
Cost-Sensitive Multigranulation Approximation in Decision-Making Applications

Abstract
:1. Introduction
2. Literature Review
3. Preliminaries
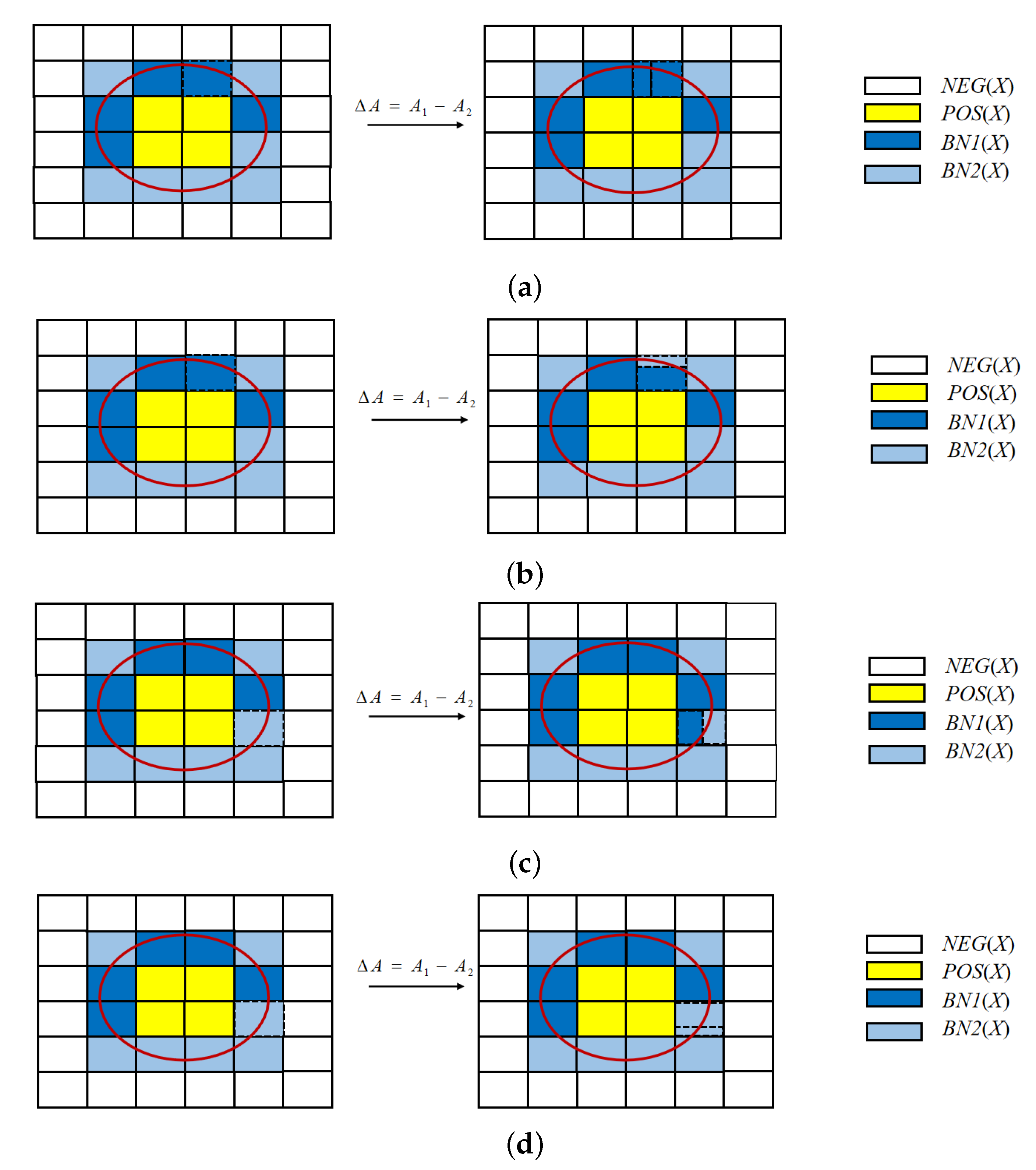
4. Cost-Sensitive Approximation Methods of the Rough Sets
- (P)
- If , ;
- (N)
- If , .
