
A Study on the Design Procedure of Re-Configurable Convolutional Neural Network Engine for FPGA-Based Applications


 ,
, 
Abstract
1. Introduction
- A compact and accurate TensorFlow-based CNN model was developed using Python which can simulate a variety of datasets.
- Implemented a step-by-step reconfigurable CNN engine on FPGA from scratch.
- The RTL design of the CNN model was synthesized using 180 nm CMOS technology and post-layout verification was carried out. The results of the FPGA and 180 nm testing were compared with the software model for validation.
- A graphical user interface (GUI) is designed for the loading and testing of data sets.
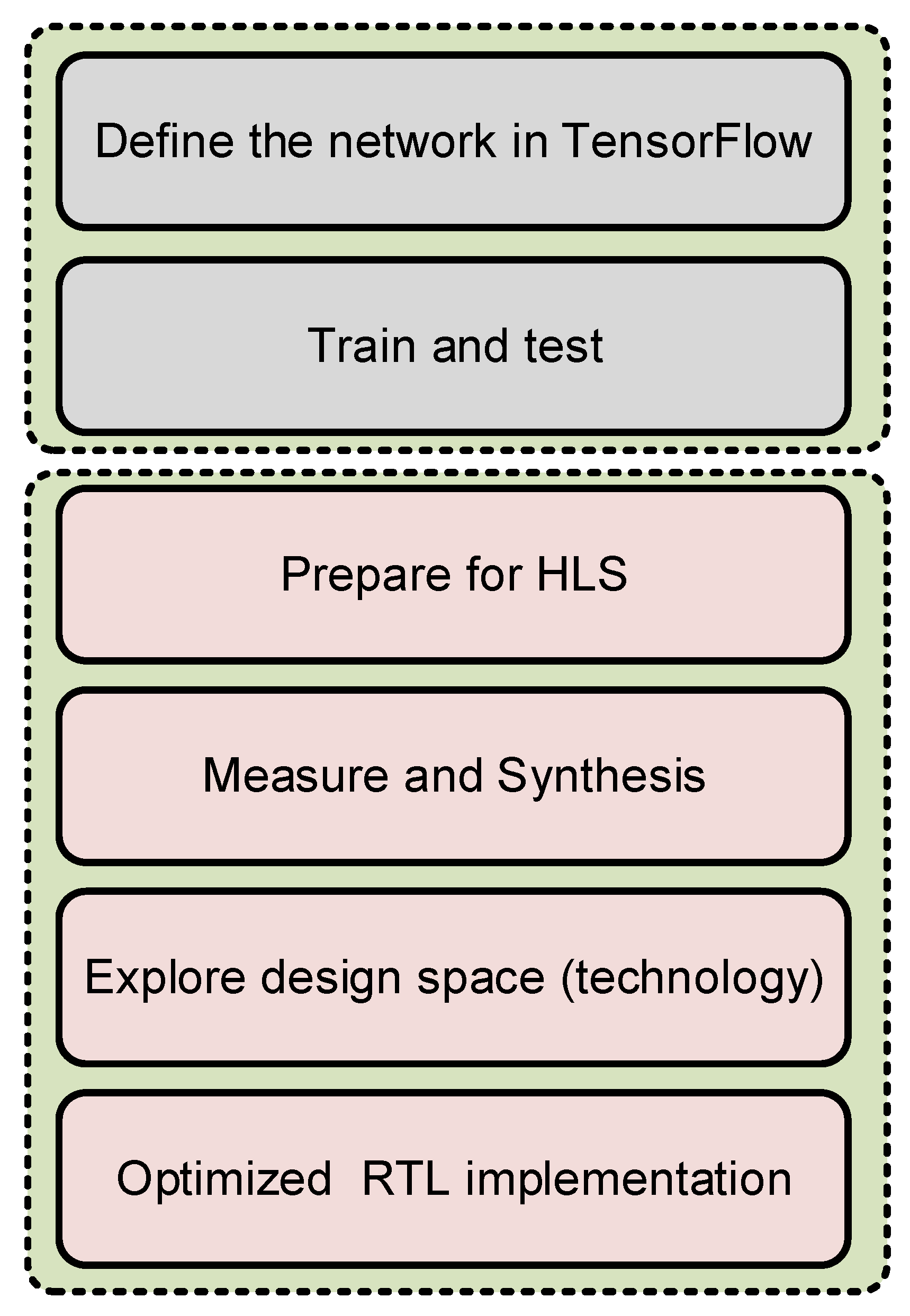
2. Proposed Design Flow
3. CNN Overall Operation
3.1. Uploading the Dataset
3.2. Divide the Dataset into Test/Training Dataset
3.3. Define the CNN Architecture
3.4. Output Accuracy Optimization
3.5. Saving the Trained Model and Weight Values
4. CNN: Layerwise Implementation
4.1. Proposed Top CNN Engine
4.2. Convolutional Layer
4.3. Pooling Layer and Activation Function
4.4. Fully Connected Layer
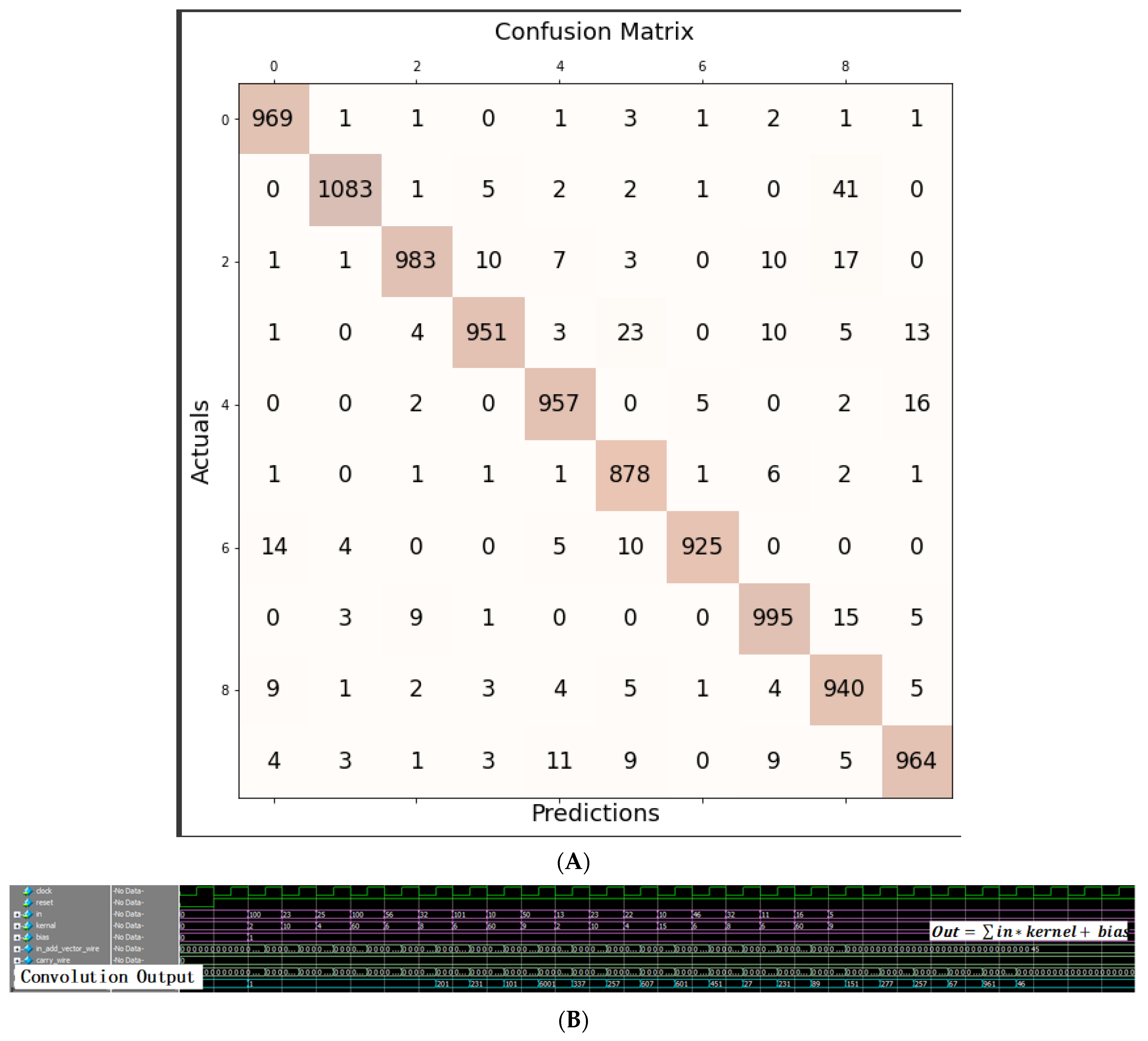
5. Synthesis and Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Verma, N.K.; Sharma, T.; Rajurkar, S.D.; Salour, A. Object identification for inventory management using convolutional neural network. In Proceedings of the 2016 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 18–20 October 2020; pp. 1–6. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Yadav, S.S.; Jadhav, S.M. Deep convolutional neural network based medical image classification for disease diagnosis. J. Big Data 2019, 6, 113. [Google Scholar] [CrossRef]
