


Reservoir Prediction Model via the Fusion of Optimized Long Short-Term Memory Network (LSTM) and Bidirectional Random Vector Functional Link (RVFL)


Abstract
1. Introduction
- (1)
- An AOS algorithm based on chaos theory and improved individual memory functions is proposed. First, the population is initialized by chaos theory, and the randomness of the population distribution is increased. Then, inspired by the PSO optimization algorithm, the individual memory function is added during the algorithm development phase to improve the optimization accuracy.
- (2)
- The poor robustness of the LSTM is attributed to the randomized generation of hyperparameters such as the number of initial neurons in the hidden layer, the learning rate, the number of iterations and the packet size. To better improve the performance of the LSTM, the IAOS is combined with the LSTM to optimize the performance of the LSTM by performing a global search for the above six parameters.
- (3)
- Inspired by the Bidirectional Extreme Learning Machine (B-ELM) and the better performance of RVFL over ELM [41,42], we propose a double-ended RVFL algorithm. BRVFL computes the optimal value of the hidden layer neurons for finding the RVFL to ensure that model minimizes the training elapsed time with training accuracy.
- (4)
- In this study, a hybrid model ILSTM-BRVFL is used for the first time for oil layer prediction. The model achieves feature extraction of the oil layer data by ILSTM. BRVFL improves the accuracy of feature prediction, reduces the model running time, and has a greater advantage in oil layer prediction. To verify the performance of the proposed model, its convergence and stability are tested using evaluation metrics (precision (P), recall (R), F1-score, and accuracy) and the confusion matrix, respectively, and compared with similar algorithms. In addition, we analyze the effect of the number of hidden nodes and the number of search groups on the accuracy of the model.
2. Preparatory Knowledge
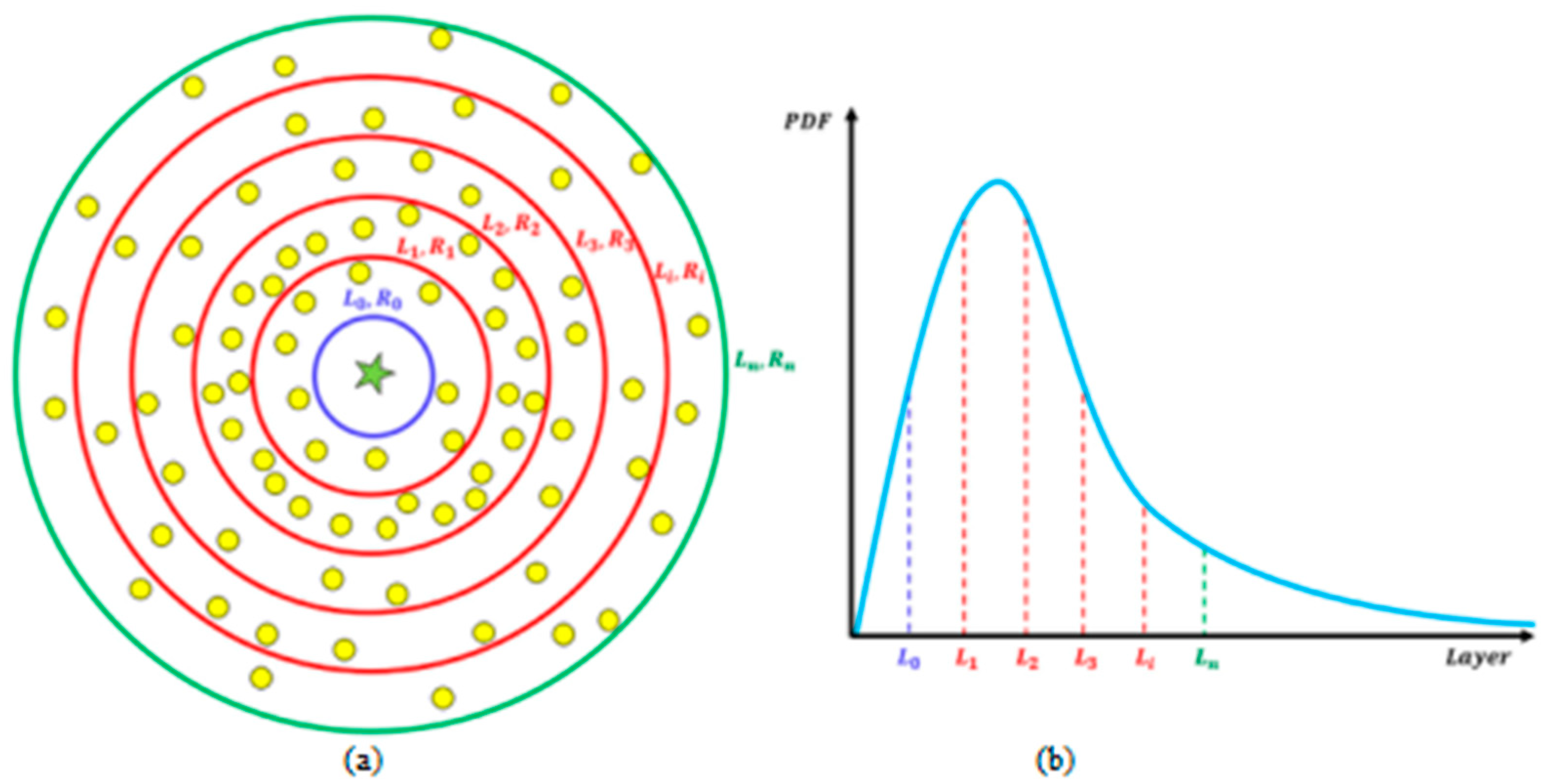
2.1. Atomic Orbital Search (AOS) Algorithm
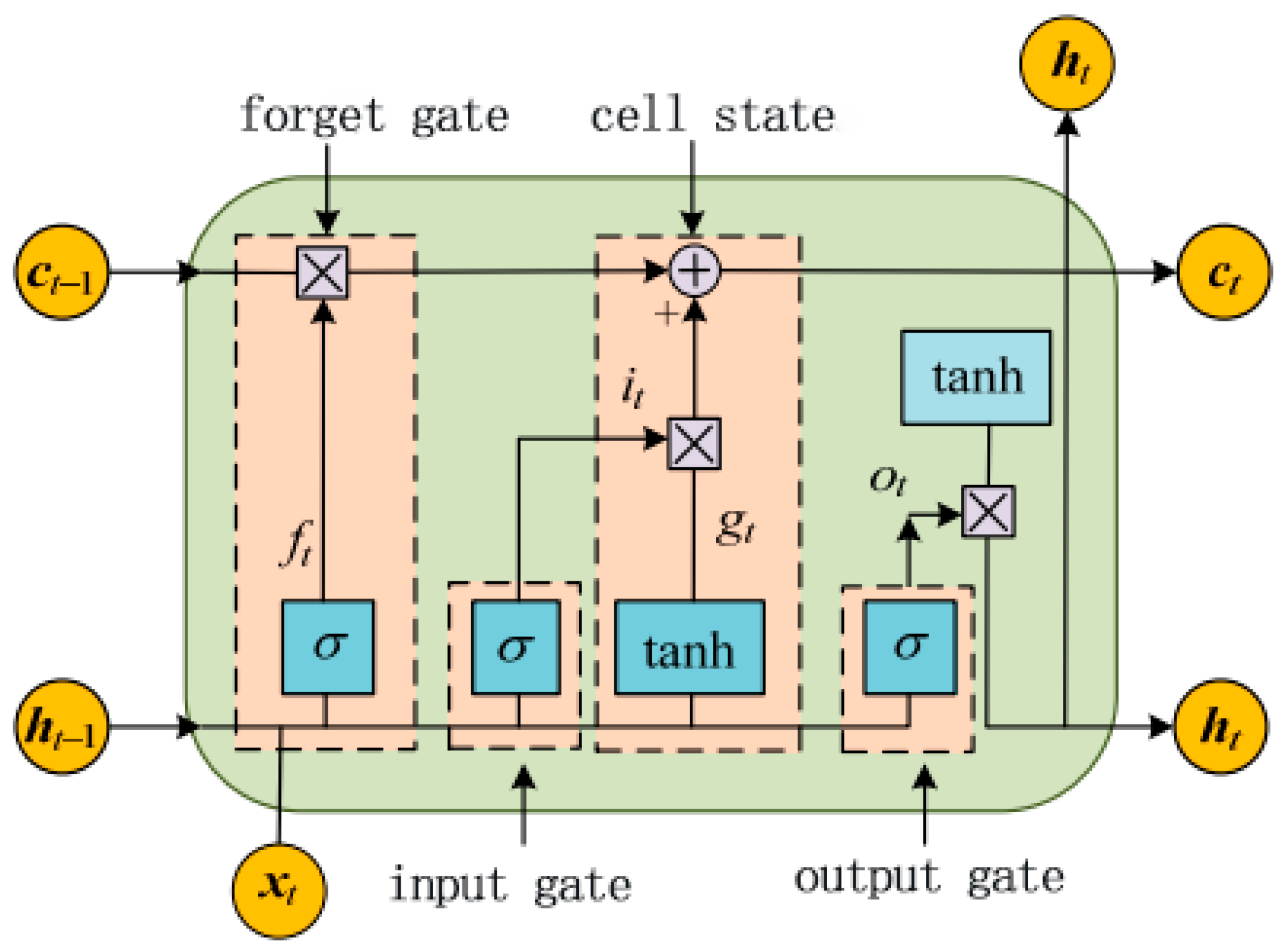
2.2. Basic LSTM
2.3. Random Vector Functional Link Network (RVFL)
- (1)
- Input layer
- (2)
- Hidden layer
- (3)
- Output layer
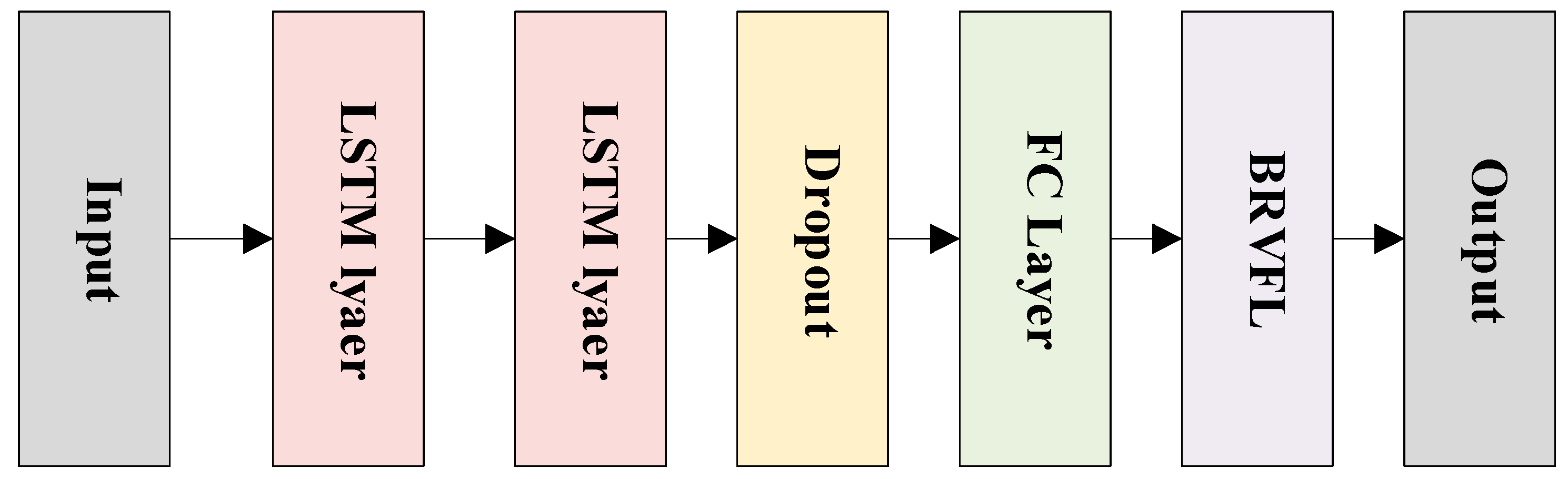
3. Reservoir Prediction Model Based on ILSTM-BRVFL
3.1. Improved Atomic Orbital Search Algorithm (IAOS)
3.1.1. Population Initialization Based on Chaos Theory
3.1.2. Position Updating Based on Individual Memory Function
- (1)
- Initialize the population, initialize the population size m, candidate positions xi, fitness function Ei, determine the binding state (BS) and binding energy (BE) of the atom, determine the candidate atom with the lowest energy level (LE) in the atom, maximum number of iterations (Maximum).
- (2)
- Sort the candidate solutions in ascending or descending order to form the solution space by probability density function (PDF).
