1. Introduction
With the advent of the era of big data, human production activities will produce massive amouts of data every day. The storage of these data will bring expensive maintenance costs and economic expenses to the data owner (DO). To address this problem, several companies are launching plans to provide cloud storage services for individuals or companies at little or no cost. From DO’s point of view, this service will undoubtedly be a huge convenience, freeing them from the hectic maintenance of data. However, this service also brings a new problem, as the DO loses direct control over important data. In this case, the cloud service provider (CSP) may delete data that the DO does not often access or never accesses in order to save costs. Alternatively, the hardware servers used by the CSP to store original data may fail, resulting in data loss. In either case, this can cause severe financial losses to the DO.
Given the above background, it is natural for the DO to be concerned about the integrity of the data stored in the cloud and to be eager to have a mechanism to help them check the integrity of the outsourced data. Therefore, various remote data integrity checking (RDIC) mechanisms, such as provable data possession (PDP), have been used extensively in the past decades [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10]. The PDP model is divided into private and public auditing depending on the types of the verifier. Both methods enable data integrity auditing. In private auditing, the DO communicates with the CSP to check the integrity of the data stored in the cloud, which undoubtedly imposes a substantial computational overhead on the DO. In public auditing, anyone can check the integrity of the data, so as to reduce the communication burden on the DO, and this operation is usually delegated to a third-party auditor (TPA) [
11,
12]. Here the TPA can be an individual or an authority with more computing power than the DO.
Since the amount of data that the DO uploads to the cloud is tremendous, and data integrity auditing needs to be checked consistently over time, most RDIC mechanisms reduce the workload by checking the integrity of only a part of the data each challenge rather than all the data stored in the cloud. In the PDP model, the TPA randomly selects some data blocks stored in the cloud and sends the challenge information to the CSP. When the CSP receives the message, it selects the challenged data blocks and the corresponding signatures to generate a proof to send to the TPA in a response to this challenge. After receiving proof from the CSP, TPA verifies the proof to determine whether the CSP has stored DO data well [
13]. In the cloud auditing model, TPA is generally considered to be honest-but-curious; thus, TPA will honestly judge whether user data are complete but will be curious about the data. Therefore, although TPA can be a great convenience for the DO, there is a risk that the original data will be leaked to the TPA during auditing process. In addition, many existing PDP schemes have complex certificate management issues, and the DO must properly store private keys that have been certified by the public key infrastructure (PKI) [
12,
14,
15]. To reduce the storage burden of the DO, Shen et al. designed a signature scheme that using the DO’s biological (such as fingerprint) instead of traditional private keys [
16]. To avoid complex certificate management issues, it is more common to use the identity-based PDP (ID-PDP) signature scheme [
17,
18,
19,
20].
These large numbers of RDIC protocols have often adopted by enterprises since they were proposed. These auditing protocols have been widely used in healthcare, finance, transportation and other fields. Its application in the field of transportation has attracted much attention from the market. In today’s growing number of private cars, the dashcam has become a must-have device for every car. For a single car owner, uploading the data recorded by the camera to the cloud and appointing a verifier to check it is a very troublesome task. Fortunately, in order to give better feedback to their customers, enterprises will take the initiative to help them store data in the cloud and check the integrity of the data. This service can reduce the local storage burden on the DO, and the data are also an important reference for enterprises to improve their services. The enterprise stores user data in the CSP and downloads relevant data from the CSP when required by itself or users. In this process, how to ensure the privacy of DO information is a problem worth considering. In the field of transportation, the identity of the DO needs to be properly protected, as well as his own data. Identity information can sometimes reveal a lot of valuable information. If there is an auditing scheme that can ensure the anonymity of the user’s identity and the privacy of the data, TPA can only judge whether the data being checked is complete when checking the integrity of the data and cannot obtain any other useful information. In [
21], Yan et al. designed an efficient ID-PDP scheme to ensure the anonymity of the DO while implementing data integrity auditing; TPA can only judge whether the data are complete during the auditing process without obtaining any information about the identity of the DO. However, this article does not consider data privacy security. In addition, while the advent of TPA eased the computational burden on the DO, it was prone to administrative chaos because anyone could audit the data. Therefore, some entity wants to restrict the verifier who checks the integrity of data to obtain the identity; that is, they can only hope that the designated verifier (DV) can complete the work [
22]. To address this problem, we proposed a certificateless PDP scheme for auditing the customer’s data stored in the cloud through the company’s designated verifier. In this paper, we envisage the application of data integrity auditing in the field of the Internet of Vehicles. By implementing the scheme in this paper, automobile companies can provide better services to their customers on the premise of ensuring safety.
1.1. Our Contributions
To summarize, both ensuring the anonymity of identity information and setting up a designated verifier to check the integrity of data are urgent problems to be solved. However, maintaining the anonymity of identity and setting up a designated verifier seem to be logically contradictory things. If the DO wants to set a designated verifier, the verifier must know who appointed it, so the anonymity of the DO’s identity cannot be guaranteed. In order to solve this problem, we introduce a new entity, CP, in the scheme. In our envisioned scenario, CP can be the general agent of a car company. The CP serves many DOs, setting designated verifiers for DOs to help them check data. From the point of view of the DV, when implementing the audit scheme designed in this thesis, it only knows that it is designated by CP but does not know which DO’s data it is checking. Through such a setting, this paper not only guarantees the anonymity of the DO’s identity but also sets up a designated verifier. The main contributions of this paper are as follows:
We have designed a PDP scheme that uses certificateless signature technology, in which the data auditing work is performed by the designated verifier. In the process of data auditing, the DV cannot obtain any other information except the result of whether the data are integrated. Specifically, the auditing process ensures both the privacy of data and the anonymity of the DO. In the scheme we designed, TPA can only judge whether the data checked are complete when performing the audit task and cannot obtain any relevant information about the data and the identity information that the data have; that is, TPA only knows that it has checked the data of a certain user of a company and does not know the specific identity of this user.
