4.1. Dataset and Evaluation Metrics
We conducted experiments on two publicly available autonomous driving datasets, KITTI [
22] and BDD100K [
23], which contain a large number of objects with large-scale changes. Specifically, the KITTI dataset was collected from different scenes in Karlsruhe during the daytime. We choose the 2D object detection data contained in KITTI, which consists of 7481 labeled images and then randomly reserved one-tenth of the original labeled dataset for testing. The chosen classes in KITTI include car, van, truck, pedestrian, person (sitting), cyclist, tram, and misc. BDD100K is a large-scale dataset that was released by the AI Lab of the University of Berkeley and collected from a complex road scene and contains sample images of various scenes under different venues, different weather conditions, and different lighting conditions. After processing, the dataset contains 70,000 images for training and 10,000 images for testing. The classes in BDD100K include car, bus, person, bike, truck, motor, train, rider, traffic sign, and traffic light.
For evaluation, we use the average precision (AP) and average recall (AR) metrics defined on the MS-COCO benchmark [
36]. To verify the detection performance with objects at different scales, we use COCO-style
,
,
,
,
, and
on objects of small (less than
), medium (from
to
), and large (greater than
) sizes as the additional evaluation metrics. Given the total number of classes
C, the class index
c, the total number of objects of class
c expected to be detected
, the number of objects of class
c truly detected
, and the number of false alarms
, AP and AR are, respectively defined as:
4.4. Ablation Study
In this section, we omit different key components of our model to investigate their roles in the effectiveness of the proposed technique with the KITTI and BDD100K datasets.
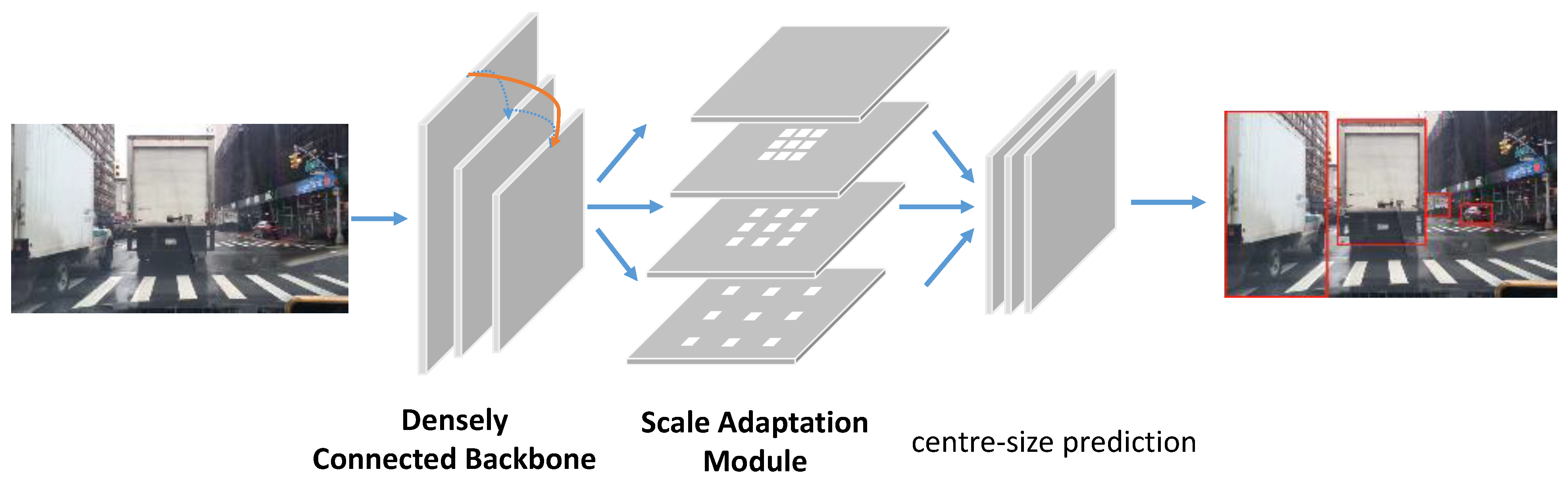
Densely Connected High-Resolution Networks. Densely connected high-resolution networks are proposed to obtain and use high-resolution convolutional features of the former stage more effectively. These networks further connect the initial high-resolution convolutional feature maps to the later low-resolution convolutional feature maps. From
Table 3, we see that all the metrics were improved greatly when using these enhanced networks alone. Particularly,
was increased from
to
and
was increased from
to
. These results indicate that densely connected high-resolution networks contribute to detecting small-scale objects.