- (P1)
- If , ;
- (N1)
- If , .
- (P2)
- If , ;
- (N2)
- If , .
- (1)
- Suppose , obviously, .
- (2)
- Suppose , obviously, .
5. Cost-Sensitive Multigranulation Approximations and Optimal Granularity Selection Method
5.1. Cost-Sensitive Multigranulation Approximations of Rough Sets
- (1)
- ;
- (2)
- ;
- (3)
- ;
- (4)
- ;
- (5)
- .
- (1)
- From Formula (14), obviously holds.
- (2)
- .
- (3)
- (4)
- From , we have . Therefore, .
- (5)
- It is easy to prove by Formulas (1), (2), and (14).
- (1)
- (2)
- (3)
- (4)
- (1)
- , according to Definition 9, holds, . According to Definition 5, , and holds, i.e., . , , . According to Definition 7, holds, i.e., . Therefore, we have .
- (2)
- From the proof of (1), . According to Definition 7, . Because , .
- (3)
- , , . According to Definition 7, , , , holds. Therefore, .
- (4)
- It is easy to prove by Formulas (4), (5), and (19).
- (1)
- (2)
- and
- (1)
- According to Definition 6, we only need to prove . , according to Definition 7, . From Definition 5, we have .
- (2)
- It is easy to prove according to Definitions 5 and 7.
- (1)
- (2)
- Here, .
- (1)
- , because , we have , then , therefore .
- (2)
- . Because , we have , then . Therefore, .
- (1)
- and
- (2)
- and
5.2. The Optimal Multigranulation Approximation Selection Method
5.3. Case Study
- (1)
- According to the above conditions, the attribute significance can be computed by Formula (25), which is shown in Table 3.
- (2)
- Each multigranulation approximation is obtained by adding attributes in ascending order of attribute significance, in each stage, respectively. We represent the attributes as follows: , , , , and .
- (3)
- For each multigranulation approximation layer, , , and are computed by Formulas (16), (24), and (25), respectively, where and the results are displayed in Table 4.
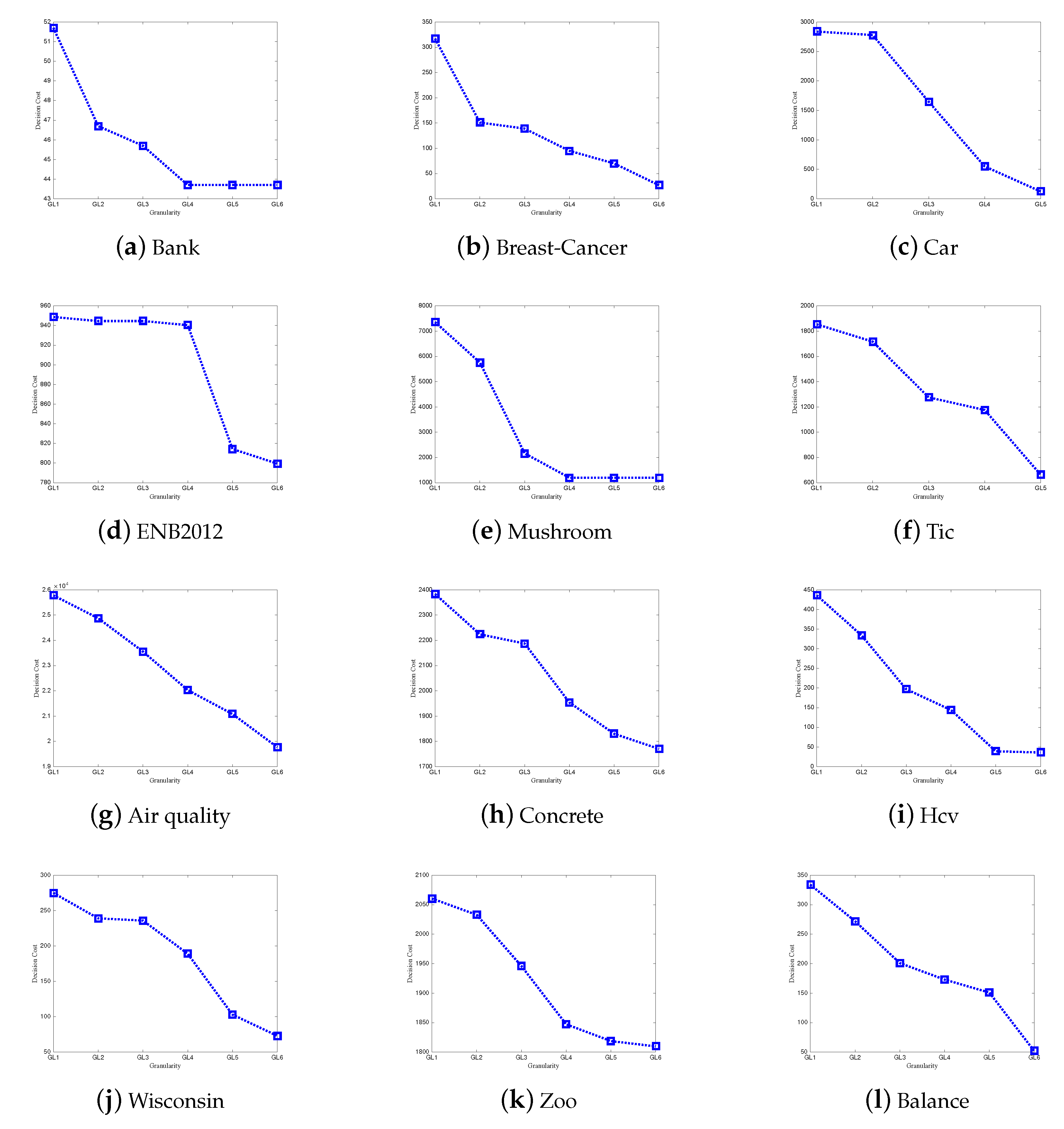
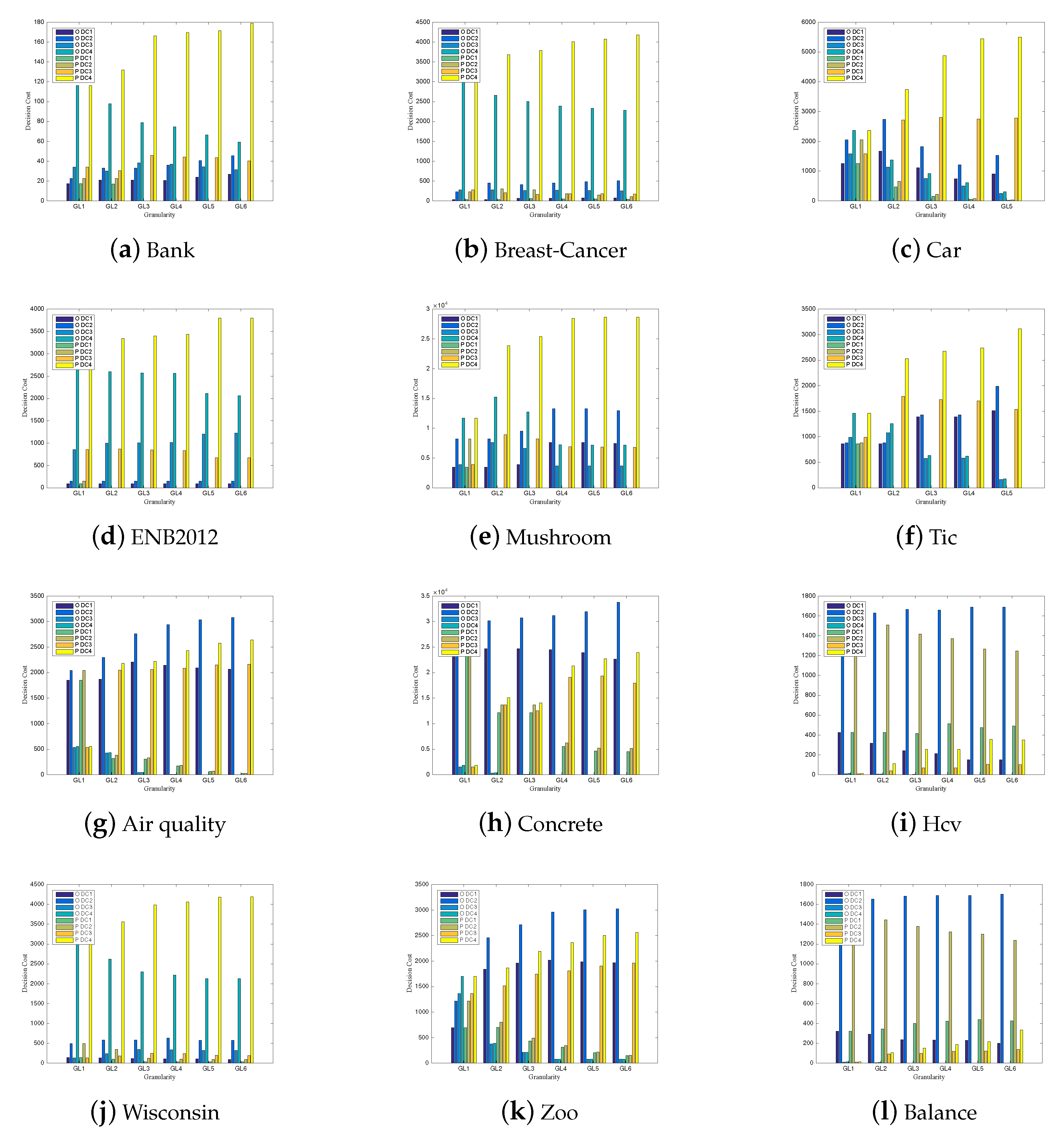
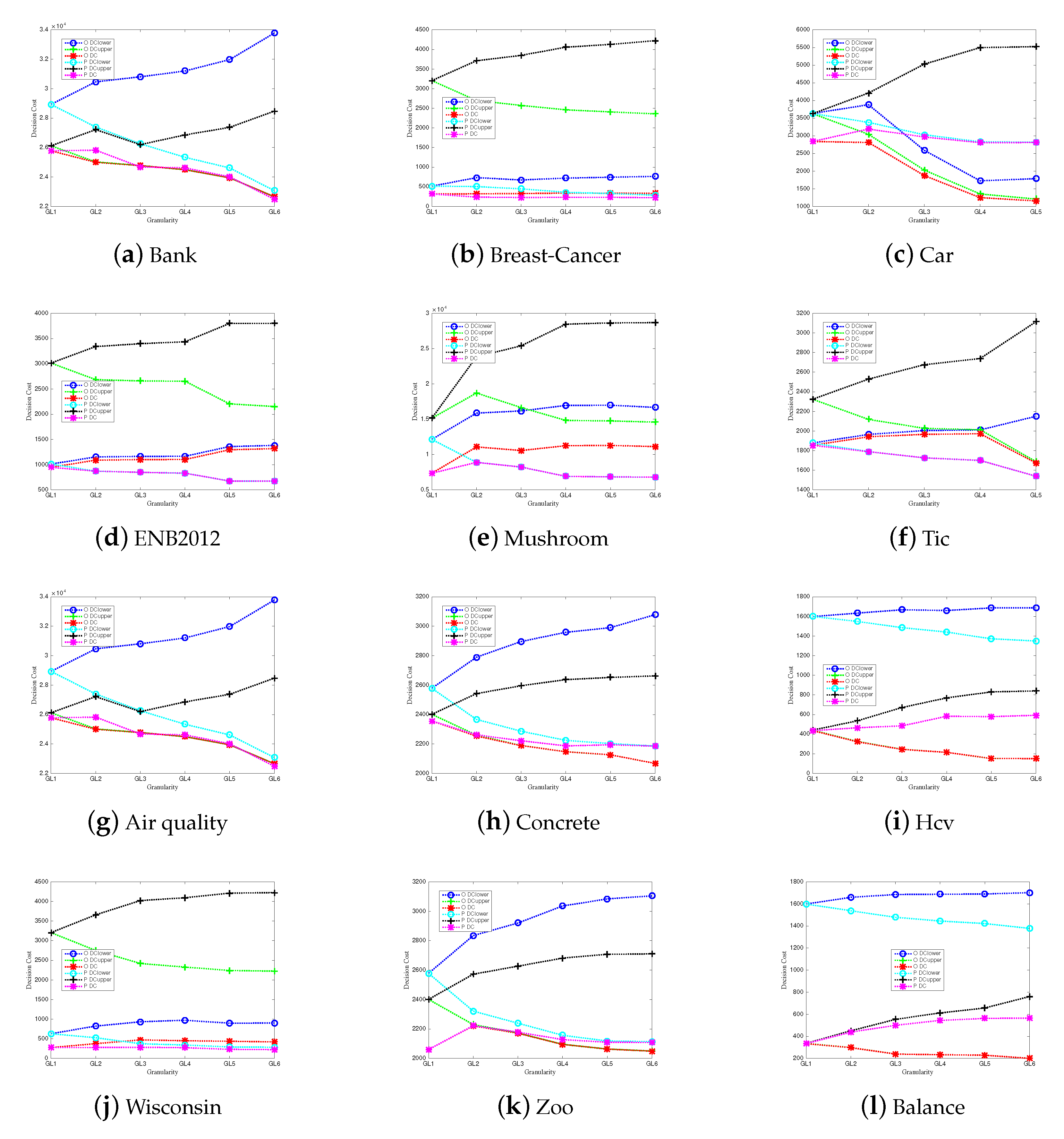
