


Selection of Relevant Geometric Features Using Filter-Based Algorithms for Point Cloud Semantic Segmentation



Abstract
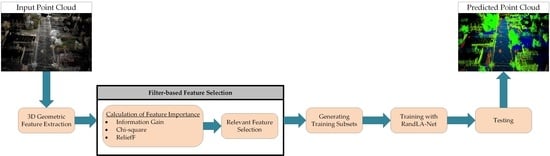
1. Introduction
2. Related Works
2.1. Point Cloud Semantic Segmentation with Point-Based Methods
2.2. Point Cloud Semantic Segmentation with Voxel-Based Methods
2.3. Point Cloud Semantic Segmentation with Projection-Based Methods
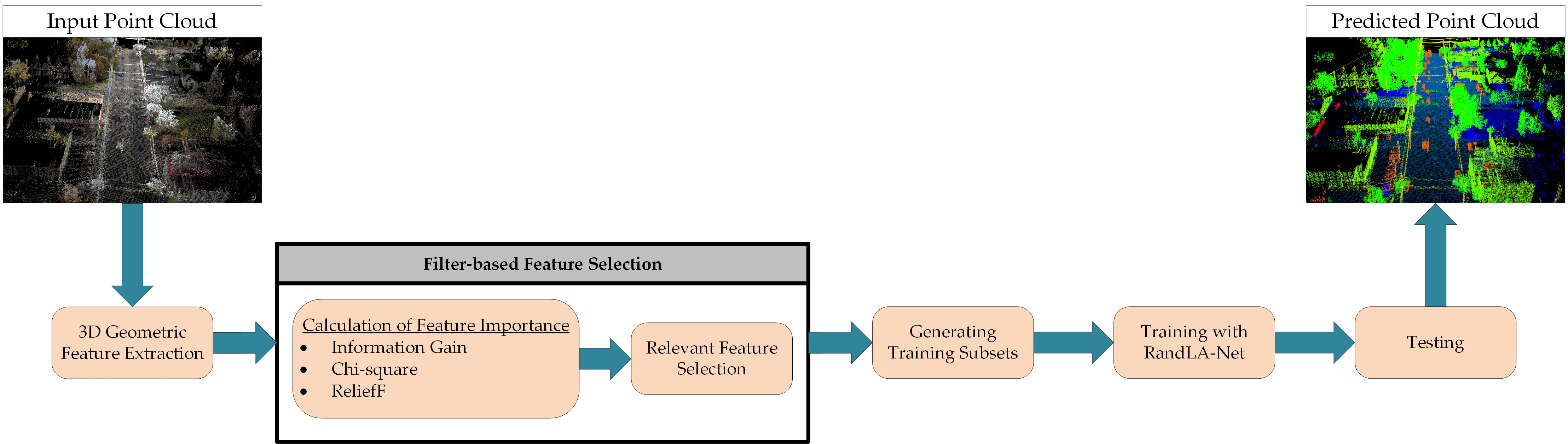
3. Materials and Methods
3.1. Datasets
3.1.1. Toronto-3D
3.1.2. SZTAKI-CityMLS
3.1.3. Paris-CARLA-3D
3.2. Filter-Based Feature Selection
3.2.1. Information Gain
3.2.2. Chi2 Algorithm
3.2.3. ReliefF
3.3. 3D Geometric Features
3.4. RandLA-Net
3.5. Superpoint Graph (SPG)
3.6. Experimental Details
4. Results
4.1. Feature Selection and Creating Subsets
- : only 3D coordinates (x, y, z).
- : 3D coordinates and RGB.
- : 3D coordinates and all geometric features.
- : 3D coordinates and 4 selected features with IG.
- : 3D coordinates and 3 selected features with Chi2.
- : 3D coordinates and 4 selected features with ReliefF.
- : 3D coordinates, RGB and all geometric features.
- : 3D coordinates, RGB, and 4 selected features with IG.
- : 3D coordinates, RGB, and 3 selected features with Chi2.
- : 3D coordinates, RGB, and 4 selected features with ReliefF.
- : only 3D coordinates (x, y, z).
- : 3D coordinates and all geometric features.
- : 3D coordinates and 7 selected features with IG.
- : 3D coordinates and 3 selected features with Chi2.
- : 3D coordinates and 5 selected features with ReliefF.
- : only 3D coordinates (x, y, z).
- : 3D coordinates and RGB.
- : 3D coordinates and all geometric features.
- : 3D coordinates and 5 selected features with IG.
- : 3D coordinates and 3 selected features with Chi2.
- : 3D coordinates and 5 selected features with ReliefF.