- (3)
- Global exploration according to Equations (10) and (11) and local exploitation according to Equation (25).
- (4)
- The maximum number of iterations is reached, and the output is saved.
| Algorithm 1 IAOS |
| Inputs: The population size m, initial positions of solution candidates (xi) based on chaos theory, Evaluate fitness values for initial solution candidates, determine binding state (BS) and binding energy (BE) of atom, determine candidate with lowest energy level in atom (LE) Outputs: The lowest energy level in atom (LE) While Iteration < Maximum number of iteration Generate n as the number of imaginary layers Create imaginary layers Sort solution candidates in an ascending or descending order Distribute solution candidates in the imaginary layers by PDF For k = 1:n Determine the binding state () and binding energy () of the kth layer Determine the candidate with lowest energy level in the kth layer () For i = 1:p Generate Determine PR If If Run Equation (10) Else if Run Equation (11) End Else if Run Equation (25) End End End Update binding state (BS) and binding energy (BE) of atom Update candidate with lowest energy level in atom (LE) End while |
3.2. LSTM Based on Improved IAOS (ILSTM)
- (1)
- Initialize the relevant parameters, and initialize the IAOS algorithm parameters: population size, fitness function, and other parameters assigned. Initialize the LSTM algorithm parameters: set the time window, set the initial number of neurons in the two-layer hidden layer, the initial learning rate, the initial number of epochs, and the batch size. In addition, the error is used as the fitness function in this paper with the following expressions.where D denotes the training set, m is the number of samples in the training set, is the predicted sample label, is the original sample label, and is a function that takes the value of 1 if and 0 otherwise.
- (2)
- Set the LSTM parameters to form the corresponding particles according to the need, and the particle structure is (, , , , ), where denotes the LSTM learning rate, denotes the number of iterations, denotes the packet size, denotes the number of neurons in the first hidden layer of LSTM, denotes the number of neurons in the second hidden layer of LSTM, and the above particles are the IAOS optimized LSTM super parameters.
- (3)
- The electron energy is updated according to Equation (10), and then the fitness value is calculated according to the new electron energy, and the lowest energy electron individual optimal solution is updated.
- (4)
- If the number of iterations reaches the maximum number of 100 iterations, the predicted values are output for the trained LSTM model according to the optimal solution, and if the number of iterations does not reach the maximum, the process (3) is returned to continue iterating.
- (5)
- The optimal hyper-parameters are brought into the LSTM model, which is the IAOS-LSTM model.