6. Simulation Experiment and Result Analysis
6.1. Simulation Experiment
6.2. Results and Discussions
- (1)
- The misclassification costs of the approximation model monotonously decrease with the granularity being finer;
- (2)
- In multigranulation approximations, under different granular layers, the misclassification costs incurred by the equivalence classes in approximating X are less than or equal to the misclassification costs incurred by the equivalence classes when they do not characterize X in boundary region I of optimistic and pessimistic rough sets. Moreover, the misclassification costs incurred by equivalence classes when they do not characterize X are less than or equal to the misclassification costs incurred by the equivalence classes in approximating X in boundary region II of optimistic and pessimistic rough sets;
- (3)
- Compared with the upper/lower approximation sets, the misclassification costs of the multigranulation approximations are the least on each granularity.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zadeh, L.A. Toward a theory of fuzzy information granulation and its centrality in human reasoning and fuzzy logic. Fuzzy Sets Syst. 1997, 90, 111–127. [Google Scholar] [CrossRef]
- Bello, M.; Nápoles, G.; Vanhoof, K.; Bello, R. Data quality measures based on granular computing for multi-label classification. Inf. Sci. 2021, 560, 51–67. [Google Scholar] [CrossRef]
- Pedrycz, W.; Chen, S. Interpretable Artificial Intelligence: A Perspective of Granular Computing; Springer Nature: Berlin/Heidelberg, Germany, 2021; Volume 937. [Google Scholar]
- Li, J.; Mei, C.; Xu, W.; Qian, Y. Concept learning via granular computing: A cognitive viewpoint. IEEE Trans. Fuzzy Syst. 2015, 298, 447–467. [Google Scholar] [CrossRef] [PubMed]