- Asano, S.; Maruyama, T.; Yamaguchi, Y. Performance comparison of FPGA, GPU and CPU in image processing. In Proceedings of the 2009 International Conference on Field Programmable Logic and Applications, Prague, Czech Republic, 31 August–2 September 2009; pp. 126–131. [Google Scholar]
- Mousouliotis, P.G.; Petrou, L.P. CNN-Grinder: From Algorithmic to High-Level Synthesis descriptions of CNNs for Low-end-low-cost FPGA SoCs. Microprocess. Microsyst. 2020, 73, 102990. [Google Scholar] [CrossRef]
- Lacey, G.; Taylor, G.W.; Areibi, S. Deep learning on FPGAs: Past, present, and future. arXiv 2006, arXiv:1602.04283. [Google Scholar]
- Shawahna, A.; Sait, S.M.; El-Maleh, A. FPGA-based accelerators of deep learning networks for learning and classification: A review. IEEE Access 2019, 7, 7823–7859. [Google Scholar] [CrossRef]
- Cong, J.; Xiao, B. Minimizing computation in convolutional neural networks. In Artificial Neural Networks and Machine Learning–ICANN 2014, Proceedings of the 24th International Conference on Artificial Neural Networks (ICANN 2014), Hamburg, Germany, 15–19 September 2014; Springer International Publishing: Cham, Switzerland, 2014; pp. 281–290. [Google Scholar]
- Abdelouahab, K.; Pelcat, M.; Serot, J.; Berry, F. Accelerating CNN inference on FPGAs: A survey. arXiv 2018, arXiv:1806.01683. [Google Scholar]
- Ma, Y.; Cao, Y.; Vrudhula, S.; Seo, J.S. Optimizing loop operation and dataflow in FPGA acceleration of deep convolutional neural networks. In FPGA ‘17: Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 45–54. [Google Scholar]
- Ma, Y.; Suda, N.; Cao, Y.; Seo, J.S.; Vrudhula, S. Scalable and modularized RTL compilation of convolutional neural networks onto FPGA. In Proceedings of the 2016 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 29 August–2 September 2016; pp. 1–8. [Google Scholar]