| Algorithm 2 Pseudocode of IAOS optimized LSTM |
| Input: Training samples set: trainsets, LSTM initialization parameters |
| Output: IAOS-LSTM model |
| 1. Initialize the LSTM model: |
| assign parameters range = [lr,epoch,batch_size,hidden0,hidden1,] = [0.0001–0.01,25–100,0–256,0–128,0–128]; |
| loss = ‘categorical_crossentropy’, optimizer = adam |
| 2. Set IAOS equalization parameters and Import trainsets to Optimization: parameters para = [lr,epoch,batch_size,hidden0,hidden1,] = fitness = 1-acc = Error Equation (26) num_iteration = 100 IAOS-LSTM = LSTM(IAOS(para),trainsets) save model:save(‘IAOS-LSTM’) return para_best to LSTM model |
3.3. Bidirectional RVFL (BRVFL)
| Algorithm 3 Pseudocode of BRVFL |
| Input: training set: ; Maximum number of hidden layer neurons. Hidden layer mapping function ; training accuracy: . |
| Output: The trained BRVFL model parameters |
| Recursive training process. |
| Initial error matrix , initial hidden layer node |
| When , and . |
| Set. |
| If |
| 1. Random selection of neuron parameters and . |
| 2. Calculate the randomly generated function sequence according to Equation (27), |
| 3. Calculate the output weight according to Equation (28) |
| If |
| 4. Calculate the error return function according to Equation (29) |
| 5. Calculate the input weight and bias according to Equations (30) and (31). |
| 6. Update according to Equation (32) |
| 7. Calculate the output weight according to Equation (33) |
| After adding a new node, calculate the error |
| When
End |
3.4. Actual Application in Oil Layer Prediction