- Zadeh, L. Fuzzy sets. Inf. Control. 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Pawlak, Z. Rough sets. Int. J. Comput. Inf. Sci. 1982, 11, 341–356. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, B. The quotient space theory of problem solving. In Proceedings of the International Workshop on Rough Sets, Fuzzy Sets, Data Mining, and Granular-Soft Computing, Chongqing, China, 26–29 May 2003; pp. 11–15. [Google Scholar]
- Li, D.Y.; Meng, H.J.; Shi, X.M. Membership clouds and membership cloud generators. J. Comput. Res. Dev. 1995, 32, 15–20. [Google Scholar]
- Colas-Marquez, R.; Mahfouf, M. Data Mining and Modelling of Charpy Impact Energy for Alloy Steels Using Fuzzy Rough Sets. IFAC-Pap. 2017, 50, 14970–14975. [Google Scholar] [CrossRef]
- Hasegawa, K.; Koyama, M.; Arakawa, M.; Funatsu, K. Application of data mining to quantitative structure-activity relationship using rough set theory. Chemom. Intell. Lab. Syst. 2009, 99, 66–70. [Google Scholar] [CrossRef]
- Santra, D.; Basu, S.K.; Mandal, J.K.; Goswami, S. Rough set based lattice structure for knowledge representation in medical expert systems: Low back pain management case study. Expert Syst. Appl. 2020, 145, 113084. [Google Scholar] [CrossRef] [Green Version]
- Chebrolu, S.; Sanjeevi, S.G. Attribute Reduction in Decision-Theoretic Rough Set Model using Particle Swarm Optimization with the Threshold Parameters Determined using LMS Training Rule. Procedia Comput. Sci. 2015, 57, 527–536. [Google Scholar] [CrossRef] [Green Version]
- Abdolrazzagh-Nezhad, M.; Radgohar, H.; Salimian, S.N. Enhanced cultural algorithm to solve multi-objective attribute reduction based on rough set theory. Math. Comput. Simul. 2020, 170, 332–350. [Google Scholar] [CrossRef]
- Beaubier, S.; Defaix, C.; Albe-Slabi, S.; Aymes, A.; Galet, O.; Fournier, F.; Kapel, R. Multiobjective decision making strategy for selective albumin extraction from a rapeseed cold-pressed meal based on Rough Set approach. Food Bioprod. Process. 2022, 133, 34–44. [Google Scholar] [CrossRef]
- Landowski, M.; Landowska, A. Usage of the rough set theory for generating decision rules of number of traffic vehicles. Transp. Res. Procedia 2019, 39, 260–269. [Google Scholar] [CrossRef]