- : 3D coordinates, RGB and all geometric features.
- : 3D coordinates, RGB, and 5 selected features with IG.
- : 3D coordinates, RGB, and 3 selected features with Chi2.
- : 3D coordinates, RGB, and 5 selected features with ReliefF.
4.2. Results of Semantic Segmentation on Toronto3D
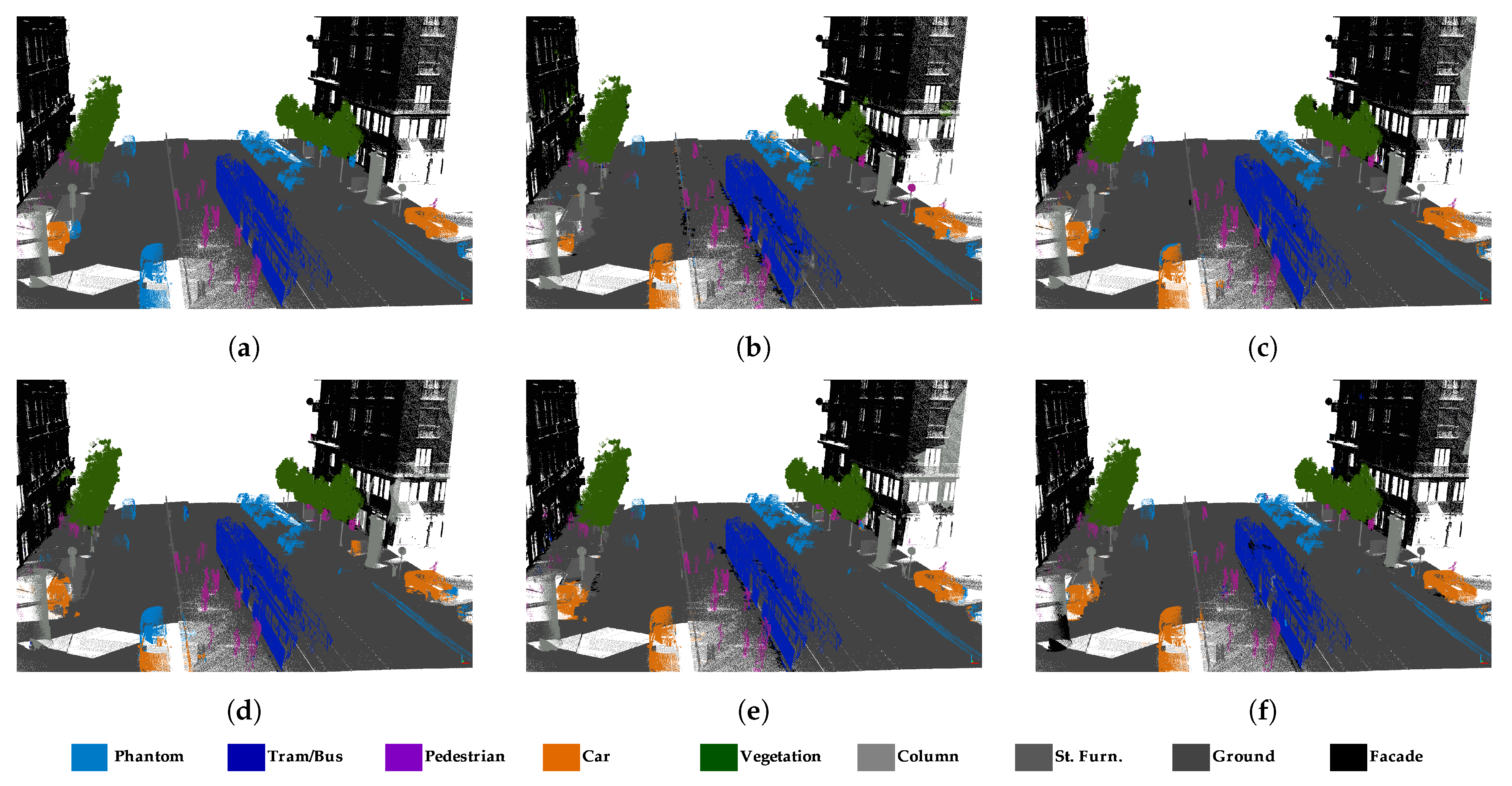
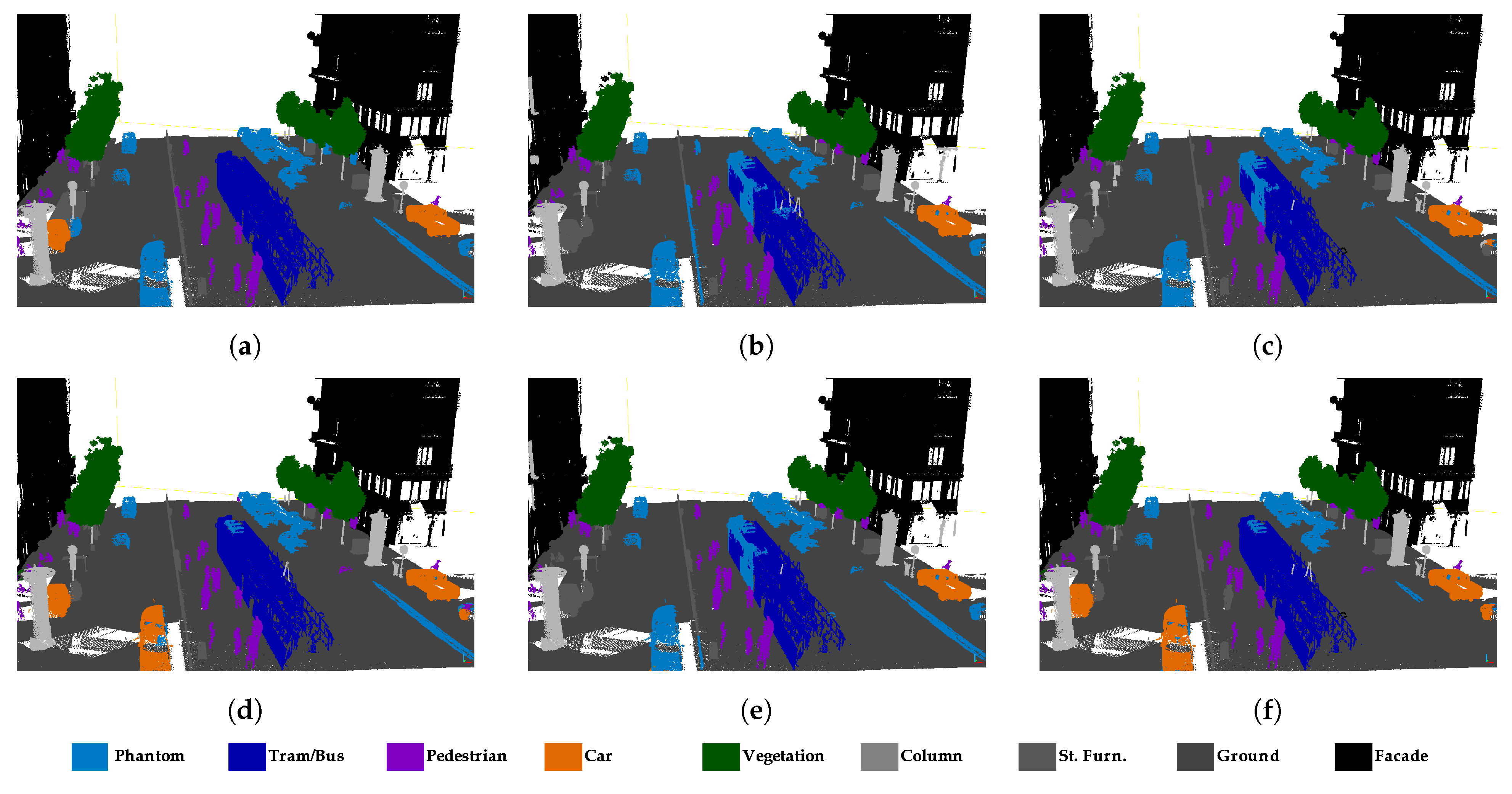
4.3. Results of Semantic Segmentation on SZTAKI-CityMLS
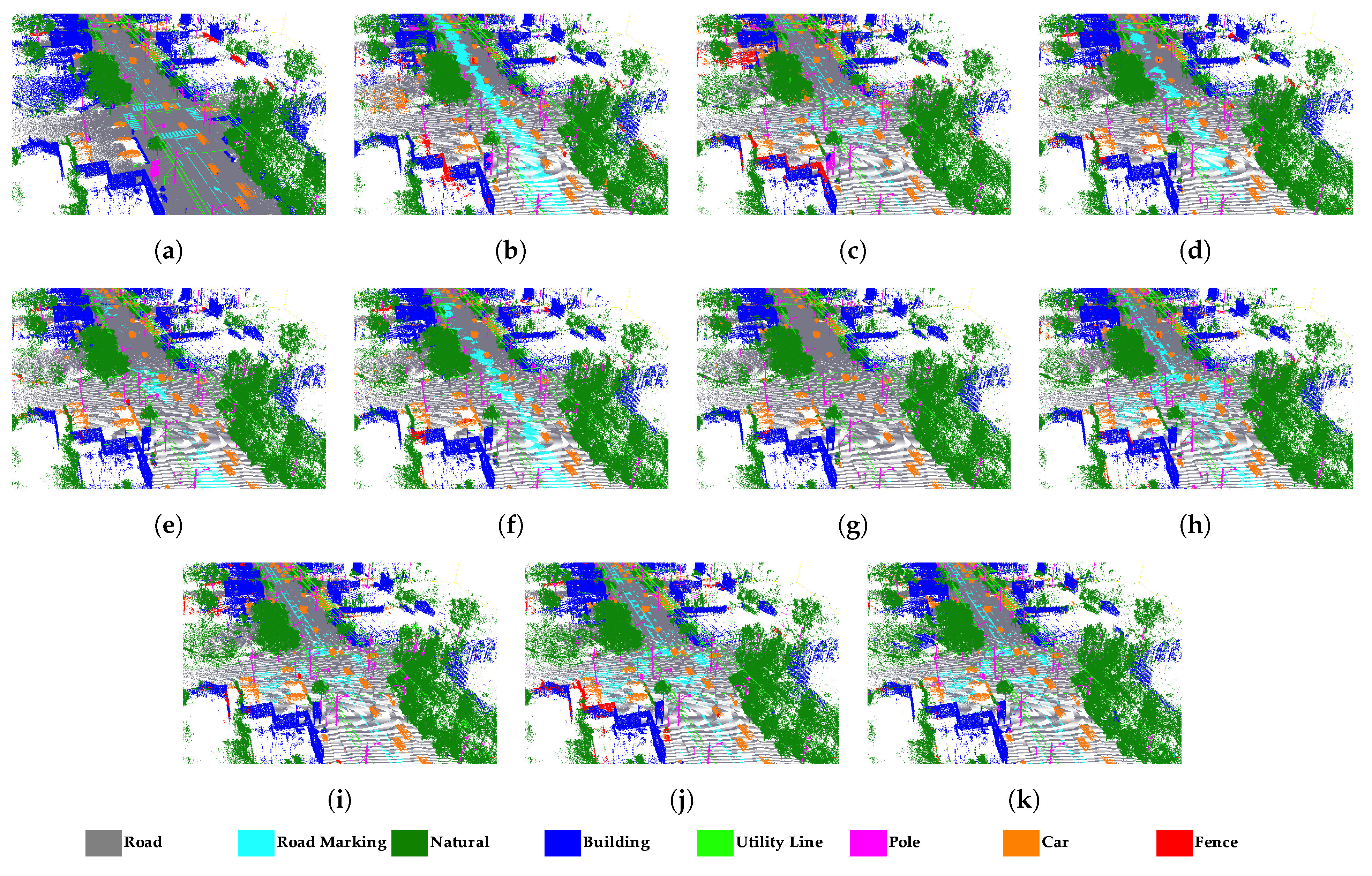
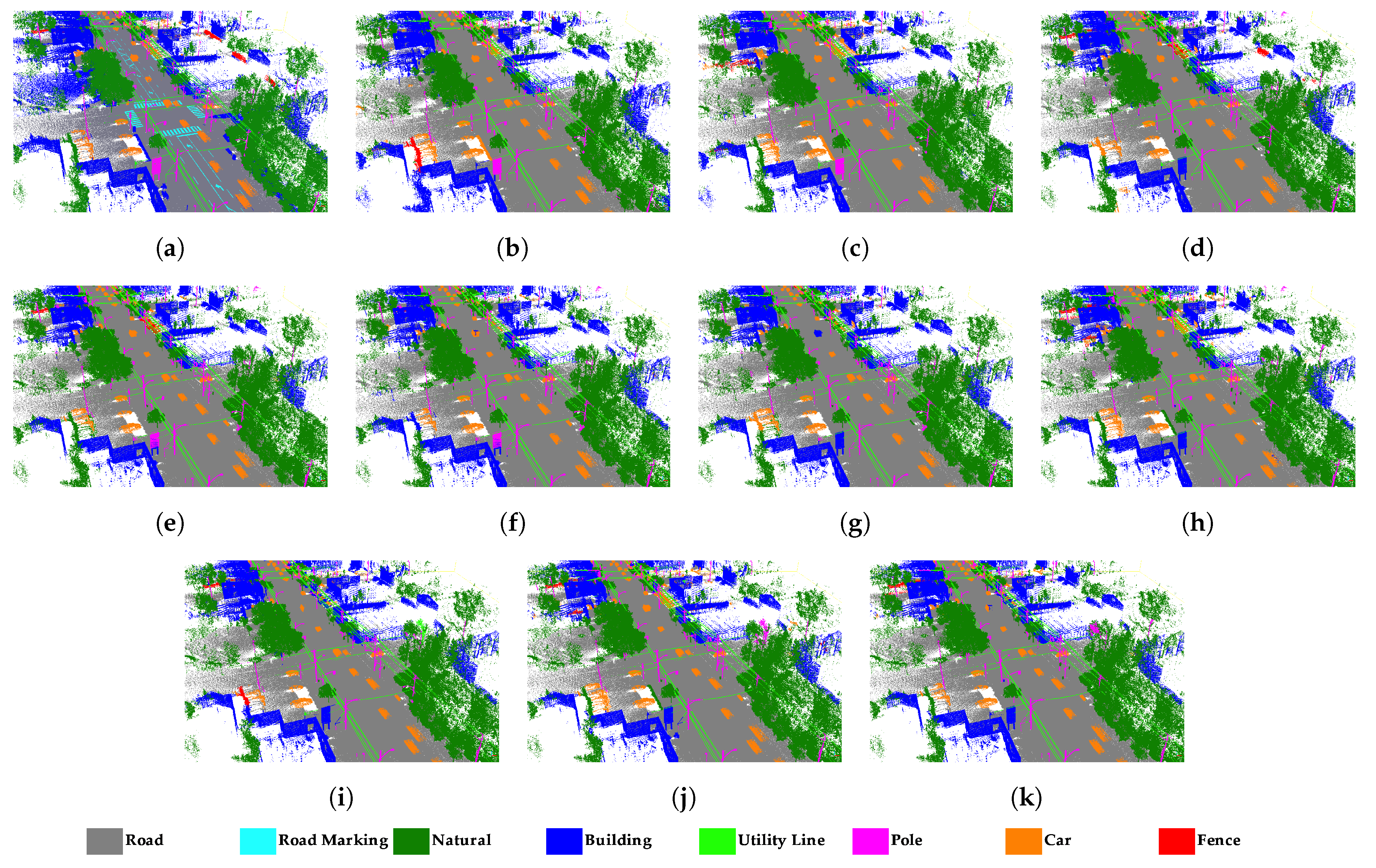
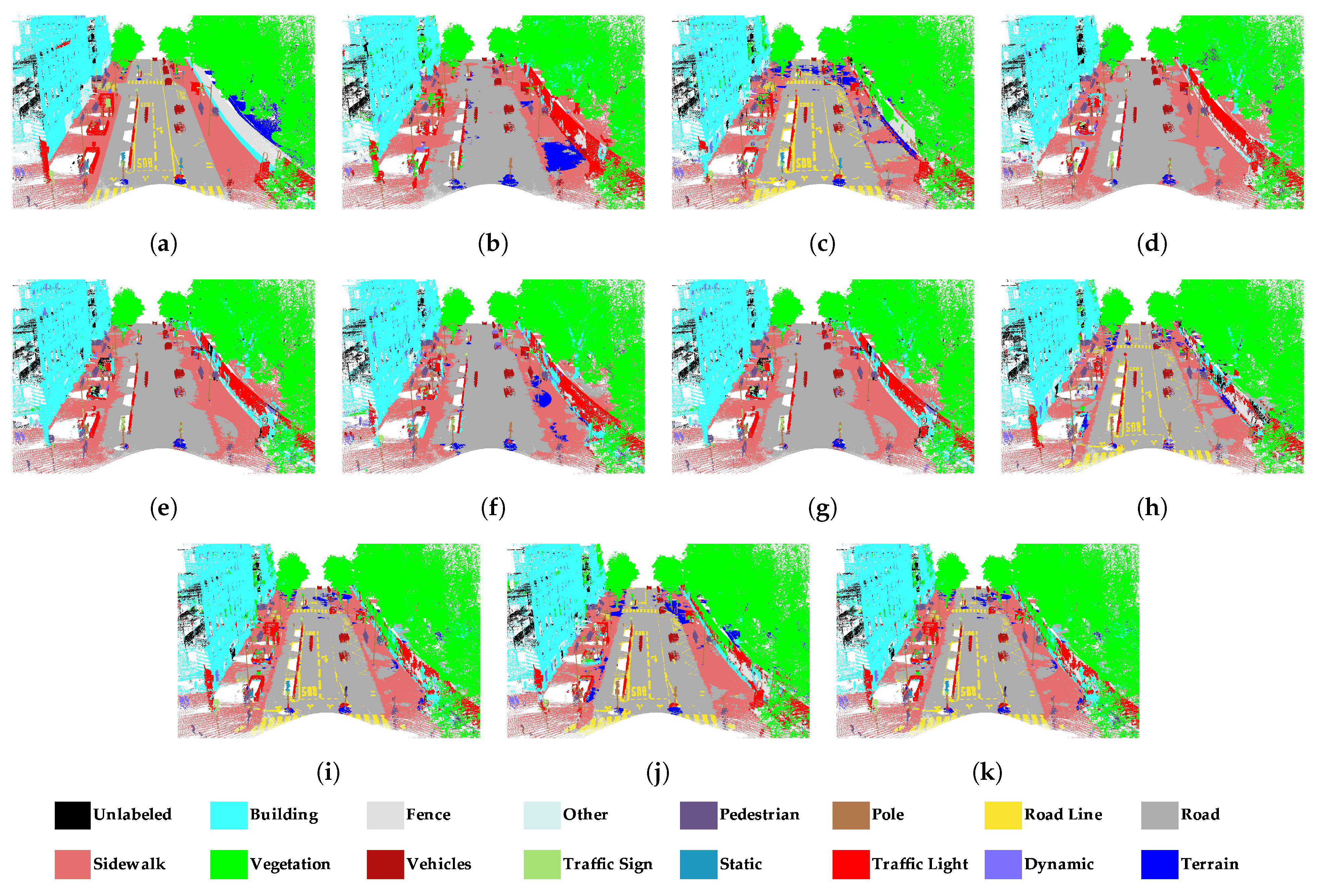
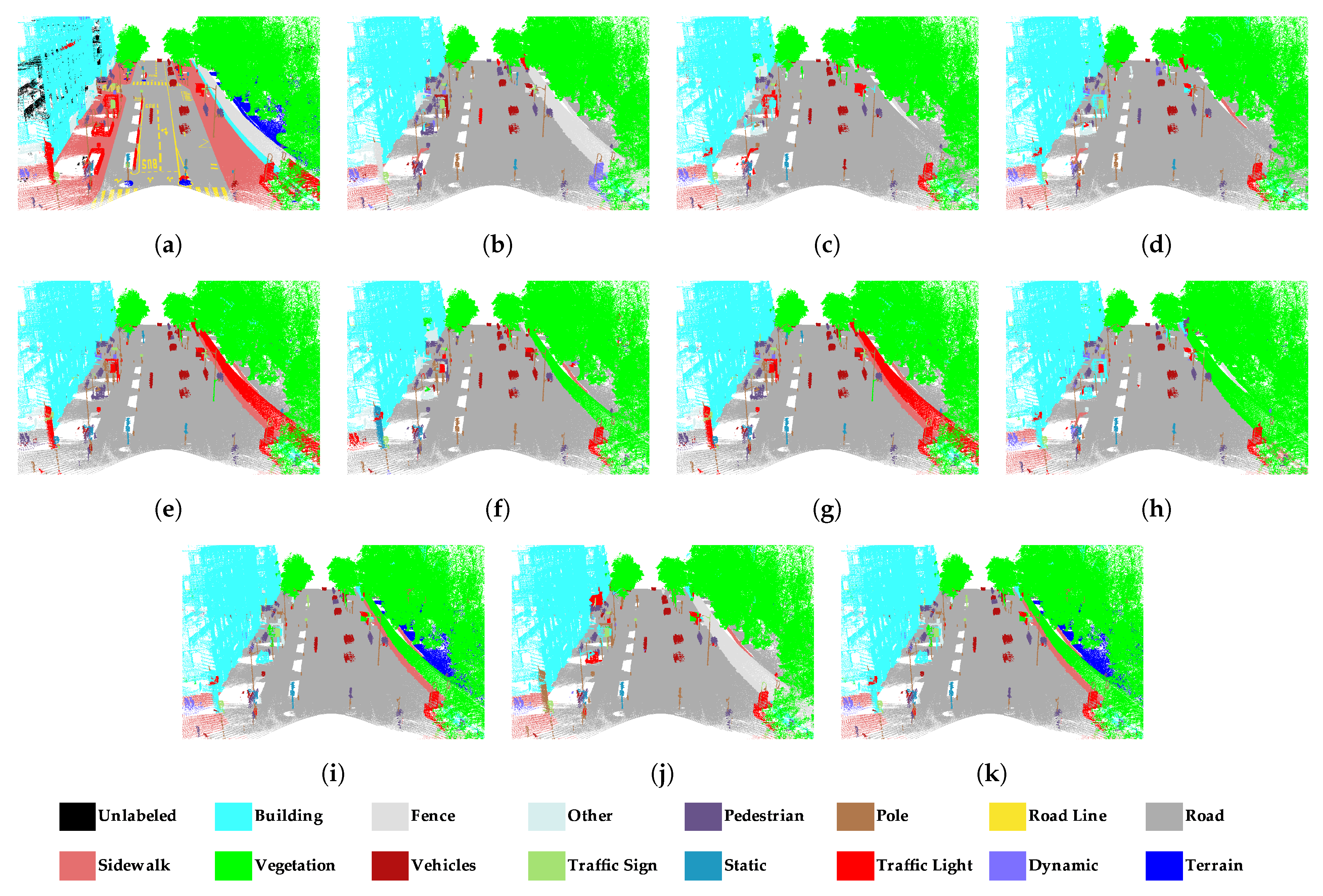
4.4. Results of Semantic Segmentation on Paris
5. Discussion
- When Table 1, Table 2, Table 3, Table 4, Table 5 and Table 6 are examined, it is concluded that the use of geometric features improves IoU and mean accuracy. The RandLA-Net algorithm achieved higher performance in , , and subsets where 3D coordinates and all 3D geometric features are used together, compared to , , and subsets containing only 3D point coordinates. In Toronto3D, accuracy metrics have increased in subsets where RGB and 3D geometric features are used together, except for the subset, because there are features that do not positively impact accuracy among 3D geometric features. Obtaining the highest mean accuracy metrics with the , and subsets applied to the feature selection confirms this situation. Furthermore, the addition of RGB information of the points improves accuracy. has higher mIoU than , and with an added 3D geometric feature. The main reason for this is that the road marking class is detected more accurately in . When the mIoU average of the classes is calculated by subtracting the road marking, has 73.4% mIoU, and , and have 72.4%, 76.0% and 75.0% mIoU, respectively. Geometric features improve