| Algorithm 4 Pseudocode ofILSTM-BRVFL |
| Input: Training set, test set, parameters of IAOS |
| Assign hyper-parameters range of ILSTM-BRVFL model = [lr,epoch,batch_size,hidden0,hidden1] = [0.0001–0.01,0–128,0–256,0–256,0–256], T = 80, population of IAOS = 30, dim of IAOS = 5, k = 5, loss of ILSTM-BRVFL model = ‘categorical_crossentropy’, optimizer of ILSTM-BRVFL model = adam, Dropout = 0.5 |
| Output: ILSTM-BRVFL model, test set accuracy, best hyper-parameters of ILSTM-BRVFL model. |
| 1. use k-fold cross validation to split the training set into five identical data sets |
|
For t = 1:k Use four of the five data sets in the training set as the training set, one as the Validation Set, and select a different one of the five as the Validation Set each iteration time. |
| 2. Initialize the population of IAOS value based on the hyper-parameters range of ILSTM-BRVFL model: |
| 3. Calculate the fitness function based on Equation (26) and find the current optimal solution |
| While t1< T For i = i: dim Determine particle state and update particle position End for Updating the hyper-parameters of ILSTM = BRVFL models to predict Validation Set accuracy t1 = t1 + 1 End while End for Record the best hyper-parameters of ILSTM = BRVFL models. Build the ILSTM-BRVFL model Use the ILSTM-BRVFL model to predict Test set. |
- (1)
- Data collection and normalization
- (2)
- Selection of the sample set and attribute simplification
- (3)
- ILSTM-BRVFL modeling
- (4)
- Comparison of algorithm results
4. Experiment and Result Analysis
4.1. Experimental Settings and Algorithm Parameters