- Tawhid, M.; Ibrahim, A. Feature selection based on rough set approach, wrapper approach, and binary whale optimization algorithm. Int. J. Mach. Learn. Cybern. 2020, 11, 573–602. [Google Scholar] [CrossRef]
- Zhang, Q.H.; Wang, G.Y.; Yu, X. Approximation sets of rough sets. J. Softw. 2012, 23, 1745–1759. [Google Scholar] [CrossRef]
- Zhang, Q.H.; Wang, J.; Wang, G.Y. The approximate representation of rough-fuzzy sets. Chin. J. Comput. Jisuanji Xuebao 2015, 38, 1484–1496. [Google Scholar]
- Zhang, Q.; Wang, J.; Wang, G.; Yu, H. The approximation set of a vague set in rough approximation space. Inf. Sci. 2015, 300, 1–19. [Google Scholar] [CrossRef]
- Zhang, Q.H.; Zhang, P.; Wang, G.Y. Research on approximation set of rough set based on fuzzy similarity. J. Intell. Fuzzy Syst. 2017, 32, 2549–2562. [Google Scholar] [CrossRef]
- Zhang, Q.H.; Yang, J.J.; Yao, L.Y. Attribute reduction based on rough approximation set in algebra and information views. IEEE Access 2016, 4, 5399–5407. [Google Scholar] [CrossRef]
- Yao, L.Y.; Zhang, Q.H.; Hu, S.P.; Zhang, Q. Rough entropy for image segmentation based on approximation sets and particle swarm optimization. J. Front. Comput. Sci. Technol. 2016, 10, 699–708. [Google Scholar]
- Zhang, Q.H.; Liu, K.X.; Gao, M. Approximation sets of rough sets and granularity optimization algorithm based on cost-sensitive. J. Control. Decis. 2020, 35, 2070–2080. [Google Scholar]
- Yang, J.; Yuan, L.; Luo, T. Approximation set of rough fuzzy set based on misclassification cost. J. Chongqing Univ. Posts Telecommun. (Nat. Sci. Ed.) 2021, 33, 780–791. [Google Scholar]
- Yang, J.; Luo, T.; Zeng, L.J.; Jin, X. The cost-sensitive approximation of neighborhood rough sets and granular layer selection. J. Intell. Fuzzy Syst. 2022, 42, 3993–4003. [Google Scholar] [CrossRef]