accuracy in many classes, especially when Chi2 and ReliefF algorithms are applied. In the SZTAKI-CityMLS dataset, although two features were eliminated with the IG method in the subset, more successful results were obtained by 3.4% in mIoU and 1.6% in MA than , which includes all geometric features. Despite the large number of classes, RandLA-Net has successful results in the Paris dataset. In the subset, which includes all of the RGB and 3D geometric features, there is a decrease in accuracy compared to . However, the highest mIoU value is obtained in and using the features selected with IG and ReliefF. When 3D coordinates and geometric features are used together, there is no significant metric difference between filter-based algorithms. Since RGB information is advantageous for finding classes such as road line, subsets , , , , and containing RGB information significantly increased in IoU compared to those without RGB.
- RandLA-Net performed well in the road, building, and natural classes in Toronto3D. However, road marking was confused by the road. As seen in Table 1, road marking IoU values are very low, especially in subsets , , , , and without RGB. Road markings cover pavement markings including driving lines, arrows, and pedestrian crossings. These markings do not differ from the road class geometrically. Therefore, it is not possible to distinguish road markings using only 3D geometric features. The main difference between road and road markings is in the RGB information. Therefore, road marking has higher IoU in subsets with RGB compared to others. In the subset, the road marking IoU reached approximately 50%. In the fence class, IoU values are generally below 30%. Because fence class has a fewer numbers of points than the others, it was predicted with