Most PDP schemes are in one-to-one mode for the digital signature of data blocks, which greatly burdens communication and storage. To solve this problem, the scheme we designed splits the raw data into a matrix before digital signature, with each row containing ten blocks of raw data. In the digital signature stage, each row of the matrix is signed as a whole, so that the number of tag blocks is reduced to one-tenth of the number of data blocks, which greatly reduces the burden of storage and communication.
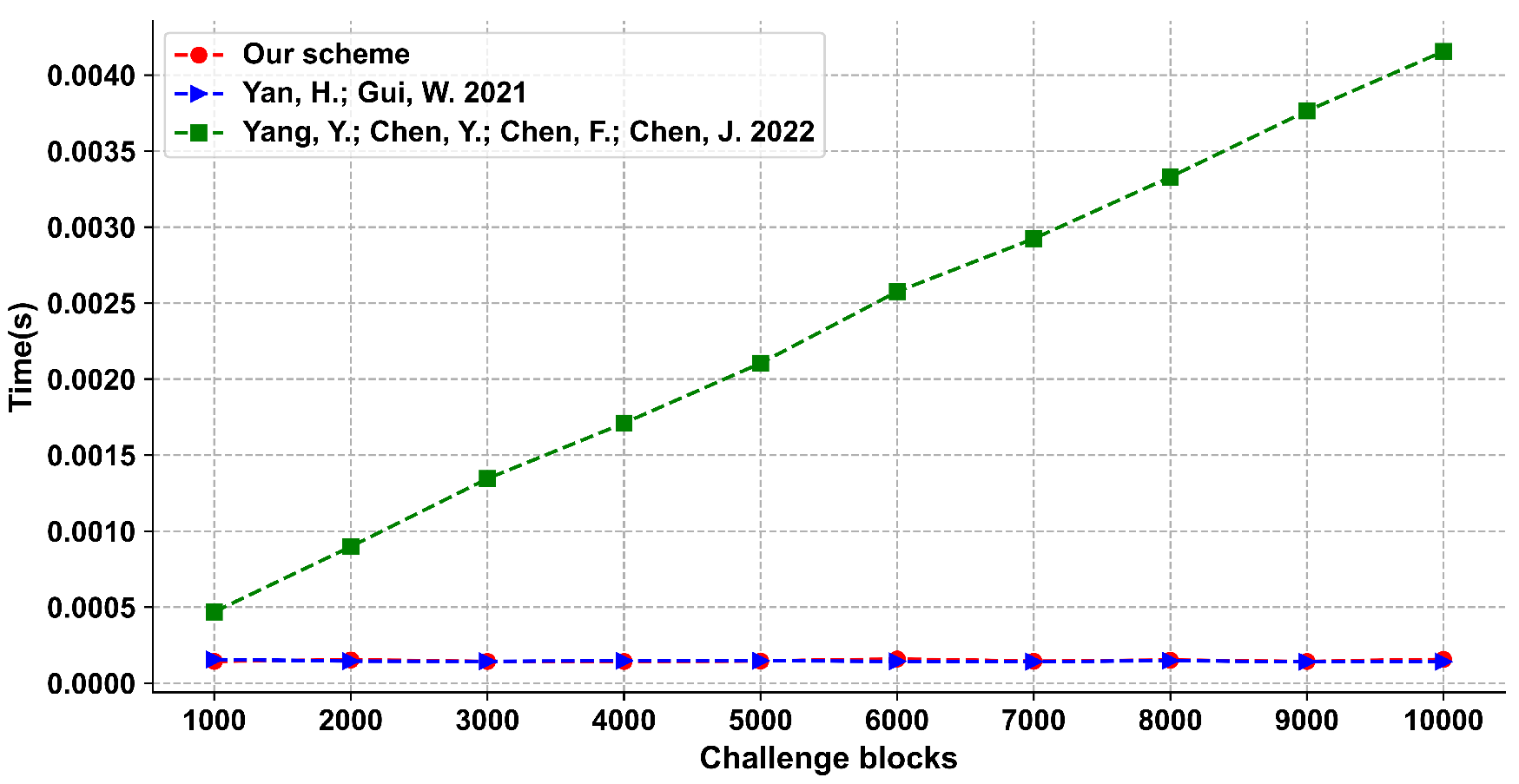
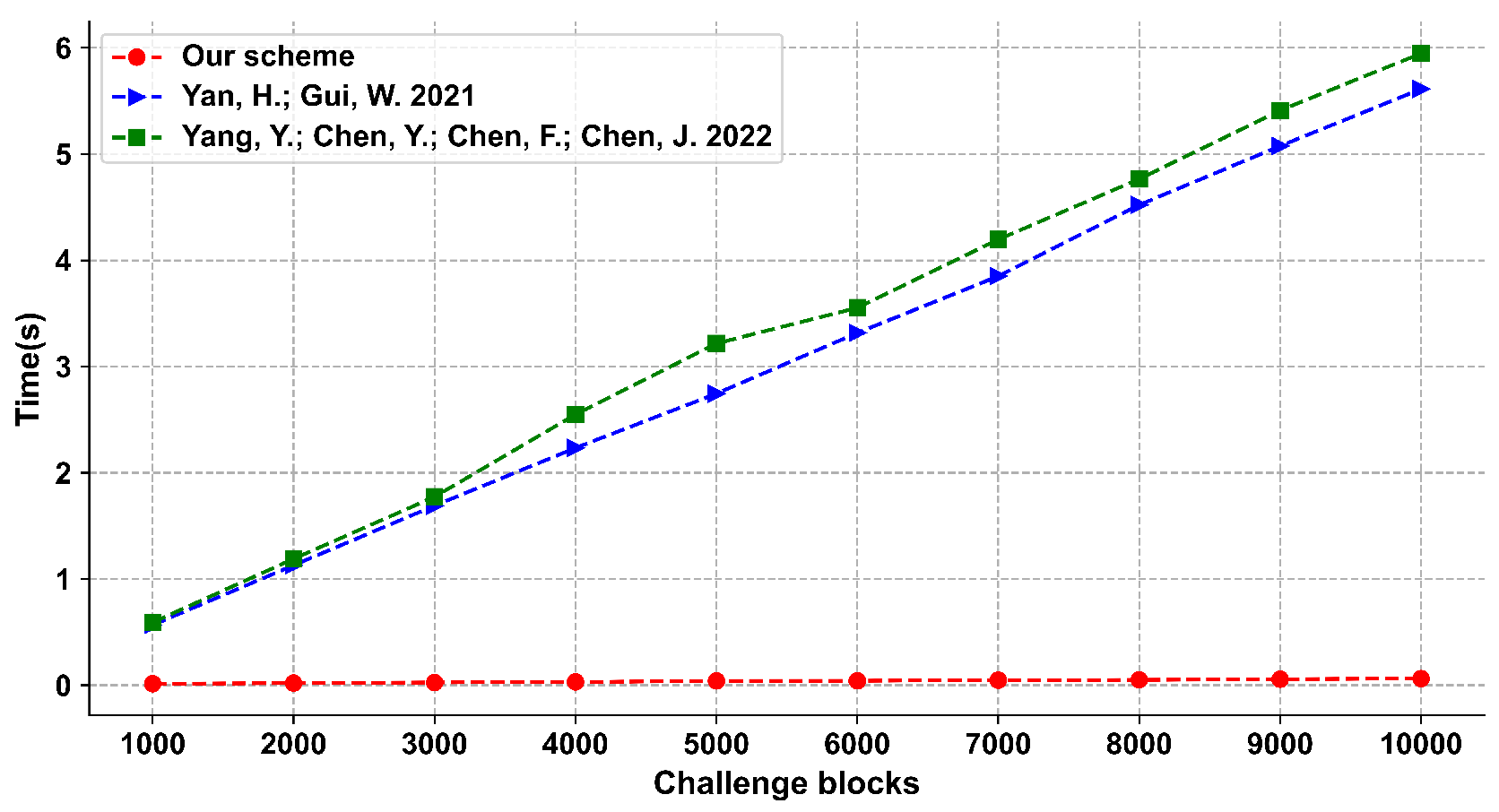
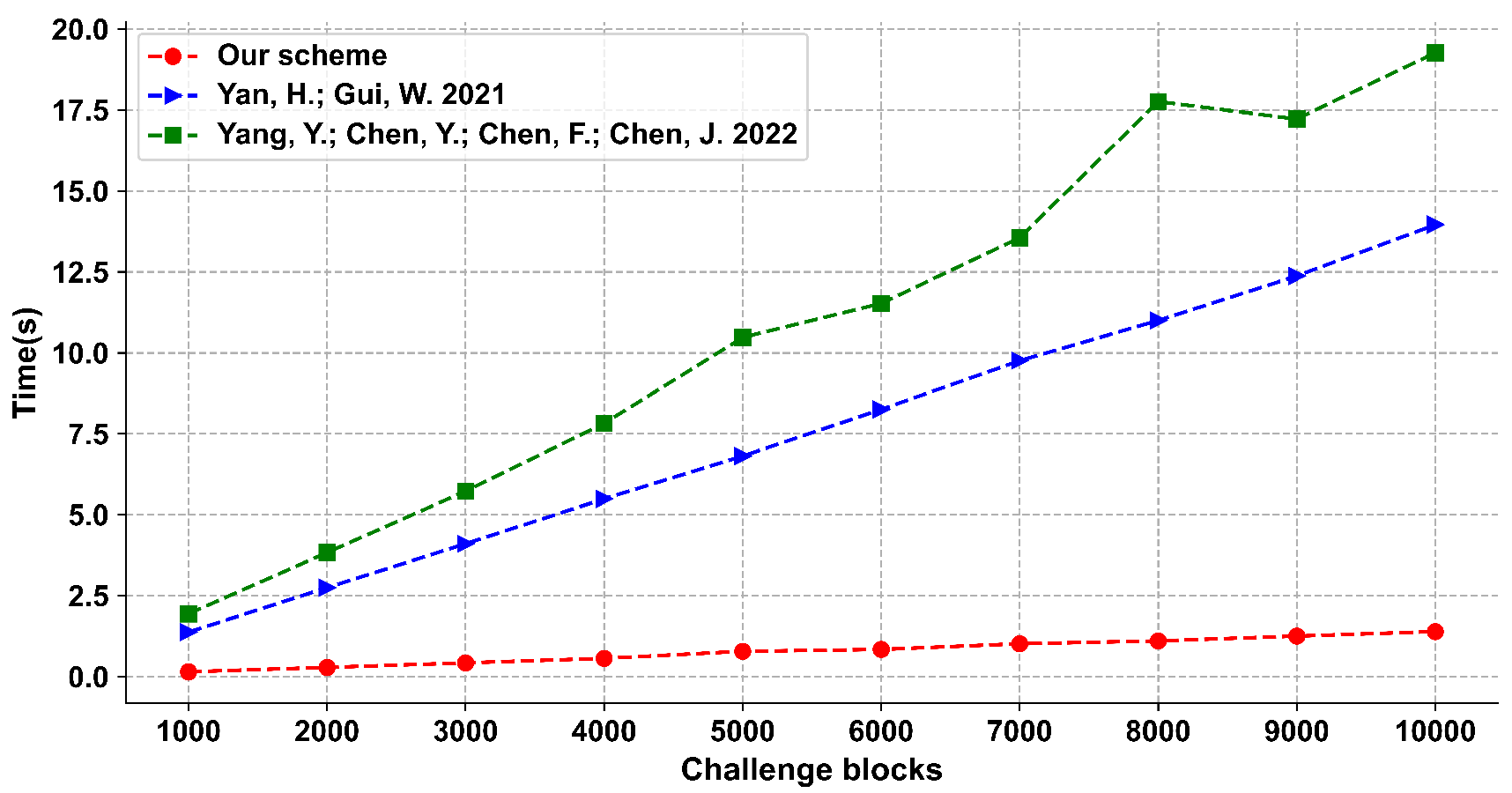
We give the provable security analysis for our scheme in a random oracle model. Moreover, we compare the proposed scheme with other schemes, and the results show that our scheme has a good performance in efficiency.
1.2. Related Work
In 2007, Ateniese et al. [
23] proposed for the first time to use the PDP model to check the integrity of data stored in the cloud. The homomorphic verification technique used in this paper can aggregate multiple proofs in the auditing process into a single value, which greatly reduces the communication burden. In the same year, Juels et al. [
24] proposed the PoR model, which realized data integrity auditing but did not support public verification.
In 2010, Wang et al. [
14] expanded the PDP model and proposed a data integrity auditing scheme supporting public auditing and a dynamic update on the basis of Merkle hash trees (MHT). However, this article is based on public audits, which is extremely unfriendly to the anonymity of users’ identities. In 2016, Yan et al. [