- Siminski, K. 3WDNFS—Three-way decision neuro-fuzzy system for classification. Fuzzy Sets Syst. 2022, in press. [Google Scholar] [CrossRef]
- Subhashini, L.; Li, Y.; Zhang, J.; Atukorale, A.S. Assessing the effectiveness of a three-way decision-making framework with multiple features in simulating human judgement of opinion classification. Inf. Process. Manag. 2022, 59, 102823. [Google Scholar] [CrossRef]
- Subhashini, L.; Li, Y.; Zhang, J.; Atukorale, A.S. Integration of semantic patterns and fuzzy concepts to reduce the boundary region in three-way decision-making. Inf. Sci. 2022, 595, 257–277. [Google Scholar] [CrossRef]
- Mondal, A.; Roy, S.K.; Pamucar, D. Regret-based three-way decision making with possibility dominance and SPA theory in incomplete information system. Expert Syst. Appl. 2023, 211, 118688. [Google Scholar] [CrossRef]
- Yao, Y.Y. Symbols-Meaning-Value (SMV) space as a basis for a conceptual model of data science. Int. J. Approx. Reason. 2022, 144, 113–128. [Google Scholar] [CrossRef]
- Qian, Y.H.; Liang, J.Y.; Dang, C.Y. Incomplete multigranulation rough set. IEEE Trans. Syst. Man-Cybern.-Part Syst. Humans 2009, 40, 420–431. [Google Scholar] [CrossRef]
- Huang, B.; Guo, C.X.; Zhuang, Y.L.; Li, H.X.; Zhou, X.Z. Intuitionistic fuzzy multigranulation rough sets. Inf. Sci. 2014, 277, 299–320. [Google Scholar] [CrossRef]
- Li, F.J.; Qian, Y.H.; Wang, J.T.; Liang, J. Multigranulation information fusion: A Dempster-Shafer evidence theory-based clustering ensemble method. Inf. Sci. 2017, 378, 389–409. [Google Scholar] [CrossRef]
- Liu, X.; Qian, Y.H.; Liang, J.Y. A rule-extraction framework under multigranulation rough sets. Int. J. Mach. Learn. Cybern. 2014, 5, 319–326. [Google Scholar] [CrossRef]
- Liu, K.; Li, T.; Yang, X.; Ju, H.; Yang, X.; Liu, D. Hierarchical neighborhood entropy based multi-granularity attribute reduction with application to gene prioritization. Int. J. Approx. Reason. 2022, 148, 57–67. [Google Scholar] [CrossRef]
