
Entity-Based Integration Framework on Social Unrest Event Detection in Social Media


Abstract
1. Introduction
- In view of social network data collection and analysis, we capture the open-source social network data, extract event-related content automatically from the raw dataset, and detect social unrest events;
- Using neural network algorithms, we propose an entity-based social unrest event detection model to preprocess a large number of unlabeled and unstructured data. The results show that the model can effectively extract event-related entities from the raw text and perform dynamic topic analysis;
- Based on the proposed event detection model, we compare the posts on the online discussion forum (Lihkg forum) and social media (Twitter) in the same period of time and perform long-term dynamic analysis. Comparison analysis is conducted to explore the differences between local and international social media platforms.
2. Related Work
3. Integration Framework on Event Detection
3.1. Definition of Social Unrest Event
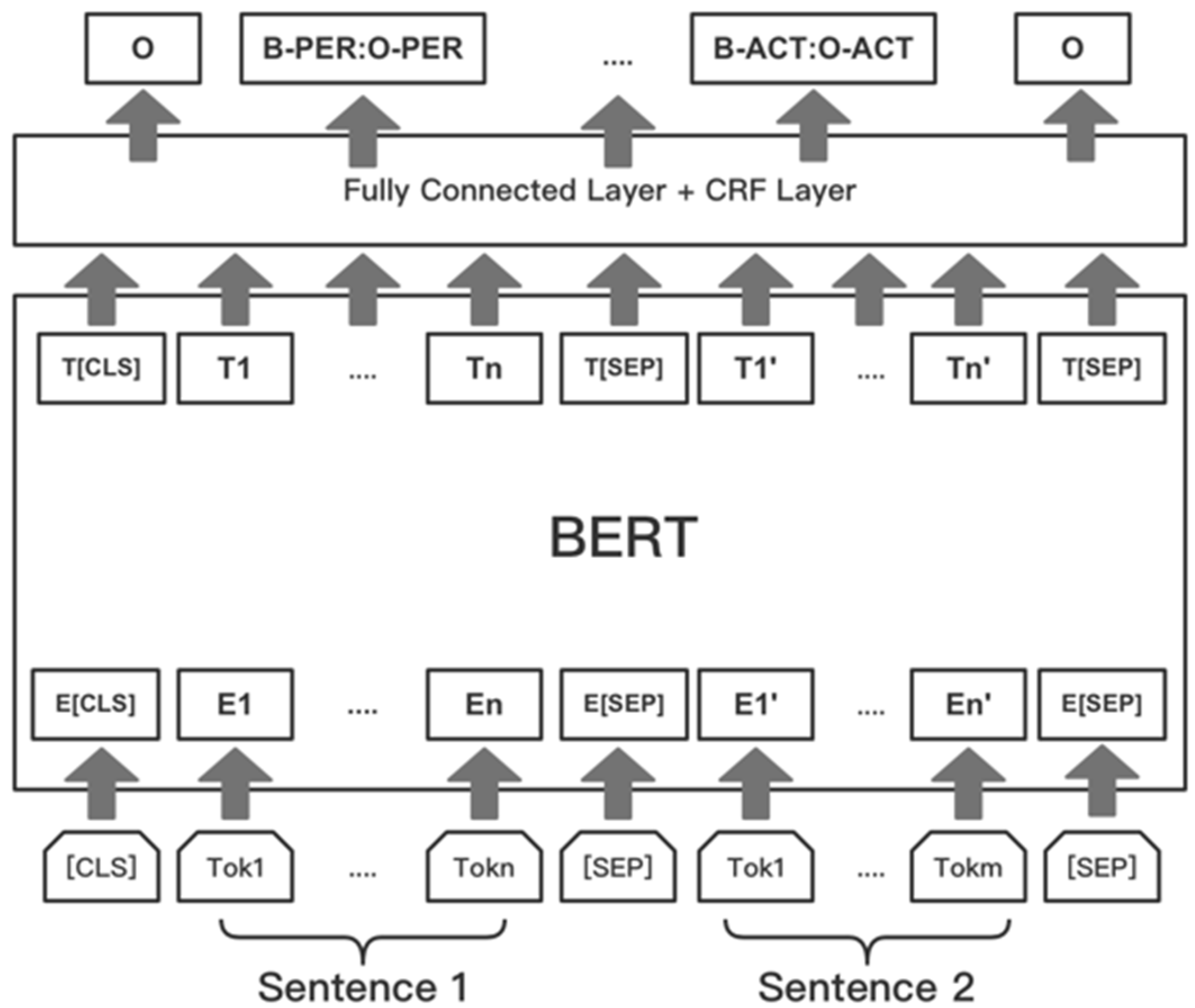
3.2. NER and Event Trigger
3.3. K-Means Clustering
3.4. Dynamic Topic Model
4. Experiment and Analysis
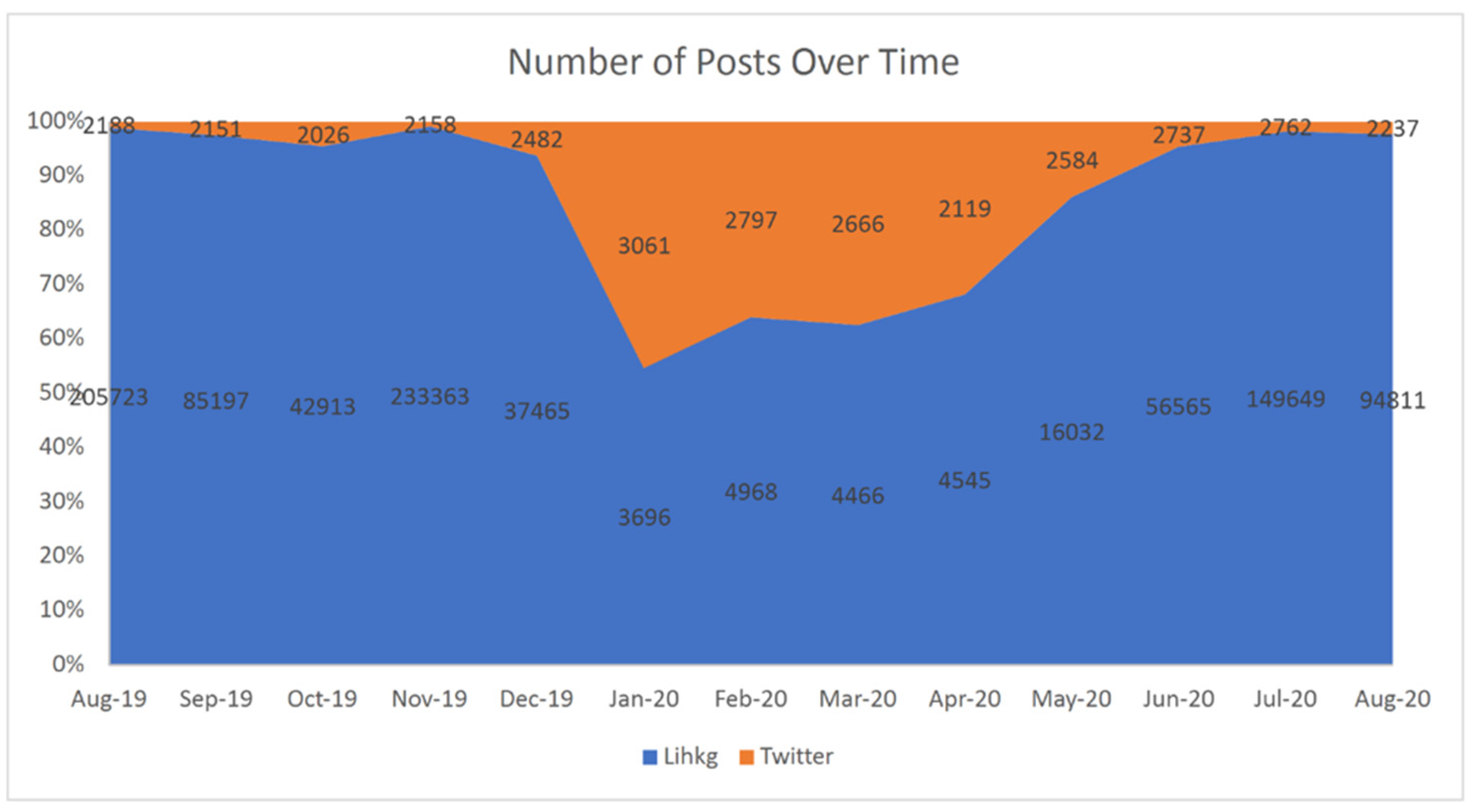
4.1. Data Collection and Labeling
- Person: Relevant person name. For example, “林鄭月娥” (Carrie Lam Cheng Yuet-ngor, the current Chief Executive of Hong Kong) and “thug” are labeled as <PER>;
- Time: Relevant date and time information. For example, “17:05”, “10月20日 (20 October)”, and so on. They are labeled with <TIM>;
- Location: Relevant addresses, including names of country, public place, road, and building. For example, “Hong Kong”, “Airport”, and “Cheung Sha Wan Station”. Location information is labeled with <LOC>;
- Organization: Relevant names of organization, including “Hong Kong Police”, “the Government”, and “The Central Committee”. They are tagged as <ORG>;
- Crime: Relevant crimes such as “assault”, “riot”, “vandalism”, and “fire”. These nouns involved in illegal activities are tagged as <CRM>;