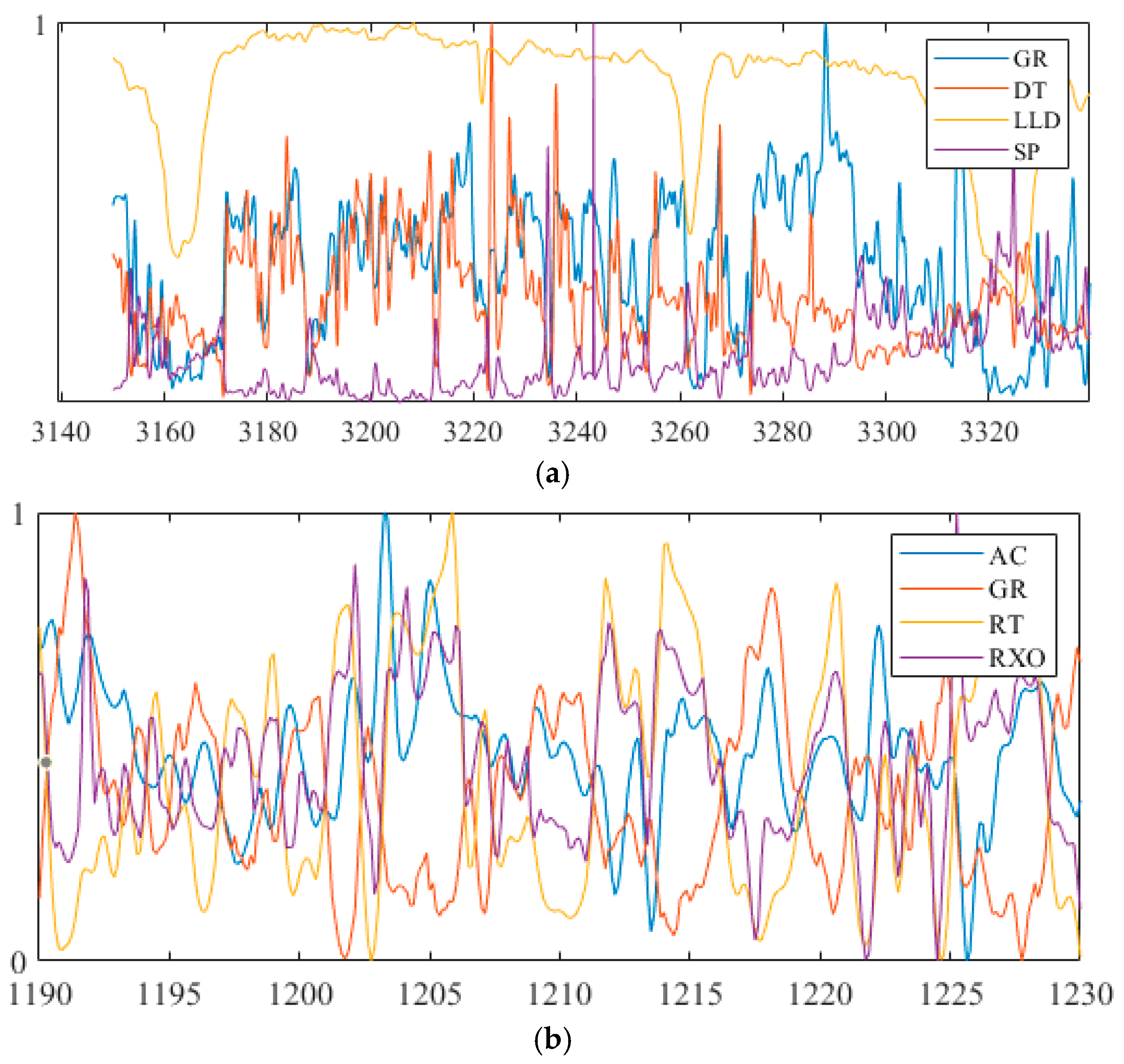
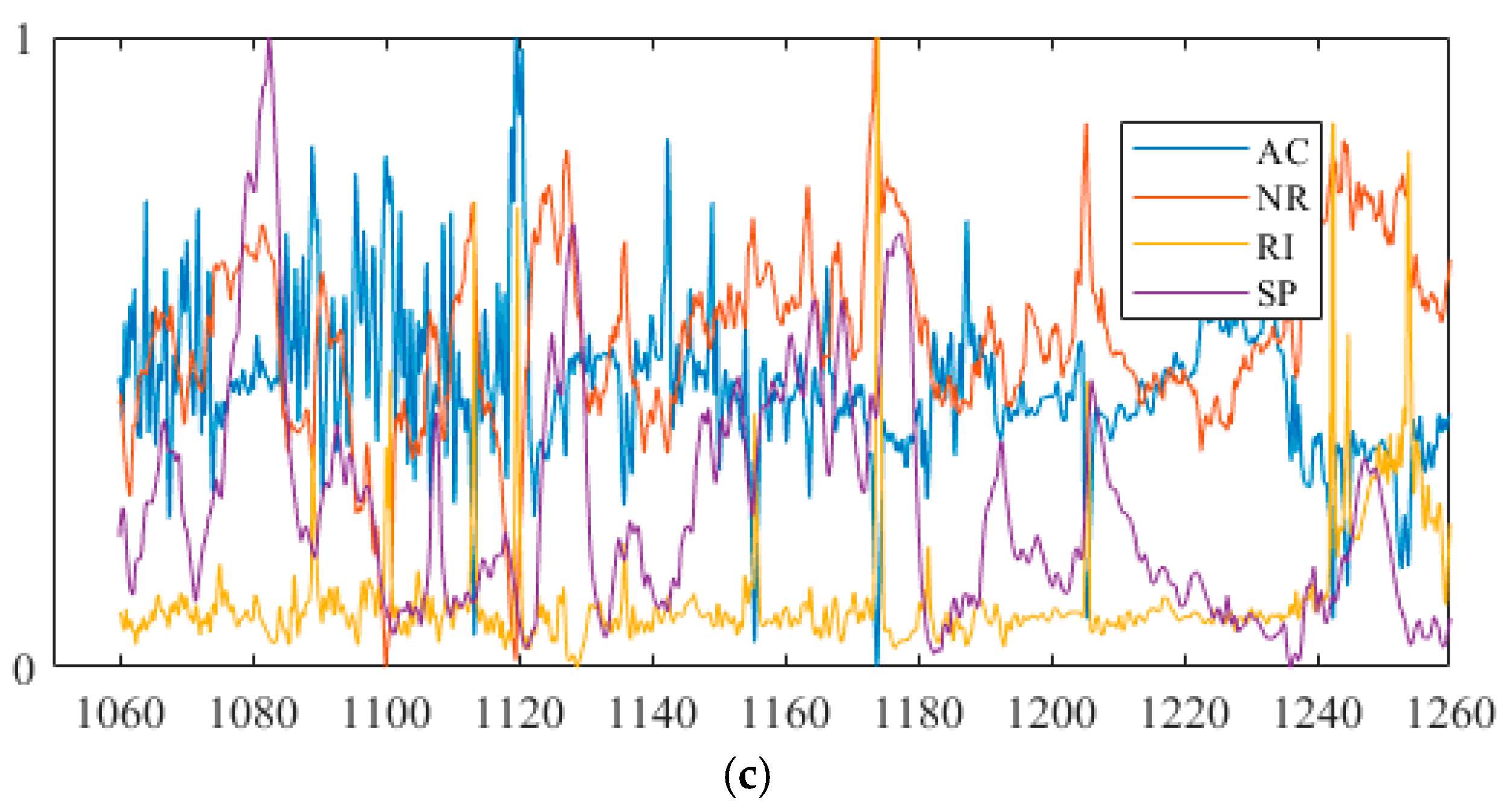
4.2. Data-Sets of Oil Layer Preparation
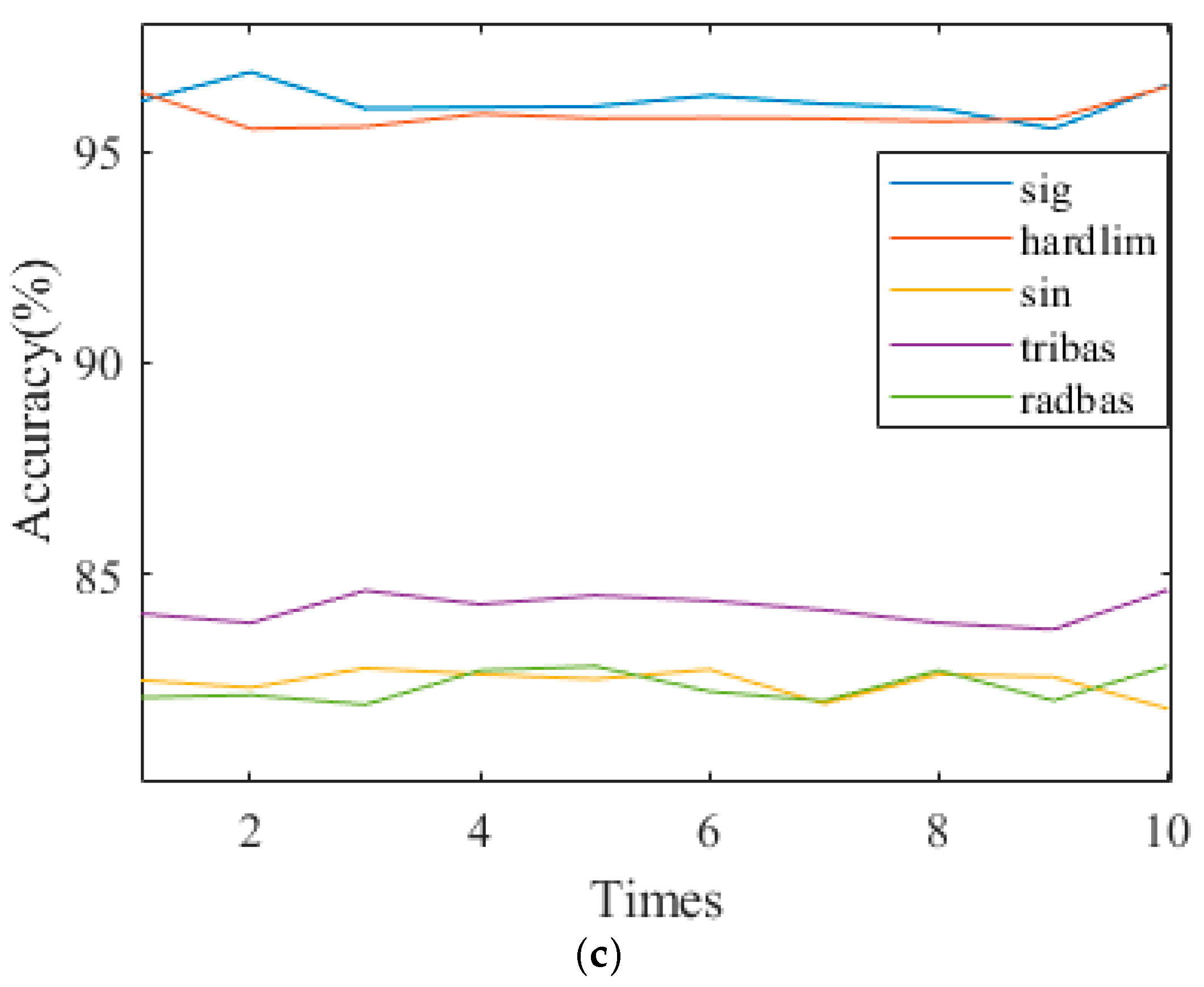
4.3. Selecting the Activation Function of the RVFL
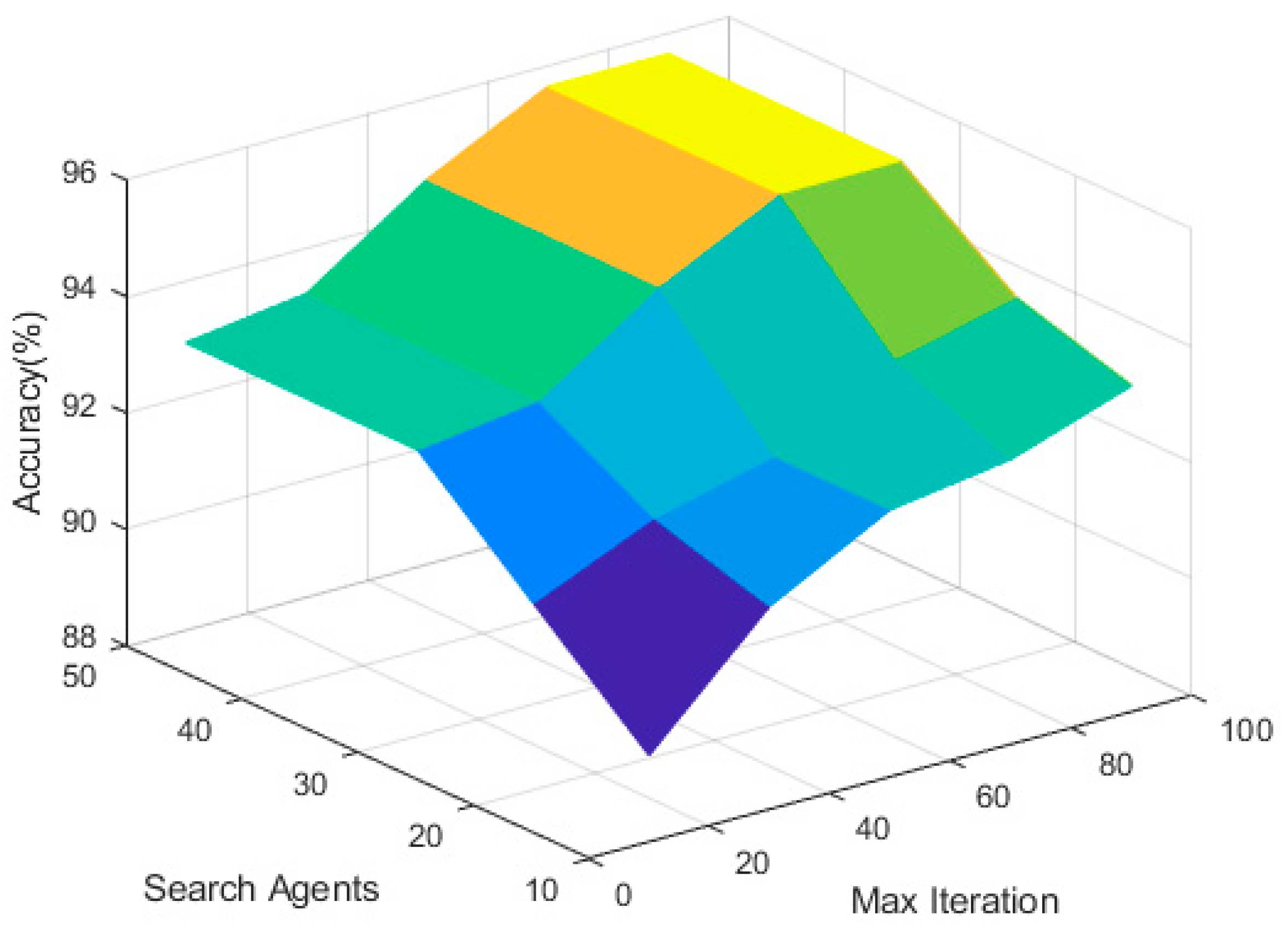
4.4. Research on the Parameters of the IAOS Algorithm
4.5. Set Parameters of the Whole Algorithm
4.6. Evaluation Indicators of the Algorithm
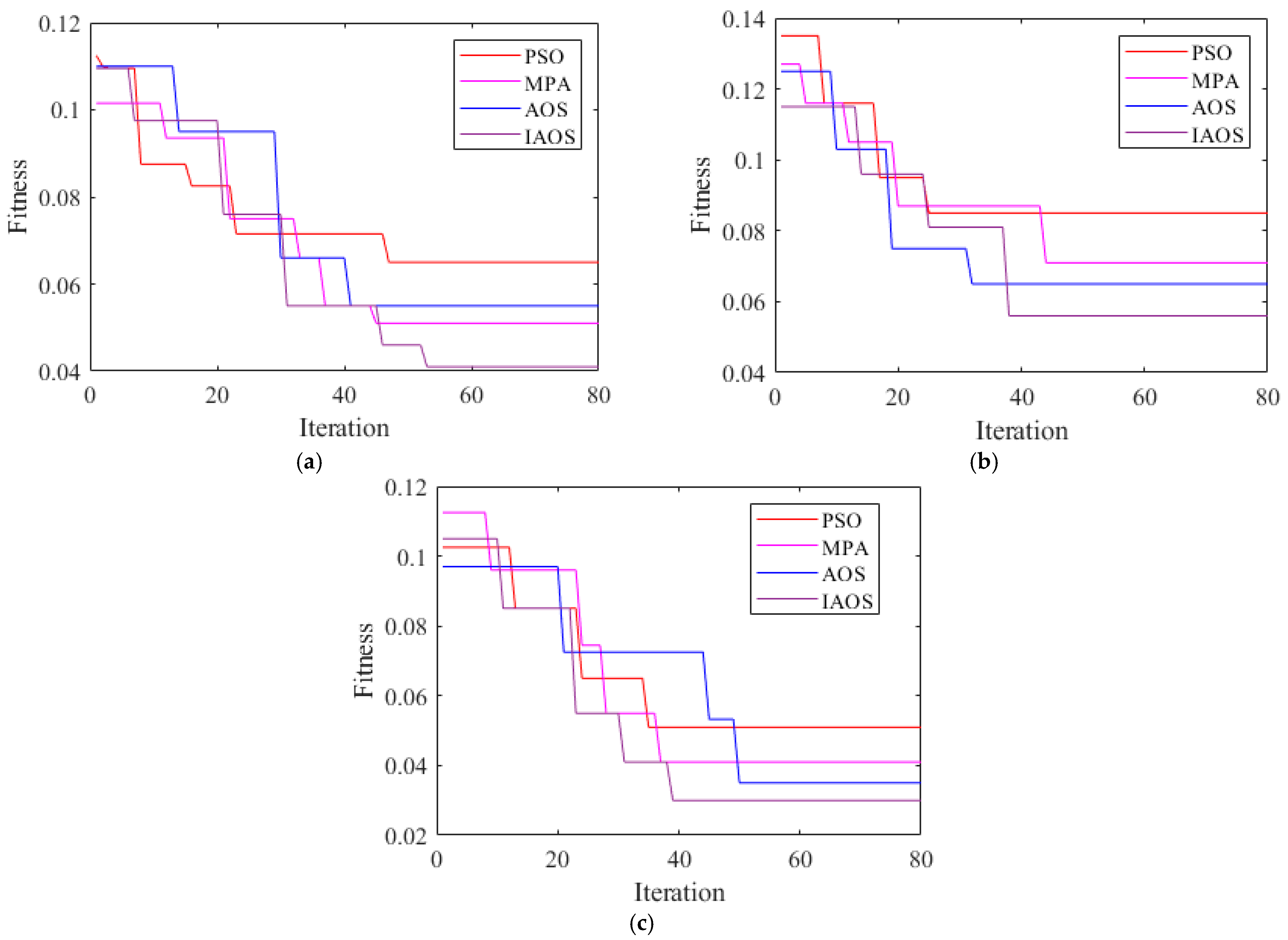
4.7. Discussion of the Algorithm Results
5. Conclusions
- (1)
- This paper presented a hybrid model—ILSTM-BRVFL—and the hyperparametric optimization of the ILSTM-BRVFL model using the IAOS algorithm. The improvement of the hybrid model was successful, as determined by the experimental results.
- (2)
- An improved Atomic Orbit Search algorithm, IAOS, was proposed, and chaos theory was introduced to increase the population’s diversity. The individual memory function was used to increase the optimization-seeking capability of AOS. The results of the experiment show that IAOS can effectively optimize the hyperparameters of the ILSTM-BRVFL model.
- (3)
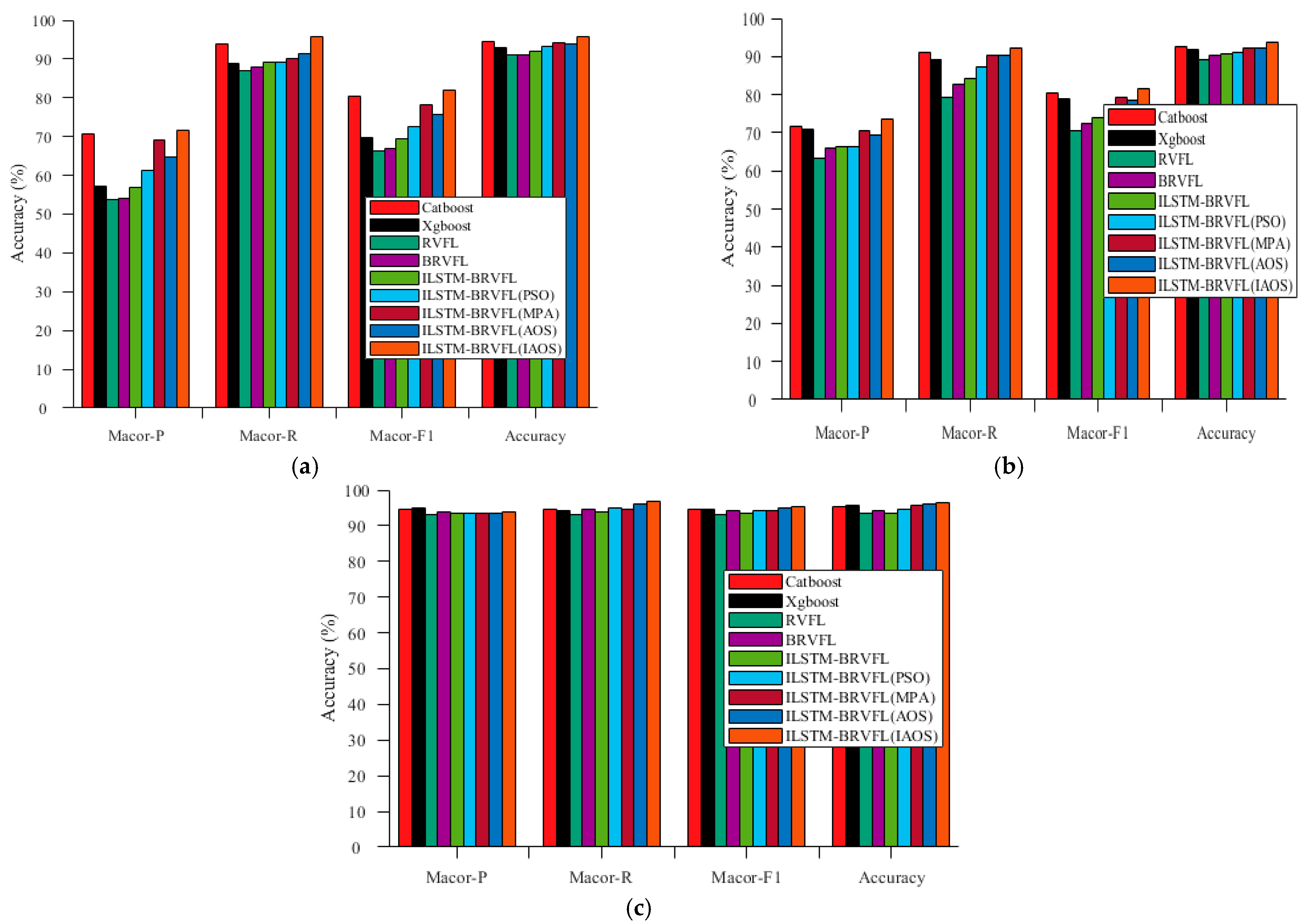
- The optimized LSTM was used to perform feature extraction of the data. The double-ended RVFL was used to perform feature prediction. The effectiveness of ILSTM-BRVFL was verified using three sets of logging data. It achieved prediction accuracies of up to 95.63%, 93.63% and 96.59%. The average prediction accuracy was improved to some extent over the RVFL, BRVFL, LSTM-BRVFL, ILSTM-BRVFL (PSO), ILSTM-BRVFL (MPA) and ILSTM-BRVFL (AOS) algorithms.