Scale Adaptation Module. In this module, we use dilated convolution to enlarge the receptive field size of the feature maps. In addition, we use different dilated convolution expansion rates to change the receptive field size. To maintain efficiency, the module is organized in a parallel structure. We first verified the effectiveness of the proposed scale-aware module. As illustrated in
Table 3,
was increased from
to
,
was increased from
to
,
was increased from
to
, and
was increased from
to
. However,
and
were decreased to some extent.
We argue that on coarse feature maps, the enlarged receptive field size may cover more noisy features for small objects; as a result, it hinders the detection of small objects. Nevertheless, when combining the scale-aware module with densely connected high-resolution networks, the performance in detecting small objects was also improved. Specifically, was increased from to , was increased from to , and was increased from to . The result again verifies the effectiveness of the densely connected module for detecting small targets.
Number of Branches. We conducted experiments to determine the appropriate number of branches to produce an efficient model on the KITTI and BDD100K datasets, and the results are shown in
Table 4 and
Table 5. The scale-aware module contains different branches to adapt to the scale changes in the objects. The results in
Table 4 show that increasing the number of branches from 1 to 3 yielded extensive improvements in the detection of middle and large objects, which is due to the increase in the receptive field size of the feature maps. However, when the number of branches was further increased, the detection performance was not further improved. In particular,
decreased when the number of branches was further increased. The enlarged receptive field size may hinder the detection of small objects. Similarly, as shown in
Table 5, increasing the number of branches from 1 to 3 yielded extensive improvements in the detection of middle and large objects. As a result, in this paper, we set the number of branches to 3 with one directly connected branch in parallel.
Dilation Rate. For the scale-aware module, we conducted further experiments to determine the appropriate dilation rate. We set two different dilation rate patterns: in one, the dilation size in each branch is identical and expands equally among the branches; in the other, a different dilation size is set for each branch, which then expands independently. The experiments were conducted on the KITTI and BDD100K datasets to further verify the stability of the results. As illustrated in
Table 6, a larger dilation rate is associated with higher
and
values, which indicates that larger dilation rates are more beneficial for large-scale object detection. However, a dilation rate that is too large will reduce the detection performance for large-scale objects. For example, when the dilation rate was set to 3, 6, and 9, the
and
values are lower than when the dilation rate was set to 2, 4, and 6. In addition, enlarging the dilation rate of each branch with different sizes can achieve better detection performance than expanding the dilation rate of each branch with the same size, especially for small object detection, as seen in the changes in the
and
values in
Table 6. We argue that setting different dilation rates for different branches leads to better adaptation to different object scale variations.
From
Table 7, the dilation rate is smaller, and
and
are higher. However, using a variable dilation rate can obtain higher detection accuracy values at different scales than using a fixed dilation rate by comparing the first three rows of results with the last three rows of results in the table. The result is consistent with
Table 6. Therefore, our method is stable on different datasets.
Different Backbones. We further conducted experiments to verify the effectiveness of the scale-aware module proposed in this paper on the features extracted by different backbone networks. As illustrated in
Table 8, our method can improve the
,
,
,
, and
values when adopting the Hourglass features. In addition, our method can improve the
,
,
, and
values when adopting the original HRNet features. These results show that our method is effective for different types of input features. It is worth noting that the result again shows that using only the dilated convolution module degrades the detection performance of small objects. Higher
and
values can be obtained with the HRNet feature than with the Hourglass feature. When our densely connected high-resolution networks are adopted, the
and
values are further improved. These results suggest that high-resolution features contribute to small-scale object detection.
Inference Speed. In this work, to maintain as much of the computational efficiency of the model as possible, we adopted the following strategies. First, we chose HRNet as the basis for our network because it connects high-to-low resolution convolution streams in parallel. Second, we only added the skip connection between level 2 and level 4 feature maps, as shown in
Figure 3, rather than connecting all low-level features to high-level features, such as DenseNet. Third, in our scale adaptation module, different branches are connected in parallel, which is different from the serial connection of YOLOF. We compared and verified the inference speed of the method; in particular, we compared the inference speed with different backbone features. As can be seen in
Table 9, when adopting the same Hourglass backbone, the inference time of our method was only 8 ms longer than that of the baseline model, CenterNet. In addition, when adopting the HRNet-w48 backbone with high-resolution features, the inference time of our method was only 18 ms longer than that of CenterNet. Notably, our method was 2 ms faster than the state-of-the-art ATSS when using a slim Hourglass. These results show that our method does not significantly improve the inference time.
Model Stability. To test the stability of our model, we conducted multiple sets of experiments with different random seeds. We plotted the error–epoch curves on the test dataset of KITTI, as shown in
Figure 5. The mean and standard deviation are approximately 0.45 and 0.01, respectively, when converged.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}