25] realized data integrity auditing and dynamic update operations through an operation record table (ORT). However, their method brought the problem of increased computational overhead. Li et al. [
22] made specific improvements to the traditional PDP model, so that the work of checking data integrity can only be carried out by the verifier designated by the user. However, this paper does not consider the dynamic updating of data, and there are some flaws in the security proof. Sun et al. [
26] designed a new data authentication structure, P-ATHAT, by introducing trapdoor and BLS signature to MHT. However, the paper was ill-considered in terms of privacy. In order to minimize the computational complexity of the DO, Garg et al. [
15] proposed a PDP scheme and proved the security of the scheme through CDH assumptions. As a protocol implemented on the mobile side, the solution is not lightweight enough. In order to better reduce the computational burden on the DO, Lu et al. [
12] designed an MHT-based PDP scheme, in which the tags generated by the DO are changed to those generated by TPA. However, the scheme gives TPA too many rights, so there is a risk of man-in-the-middle attacks. Considering that most of the traditional PDP scheme uses signature technologies, such as RSA or BLS, which will bring great computational overhead and low efficiency, Zhu et al. [
27] designed a PDP scheme with privacy protection and higher efficiency based on ZSS signature technology. However, the above papers involve a complex certificate management process. In 2020, Ning et al. [
28] implemented an auditing scheme with the help of the Hyperledger fabric, so that each audit task can dynamically select the TPA.
Identity-based signature technology can effectively solve the above problems. Shang et al. [