lower IoU. In SZTAKI-CityMLS dataset, tram/bus, vegetation, column, ground, and facade classes are predicted correctly in all cases. Here, phantom objects are usually the class with the lowest IoU. Classification of phantom objects is a challenge in MLS point clouds. Phantom objects that exist in point clouds representing temporary objects (vehicles, people, or animals) cannot be used for mapping purposes. Phantom objects are confused with other objects because they have irregular geometric structure. It is quite difficult to detect phantom objects using 3D geometric features. When all geometric features are used in the subset, the IoU of the phantom class decreases. However, the IoU value was significantly increased, with seven features selected by the IG method. It seems that the planarity and linearity features negatively affect the accuracy of the phantom class. Significant improvement in the accuracy of the phantom class has been achieved with optimal feature selection. The pedestrian class is often mixed with other classes located nearby. According to Table 5, building, road, and vegetation were successfully extracted in all subsets with RandLA-Net in Paris dataset. Higher IoU is achieved when RGB information is added to the feature vector for the road line class, as in Toronto3D. The classes with the lowest IoU are fence, other, static, dynamic, and terrain. These classes are often confused with other classes of similar characteristics. Dynamic objects can be assigned to other classes because they are geometrically complex and diverse. While the Terrain class is almost never removed in other subsets, the IoU value reaches 55.8% IoU with the and subsets. It is often confused with vegetation and road. and selected with Chi2 are not enough to distinguish terrain.