- Ma, Y.; Cao, Y.; Vrudhula, S.; Seo, J.S. An automatic RTL compiler for high-throughput FPGA implementation of diverse deep convolutional neural networks. In Proceedings of the 2017 27th International Conference on Field Programmable Logic and Applications (FPL), Ghent, Belgium, 4–8 September 2017; pp. 1–8. [Google Scholar]
- Wang, C.; Gong, L.; Yu, Q.; Li, X.; Xie, Y.; Zhou, X. DLAU: A scalable deep learning accelerator unit on FPGA. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2017, 36, 513–517. [Google Scholar] [CrossRef]
- Aghdam, H.H.; Heravi, E.J. Caffe Library. In Guide to Convolutional Neural Networks; Springer International Publishing: Cham, Switzerland, 2017; pp. 131–166. [Google Scholar] [CrossRef]
- Rivera-Acosta, M.; Ortega-Cisneros, S.; Rivera, J. Automatic Tool for Fast Generation of Custom Convolutional Neural Networks Accelerators for FPGA. Electronics 2019, 8, 641. [Google Scholar] [CrossRef]
- Venieris, S.I.; Bouganis, C.-S. fpgaConvNet: A framework for mapping convolutional neural networks on FPGAs. In Proceedings of the 2016 IEEE 24th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Washington, DC, USA, 1–3 May 2016; pp. 40–47. [Google Scholar]
- Guan, Y.; Liang, H.; Xu, N.; Wang, W.; Shi, S.; Chen, X.; Sun, G.; Zhang, W.; Cong, J. FP-DNN: An automated framework for mapping deep neural networks onto FPGAs with RTL-HLS hybrid templates. In Proceedings of the 2017 IEEE 25th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Napa, CA, USA, 30 April–2 May 2017; pp. 152–159. [Google Scholar]
- Deng, L. The MNIST Database of Handwritten Digit Images for Machine Learning Research [Best of the Web]. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: http://www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf (accessed on 15 November 2022).