29] used the identity-based PDP model to achieve dynamic data updating and auditing operations. However, the disadvantages of privacy and large computational overhead make this scheme not suitable for most scenarios. Zhao et al. [
30] designed a big data dynamic auditing method based on fuzzy identity by combining MHT and index logic tables (ILT), which simplified the interaction process between DO and CSP in dynamic updates. Again, the paper does not do a good job of privacy protection. Considering the privacy of important information, Shen et al. [
31] designed an identity-based PDP model so that user information would not be leaked to any malicious entity in the auditing process. For the first time, Peng et al. [
17] proposed an identity-based PDP scheme with full dynamic updates and multi-replica batch checking. Unfortunately, the calculation overhead of this scheme is still a bit high. Li et al. [
18] proposed identity-based authentication technology, which ensures the privacy of data in the process of data auditing. However, the security proof of this scheme is not quite correct. Yang et al. [
19] designed a compressive secure cloud storage scheme inspired by the Goldreich–Goldwasser–Halevi (GGH) cryptosystem. However, the introduction of this mechanism increases the actual overhead of the scheme. Tian et al. [
20] designed a scheme that supports user behavior prediction, which saves resources by setting a safe time to avoid repeated verification of the same data block in a short period of time. The problem with identity-based signature technology is that key management is too centralized, and there is a risk of being attacked. In 2022, Li et al. [
32] proposed a lightweight auditing scheme based on certificates and provided a security model.