- Feature selection improves evaluation metrics in all datasets in the semantic segmentation performed with SPG. Adding RGB or geometric features in the Toronto3D dataset increases the accuracy of semantic segmentation. Chi2 is superior to other methods in semantic segmentation of Toronto3D with SPG. The mIoU of is 1.2% higher than , which includes all geometric features, and the mIoU of is 2.8% higher than , which includes RGB and all geometric features. Features selected with ReliefF reduce the semantic segmentation accuracy of SPG in Toronto3D. In SZTAKI-CityMLS, the highest accuracy was obtained in the subset created with the features selected with IG. In the Paris dataset, as in RandLA-Net, the highest mIoU was obtained in and created with IG and ReliefF. Generally, the subset results are similar to RandLA-Net. Thus, it was concluded that the features determined via filter-based methods have similar effects in different algorithms.
- Road markings are assigned as road. Since road and road marking (line) have the same geometric structure, they cannot be distinguished by SPG, which mostly uses geometric relationships. The most significant differences between the subsets in the Toronto3D dataset occur in the fence class. Adding RGB information in particular increases the IoU of the car class. Although SPG has a better result in determining the phantom class in SZTAKI-CityMLS, some points belonging to the tram/bus class are assigned to the phantom class. IoU increased in most classes with IG, while it decreased with ReliefF.
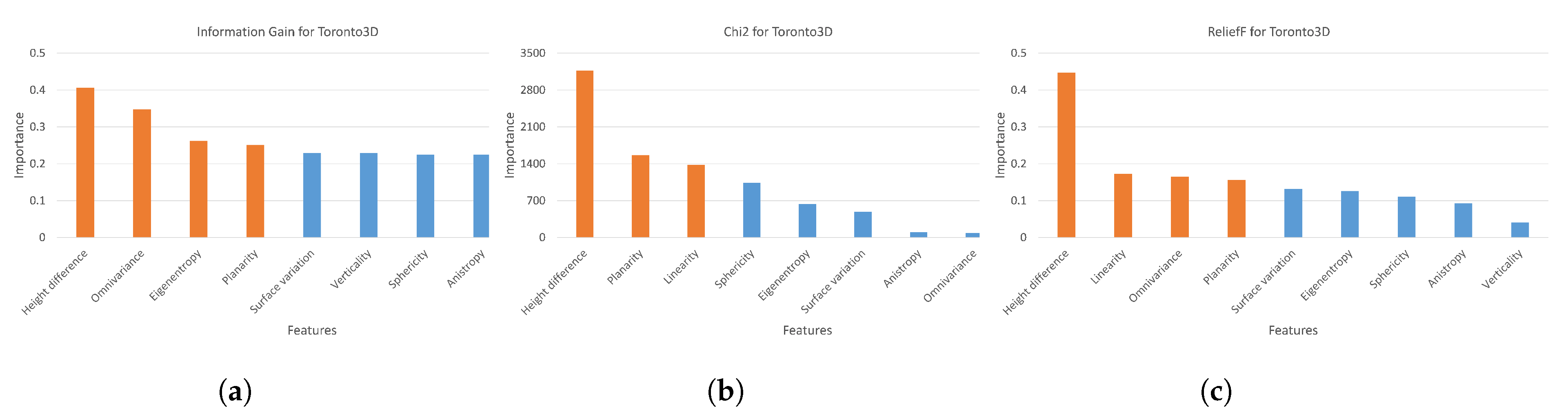
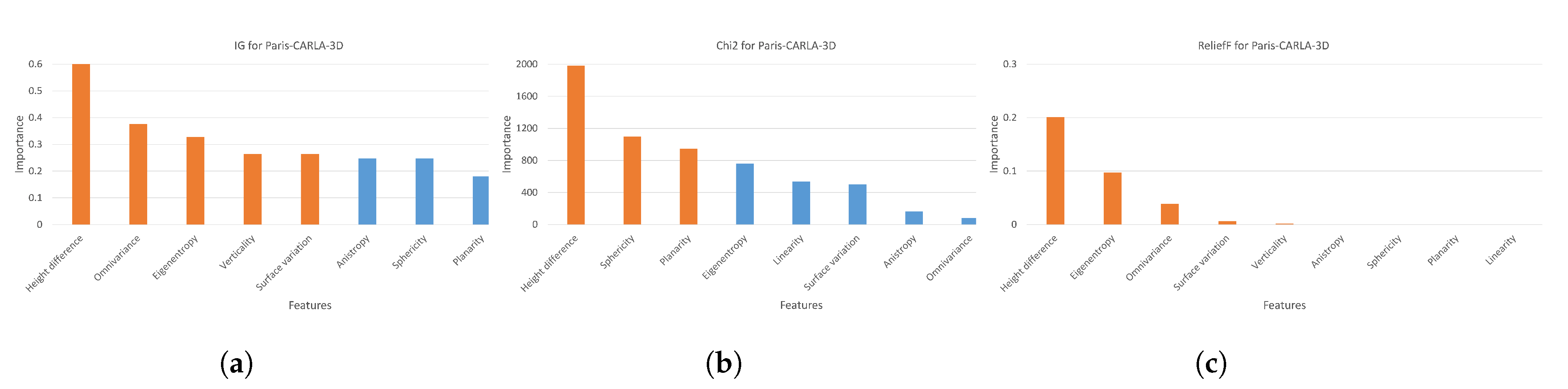
- IG and Chi2 algorithms performed more successful feature selection in the Toronto3D dataset. Semantic segmentation with features determined by ReliefF has lower accuracy. According to the results presented in Figure 2, ReliefF calculated the effect of features other than height difference as both very low and close to each other. In addition, although similar features have high importance, it was concluded that the combination of features is important for semantic segmentation. Although there is only one feature difference between and , an increase of approximately 3% mIoU and 1.6% MA is achieved with . Even though only the omnivariance feature was added in , mIoU decreased by 1.2% and MA by 4.2% compared to . When RGB is added to the selected features, the highest metrics created with Chi2 are obtained. In the semantic segmentation of the SZTAKI-CityMLS dataset, the positive effect of 3D geometric features on accuracy is seen more clearly. All other subsets containing 3D geometric features are superior to the dataset , which contains only the 3D coordinates of the points. Although there is no significant difference between filter-based algorithms when only selected geometric features are used, when RGB information is added, approximately 2.5% improvement in mIoU is achieved in subsets created with features selected by IG and ReliefF algorithms compared to Chi2 in Paris dataset.
- However, instead of using all of the geometric features, the results are more successful when the most suitable ones are selected with feature selection. Although all geometric features were used in the subsets , , , , and , the highest metrics could not be obtained. Some of the features can negatively affect semantic segmentation. For this reason, applying feature selection methods enabled the development of semantic segmentation results by eliminating unnecessary features. This is confirmed by the results of the study.
6. Conclusions
- Using all geometric features does not guarantee better results. Feature selection methods improve semantic segmentation accuracy by identifying suitable features. This improvement becomes even more evident, especially if there are geometrical differences between classes. The usage of effective geometric features provides an advantage in semantic segmentation.
- Successful results were obtained by selecting features with the IG method in all datasets. Thanks to the feature selection with the Chi2 method, the highest mean accuracy is obtained in Toronto3D, while the IG method is more successful than Chi2 in the SZTAKI-CityMLS and Paris datasets. The feature selection problem may differ depending on the dataset. The fact that the datasets are different and the datasets have different features related to each other causes the appropriate feature selection method to change. Similar feature selection algorithms can be used for datasets with similar features.
- Evaluation metrics increase if spectral information is used together with 3D geometric features. Spectral features are useful for separating features such as road lines.