- Qian, Y.H.; Liang, X.Y.; Lin, G.P.; Guo, Q.; Liang, J. Local multigranulation decision-theoretic rough sets. Int. J. Approx. Reason. 2017, 82, 119–137. [Google Scholar] [CrossRef]
- Qian, Y.H.; Zhang, H.; Sang, Y.L.; Liang, J. Multigranulation decision-theoretic rough sets. Int. J. Approx. Reason. 2014, 55, 225–237. [Google Scholar] [CrossRef]
- Xu, W.; Yuan, K.; Li, W. Dynamic updating approximations of local generalized multigranulation neighborhood rough set. Appl. Intell. 2022, 52, 9148–9173. [Google Scholar] [CrossRef]
- Sun, L.; Wang, L.; Ding, W.; Qian, Y.; Xu, J. Feature selection using fuzzy neighborhood entropy-based uncertainty measures for fuzzy neighborhood multigranulation rough sets. IEEE Trans. Fuzzy Syst. 2020, 29, 19–33. [Google Scholar] [CrossRef]
- She, Y.H.; He, X.L.; Shi, H.X.; Qian, Y. A multiple-valued logic approach for multigranulation rough set model. Int. J. Approx. Reason. 2017, 82, 270–284. [Google Scholar] [CrossRef]
- Li, W.; Xu, W.; Zhang, X.Y.; Zhang, J. Updating approximations with dynamic objects based on local multigranulation rough sets in ordered information systems. Artif. Intell. Rev. 2021, 55, 1821–1855. [Google Scholar] [CrossRef]
- Zhang, C.; Li, D.; Zhai, Y.; Yang, Y. Multigranulation rough set model in hesitant fuzzy information systems and its application in person-job fit. Int. J. Mach. Learn. Cybern. 2019, 10, 717–729. [Google Scholar] [CrossRef]
- Hu, C.; Zhang, L.; Wang, B.; Zhang, Z.; Li, F. Incremental updating knowledge in neighborhood multigranulation rough sets under dynamic granular structures. Knowl.-Based Syst. 2019, 163, 811–829. [Google Scholar] [CrossRef]
- Hu, C.; Zhang, L. Dynamic dominance-based multigranulation rough sets approaches with evolving ordered data. Int. J. Mach. Learn. Cybern. 2021, 12, 17–38. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| X | ||||
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | |
| 0 | 0 | 1 | 0 | |
| 0 | 1 | 0 | 0 | |
| 0 | 1 | 1 | 1 | |
| 1 | 0 | 0 | 0 | |