The use of certificateless signature technology can solve the above problems. Wang et al. [
33] designed a lightweight PDP scheme based on asymmetric bilinear mapping. In this scheme, the certificate participates in the decryption operation as a part of the key. In the same year, Hong et al. [
34] proposed an efficient certificateless auditing scheme based on the Internet of Things. However, the data in the industrial field are constantly flowing, and this scheme does not consider the dynamic updates of data security. Considering the needs of group users, Li et al. [
35] designed a certificateless PDP scheme. In order to improve the availability and durability of data, Zhou et al. [
36] proposed a multi-copy dynamic auditing scheme with certificateless signatures, which not only guarantees the privacy of data, but also supports the dynamic update operation of multi-copy data. In the same year, Jaya et al. [
37] designed a multi-copy audit protocol, which has excellent performance in computational efficiency. Unfortunately, the above studies are not perfect in terms of identity anonymity.
1.3. Organization
The remainder of this paper is organized as follows. In
Section 2, we introduce the basic knowledge and give the security model of our scheme. In
Section 3, we give the detailed structure of the proposed scheme. In
Section 4, a provable security analysis is given. In
Section 5, we evaluated our scheme both theoretically and experimentally. Finally, the conclusion of this paper is presented in
Section 6 [
4].
2. Preliminaries
In this part, we first introduce the system model and basic knowledge involved in this paper, then give the outline of our scheme and the security model.
Table 1 below shows some of the mathematical symbols involved in this paper and their corresponding meanings.
2.1. System Model
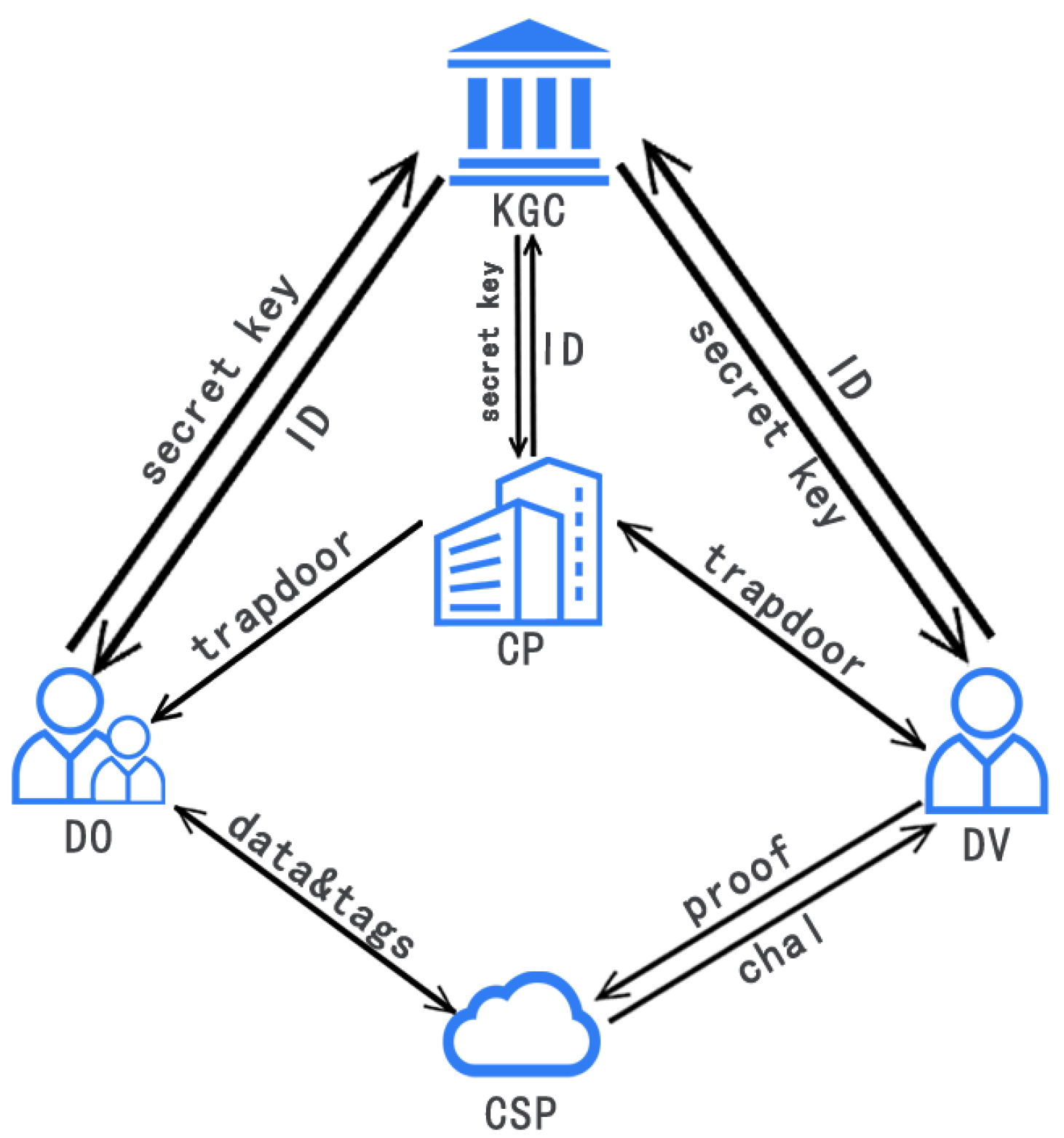
There are five entities in our scheme: DO, CSP, KGC, company (CP) and DV. The relationship between them is shown in
Figure 1.