- Mobile point clouds are often captured in a dynamic environment. Future studies will focus on eliminating the noise caused by dynamic objects (moving car, moving pedestrian, other living beings, etc.) in the mobile LiDAR point clouds.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bello, S.A.; Yu, S.; Wang, C.; Adam, J.M.; Li, J. Review: Deep learning on 3D point clouds. Remote Sens. 2020, 12, 1729. [Google Scholar] [CrossRef]
- Griffiths, D.; Boehm, J. A Review on deep learning techniques for 3D sensed data classification. Remote Sens. 2019, 11, 1499. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3D Point Clouds: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4338–4364. [Google Scholar] [CrossRef]
- Duran, Z.; Aydar, U. Digital modeling of world’s first known length reference unit: The Nippur cubit rod. J. Cult. Herit. 2012, 13, 352–356. [Google Scholar] [CrossRef]
- Hoang, L.; Lee, S.H.; Lee, E.J.; Kwon, K.R. GSV-NET: A Multi-Modal Deep Learning Network for 3D Point Cloud Classification. Appl. Sci. 2022, 12, 483. [Google Scholar] [CrossRef]
- He, Y.; Chen, W.; Li, C.; Luo, X.; Huang, L. Fast and accurate lane detection via graph structure and disentangled representation learning. Sensors 2021, 21, 4657. [Google Scholar] [CrossRef]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. SqueezeSegV2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a LiDAR point cloud. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4376–4382. [Google Scholar]
- Akyol, O.; Duran, Z. Low-Cost Laser Scanning System Design. J. Russ. Laser Res. 2014, 35, 244–251. [Google Scholar] [CrossRef]
- Rim, B.; Lee, A.; Hong, M. Semantic segmentation of large-scale outdoor point clouds by encoder–decoder shared mlps with multiple losses. Remote Sens. 2021, 13, 3121. [Google Scholar] [CrossRef]
- Weinmann, M.; Jutzi, B.; Hinz, S.; Mallet, C. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers. ISPRS J. Photogramm. Remote Sens. 2015, 105, 286–304. [Google Scholar] [CrossRef]
- Atik, M.E.; Duran, Z.; Seker, D.Z. Machine learning-based supervised classification of point clouds using multiscale geometric features. ISPRS Int. J. Geo-Inf. 2021, 10, 187. [Google Scholar] [CrossRef]
- Atik, M.E.; Duran, Z. Classification of Aerial Photogrammetric Point Cloud Using Recurrent Neural Networks. Fresenius Environ. Bull. 2021, 30, 4270–4275. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland; pp. 234–241. [Google Scholar]
- Atik, S.O.; Ipbuker, C. Building Extraction in VHR Remote Sensing Imagery Through Deep Learning. Fresenius Environ. Bull. 2022, 31, 8468–8473. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Atik, S.O.; Ipbuker, C. Integrating convolutional neural network and multiresolution segmentation for land cover and land use mapping using satellite imagery. Appl. Sci. 2021, 11, 5551. [Google Scholar] [CrossRef]
- Atik, S.O.; Atik, M.E.; Ipbuker, C. Comparative research on different backbone architectures of DeepLabV3+ for building segmentation. J. Appl. Remote Sens. 2022, 16, 024510. [Google Scholar] [CrossRef]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-Net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, DC, USA, 16–18 June 2020; pp. 11108–11117. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-Scale Point Cloud Semantic Segmentation with Superpoint Graphs. arXiv 2017, arXiv:1711.09869. [Google Scholar]
- Liu, H.; Setiono, R. Chi2: Feature selection and discretization of numeric attributes. In Proceedings of the Seventh IEEE International Conference on Tools with Artificial Intelligence, Herndon, VA, USA, 29–31 May 1995; pp. 388–391. [Google Scholar]
- Robnik-Šikonja, M.; Kononenko, I. Theoretical and Empirical Analysis of ReliefF and RReliefF. Mach. Learn. 2003, 53, 23–69. [Google Scholar] [CrossRef]
- Tan, W.; Qin, N.; Ma, L.; Li, Y.; Du, J.; Cai, G.; Yang, K.; Li, J. Toronto-3D: A large-scale mobile LiDAR dataset for semantic segmentation of urban roadways. arXiv 2020, arXiv:2003.08284. [Google Scholar]
- Nagy, B.; Benedek, C. 3D CNN-based semantic labeling approach for mobile laser scanning data. IEEE Sens. J. 2019, 19, 7269. [Google Scholar] [CrossRef]
- Deschaud, J.E.; Duque, D.; Richa, J.P.; Velasco-Forero, S.; Marcotegui, B.; Goulette, F. Paris-CARLA-3D: A Real and Synthetic Outdoor Point Cloud Dataset for Challenging Tasks in 3D Mapping. Remote Sens. 2021, 13, 4713. [Google Scholar] [CrossRef]
- Lawin, F.J.; Danelljan, M.; Tosteberg, P.; Bhat, G.; Khan, F.S.; Felsberg, M. Deep projective 3D semantic segmentation. In Proceedings of the 2017 International Conference on Computer Analysis of Images and Patterns, Ystad, Sweden, 22–24 August 2017; pp. 95–107. [Google Scholar]
- Meng, H.Y.; Gao, L.; Lai, Y.K.; Manocha, D. VV-net: Voxel VAE net with group convolutions for point cloud segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 8500–8508. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 77–85. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5105–5114. [Google Scholar]
- Jiang, M.; Wu, Y.; Zhao, T.; Zhao, Z.; Lu, C. PointSIFT: A SIFT-like Network Module for 3D Point Cloud Semantic Segmentation. arXiv 2018, arXiv:1807.00652. [Google Scholar]
- Lowe, G. SIFT—The Scale Invariant Feature Transform. Int. J. Comput. Vis. 2004, 2, 91–110. [Google Scholar] [CrossRef]
- Engelmann, F.; Kontogianni, T.; Schult, J.; Leibe, B. Know what your neighbors do: 3D semantic segmentation of point clouds. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhao, H.; Jiang, L.; Fu, C.W.; Jia, J. Pointweb: Enhancing local neighborhood features for point cloud processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5565–5573. [Google Scholar]