- Action: Relevant actions mentioned on the posts. For example, “sit-in”, “destroy”, “gather”, “commit arson”, and so on. These verbs are tagged as <ACT>;
- Tool: Hazardous tools mentioned on the posts, such as “metal rod”, “arms”, “fire extinguisher”, and “petrol bomb”. They are labeled as <TOO>;
- Emotion: Emotional words on the posts, such as “hatred”, “love”, and “support”. They are labeled as <EMO>.
4.2. NER and Trigger Analysis
4.3. Clustering Comparison
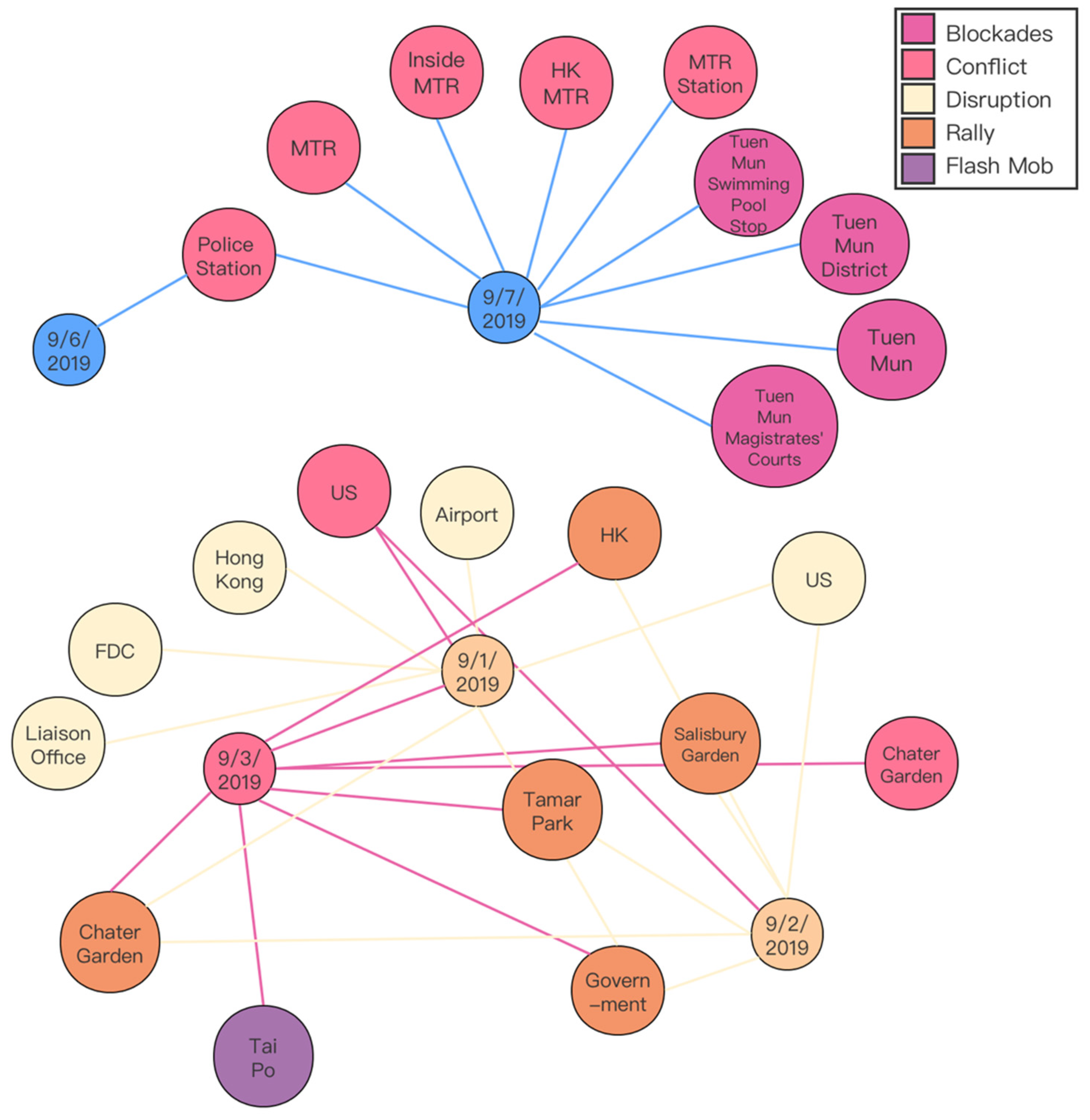
4.4. Event Tracing
5. Discussion
5.1. Event Spreading on Social Media
- (1)
- People talk about different topics at different time periods. Even if the topic is the same, the words will change accordingly, particularly in the way they describe other people. For example, their addressing of the police changes from “Police” to “Black Police”, then to “Black Dog”.
- (2)
- Some regular topics relatively maintain a certain level of popularity, including international relations, laws and regulations, and some popular words related to demonstration.
- (3)
- The appearance of some irregular topics will reduce the popularity of regular topics and will temporarily become hot topics, especially when emergencies that threaten people’s safety or national interests occur. For example, the traffic jam caused by protests, the appearance of COVID-19, topics arising from the words and deeds of public figures, and so on.
- (4)
- Some topics related to a specific time or festival will become more and more popular as the date approaches. Before the festivals such as Hong Kong Special Administrative Region Establishment Day and National Day of the People’s Republic of China, the number of posts and demonstrations will increase greatly. For example, on National Day, there is a demonstration called “No national day! Only national death!” which is also the keyword of the posts at that period of time. These topics are predictable to a certain extent, and some preventive measures can be taken in advance.