CP: The CP is responsible for assigning verifiers to its clients to check the integrity of data stored in the cloud.
DO: The DO cuts and chunks the local data while generating tags and then sends them to the CSP.
CSP: The CSP has abundant storage space and powerful computing ability. It can provide data storage services for the DO and proof of data integrity for the DV when receiving a data integrity challenge.
KGC: The KGC is an organization that is responsible for distributing keys. Each time a request is received, the KGC generates part of the private key for the client.
DV: The DV is designated by the CP, which checks whether the data are completely stored in the cloud. The DV has enough computing power to complete data integrity verification.
2.2. Bilinear Maps
Let and be two multiplicative cyclic groups with the same large prime order p. g is a generator of . e is a bilinear map that satisfies with the following properties:
Bilinearity: for and , there are .
Computability: for , there is an efficiently algorithm to compute .
Non-degeneracy: , there is .
2.3. Security Assumptions
CDH (Computational Diffie–Hellman) Problem: Let be a multiplicative cyclic group. g is a generator of . Given the tuple , where is unknown, the CDH problem calculates .
CDH Assumption: For any probabilistic polynomial time (PPT) adversary
, the advantage for
to solve the CDH problem in
is negligible. Assume
is a negligible value; it can be defined as:
DL (Discrete Logarithm) Problem: Let be a multiplicative cyclic group. g is a generator of . Given the tuple , where is unknown, the DL problem is to calculate x.
DL Assumption: For any PPT adversary
, the advantage for
to solve the DL problem in
is negligible. Assume
is a negligible value; it can be defined as:
2.4. Outline of Our Scheme
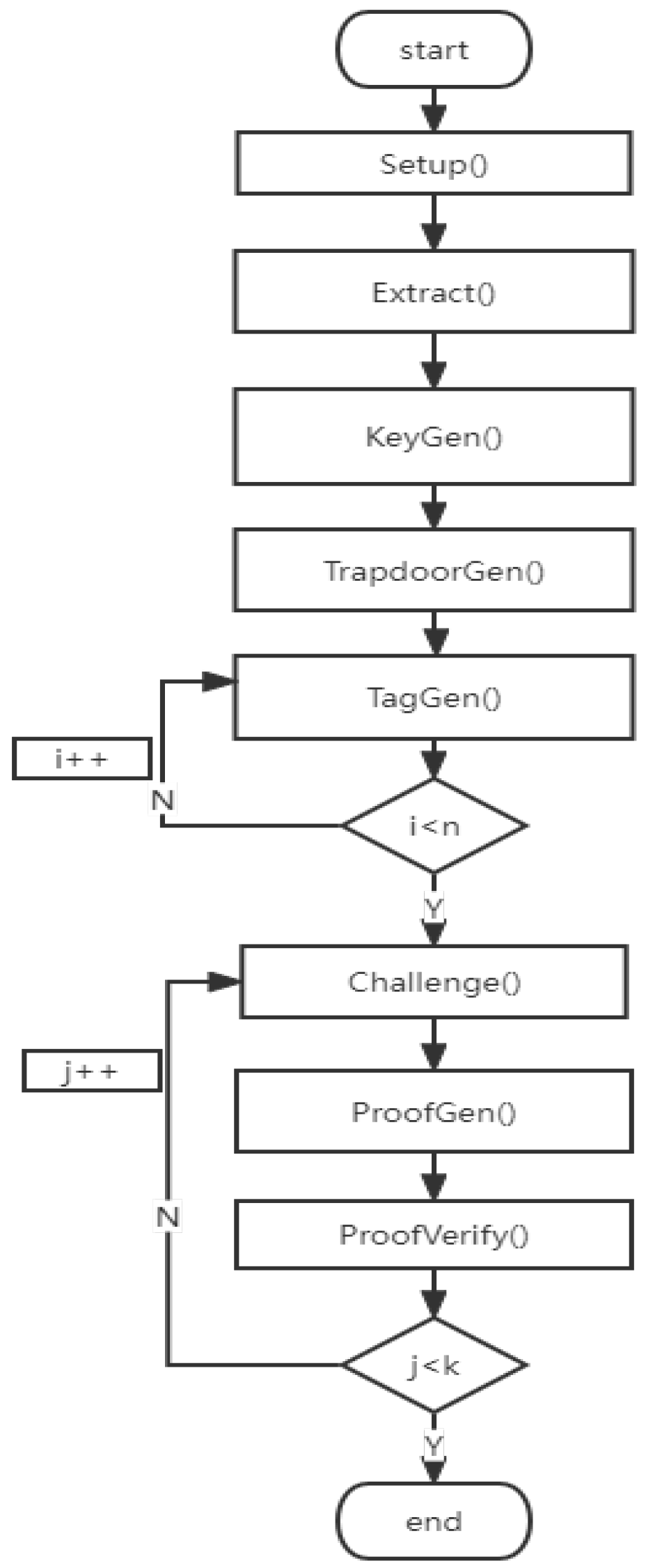
Our scheme contains eight algorithms, and their functions are described as follows:
: This algorithm inputs security parameter k, outputs public parameters and system secret key .
: This algorithm is run by the KGC, which is used to generate part of the private key. After receiving the customer , the algorithm uses the master key to generate part of the security key for the customer.