- (4)
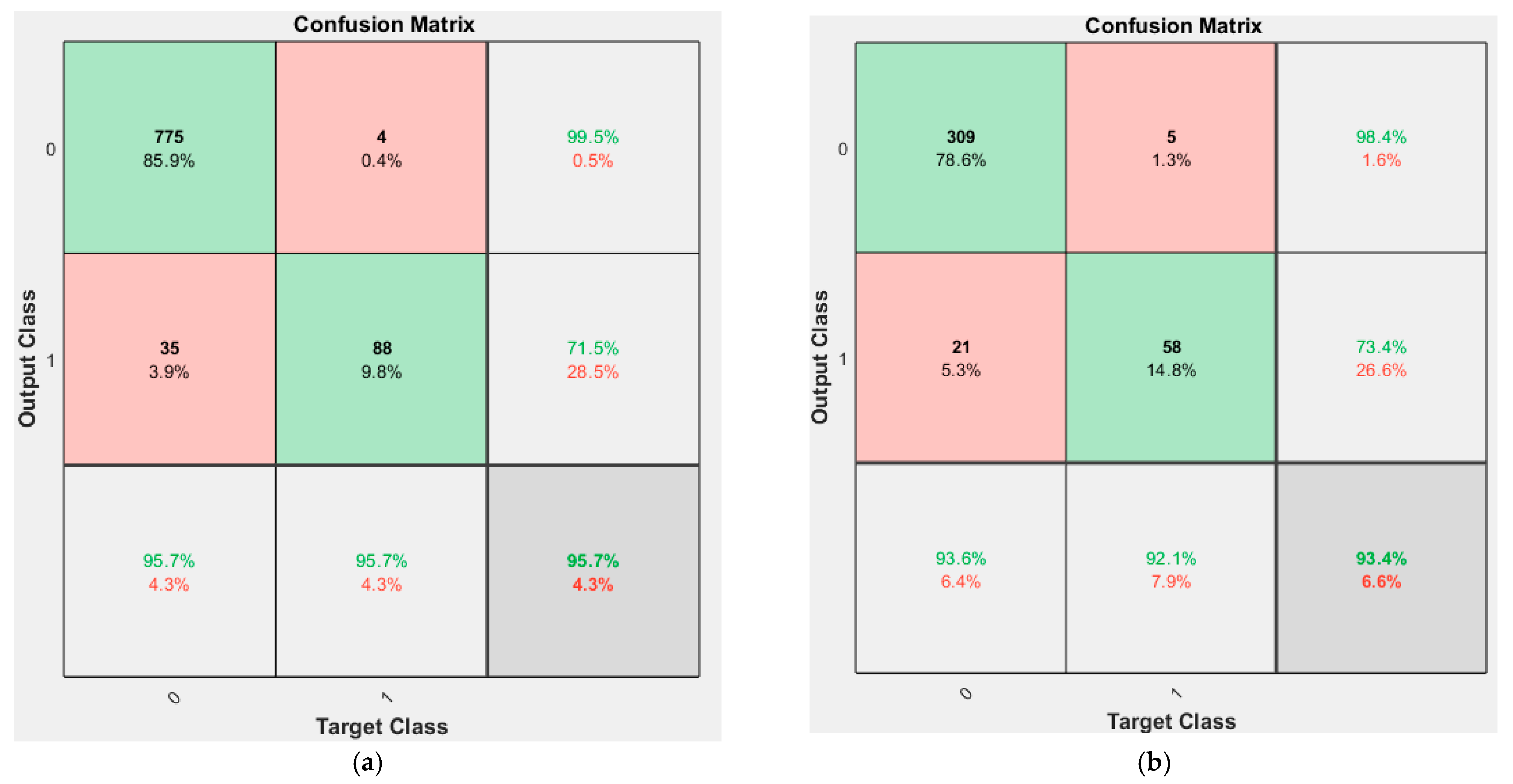
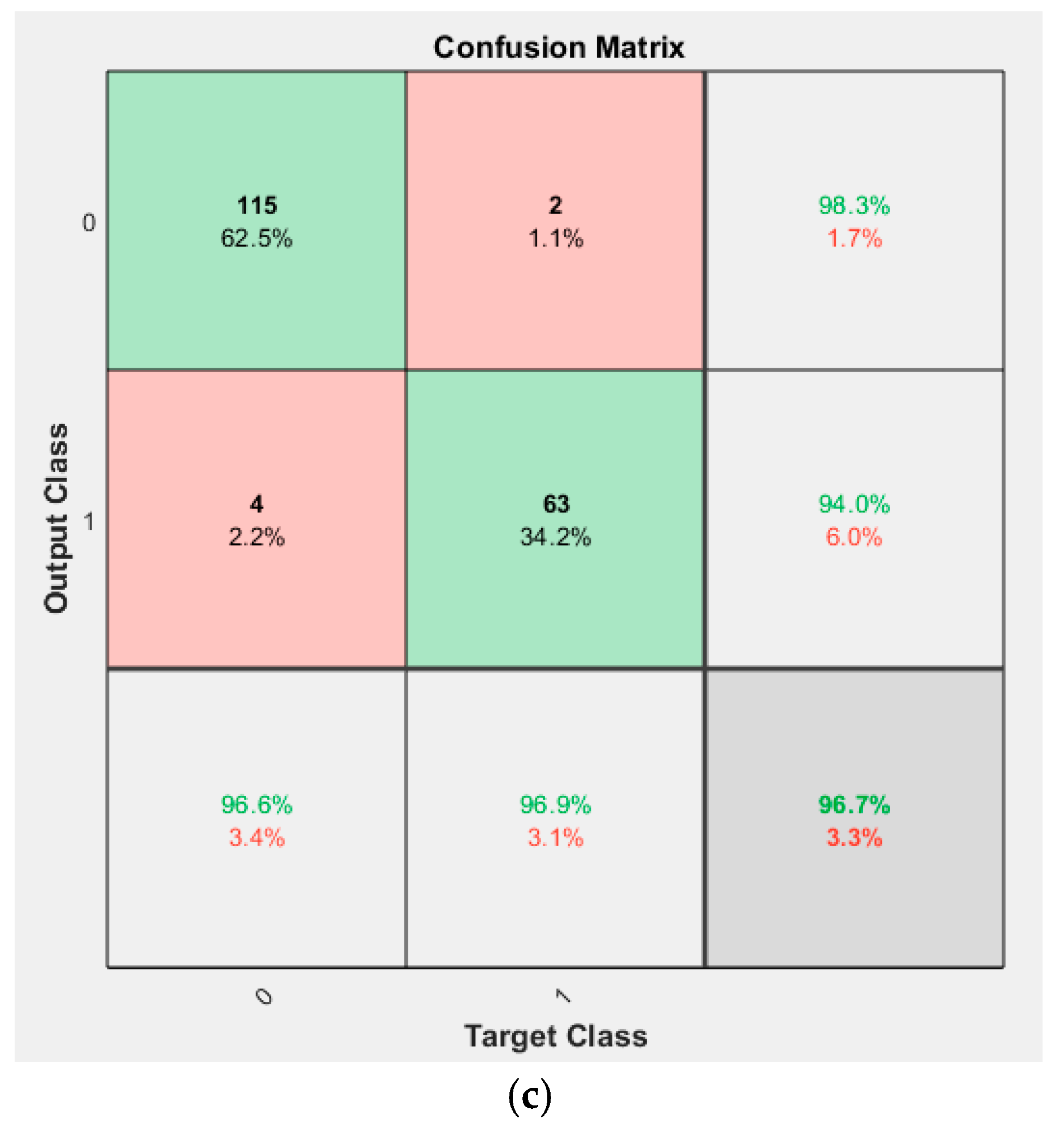
- The confusion matrix and the evaluation metrics (precision (P), recall (R), F1-score, Accuracy) show that the algorithm proposed in this paper has certain advantages over the comparison algorithms in terms of stability, accuracy, and generalization ability.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mu, R.; Zeng, X. A review of deep learning research. KSII Trans. Internet Inf. Syst. TIIS 2019, 13, 1738–1764. [Google Scholar]
- Liu, T.; Xu, H.; Shi, X.; Qiu, X.; Sun, Z. Reservoir Parameters Estimation with Some Log Curves of Qiongdongnan Basin Based on LS-SVM Method. J. Phys. Conf. Ser. 2021, 2092, 012024. [Google Scholar] [CrossRef]
- Bebis, G.; Georgiopoulos, M. Feed-forward neural networks. IEEE Potentials 1994, 13, 27–31. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhang, R.; Zhu, Z. Robust Kalman filtering with long short-term memory for image-based visual servo control. Multimed. Tools Appl. 2019, 78, 26341–26371. [Google Scholar] [CrossRef]
- Han, J.; Lu, C.; Cao, Z.; Mu, H. Integration of deep neural networks and ensemble learning machines for missing well logs estimation. Flow Meas. Instrum. 2020, 73, 101748. [Google Scholar]
- Guo, H.; Zhuang, X.; Chen, P.; Alajlan, N.; Rabczuk, T. Stochastic deep collocation method based on neural architecture search and transfer learning for heterogeneous porous media. Eng. Comput. 2022, 1–26. [Google Scholar] [CrossRef]
- Guo, H.; Zhuang, X.; Chen, P.; Alajlan, N. Analysis of three-dimensional potential problems in non-homogeneous media with physics-informed deep collocation method using material transfer learning and sensitivity analysis. Eng. Comput. 2022, 1–22. [Google Scholar] [CrossRef]
- Eldan, R.; Shamir, O. The power of depth for feedforward neural networks. In Proceedings of the Conference on Learning Theory PMLR, Columbia University, New York, NY, USA, 23–26 June 2016; pp. 907–940. [Google Scholar]
- Medsker, L.R.; Jain, L.C. Recurrent neural networks. Des. Appl. 2001, 5, 64–67. [Google Scholar]
- Taha, O.M.E.; Majeed, Z.H.; Ahmed, S.M. Artificial neural network prediction models for maximum dry density and optimum moisture content of stabilized soils. Transp. Infrastruct. Geotechnol. 2018, 5, 146–168. [Google Scholar] [CrossRef]
- Triveni, G.; Rima, C. Estimation of petrophysical parameters using seismic inversion and neural network modeling in Upper Assam basin, India. Geosci. Front. 2019, 10, 1113–1124. [Google Scholar]
- Gilani, S.; Zare, M.; Raeisi, E. Locating a New Drainage Well by Optimization of a Back Propagation Model. Mine Water Environ. 2019, 38, 342–352. [Google Scholar] [CrossRef]
- Jiang, K.; Wang, S.; Hu, Y. Lithology identification model by well logging based on boosting tree algorithm. Well Logging Technol. 2018, 42, 395–400. [Google Scholar]
- Xueqing, Z.; Zhansong, Z.; Chaomo, Z. Bi-lstm deep neural network reservoir classification model based on the innovative input of logging curve response sequences. IEEE Access 2021, 9, 19902–19915. [Google Scholar] [CrossRef]
- Wu, X.; Liang, L.; Shi, Y.; Geng, Z.; Fomel, S. Deep learning for local seismic image processing: Fault detection, structure-oriented smoothing with edge preserving, and slope estimation by using a single convolutional neural network. In Proceedings of the San Antonio, 2019 SEG Annual Meeting, San Antonio, TX, USA, 15 September 2019. [Google Scholar]
- Zhang, D.; Chen, Y.; Meng, J. Synthetic well logs generation via Recurrent Neural Networks. Pet. Explor. Dev. 2018, 45, 598–607. [Google Scholar] [CrossRef]
- Wang, H.; Mu, L.; Shi, F.; Dou, H. Production prediction at ultra-high water cut stage via Recurrent Neural Network. Pet. Explor. Dev. 2020, 47, 1009–1015. [Google Scholar] [CrossRef]
- Zeng, L.; Ren, W.; Shan, L. Attention-Based Bidirectional Gated Recurrent Unit Neural Networks for Well Logs Prediction and Lithology Identification. Neurocomputing 2020, 414, 153–171. [Google Scholar] [CrossRef]
- Huang, G.; Zhu, Q.; Siew, C. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Duan, M.; Li, K.; Yang, C.; Li, K. A hybrid deep learning CNN–ELM for age and gender classification. Neurocomputing 2018, 275, 448–461. [Google Scholar] [CrossRef]
- Kumar, K.B.S.; Bhalaji, N. A Novel Hybrid RNN-ELM Architecture for Crime Classification. In Proceedings of the International Conference on Computer Networks and Inventive Communication Technologies; Springer: Cham, Switzerland, 2019; pp. 876–882. [Google Scholar]