5.2. Use Cases for Event Detection Framework
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cadena, J.; Korkmaz, G.; Kuhlman, C.J.; Marathe, A.; Ramakrishnan, N.; Vullikanti, A. Forecasting social unrest using activity cascades. PLoS ONE 2015, 10, e0128879. [Google Scholar] [CrossRef]
- Muthiah, S.; Huang, B.; Arredondo, J.; Mares, D.; Getoor, L.; Katz, G.; Ramakrishnan, N. Planned protest modeling in news and social media. In Proceedings of the Twenty-Seventh IAAI Conference, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Harris, C.J. Police use of improper force: A systematic review of the evidence. Vict. Offenders 2009, 4, 25–41. [Google Scholar] [CrossRef]
- Shek, D.T.L. Protests in Hong Kong (2019–2020): A perspective based on quality of life and well-being. Appl. Res. Qual. Life 2020, 15, 619–635. [Google Scholar] [CrossRef]
- Agarwal, S.; Sureka, A. Applying social media intelligence for predicting and identifying online radicalization and civil unrest oriented threats. arXiv 2015, arXiv:1511.06858. [Google Scholar]
- Newell, E.; Jurgens, D.; Saleem, H.M.; Vala, H.; Sas-sine, J.; Armstrong, C.; Ruths, D. User migration in online social networks: A case study on reddit during a period of community unrest. In Proceedings of the Tenth International AAAI Conference on Web and Social Media, Cologne, Germany, 17–20 May 2016. [Google Scholar]
- Vătămănescu, E.M.; Bratianu, C.; Dabija, D.C.; Popa, S. Capitalizing online knowledge networks: From individual knowledge acquisition towards organizational achievements. J. Knowl. Manag. 2022; ahead-of-print. [Google Scholar] [CrossRef]
- Benkhelifa, E.; Rowe, E.; Kinmond, R.; Adedugbe, O.A.; Welsh, T. Exploiting social networks for the prediction of social and civil unrest: A cloud based framework. In Proceedings of the 2014 International Conference on Future Internet of Things and Cloud, Barcelona, Spain, 27–29 August 2014; pp. 565–572. [Google Scholar]
- Ji, Y.; Lin, Y.; Gao, J.; Wan, H. Exploiting the entity type sequence to benefit event detection. In Proceedings of the The 23rd Conference on Compu-tational Natural Language Learning (CoNLL), Hong Kong, China, 3–4 November 2019; pp. 613–623. [Google Scholar]
- Zhao, Y.; Jin, X.; Wang, Y.; Cheng, X. Document embedding enhanced event detection with hierarchical and supervised attention. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 2, pp. 414–419. [Google Scholar]
- Wang, X.; Wang, Z.; Han, X.; Jiang, W.; Han, R.; Liu, Z.; Zhou, J. MAVEN: A massive general domain event detection dataset. arXiv 2020, arXiv:2004.13590. [Google Scholar]
- Yin, H.; Cao, J.; Cao, L.; Wang, G. Chinese emergency event recognition using conv-RDBiGRU model. Comput. Intell. Neurosci. 2020, 2020, 7090918. [Google Scholar] [CrossRef]
- Chiu, J.P.; Nichols, E. Named entity recognition with bidirectional LSTM-CNNs. Trans. Assoc. Comput. Linguist. 2016, 4, 357–370. [Google Scholar] [CrossRef]
- Yadav, V.; Bethard, S. A survey on recent advances in named entity recognition from deep learning models. arXiv 2019, arXiv:1910.11470. [Google Scholar]
- Wu, Y.; Jiang, M.; Lei, J.; Xu, H. Named entity recognition in Chinese clinical text using deep neural network. Stud. Health Technol. Inform. 2015, 216, 624. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Cho, K.; Merriënboer, B.V.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Liang, C.; Yu, Y.; Jiang, H.; Er, S.; Wang, R.; Zhao, T.; Zhang, C. Bond: Bert-assisted open-domain named entity recognition with distant supervision. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Virtual Event, 23–27 August 2020; pp. 1054–1064. [Google Scholar]
- Boros, E.; Besancon, R.; Ferret, O.; Grau, B. The Importance of Character-Level Information in an Event Detection Model. In International Conference on Applications of Natural Language to Information Systems; Springer: Cham, Switzerland, 2021; pp. 119–131. [Google Scholar]