: This algorithm is run by a customer to generate his own key pair.
: This algorithm generates a trapdoor through the key pair of the CSP and DV.
: This algorithm is run by the DO, which is used to generate tags for data blocks and the file name.
: This algorithm is run by DV to generate a data integrity challenge request for the file named .
: After receiving , the algorithm generates the corresponding proof P with the data blocks and tags.
: The validity of P is verified by this algorithm to determine whether the data are intact. If the output result is 1, it proves that the data are still saved safely; otherwise, it has been damaged.
To further illustrate our proposed scheme, the following
Figure 2 is a flowchart of the algorithm, where
n is the total number of tags to generate hypothetically, and
k is the number of challenges.
2.5. Security Model
To elaborate on the security of the scheme proposed in this paper, we design a series of games between a challenger and an adversary A. Although the scheme designed in this paper involves multiple users, in order to simplify the proof process, we used a single user with an identity as an example in the security model. It is worth noting that the challenger represents the DO, and the adversary A represents a malicious cloud. The most basic game rules are as follows:
Setup: The challenger executes system initialization to obtain the public parameters, params, and the master key . Then the challenger sends to the adversary A and keeps secret.
Queries: For the game to proceed effectively, the following interactions can be performed between the challenger and the adversary A.
Hash queries: The adversary A can send a series of different to the challenger . When the challenger receives relevant query information, it will use the resources at its disposal to perform relevant calculations and feedback the results to the adversary A.
Partial secret public key query: In order to forge legal proof, the adversary A can query the public and private keys of the DO whose identity is , and the challenger sends the result to the adversary A when it receives the relevant query information.
Tag query: The adversary A can randomly select a data block and query its corresponding tag. The challenger executes to generate the tag and sends it to the adversary A.
Integrity proof queries: The adversary A can also query the integrity proof of any set of data blocks. When receiving a query request, challenger performs relevant calculations and shares the results with adversary A.
Challenge: At this stage, the challenger generates a challenge set of data blocks and sends it to the adversary A. The adversary generates a proof and sends it to the challenger after receiving the challenge information.
Forge: After receiving the challenge information, the adversary A generates a data integrity proof P and sends it to the challenger . If the proof can be verified by , it is considered that the adversary A has won this game.
In the above model, the goal of the adversary is to pass the verification of the challenger by using a forged proof for the challenged blocks. Obviously, we need to prove that the adversary A cannot generate a valid proof without fully grasping the data blocks involved in the challenge information.
Definition 1. If the probability of A winning the game is non-negligible, there is a knowledge extractor that can listen to the communication between the adversary A and the challenger β.
Our scheme focuses on protecting users’ information from being disclosed to unauthorized organizations. Privacy information in our scheme includes both original data and the user’s identity. The DV tries to obtain original data and distinguish the identity of the DO during the data integrity auditing process. Thus, the scheme should not only ensure data privacy against DV but also enable the DO’s anonymity against DV.
Definition 2. A certificateless data integrity auditing scheme for important information is privacy preserving if the DV cannot distinguish the identity of DO and cannot obtain the DO’s original data during the data integrity auditing process.
3. The Proposed Scheme
In this section, we elaborate on the certificateless data integrity auditing scheme with privacy preservation and a designated verifier.
The DO divides the local data file
F into
n blocks with a fixed length, and each data block contains
s small data blocks with the same length. That means
is a unique symbol for the file F. The details of the algorithms involved in our scheme are shown below.
: Given a security parameter k, KGC randomly selects a large prime p with the feature . Then, KGC selects two multiplicative cyclic groups and with the same order p, respectively. g is a generator of , and are all random elements of the group . are two cryptographic hash functions, which satisfy that . e is a bilinear map acting on , : . is a pseudo-random permutation (PRP), and is a pseudo-random function (PRF). Then, KGC generates the master secret key , where x is randomly selected from . The master public key is calculated by . After doing the above work, KGC will publish but keep private.
: When the ID representing the customer’s identity is received, KGC calculates the partial private key of this customer by the equation and then sends it to customer through a secure channel. By this method, DO, DV and CP obtain their corresponding partial private keys , , .
: Take the DO as an example. After receiving the sent by KGC, the DO first checks the equation . If the validation fails, the DO terminates this algorithm and applies to KGC for a partial private key again. Otherwise, the DO selects a secret value and calculates . Thus, the DO combines with as his private key and published public key . By this method, DV and CP obtain their corresponding key pair , , respectively.
: The CP uses its own private key and the public key of the DV to compute trapdoor and sends it to the DO. Obviously, the DV can obtain the same result by calculating .
: The DO generates a tag
for the file
F by using a certificateless signature technique such as [
33]. The CSP can verify the validity of
through the same signature technique. Then, the DO calculates the tag by computing Equation (
4):
for each
. Denote the collection of tags as
.
is the multiplicative inverse element of
in
. Finally, the DO transfers message
to the CSP. A single tag can be verified by
.
: The DV can perform multiple integrity challenges and randomly select some data blocks for each challenge. Suppose one of the challenges check c blocks and the DV randomly selects two values, . Then, the DV sends the challenge request to the CSP.
: After receiving
from the DV, the CSP randomly selects two elements
and
. The parameter set
is calculated, where
. Then, the CSP calculates
Here, is the additive inverse of k in . Finally, the CSP sends to DV.