- Storn, R.; Price, K. Differential Evolution—A Simple and Efficient Heuristic for global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Peng, Y.; Li, Q.; Kong, W.; Qin, F.; Zhang, J.; Cichocki, A. A joint optimization framework to semi-supervised RVFL and ELM networks for efficient data classification. Appl. Soft Comput. 2020, 97, 106756. [Google Scholar] [CrossRef]
- Malik, A.K.; Ganaie, M.A.; Tanveer, M.; Suganthan, P.N. A novel ensemble method of rvfl for classification problem. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Zhou, P.; Jiang, Y.; Wen, C.; Dai, X. Improved incremental RVFL with compact structure and its application in quality prediction of blast furnace. IEEE Trans. Ind. Inform. 2021, 17, 8324–8334. [Google Scholar] [CrossRef]
- Guo, X.; Zhou, W.; Lu, Q.; Du, A.; Cai, Y.; Ding, Y. Assessing Dry Weight of Hemodialysis Patients via Sparse Laplacian Regularized RVFL Neural Network with L2, 1-Norm. BioMed Res. Int. 2021, 2021, 6627650. [Google Scholar] [CrossRef]
- Yu, L.; Wu, Y.; Tang, L.; Yin, H.; Lai, K.K. Investigation of diversity strategies in RVFL network ensemble learning for crude oil price forecasting. Soft Comput. 2021, 25, 3609–3622. [Google Scholar] [CrossRef]
- Aggarwal, A.; Tripathi, M. Short-term solar power forecasting using Random Vector Functional Link (RVFL) network. In Ambient Communications and Computer Systems; Springer: Singapore, 2018; pp. 29–39. [Google Scholar]
- Chen, J.; Zhang, D.; Yang, S.; Nanehkaran, Y.A. Intelligent monitoring method of water quality based on image processing and RVFL-GMDH model. IET Image Process. 2021, 14, 4646–4656. [Google Scholar] [CrossRef]
- AbuShanab, W.S.; Elaziz, M.A.; Ghandourah, E.I.; Moustafa, E.B.; Elsheikh, A.H. A new fine-tuned random vector functional link model using Hunger games search optimizer for modeling friction stir welding process of polymeric materials. J. Mater. Res. Technol. 2021, 14, 1482–1493. [Google Scholar] [CrossRef]
- Mirjalili, S. Genetic algorithm. In Evolutionary Algorithms and Neural Networks; Springer: Cham, Switzerland, 2019; pp. 43–55. [Google Scholar]
- Opara, K.R.; Arabas, J. Differential Evolution: A survey of theoretical analyses. Swarm Evol. Comput. 2019, 44, 546–558. [Google Scholar] [CrossRef]
- Bullnheimer, B.; Hartl, R.F.; Strauss, C. An improved ant System algorithm for thevehicle Routing Problem. Ann. Oper. Res. 1999, 89, 319–328. [Google Scholar] [CrossRef]
- Huang, C.L.; Dun, J.F. A distributed PSO–SVM hybrid system with feature selection and parameter optimization. Appl. Soft Comput. 2008, 8, 1381–1391. [Google Scholar] [CrossRef]
- Tariq, Z.; Mahmoud, M.; Abdulraheem, A. An artificial intelligence approach to predict the water saturation in carbonate res-ervoir rocks. In Proceedings of the SPE Annual Technical Conference and Exhibition, Bakersfield, CA, USA, 2 October 2019. [Google Scholar]
- Costa, L.; Maschio, C.; Schiozer, D. Application of artificial neural networks in a history matching process. J. Pet. Sci. Eng. 2014, 123, 30–45. [Google Scholar] [CrossRef]
- Azizi, M. Atomic orbital search: A novel metaheuristic algorithm. Appl. Math. Model. 2021, 93, 657–683. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, Z.; Zheng, J. CatBoost: A new approach for estimating daily reference crop evapotranspiration in arid and semi-arid regions of Northern China. J. Hydrol. 2020, 588, 125087. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Yang, Y.; Wang, Y.; Yuan, X. Bidirectional extreme learning machine for regression problem and its learning effectiveness. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1498–1505. [Google Scholar] [CrossRef] [PubMed]
- Cao, W.; Ming, Z.; Wang, X.; Cai, S. Improved bidirectional extreme learning machine based on enhanced random search. Memetic Comput. 2019, 11, 19–26. [Google Scholar] [CrossRef]
- Svozil, D.; Kvasnicka, V.; Pospichal, J. Introduction to multi-layer feed-forward neural networks. Chemom. Intell. Lab. Syst. 1997, 39, 43–62. [Google Scholar] [CrossRef]
- Levy, D. Chaos theory and strategy: Theory, application, and managerial implications. Strateg. Manag. J. 1994, 15, 167–178. [Google Scholar] [CrossRef]
- Bai, J.; Xia, K.; Lin, Y.; Wu, P. Attribute Reduction Based on Consistent Covering Rough Set and Its Application. Complexity 2017, 2017, 8986917. [Google Scholar] [CrossRef]
- Aghdam, M.Y.; Tabbakh, S.R.K.; Chabok, S.J.M.; Kheirabadi, M. Optimization of air traffic management efficiency based on deep learning enriched by the long short-term memory (LSTM) and extreme learning machine (ELM). J. Big Data 2021, 8, 54. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Well | Attribute |
|---|---|