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Byun, S.-J.; Kim, D.-G.; Park, K.-D.; Choi, Y.-J.; Kumar, P.; Ali, I.; Kim, D.-G.; Yoo, J.-M.; Huh, H.-K.; Jung, Y.-J.; et al. A Low-Power Analog Processor-in-Memory-Based Convolutional Neural Network for Biosensor Applications. Sensors 2022, 22, 4555. [Google Scholar] [CrossRef] [PubMed]
- Kumar, P.; Yingge, H.; Ali, I.; Pu, Y.-G.; Hwang, K.-C.; Yang, Y.; Jung, Y.-J.; Huh, H.-K.; Kim, S.-K.; Yoo, J.-M.; et al. A Configurable and Fully Synthesizable RTL-Based Convolutional Neural Network for Biosensor Applications. Sensors 2022, 22, 2459. [Google Scholar] [CrossRef] [PubMed]
- Moolchandani, D.; Kumar, A.; Sarangi, S.R. Accelerating CNN Inference on ASICs: A Survey. J. Syst. Arch. 2020, 113, 101887. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Nazemi, M.; Eshratifar, A.E.; Pedram, M. A hardware-friendly algorithm for scalable training and deployment of dimensionality reduction models on FPGA. In Proceedings of the 2018 19th International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, USA, 13–14 March 2018; pp. 395–400. [Google Scholar]
- He, X.; Lu, W.; Yan, G.; Zhang, X. Joint Design of Training and Hardware Towards Efficient and Accuracy-Scalable Neural Network Inference. IEEE J. Emerg. Sel. Top. Circuits Syst. 2018, 8, 810–821. [Google Scholar] [CrossRef]
- Li, C.; Bi, Y.; Benezeth, Y.; Ginhac, D.; Yang, F. High-level synthesis for FPGAs: Code optimization strategies for real-time image processing. J. Real Time Image Process. 2017, 14, 701–712. [Google Scholar] [CrossRef]
- Layer Activation Functions. Keras Website. Available online: https://keras.io/api/layers/activations/ (accessed on 15 November 2022).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Type | Size | Classes |
|---|---|---|---|
| MNIST | Gray | 28–28 | 10 |
| CIFAR-10 | Color | 32 × 32 | 10 |
| STL-10 | Color | 96 × 96 | 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumar, P.; Ali, I.; Kim, D.-G.; Byun, S.-J.; Kim, D.-G.; Pu, Y.-G.; Lee, K.-Y. A Study on the Design Procedure of Re-Configurable Convolutional Neural Network Engine for FPGA-Based Applications. Electronics 2022, 11, 3883. https://doi.org/10.3390/electronics11233883
Kumar P, Ali I, Kim D-G, Byun S-J, Kim D-G, Pu Y-G, Lee K-Y. A Study on the Design Procedure of Re-Configurable Convolutional Neural Network Engine for FPGA-Based Applications. Electronics. 2022; 11(23):3883. https://doi.org/10.3390/electronics11233883
Chicago/Turabian StyleKumar, Pervesh, Imran Ali, Dong-Gyun Kim, Sung-June Byun, Dong-Gyu Kim, Young-Gun Pu, and Kang-Yoon Lee. 2022. "A Study on the Design Procedure of Re-Configurable Convolutional Neural Network Engine for FPGA-Based Applications" Electronics 11, no. 23: 3883. https://doi.org/10.3390/electronics11233883
APA StyleKumar, P., Ali, I., Kim, D.-G., Byun, S.-J., Kim, D.-G., Pu, Y.-G., & Lee, K.-Y. (2022). A Study on the Design Procedure of Re-Configurable Convolutional Neural Network Engine for FPGA-Based Applications. Electronics, 11(23), 3883. https://doi.org/10.3390/electronics11233883