- Zhang, Z.; Hua, B.S.; Yeung, S.K. ShellNet: Efficient point cloud convolutional neural networks using concentric shells statistics. In Proceedings of the IEEE International Conference on Computer Vision, Thessaloniki, Greece, 23–25 September 2019; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2019; pp. 1607–1616. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L. KPConv: Flexible and deformable convolution for point clouds. arXiv 2019, arXiv:1904.08889. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution on X-transformed points. In Advances in Neural Information Processing Systems 31; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 820–830. [Google Scholar]
- Xu, Y.; Fan, T.; Xu, M.; Zeng, L.; Qiao, Y. SpiderCNN: Deep learning on point sets with parameterized convolutional filters. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Boulch, A. ConvPoint: Continuous convolutions for point cloud processing. Comput. Graph. 2020, 88, 24–34. [Google Scholar] [CrossRef]
- Zhou, H.; Feng, Y.; Fang, M.; Wei, M.; Qin, J.; Lu, T. Adaptive Graph Convolution for Point Cloud Analysis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 19–25 June 2021; pp. 4965–4974. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph Cnn for learning on point clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Lin, Z.H.; Huang, S.Y.; Wang, Y.C.F. Convolution in the cloud: Learning deformable kernels in 3D graph convolution networks for point cloud analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1800–1809. [Google Scholar]
- Liu, J.; Ni, B.; Li, C.; Yang, J.; Tian, Q. Dynamic points agglomeration for hierarchical point sets learning. Proc. IEEE Int. Conf. Comput. Vis. 2019, 2019, 7545–7554. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 922–928. [Google Scholar]
- Liao, L.; Tang, S.; Liao, J.; Li, X.; Wang, W.; Li, Y.; Guo, R. A Supervoxel-Based Random Forest Method for Robust and Effective Airborne LiDAR Point Cloud Classification. Remote Sens. 2022, 14, 1516. [Google Scholar] [CrossRef]
- Choy, C.; Gwak, J.; Savarese, S. 4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3075–3084. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1887–1893. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. RangeNet ++: Fast and Accurate LiDAR Semantic Segmentation. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Macau, China, 4–8 November 2019; IEEE: New York, NY, USA, 2019; pp. 4213–4220. [Google Scholar]
- Cortinhal, T.; Tzelepis, G.; Aksoy, E.E. SalsaNext: Fast, Uncertainty-Aware Semantic Segmentation of LiDAR Point Clouds. In Advances in Visual Computing ISVC 2020 Lecture Notes in Computer Science; Bebis, G., Ed.; Springer: Cham, Switzerland, 2020; Volume 12510, pp. 207–222. [Google Scholar]
- Aksoy, E.E.; Baci, S.; Cavdar, S. SalsaNet: Fast Road and Vehicle Segmentation in LiDAR Point Clouds for Autonomous Driving. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 926–932. [Google Scholar]
- Biasutti, P.; Lepetit, V.; Aujol, J.F.; Bredif, M.; Bugeau, A. LU-net: An efficient network for 3D LiDAR point cloud semantic segmentation based on end-to-end-learned 3D features and U-net. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Atik, M.E.; Duran, Z. An Efficient Ensemble Deep Learning Approach for Semantic Point Cloud Segmentation Based on 3D Geometric Features and Range Images. Sensors 2022, 22, 6210. [Google Scholar] [CrossRef] [PubMed]
- Jaritz, M.; Gu, J.; Su, H. Multi-view PointNet for 3D Scene Understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCVW), Seoul, Korea, 1 October 2019; pp. 3995–4003. [Google Scholar]
- Meng, Q.; Wang, W.; Zhou, T.; Shen, J.; Jia, Y.; Van Gool, L. Towards a Weakly Supervised Framework for 3D Point Cloud Object Detection and Annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4454–4468. [Google Scholar] [CrossRef]
- Wu, B.; Chen, C.; Kechadi, T.M.; Sun, L. A comparative evaluation of filter-based feature selection methods for hyper-spectral band selection. Int. J. Remote Sens. 2013, 34, 7974–7990. [Google Scholar] [CrossRef]
- Lei, S. A feature selection method based on information gain and genetic algorithm. In Proceedings of the 2012 International Conference on Computer Science and Electronics Engineering, Hangzhou, China, 23–25 March 2012; Volume 2, pp. 355–358. [Google Scholar]
- Colkesen, I.; Kavzoglu, T. Selection of Optimal Object Features in Object-Based Image Analysis Using Filter-Based Algorithms. J. Indian Soc. Remote Sens. 2018, 46, 1233–1242. [Google Scholar] [CrossRef]
- Kononenko, I. Estimating attributes: Analysis and extensions of RELIEF. In Proceedings of the European Conference on Machine Learning; Springer: Catania, Italy, 1994; pp. 171–182. [Google Scholar]
- Duran, Z.; Ozcan, K.; Atik, M.E. Classification of photogrammetric and airborne lidar point clouds using machine learning algorithms. Drones 2021, 5, 104. [Google Scholar] [CrossRef]
- Pedregosa, F.; Gramfort, N.A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; Vanderplas, J.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Holmes, G.; Donkin, A.; Witten, I.H. WEKA: A machine learning workbench. In Proceedings of the ANZIIS ’94—Australian New Zealnd Intelligent Information Systems Conference, Brisbane, Australia, 29 November–2 December 1994. [Google Scholar]
- Zhou, Q.Y.; Park, J.; Koltun, V. Open3D: A Modern Library for 3D Data Processing. arXiv 2018, arXiv:1801.09847. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subset | Road | Road Mrk. | Natural | Building | Util. Line | Pole | Car | Fence | mIoU | MA |
|---|---|---|---|---|---|---|---|---|---|---|
| 69.4 | 7.7 | 92.3 | 85.7 | 76.3 | 70.0 | 76.9 | 7.95 | 60.8 | 74.2 | |
| 94.0 | 49.6 | 93.3 | 84.4 | 78.5 | 69.9 | 79.5 | 14.1 | 70.4 | 86.0 | |
| 77.1 | 6.1 | 94.7 | 91.2 | 85.9 | 72.6 | 50.6 | 23.4 | 62.7 | 79.8 | |
| 91.0 | 7.2 | 95.8 | 92.1 | 84.9 | 78.3 | 83.7 | 23.2 | 69.5 | 76.6 | |
| 79.4 | 6.7 | 95.2 | 92.2 | 84.6 | 73.9 | 80.4 | 31.9 | 68.0 | 79.2 | |
| 90.5 | 8.2 | 94.8 | 91.6 | 85.1 | 74.9 | 69.2 | 20.1 | 66.8 | 75.0 | |
| 77.8 | 17.5 | 95.3 | 90.4 | 85.6 | 76.9 | 51.6 | 25.7 | 65.1 | 83.1 | |
| 87.5 | 37.8 | 95.5 | 89.6 | 82.1 | 79.3 | 49.5 | 23.4 | 68.2 | 87.2 | |
| 87.2 | 29.2 | 95.2 | 90.7 | 83.1 | 76.1 | 79.1 | 20.5 | 70.1 | 87.4 | |