- Hamborg, F.; Breitinger, C.; Gipp, B. Giveme5w1h: A universal system for extracting main events from news articles. arXiv 2019, arXiv:1909.02766. [Google Scholar]
- Karaman, Ç.Ç.; Yalıman, S.; Oto, S.A. Event detection from social media: 5W1H analysis on big data. In Proceedings of the 2017 25th Signal Processing and Communications Applications Conference (SIU), Antalya, Turkey, 15–18 May 2017; pp. 1–4. [Google Scholar]
- Chakma, K.; Swamy, S.D.; Das, A.; Debbarma, S. 5W1H-Based semantic segmentation of tweets for event detection using BERT. In International Conference on Machine Learning, Image Processing, Network Security and Data Sciences; Springer: Singapore, 2020; pp. 57–72. [Google Scholar]
- Hossny, A.H.; Mitchell, L. Event detection in twitter: A keyword volume approach. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; pp. 1200–1208. [Google Scholar]
- Iyda, J.J.; Geetha, P. Keyword-Based Approach for Detecting Civil Unrest Events from Social Media. In EAI International Conference on Big Data Innovation for Sustainable Cognitive Computing; Springer: Cham, Switzerland, 2020; pp. 287–298. [Google Scholar]
- Becker, H.; Naaman, M.; Gravano, L. Beyond trending topics: Real-world event identification on twitter. In Proceedings of the International AAAI Conference on Web and Social Media, Catalonia, Spain, 17–21 July 2011; pp. 438–441. [Google Scholar]
- Allan, J.; Papka, R.; Lavrenko, V. On-line new event detection and tracking. In Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Melbourne, Australia, 24–28 August 1998; pp. 37–45. [Google Scholar]
- Chambers, N.; Jurafsky, D. Template-based information extraction without the templates. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, Oregon, 19–24 June 2011; pp. 976–986. [Google Scholar]
- Lee, C.S.; Chen, Y.J.; Jian, Z.W. Ontology-based fuzzy event extraction agent for Chinese e-news summarization. Expert Syst. Appl. 2003, 25, 431–447. [Google Scholar] [CrossRef]
- Inyaem, U.; Meesad, P.; Haruechaiyasak, C.; Tran, D. Construction of fuzzy ontology-based terrorism event extraction. In Proceedings of the 2010 Third International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 9–10 January 2010; pp. 391–394. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Ying, H. New Event Detection Based on LDA and Correlation of Topic Terms. Comput. Mod. 2012, 1, 6. [Google Scholar]
- Wang, X.; McCallum, A. Topics over time: A non-markov continuous time model of topical trends. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 424–433. [Google Scholar]
- Blei, D.M.; Lafferty, J.D. Dynamic topic models. In Proceedings of the 23rd international conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 113–120. [Google Scholar]
- Zhang, X.; Wang, T. Topic Tracking with Dynamic Topic Model and Topic-based Weighting Method. J. Softw. 2010, 5, 482–489. [Google Scholar] [CrossRef]
- Yao, F.; Wang, Y. Tracking urban geo-topics based on dynamic topic model. Comput. Environ. Urban Syst. 2020, 79, 101419. [Google Scholar] [CrossRef]
- Song, Y.; Yi, E.; Kim, E.; Lee, G.G.; Park, S.J. POSBIOTM-NER: A machine learning approach for bio-named entity recognition. Korea 2004, 305, 350. [Google Scholar]
- Wojek, C.; Schiele, B. A dynamic conditional random field model for joint labeling of object and scene classes. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2008; pp. 733–747. [Google Scholar]
- Shen, A.; Chow, K.P. Time and Location Topic Model for analyzing Lihkg forum data. In Proceedings of the 2020 13th International Conference on Systematic Approaches to Digital Forensic Engineering (SADFE), New York, NY, USA, 15 May 2020. [Google Scholar]
- Geographic Information in HK. Available online: https://data.gov.hk/en-data/dataset/hk-ogcio-st_div_02-als (accessed on 4 July 2022).