| Original Attribute (w1) | GR, DT, SP, WQ, LLD, LLS, DEN, NPHI, PE, U, TH, K, CALL |
| Reduction results (w1) | GR, DT, SP, LLD, LLS, DEN, K |
| Original Attribute (w2) | AC, CNL, DEN, GR, RT, RI, RXO, SP, R2M, R025, BZSP, RA2, C1, C2, CALI, RINC, PORT, VCL, VMA1, VMA6, RHOG, SW, VO, WO, PORE, VXO, VW, so, rnsy, rsly, rny, AC1 |
| Reduction results (w2) | AC, GR, RT, RXO, SP |
| Original Attribute (w3) | AC, CALL, GR, NG, RA2, RA4, RI, RM, RT, RXO, SP |
| Reduction results (w3) | AC, NG, RI, SP |
| Well | Training Set | Test Set | ||||
|---|---|---|---|---|---|---|
| Depth (m) | Oil Layers | Dry Layers | Depth (m) | Oil Layers | Dry Layers | |
| w1 | 3150~3340 | 112 | 1238 | 3340~3470 | 92 | 810 |
| w2 | 1190~1230 | 65 | 430 | 1230~1300 | 63 | 330 |
| w3 | 1160~1260 | 55 | 800 | 1260~1300 | 79 | 105 |
| Algorithm | Parameters |
|---|---|
| PSO | Population Size = 30, Maximum Iteration = 80, ω0 = 0.7, c1 = c2 = 1.5, dim = 5 |
| MPA | Population Size = 30, Maximum Iteration = 80, FADs Effect coefficient = 0.2, p = 0.5 dim = 5 |
| AOS | Population Size = 30, Maximum Iteration = 80, dim = 5 |
| IAOS | Population Size = 30, Maximum Iteration = 80, dim = 5 |
| LSTM | Maximum number of training rounds: Maxpochs = 50, hidden_size = 256 Learning rate:initialLearnRate = 0.001, Optimization method: adam Size of mini-bath:MiniBathSize = 64 |
| RVFL | Number of hidden layer nodes: Number of Hidden Neurons = 105 Number of input layer nodes: Number of input Neurons = Number of training set samples, Activation function: sigmoid |
| ILSTM-BRVFL | hyper-parameters range of ILSTM-BRVFL model = [lr,epoch,batch_size,hidden0,hidden1] = [0.0001–0.01,0–128,0–256,0–256,0–256] loss of ILSTM-BRVFL model = categorical_crossentropy, optimizer of ILSTM-BRVFL model = adam, Dropout = 0.5 |
| well | Learing Rate | Epoch | Batch_size | Hidden0 | Hidden1 |
|---|---|---|---|---|---|
| w1 | 0.0091 | 56 | 212 | 125 | 178 |
| w2 | 0.0012 | 45 | 185 | 138 | 154 |
| w3 | 0.0095 | 63 | 176 | 98 | 167 |
| Macro-P% | Macro-R% | Marco-F1% | Accuracy% | |
|---|---|---|---|---|
| Catboost | 70.68 | 93.82 | 80.40 | 94.45 |
| Xgboost | 57.25 | 88.88 | 69.64 | 93.01 |
| RVFL | 53.69 | 86.95 | 66.38 | 91.05 |
| BRVFL | 54.00 | 88.04 | 66.94 | 91.17 |
| LSTM-BRVFL | 56.94 | 89.13 | 69.49 | 92.02 |
| ILSTM-BRVFL (PSO) | 61.20 | 89.13 | 72.57 | 93.12 |
| ILSTM-BRVFL (MPA) | 69.17 | 90.21 | 78.30 | 94.28 |
| ILSTM-BRVFL (AOS) | 64.61 | 91.30 | 75.67 | 93.98 |
| ILSTM-BRVFL (IAOS) | 71.52 | 95.71 | 81.86 | 95.63 |
| Macro-P% | Macro-R% | Marco-F1% | Accuracy% | |
|---|---|---|---|---|
| Catboost | 71.63 | 91.24 | 80.25 | 92.62 |
| Xgboost | 70.89 | 89.35 | 79.05 | 91.85 |
| RVFL | 63.29 | 79.37 | 70.42 | 89.31 |
| BRVFL | 65.82 | 82.54 | 72.38 | 90.36 |
| LSTM-BRVFL | 66.25 | 84.12 | 74.12 | 90.51 |
| ILSTM-BRVFL (PSO) | 66.26 | 87.30 | 75.34 | 90.94 |
| ILSTM-BRVFL (MPA) | 70.37 | 90.47 | 79.16 | 92.36 |
| ILSTM-BRVFL (AOS) | 69.51 | 90.47 | 78.62 | 92.02 |
| ILSTM-BRVFL (IAOS) | 73.41 | 92.13 | 81.73 | 93.63 |
| Macro-P% | Macro-R% | Marco-F1% | Accuracy% | |
|---|---|---|---|---|
| Catboost | 94.51 | 94.65 | 94.57 | 95.33 |
| Xgboost | 94.93 | 94.28 | 94.60 | 95.85 |
| RVFL | 93.04 | 93.14 | 93.04 | 93.33 |
| BRVFL | 93.69 | 94.54 | 94.11 | 94.24 |
| LSTM-BRVFL | 93.48 | 93.71 | 93.59 | 93.63 |
| ILSTM-BRVFL (PSO) | 93.39 | 95.04 | 94.18 | 94.52 |
| ILSTM-BRVFL (MPA) | 93.31 | 94.71 | 94.16 | 95.54 |
| ILSTM-BRVFL (AOS) | 93.49 | 96.16 | 94.80 | 96.09 |
| ILSTM-BRVFL (IAOS) | 93.79 | 96.97 | 95.35 | 96.59 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, G.; Pan, Y.; Lan, P. Reservoir Prediction Model via the Fusion of Optimized Long Short-Term Memory Network (LSTM) and Bidirectional Random Vector Functional Link (RVFL). Electronics 2022, 11, 3343. https://doi.org/10.3390/electronics11203343
Li G, Pan Y, Lan P. Reservoir Prediction Model via the Fusion of Optimized Long Short-Term Memory Network (LSTM) and Bidirectional Random Vector Functional Link (RVFL). Electronics. 2022; 11(20):3343. https://doi.org/10.3390/electronics11203343
Chicago/Turabian StyleLi, Guodong, Yongke Pan, and Pu Lan. 2022. "Reservoir Prediction Model via the Fusion of Optimized Long Short-Term Memory Network (LSTM) and Bidirectional Random Vector Functional Link (RVFL)" Electronics 11, no. 20: 3343. https://doi.org/10.3390/electronics11203343
APA StyleLi, G., Pan, Y., & Lan, P. (2022). Reservoir Prediction Model via the Fusion of Optimized Long Short-Term Memory Network (LSTM) and Bidirectional Random Vector Functional Link (RVFL). Electronics, 11(20), 3343. https://doi.org/10.3390/electronics11203343