| 87.6 | 31.9 | 95.2 | 88.5 | 83.7 | 78.0 | 71.9 | 20.7 | 69.5 | 87.2 |
| Subset | Road | Road Mrk. | Natural | Building | Util. Line | Pole | Car | Fence | mIoU | MA |
|---|---|---|---|---|---|---|---|---|---|---|
| 94.1 | 0.0 | 90.4 | 84.6 | 81.9 | 72.0 | 82.7 | 1.4 | 63.4 | 68.8 | |
| 94.2 | 0.0 | 94.2 | 87.4 | 83.2 | 77.7 | 83.9 | 2.4 | 65.4 | 69.3 | |
| 94.5 | 0.0 | 94.6 | 90.0 | 79.2 | 72.4 | 85.4 | 11.9 | 66.0 | 71.7 | |
| 94.5 | 0.0 | 94.6 | 88.6 | 79.2 | 75.2 | 84.5 | 11.4 | 66.0 | 73.4 | |
| 94.3 | 0.0 | 94.3 | 91.4 | 78.0 | 74.9 | 86.9 | 17.8 | 67.2 | 72.5 | |
| 94.5 | 0.0 | 93.3 | 88.1 | 79.3 | 74.7 | 77.1 | 6.8 | 64.2 | 69.3 | |
| 94.4 | 0.0 | 95.6 | 90.6 | 80.8 | 70.0 | 89.1 | 15.4 | 67.0 | 72.3 | |
| 94.1 | 0.0 | 94.3 | 91.7 | 79.4 | 68.7 | 89.5 | 22.5 | 67.5 | 73.8 | |
| 94.4 | 0.0 | 95.6 | 90.5 | 79.7 | 69.7 | 91.2 | 37.3 | 69.8 | 75.9 | |
| 94.1 | 0.0 | 94.3 | 89.1 | 81.8 | 71.4 | 89.5 | 4.7 | 65.6 | 70.0 |
| Subset | Phantom | Tram/Bus | Pedestrian | Car | Vegetation | Column | Street Furn. | Ground | Facade | mIoU | MA |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 45.4 | 91.8 | 53.3 | 45.7 | 99.2 | 83.9 | 69.1 | 97.6 | 98.2 | 76.0 | 89.4 | |
| 42.9 | 99.7 | 51.4 | 55.7 | 99.8 | 89.1 | 89.8 | 98.9 | 98.9 | 80.7 | 92.1 | |
| 65.3 | 98.2 | 53.3 | 73.0 | 99.7 | 87.7 | 81.9 | 99.0 | 99.1 | 84.1 | 93.7 | |
| 50.0 | 89.8 | 57.0 | 60.0 | 99.6 | 84.8 | 81.8 | 98.1 | 98.4 | 79.9 | 92.2 | |
| 40.2 | 98.2 | 47.9 | 53.2 | 99.3 | 90.1 | 79.5 | 98.6 | 98.9 | 78.4 | 89.8 |
| Subset | Phantom | Tram/Bus | Pedestrian | Car | Vegetation | Column | Street Furn. | Ground | Facade | mIoU | MA |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 57.3 | 79.3 | 54.2 | 62.2 | 99.8 | 89.4 | 39.0 | 98.1 | 99.2 | 75.4 | 83.5 | |
| 61.5 | 80.5 | 62.0 | 62.0 | 99.9 | 91.5 | 42.3 | 98.1 | 99.3 | 77.5 | 85.2 | |
| 68.0 | 93.7 | 59.5 | 62.5 | 99.8 | 95.1 | 39.0 | 98.1 | 99.4 | 79.5 | 86.9 | |
| 61.9 | 80.4 | 60.4 | 51.0 | 99.9 | 90.4 | 44.1 | 98.1 | 99.2 | 76.1 | 84.7 | |
| 45.4 | 99.0 | 54.8 | 60.8 | 99.8 | 90.2 | 50.1 | 98.1 | 99.2 | 77.5 | 86.8 |
| Class | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Unlabeled | 72.5 | 67.3 | 68.4 | 68.3 | 72.0 | 68.3 | 60.2 | 72.0 | 68.9 | 72.0 |
| Building | 85.7 | 84.9 | 84.6 | 85.4 | 85.5 | 85.4 | 83.6 | 86.1 | 88.1 | 86.1 |
| Fence | 15.5 | 22.9 | 15.9 | 12.2 | 16.1 | 12.2 | 20.5 | 22.3 | 18.9 | 22.3 |
| Other | 22.0 | 30.2 | 23.1 | 20.3 | 26.0 | 20.3 | 27.7 | 23.5 | 27.4 | 23.5 |
| Pedestrian | 68.9 | 58.4 | 50.7 | 61.4 | 64.1 | 61.4 | 42.2 | 60.5 | 67.9 | 60.5 |
| Pole | 51.3 | 61.8 | 48.5 | 49.6 | 49.4 | 49.6 | 55.0 | 60.2 | 56.0 | 60.2 |
| Road Line | 0.0 | 65.3 | 0.0 | 0.0 | 0.0 | 0.0 | 72.3 | 69.2 | 70.0 | 69.2 |
| Road | 84.9 | 86.9 | 85.1 | 85.6 | 83.7 | 85.6 | 91.9 | 91.2 | 93.2 | 91.2 |
| Sidewalk | 63.7 | 58.6 | 63.1 | 62.1 | 57.4 | 62.1 | 67.5 | 72.5 | 60.9 | 72.5 |
| Vegetation | 89.5 | 84.3 | 90.2 | 88.5 | 91.9 | 88.5 | 89.4 | 86.8 | 85.6 | 86.8 |
| Vehicles | 75.7 | 84.2 | 84.7 | 84.3 | 75.2 | 84.3 | 77.3 | 82.0 | 84.1 | 82.0 |
| Traffic Sign | 0.0 | 51.8 | 24.2 | 21.8 | 29.0 | 21.8 | 34.6 | 48.1 | 46.5 | 48.1 |
| Static | 0.0 | 30.5 | 2.6 | 0.0 | 0.0 | 0.0 | 0.0 | 32.2 | 0.0 | 32.2 |
| Traffic Light | 33.4 | 36.0 | 36.2 | 46.1 | 24.6 | 46.1 | 38.4 | 45.7 | 42.5 | 45.7 |
| Dynamic | 15.1 | 18.9 | 14.9 | 14.2 | 10.0 | 14.2 | 23.4 | 25.6 | 28.1 | 25.6 |
| Terrain | 4.2 | 1.3 | 5.0 | 3.8 | 5.7 | 3.8 | 7.5 | 5.0 | 6.4 | 5.0 |
| mIoU | 42.7 | 52.7 | 43.6 | 43.9 | 43.2 | 43.9 | 49.5 | 55.2 | 52.6 | 55.2 |
| MA | 54.1 | 68.0 | 55.0 | 54.7 | 53.6 | 54.7 | 63.7 | 67.9 | 65.5 | 67.9 |
| Class | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Unlabeled | 1.9 | 2.0 | 2.5 | 2.7 | 3.4 | 2.7 | 2.5 | 55.8 | 2.7 | 55.8 |
| Building | 88.3 | 86.3 | 87.4 | 88.3 | 87.1 | 88.3 | 85.9 | 87.4 | 85.8 | 87.4 |
| Fence | 31.1 | 23.8 | 0.7 | 10.6 | 28.3 | 10.6 | 6.1 | 14.7 | 14.7 | 14.7 |
| Other | 23.4 | 17.0 | 6.3 | 19.1 | 24.6 | 19.1 | 20.0 | 11.9 | 10.5 | 11.9 |
| Pedestrian | 33.4 | 62.7 | 59.6 | 58.3 | 50.2 | 58.3 | 48.2 | 62.7 | 73.7 | 62.7 |
| Pole | 56.8 | 54.7 | 58.1 | 58.9 | 47.9 | 58.9 | 54.8 | 50.9 | 55.4 | 50.9 |
| Road Line | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Road | 74.6 | 72.9 | 73.0 | 74.6 | 73.7 | 74.6 | 75.2 | 75.2 | 74.6 | 75.2 |
| Sidewalk | 0.9 | 2.1 | 2.5 | 0.7 | 0.2 | 0.7 | 2.4 | 1.2 | 1.2 | 1.2 |
| Vegetation | 94.7 | 94.3 | 94.9 | 93.9 | 88.6 | 93.9 | 80.9 | 89.2 | 93.9 | 89.2 |
| Vehicles | 77.3 | 88.9 | 84.6 | 82.5 | 87.0 | 82.5 | 84.5 | 86.2 | 91.6 | 86.2 |
| Traffic Sign | 35.8 | 23.9 | 38.8 | 24.5 | 22.6 | 24.5 | 34.6 | 41.8 | 35.7 | 41.8 |
| Static | 30.1 | 22.3 | 13.4 | 34.5 | 10.4 | 34.5 | 24.9 | 24.9 | 26.3 | 24.9 |
| Traffic Light | 1.2 | 33.0 | 6.7 | 12.1 | 19.5 | 12.1 | 9.0 | 9.1 | 16.7 | 9.1 |
| Dynamic | 4.4 | 17.3 | 17.0 | 6.2 | 5.9 | 6.2 | 20.4 | 4.5 | 8.7 | 4.5 |
| Terrain | 1.9 | 2.0 | 2.5 | 2.7 | 3.4 | 2.7 | 2.5 | 55.8 | 2.7 | 55.8 |
| mIoU | 53.1 | 57.5 | 52.3 | 54.4 | 52.6 | 54.4 | 52.7 | 59.0 | 56.7 | 59.0 |
| MA | 46.1 | 45.8 | 43.1 | 46.4 | 44.3 | 46.4 | 45.9 | 48.1 | 45.8 | 48.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Atik, M.E.; Duran, Z. Selection of Relevant Geometric Features Using Filter-Based Algorithms for Point Cloud Semantic Segmentation. Electronics 2022, 11, 3310. https://doi.org/10.3390/electronics11203310
Atik ME, Duran Z. Selection of Relevant Geometric Features Using Filter-Based Algorithms for Point Cloud Semantic Segmentation. Electronics. 2022; 11(20):3310. https://doi.org/10.3390/electronics11203310
Chicago/Turabian StyleAtik, Muhammed Enes, and Zaide Duran. 2022. "Selection of Relevant Geometric Features Using Filter-Based Algorithms for Point Cloud Semantic Segmentation" Electronics 11, no. 20: 3310. https://doi.org/10.3390/electronics11203310
APA StyleAtik, M. E., & Duran, Z. (2022). Selection of Relevant Geometric Features Using Filter-Based Algorithms for Point Cloud Semantic Segmentation. Electronics, 11(20), 3310. https://doi.org/10.3390/electronics11203310