: After receiving the proof
P from CSP, the DV calculates
, where
. Then, it verifies Equation (
6):
If Equation (
6) holds, the data blocks are well preserved in this challenging period, and it returns 1. Otherwise, it means that the data has been damaged, and it returns 0.
4. Security Proof
In this section, we give the security proof of our scheme. The security of this paper mainly involves five aspects: correctness, soundness, privacy preservation, trapdoor security, and detectability. For each aspect, this section gives the following detailed proof.
4.1. Correctness Proof
The scheme designed in this paper contains the three core functions of key generation, tag verification, and proof verification, so a detailed proof of its correctness is required.
First, we prove the correctness of the partial private key generated by KGC. When KGC outputs a correct partial private key for the client, it obviously has the following formula:
Therefore, the correctness of the generated part of the private key has been proven.
Then, we prove the correctness of the tag verification. In this paper, Equation (
4) shows how to verify the correctness of a signal tag. With the help of the nature of the bilinear map, the correctness of Equation (
4) can be proved as follows:
Equation (
6) explains how the DV checks the proof of KGC feedback, and the proof of its correctness is as follows.
Thus, the equality reasoning for the proof of the verification algorithm has been completed.
4.2. Soundness Proof
Theorem 1 (Unforgeability). If the probability of the adversary A winning the game is negligible, then our scheme satisfies the proof unforgeability under Definition 1.
Proof. We will prove through several games that if the adversary A successfully forges a proof P that can be verified by the challenger in the absence of complete data, there is a knowledge extractor that can solve the CDH question or DL question by intercepting the communication information between A and . □
:
is already defined in the security model in
Section 2; we therefore will not go into too much detail here.
: and have the same rules except for one detail. In addition to challenging adversary A, the challenger also maintains a local list of information about each challenge. The challenger carefully checks the proof information P returned by each adversary A. If the proof information returned by the adversary A passes the verification algorithm, and the in it is not equal to the expected , which means that there is at least one tag that differs from the true value, the challenger terminates the game and declares failure.
: If the adversary A wins with non-negligible probability, then there exists a knowledge extractor that can solve the CDH problem with non-negligible probability. In this process, the knowledge extractor takes the place of the challenger to talk to the adversary A. Given , the knowledge extractor’s goal is to compute .
If the adversary
A wins the game, it means that it has successfully forged a verifiable proof
. Then, the knowledge extractor has:
Assuming the correct proof is
, then it has:
Obviously, there is at least one difference between
and
, otherwise
. The knowledge extractor randomly selects
for each
in the challenge, then sets
where
and
. Thus, the knowledge extractor has
. After doing that, the extractor randomly selects an element
as
and then performs
and
to generate the private key
. Then the extractor randomly selects an element
and sets
, which means
. Finally, for each
i, the knowledge extractor computes:
Thus, the tag can be comouted by
. Dividing the two verification equations, the knowledge extractor has
Simplifying this equation even further, the knowledge extractor has:
Finally, the knowledge extractor can solve the CDH problem with the following equation:
It can be easy to find that the probability for this equation to fail is a negligible value . Then, the knowledge extractor can find a solution to the CDH problem with a high probability . This contradicts with the CDH assumption.
: This game is run between the challenger and the adversary A in the same manner as with one difference. The challenger still observes each instance of the challenge and response proof, while the challenger declares failure and aborts this game if there exists not equal to the correct M.
: Given a DL instance
, it can construct an extractor whose purpose is to calculate a value
that satisfies
. Suppose there is a correct proof
; the knowledge extractor then has
Assume that the adversary generates a proof
, which is different from the correct one. If the forged proof can pass the verification, the knowledge extractor has
Based on
, we know that
. Thus, we can conclude that
and therefore
Therefore, the knowledge extractor has found the solution to the DL problem unless . Therefore, the probability for this equation to fail is , which is negligible. However, this contradicts with the DL assumption. Therefore, the theorem is proved.
4.3. Privacy Preserving Proof
Theorem 2 (Privacy Preservation). If the probability of the DV obtaining any information about the DO’s identity and raw data during the audit process is negligible, then our scheme satisfies privacy preservation under Definition 2.
Proof. The DV periodically makes data integrity challenges to the CSP in order to check whether the data stored in the cloud have their integrity. In the audit system, CSP generates a corresponding proof P for each challenge and sends it to the DV to prove that the data is well preserved. In order to prevent the DV from obtaining any information about the data and the ID of the DO, the proof generated by the CSP in our scheme is . The DV struggles to calculate k from and based on the DL problem. This means that the DV cannot obtain any information about the data by challenging the same data block multiple times. In addition, the ID is hidden in by the random value r. Obviously, the DV cannot obtain the relationship between DO and data. Therefore, our scheme not only achieves the anonymity of the DO but also protects the privacy of the data in the process of data auditing. □
4.4. Detectability Proof
Theorem 3 (Detectability). If the data block stored at the CSP is damaged, the scheme proposed in this paper can effectively check it out.
Proof. Suppose a file
F consists of
n blocks, where
k blocks are corrupted. At the same time, assume that the TPA selects
c data blocks to challenge. Let
denote the probability of detecting the data corruption. Then, we have
From the above equation, we can find that the greater the number of challenged blocks, the greater the probability of detecting corrupt blocks. For example, if 1000 of 10,000 blocks are corrupted, and 100 blocks are challenged in each data auditing, then the probability of detecting this error state is at least 99.9%. Therefore, our scheme has a very high probability of checking the data integrity. □










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}