-minated manuscript. Spectrochim. Acta Part B At. Spectrosc. 2001, 56, 2337–2346. [Google Scholar] [CrossRef]
- Cicconi, F.; Lazic, V.; Palucci, A.; Assis, A.A.; Romolo, F.S. Forensic Analysis of Commercial Inks by Laser-Induced Breakdown Spectroscopy (LIBS). Sensors 2020, 20, 3744. [Google Scholar] [CrossRef]
- Pokrajac, D.D.; Sivakumar, P.; Markushin, Y.; Milovic, D.; Holness, G.; Liu, J.; Melikechi, N.; Rana, M. Modeling of laser-induced breakdown spectroscopic data analysis by an automatic classifier. Int. J. Data Sci. Anal. 2019, 8, 213–220. [Google Scholar] [CrossRef]
- Cremers, D.A.; Yueh, F.Y.; Singh, J.P.; Zhang, H. Laser-induced breakdown spectroscopy, elemental analysis. In Encyclopedia of Analytical Chemistry: Applications, Theory, and Instrumentation; John Wiley & Sons: New York, NY, USA, 2006. [Google Scholar]
- Harmon, R.S.; Remus, J.; McMillan, N.J.; McManus, C.; Collins, L.; Gottfried, J.L.; DeLucia, F.C.; Miziolek, A.W. LIBS analysis of geomaterials: Geochemical fingerprinting for the rapid analysis and discrimination of minerals. Appl. Geochem. 2009, 24, 1125–1141. [Google Scholar] [CrossRef]
- Caridi, F. Laser-induced breakdown spectroscopy: Theory and applications, edited by Sergio Musazzi and Umberto Perini. Contemp. Phys. 2017, 58, 273. [Google Scholar] [CrossRef]
- Martin, M.Z.; Labbé, N.; André, N.; Harris, R.; Ebinger, M.; Wullschleger, S.D.; Vass, A.A. High resolution applications of laser-induced breakdown spectroscopy for environmental and forensic applications. Spectrochim. Acta Part B: At. Spectrosc. 2007, 62, 1426–1432. [Google Scholar] [CrossRef]
- Sakka, T. Introduction to Laser-induced Breakdown Spectroscopy. J. Inst. Electr. Eng. Jpn. 2022, 142, 69–72. [Google Scholar] [CrossRef]
- Jaswal, B.B.S.; Singh, V.K. Analytical assessments of gallstones and urinary stones: A comprehensive review of the devel-opment from laser to LIBS. Appl. Spectrosc. Rev. 2015, 50, 473–498. [Google Scholar] [CrossRef]
- Chen, M.; Kuzmin, K.; Szymanski, B.K. Community Detection via Maximization of Modularity and Its Variants. IEEE Trans. Comput. Soc. Syst. 2014, 1, 46–65. [Google Scholar] [CrossRef]
- Orman, G.K.; Labatut, V.; Cherifi, H. Comparative evaluation of community detection algorithms: A topological approach. J. Stat. Mech. Theory Exp. 2012, 2012, P08001. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Fortunato, S. Community detection algorithms: A comparative analysis. Phys. Rev. E 2009, 80, 056117. [Google Scholar] [CrossRef]
- Traag, V.A.; Van Dooren, P.; Nesterov, Y. Narrow scope for resolution-limit-free community detection. Phys. Rev. E 2011, 84, 016114. [Google Scholar] [CrossRef] [PubMed]
- Traag, V.A.; Waltman, L.; Van Eck, N.J. From Louvain to Leiden: Guaranteeing well-connected communities. Sci. Rep. 2019, 9, 5233. [Google Scholar] [CrossRef]
- Velmurugan, T.; Santhanam, T. Computational complexity between K-means and K-medoids clustering algorithms for normal and uniform distributions of data points. J. Comput. Sci. 2010, 6, 363. [Google Scholar] [CrossRef]
- Madhulatha, T.S. Comparison between k-means and k-medoids clustering algorithms. In Proceedings of the International Conference on Ad-vances in Computing and Information Technology, Chennai, India, 14–17 July 2011; Springer: Berlin, Germany, 2011. [Google Scholar]
- Dharmarajan, A.; Velmurugan, T. Lung Cancer Data Analysis by k-means and Farthest First Clustering Algorithms. Indian J. Sci. Technol. 2015, 8, 974–6846. [Google Scholar] [CrossRef]
- Kumar, M. An optimized farthest first clustering algorithm. In Proceedings of the 2013 Nirma University International Conference on Engineering (NUiCONE), Ahmedabad, India, 28–30 November 2013. [Google Scholar]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN revisited, revisited: Why and how you should (still) use DBSCAN. ACM Trans. Database Syst. (TODS) 2017, 42, 1–21. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Printer Type | Brand | Model (Reference) | Ink Type | Paper Brand |
|---|---|---|---|---|
| Laser | Canon | i-SENSYS (MF231) | AR CRG 737 | Copy laser |
| Laser | Canon | i-SENSYS (MF4010) | AR FX 10 | Copy laser |
| Laser | Canon | i-SENSYS (LBP6000) | AR CRG725 | Copy laser |
| Laser | Canon | Image CLASS (MF264) | CRG 51 | Copy laser |
| Laser | Canon | i-SENSYS (MF4430) | 728 | Copy laser |
| Laser | Canon | i-SENSYS (MF4730) | 128 | Golden plus |
| Laser | Ricoh | Aficio (MP4001) | Toner black mp c4500 | Copy laser |
| Laser | Kyocera | Aficio (MPC2051) | Toner black mp c2051c | Copy laser |
| Inkjet | Epson | EcoTank (ITSL3070) | Any color ink refill | Copy laser |
| Inkjet | Canon | Pixma (TS6020) | Vivid ink refill | Copy laser |
| Inkjet | HP | Page Wide Pro (577dw) | YOUSIF UV dye ink | Copy laser |
| Paper Brand | Origin |
|---|---|
| Copy laser | Indonesia |
| Ballet Universal | China |
| PAPEROne | India |
| Paperline | Indonesia |
| local | China |
| Algorithm | Total Nodes Tested | Successfully Distinguished | Failed to Distinguish | Accuracy | Average Time Execution for Every 10 Nodes (s) |
|---|---|---|---|---|---|
| Proposed | 455 | 419 | 36 | 92.08% | 0.039 |
| Louvain | 455 | 413 | 42 | 90.7% | 0.043 |
| FFT | 455 | 364 | 91 | 80% | 0.7 |
| K-Medoid | 455 | 348 | 107 | 76.48% | 0.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Ameri, M.A.A.; Ciylan, B.; Mahmood, B. Spectral Data Analysis for Forgery Detection in Official Documents: A Network-Based Approach. Electronics 2022, 11, 4036. https://doi.org/10.3390/electronics11234036
Al-Ameri MAA, Ciylan B, Mahmood B. Spectral Data Analysis for Forgery Detection in Official Documents: A Network-Based Approach. Electronics. 2022; 11(23):4036. https://doi.org/10.3390/electronics11234036
Chicago/Turabian StyleAl-Ameri, Mohammed Abdulbasit Ali, Bunyamin Ciylan, and Basim Mahmood. 2022. "Spectral Data Analysis for Forgery Detection in Official Documents: A Network-Based Approach" Electronics 11, no. 23: 4036. https://doi.org/10.3390/electronics11234036
APA StyleAl-Ameri, M. A. A., Ciylan, B., & Mahmood, B. (2022). Spectral Data Analysis for Forgery Detection in Official Documents: A Network-Based Approach. Electronics, 11(23), 4036. https://doi.org/10.3390/electronics11234036