- Bhadury, A.; Chen, J.; Zhu, J.; Liu, S. Scaling up dynamic topic models. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–15 May 2016; pp. 381–390. [Google Scholar]
- Kingma, D.P.; Adam, J.B. A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measurement | Entity Identification | Entity Classification |
|---|---|---|
| Accuracy | 95.02% | - |
| Precision | 0.91 | 0.74 |
| Recall | 0.83 | 0.61 |
| F1-score | 0.86 | 0.67 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| BiLSTM-CRF | 90.35% | 0.68 | 0.55 | 0.61 |
| BERT-CRF | 95.02% | 0.74 | 0.61 | 0.67 |
| Named Entity | Frequency | Named Entity | Frequency |
|---|---|---|---|
| 路障 (Set roadblock) | 461 | 聚集 (Gathering) | 259 |
| 遊行 (Procession) | 453 | 堵塞 (Block) | 188 |
| 示威 (Demonstration) | 425 | 包圍 (Encircle) | 187 |
| 堵路 (Block the road) | 330 | 罷工 (Labor strike) | 159 |
| 集會 (Assembly) | 298 | 佔領 (Occupy) | 157 |
| Cluster No. | Named Entities |
|---|---|
| 1 | 5 August 2019, 天水圍警署 (Tin Shui Wai Police Station), 示威者 (Demonstrator), 警員 (Police) |
| 2 | 5 August 2019, 深水埗 (Sham Shui Po), 催淚彈 (Tear gas), 黃大仙 (Wong Tai Sin), 警員 (Police) |
| 3 | 5 August 2019, 沙田 (Sha Tin), 聚集 (Gathering) |
| 4 | 5 August 2019, 荃灣 (Tsuen Wan), 襲擊 (Attack), 眾安街 (Chung On Street), 示威者 (Demonstrator) |
| Topic 0 (People involved in demonstration) | 藍絲 (Blue Ribbon), 警方 (Police), 示威者 (Demonstrator), 催淚彈 (Tear gas), 暴徒 (Thug), 白衫 (White Shirt), 攻擊 (Attack), 街坊 (Neighborhood) |
| Topic 2 (Location) | 機場 (Airport), 觀塘 (Kwun Tong), 太子 (Prince Edward), 學校 (School), 黃埔 (Whampoa), 香港 (Hong Kong), 屯門 (Tuen Mun), 學生 (Students) |
| Topic 3 (Different roles) | 警員 (Police officer), 林鄭 (Lam Cheng), 市民 (Citizen), 警隊 (Police force), 記者 (Reporter), 示威者 (Demonstrator) |
| Topic 6 (Countries and regions) | 香港 (Hong Kong), 中國 (China), 美國 (America), 大陸 (Mainland), 英國 (United Kingdom), 外國 (Foreign country) |
| Posts | Event Trigger |
|---|---|
| 大角咀之路 六校人鏈 日期: 9月9日 Tai Kok Tsui Road Six schools human chain Date: 9 September | Human chain |
| 119 星期日 天下制裁 遮打花園集會安排 119 Sunday Sanctions Chater Garden Rally | Rally |
| 今晚7點一齊坐爆元朗站 Tonight 7 pm sit-in Yuen Long Station | Sit-in |
| 今晚獅子山都有人鏈! Tonight Human chain on Lion Rock | Human chain |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, A.; Chow, K.P. Entity-Based Integration Framework on Social Unrest Event Detection in Social Media. Electronics 2022, 11, 3416. https://doi.org/10.3390/electronics11203416
Shen A, Chow KP. Entity-Based Integration Framework on Social Unrest Event Detection in Social Media. Electronics. 2022; 11(20):3416. https://doi.org/10.3390/electronics11203416
Chicago/Turabian StyleShen, Ao, and Kam Pui Chow. 2022. "Entity-Based Integration Framework on Social Unrest Event Detection in Social Media" Electronics 11, no. 20: 3416. https://doi.org/10.3390/electronics11203416
APA StyleShen, A., & Chow, K. P. (2022). Entity-Based Integration Framework on Social Unrest Event Detection in Social Media. Electronics, 11(20), 3416. https://doi.org/10.3390/electronics11203416