| 1 | 0 | 1 | 1 | |
| 1 | 1 | 0 | 1 | |
| 1 | 1 | 1 | 1 |
| Firm | D | |||||
|---|---|---|---|---|---|---|
| 3 | 3 | 3 | 3 | 1 | High | |
| 2 | 1 | 2 | 3 | 2 | High | |
| 2 | 1 | 2 | 1 | 2 | High | |
| · | · | · | · | · | · | · |
| · | · | · | · | · | · | · |
| · | · | · | · | · | · | · |
| 3 | 3 | 2 | 2 | 3 | Low | |
| 3 | 1 | 3 | 3 | 1 | Low | |
| 1 | 1 | 3 | 3 | 1 | Low |
| Attribute | |||||
|---|---|---|---|---|---|
| 0.74 | 0.56 | 0.54 | 0.36 | 0.77 |
| 8.3 | 5.9 | 4.7 | 3.6 | 3.5 | |
| 0.36 | 0.9 | 1.46 | 2.2 | 2.97 | |
| 8.66 | 6.8 | 6.16 | 5.8 | 6.47 |
| ID | Dataset | Attribute Characteristics | Instances | Condition Attributes |
|---|---|---|---|---|
| 1 | Bank | Integer | 39 | 12 |
| 2 | Breast-Cancer | Integer | 699 | 9 |
| 3 | Car | Integer | 1728 | 6 |
| 4 | ENB2012data | Real | 768 | 8 |
| 5 | Mushroom | Integer | 8124 | 22 |
| 6 | Tic | Integer | 958 | 9 |
| 7 | Air Quality | Real | 9358 | 12 |
| 8 | Concrete | Real | 1030 | 8 |
| 9 | Hcv | Real | 569 | 10 |
| 10 | Wisconsin | Real | 699 | 9 |
| 11 | Zoo | Integer | 101 | 16 |
| 12 | Balance | Integer | 625 | 4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Kuang, J.; Liu, Q.; Liu, Y. Cost-Sensitive Multigranulation Approximation in Decision-Making Applications. Electronics 2022, 11, 3801. https://doi.org/10.3390/electronics11223801
Yang J, Kuang J, Liu Q, Liu Y. Cost-Sensitive Multigranulation Approximation in Decision-Making Applications. Electronics. 2022; 11(22):3801. https://doi.org/10.3390/electronics11223801
Chicago/Turabian StyleYang, Jie, Juncheng Kuang, Qun Liu, and Yanmin Liu. 2022. "Cost-Sensitive Multigranulation Approximation in Decision-Making Applications" Electronics 11, no. 22: 3801. https://doi.org/10.3390/electronics11223801
APA StyleYang, J., Kuang, J., Liu, Q., & Liu, Y. (2022). Cost-Sensitive Multigranulation Approximation in Decision-Making Applications. Electronics, 11(22), 3801. https://doi.org/10.3390/electronics11223801